ITコラム
AI時代に求められるクラウド分析基盤と統合データ・プラットフォーム(後編:ソリューション最新情報)
記事をシェアする:
AIを導入し競争力を強化する動きが加速し、AI活用のとなるデータの在り方が企業の競争力に直結する状況となっています。しかし多くの企業では、データが散在している、知見をどのように得るのか分からないなど、データ活用における課題・障壁があります。
このブログでは、データを企業で最大限に活用するための、データ管理からAI/機械学習の業務活用までを統合的にサポートするプラットフォームの要件を改めて整理し、データから価値を引き出すための2つのソリューションをご紹介。今回は「Watson Studio」と「IBM Cloud Private for Data(以下、ICP for Data)」の最新情報について解説します。
前編:データを企業で最大限に活用するための、データ管理からAI/機械学習の業務活用までを統合的にサポートするプラットフォームの要件を改めて整理するというデータの在り方について解説はこちら
1. Watson Studio/ICP for Dataの主な特徴
前編で述べた、データから価値を引き出すための要件・課題に対応するソリューションとして、Watson StudioとICP for Dataを提供しています。
2つのソリューションは、以下の特徴をもち、次世代のデータ活用を強力に支援します。
- データ活用のフルサイクルを一気通貫でサポートし、チームコラボレーションを促進する
「データ準備・加工」から「分析・可視化」の作業をツールをまたぐことなく一貫して行えます。それにより、データ活用の試行錯誤を進めやすくなる、業務部門とシステム部門のコミュニケーションを円滑にできる、などの効果があります。 - 様々なデータ利用者が、必要な時に、必要なデータにアクセスし、好きなツールを使える環境を提供し、アジリティを高める
プレパレーションツール、分析/マシンラーニングエンジン、BIエンジンなど、利用者の目的に応じて、スピーディにデータ活用を進める環境を装備しています。
さらに、作業のアウトプットを、エンタープライズ・カタログを介して共有することで、上記チームプレイを円滑に支援します。 - マルチクラウド環境でのデータ関連資産の可搬性を高める
オンプレ、クラウド環境をまたいで、データ辞書、加工データ、バッチモジュール、分析モデルなどの資産を利用できます。それを実現するための基礎として、コンテナーテクノロジー、Jupyterフレームワークといったオープンソースベースの技術を採用しています。
次節以降でそれぞれのソリューションを具体的に解説していきます。
2. AIのためのクラウド分析基盤:Watson Studio
データ・AI活用によりビジネスの成功に導くためには、「データ基盤」「分析・AI基盤」「人工知能」の三者を相互に連携させ、継続学習のサイクルを確立することが重要なポイントとなります。IBM Watson(以下、Waston)ではそのための関連ソリューションを用意しており、Watson StudioはAIのためのクラウド分析基盤として位置付けられます。
また現在では、プロトタイプとなるクラウド環境を構築して、すぐに手に入るデータを基にクラウド上で試行錯誤しながらデータ分析を行うアプローチが一般的になっています。そのような環境を分析ユーザーのためのサンドボックスと呼ぶこともあります。小規模な分析プロジェクトから開始し、ステップを踏んで大きな仕掛けとするアプローチが必要となってきています。
図1では、クラウド分析基盤としてのWatson Studioに関連するサービス群を詳細化しています。その中で中心となるサービスの概観を解説します。
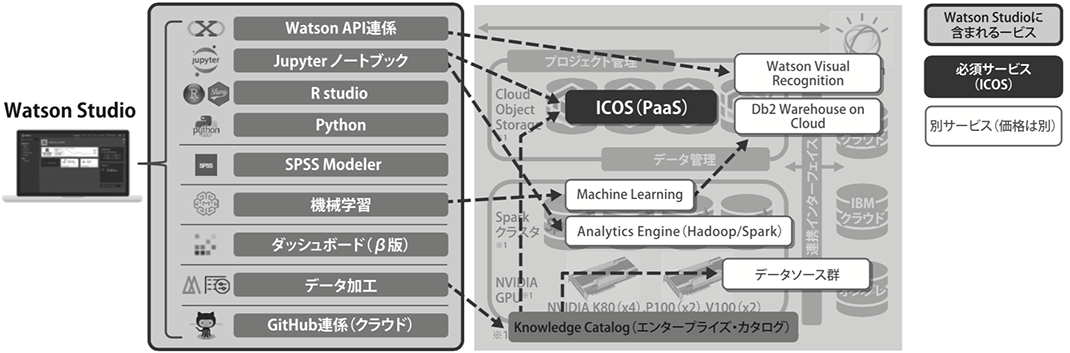
図1. Watson Studioに関連するサービス群
分析とAI開発
企業内でデータ・サイエンティストが使っているツールがそれぞれ違っていても、同じ環境で分析結果を閲覧、再利用しながらチームで分析できる仕組みとなっています。
例えば、データ・サイエンティストの利用の多いPython、Rなどでの分析が可能なように、オープンソース・ソフトウェアとしてPython Notebook、RStudioのツール利用が可能です。IBMソフトウェアとして利用者の多いSPSS Modelerの機能をWatson Studio内で利用することも可能です。さらに、分析スキルのあまり高くない業務ユーザーもマシン・ラーニング(以下、ML)のGUIから入力データを指定して機械学習を行うことも可能なため、データ・サイエンティストにとどまらず、ビジネス・ユーザー主導での分析に利用されます。
また画像認識が可能なWatson Visual Recognition APIやCoreML用の画像認識用モデルのエクスポートも利用できるため、分析プロジェクトだけでなく、AIプロジェクトの基盤としての利用も想定しています。
エンタープライズ・カタログ(Knowledge Catalog)
は、企業内の部門間にまたがるデータの管理・可視化・意味付けに役立ちます。メタデータは「データのためのデータ」という意味で、テーブルのカラムやCSVファイルのヘッダー部分などデータに関する意味付けの部分を指し、データそのものではなくメタデータを管理しておくことで、実体のデータをコピーすることなく管理可能です。Knowledge Catalogのデータソースとしては、IBMのデータソースのみならずサードパーティーのデータソースにも接続可能です。部門ごとにバラバラのデータソースを利用して分析を行っている場合は、データを一元化し、意味内容を把握した段階で、分析で検索可能にするためのタグ付け機能を利用できます。利用するためのデータはデータ加工機能で加工を行え、分析の作業工数でもっとも大きいと言われるデータ整備の作業工数を削減可能です。
データ蓄積
IBM Cloud Object Storage(ICOS)に大量データを格納して、大量データを処理できる仕組みがあること、アカウントを作ってインスタンスを作成するだけで手軽に始められることがクラウドで分析環境を実装する上での大きなメリットとなります。
3. 統合データ・プラットフォーム:ICP for Data
3-1. ICP for Dataが提供する機能
ICP for Dataでは、図2に示すとおり、2章で述べたデータ整備から業務適用までのフルサイクルを包括的にサポートするコンポーネントが装備されています。利用イメージとしては、ICP for Dataを既存のデータソースに接続させ、そのデータを加工したりMLで分析したりして、アウトプットをアプリに適用するような一連の流れで利用できます。
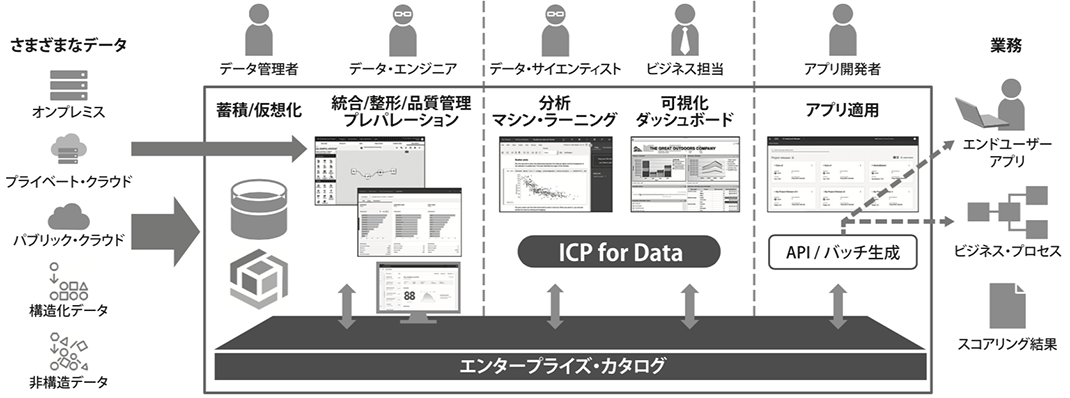
図2. ICP for Dataの概観
また各機能は従来のIBMミドルウェアやオープンソース・ソフトウェアが拡張し実装されています。例えばデータ蓄積には、ノン・チューニングなインメモリーDWHとして高速化・簡易化された「Db2 Warehouse」がコンテナ・ベースで同梱されます。プレパレーションとしては、多くの企業で活用されるETL「DataStage」が利用ユーザー部門向けにライトなGUIで最新化され、コンテナ・ベースで同梱されます。したがってIBMミドルウェアを利用中の企業では既存資産を生かし、最新化されたICP for Dataを利用できます。また他社システムを利用中の企業でも、ICP for Dataを組み合わせて利用可能です。次にICP for Dataに装備される主な機能のうち、エンタープライズ・カタログ、品質管理、プレパレーション機能の概観を記載します。
エンタープライズ・カタログ
カタログの目的は大きく2つあります。
1つ目は、データ利用ユーザーが、適切なデータを必要なタイミングで探し、取り出しやすくすることです。カタログは、ビジネス用語でもデータを検索し、必要なデータの所在や来歴(どのような加工フローで作成されたか)を確認できます。そのためには、事前にビジネス用語とデータ定義(テーブル名・カラム名)のマッピングが必要です。そういった作業の負荷を軽減するために、AI技術が内蔵されていく方向にあります。例えば、過去のマッピング定義を学習データとして機械学習で自動マッピングさせることができます。
2つ目は、全社でのコラボレーションを促進することです。各メンバーが加工/生成した学習データや、分析モデルをカタログを介して共有・再利用することで、重複した加工作業や分析作業を削減し、企業全体の生産性を向上します。
データ品質管理
データ品質の状況を可視化します。例えば分析結果に影響を与えるデータの欠損値の有無を確認できます。このようにデータの正確性をあらかじめ調査し管理しておくことで、各データ利用ユーザーが、都度データ品質を確認する手間を省きます。また過去の利用者によるデータへの評価を登録でき、データの正確性や信頼性を利用前に確認することが可能です。
データ・プレパレーション
データ利用ユーザー自身が、データ管理者に依頼せずとも、データを加工することが可能です。担当者間のやりとりを減らし、データ活用のスピードを加速させ、生産性を向上します。
分析系の機能は、3章で説明したWatson Studioに含まれるものと同等のため、本章では割愛します。
3-2. ICP for Dataの構成
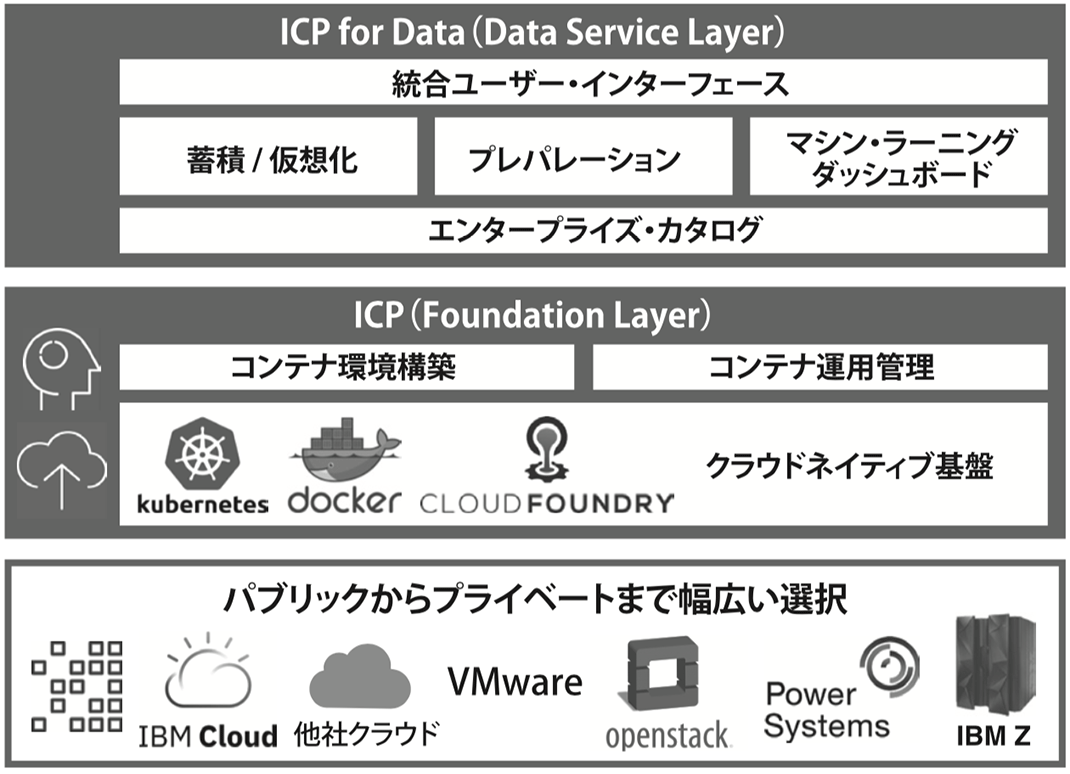
図3. ICP for Dataの基盤構成
図3にICP for Dataの基盤構成を示します。ICP for Dataは、「IBMCloudPrivate」(以下、ICP)[*1]の上位層として構成されます。ICPは、Kubernetesベースのコンテナで実装された統合クラウド・プラットフォームで、基盤の導入・管理のワークロードを大幅に削減します。コンテナ・ベースであるため、クラウド上で構築したDWHやETLをオンプレミス環境に移行しやすくできるなど、ハイブリッド環境での可搬性も向上します。[*1]IBM Cloud Private,
またICPやICP for Dataは、オンプレミスのサーバーや、クラウドのIaaS上に構築可能で、セキュリティー・レベルを高められるため、個人情報を含めたデータの管理にも適しています。
4. Watson StudioとICP for Dataの位置付けと組み合わせ
2つのソリューションは、2章で述べた分析、データ・プラットフォームの要件をともに実装しています。選択肢として、スピードを重視したプロトタイプでのAIプロジェクトにはWatson Studioを、セキュリティーを重視した統合データ・プラットフォームの構築にはICP for Dataをといった使い分けが可能です。2つの組み合わせも可能で、オンプレミスとクラウドの適切なデータを取り出してETLバッチも活用しながらデータを整形しAI-readyな状態にするICP for Dataと、そのデータをAIに適用するWatson Studioといった連携も考えられます。
またソリューション間で以下のような連携のシナリオが考えられます。
(1)エンタープライズ・カタログに登録されたAIやデータのアセットを相互連携
- オンプレミス上の資産を登録したICP for Dataのカタログから、クラウド上のWatson Studioのカタログに、アセット情報をインポート可能です。オンプレミスでカタログに登録したビジネス用語を、クラウドのプロトタイプ環境にインポートするなどの利用シーンが考えられます。このように、それぞれのカタログを組織横断の資産共有・再利用の場として活用できます。
(2)分析モデルや学習データを相互連携(以下は将来的なロードマップも含みます)
- プライベート環境の全社データを利用し、ICP for Dataのマシン・ラーニングでモデルを開発します。そのモデルをWatson Studioのスコアリング・エンジンで、クラウド・アプリに適用します。
- クラウド上で、Watson Studioのディープ・ラーニング・サービスでモデルを開発します。そのモデルをICP for Dataのスコアリング・エンジンで、オンプレミス環境のアプリに適用します。
2つのソリューションはIBM内の統合された開発拠点で開発されており、今後も相互連携を強化する方向です。
5. Watson StudioとICP for Dataの利用パターン
さまざまな業界において、デジタル変革推進とトップライン向上のために、データ利活用を高度化するニーズがますます増えています。またIoTデータや非構造データなど、これまで利用できていないデータを含めて活用するニーズも増えています。それらのニーズに統合的にアプローチする際に、Watson StudioやICP for Dataを利用できることを前編で解説してきました。図4に、国内外の事例を基に汎化した利用パターンを示します。ビジネス担当者やデータ・サイエンティストがデータから新たな洞察を得るための試行錯誤ができるサンドボックス環境から、全社データ活用促進のためのデータ探索・加工・分析のサイクルを実装する環境や、高度な分析や自動化の仕組みを提供する環境まで、さまざまな業界で取り組み事例が創出されています。このようにデータの蓄積・可視化が中心であった従来のデータ基盤に対し、図7に示すような分析・AI活用の要素を段階的に強化し、次世代の統合AI分析基盤へと発展させることができます。
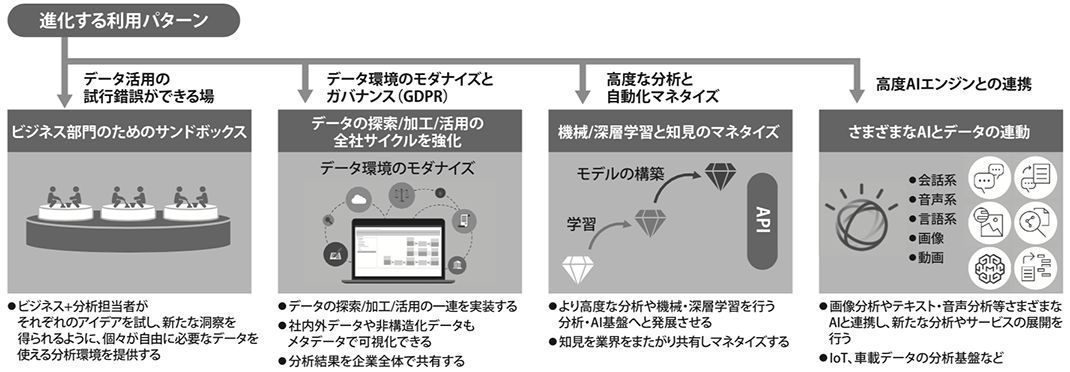
図4. Watson Studio/ICP for Dataの利用パターン
まとめ:企業のデータ活用を支援するWatson Studio、ICP for Dataの最新情報を解説してきました。2つのソリューションは、今後も拡張され最新のテクノロジーを実装していくため、実装時点の最新情報をご確認ください。例えば10月に発表されたAI OpenScaleサービスで、AIの判断根拠の説明性を強化したり、AIの判断の偏り(バイアス)を確認し公平性を強化することが可能となっています。企業横断のAIプロジェクトにおいて、整備・開発したデータとAI関連のアセットをフルサイクルでより高度に管理・再利用する役割が期待されます。
前編:データを企業で最大限に活用するための、データ管理からAI/機械学習の業務活用までを統合的にサポートするプラットフォームの要件を改めて整理するというデータの在り方について解説はこちら
IBMは、デジタル変革を加速する企業や組織に向けて、Watson StudioやICP for Dataを駆使し、単体ソリューションの組み合わせでは実現できないアジリティーで、AIとデータを統合した次世代プラットフォームと包括的な支援を提供します。企業全体のデジタル変革に向けて、ビジネス部門とIT部門とが一体となって新たな価値創出を推進するための一助となれば幸いです。
データからより高い価値を引き出すというゴールを実現には、3つの基本的な課題「データのアクセスしやすさ」「データの品質」、および「人材不足」の改善に取り組むことが必要です。また進展をつづける各種法制度に対応していく必要もあります。これらの課題を解決することが、重要事案に対する意思決定やAI活用に役立つ、信頼できるデータ基盤を構築するための足掛かりとなります。

久保 俊彦 Toshihiko Kubo
日本アイ・ビー・エム株式会社 IBMクラウド事業本部 シニア・アーキテクト
1999年日本IBM入社。電子カルテシステムの開発プロジェクトへの従事を経て、Information Architectとして、金融・製造・流通業の基幹系/情報系システムのコンサ ルティング、アーキテクチャー設計を、海外SMEと連携し推進。現在は金融機関のビジネス/IT部門とともに、企業横断でのデータ・AI・クラウド活用による価値創出を推進している。

時光 さや香 Sayaka Tokimitsu
2002年日本IBMにSEとして入社。金融・製造・流通など様々な現場で8年間オープン系アプリケーションのデータ設計・データ関連コンサルティング、情報系システム構築を担当。7年前からは技術営業として、データ分析製品の選定支援を行う。現在はWatson Data &AIを中心としたクラウド・サービスの選定支援を行っている。


多言語自然言語処理研究の基礎を支える、評価尺度BLEU
ディープラーニングが自然言語処理の世界を席巻するようになり、翻訳や要約など様々なタスクにおいて精度を向上させる新しい手法が毎日のように提案されています。 一方、精度がどのくらい向上したかを判断するための評価手法については […]

人間中心のAIとは?
AIは、営業、財務、人事など様々な領域で、ますます応用されています。本記事では、AIシステムの開発において、IBMリサーチが採用している人間中心のアプローチを紹介します。 自動車の自動運転、創薬、ニュースや […]