Data
Architecture de données : comment choisir le bon pattern ?
Share this post:
Mes clients me posent souvent la question de la stratégie à adopter pour faire évoluer leur architecture de données. Il faut dire que celle-ci se complexifie de plus en plus, les alternatives s’étant multipliées ces dernières années : au traditionnel Datawarehouse s’est ajouté le Datalake puis plus récemment le Lakehouse. Il est également question de Data Virtualisation.
De plus, l’émergence d’architectures et de pratiques transverses à l’Entreprise comme DataFabric et Datamesh tendent à rapprocher les usages analytiques et transactionnels, comme dans le cas d’usage vision 360°.
Enfin nos clients sont tentés de migrer ou d’hybrider les silos de données traditionnellement on-premise dans le Cloud pour plus d’agilité (élasticité) ou des raisons économiques (facturation à l’usage). Cependant cela pose souvent de vrais problèmes de sécurité et de confidentialité des données…
Pas facile de faire les bons choix dans ces conditions! Chacun a ses avantages et ses inconvénients, tout dépendra du profil de vos utilisateurs, des cas d’usage envisagés, de votre existant et de votre stratégie.
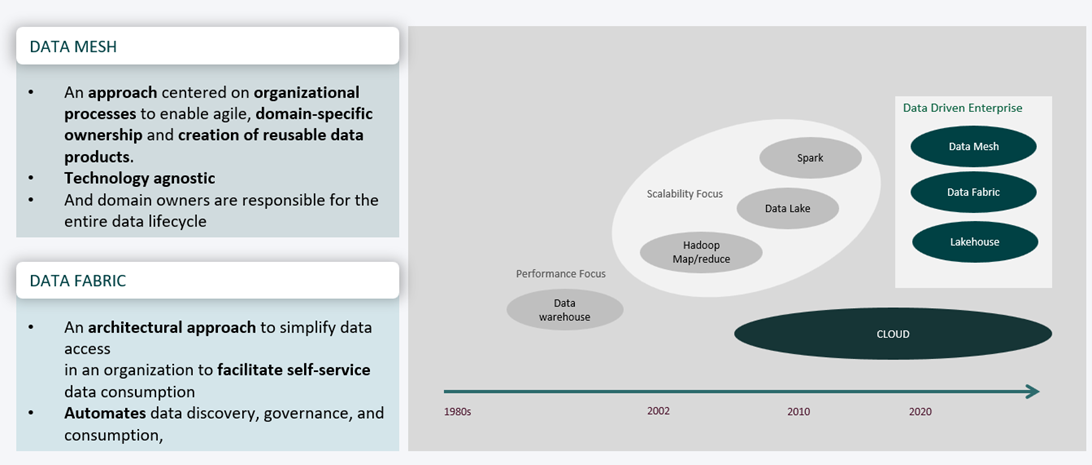
Historique des architectures de données (Crédit : Xiaohua Le)
Les patterns d’architecture de données
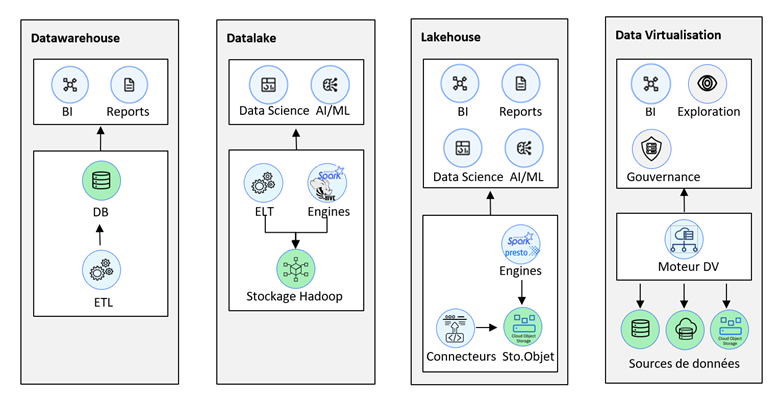
Comparaison des patterns d’architecture de données
Le Datawarehouse
L’entrepôt de données ou Datawarehouse est utilisé et maitrisé depuis longtemps par les Entreprises pour les usages de BI et de Reporting des utilisateurs métier. Concrètement il s’agit d’une solution d’informatique décisionnelle dédiée au traitement analytique de données de référence qui repose sur des tables SQL. En pratique il sera complété par une « appliance » matérielle dédiée afin de gagner en performances et en scalabilité ainsi que de solutions logicielles d’ingestion ETL, d’observabilité pour fiabiliser les traitements et de gouvernance de la donnée pour améliorer l’efficacité opérationnelle et la conformité.
Ses points forts :
- Il contient des données historisées et cohérentes sur l’entreprise
- Il répond au besoin de scénarios répétables et fiabilisés comme ceux du domaine risque-finance
- Il a une architecture optimisée pour les performances et des temps d’accès rapides
- Il offre une interface SQL connue et maitrisée par les utilisateurs
- Il permet d’exécuter des requêtes SQL complexes
- Il est disponible à la fois OnPremise et sur le Cloud
Ses points faibles :
- Limité aux cas d’usage BI/reporting et à l’exploration de données
- Fraicheur des données: il est généralement alimenté par ETL et non adapté au temps réel
- Manque de flexibilité et d’évolutivité : il ne traite que des données structurées et normées, les données doivent impérativement être transformées dans le schéma cible avant ingestion
- Coûts d’infrastructure : l’infrastructure matérielle doit être adaptée pour des performances maximales
- Coûts de développement et de maintenance élevés: toute modification des schémas de données nécessite l’intervention des Data Engineers pour effectuer des évolutions des jobs d’alimentation ETL, ce qui génère des délais projet et frustre souvent les métiers
- Coûts de run : le non-respect des formats et des contraintes d’intégrité peut entrainer des erreurs dans l’alimentation
Le Data Lake
Historiquement lié à la mouvance du BigData, le lac de données ou Datalake permet d’effectuer facilement tous types de traitements analytiques et data science en mode self-service. Il est principalement utilisé par les Data Scientists même si ses usages tendent à s’élargir ces dernières années. Son architecture Hadoop repose sur des moteurs pour les traitements analytiques et une zone de stockage qui utilise une structure de fichiers distribuée adaptée aux gros volumes.
Ses avantages :
- Il supporte la plupart des types, formats et variétés de données existants
- Support de nombreux frameworks et moteurs analytiques
- Il est très flexible car il n’impose pas de schéma à l’ingestion.
- Il est adapté aux grands volumes de données structurées et non structurées
- Il est adapté à de nombreux usages : exploration de données, data science, processing…
- Il est construit pour la résilience des données, il est scalable et adapté aux traitements parallèles
- Il est généralement déployé sur une infrastructure matérielle peu couteuse
- Il peut supporter les scénarios batch mais aussi le streaming via des architectures de type événementielles (EDA – Event Driven Architecture)
- Les données sont accessibles simplement en SQL (Hive, Impala…)
- Contrairement au Datawarehouse les données peuvent être directement déposées brutes dans une zone ad-hoc ou « landing zone », pattern aussi nommé « schema on read »
- Les transformations peuvent être faites à posteriori via des traitements ETL ou « pipelines », par exemple pour être ingérées dans un Datawarehouse, pattern « schema on write ».
Ses inconvénients :
- Pas toujours adapté : le mauvais positionnement du Datalake comme remplacement du Datawarehouse pour les raisons expliquées plus haut a conduit à la majorité des échecs d’utilisation
- Pas de catalogue de méta-données, gouvernance et traçabilité compliquées
- Couts de run : les volumes à stocker sont conséquents, de plus les données sont souvent répliquées plusieurs fois pour différents usages
- Fraicheur des données et fréquence de mise à jour : vu les volumes le process d’ingestion de type batch peut être couteux même s’il est possible de faire de l’ingestion au fil de l’eau
- Pas toujours optimisé pour les performances, moins rapide en lecture qu’un Datawarehouse
- Difficulté de gérer la sécurité et l’isolation des données en fonction des profils (RBAC)
- Gestion de la dette technique : de nombreux frameworks à gérer
- Fiabilité des traitements : nécessite des contrôles de cohérence et d’intégrité des données accrus
- Les anciennes versions ne gèrent pas l’acidité transactionnelle ni les updates
Le Lakehouse
Le lac de données ou Lakehouse est apparu plus récemment, il se veut l’évolution du Datalake et promet de combiner ses avantages avec ceux du Datawarehouse tout en offrant un TCO plus faible. Il propose une interface SQL permettant d’élargir ses usages à des profils non techniques via une nouvelle architecture hybride pour les données structurées et semi-structurées basée sur une structure de tables.
Ses avantages :
- Simplicité : comme le Datawarehouse et la Data Virtualisation il offre une interface utilisateur SQL connue et simple à maitriser
- Scalabilité : comme le Datalake il est distribué et scalable par construction
- Flexibilité : il permet d’importer la plupart des formats de données structurés et semi-structurés y compris les plus récents.
- Performances : Les moteurs de requêtage SQL distribués comme Presto utilisent des technologies de cache et les dernières évolutions peuvent effectuer les traitements en mémoire avec Spark
- Couts d’infrastructure : contrairement au Datalake il permet de séparer les noeuds compute et stockage et il utilise un stockage objet à bas cout
- Ouverture : comme la Data Virtualisation il offre de nombreux connecteurs vers les bases de données relationnelles et noSQL, ce qui permet aussi de requêter les données sans les copier
- Règlementaire: les dernières versions supportent les transactions ACID et le versioning (time travel)
Ses inconvénients :
- Récent : peu de recul sur des projets en production
- Stockage et manipulation limités au format table, pas de données non structurées
- Cas d’usage plus limités que le Datalake du fait des restrictions du format table
- Moins efficace en performances qu’un Datawarehouse
La Data Virtualisation
Contrairement aux solutions précédentes la virtualisation de données est une solution logique et non physique qui consiste en une couche d’abstraction pour unifier les silos de données. La virtualisation pourra servir à créer une plateforme de données ou DataHub afin d’en fournir une vue unique en mode self-service à destination des utilisateurs finaux tout en conservant les données de référence là où elles se trouvent.
Ses avantages :
- Cas d’usage fréquents : adapté à l’exploration de données et la BI
- Simplicité d’usage : similaire à une vue composite d’un point de vue utilisateur, permet d’effectuer des requêtes SQL composites à des données multi-sources de manière transparente
- Fraicheur : permet l’accès aux données opérationnelles en temps réel, pas d’ETL requis
- Flexibilité : nombreux connecteurs (drivers) vers les datasources relationnelles, noSQL, Hadoop…
- Impact minimal sur le SI : les données restent ou elles sont et sont lues par le moteur de requêtage multi-sources.
- Cout de mise œuvre faible
Ses inconvénients :
- Inadapté aux gros volumes
- Limité aux interfaces SQL
- Performances limitées par le réseau et le stockage malgré des mécanismes de cache
- Lecture seule dans la plupart des cas
- Plans d’exécutions multi-sources nécessitant parfois l’installation d’agents et pas forcément simples à concevoir
- Nécessite de l’administration pour la conception et la maintenance des vues
Conclusion
Le tableau plus bas résume les caractéristiques de chacune de ces architectures :

En pratique quelle architecture retenir pour quel usage ? Il n’y a pas de réponse toute faite mais voici quelques exemples :
Un premier cas concerne les clients qui ont un Datawarehouse historique dont ils souhaitent diminuer les coûts. Ceux-ci pourront envisager le passage à un Lakehouse afin de gagner en TCO et en agilité tout en conservant les usages traditionnels de la BI.
Un deuxième cas concerne ceux qui veulent moderniser leur Datawarehouse. Là encore ils pourront tirer parti d’un Lakehouse qui leur permettra d’accueillir des données semi-structurées et de développer de nouveaux aux cas d’usage BigData analytiques en utilisant des technologies modernes.
Un troisième cas concerne les clients qui veulent réduire le coût de run de leur Datalake. Ils auront avantage à le décharger et éventuellement à terme le remplacer par un Lakehouse utilisant du stockage Objet à moindre coût. Ils pourront par exemple déplacer le traitement des données raffinées dans le Lakehouse et limiter l’usage du Datalake aux données brutes et non structurées.
Le dernier cas que je citerai concerne les clients qui souhaitent mettre en place une architecture de type DataFabric sur laquelle va s’appuyer une organisation DataMesh afin de donner accès aux différentes bases de données de l’Entreprise à leurs utilisateurs finaux. Une solution de Data Virtualisation leur permettra d’abstraire la complexité des sources de données et d’en simplifier l’accès en mode self-service pour des besoins d’exploration ou de BI, et ceci sans nécessiter de refonte de l’existant.
Enfin il ne faut pas oublier que pour être exploitables ces architectures doivent également s’inscrire dans un projet d’Entreprise où l’ensemble du cycle de vie de la donnée (collecte, gestion et utilisation) doit être partagé à travers les différents rôles et responsabilités avec une gouvernance et des process communs. Cette stratégie de « data management » doit être portée au plus haut niveau de l’entreprise et être partagée par l’ensemble des acteurs métiers et IT.
N’hésitez pas à prendre contact avec nos équipes consulting et avant-vente pour bénéficier de nos conseils sur ces architectures et de nos retours d’expérience dans des contextes similaires.

Principal Account Technical Leader, Financial Services, IBM France

La CSRD, un changement de paradigme pour les entreprises européennes
La Corporate Sustainability Reporting Directive (CSRD) inaugure un nouveau paradigme et marque le début d’une nouvelle ère en matière de « rapportage » de durabilité et de soutenabilité. En instaurant un cadre définissant les principes de l’analyse de double matérialité, l’Union Européenne (UE) offre aux entreprises une nouvelle opportunité d’opérer leur transformation stratégique durable, tout […]

L’intelligence artificielle et l’analytique avancée dans le système de santé français (Partie 2)
Face aux défis auxquels sont confrontés les systèmes de soins de santé, l’analytique avancée (AA) et l’intelligence artificielle (IA) sont des technologies à haut potentiel d’impact. Ces technologies peuvent équiper les systèmes de santé d’outils avancés pour renforcer les soins des patients et améliorer l’efficacité opérationnelle. La deuxième partie de cet article reprend le fil […]

L’importance d’une culture DevOps au sein d’une entreprise
DevOps ne concerne pas uniquement les phases d’intégration et de déploiement d’application et l’automatisation de celles-ci mais tout le cycle de vie d’une application. DevOps ? Kezako ? Pourquoi ? Historiquement, les équipes de développement et opérations étaient organisées en silo, chacune travaillant uniquement sur leur scope avec une communication limitée. Avec l’arrivée de […]