SPSS Statistics
SPSS Statistics Small Tips #02決定木による顧客のセグメンテーション〜SPSS Statistics Decision Trees〜
2021年09月10日
カテゴリー IBM Data and AI | SPSS Statistics | アナリティクス | データサイエンス
記事をシェアする:
決定木分析とは
決定木分析はディシジョンツリーとも呼ばれ、対象となる従属(目的)変数に対して影響のある独立(説明)変数でデータを分類する手法です。これまで医療や教育における研究、マーケティングなど幅広く利用されてきましたが、昨今のA I・機械学習ブームでさらに注目されるようになりました。また本来は要因の構造を把握するのに便利だとされてきましたが、さまざまな応用モデルが登場し、より高い予測精度を求めるデータサイエンティストが好んで使うことでも知られています。
今回は、SPSS StatisticsのオプションDecision Treesで使える決定木分析をご紹介します。前回のSPSS Statistics Small Tips #01顧客データ分析を始める方必見!!〜SPSS Statistics Direct Marketing〜の「オファーに回答した連絡先のプロファイルを作成」の機能でも利用されている分析手法です。
ところで、みなさんは「介護認定制度」をご存知でしょうか。平成12年の4月から始まった制度で、申請者の心身の状況が、どの状態区分に該当するかを分類して、支援や介護の認定判断を行います。この介護認定制度を現在の仕組みに整えるまでには、具体的な症例(Evidence)を用いた研究が不可欠でした。どのような症例グループには、どのような支援や介護が必要とされるのか、グループの特徴をデータに基づいて解明することにより、事実を反映した一般化されたルールの制定が可能になりました。
実は、そこで用いられたのが、SPSS StatisticsのオプションDecision Treesでした。Decision Treesによって、さまざまなデータの関係性を重要な要素に絞り込んで状況を説明することができるようになったのです。
決定木分析を使ったアプローチを皆様のデータ活用のシナリオに追加することで、上記のように新しい仕組みを作成したり、またこれまでの仕組みを見直したり、改善したりできるはずです。
SPSS StatisticsのDecision Treesでは、CHAID(チェイド)、Exhaustive CHAID(イグゾースティブ チ
ェイド)、CRT(カート)、QUEST(クエスト) の4種類の決定木分析の手法が用意されています。
では、実際にSPSS Statisticsで決定木分析を実行してみましょう。
SPSS Statistics Decision Treesを使ってみよう
以下の例では、製品に同梱されているサンプルファイルtree_credit.savを使用します。
このデータには、以下の変数が保存されています。
| 変数名 | 説明 |
| 信用度 | 金融機関における顧客の信用度(悪い・良い) |
| 年齢 | 顧客年齢 |
| 所得 | 所得カテゴリ(低・中・高) |
| クレジットカード | クレジット機能付きカード枚数(5枚未満・5枚以上) |
| 教育 | 学歴レベル(高校・大学) |
| 車ローン | 車ローンの有無(1以下・2以上) |

ここでは、信用度に注目しています。顧客に融資を行った結果、適切に返済が完了した人とそうでない人がいます。融資を実施する側は、返済金の支払いが困難な状況に陥ったり、支払いが滞ったりする可能性が高い人を見極めて、リスクを回避したオファーをしたいと考えています。信用度を説明するには、どのようなアプローチが考えられるでしょうか?
従属変数の分布を確認
信用度の度数分布表を作成してみます。
「分析」メニューの「記述統計」>「度数分布表」を選択します。
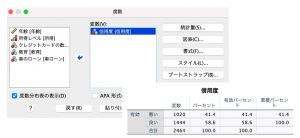
2464ケースのデータがあることが分かりました。そのうち信用度が「悪い」と記録されているのは41.4%です。
従属変数と独立変数の関係性を確認
信用度を別の変数と組み合わせて分布を確認してみましょう。
「分析」メニューの「記述統計」>「クロス集計」を選択します。


信用度と関係がありそうな独立変数を4つ選び、クロス集計表を作成しました。ひとつひとつの結果をみて、信用度とその他の変数の関係性を理解していくのはかなり手間がかかりそうです。2次元(行と列)のクロス集計だけでなく、3次元(行と列と層)クロス集計表や、さらに4次元、5次元など多次元クロス集計を作成するとなると、その解釈はかなり複雑になっていきます。
この多次元クロス集計を簡単に作成でき、その解釈も簡単にできるとしたら、どんな人が信用度が「良い」のか、「悪い」のか、そのセグメントの特徴を明らかにできるはずです。
決定木分析を実行
「分析」メニューの「分類」>「ツリー」を選択します。

決定木分析の名前は、アウトプットの図のスタイルが逆さまになった木のイメージをしていることに由来します。


ルートノードとなる「ノード0」は、データ全体の信用度の分布を示しています。「悪い」信用度の人は、全体の1020人で、41.4%を占めています。「ノード0」は、「所得レベル」変数で分割され、「ノード1」、「ノード2」、「ノード3」に分岐しています。左側の「ノード1」は、所得レベルが「低」のセグメントです。「悪い」信用度の人は、454人で82.1%を占めています。つまり、全体の2倍の「悪い」信用度の人が、「ノード1」に含まれていることになります。
さらに「ノード4」を注目してみましょう。この「ノード4」は、「所得レベル」が「低」、かつ「クレジットカードを5枚以上所有」のセグメントです。このセグメントでは、「悪い」信用度の比率がさらに上がり、90.1%となっています。この構造を追っていくとどのような特徴の人が、信用度が「良い」のか、または「悪い」のか、複数の変数の組合せの関係を簡潔に説明することができます。
説明ができれば、新しい顧客の特徴から融資のオファーが妥当かどうかを予測することもできるようになります。

さらに、決定木分析では、従属変数(この例では「信用度」)に対して影響度の高い変数のみを使用する特徴があります。そのため、ある現象に対する要因を追求する分析手法として非常に効果的なアプローチといえます。例えば、『顧客の解約』や『従業員の離職』、『設備の故障』、『患者の罹患』に対する原因分析に利用されています。
まとめ
いかがでしたか。決定木による顧客のセグメンテーションでは、要因を選別しながらルールを見つけ出し、ターゲットの予測が行えます。SPSS Statistics Decision Treesがあれば、データ分析を始める準備はOKです。
もし、SPSS Statistics Decision Treesの操作手順に不安があったり、機能についてしっかり習得したいといった場合には、E-Learningがお薦めです。https://www.stats-guild.com/spss-e-learning/courselist/es2702d
SPSS Statisticsの決定木分析を基礎から応用までカバーしたプログラムです。
さっそく使って始めてみませんか。
SPSS Statistics 無料評価版 https://www.ibm.com/jp-ja/products/spss-statistics
お問い合わせは SPSS営業部まで jpsales@jp.ibm.com
→SPSS Statistics Small Tips バックナンバーはこちら

牧野 泰江
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス

イノベーションを起こす方法をイノベーションしなければならない(From IBVレポート「エコシステムとオープン・イノベーション」より)
Client Engineering, IBM Data and AI, IBM Partner Ecosystem
不確実性が増し、変化が絶え間なく続く時代には「イノベーション疲れ」に陥るリスクがある。誰もがイノベーションを起こしていると主張するならば、結局、誰もイノベーション(革新的なこと)を起こしてなどいないことになるだろう 当記 ...続きを読む

データ分析者達の教訓 #16- ステークホルダーの高い期待を使命感と創意工夫で乗り越えろ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

キー・パートナーに訊く | 毛利 茂弘(株式会社システムリサーチ)
IBM Data and AI, IBM Partner Ecosystem
株式会社システムリサーチでPM/Tech Advisorとして活躍する毛利茂弘氏に、日本IBMで中部地区パートナーを担当する大石正武が訊きます。 (写真左)毛利 茂弘(もうり しげひろ) | 株式会社システムリサーチ 製 ...続きを読む