Planning for ODM disaster recovery
By ODM performance architects: Pierre-Andre Paumelle and Nicolas Peulvast
Introduction
Operational Decision Manager (ODM) empowers business users and developers to collaborate when they automate an organization’s business policies. ODM automates the decision making process and governs future policy updates. Execution of the business rules (decision services at run time) scales out in clusters of servers running on bare metal, virtual machines, or containers.
ODM standard is a decision making platform composed of 2 main servers, both of which use a database to store application data and state:
- Decision Server Rules enables the deployment of new versions of a decision service and notifies all of the servers to pick up the latest version.
- Decision Center is a web application to author and manage the business rules.
Note, if you need to restart Decision Server Rules or Decision Center you can start them from the databases without losing in-flight data.
As these applications are expected to be highly available (business is now globally less tolerant of downtime), a disaster can have a devastating effect if they are down for any time. A disaster can be anything that puts an organization’s operations at risk, from a cyberattack, to equipment failures, to natural disasters.
Preparing for a disaster and recovering from such an event, in a reasonable amount of time, needs you to evaluate the resistance of your company’s hardware and software, networking equipment, power, and connectivity.
The process of planning for disaster recovery (DR) must include some testing, and may involve a separate physical site for restoring operations.
Why plan for disaster recovery
DR planning aims to protect an organization from the effects of negative events. The goal of DR is for a business to continue operating as closely to normal as possible following a disaster, and to quickly resume mission-critical functions. It’s really important to hold an uninfected, or “last known good” copy of your systems, completely separate from your live systems. Backups can help to protect your organization against disasters. However, having backups is not always good enough in today’s cybercrime environment; you need to test the recovery procedures and they need to be as efficient as possible.
Recovery is a major concern because of recent ransomware attacks, like WannaCry and Bad Rabbit. For a business, the decision to pay a ransom can come down to which is cheaper: restoring from backups or paying the ransom. The Center for Internet Security has good practices to protect users and has guidelines on how to harden and secure endpoints and servers. These recommendations can help to reduce the likelihood that ransomware gets on the system and finds critical data.
Recovery point objective (RPO) and recovery time objective (RTO) are two influential measurements in DR and downtime. While implementing a thorough DR plan isn’t a small task, the potential benefits are significant.
Terms fundamental to disaster recovery
Redundancy: The provision of additional or duplicate systems or equipment if an operating part or system fails.
High Availability (HA): Ensures the system can continue to process work within one location after routine single component failures.
Continuous Operations: Ensure the system is never unavailable during planned activities. For example, if the application is upgraded to a new version, it is done in a way that avoids downtime.
Continuous Availability (CA) : High availability coupled with continuous operations. No tolerance for planned downtime and little unplanned downtime as possible. Note that while achieving CA almost always requires an aggressive DR plan, they are not the same thing.
Disaster Recovery (DR): Ensures the system can be brought back up at another location and can process work after an unexpected catastrophic failure at one location. Often multiple single failures is considered catastrophic. There may or may not be significant downtime as part of a disaster recovery. This environment may be substantially smaller than the entire production environment, as only a subset of production applications demand DR.
- Recovery Point Objective (RPO): Data recovery and acceptable data loss. RPO is the maximum age of files that an organization must recover from backup storage for normal operations to resume after a disaster. The recovery point objective determines the minimum frequency of backups. For example, if an organization has an RPO of four hours, the system must back up at least every four hours.
- Recovery Time Objective (RTO): Service recovery with little to no interruption. RTO is the maximum amount of time, following a disaster, for an organization to recover files from backup storage and resume normal operations. In other words, the recovery time objective is the maximum amount of downtime an organization can handle. If an organization has an RTO of two hours, it cannot be down for longer than that.
The following diagram shows the relationship between the two measurements:

Service Levels (SLAs): Includes a clear set of conditions that define the availability requirements of the system. The requirements take into account:
- Components of the system: A system has many pieces and business aspects. How do the requirements differ?
- Responsiveness and throughput requirements: 100% of requests aren’t going to work perfectly 100% of the time.
- Degraded service requirements: Does everything have to meet the responsiveness requirements ALL the time?
- Dependent system requirements: What are the implications if a system on which you depend is down?
- Data loss
- Application data
- Application state (is this critical in a disaster?)
- Maintenance. Change occurs, how does that affect availability?
- The unimaginable happens, then what?
Cells and data centers
Multiple cells or data centers can eliminate a single point of failure (SPOF). A SPOF is a part of a system that, if it fails, stops the entire system from working; a SPOF can be a cell or an entire data center. In both cases, having multiple points increases reliability and insurance against disaster.
However, a word of warning! It is possible to construct a network so that latency is NOT an issue under normal conditions. But, WANs are less reliable than LANs; and much harder to fix! It is also important to understand that network interdependency between data centers means that the data centers are not independent. Outages in one data center can impact cells in another data center if the cells aren’t aligned to the data center boundaries.
In a typical DR scenario, an organization can recover and restore its technology infrastructure and operations when its primary data center is unavailable. DR sites can be internal or external. Companies with large information requirements and aggressive RTOs are more likely to use an internal DR site, which is typically a second data center.
External sites can be hot, warm, or cold. An outside provider can own and operate an external DR site.
- Hot site: A fully functional data center with hardware and software, personnel and customer data, typically staffed around the clock.
- Warm site: An equipped data center that does not have customer data. An organization can install additional equipment and introduce customer data following a disaster.
- Cold site: Has infrastructure to support IT systems and data, but no technology until an organization activates DR plans and installs equipment.
Data center option 1: Classic “Active/Active”
Two active data centers is the hardest and most costly option to achieve. Active/Active has the following characteristics:
- Both centers serve requests for the same applications.
- Requires shared application data.
- Application data consistency is a prerequisite to any other planning.
- Simultaneous reads/writes requires geographic synchronous disk replication. For example, IBM High Availability Geographic Cluster (HAGEO) or Sun Cluster Geographic Edition.
- Expectation of continuous availability and transparent fail-over.
- Requires sharing application state.
- Expectation is seldom realized.
- Outage of one data center stops disk writes in both, and this is no longer “transparent”.
Note, the disk replication you employ for application data and state, WAS-ND cell configuration, software updates, and application maintenance must be maintained independently to ensure isolation (and availability).
Data center option 2: “Active/Passive”
Two data centers, where one serves requests and the other is idle. Active/Passive has the following characteristics:
- Easier than Active/Active.
- User and application state synchronization is less critical.
- Asynchronous replication is likely sufficient.
- Lower cost for network and hardware capacity.
From a capacity perspective one data center is being under utilized. Typically the idle data center does not incur S/W license charges. If you don’t pay for S/W licenses is the cost and under utilization a concern?
WebSphere and ODM licenses are available for hot, warm, and cold external sites:
- Hot: Processing requests means a license is required. DB2 and MQ require hot licenses for replication.
- Warm: Started but not processing requests means a license is not required.
- Cold: Installed but not started means a license is not required.
Data center option 3: Hybrid “Active/Active” (Partitioned by applications)
Two data centers that run RES, where both serve requests, but run different applications or new application tests. For example, a specialized data center to run decision services for one country, and another specialized data center to run different decision services for another country. Hybrid Active/Active has the following characteristics:
- No shared application state, no shared application data.
- If you run the same application in both sites in the event of a disaster, there will be a loss of service.
- Users failover from one data center to the other.
- Asynchronous replication sufficient.
- Be aware of the implications of losing 50% of your system capacity should one data center go out of service.
Provides most of the benefits of classic “Active/Active” without the cost and complexity.
Prioritization using tiers and business objectives
In order to consider the data center options:
- Group your business needs and associated applications into tiers. Tier 0 represents the least amount of off-site recover ability and tier 6 represents the most. Tier 6 has minimal to zero data loss and recovery is instantaneous (no downtime or perhaps just a few minutes of down time). While the ability to recover improves with the next highest tier, costs also increase.
- Place each application into a tier based on the hard/soft dollar impact on the organization.
- Categorize by RPO and RTO. Tier 5 may have an RTO of 24 hours, then 48 to 72 hours, then perhaps 72 to 96 hours, and so on.
The recovery time objective (RTO) provides a guideline on how quickly the system must be able to accept traffic after the disaster. It is stating the obvious but shorter times require progressively more expensive techniques. For example, a tape backup and restore is relatively inexpensive, whereas a fully redundant fully operational data center is very expensive.
The recovery point objective (RPO) determines how much data you are willing to lose when there is a disaster. Again, it might be stating the obvious but the lower the data loss you can afford the higher the cost. For example:
- Restoring from tape is relatively inexpensive but you’ll lose everything since the last backup.
- Asynchronous replication of data and system state requires significant network bandwidth to prevent falling far behind.
- Synchronous replication to the backup data center guarantees no data loss but requires very fast and reliable network and can significantly reduce performance.
Most RTO and RPO goals deeply impact application and infrastructure architecture and can’t be done “after something has happened”, when it is too late to change anything. For example, if you share data across data centers, your database and application design should avoid conflicting database updates and/or tolerate them. If application upgrades have to account for multiple versions of the application running at the same time this can impact user interface design, database layout, and so on.
Build a solid infrastructure to mitigate risk, and then add technologies to protect your data and scale your applications. The following diagram shows the infrastructure foundation and the building blocks you can use to reduce your recovery time.

Extreme RTO and RPO goals tend to conflict one another. For example, using synchronous disk replication of data gives you a zero RPO, but that means the second system can’t be operational, which raises RTO.
Trying to achieve a zero RTO AND a zero RPO is mutually exclusive!
Testing
An essential part of any plan is knowing who approves a recovery. An automated site fail-over is a bad idea, because triggering DR is very expensive and doing it if the situation does not warrant it just makes matters worse. However, one big challenge is detecting when a disaster has happened. It takes time to determine you are in a disaster state and trigger disaster procedures. While you are deciding if the system is down, you are probably missing your SLA.
An organization should have a schedule for testing its disaster recovery policy and be aware of how intrusive it is. Use the results from the tests to update the DR plan.
Recommended starting point for ODM
To begin with, if you are unsure of where to start, base your DR scenario on the Active/Passive option. The Active/Active option is harder to achieve and is more expensive. The replication of the database and LDAP can be an asynchronous replication or a backup/restore process depending on your DR objectives and service level.
The following diagram shows a DR scenario with two data centers running WAS ND with an architecture that is highly available; with one data center active and one data center passive with a network switch between them. Note that topologies with other application servers, may have variations. The tutorial on Implementing IBM Operational Decision Manager RES console for high availability describes how to configure ODM for high availability (HA).
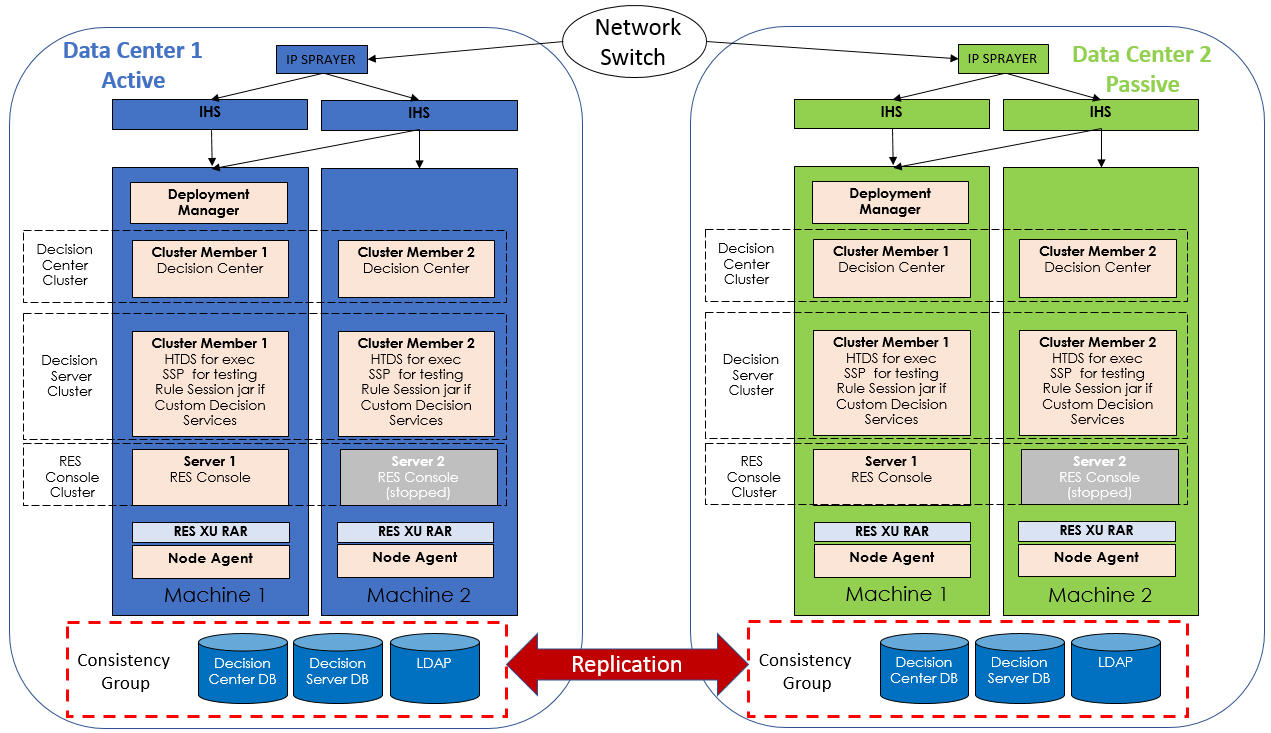
If data center 1 goes down then data center 2 switches from passive to active. All projects are loaded from the Decision Center database. LDAP content is restored to manage access to Decision Center and Decision Server Rules. Execution is restored based on the Rule Execution Server database, which contains all the necessary executable artifacts.
When data center 2 is up and ready to accept transactions, you can then switch the DNS or a VIP to route http(s) requests to data center 2.
If you want to use an Active/Active solution, contact the ODM team to help you build the solution.
Leave a Reply