New release of Hortonworks Data Platform is now available from IBM
HDP 3.0 delivers new capabilities for the enterprise to enable agile application deployment, new machine learning/deep learning workloads, real-time database, & security and governance. It is a key component of the modern data architecture and can be deployed both on-premises and the cloud. Many of the new enhancements to HDP 3.0 are based on Apache Hadoop 3.1 and include containerization, GPU support, erasure coding and namenode federation.
The new FASTER, SMARTER, HYBRID platform has a lot of innovation and improved usability to make it more enterprise-ready and secure for our customers. . Read more here: HDP 3.0 announcement
New release of Hortonworks DataFlow is now available from IBM
Hortonworks DataFlow (HDF) is a scalable, real-time streaming analytics platform that ingests, curates and analyzes data for key insights and immediate actionable intelligence. Build complex data pipelines with minimal effort with a simple visual user interface for building sophisticated data flows to accomplish major data ingestions, transformations and enrichment from a variety of streaming sources. Powered by Apache NiFi, HDF can ingest data from a range of data sources—devices, enterprise applications, partner systems or edge applications generating real-time streaming data.
Moreover, it has the building blocks for an organization to move towards becoming an AI organization. This offering comes as an extension to the successful partnership between IBM and Hortonworks which focusses on enabling clients into becoming data driven organizations. Read more here: HDF 3.2 announcement
Did you know… Bloor Research identified IBM Db2 Big SQL as a leader among SQL Engines on Hadoop
Bloor Research released a Market Report paper on SQL Engines on Hadoop. It compares a myriad of SQL engines on Hadoop and based on use cases, has placed Db2 Big SQL as a leader in Hadoop use cases, performance and SQL support.
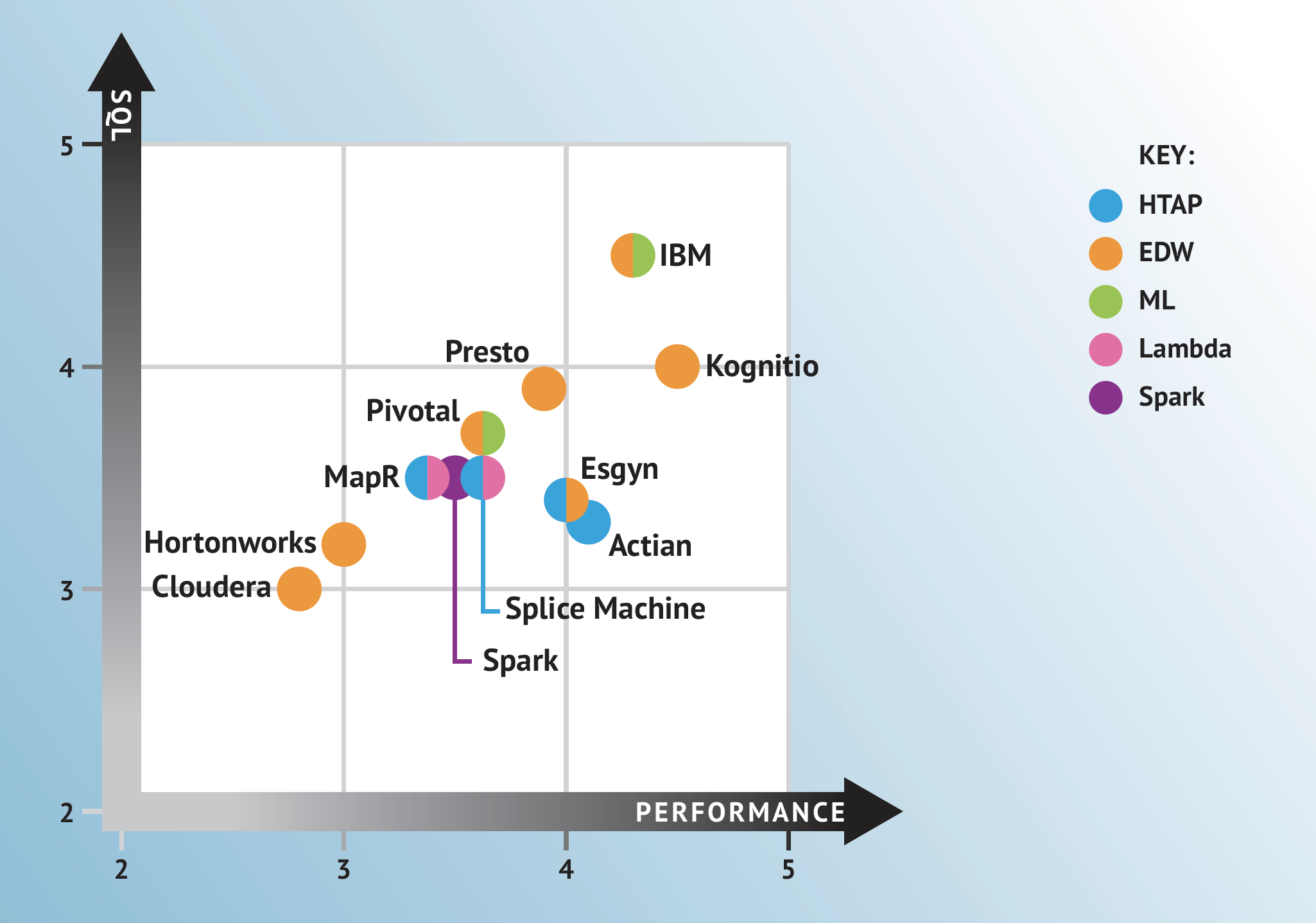
Hadoop is part of every enterprises’ data management platform for various needs. One major need is the ability to execute SQL on Hadoop data. As most applications for business intelligence and analytics are in SQL, and SQL skills are ubiquitous in any analytics department, it is imperative to have solutions that support high level of SQL compliance and performance.
Bloor Research evaluates many SQL engines on Hadoop and boils down the key differentiating capabilities of these engines in 3 categories, they are: use cases it supports, level of SQL support and performance. The SQL engine that leads in those categories is IBM Db2 Big SQL.
Quotes:
The key differentiators between products are the use cases they support, their performance, and the level of SQL they offer.
The level of support for ANSI standard SQL varies widely. IBM – not just in Big SQL and Db2, but across its product range – is much the most advanced vendor in this respect.
Db2 Big SQL as the name suggests, is an advanced SQL engine that brings the power of Db2 to Hadoop. It has the most advanced ANSI standard SQL implementation. And includes SQL compatibility with Oracle PL/SQL (over 95%). The true strength of Db2 Big SQL is its inherit capability of executing complex analytics serving many concurrent users.
Adding to the core capabilities of Db2, Db2 Big SQL also brings the ability to query both Hive and HBase tables in a single query, and the ability to extend the warehouse environment to machine learning with its bi-directional integration with Spark. One key differentiator is its ability to query disparate data sources in a single query using its enterprise federation capabilities.
Get the free report here: https://www.bloorresearch.com/sql-engines-on-hadoop-free/
| More Resources: More information on IBM Db2 Big SQL + Try the New IBM Big SQL Sandbox: IBM Db2 Big SQL webpage More information on Hadoop: IBM Hadoop webpage Explore technical topics and join the community: Hadoop and Big SQL Community Find answers quickly: IBM Db2 Big SQL Knowledge Center and IBM Big Replicate Knowledge Center Provide feedback and product improvement ideas: Ideas Portal (Choose Component: Db2 Big SQL, BigReplicate) Communicate with the IBM Db2 Big SQL Offering Team: bigsql@us.ibm.com Keep up to date with IBM Db2 Big SQL news and announcements: Twitter: @Db2BigSQL |