Data Science and AI
基盤モデルの革新を加速するクラウドネイティブ・オープンソース・スタック
2023年06月21日
カテゴリー Data Science and AI | IBM Data and AI | IBM Watson Blog
記事をシェアする:

基盤モデル、そして生成AIは、私たちの想像力を魅了し、私たちの生活や仕事のやり方を改善する新しい方法の発見を可能にしました。自然言語を用いたシームレスなテクノロジーとの対話から、コードやその他のデータの自動生成、そして科学のさまざまな領域にわたる使用例まで、基盤モデルの応用は日に日に拡大しています。IBMでは、この技術を製品ポートフォリオ全体に浸透させることと、お客様が迅速かつ効率的に、そして安全に基盤モデルを自社の製品に採用できるようにすることを目標にしています。
この取り組みの一環として、私たちは、AIスーパーコンピューターであるVelaをIBM Cloudで構築した理由についての見解を共有しました。Velaの構築は、最先端のAIモデルを学習、ファインチューニング、展開する方法を加速するために、IBMのテクノロジー・スタック全体を再構築する大きな取り組みの一部でした。このプロセスを通じて、私たちは基盤モデル時代に最適化された、モダンで柔軟なAIソフトウェア・スタックを構築しました。
このブログでは、IBMが新発表したwatsonxプラットフォームの基盤となる、高性能でクラウドネイティブなAI学習スタックについて説明します。この学習スタックは、Red Hat OpenShift Container Platform上で稼働します。
学習スタックを補完するのが、基盤モデルのチューニング・推論サービスを、コストとパフォーマンスの点で最適化して提供するためのテクノロジー・スタックです。以下に説明する技術の多くは、PyTorch、Ray、Kserve、そしてOpen Data Hub(ODH)といったオープンソースのコミュニティーに既に貢献しています。ODHはKubernetes上でデータ集約型アプリケーションを構築、展開、管理するためのオープンソースプラットフォームです。ODHで成熟した技術は、Red Hat OpenShift AIに組み込まれ、さらにそれを利用している、IBMの次世代AIプラットフォームであるwatsonx.aiにも活用されています。このアプローチにより、IBMとRed Hatは、お客様が選択した任意の環境(オンプレミス、IBM Cloud、または他のパブリッククラウド)で実行できる最先端のオープンソース基盤モデルスタックを提供することができます。
基盤モデル学習への私たちのアプローチ
AI学習スタックの再構築に着手したとき、私たちは2つの目標を掲げていました。1つ目は、ハードウェアの最大活用とハイパフォーマンス・インフラの効率的な利用という、従来からあるHPCシステムの利点を活かすことです。2つ目は、ハイブリッドクラウド開発で得られる柔軟性と生産性のメリット、つまり開発の俊敏性、コードの再利用、インフラとソフトウェアを管理しスケールすることの簡略化を実現することです。2つ目の目標を達成するために、私たちはKubernetesでソリューションを構築し、コンテナを利用してコードの再利用とソフトウェアの拡張を可能にすることにしました。しかし、これを実現するには、Kubernetesをハイパフォーマンスのワークロードに適したプラットフォームにする必要があります。
また、データの前処理、分散学習、モデルの検証など、AI学習作業の各ステップに対応するソリューションが必要でした。作業全体をエンドツーエンドで扱うために提携すべき主要なオープンソース・コミュニティーと、ユーザーがジョブを立ち上げ、実行し、スケールするために克服すべきユーザー・エクスペリエンスの主要な障害を特定しました。
以下の図1の左側は、2022年後半からIBM CloudのVela上で稼働し、IBM Research全体で使用されている、私たちの学習ソフトウェア・スタックの全体像を示しています。図1の右側は、ブログで後述する基盤モデルのチューニング・推論サービス提供のためのスタックを描いています。

図1:基盤モデルの学習と検証(左)、チューニング・推論サービス(右)のためのクラウドネイティブなソフトウェアスタック
Kubernetesネイティブの高度なリソース活用と管理
私たちがこの仕事を始めたとき、Kubernetesのエコシステムには、大規模でハイパフォーマンスなAIワークロードを処理するのに不足した点がまだたくさんありました。初期の焦点の1つは、たとえばネットワーク・リソースのようなインフラの能力を、追加のオーバーヘッドを発生させることなくワークロード側に公開する方法でした。このために私たちは、下層にあるネットワーク・インターフェイスを構成するマルチNIC CNIオペレーターを作成し、カプセル化を排除することでネットワークのレイテンシーを半分に削減し、帯域幅を既製のコンテナ・ネットワーク・ソリューションと比較して7倍に増加させました。しかもこれらの改善は、エンドユーザーが意識せずに利用可能になります。
補う必要があった2つ目の不足点は、クラウドネイティブなジョブスケジューラーを採用することです。多くのAI開発者がVela上でジョブを走らせたがっていたため、リソースを割り当て、ジョブに優先順位をつけてリソースの利用率を最大化するスケジューラーが必要でした。この問題を解決するために、IBMの研究者は、ジョブ待ち行列、ジョブの優先順位と割り込み、タイムアウト、システムのユーザー間のリソース共有の仲介を行うMulti Cluster App Dispatcher(MCAD)を作成しました。さらに、リソースの断片化を解消するためのワークロード・パッキングとギャング・スケジューリングを可能にし、これらはすべてOpenShiftの上で実行されました。さらに私たちは、クラウドホスティングされたOpenShiftクラスターを動的にスケールするためにMCADと連携するInstaScaleを開発しました。クラウドプロバイダーからの要求に応じてGPUを自動的に取得・解放することで、InstaScaleはインフラ管理やコストに関する心配からユーザーを解放します。
スケーラブルで効率的なデータの前処理、モデルの学習、検証
AIパイプラインのすべてのステップをシンプルかつ効率的に実行するために、私たちはPyTorchとRayという2つの主要なオープンソース・テクノロジーを活用し、それに貢献することに重点を置いています。Rayでは、データ・サイエンティスト向けのPython APIを使用して、スケーラブルなデータの前処理・後処理を可能にします。データの前処理では、文章表現のフィルターを使ったヘイトスピーチ、暴言、下品な表現などのフィルタリングなどを、後処理ではモデルのファインチューニングや検証などを行います。MCADとの連携でRayを実行することで、同時に実行されている多様なRayジョブ間でのリソースプールの効率的な共有が可能になります。
私たちはPyTorchと協力して、rate_limiterの導入によるFSDP(Fully Sharded Data Parallel)学習APIのサポートの高機能化など分散学習のサポートを進めています。IBM CloudにおけるVelaのようなイーサネットベースの環境で、100億以上のパラメータを持つモデルの分散学習ジョブを効率的にスケーリングできることを、私たちは最近実証しました。また、MCADをTorchXと統合することで、異なるAPIやフレームワークを使用するPyTorchベースのジョブを幅広く透過的にサポートすることができるようになりました。TorchXは、PyTorchアプリケーション用の汎用ジョブランチャーです。多様なジョブの取り扱いについて、下層で利用しているジョブ管理システムがそのようなメリットを受けるために、AIモデルを学習するクリエイターがコードを修正する必要はありません。
シンプルになったユーザーエクスペリエンス
一連の処理のうち学習部分は、以下のステップで行われます。すなわち、モデル探索(通常、スケールダウンした実験を数台のGPUで実行)、スケールアップした分散学習ジョブ(数百台のGPUを消費)、そして最後にモデルの検証です。これらのステップを構成することは、多くのAIクリエイターにとって複雑であり、設定や管理に時間が費やされます。私たちがこの課題を解決するため取り組んでいるプロジェクトCodeFlareは、学習、評価、そして学習状態をモニタリングするというクリエイターの作業をガイドし、シンプルにします。
コンソールとUIベースで提供されるCodeFlare CLIは、ジョブの設定、ストレージのセットアップ、ロギング、モニタリングとプロファイリングのためのエンドポイントを自動化しながら、リモートOpenShiftクラスタで実行する複雑な作業についてユーザーをガイドします。Jupyterベースの CodeFlare SDKは、バッチリソースのリクエスト、ジョブの投入、観測のための直感的なPythonインターフェイスをユーザーに提供します。これらの機能により私たちは実際に、IBMのAI研究者がクラウドネイティブ・スタックを使い始める負担を大幅に引き下げています。
Velaでのスタック運用
2022年末までに、IBMの基盤モデルの学習処理はすべて、IBM CloudのVela上でこのソフトウェア・スタックを使用して実行するように移行しました。現在、MCADは、シングルGPUのジョブから512台以上のGPUを活用するジョブまで、これらのAIジョブのキューを管理し、ジョブの優先順位付けと割当量の管理に対応しています。例えば、OpenShift Installer Provisioned Infrastructure (IPI)を強化して、高性能インフラでのOpenShiftの展開と管理を容易にすることができます。
基盤モデルのチューニングと推論サービスに対する私たちのアプローチ
最先端の基盤モデルの学習と検証は、AIバリューチェーンの重要な初期段階ですが、チューニングや推論の段階に至ってモデルが実運用されるときにAIユーザーにとっての価値が最終的に生まれます。推論とモデルチューニングのための当社のソフトウェア・スタックは、それを走らせるハードウェア上でモデルを効率的に実行すること、受け取ったリクエストを最適な方法でバッチ処理すること、アプリケーションへのAIの統合を簡素化すること、モデル適応のための最先端の技術を提供することに重点を置いています。図1の右側は、基盤モデルのチューニング・推論サービスのスタックを表したもので、以下で詳しく説明します。
推論のパフォーマンス
同じハードウェア・プラットフォーム上でも基盤モデルの実行を最適化するソフトウェア・ライブラリーを利用すれば、出力と遅延時間を10~100倍向上させることができます。当社の推論サービスのスタックには、一般的なモデル・アーキテクチャーの推論の最適化に使える定番ツール(ONNXやHugging Face Optimumなど)が含まれているだけでなく、新しい推論サーバーや最適化ツールが登場した際に対応できるよう拡張可能です。AIやオープンソース・コミュニティーにおける技術革新のスピードが速いことを考慮すると、拡張性は我々のスタックの重要な設計ポイントです。さらに、実際のAIサービスでは、複数のユーザーから大量の推論要求があり、それらが異なるモデルのサービスを同時に要求することがあります。私たちのサービススタックは、Hugging Face、Kserve、Model Meshの各コミュニティーを参考にしながら、受信したリクエストを動的にバッチ処理し、モデル間の多重化を効率的に行うことができます。
アプリケーションの統合を簡素化
AIモデルを実行するために現在利用できる推論サーバーを使うには、AIについてかなりの専門知識がユーザーに要求されます。モデルへの入力も出力もテンソルですが、この形式はタスクを達成するのにただモデルを使いたいと思うアプリケーション開発者にとって、とっつきやすいものではありません。このプロセスをより開発者フレンドリーにするために、モデルの出力をもっと利用しやすいものに変換する必要があります。そこで私たちは、Caikitと呼ばれる抽象化レイヤーを作成しましたが、これはアプリケーション開発者に直感的なAPIとデータモデルを提供し、モデルとアプリケーションが独立して進化できるようにする、安定したインターフェイスです。この抽象化は、IBMのWatsonモデル・サービス・インフラで使用されており、近々オープンソースとして提供される予定です。
基盤モデルのチューニング
基盤モデルの重要な価値の1つは、事前に訓練されたベースモデルを活用し、特定のデータを用いて「ファインチューニング」(「微調整」または「適応」とも呼びます)することで、下流のタスクに対する性能を向上させることができることです。私たちの目標は、計算効率の高いモデル適応の最新技術をパッケージ化し、その仕組みについてほとんど知らない人にも簡単に使えるようにすることです。私たちの拡張可能なスタックは現在、マルチタスク・プロンプト・チューニング(MPT: Multi-task Prompt Tuning)とファインチューニングをサポートしており、PEFT(Parameter Efficient Fine Tuning)というオープンソース・プロジェクトで統合されています。今後数ヶ月の間に、私たちはプロンプトチューニングのアルゴリズムと実装の多くをオープンソース化する予定です。
Red Hatとの協働
IBM ResearchはRed Hatと協力し、開発した機能を主要なオープンソース・コミュニティーやOpen Data Hub(ODH)に直接貢献することで、他の人にも利用可能にしています。ODHは、OpenShiftの強みを活かしてAI開発のライフサイクル全体を促進するように設計された、オープンソース・ツールの包括的なコレクションです。Open Data Hubで紹介された技術の多くは、Red Hat OpenShift AIの一部として成熟し、watsonx.aiのミドルウェアベースとして機能します。図 2 は、このブログで説明したオープンソースへのさまざまな貢献が ODH に集まり、基盤モデルのユースケースをサポートする様子を示しています。
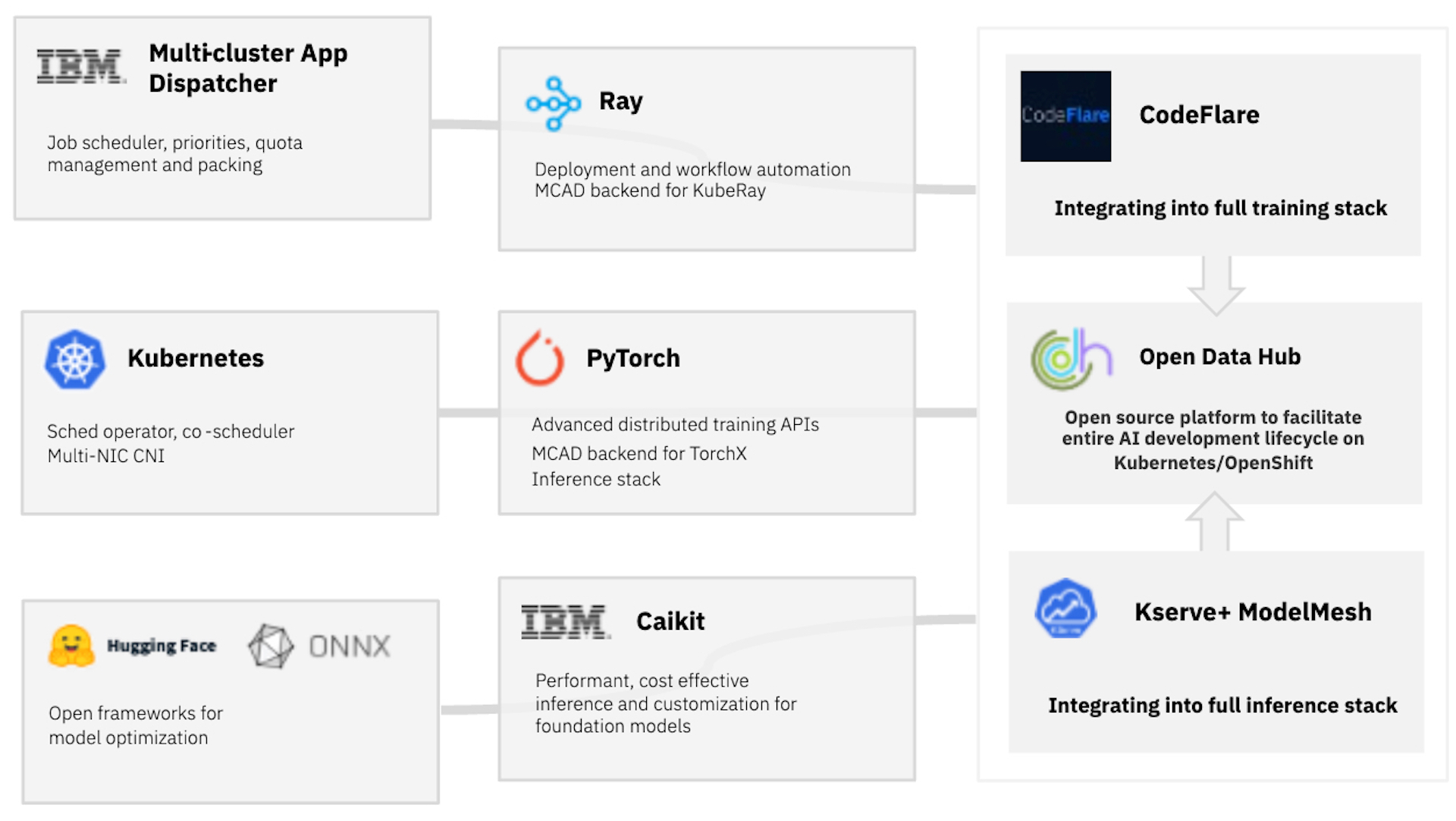
今後の展開
この基盤モデル時代に適したエンドツーエンドのソフトウェア・スタックを再構築したことは、AIコミュニティーにとって大きな価値をもたらしました。AI研究者は、ジョブを高いパフォーマンスで実行するために、あまり詳細なインフラの知識を必要としなくなりました。数台のGPUから数百台のGPUにジョブをスケールする方法や、高いワークロード性能を達成するためにジョブを正確に分散させる方法を理解する必要がなくなりました。コードはチーム間で再利用でき、実験も他の人が簡単に再現できます。また、開発者フレンドリーな方法と高い計算効率で基盤モデルの推論サービスを提供したり、チューニングしたりする方法を大幅に簡単化しました。
おそらく最も重要なことは、OpenShift上でこのスタックを構築することで、他の環境への移植性が得られ、当社のパートナーはオンプレミスやあらゆるパブリッククラウドでこれらの機能を活用できるということです。Red Hatとともに、Open Data Hubを通じてこれらのイノベーションをオープンソース・コミュニティーに提供し、Kubernetes上のAI処理の最先端をさらに先へと進め、これらのイノベーションをRed Hat OpenShift AIとwatsonx.aiで活用できるということに興奮しています。このアプローチにより、基盤モデルのエンドツーエンドのライフサイクルに対応した、ビジネスに利用可能なプラットフォームを実現します。私たちは、基礎的なオープンソース・コミュニティーに貢献することで多くの人たちや製品のお役に立つことを嬉しく思っていますし、その仕事を一緒にする仲間を常に求めています。
この記事は英語版IBM Blog「A cloud-native, open-source stack for accelerating foundation model innovation」(2023年5月9日公開)を翻訳し一部更新したものです。

ジェネレートするAI。クリエートする人類 。 | Think Lab Tokyo 宇宙の旅(THE TRIP)
IBM Data and AI, IBM Partner Ecosystem, IBM Sustainability Software
その日、船長ジェフ・ミルズと副船長COSMIC LAB(コズミック・ラブ)は、新宿・歌舞伎町にいた。「THE TRIP -Enter The Black Hole-」(以下、「THE TRIP」)と名付けられた13度目の ...続きを読む

イノベーションを起こす方法をイノベーションしなければならない(From IBVレポート「エコシステムとオープン・イノベーション」より)
Client Engineering, IBM Data and AI, IBM Partner Ecosystem
不確実性が増し、変化が絶え間なく続く時代には「イノベーション疲れ」に陥るリスクがある。誰もがイノベーションを起こしていると主張するならば、結局、誰もイノベーション(革新的なこと)を起こしてなどいないことになるだろう 当記 ...続きを読む

キー・パートナーに訊く | 毛利 茂弘(株式会社システムリサーチ)
IBM Data and AI, IBM Partner Ecosystem
株式会社システムリサーチでPM/Tech Advisorとして活躍する毛利茂弘氏に、日本IBMで中部地区パートナーを担当する大石正武が訊きます。 (写真左)毛利 茂弘(もうり しげひろ) | 株式会社システムリサーチ 製 ...続きを読む