Adversarial Robustness Toolbox: One Year Later with v1.4
IBM Research published the latest major release of the Adversarial Robustness Toolbox (ART), an open-source Python library for machine learning security.
IBM Research published the latest major release of the Adversarial Robustness Toolbox (ART), an open-source Python library for machine learning security.
One year ago, IBM Research published the first major release of the Adversarial Robustness Toolbox (ART) v1.0, an open-source Python library for machine learning (ML) security.1 ART v1.0 marked a milestone in AI Security by extending unified support of adversarial ML beyond deep learning towards conventional ML models and towards a large variety of data types beyond images including tabular data. This release aimed to help especially enterprise AI users, as their data is often in tabular form, in defending and evaluating their ML models with the same methods in a unified, user-friendly environment to create more robust and secure AI applications.
Earlier this summer, IBM donated ART to the Linux Foundation with the simple rationale to accelerate the development of responsible AI-powered technologies and encourage the AI and Security communities to join forces and co-create these tools together to ensure that they work for everybody as intended in diverse real-world AI deployments. IBM itself recently added ART to its IBM Cloud Pak for Data as part of the Open Source Management service to provide developers easy and secure access to ART.
ART has grown substantially during the last year and certainly has surpassed all expectations. As of today, ART has attracted more than 40 contributors, received more than 1.7K stars and has been forked nearly 500 times on GitHub. This success continuously inspires us to further develop and improve ART. Today we are very excited to announce the release of ART v1.4 and to present an overview of the exciting new tools of ART.
ART v1.4 enables developers and researchers for the first time to evaluate and defend ML models and applications against the 4 adversarial threats of evasion, poisoning, extraction and inference with a single unified library. Figure 1 shows the relation of these 4 adversarial threats against ML models and training data including the newly added threats of extraction, where the attacker attempts to steal a model through model queries, and inference, which allows the attacker to learn about potentially sensitive private information in a model’s training data just by accessing the trained model.
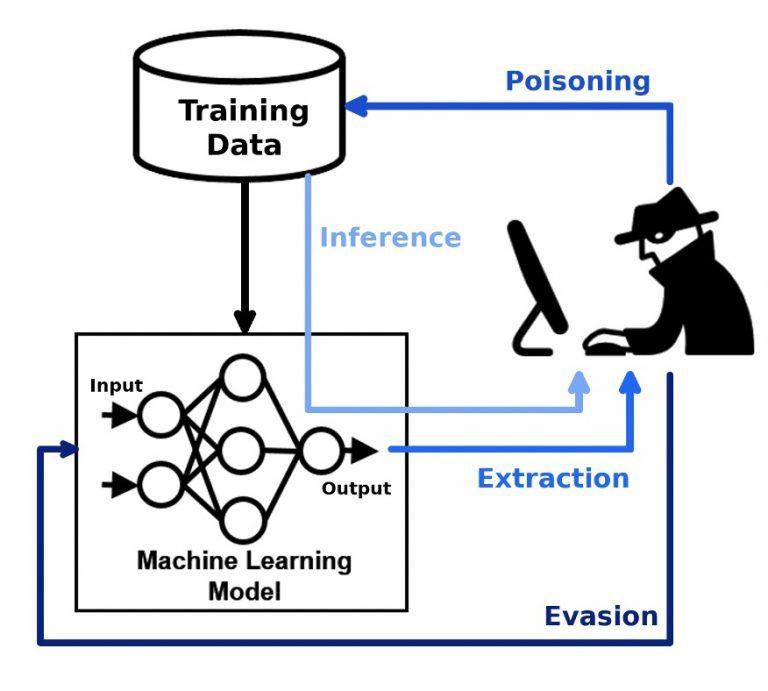
Furthermore, ART v1.4 extends the supported ML tasks to include object detection, generative-adversarial networks (GAN), automatic speech recognition (ASR), and robustness certification in addition to classification and is compatible with all popular MLframeworks to prevent users from getting locked into a framework.
The threat of inference is of especially high interest to many enterprise users and researchers because of stringent regulations for data and privacy protection. Therefore, we’ll dive deeper into these attacks and tools in the following paragraphs. ART v1.4 provides 3 different types of inference attacks that invade different aspects of the privacy of training data: membership inference, attribute inference and model inversion. ART v1.4 introduces these attacks to provide developers and researchers with the tools required for evaluating the robustness of ML models against these inference attacks.
The new membership inference attacks of ART v1.4 allow reproducing a malicious attacker attempting to determine if the information of a certain record, e.g. of a person, has been part of the training data of a trained ML model or not. Such attacks represent serious threats as they could reveal sensitive private information just from access to a trained ML model. Specifically, an attacker using membership inference could based on learning if a person’s record was part of the training data of a ML model deduce if this person, for example, suffers from a disease, has to take medication, etc. The tools of ART enable developers and researcher to evaluate and prevent such risks before a model gets deployed into production and exposed to attackers.
Secondly, ART’s attribute inference attacks aim at inferring the actual feature values of a record known to exist in the training data only by accessing the trained model and knowing few of the other features of the record. That way, for example, a ML model trained on demographic data attacked with attribute inference could leak information about a person’s exact age or salary.
The third type of inference attack in ART v1.4 is model inversion where attackers aim to reconstruct representative averages of features of the training data by inverting a trained ML model. In the following example, ART’s model inversion tools reconstruct typical training samples for each of the 10 classes of hand-written digits classification task. Whereas in this example the leaked information is not sensitive, one can easily imagine scenarios where an adversary succeeds to infer sensitive private information with the same attack tool. Further details of the model inversion shown in Figure 2 can be found in this ART Jupyter notebook.

Fortunately, many of these inference attacks can be countered for example by training with differential privacy using the IBM Differential Privacy Library (Diffprivlib) or accuracy-guided anonymization.2, 3 ART is fully compatible with both libraries which facilitates evaluating the privacy risk even against defended models and enables verifying the effectiveness of these defenses before deploying a model into production and exposing it to potential attackers.
The following table (Figure 3) shows an evaluation of a Random Forest (RF) classifier using ART’s membership inference attacks. It can be seen how defending with differentially private training (weaker defence: epsilon=10 and stronger defence: epsilon=1) or accuracy-guided anonymization of the training data (weaker defence: k=50 and stronger defence: k=100) are able to reduce the success of the membership inference attacks (Attack accuracy, Precision and Recall) with minimal reduction in the RF classifier’s accuracy (Train and Test accuracy).

Try out Adversarial Robustness Toolbox (ART) today and please share your feedback.
Date
02 Oct 2020References
-
Nicolae, M.-I. et al. Adversarial Robustness Toolbox v1.0.0. arXiv:1807.01069 [cs, stat] (2019). ↩
-
Holohan, N., Braghin, S., Mac Aonghusa, P. & Levacher, K. Diffprivlib: The IBM Differential Privacy Library. arXiv:1907.02444 [cs] (2019). ↩
-
Goldsteen, A., Ezov, G., Shmelkin, R., Moffie, M. & Farkash, A. Anonymizing Machine Learning Models. arXiv:2007.13086 [cs] (2021). ↩