
For the first time in history, computing has branched. Now, rather than progressing along a curve governed by an increasing number of transistors representing binary digits, we have access to a fundamentally different underlying computing architecture. This new architecture, the quantum bit, or qubit, has the potential to provide speedups for problems that have long proven intractable for classical supercomputers.
However, we’ve already established that quantum computers won’t solve every problem more efficiently than classical supercomputers. Instead, we expect quantum processing units (QPUs) to serve as accelerators for high-performance computers, assisting CPUs and GPUs for a subset of challenging problems as part of a heterogeneous compute model. We call this new supercomputing paradigm “quantum-centric supercomputing.”
With our 2023 utility experiment, we demonstrated the first evidence towards the usefulness of today’s quantum computers. That research showed that quantum error mitigation could enable noisy, utility-scale quantum computers with 100+ qubits to run calculations beyond the ability of brute-force classical simulations.
Since then, we’ve shown that pairing utility-scale quantum computers with HPC resources allows us to run workloads that we believe will soon surpass anything we could achieve with classical HPC compute architectures alone. As researchers employ new tools to experiment in this uncharted computational space, we’re seeing more and more examples of how quantum computers are already accelerating scientific discovery.
Today at the SC24 conference, we presented this vision for the future of quantum-centric supercomputing (QCSC)—and invited HPC users to join us for the ride. We have demonstrated quantum utility, and now developers are using these systems to do real scientific work. As quantum technology continues to mature, we are deploying quantum as a resource alongside classical HPC using resource management systems like Slurm so HPC users can participate in this new era of quantum-enabled scientific discovery.
Quantum accelerating classical
The future of computing is bigger than just quantum versus classical. It is about using both quantum and classical computing together to discover new algorithms.
Our thesis is that the future of computing will require mapping interesting problems to linear algebra problems—those represented by tensors and quantum circuits. And we know that quantum computers are better-equipped to run circuits than classical computers—that’s what we demonstrated by running the quantum utility experiment.
Therefore, at IBM Quantum our goal is to enable fast, accurate circuits which can be used as subroutines for these kinds of problems. We must push the performance of our hardware and software so they can run longer circuits more accurately—and so that quantum does not become a bottleneck for problems that require both quantum and classical resources concurrently.
Classical accelerating quantum
Though we desire accurate results for quantum circuits run on real quantum computers, today’s quantum computers are biased by noise that we must mitigate or correct. At present, the techniques that would allow for fault-tolerant quantum computing all require a scaled-up physical resource overhead that has yet to be demonstrated by any quantum computer.
Take the modeling of the iron sulfide molecule Fe4S4 as an example. We know that a classical computer is incapable of fully modeling this system. We also know that a present-day quantum computer would require millions of years to do so using established methods designed to make the most of noisy, shallow quantum circuits. In the future, a fault tolerant quantum computer with access to 4.53 million physical qubits could use those same methods to tackle this problem, but even that system would require an estimated 13 days’ runtime.
However, with quantum-centric supercomputing, we have access to a new suite of techniques that have the potential to produce better estimates than state-of-the-art classical compute techniques alone.
Sample-based quantum diagonalization (SQD), for example, is a chemistry simulation technique that uses the quantum computer to extract a noisy distribution of possible electronic configurations of a molecule in the form of bitstrings. Then, it runs an iterative correction entirely on a classical computer to cluster these bitstrings around the correct electron configuration. This technique, for a large enough noisy quantum computer with low enough error rates, has the potential to perform more efficiently than classical approximation methods.
IBM partners RIKEN and Cleveland Clinic Foundation have already published the results of experiments employing SQD, demonstrating promising evidence that quantum-centric supercomputing will open new applications previously considered impossible to execute without fault tolerance.
Integrating classical and quantum into a single user experience
Realizing quantum-centric supercomputing techniques like SQD will require more than connected QPUs and CPUs. We also must combine the expectations of quantum and classical developer personas into a single user experience. We do so by updating HPC workload management systems to accommodate quantum workloads.
Data centers and supercomputing facilities use workload management systems (WMS) to take care of resource management and job scheduling. Workload management systems know what types of resource are available at what time, and can efficiently execute tasks based on resource requirements. Popular resource management systems include Slurm, LSF, PBS, etc., and while they may look different, they incorporate the same core concepts: resource, node, task, queue.
- A resource is a unit of computational infrastructure, like CPU, GPU, memory, and QPU.
- A node is an abstraction to unite a set of computational resources into one entity.
- A task is a unit of computation or a program that has associated resource requirements.
- A queue is a task execution management mechanism.
HPC developer personas working with workload management systems might describe a computation using a graph of tasks, as below:
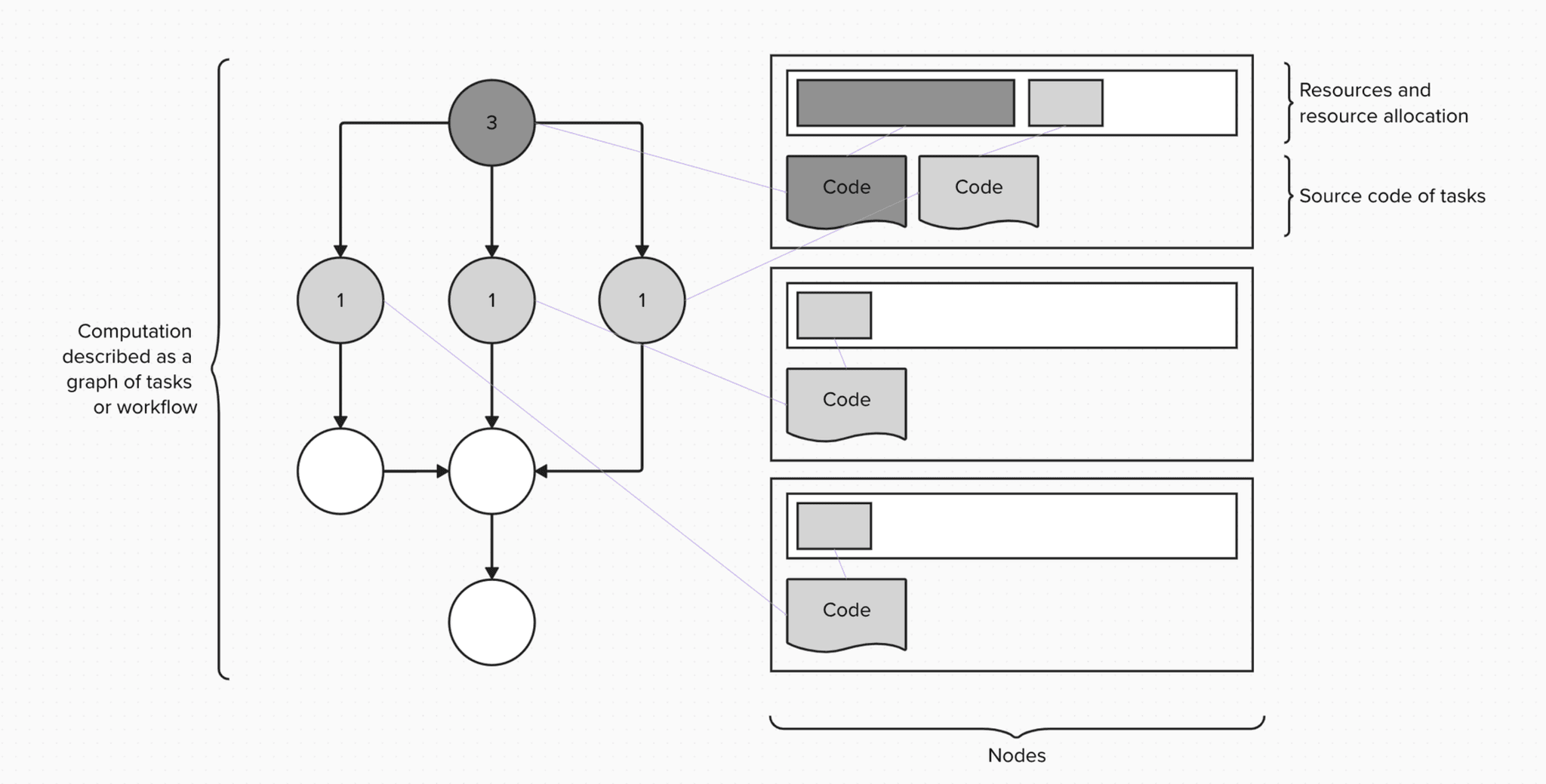
Now, programming quantum computers requires a different programming workflow, in this case based around the Qiskit software stack. Quantum computational scientists use Qiskit primitives to interface with quantum computers. Qiskit primitives are computational abstractions that extract outputs from quantum computations in the form of circuits. There are two Qiskit primitives: Sampler, which samples from a distribution of possible outcomes from a quantum circuit, and Estimator, which calculates an expectation value, or weighted average of the possible outcomes, from the circuit.
Combining these two computing paradigms means calling Qiskit primitives within tasks of a larger computational workflow to drive the quantum part of the computation. Then, the workload manager will use a new type of resource—a quantum processing unit, or QPU—for compute allocation.
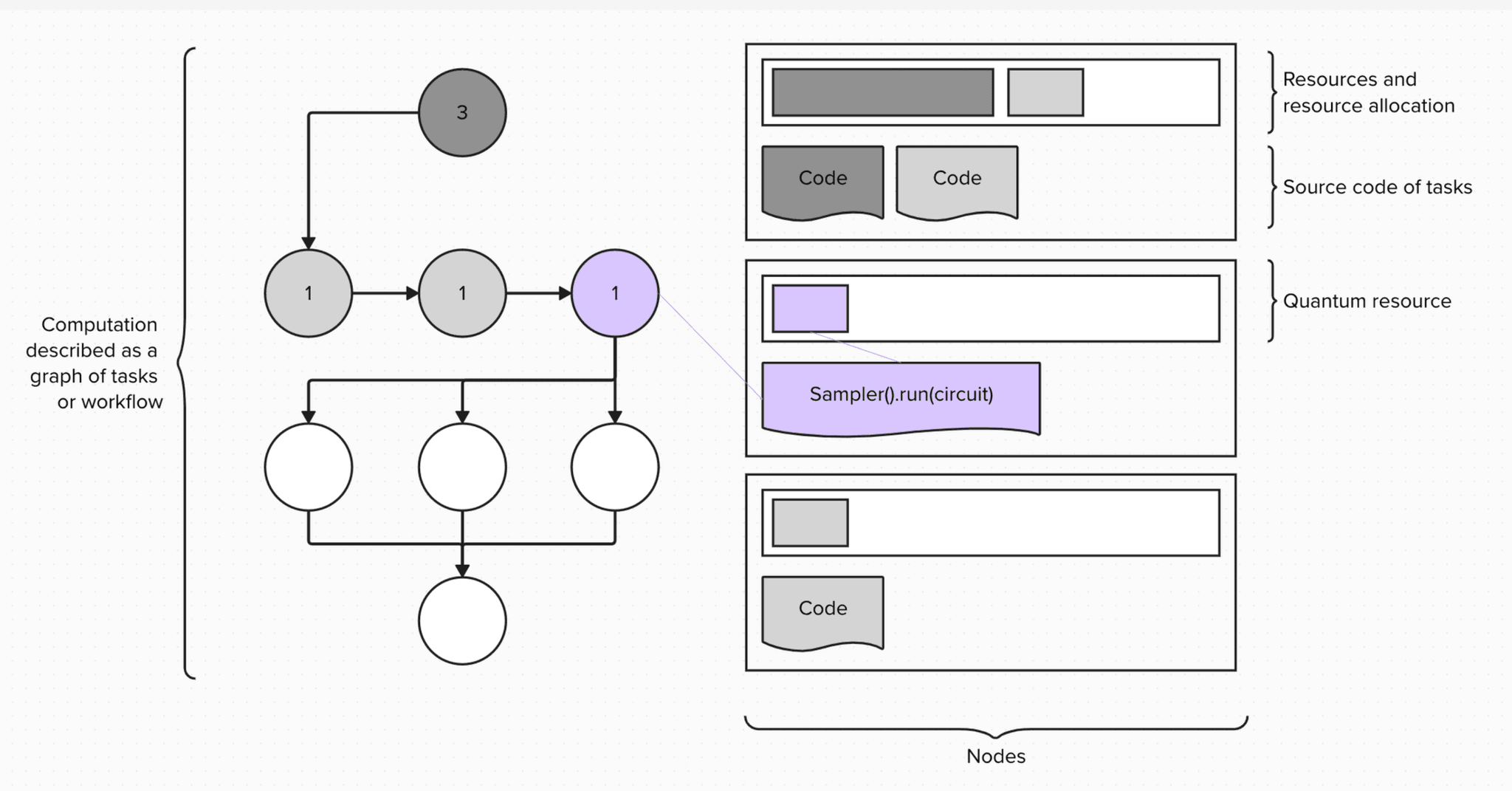
Designing a QCSC architecture
Working with a hybrid quantum-classical computational flow requires an appropriate architecture. Here, we will demonstrate example architectures and explore their benefits and drawbacks, and then show how to implement an SQD workflow on a QCSC architecture and run it with Slurm.
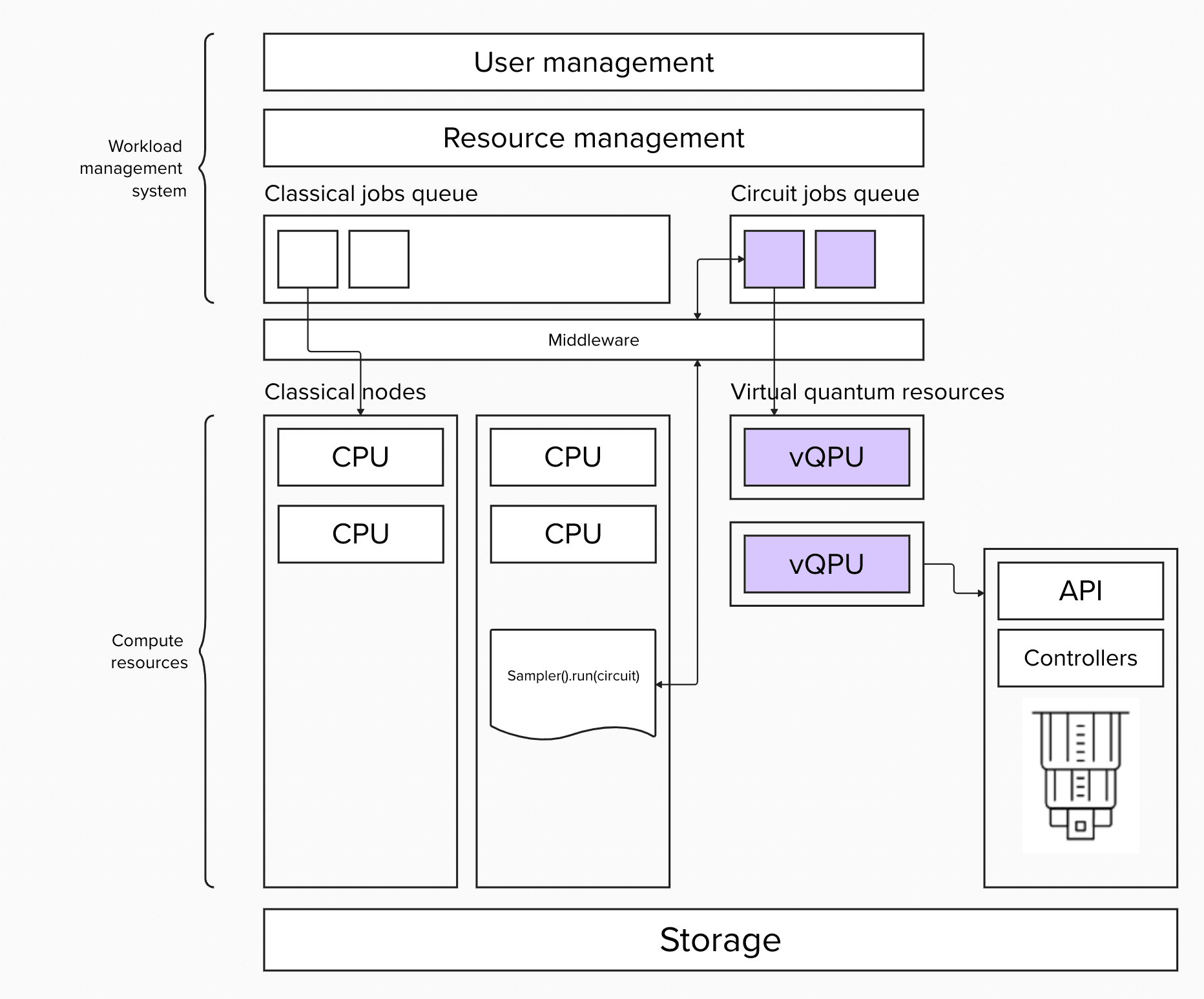
In the first architecture, we separate classical from quantum jobs. Quantum jobs are single executions of the Qiskit primitives, Sampler or Estimator. Separating queues by resource type lets us achieve higher utilization of the quantum device, since the queue is always saturated by strongly typed primitives jobs.
However, dueling queues might violate the order of submitted jobs. The start time of a classical job does not guarantee that you will have quantum allocation ready, as the QPUs might be occupied by other Qiskit primitives jobs started earlier. Therefore, QPU utilization has higher priority over classical resources, since quantum resources are rarer.
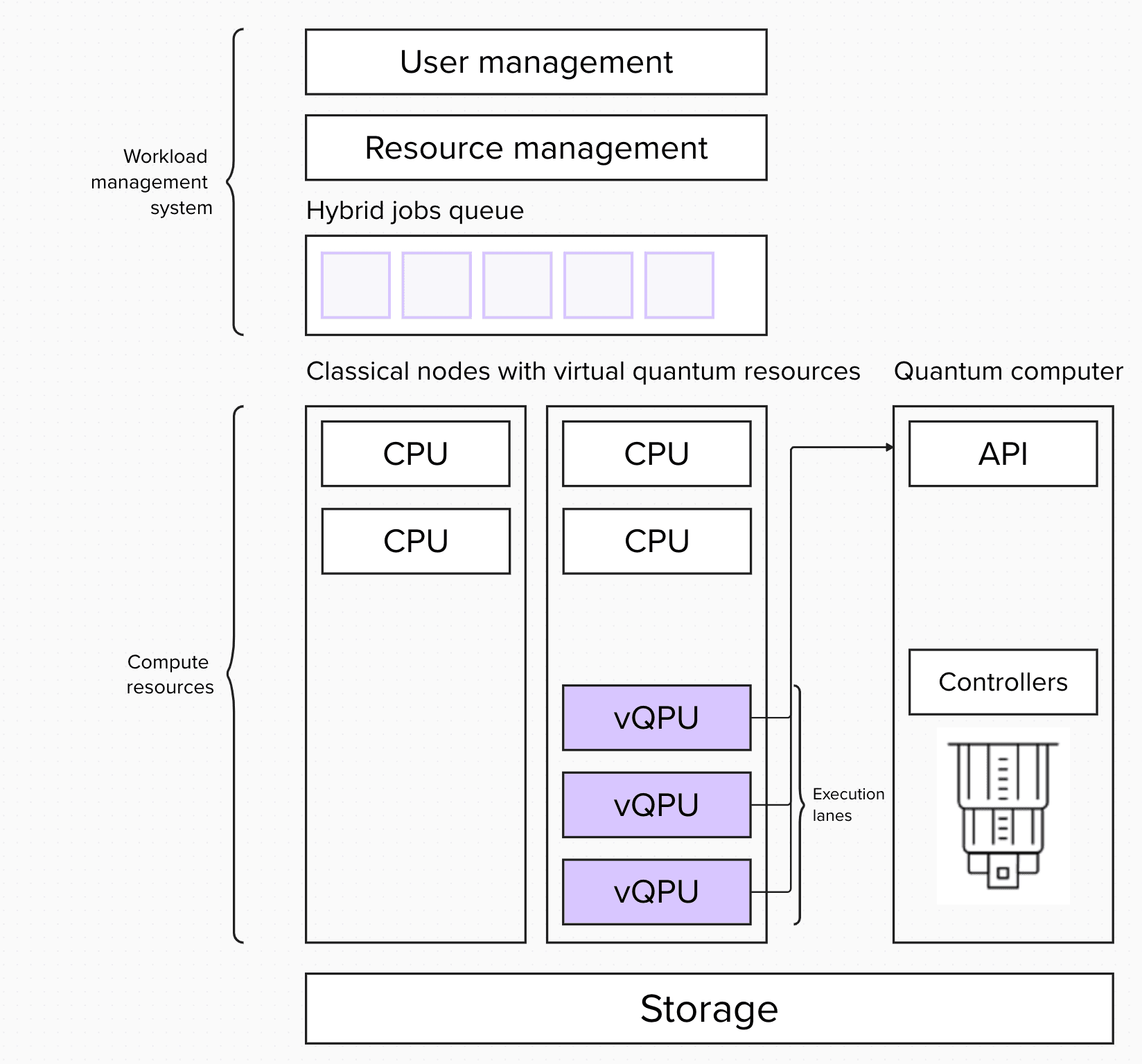
We could also imagine a hybrid model, where we treat quantum resources like any other resource, and all jobs in the integrated system as hybrid jobs. We differentiate and allocate based on the type of resource required by each job. Here we also define a vQPU resource. Nodes with this resource have access to a quantum computer API.
With this approach, once your quantum-classical job starts running, all resources required for this job are blocked for entire duration of the job. This is useful for algorithms that require a tight loop between classical and quantum resources. The downside of this approach is the blocking of quantum resource for the duration of the entire job, which lowers the utilization of the quantum system.
Finally, we could imagine a mixed model, allowing you to unlock benefits of both of the above mentioned strategies, while mitigating drawbacks through configuration. This type of architecture requires more complex configuration and development, but it offers the possibility of tighter integration between classical and quantum when needed by altering the job submission to hybrid and classical queues.
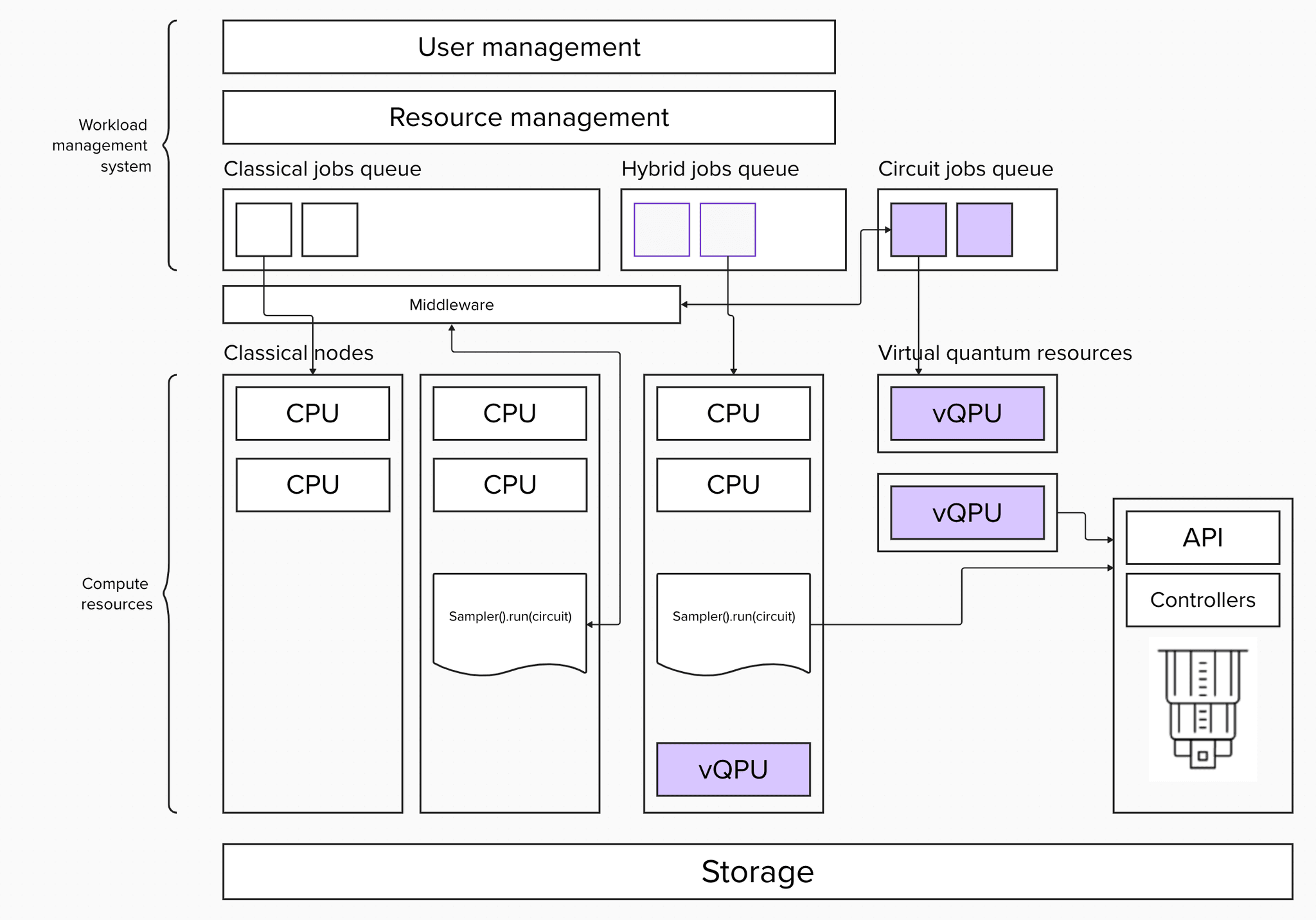
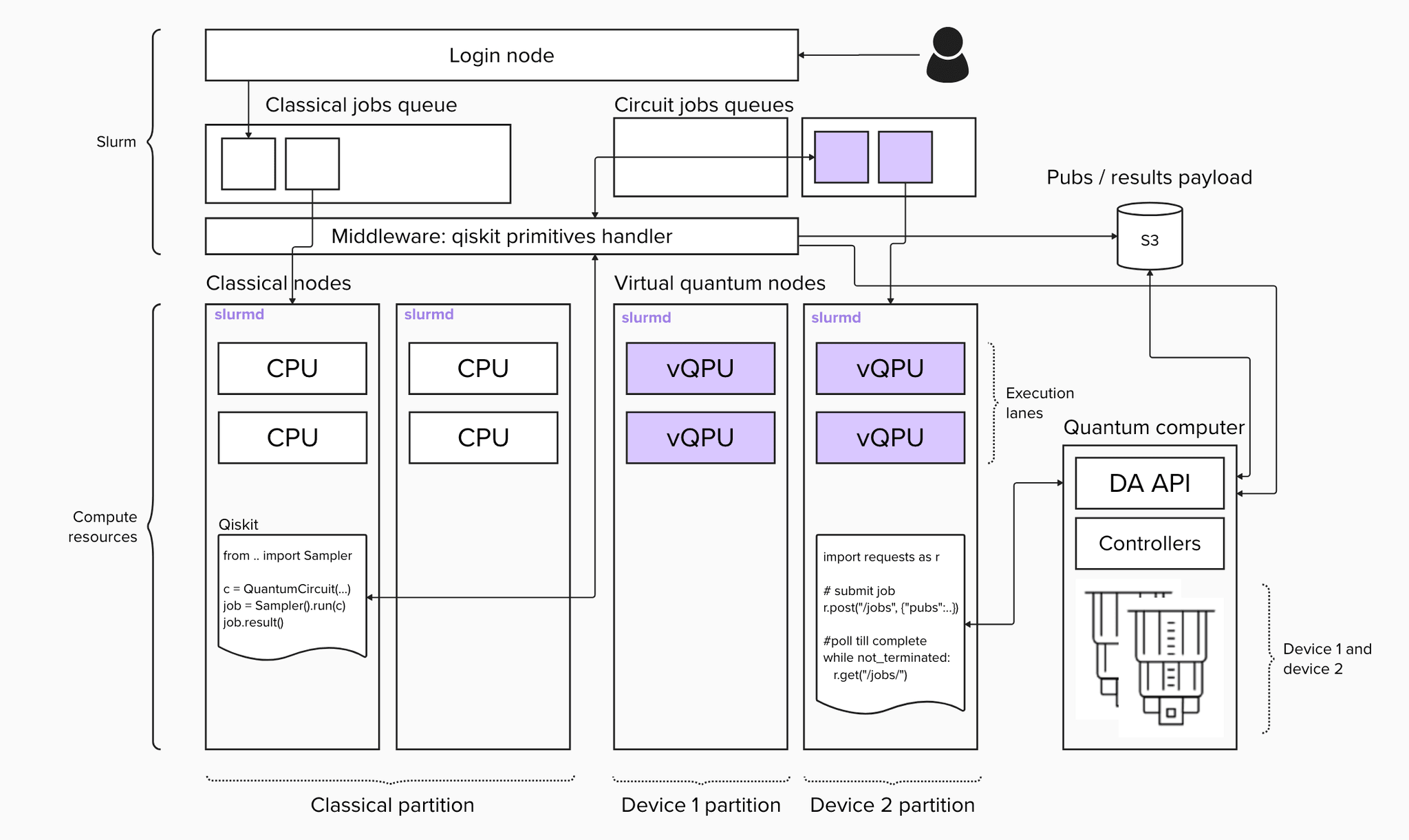
We can map the above mentioned architectures to existing workload management systems. Let’s take the dueling queue architecture and apply it to Slurm. For a simple implementation we need 3 components: a client that implements primitives, middleware to handle client calls, and primitives job logic to talk to the API of the quantum system.
These are all relatively easy to implement: for the client, you will need to extend the Qiskit primitives base classes. For middleware, we need to implement a microservice that acts like a proxy for Slurm rest or central deamon commands. A job is a call to the quantum system APIs.
Now, let’s write our first hybrid quantum-classical program based around the SQD technique and run it on this integrated environment. As with any quantum computation, it will require us to follow the steps of mapping of the problem, optimization, execution, and postprocessing.
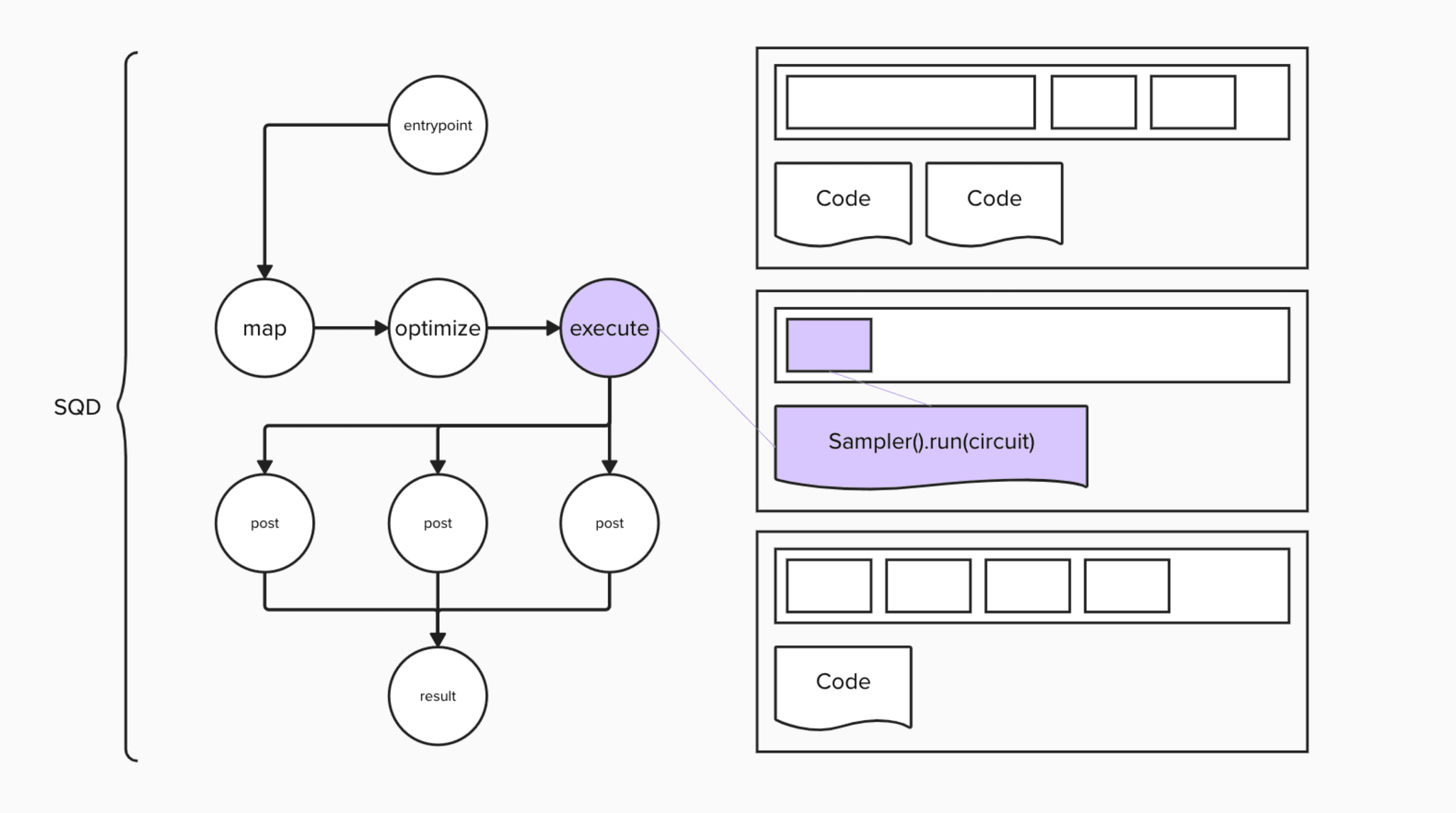
For each step of this process we will create a job script and submission script for Slurm. Let’s start with mapping, converting a molecule’s full-configuration interaction into circuit of interest.
map.py
from ... import LUCJCircuit
lucj_circuit = LUCJCircuit.from_fci("n2_fci.txt", ...)
with open("lucj_circuit.json", "w") as f:
json.dump(lucj_circuit, f, cls=...)map.sh
#!/bin/bash
#SBATCH --job-name=map
srun python3 map.pyFor the optimization step, we will transform the circuits into ISA circuits optimized for the target backend. Here, we will be using an implemented client to get the specifications of available backends.
optimize.py
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
from ... import SlurmService
backend = SlurmService().get_backend("heron_1")
pass_manager = generate_preset_pass_manager(
optimization_level=3,
backend=backend,
initial_layout=initial_layout
)
with open("lucj_circuit.json") as f:
isa_circuit = pass_manager.run(json.load(f))
with open("isa_circuit.json", "w") as isa_f:
json.dump(isa_circuit, f, cls=...)optimize.sh
#!/bin/bash
#SBATCH --job-name=optimize
srun python3 optimize.pyFor execution, we will again use the client with Sampler and execute the ISA circuit against the backend.
execute.py
from ... import SlurmService, Sampler
backend = SlurmService().get_backend("heron_1")
sampler = Sampler(mode=backend)
with open("isa_circuit.json") as f:
isa_circuit = json.load(f)
job = sampler.run([isa_circuit], shots=10_000)
primitive_result = job.result()
pub_result = primitive_result[0]
counts = pub_result.data.meas.get_counts()
with open("counts.json", "w") as counts_f:
json.dump(counts, counts_f)execute.sh
#!/bin/bash
#SBATCH --job-name=execute
srun python3 execute.pyIn the postprocessing step we will use the SQD procedure, leveraging parallel computation to recover energies.
postprocessing.py
from mpi4py import MPI
comm = MPI.COMM_WORLD
size = comm.Get_size()
rank = comm.Get_rank()
...
with open("counts.json") as f:
bitstrings = counts_to_arrays(json.load(f))
print(f"Starting configuration recovery.")
batches = None
if rank == 0:
batches = postselect_and_subsample(bitstrings, ...)
batches = comm.scatter(batches, root=0)
energy_sci = solve(batches, ...)
energies = comm.gather(energy_sci, root=0)
if rank == 0:
result = combine(energies, ...)postprocessing.sh
#!/bin/bash
#SBATCH --job-name=postprocessing
#SBATCH --ntasks=10
srun python3 postprocessing.pyNow, we have everything that we need to run our workflow. For simplicity we will chain jobs, but any workflow management tool can be used to construct the execution graph.
MAPPING_JOB=$(sbatch --parsable map.sh)
OPTIMIZE_JOB=$(sbatch --parsable --dependency=afterok:$MAPPING_JOB optimize.sh)
EXECUTE_JOB=$(sbatch --parsable --dependency=afterok:$OPTIMIZE_JOB execute.sh)
POSTPROCESSING_JOB=$(sbatch --parsable --dependency=afterok:$EXECUTE_JOB postprocessing.sh)We can explore the Slurm queue to see the execution of our job and the execution of primitives.
squeue
# JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
# 12 heron_1 21ebc89f root R 0:01 1 q3
# 11 main execute root R 0:12 1 c1
This architecture overview provides you a simple yet powerful integration plan to bring quantum into an HPC infrastructure without disturbing existing usage patterns of users. The learning curve for users of this integrated environment is close to zero, as we are keeping side dependencies to a bare minimum and reusing what is already available to our large user base.
Today, IBM is already providing users with the hardware and software tools they need to begin exploring quantum-centric supercomputing. Last week, we showed that IBM quantum computers can run circuits with over 5,000 gates—a range well into the regime beyond exact classical simulation.
We also demonstrated a host of features that are making quantum easier-than-ever to use. These include Qiskit addons, which are packages for implementing state-of-the-art techniques like SQD, and Qiskit Functions, which are hosted services to further optimize quantum application development provided by IBM and third parties.
We encourage you to get started exploring quantum-centric supercomputing today, so that together we can bring useful quantum computing to the world.



