AI
IBM專家觀點:從ChatGPT走紅,談企業需要甚麼樣的人工智能 —— 從「百事通」到「業務助手」
Share this post:

ChatGPT火爆出圈
最近幾週,AI業界最大的新聞無疑是ChatGPT橫空出世,從而引發的業界震動。 市場上有大量的評論文章,有把它描述成無所不能的,大有代替人類職業之勢; 也有提出擔憂,某些頂級學術雜誌和知名高校已經明確限制AI作者發表論文和科研成果。
出於好奇,筆者也試用了ChatGPT。整體感覺對於一般的開放性問題,ChatGPT生成的回答文法結構完整,語言風格自然,比之前的聊天機械人有明顯的進步。內容的準確性和完整性,往往能超過正常交流時大多數人的「第一反應」,更像是經過了一番思考並整理後的結果,條理清晰,很有啟發。但對於專業性問題,尤其是需要邏輯推理的知識,ChatGPT並沒有像網上文章說的那麼出色,經常張冠李戴或者形式上像、模像樣、但內容上卻不知所云。
為甚麼會這樣呢?我們可以問一問ChatGPT自己。
「ChatGPT是由OpenAI公司開發的一款預訓練語言轉換器,旨在生成人類可讀的文本。它通過讀取大量的文本數據,學習了如何生成與語言相關的內容,並在輸入一段文本時生成一段有關的文本輸出……」
ChatGPT中的GPT的全稱是的 Generative Pre-trained Transformer -即「生成式預訓練轉換器」。借用一位名叫#矽谷學霸Jolin 的技術教育博主對GPT模型的淺顯解釋,她說,以ChatGPT為代表的「生成性AI」是一項技術突破,之前AI學習大多聚焦於觀測、分類和分析內容,而生成性AI則不限於分析現有數據,它可以生成新內容,可以根據需要生成新的代碼、詩歌、文章和藝術品。 ChatGPT是專注於文本內容的生成性AI。所謂「預訓練」是指該轉換器已經在某些有限的數據集上進行了訓練;事實上,ChatGPT已經學習了2021年6月以前人類編寫和發佈在互聯網上的海量資料,而且是通過「監督學習」和「人類反饋強化學習」這兩種技術進行的學習。 Transformer是一個非常底層的AI機器學習的算法架構,是一種深度神經網絡。從GPT-1到今天的GPT-3.5都是採用Transformer架構,而GPT模型的進化有賴於底層硬件超級算力的效率提升,以支持AI對更多、更大數據集的訓練和學習。
也就是說,ChatGPT是通過海量(約45TB)語料訓練而掌握了語法和語義結構的成熟的大型語言模型(Large Language Model, LLM),其特色是文本生成能力很強,產生的文字風格和內容很像之前的輸入,即人類語言。由於訓練語料涉及面廣,所以ChatGPT對各行各業的資料都有涉獵,總能略知一二,有時甚至回答得頭頭是道。對某些專業領域,比如編程,甚至可以產生準確的代碼並直接運行。然而,若仔細觀察,這些代碼往往都是解決特定的小任務,代碼風格似曾相識。若要完成一個創新的算法,或者複雜問題的編程,ChatGPT就無能為力了。
總體而言,這類通過學習語料來生成文本的AI模型,都是在學習過去,其目標是模仿過去,生成出幾可亂真的作品,並不是真正意義下的創造未來。 ChatGPT也不例外。作為助手,對思考的廣度往往有幫助,對思考的深度卻不盡然。
從聊天到業務助手
ChatGPT讓我們看到了大型語言模型的未來。然而,在企業應用中,為了創造業務價值,這類對話形式的應用(ChatBot,聊天機械人)則更多用於對外的「客戶服務」或對內的「業務助手」方面。這就對此類模型提出更高的要求——
第一, 準確性和專業性
企業往往要求回答準確且專業,如果對答案沒有把握,回答「不知道」也好過生成一大段豐富而無用的文字。
ChatGPT是一種「開放領域系統」(Open-domain system),類似的還有Google的Bard,它們都需要海量的資料輸入和長時間的訓練,能應付所有領域的對話,回答內容相關度高,對答自知,語法自然。
而企業級的ChatBot是一種「封閉領域系統」(Close-domain system),往往不是需要一個乖巧的「百事通」,而是需要專業領域可靠的「知識助手」。它的訓練語料是有限的,包含企業內部文檔和資料、專業領域知識庫、外部該領域的相關文章等等,大量的資料都是不公開的。 ChatBot能回答的問題也限定在專業領域的場景語境中。不必面面俱到,但求簡練、精準、專業。
第二,主動式對話
碰到模棱兩可的提問時,企業應用往往要求通過主動引導式對話,甚至反問的方法,迅速澄清意圖,然後再給出明確的答案。這一點ChatGPT目前尚未做到,當問題模糊時,回答也模糊,提問者發現後,換一種問法,或者在對話中縮小範圍,可逐步得到想要的結果。整個過程中,ChatGPT每次都是被動回答。
第三,後台整合能力
ChatBot作為企業對話的窗口,在提供服務時需要和企業大量的後台系統連結和整合。比如:在識別意圖後可以從數據庫或大數據平台中自動收集相關數據,並進行分析和推理,得到客戶所需的明確答案;或者啟動一條指令或一個後台流程,幫助客戶完成相關操作。
IBM Watson服務企業級AI應用
OpenAI從2018年以來長期堅持研發大型語言模型,通過不斷迭代,從最初的GPT-1到目前的GPT-3,且今年會發行GPT-4。目前,在開源社區找到GPT-3模型,也為企業開展此類研究提供了範本。
ChatGPT對企業的吸引力是毋庸置疑的,多數企業都有意願擁有一個自己的ChatGPT。然而,當前ChatGPT採用最新的GPT-3.5模型,含有千億級參數,一次訓練就要花費數百萬美元 。大多數企業都不具備如此大的算力,但如果為了獲得對話模型,把企業內部數據都上傳到網上,利用公共雲訓練也會有安全顧慮。所以,企業主導訓練一個定製版ChatGPT,無論從財力還是合規方面都會有障礙。
IBM Watson,也就是IBM企業級的人工智能,經過十多年的發展,從研究到實驗,至今已經發展成為一套可以在Red Hat OpenShift上任意運行的AI能力,以產品化的方式提供給用戶,幫助企業整合和分析混合環境下分散而複雜的企業數據,從而實現數據驅動的預測性決策、智能自動化和基於企業內外適時數據和洞察的安全策略與回應。
今天IBM Watson已經應用於全球四萬多企業用戶的業務場景當中,為具有不同水平AI技能的用戶提供尖端的AI能力,無論是缺乏AI技能卻想通過AI重獲時間效率的商務及專業人士(例如人力資源、財務、網絡安全管理人員等),或是具備一定AI技能並且正在大規模使用AI的數據科學家、IT專業人員等。
IBM Watson提供了許多不同的工具和服務,用於解決多種問題。它涵蓋了語言處理、解釋、回答和生成文本等多種功能,以幫助客戶解決商業問題。同時,它也提供了語音識別、圖像識別等其它功能,使之成為一個非常強大和全面的人工智能平台。
長期以來,IBM Watson提供企業級AI應用,特別為企業定制「業務助手」類的對話式應用。基本上,Watson有語音文字轉換、意圖識別、對話流設計、文本分析、知識整理、情感分析等功能,使得Watson可以在通用的語言模型上疊加專業領域知識,並有意識地設計和引導對話方向。
Watson通過後台的機器學習、自然語言處理、文本生成、語音識別與合成、對話系統、知識圖譜技術,可以分解文本結構,精準定位觀點、事實、論據、邏輯關係等。早在數年前,採用IBM Watson技術的IBM人工智能辯手(Project Debater) 就曾以它的機智幽默和高情商而驚艷業界,它可以針對任何一個預設話題,比如「國家應該為每個人提供基本收入」,臨時選擇正方或反方,與人類的辯論冠軍選手進行對辯。今天的ChatGPT也可以達到這個效果。應該承認,其通用語言模型和文本生成技術所呈現的體驗感受甚至可以超過Watson,令人驚詫,其開放的用戶界面更是讓大眾能夠親身體驗這種驚艷,然而Watson的專業性、可設計性、整合性則更適合企業級的業務定位。 IBM把這種普適性的大型基礎模型稱為基礎模型(Foundation model) ,它利用遷移學習(transfer learning)經過少量的專業訓練,就能進入一個知識領域,並且得到新的啟發,這一點非常像人類的學習過程,有廣闊的應用前景,也是IBM今後研究的重點。
我設想,對於企業已有的Watson對話模型,也可以利用ChatGPT得到增強。可以是協同模式:當發現是專業領域的封閉式問題,可用原有Watson模型回答,當發現是開放式問題,可用ChatGPT回答。也可以通過競爭模式:一次生成多個答案,由人類做裁判,相互學習,共同提高。
總言之,ChatGPT將人機對話的體驗提高了一個檔次,利用強大的搜索和知識整理的能力,在問題回答的廣度上往往很有啟發,但深度不足。目前只能學習(Learn)人類語言和知識,還做不到思考(Think)推理,也難以駕馭高度創新和深度思考的任務。我認為,對於企業級的應用,融合ChatGPT與IBM Watson之所長,不乏為快速高效地應用AI 提升體驗、創造價值之選。
參考資料:
[1] OpenAI公司在GitHub上開源的GPT-3模型,https://github.com/openai/gpt-3
[2] IBM致力於基礎模型研究 https://research.ibm.com/blog/what-are-foundation-models , https://research.ibm.com/blog/molecular-transformer-discovery
本文作者簡介:
陳宇翔先生現任IBM大中華區客戶成功架構師,他是IBM傑出工程師(Distinguished Engineer), 也是IBM大中華區金融行業首席架構師。在近25年的IT 從業經歷中,他主持了許多大型項目的解決方案設計和IT 架構設計,熟悉銀行領域相關業務,是行業高級顧問。陳宇翔先生也是軟件和技術專家,長期致力於軟件推廣工作。同時擁有IBM 高級工程師和資深架構師認證。

IBM 傑出工程師、IBM 大中華區金融業首席架構師
ASL Optimizes Application Performance with IBM AIOps Solution
Organizations are now accelerating their digital transformation, therefore transforming the application landscape and making it more hybrid and complex. However, Hong Kong has seen a shortage of tech talent in recent years, presenting several key challenges to organizations when managing their applications. The talent shortage is an urgent concern that is currently slowing […]
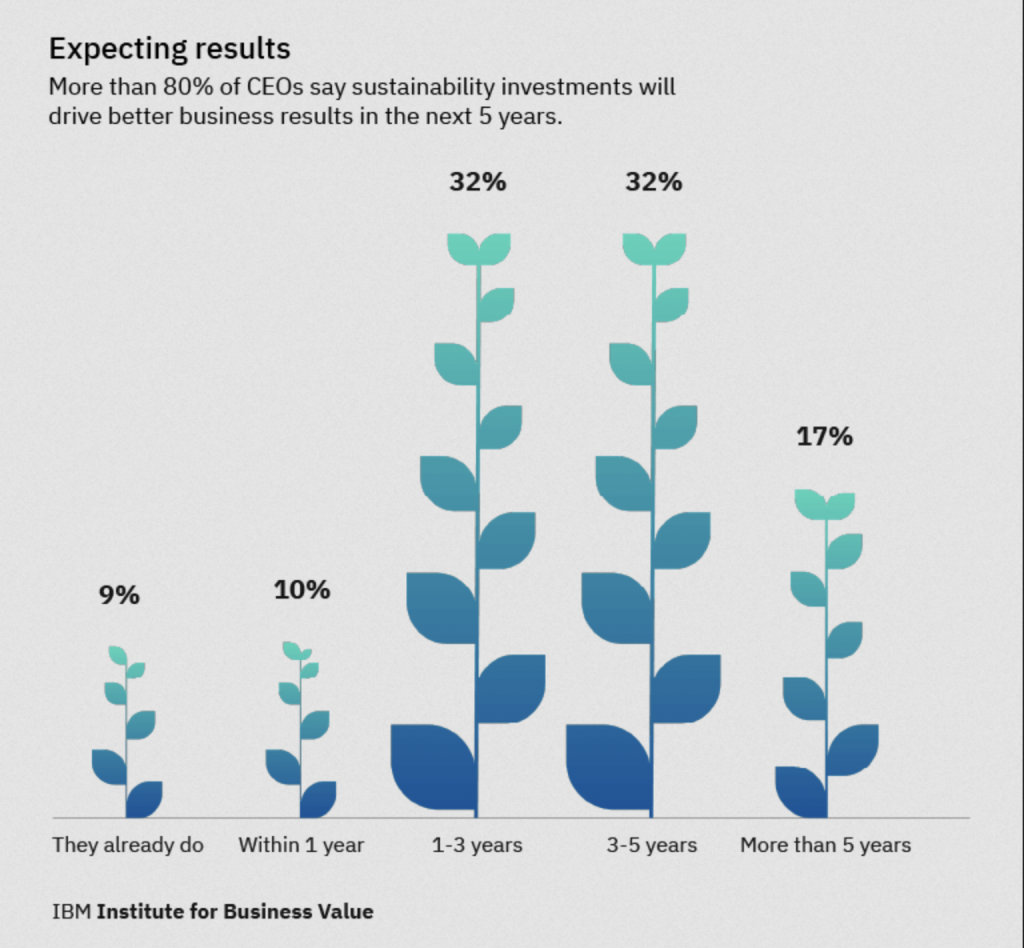
Putting Sustainability at the Heart of Business as the Key to Success
Increasingly, we are witnessing climate change play a growing role in staying abreast in a competitive business market. Just late last year, the Hong Kong government announced the Hong Kong Climate Action Plan 2050, setting out the vision for achieving carbon neutrality before 2050, with an interim target to reduce carbon emissions levels by 50% […]

Why the Future of Financial Services Lie in Extreme Digitization
Three years into a global COVID-19 pandemic and financial services firms are beginning to face a different market landscape. The biggest change is customer expectations. After shifting to a more digital lifestyle, retail and business customers want the same level of seamless experience that fintechs, virtual banks, platform players, and SaaS applications offer. It’s […]