ODM Business Rules with Apache Spark Batch operations
This article by Pierre Feillet an ODM Product Architect is for Decision Management architects who are looking to combine the strengths of Apache® Spark™ Analytics batch operations with the leading ODM business rules capabilities for improved decisions. This is the first of a set or articles on IBM Operational Decision Manager and Spark.
Introduction
Apache® Spark™ is an open-source cluster computing framework with in-memory processing to speed analytic applications. Highly versatile and scalable in many environments, Apache Spark gets an increasing popularity for its ease of use in creating algorithms that harness insight from complex data.
This framework brings a programming model and an engine to empower big data parallel processing while targeting performance and resiliency. It brings a general purpose cluster computing system with a rich set of higher level tools including for machine learning.
But what about running business rules in this cluster engine. Such an integration makes value for the following use cases:
- running massive decision making batches highly distributed on a cluster
- computing metrics and KPIs on decision batches in simulation or production workloads
- invent new Machine Learning based Cognitive solutions by combining machine learning and rule based decisions
This article focus on the decision making batch use case.
It explains how you can leverage business rules technology inside a Spark application. The article will demonstrate such an integration by using IBM Operational Decision Manager Standard platform to model, test, simulate, hot deploy and execute rule based decision services that capture the business logic within that environment.
The Concepts
Apache® Spark™ provides batch processing through a graph of transformation and actions applied to Resilient Datasets. It consists as a big data analytical engine with a context that handles the application modeled as a directed acyclic graph of transformations and actions.
For the rule based decision part IBM ODM Standard manages decision services that are executed by a rule engine. A decision service is basically a function that executes a ruleset against input dataset to return a response dataset. Each piece plays the following roles:
- The request dataset bring the necessary context to take the decision by example a borrower or a patient history. This dataset is serialized typically in JSON.
- The ruleset represents the decision logic structured by a flow of tasks, selecting if-then-else rules and decision tables to evaluate. The rule engine applies the ruleset to the passed request dataset, executes the rules to produce the outcome data.
- The response dataset includes the outcome of the decision making by example the loan application approval status or the diagnostic for the patient. The response is serializable typically in JSON.
Apache Spark and IBM ODM are capable to compile their respective artifacts into Java bytecode and to run in a JRE:
- Apache Spark compiles RDD transformations and actions into Java bytecode
- IBM ODM compiles business rules into Java bytecode thanks to its Decision Engine
Let’s see the general integration pattern to invoke a rule based Decision Service inside a Spark application.
The RDD Flows to Invoke Decision Services in Spark
The main design point is to read a decision request dataset from a persistent store and dispatch the decision making in a cluster. For each request found in the batch we apply the business policy implemented as a rule based decision service. We write the decision made for each request, potentially compute metrics for each decision and KPIs for the batch.


More precisely the Apache Spark application is designed in 2 main phases each coming with internal steps:
1. Rule based decision making
- Read a decision request RDD from a file or alternate store
- Apply a Map transformation to the request RDD through a function that executes the decision service. This function calls the ODM API to load and execute the ruleset.
- Create a decision RDD with the request and the associated response for each decision made
- Save the decision RDD in HDFS or other persistent store
2. Potentially post process the decisions
- To compute one or several metrics on each decision to create a Decision metric RDD. This Map transformation extracts a parameter from the decision to typically construct a business metric.
- To compute one or several KPIs on the overall decision RDD but applying a reduce function on the Decision metrics RDD. You can by example count the total number of approved loans with an amount > 100 K dollars.
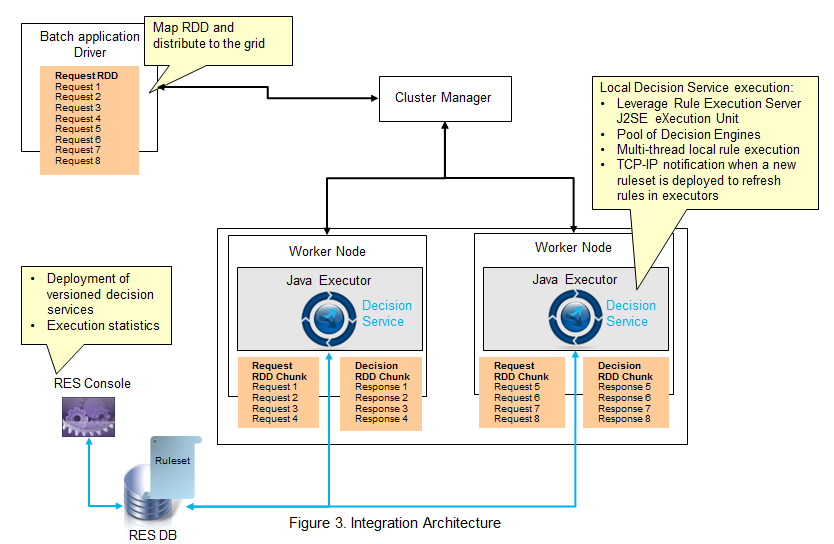
The Architecture
IBM ODM provides multiple Java APIs to enable the invocation of Decision Services. We recommend here to use the Rule Execution Server JSE RuleSession API to execute locally the rules inside the Spark JVM and leverage features as hot deployment, ruleset versioning, optimized multi-threaded execution, and management through a web console.
This choice allows deployment of the compiled decision and Rule Execution Server close to where the data resides, which avoids any extra data serialization or remoting invocations when executing. Note that remote invocation style remains possible through Web Services in SOAP or REST.
The Java or Scala written Spark application that performs the decision making, and potentially metric & KPI computation steps is run standalone or in a cluster. Spark solves the distribution of the workload across the worker nodes. Each Java executor applies the transformations and actions on the RDDs and run in memory the rule engine to take the decisions.
At the end of the batch, decision RDD, decision metric & KPI RDDs are produced and persisted.
The documented RDD flows and integration pattern have been verified with IBM ODM Standard v8.8.0, Apache Spark v1.5.2.& Java 8.
Conclusion
We have presented the blueprint of the execution of rule based decision services in an Apache Spark batch application by using IBM ODM. The 2 technologies integrate and co-exist together well as ODM provides Java API and rules compilation to run natively inside a Spark Java application. Rules based decisions are loaded on demand for the Spark worker when needed by the application.
Integration within Apache Spark uses the ODM Standard features with no custom extensions. The joint solution provides value for LOB’s and IT as it empowers business users to author, change the rules, test and simulate the decision services which provide the business control to complement the analytics. These decision services are deployed by the IT or directly by the LOB. In both cases ODM supports hot deployment of the rules without requiring a repackaging of the calling application. Integration of the decision service, its admin, and monitoring remain mastered by IT.
This complementarity opens the perspective of using business rules in Big Data analytics opening the door to massive decision automation and synergies with Machine Learning to invent a new field of cognitive applications.
[…] Read the full article […]