インフラ向けスマートアラート
スマート・アラートを使用すると、選択したインフラストラクチャー・メトリックに基づいてアラートを自動的に受信できます。
Instana アラートを受け取りたいインフラストラクチャのメトリクスをリストから選択すると、しきい値やその他の設定が提案されます。 設定に複数のアラート配信チャネルを追加すると、 Instana が自動的にカスタマイズされたアラートを作成します。
Kubernetes - 特定のスマートアラート
Kubernetes 環境を監視する必要がある場合は、 Kubernetes に関連するアラートのみを表示する、インフラストラクチャのスマートアラート専用のビューにアクセスできます。 このビューは UI () Instana で利用可能であり、管理者 Kubernetes 向けに特化した機能を提供します。 詳細については、「 インフラストラクチャ向けスマートアラート 」を参照してください
アラートを追加する
アラートを追加するには、以下の手順を実行します。
- Instana のUIにあるナビゲーションメニューから、 「インフラストラクチャ」 を選択します。
- 「スマート・アラート」 タブを選択します。
- スマート・アラートの追加をクリックします。
「スマート・アラートの追加」 は、スマート・アラートを構成できるアラート構成ダイアログを開きます。
アラート構成プロセスには、以下のステップが含まれます。
- 有効範囲を定義します。
- 違反の基準を定める。
- アラートを発するタイミングの閾値を定義してください。
- 通知対象のアラートチャネルを選択してください。
- アラートのプロパティを設定します。
- アラートに含めるカスタムペイロードを追加します。
スコープの定義
アラートの適用範囲を定義するには、 「適用範囲 」セクションで以下の手順を実行してください:
以下のいずれかの方法を使用して、 [メトリクス] リストからメトリクスを選択してください:
- [ リスト] タブで、キーワードを使用してメトリクス一覧を検索します。
- [ 正規表現] タブで、正規表現を使用してメトリクスのスコープを定義します。
図1. 指標の選択 
集計を次のように定義します:
- 時間の集計:希望する時間軸ごとの集計方法を選択してください。 この手法では、データポイントを1つのバケットにまとめます。
- シリーズ間の集計:データシリーズ間でバケットの合計を算出するには、 「シリーズ間の集計にSUMを使用する」 をオンに設定します。 通常、シリーズ間の集計は、期間間の集計と同じです。
以下の通知方法から1つを選択してください:
- カスタム集計 :定義した特定のカスタムタグに基づいてメトリクスデータをグループ化するには、 「カスタム集計」 をクリックします。 この方法はデフォルトで有効になっています。
図 2. カスタム集計 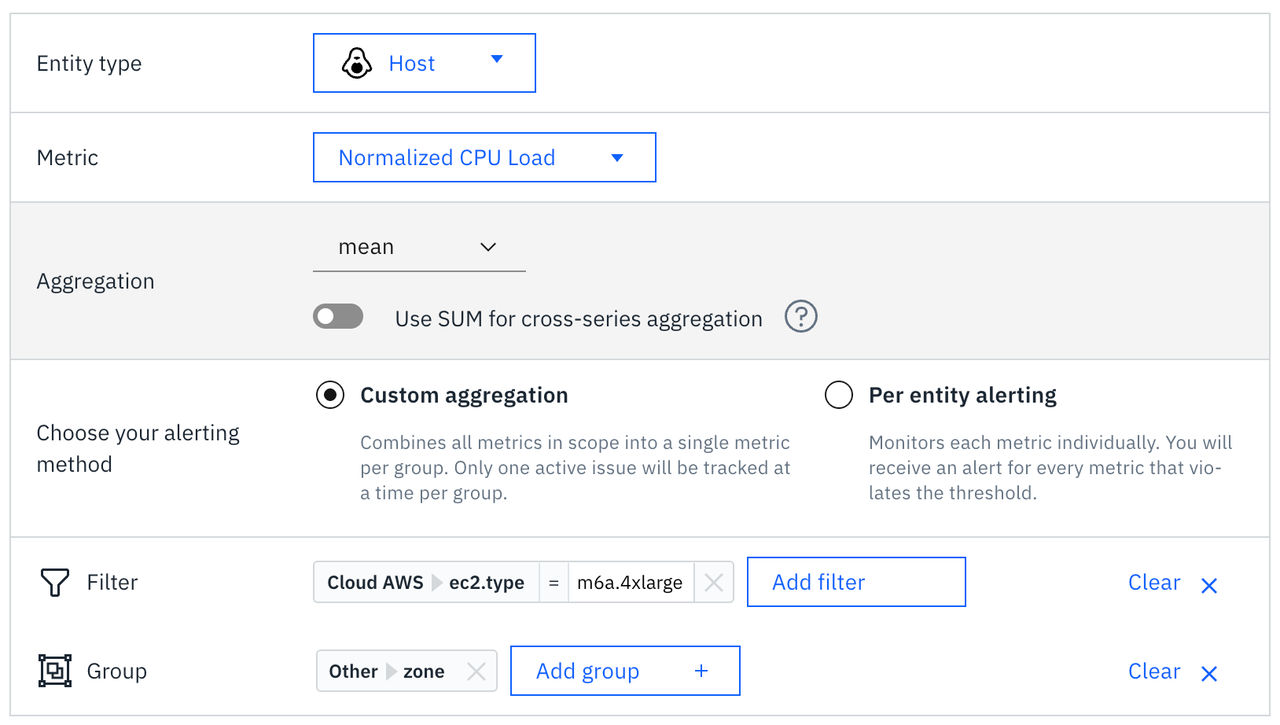
次のような場面で、カスタム集計を使用します:
- 複数のエンティティにわたる集計メトリクスの監視(例:特定のゾーンまたはリージョン内の全ホストにおける平均CPU使用率)。
- 類似したエンティティをグループ化することで、アラートのノイズを低減する。
- 個々の主体の行動ではなく、全体的な傾向やパターンを分析する。
- クラスタまたは環境全体における総容量やリソース使用率を追跡する。
例:アベイラビリティゾーンごとにグループ化されたすべての本番用ホストにおける平均CPU使用率を監視する。 ゾーン内の平均CPU使用率がしきい値を超えた場合、ホストごとに個別のアラートが送信されるのではなく、1つのアラートが送信されます。
エンティティごとのアラート設定 :各メトリクスを個別に監視し、個々のエンティティごとにアラートをトリガーするには、 「エンティティごとのアラート設定」 をクリックします。
図 3. エンティティーごとのアラート 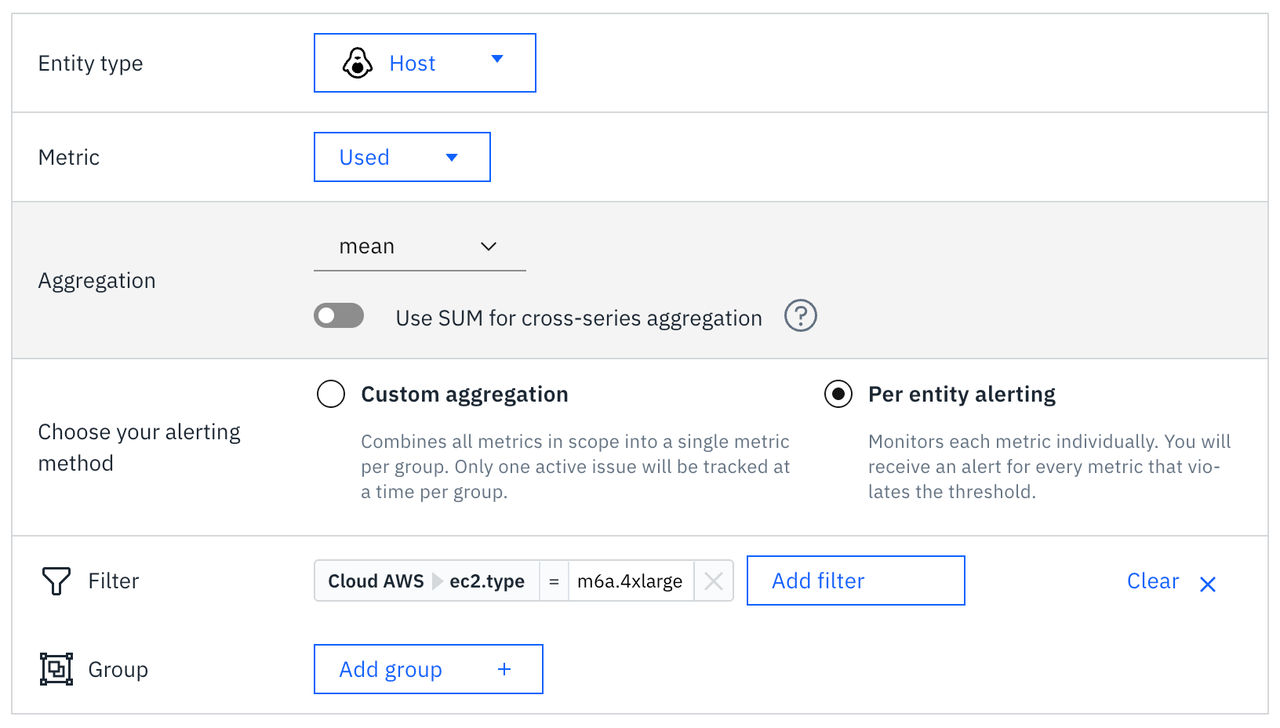
以下のシナリオでは、エンティティごとのアラート機能を使用してください:
- 特定のエンティティ(特定のホスト、コンテナ、データベースインスタンスなど)に関する問題を特定し、対応する。
- 各エンティティに対して個別に注意を払い、是正措置を講じる。
- 個々の障害が重大な影響を及ぼす重要なリソースの監視。
- エンティティ固有のSLAやパフォーマンス要件の追跡。
例:各本番用データベースサーバーのCPU使用率を個別に監視する。 CPUのしきい値を超えたデータベースサーバーごとに個別のアラートが送信されるため、問題のあるインスタンスを特定して対処することができます。
エンティティごとのアラートでは、[ ] などのメトリクス関連タグや、[
metricIdmountpoint]、[ ]、[devicestate] などのカスタムタグによるグループ化が可能です。 このグループ化により、メトリックパターンやカスタムタグ付きのメトリックを使用する際、個々のメトリックバリアントごとに個別のアラートを設定できるようになります。図 4. グループ分けによるエンティティごとのアラート通知 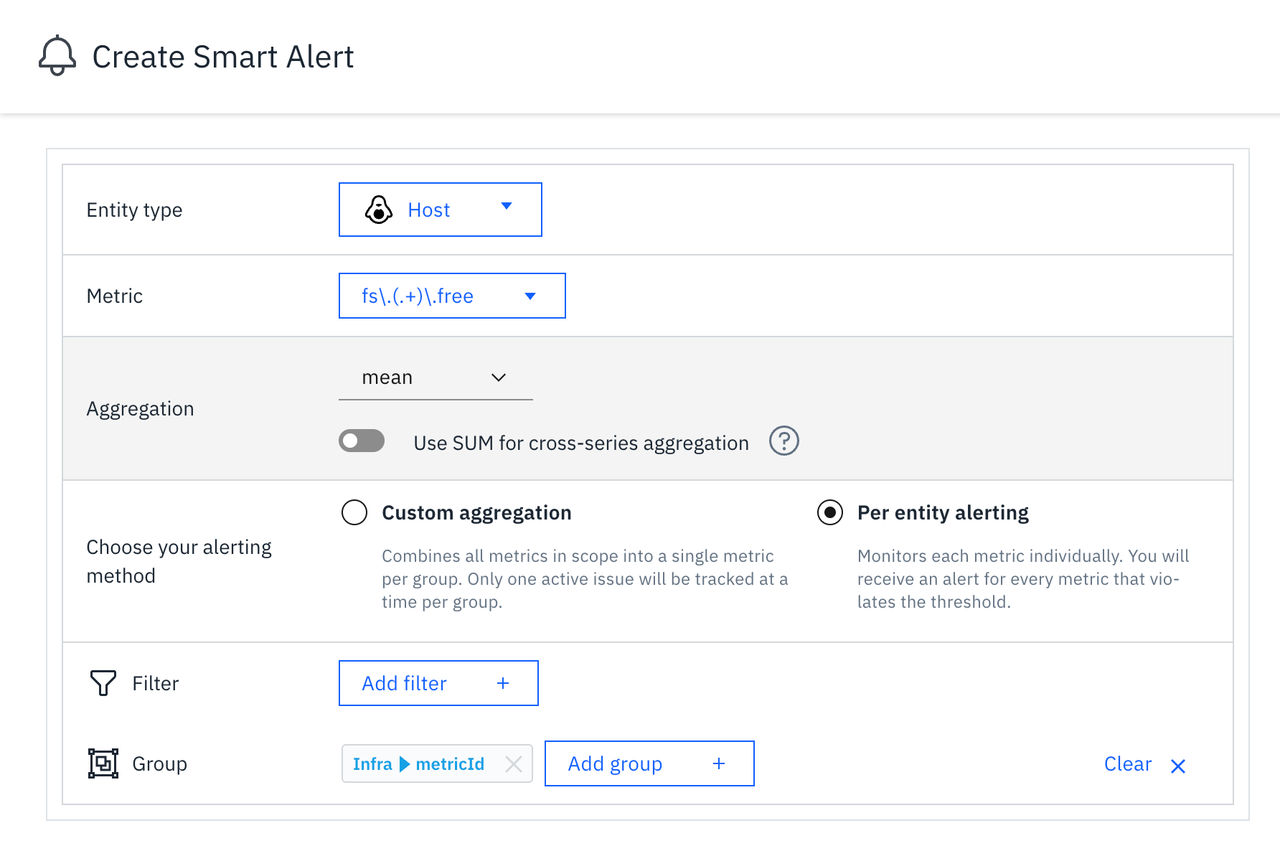
- カスタム集計 :定義した特定のカスタムタグに基づいてメトリクスデータをグループ化するには、 「カスタム集計」 をクリックします。 この方法はデフォルトで有効になっています。
さらに絞り込むには、フィルターを追加してください。
利用可能なグループ化タグを使用して、メトリクスの結果をグループ化します。 メトリックをグループ化するために最大 5 つのタグを使用できます。
閾値の設定
インフラストラクチャ用のスマートアラートを設定する際、 固定しきい値と適応型しきい値のいずれかを選択できます。
静的
静的な閾値は時間の経過とともに変化しません。 スマートアラートを作成または変更する際に設定できます。 警告と重要の深刻度には、それぞれ異なるしきい値を設定できます。 基礎となる指標が大幅に変化すると、静的な閾値はもはや適切でなくなる可能性があります。 これに対応して、いつでも手動でしきい値を調整したり、再計算したりすることができます。 しきい値演算子を選択して、しきい値条件を定義することができます。
静的閾値を使用するタイミング
静的しきい値は、次のような状況で最も効果的です:
- 対象となる指標の季節性にかかわらず、その指標は一定の値を超えたり下回ったりしてはならない。
- この指標は季節的な変動があるため、時間帯や曜日によって閾値が異なります。 ただし、これらの閾値自体は時間の経過とともに変化することはありません。 これらの閾値を長期間にわたって徐々に変更することは望ましくない。
適応
適応型しきい値は、 Instana が観測する新しいデータに応じて、継続的に変化し、調整されます。 つまり、この閾値は、人の手を介することなく、基礎となる指標の季節的な変動を常に考慮に入れるということです。 詳細については、 適応しきい値に関するドキュメントを参照してください。
適応しきい値を使用するタイミング
適応しきい値は、次のような状況で最も効果を発揮します:
- この指標には季節的な変動はありません。 この閾値は時間の経過とともに徐々に変化していくと予想されますが、この傾向から急激に逸脱することは望ましくありません。
- この指標は季節的な変動があり、時間帯や曜日によって異なる閾値が設定されています。 閾値自体は時間の経過とともに徐々に変化していくものと予想されますが、この傾向から急激に逸脱することは望ましくありません。
適応型閾値要件
適応しきい値を設定するには、少なくとも6時間分の連続したメトリックデータが必要です。 この要件が満たされていなくても、スマートアラートを作成することは可能です。 使用されるモデルの初期化に必要なデータ要件が満たされ次第、問題の検出とアラート通知が開始されます。
アラートのプレビュー
範囲と閾値を定義すると、指標に対する過去のデータに基づいてグラフが作成されます。 グラフでは、最大7日分の過去データを表示できます。 過去24時間と過去7日間の履歴データを切り替えて、メトリクスデータの推移を確認することができます。
過去のデータとしきい値条件に基づき、このグラフには現在のしきい値によって発動する可能性のあるアラートが表示されます。
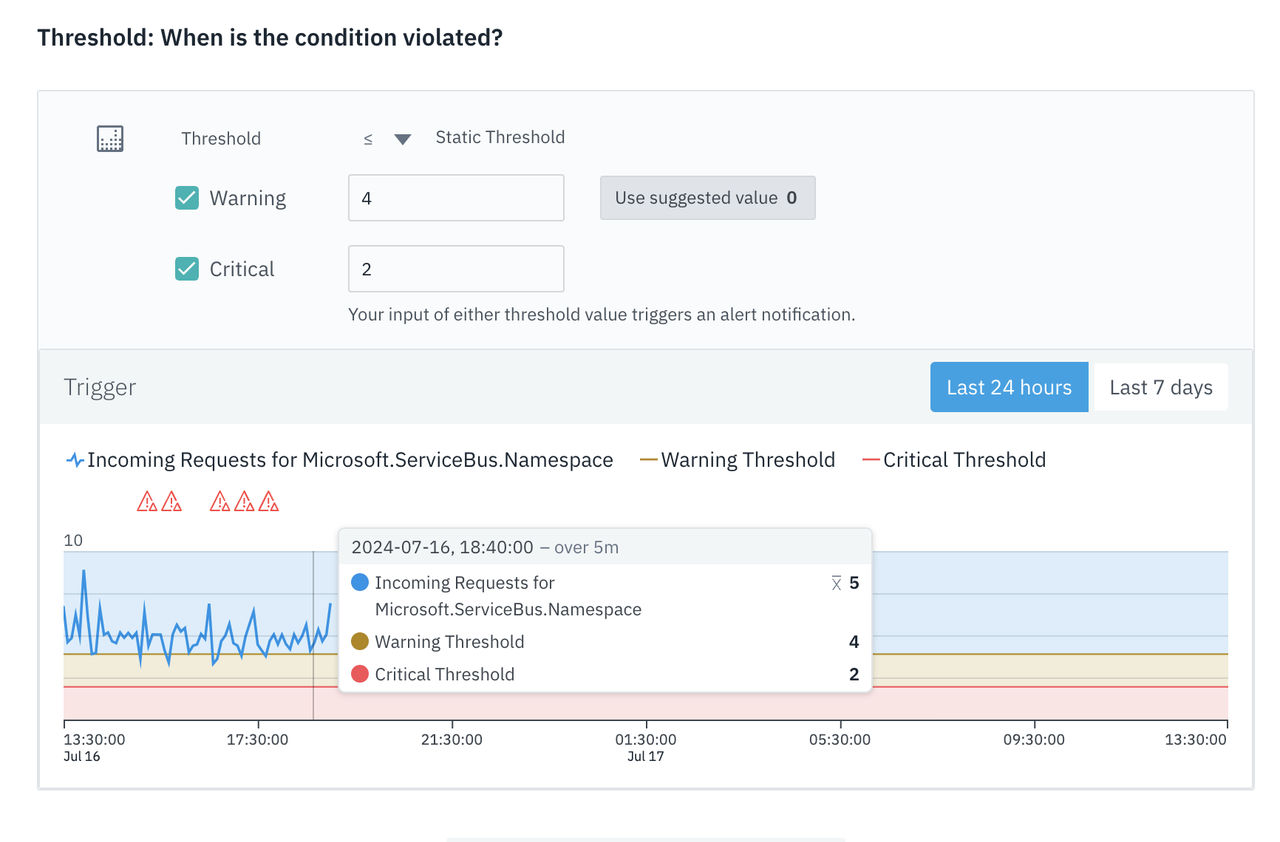
グループ化オプションを選択すると、グループ化の結果がグラフの直後に表として表示される場合があります。 各グループに対してグラフ内のメトリック・データの傾向を分析するには、表内の該当する行を選択します。
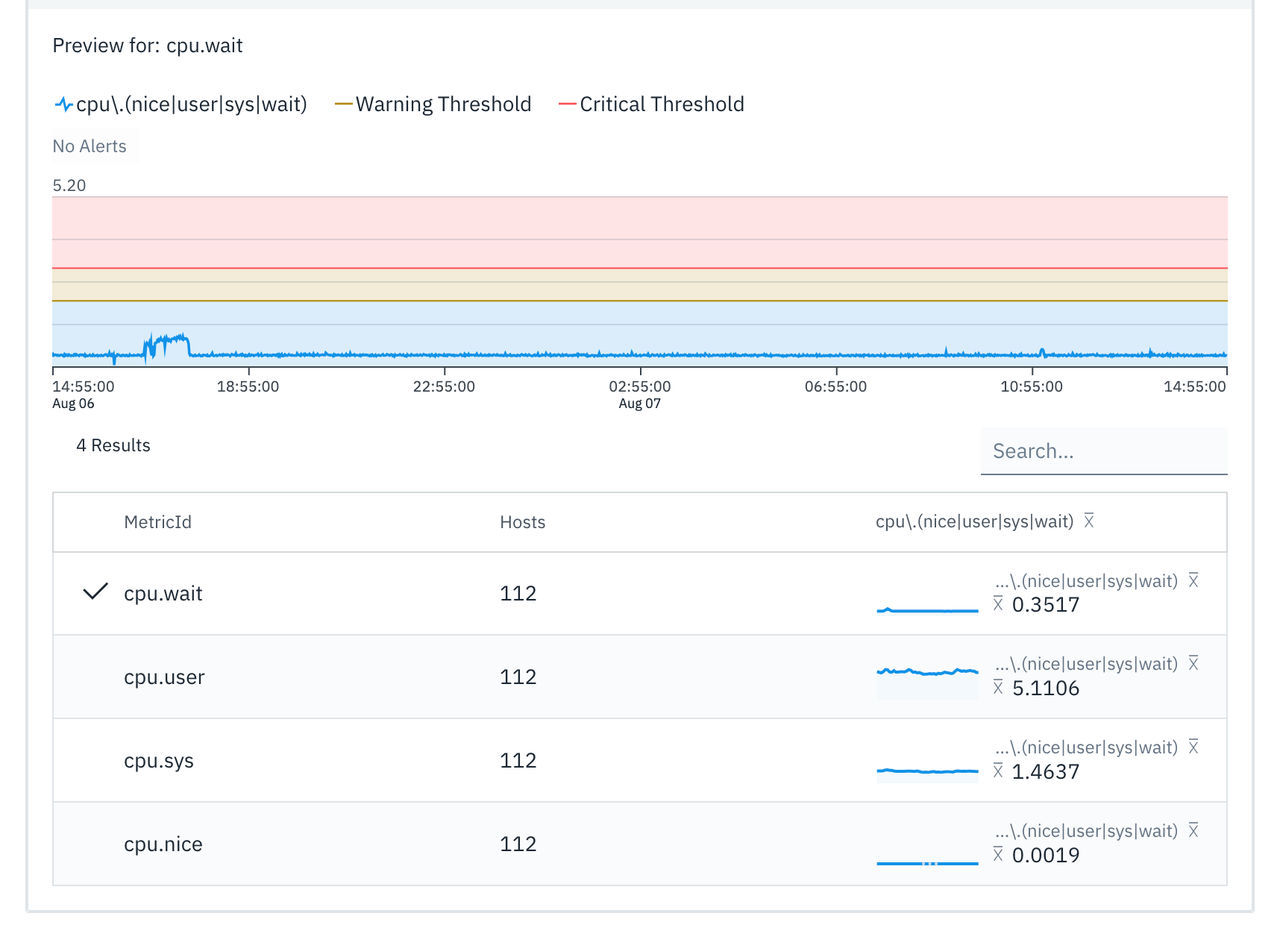
時間的閾値の設定
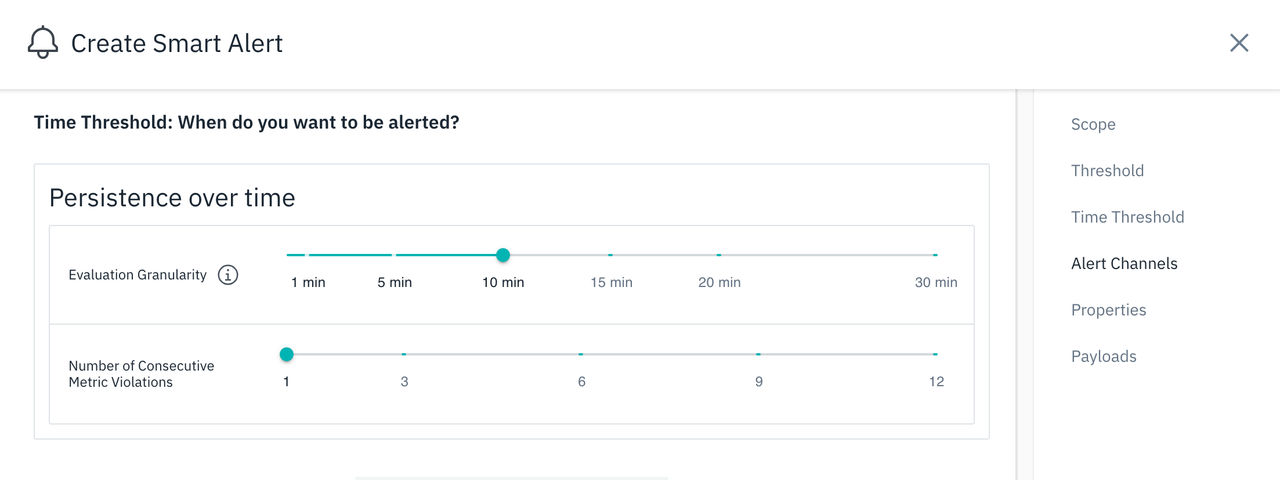
トリガーされるアラートについては、選択したメトリックに定義されているしきい値に違反した場合に、「時間しきい値」セクションにさらに条件を追加できます。
実際によく使用される以下の標準的な条件は、以下のとおりです。
- 時間の経過に伴う持続性: 時間枠と違反の連続回数を選択します。 メトリックが、定義された時間枠にわたって定義されたしきい値に違反すると、アラートを受け取ります。
オプション:予測アラート機能を利用して、事前に通知を受け取る
予測アラートを設定することで、システムに影響が出る前に潜在的な問題に対処できるよう、事前の通知を受け取ることができます。 たとえば、ディスクの容量が限界に近づいたときや、プロセスのメモリ使用量がコンテナの制限値に近づいたとき(これはメモリリークの兆候である可能性がある)に、アラートを受け取りたい場合などがあります。 Instana を使用すると、メトリクスの予測に基づいてアラートを設定できます。

予報アラート機能を選択する場合は、以下の2つの時間帯を設定してください:
- 履歴データの時間範囲 :このウィンドウでは、予測モデルの推定に使用する指標の時間範囲を指定します。 これにより、選択した指標について、短期的な傾向と長期的な傾向のどちらを重視するかを指定できます。
- 予測対象期間 :この期間には、アラート発行に使用される線形予測の時間枠を指定します。 予測される時間が長くなるほど、誤警報が発生する可能性が高まります。
次の図は、2つの指標の例について、これらの時間枠と、アラート設定が異なる場合の線形予測を示しています:

メトリクスの値または予測値のいずれかが、設定されたルールに基づく閾値を超えた場合、アラートがトリガーされます。
アラートチャネルの追加
「Smart Alerts for Infrastructure」では、深刻度ごとに異なるアラート配信先を設定できます。 アラートチャネルを追加するには、以下の手順に従ってください:
- 「アラート・チャネルの選択」をクリックします。
- 事前構成されたチャネルのリストから、アラートの受信元のチャネルを選択します。
警告および重大な深刻度に対して閾値が設定されている場合、各深刻度ごとにアラートチャネルを設定できます。 両方の深刻度に対してしきい値が設定されている場合、警告の深刻度については、デフォルトですべてのアラートチャネルが選択されます。
両方の重大度レベルが設定されているアラートチャネル:
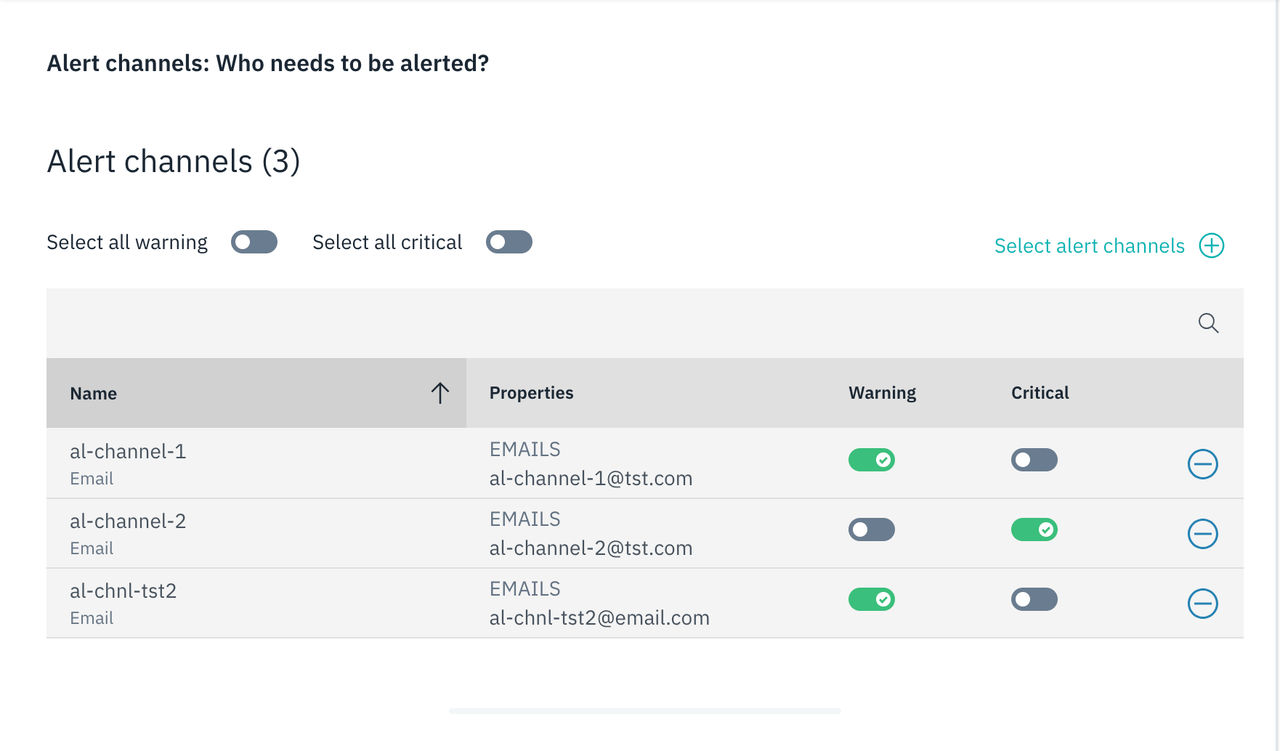
ある重大度に対してのみ閾値が設定されている場合、その重大度はすべてのアラートチャネルにおいてアラートレベルとして表示されます。
1つの深刻度が設定されているアラートチャネル:
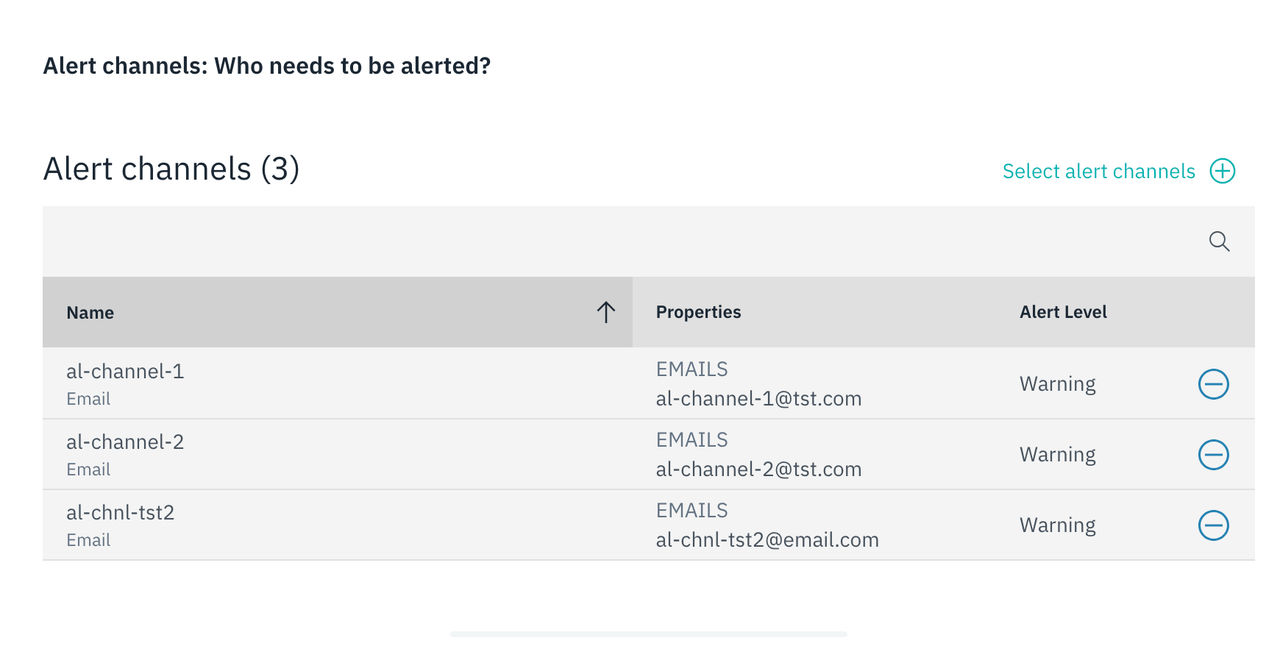
チャンネルの作成に関する詳細については、 「アラート・チャンネル」 を参照してください。
アラートのプロパティの選択
このセクションでは、必要に応じて、スマートアラート設定を使用して作成されたアラートに関連するさまざまなプロパティを設定できます。

役職
Instana 選択されたエンティティタイプとメトリクスに基づいて、デフォルトのタイトルを提案します。 ただし、このタイトルを独自の静的テキストで上書きしたり、プレースホルダーを挿入して動的なタイトルを使用したりすることも可能です。
「プレースホルダーの挿入」 ドロップダウンから、アラートのタイトルに動的なプレースホルダーを挿入できます。 これらのプレースホルダーは、アラートがトリガーされた際に、その文脈をより明確に把握するのに役立ちます。
- タイトルに
${severity}プレースホルダーを含めることができるようになりました。 このプレースホルダーは、1つのアラート内で複数の重大度レベルを設定する場合に便利です。 たとえば、「」のようなタイトルは、アラートのHigh CPU Usage - ${severity}タイトルに直接深刻度レベルを示しています。 - 利用可能なプレースホルダーは、選択した通知方法によって異なります:
- カスタム集計機能を使用すると、タグによるグループ化(
zone)を行い、そのグループ化されたタグをプレースホルダーとして使用できます(${zone})。このプレースホルダーは、 「プレースホルダーの挿入」 ドロップダウンから利用可能になりました。 - エンティティごとのアラートを設定する際、この
${entity.label}プレースホルダーを使用できます。 このプレースホルダーは、アラートをトリガーした具体的なエンティティを特定します。 - 正規表現のキャプチャグループ (例:
fs\.(.+)\.free)を含むメトリックパターンを使用する場合、キャプチャされた値をタイトル内のプレースホルダーとして含めることができます。 「 プレースホルダーの挿入 」メニューには、次のような項目が含まれています:Regex 1st capturing groupパターンの最初のキャプチャグループに対してRegex 2nd capturing group、Regex 3rd capturing group、など、その他の捕捉群
これらのプレースホルダーを使用すると、一致したメトリック名の一部をアラートのタイトルに動的に組み込むことができます。
- カスタム集計機能を使用すると、タグによるグループ化(
インシデントのトリガー
アラートが発生した際に自動的にインシデントをトリガーするには、このトグルを使用してください。 このアラートは、インシデントの発生原因として記録されます。 このインシデントには関連する事象が含まれており、推奨される対応策が示されています。
説明
必要に応じて、アラートの説明を追加してください。 この説明文では、アラートの目的を要約し、調査や解決に向けた推奨される手順を概説しています。
説明文に動的なプレースホルダーを挿入できるようになりました。 「 プレースホルダーの挿入 」ドロップダウンを使用して、アラートがトリガーされた際に状況情報を提供するプレースホルダーを追加します。

カスタムペイロードの追加
Instana から送信される特定のアラート設定のアラート通知に、関連するペイロードを追加するには、 「カスタムペイロード 」セクションの 「行を追加」 をクリックします。
該当する場合、アラート通知にはグローバルなカスタムペイロードとアラート固有のカスタムペイロードの両方が含まれますが、アラート固有の設定がグローバルな設定よりも優先されます。 その結果、同じキーを使用すると、グローバル・カスタム・ペイロード・フィールドの値がアラート固有の値によってオーバーライドされます。
以下のイメージは、アラート構成で使用される、グローバルに定義されたカスタム・ペイロードを示しています。
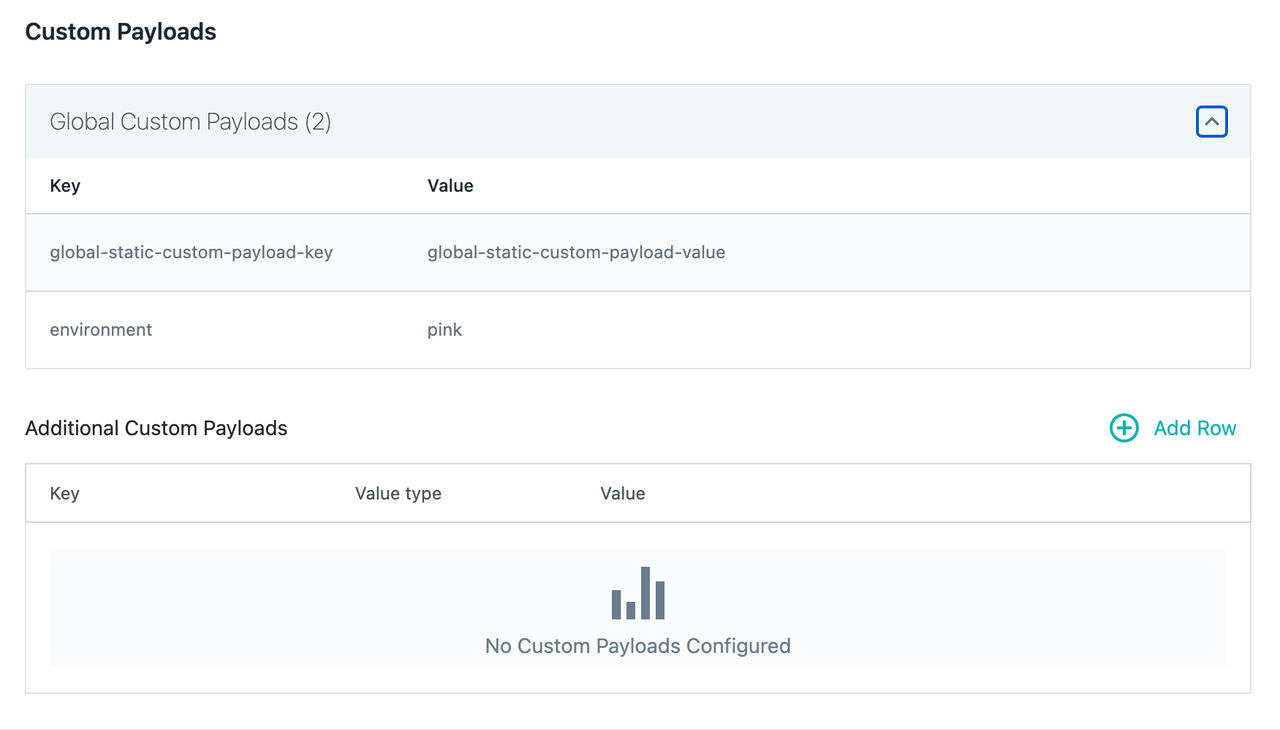
グローバルなカスタムペイロードに関する詳細については、 「カスタムペイロードのグローバル設定」 を参照してください。
現時点では、パブリックプレビュー版では動的なグローバルカスタムペイロードはサポートされていません。
Terraform のサポート
Instana インフラストラクチャ・アズ・コード( IaC )機能を実現し、インフラストラクチャのスマートアラートをプログラムで管理するための Terraform リソースを提供します。 この機能により、 DevOps およびSREチームは、アラート設定をコードとして定義、デプロイ、および維持管理することができます。 これにより、環境間の自動化と一貫性が向上します。
Terraform を使用したインフラストラクチャのスマートアラートの管理に関する詳細については、 Instana のインフラストラクチャアラート設定に関するドキュメントを参照してください。
FAQ
インフラメトリクスのカスタムイベントをSmart Alertsに移行する理由は何ですか?
- メトリックパターンや正規表現のサポートにより、メトリックの選択がより柔軟になりました。
- 深刻度に基づくルーティングによるアラートチャネルの直接割り当て。
- グループ化および集計機能の強化。
- 予防的な監視のための予測アラート。
- アラートのタイトルと説明文における動的なプレースホルダー。
- 過去のデータに基づいてアラート設定を行う際のプレビュー。
カスタムイベントをスマートアラートに移行する方法
- 複数のメトリクスを含むカスタムイベント :移行できるのは、単一のメトリクスを持つカスタムイベントのみです。
- 集計タイプ :以下の集計を使用するカスタムイベントは移行できません:
- 相対差
- 絶対差
- システムルール :以下の組み込みシステムルールは、インフラストラクチャのスマートアラートに移行することはできません:
- オフライン・イベントの検出
- 対応するエンティティが実行されていないホスト
- ホスト可用性の検出
- 予期せぬ数のエンティティが実行されているホスト
半自動移行
- 「移行済み」としてマークする :非推奨のカスタムイベントを「移行済み」としてマークし、無効にします。 カスタムイベントを手動でスマートアラートに移行する場合は、このオプションを選択してください。 カスタムイベントを「移行済み」としてマークした後も、リスト上でそのイベントを表示し、参照用に設定内容を確認することができます。 この機能は、移行の進捗状況を把握するのに役立ち、カスタムイベントが重複して移行されるのを防ぎます。
- 「Smart Alert」へ移行 :カスタムイベントから事前に入力された値を含む「Smart Alert」ダイアログを開きます。 これらの値には、名前、説明、重大度、インシデントフラグ、メトリクス、評価の粒度、集計方法、オペレーター、およびしきい値などが含まれます。 Instana これらのフィールドを、可能な限り移行しようと試みます。 カスタムイベントの動的フォーカスクエリ(DFQ)で定義された範囲、または選択されたエンティティは、それぞれのエンティティを選択するか、タグフィルターを使用することで引き継がれます。 DFQを完全にマッピングできない場合、警告メッセージが表示され、その後、手動で範囲を調整することができます。 「スマートアラート」を保存すると、以前のカスタムイベントは自動的に無効化され、「移行済み」としてマークされます。
手動マイグレーション
- メトリクスのマッピング :移行の際は、インフラストラクチャのSmart Alert設定で、対応するメトリクスを選択するようにしてください。 メトリック一覧または正規表現によるパターン一致を利用して、適切なメトリックを特定してください。
- 適用範囲と対象の選択 :Infrastructure Smart Alerts では、Dynamic Focus Queries の代わりにタグベースのフィルタリングを使用します。 カスタムイベントの範囲を再現するには:
- カスタムイベントの対象となるエンティティを特定します。
- スマートアラートの設定にある「 フィルターを追加」 オプションを使用して、同等のタグフィルターを適用してください。
- 「 カスタム集計 」(エンティティ横断的なメトリクスの集計用)と「 エンティティごとのアラート」 (個々のエンティティの監視用)のいずれかを選択してください。
- 集計マッピング :カスタムイベントの集計タイプを、Smart Alerts の対応するオプションにマッピングします:
- 時間集計 :時間軸ごとの集計方法(例:平均、最小、最大、合計)を選択します。
- シリーズ間の集計 :複数のエンティティにわたって合計を算出したい場合は、「シリーズ間の集計にSUMを使用する」 を有効にしてください。
- しきい値の調整 :しきい値を移行する際は、以下の点に留意してください
- メトリクスの粒度の違い :カスタムイベントとインフラストラクチャのスマートアラートでは、基盤となるメトリクスのロールアップが異なります:
- カスタムイベントでは、30分未満の時間枠については1秒ごとのメトリクスストリームを使用し、30分以上の時間枠については5秒ごとの集計値(1秒ごとのメトリクスの平均値)を使用します。 この集計は、これらの値のスライディングウィンドウに対して適用されます。
- インフラストラクチャ・スマートアラートでは、10秒ごとの集計値(1秒ごとのメトリクスから算出した平均値)を用いた評価サイクルを採用しています。 各評価サイクルでは、これらの10秒ごとの集計データに基づいて、時間軸をまたいだ集計(およびオプションで系列をまたいだ集計)が行われます。
- 新しい評価の粒度と集計タイプに基づいて、しきい値を調整してください。
- プレビューチャートを使用して、閾値が過去のデータに対して想定どおりにアラートをトリガーするかどうかを確認してください。
SUM集計の例 : ActiveMQ エンティティのカスタムイベントで、SUM集計を使用し、1分間の時間ウィンドウで秒間100メッセージというしきい値が設定されている場合、Smart AlertでSUM集計を使用し、評価粒度を5分間としているときは、しきい値を30,000メッセージ(100 × 60 × 5)に調整してください。
MEAN集計の例 :カスタムイベントでMEAN(平均)集計を使用し、しきい値を1秒あたり100メッセージに設定している場合、スマートアラートでもMEAN集計を使用すると、しきい値はほぼ同じまま(1秒あたり100メッセージ、または10秒ごとの集計で約1,000メッセージ)となります。これは、平均値が単純に合計されるのではなく、評価ウィンドウ全体で計算されるためです。
主な違いは、SUM集計ではしきい値を評価ウィンドウの期間に応じて調整する必要がありますが、MEAN、MIN、MAX集計では通常、しきい値の調整は必要ないという点です。
- メトリクスの粒度の違い :カスタムイベントとインフラストラクチャのスマートアラートでは、基盤となるメトリクスのロールアップが異なります:
- 時間閾値のマッピング :カスタムイベントの猶予期間と時間枠を、スマートアラートの時間閾値オプションにマッピングします:
- 「時間の経過に伴う持続性」 を使用して、アラートを発する前に連続した違反が発生することを条件とする。
- Smart Alerts の評価粒度は、カスタムイベントの 1 秒単位の粒度と比較してより安定した指標を提供するため、長期間の猶予期間を設ける必要性が低くなります。
- アラートチャネルの割り当て :ルーティングにアラート設定に依存するカスタムイベントとは異なり、インフラストラクチャのスマートアラートでは、重大度に基づくルーティングとともにアラートチャネルを直接割り当てることができます。 必要に応じて、警告および重大な深刻度に対して適切なチャネルを割り当ててください。
「カスタム集計」と「エンティティごとのアラート」の違いは何ですか?
カスタム集計グループは、ユーザーが定義したタグに基づいてメトリクスデータを集計し、集計されたメトリクスをしきい値と比較して評価します。 このアプローチは、複数のエンティティにわたる全体的な傾向を監視し、アラートのノイズを減らすのに役立ちます。 集計されたメトリクスがしきい値を超えた場合、1回のアラートが送信されます。
エンティティごとのアラート機能は、 各エンティティを個別に監視し、しきい値を超えたエンティティごとに個別のアラートを発動します。 このアプローチは、特定のエンティティに関する問題を特定し、対応する必要がある場合に役立ちます。 影響を受ける各エンティティについて、個別の通知が届きます。
集計された挙動(カスタム集計)を監視するか、個々のエンティティの挙動(エンティティごとのアラート)を監視するかによって、アラート通知方法を選択してください。
インフラストラクチャのスマートアラートにおける予測アラートはどのように機能しますか?
- 過去データの時間範囲 :予測モデルを推定するために使用する過去データの期間を指定します。
- 予測期間 :予測の対象となる将来の期間を指定します。
現在のメトリクス値または予測値のいずれかがしきい値を超えた場合、アラートがトリガーされます。 この予防的なアプローチにより、ディスク容量の不足や、コンテナの制限値に近づくメモリリークなど、システムに影響を及ぼす前に潜在的な問題に対処することができます。
予測時間枠を長くすると誤検知の可能性が高まるため、具体的な利用状況に応じて、積極的なアラート通知とアラートの精度とのバランスを考慮してください。