Fix Readme
Abstract
IBM Data Replication blog entries from 2019 and earlier.
Content
Open your doors to Open Source Database Management Systems with IBM Data Replication support for log based captures from PostgreSQL
Blog By: Davendra Paltoo, Offering Manager, IBM Data Replication
Every business today revolves around data. Conversations with our customers frequently confirm the following:
- Organizations need real time access to the latest data to improve organizations’ customer experiences and also to make timely business decisions. Continuous Intelligence requires nothing but the real-time availability of data. Gartner predicts that by 2022, more than half of major new business systems will incorporate continuous intelligence that uses real-time context data to improve decisions. Moreover, Gartner also predicts that augmented analytics that uses machine learning and AI techniques will transform how analytics content is developed, consumed and shared.
- Our users continue to experience challenges with making data easier to access and use especially when organizations have multiple databases for multiple purposes and often when organizations have some data on premise and some in the cloud. Moreover, with open source database management systems “OSDBMS” growing in popularity due to lower expected costs and improving quality1 , Gartner forecasts that “By 2022, more than 70% of new in-house applications will be developed on an OSDBMS, and 50% of existing commercial RDBMS instances will have been converted or will be in process of converting.”2
Organizations are looking cost effective solutions to the above challenges.
IBM Data Replication “IDR” can help by providing up to the second replicas of changing data where and when needed keeping data synchronized with low latency. Our users are replicating operational data from most of the world’s popular relational databases like Oracle and Db2 z/OS to everything from a traditional data warehouses to a data appliance such as Pure Data Analytics or IBM Integrated Analytics System, to a Big Data cluster driven by Apache Kafka and Hadoop, or even to a Cloud based On Line Analytical Processing (OLAP) environment such Db2 Warehouse on Cloud.
Understanding the adoption patterns around OSDBMS, for some time, IBM Data Replication has provided users the ability to feed data INTO PostgreSQL while sourcing from a wide variety of source DBMS by employing low impact database log based captures.
With Db Engines currently indicating that PostgreSQL is currently the fourth most popular database in the world, leveraging PostgreSQL around the enterprise just got easier. IBM Data Replication now supports PostgreSQL as a SOURCE3 in a recent deliverable.
The IDR CDC PostgreSQL capture interoperates, out of the box, with the extensive array of target platforms supported by CDC. This includes most major DBMSs, Kafka, Hadoop, files, messaging systems and more.
PostgreSQL as a source released in an IDR 11.4 Fixpack with support for both PostgreSQL Enterprise and community editions provided they meet the published system requirements . Note that users with sufficient license entitlement of either IBM Data Replication or IBM InfoSphere Data Replication can deploy the new PostgreSQL capture with no additional purchase. If in doubt, please check with your IBM account representative.
Click here for a table of contents linking to more details about IBM’s CDC technology for capturing PostgreSQL database changes and replicating them across the data center or around the world.
1 https://opensource.com/life/15/12/why-open-source
2 https://www.exist.com/blog/the-future-is-open-edb-postgres-and-your-enterprise-data/)
Why is my CDC so slow on my PDA?
I hear a lot of feedback on the use of CDC to put data into a PureData for Analytics, Powered By Netezza Technology device. In the other machines (traditional database engines) the data flies into the box, the CDC is on-and-off the machine in seconds. But in my Netezza machine, the CDC seems to grind. I have it running every fifteen minutes, they say, and the prior CDC instance is still running when the next instance kicks off. This is totally unacceptable. Maybe we shouldn't be using CDC for this?
Or maybe they just don't have it configured correctly?
There are two major PDA principles in play here. One is strategic and the other is tactical. Many people can look at the tactical principle and accept it because it is testable, repeatable and measurable. The strategic one however, they will hold their judgment on because it does not fit their paradigm of what a database should do. I'll save the strategic one for last, because its implications are further reaching.
The CDC operation will accumulate records into a cache and then apply these at the designated time interval. This micro-batch scenario fits Netezza databases well. The secondary part of this is that the actual operation will include a delete/insert combination to cover all deletes, updates and inserts. So when the operation is complete, the contents of the Netezza table will be identical to the contents of the source table at that point in time (even though we expect some latency, that's okay).
The critical piece is this: An update operation on a Netezza table is under-the-covers a full-record-delete and full-record-insert. It does not update the record in place. A delete operation is just a subset of this combination. This is why the CDC's delete/insert combination is able to perfectly handle all deletes, updates and inserts. The missing understanding however, is the distribution key.
If we have a body of records that we need to perform a delete operation with against another, larger table, and the larger table is distributed on RANDOM, think about what the delete operation must do in a mechanical sense. It must take every record in the body of incoming records and ship it to every SPU so that the data is visible to all dataslices. It must do this because the data is random and it cannot know where to find a given record to apply the operation - it could literally be anywhere and if the record is not unique, could exist on every dataslice. It's random after all. This causes a delete operation (and by corollary an update operation) to grind as it attempts to locate its targets.
Contrast this to a table that is distributed on a key, and we actually use the key in the delete operation (such as a primary key). The incoming body of records is divided by key, and only that key's worth of data is shipped to the dataslice sharing that key - the operation is lightning-fast. This is why we say - never, ever perform a delete or update on a random table, or on a table that doesn't share the distribution key of the data we intend to affect. Deletes and Updates must be configured to co-locate, or they will grind.
Now back to the CDC operation. Whenever I hear that the CDC operation is grinding, my first question is: Do you have the target Netezza tables distributed on the same primary keys of the source table? The answer is invariably no (we will discover why in a moment). So then I ask them, what would it take to get the tables distributed on the primary key? How much effort would it be? And they invariably answer, well, not much, but it would break our solution.
Why is that?
Because they are reporting from the same tables that the CDC is affecting. And when reporting from these tables, the distribution key has to face the way the reporting users will use the tables, not the way CDC is using the tables. This conversation often closes with a "thank you very much" because now they understand the problem and see it as a shortcoming of Netezza or CDC, but not a shortcoming of how they have implemented the solution.
Which brings us to the strategic principle: There is no such thing as a general purpose database in Netezza.
What are we witnessing here? The CDC is writing to tables that should be configured and optimized for its use. They are not so, because the reporting users want them configured and optimized for their own use. They are using the same database for two purposes because they are steeped in the "normalization" protocol prevalent in general-purpose systems - that the databases should be multi-use or general-purpose.
But is this really true in the traditional databases? If we were using Oracle, DB2, SQLServer - to get better performance out of the data model wouldn't we reconfigure it into a star schema and aggressively index the most active tables? This moves away from the transactional flavor of the original tables to a strongly purpose-built flavor.
Why is it that we think this model is to be ignored when moving to Netezza? Oddly, Netezza is a Data Warehouse Appliance - it was designed to circunscribe and simplify the most prevalent practices of data warehousing - not the least of which - is the principle that there is no such thing as a general-purpose database. In a traditional engine we would never attempt to use transactional tables for reporting - they are too slow for set-based operations and deep-analytics. Yet over here in the Netezza machine, somehow this principle is either set-aside or ignored - or perhaps the solution implementors are unaware of it - and so these seemingly inexplicable grinding mysteries arise and people scratch their heads and wonder what's wrong with the machine.
And again, they never wonder what's wrong with their solution.
If we take a step back, what we will see are reports that leverage the CDC-based tables, but we will see a common theme, which I will cover in a part-2 of this article. The theme is one of "re integration" versus "pre-integration". That is, integration-on-demand rather than data that is pre-configured and pre-formulated into consumption-ready formats. What is a symptom of this? How about a proliferation of views that snap-together five or more tables with a prevalence of left-outer-joins? Or a prevalence of nested views (five, ten, fifteen levels deep) that attempt to reconfigure data on-demand (rather than pre-configure data for an integrate-once-consume-many approach?) Think also about the type of solution that performs real-time fetches from source systems, integrates the data on-the-fly and presents it to the user - this is another type of integration-on-demand that can radically debilitate source systems as they are hit-and-re-hit for the very same set-based extracts dozens or hundreds of times in a day.
I'll take a deep-dive on integration-on-demand in the next installment, but for now think about what our CDC-based solution has enticed us to do: We have now reconfigured the tables with a new distribution key that helps the reports run faster, but because this deviates from the primary-key design of the source tables (which CDC operates against) then the CDC operation will grind. And when it grinds, it will consume precious resources like the inter-SPU network fabric. The grinding isn't just a duration issue - it's inappropriately using resources that would otherwise be available to the reporting users.
What's missing here is a simple step after the CDC completes. Its a really simple step. It will cause the average "purist" data modeler and DBA to retch their lunch when they hear of it. It will cause the admins of "traditional" engines to look askance at the Netezza machine and wonder what they could have been thinking when they purchased it. But the ultimate users of the system, when they see the subsecond response of the reports and way their queries return in lightning fashion compared to the tens-of-minutes, or even hours - of the prior solution, these same DBAs, admins and modelers will want to embrace the mystery.
The mystery here is "scale". When dealing with tables that have tens of billions, or hundreds of billions of records, the standard purist protocols that rigorously and faithfully protect capacity in the traditionl engines - actually sacrifice capacity and performance in the Netezza engine. It's not that we want to set aside those protocols. We just want to adapt them for purposes of scale.
The "next step" we have to take is to formulate data structures that align with how the reporting users intend to query the data, then use the CDC data to fill them. It's not that the CDC product can do this for you. It gets the data to the box. This "next step" in the process is simply forwarding the CDC data to these newly formulated tables. When this happens, the pre-integration and pre-calculation opportunities are upon us, and we can use them to reduce the total workload of the on-demand query by including the pre-integration and pre-calculation into the new target tables. These tables are then consumption-ready, have far fewer joins (and the need for left-outer joins often fall by the way-side). After all, why perform the left-outer operations on-demand if we can perform them once, use Netezza's massively parallel power for it, and then when the users ask a question, the data they want is pre-formulated rather than re-formulated on demand.
This necessarily means we need to regard our databases in terms of "roles". Each role has a purpose - and we deliberately embrace the notion of purpose-built schemas, and deliver our solution from the enslavement of a general-purpose model. The CDC-facing tables with support CDC - we won't report from them. The reporting tables face the user - we won't CDC to them.
Keep in mind that this problem (of CDC to Netezza) can rear its head with other approaches also - such as streaming data with a replicator or ETL tool to simulate the same effect of CDC. Either way, the data arrives in the Netezza machine looking a lot like the source structures and aren't consumption-ready.
I worked with a group some years ago with a CDC-like solution, and they took the "next step" to heart, formulated a set of target tables that were separate from staging and then used an ETL tool to fill them. The protocol was simply this: The ETL tool sources the data and fills the staging tables, then the ETL sources the staging tables and fills the target tables. This provided the necessary separation, so functionally fulfilled the mission. The problem with the solution however, was that for the transformation leg, the ETL tool was yanking the data from the machine into the ETL tool's domain, reformulating it and then pushing it back onto the machine. The data actually met itself coming-and-going over the network. A fully parallelized table was being serialized, crunched and then re-paralellized into the machine. As the data grew, this operation became slower and slower. That's what we would expect right? The bottleneck now is the ETL tool. The proper way to do this, if an ETL tool must be involved, is to leverage it to send SQL statements to the machine, keep the data inside the box. The Netezza architecture can process data internally far faster than any ETL tool could ever hope - so why take it out and incur the additional penalty of network transportation?
The ETL tool aficionados will balk at such a suggestion because it is such a strong deviation from their paradigm. But this is why Netezza is a change-agent. It requires things that traditional engines do not because it solves problems in scales that traditional engines cannot. In fact, performing such transformations inside a traditional engine would be a very bad idea. The ETL tools are all configured and optimized to handle transformation one way - outside the box. This is because it is a general-purpose tool and works well with general-purpose engines. There is a theme here: the phrase "general purpose" has limited viability inside the Netezza machine. If we embrace this reality with a full head of steam, the Netezza technology can provide all of our users with a breathtaking experience and we will have a scalable and extensible back-end solution.
Share mission critical Db2 z/OS data with new environments for analytics, integration and cloud projects while reducing operating costs with IBM Data Replication
Blog Post by : Davendra Paltoo, Offering Manager IBM Data Replication
A Data Integration and Integrity(DII) End User Survey 2017 (Doc #US42074117, March 2018)
[1] was conducted by IDC in November 2017. It was aimed at end-users of DII software to help identify trends. It was reported that keeping data synchronized among applications is and will be the most prevalent use case for data integration.See the chart below for trends:

We know that much mission critical data is managed, captured and stored in IBM’s DB2 on z/OS and there is often a need to share this data into new environments for analytics and integration projects whether it is for feeding a data lake, sharing data with cloud based applications or for detecting events in near real time for compliance or using this data for real time business insights.
Sharing such data gives rise to a number of challenges including the incremental mainframe operating costs of running “data capture” tools on System Z, the costs associated with staffing data integration projects with the right skills and expertise, and the time associated with making such projects successful. To compound these challenges, an increasing number of projects demand up-to-the-second, and easier and faster access to the enterprise data that resides in Db2 for z/OS.
For users interested in a “custom code free”, proven and easy to deploy solution for near real time replication in support of the aforementioned analytics or integration projects, IBM Data Replication today provides a comprehensive solution for dynamic integration of z/OS transactional data, via near-real time, incremental delivery of transactional relational data captured from database logs to a broad spectrum of database and big data targets including Kafka and Hadoop. Read this solution brief to learn more.
Moreover, in a recent release, IBM has introduced a new Remote Capture source engine for Db2 for z/OS sources that can be deployed remotely from the mainframe. To help customers reduce mainframe operating costs, the remote capture could help organizations reduce the z/OS MIPS needed to replicate their Db2 Z data to other platforms all while experiencing the benefits of IBM’s real time log-based data replication.
The new remote Db2 z/OS source capture is also expected to reduce the need for organizations to be dependent on specialized System Z skills for deploying, configuring and monitoring IBM Data Replication.
For more information, please see our knowledge center announcement here.
Improve flexibility when synchronizing data from Microsoft SQL Server across your enterprise with IBM Data Replication
Blog By: Davendra Paltoo, Offering Manager , IBM Data Replication
Every business today revolves around data. As I meet customers, the conversations confirm that the following needs are often present:
-
Real time access to the latest data to improve organizations’ customer experiences and also to make timely business decisions
-
Make data easier to access and use especially when organizations have multiple databases for multiple purposes
-
Monetize this enterprise data to gain business value
When data is moved in batches periodically, data is never up to data and available at the right time to make the right business decisions. At the same time, organizations demand that the cost of making data available be kept as low as possible whether cost is measured by resource consumption, staffing needs and so on.
In addition, with the proliferation of data, organizations today have multiple databases which cater to the varied needs that they have. From relational databases to NoSQL databases the list goes on. According to https://db-engines.com/en/ranking, Microsoft SQL Server is the third most popular database in the world and we have observed a growing need for organizations to replicate data and keep it synchronized from their MS SQL Server database sources for example, to target data marts and data lakes.
To make data easier to access by providing more flexibility in deployment options available for our CDC technology that captures changes from Microsoft SQL Server database logs, IBM has now introduced a new “remote capture“ capability in the existing IBM Data Replication “Change Data Capture (CDC)” technology replication engine for Microsoft SQL Server. Now, users have the option to capture changes from source Microsoft SQL Server database logs using a capture engine that is deployed on a different server from the source database. While the CDC source capture engine was built to be as low impact as possible to the source system, some users will prefer the flexibility of not running the replication capture on the same environment as their mission critical SQL server database. This could help users save on resource costs on the source database server. In addition, in some IT environments there may be policies in place that make it difficult to secure permission to have another application running on the source database server whether it is because of resource consumption concerns or for any other reason.
IBM Data Replication can provide up to the second replicas of changing data where and when needed and keeps data synchronized. Our users are replicating operational data from most of the world’s popular relational databases like Microsoft SQL server to everything from a traditional data warehouses to a data appliance such as Pure Data Analytics or IBM Integrated Analytics System to a Big Data cluster driven by Apache Kafka and Hadoop, or even to a Cloud based On Line Analytical Processing (OLAP) environment such as Db2 Warehouse.
For more details about how you can use IBM Data Replication to replicate and capture changes from your source Microsoft SQL Server database, click here.
For more information on configuring a remote source of the CDC replication engine for Microsoft SQL Server, click here.
Deliver real time feeds of operational data in to IBM Integrated Analytics System (IIAS) and Db2 Warehouse with IBM Data Replication
Blog Post by : Davendra Paltoo, Offering Manager, IBM Data Replication
In November 2017, IDC’s Data Integration and Integrity (DII) Software Research Group conducted a survey targeted at end-users of DII software, including similar questions as asked in 2015 to help identify trends. With the need to bring real time and most recent data in to the enterprise for analytics efforts, IDC survey respondents found that keeping data synchronized among applications is and will be the most prevalent use case for data integration with 51% of survey respondents indicating application data sync to be the top use case. IDC is also observing that data intelligence will grow from one of the least today, to one of the most prevalent by 2020, in support of data governance, profiling, discovery and knowledge1.
As organizations continue to face the challenge of bringing real time data for analytics applications/purposes, IBM provides the IBM® Integrated Analytics System (IIAS) which consists of a high-performance hardware platform and optimized database query engine software that work together to support various data analysis and business reporting features for today’s big data needs. IBM also provides Db2 Warehouse for Data Warehousing to provide users with in database analytics capabilities.
Users often need to integrate data from various data sources into their IIAS appliance or Db2 Warehouse deployment, if such technologies exist in their enterprise.
In addition, for an increasing variety of analytics use cases, only the freshest data is sufficient. Whether it is the customer interacting with a self-service portal or an executive looking for up to the minute financial performance, no organization can afford to serve up stale data. Yet, this can happen if organizations depend on periodic bulk movement of data around the enterprise.
IBM Data Replication provides up to the second replicas of changing data where and when needed. Our users are replicating operational data to everything from a traditional data warehouses to a data appliance such as the Pure Data Analytics (PDA) appliance or IIAS, to a Big Data cluster driven by Apache Kafka and Hadoop or even to a Cloud based OLAP environment such as Db2 Warehouse.
IBM data replication (Change Data Capture technology) can deliver changes using log based captures that minimize the impact on source databases from ALL supported CDC sources into IIAS and Db2 warehouse directly (i.e. in one hop).
In the recent release, IBM has introduced a new Mirror Bulk Apply option that supports Db2 External Tables as the apply mechanism for faster ingest into column organized tables within Db2 Warehouse deployed in the IIAS appliance or column organized tables in “standalone” Db2 Warehouse databases. This is as compared to the previously available apply mechanisms for applying changes to such column organized tables. External table bulk apply is the algorithm that CDC employs to apply changes to the IBM Pure Data Appliance or “Netezza”.
This support is now being extended to Db2 Warehouse. Such column organized tables are useful in databases intended for use in analytics since they aid query performance.
The new CDC apply performance capability will give end users the confidence that even the data from the most high volume transactional systems can be replicated with acceptable latency into IIAS and Db2 Warehouse’s column organized tables.
For more information on the Mirror Bulk apply capability please see our knowledge center.
For more information on IBM Data replication, please read the IBM Data Replication solution brief.
ALERT : IBM New Support Experience is live!
Dear IBM Data Replication Client,
This is to inform you that as of July 15 2018, we have successfully transitioned IBM Data Replication to our new Support Community, along with your case history and any active cases.
The move to this new support experience should be seamless for you – and it will continue to evolve and become richer over time. We invite you to view the following quick videos which provide an overview of the initial experience.
Introducing the IBM Support Community: Search https://mediacenter.ibm.com/media/t/1_hjcvgybl
IBM Support Community: Open And Manage Cases https://mediacenter.ibm.com/media/t/1_47uqs38j
Introducing the IBM Support Community: Forums https://mediacenter.ibm.com/media/t/1_dnpmr6oi
Among other improvements, we’re incorporating IBM Watson technology to provide a “one-stop shop” for Customer Support related information for Data Replication. We know you may have other IBM products; those will also be migrating to this new experience over time.
Within the new Support Community, self-service capabilities will be available to allow for better ease of use. They include:
Ticket creation/updates
Ability to attach documents for review by Support
Simplified search capability to view ticket history and knowledge base artifacts
As an added level of security, future notifications about case updates will include a secure link to your case (rather than actual case updates, to prevent unauthorized viewing of your case).
You can continue to use the same phone numbers, email addresses, and URLs you use currently. The existing access methods will seamlessly connect to the new Support Community, once you select Data Replication as a product. Alternatively, you can access the new Support experience directly by following these steps:
1. Go to www.ibm.com/mysupport, where you can select your Product from the list.
2. For a personalized experience, log in with your IBM ID.
If you do not have an IBM ID, you can go here to sign up for one: https://www.ibm.com/account/us-en/signup/register.html.
If you experience a problem with the portal (such as a login issue, etc.), we are here to help. Submit your issue via our Support Community by clicking “Provide feedback” and someone will get back to you as quickly as possible.
We hope you enjoy the enhancements of this new IBM support experience and always welcome your feedback.
Regards,
IBM Data Replication Support team.
How to retrieve data with transactional semantics from Kafka using the IBM Data Replication CDC Target Engine?
Blog post by: Davendra Paltoo, Offering Manager, Data Replication
Follow him on twitter: https://twitter.com/Davendr18397388
In addition to Apache Kafka’s more widely known capabilities as a distributed streaming platform, its capabilities, scalability and low cost as a storage system make it suitable as a central point in the enterprise architecture for data to be landed and then consumed by various applications.
When messages are landed in a Kafka cluster, there are a variety of available connectors or consumers that can in turn retrieve messages and deliver such messages to target destinations such as HDFS and Amazon S3. Or, Kafka users can write their own consumers.
However, developers of consumers struggle to find an easy way to:
- Only retrieve and consume transactions that have been completely delivered to Kafka (possibly to many different Kafka topics) with records in the original order as they occurred on the source database.
- Avoid processing of duplicate messages that have been delivered to Kafka.
- Avoid deadlocks when reading committed transactions from Kafka topics.
This is a concern to many Kafka users because in some critical scenarios, it is extremely valuable to users to have Kafka behave with database-like transactional semantics.
For example:
- The Kafka consumer needs to use Kafka data to populate parent child referential integrity tables in the same order as they were populated on the source.
- Processing of duplicate messages (which can sometimes occur during some failure and recovery scenarios when messages are being delivered to Kafka by Kafka producers or writers) cannot be tolerated by downstream applications. For example, knowing that no duplicates will be delivered, key business events can be triggered exactly once in response to messages delivered into Kafka.
- The Kafka consumer needs to guarantee retrieval and delivery of consistent transactions with the ability to recover from failures.
Why settle for duplicate data and promises of eventual consistency when you can leverage the performance and low cost of Kafka AND have database-like transactional semantics while not compromising on performance while delivering changes into Kafka?
IBM Data Replication’s “CDC” technology, with the initial version of its 11.4.0 release, provided users the ability to replicate from any supported CDC Replication source to a Kafka cluster by using the CDC target Replication Engine for Kafka.
In a recent delivery update, CDC now provides a java class library that can be included in a Kafka consumer application that is intended to consume data delivered by CDC into Kafka. This library, provides:
- Data in the original source log stream ORDER with identifiers available to denote transaction boundaries.
- A mechanism for ensuring exactly once delivery, so if there is an interruption in the Kafka environment and data has to be re-sent to Kafka by a producer or writer into Kafka, a consumer can be developed to only consume and process the data once.
- A “bookmark “that can be used to restart the consuming application from where it last left off processing.
Also available in the recent CDC delivery, are sample consuming applications that show how to:
- Poll records that were read by the Kafka transactionally consistent consumer for a specified subscription and write them to the standard output in the order of the source operation.
- Poll records that were read by the Kafka transactionally consistent consumer and publishes them in text format to a JMS topic.
Users are free to adapt the samples to suit their needs or to write their own consumer applications.
For more information on the Kafka transacationally consistent consumer please see our knowledge center at:
https://www.ibm.com/support/knowledgecenter/en/SSTRGZ_11.4.0/com.ibm.cdcdoc.cdckafka.doc/concepts/kafkatcc.html
For demo videos on how to make use of the IBM Data Replication Kafka Apply or to contribute to the IBM Data replication community, please see the replication developer works page: https://www.ibm.com/developerworks/community/wikis/home?lang=en#!/wiki/W8d78486eafb9_4a06_a482_7e7962f5ac59/page/Replication%20How%20To%20Videos
For more information on how IBM Data Replication can provide near real-time incremental delivery of transactional data to your Hadoop and Kafka based Data Lakes or Data Hubs, download this solution brief.
Make your organization insight-driven with the right replication solution
Blog Post by : Davendra Paltoo, Offering Manager, Data Replication
Follow him on Twitter : https://twitter.com/Davendr18397388
One thing that is common across organizations today is that each one wants to be customer-centric and in order to be so, they need to be insights-driven. Insights-driven firms are growing at an average of more than 30% annually and are on track to earn $1.8 trillion by 2021 predicts Forrester.
These Insights-driven organizations are built on data. In order to have 360-degree view of a customer, organizations need data which is spread across disparate databases and data warehouses. Some data may reside on premise in a IBM DB2 database, or Teradata database or in the cloud in a Microsoft Azure SQL based on business needs.
Irrespective of where your data resides, you need a data replication solution for real time replication requirements in support of your data integration and analytics projects.
To help meet the needs of organizations who make use of Teradata and MS Azure SQL databases, IBM Data Replication Change Data Capture technology now supports targeting Teradata in the latest 11.4 product line. Previously, the CDC apply for Teradata was only available in earlier supported versions.
In addition, CDC is now validated to support targeting Azure SQL databases, which closely resemble Microsoft SQL Server databases, via use of the CDC for Microsoft SQL Server data replication target/apply.
CDC Replication supports Azure SQL Database as a remote target only. The CDC Replication target can either be installed on premises or in an Azure VM. For optimum performance, the CDC Replication target should be installed on a VM in the same region as the Azure SQL Database.
For more information, on our Azure SQL database targeting capability please see our knowledge centre:
For more information on our Teradata apply in 11.4 visit our knowledge centre:
Improve the flexibility of message delivery into Kafka with Kafka Custom Operation Processors
Blog Post by : Davendra Paltoo, Offering Manager, Data Replication
Follow Davendra on Twitter at : https://twitter.com/Davendr18397388
Real time analytics can provide real time insights. When businesses have data at the right time, they can be more efficient and make the right tactical and strategic decisions. Apache Kafka® is used for building Data hubs or landing zones, building real-time data pipelines, and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.
The Apache Kafka (https://kafka.apache.org/) platform now has a vibrant associated eco-system.
When messages are landed in a Kafka cluster, there are a variety of available connectors or consumers that can in turn retrieve messages and deliver such messages to target destinations such as HDFS and Amazon S3. Users can save time and costs by using one of these available consumers, such as those listed on https://docs.confluent.io/current/connect/connectors.html or https://community.hortonworks.com/topics/Kafka.html
IIDR (CDC), with the initial version of its 11.4.0 release, provided users the ability to replicate from any supported CDC Replication source to a Kafka cluster by using the IIDR (CDC) target Replication Engine for Kafka. This engine writes Kafka messages that contain the replicated data to Kafka topics. The replicated data in the Kafka messages is by default written in the Avro binary format. Consumers that want to read these messages from Kafka clusters needed to utilize an Avro binary deserializer.
Users on the other hand, desired more flexibility in the IIDR (CDC) Kafka apply so that it could help users produce the various permutations of data formats of messages written to Kafka expected by the wide variety of off the shelf, custom connectors and consumer applications.
To help customers solve this challenge, IIDR (CDC) has recently introduced support for "Kafka custom operation processors" (KCOP) to improve the flexibility of message delivery into Kafka. Customers can make use of a number of integrated predefined output formats, or adapt these user exits to define their own custom formats, what data is included in the message payload, and more. Apart from giving users the flexibility of defining the message formats and payloads, users are now also able to specify the Kafka topic names for their message destinations, and much more.
Moreover, as more common customer needs are assessed IBM will add more such predefined output formats.
For more information on the KCOP and samples available, please see the IIDR (CDC) knowledge center:
For demo videos on how to make use of the sample KCOPs or to contribute to the IBM Data replication community, please see the replication developer works page: https://www.ibm.com/developerworks/community/wikis/home?lang=en#!/wiki/W8d78486eafb9_4a06_a482_7e7962f5ac59/page/Replication%20How%20To%20Videos
For more information on how IBM Data Replication can provide near real-time incremental delivery of transactional data to your Hadoop and Kafka based Data Lakes , visit : https://www.ibm.com/analytics/data-replication
Bring industry standard authentication mechanisms to your environment and protect your data
Blog Author: Davendra Paltoo, Offering Manager,Data Replication
With growing volumes, variety, and velocity of data, the challenge of protecting data continues. Every organization today is striving to protect its customer data and other data as the cost of data breaches are high. The 2017 Ponemon Cost of Data Breach Study, reports that the global average cost of a data breach is $3.62 million. The average cost for each lost or stolen record containing sensitive and confidential information decreased from $158 in 2016 to $141 in 2017. Despite the decline in the individual cost per record, companies report having larger breaches in 2017. The average size of the data breaches reported in this research increased 1.8 percent to more than 24,000 records per incident.
Security professionals are shifting their focus from device-specific controls to a data-centric approach that focuses on securing the apps and data and controlling access. Business, security, and privacy leaders understand that industry standard security practices have to be adopted to protect an organization’s data.
One of the reasons for security of data being compromised is when industry standard authentication mechanisms are not applied.
As part of movement to more centralized governance models for ease of administration and better security, organizations commonly want to centrally manage user credentials, security policies and access rights as part of managing access to their applications and data.
As a result, many organizations manage their user credentials, security policies and access rights in a central repository by implementing a Lightweight Directory Access Protocol (LDAP) compliant Directory Service such as IBM’s Tivoli, Microsoft’s Active Directory, and Apache’s Directory Services.
In addition, organizations also prefer business software to leverage these directory services rather than use decentralized, individually managed user credentials, security policies or access rights that could potentially be created for each piece of software deployed.
To help cater to the aforementioned security needs of today’s digital businesses, IBM Data Replication’s Change Data Capture (“CDC”) technology has introduced support for integration with LDAP directory services. Traditionally, the CDC Access Server authenticates users, stores user credentials and data access information, and acts as the centralized communicator between all replication agents and Management Console clients.
Now, starting with the IIDR 11.4.0.0-10291 Management Console and Access Server delivery, users can choose to have an LDAP server manage their CDC user credentials, user authentication, and data store access information to help users conform to LDAP based centralized security architecture in their enterprise.
For more information about the new IIDR (CDC) LDAP enablement and for details on how to configure LDAP with IIDR (CDC) please refer to the below links.
Data replication as a sensor on your database
When I first joined IBM in 2007 it seemed somewhat anachronistic that the Toronto Software Lab was managed by the leader of the Sensors and Actuators group. Now it seems prescient. As we consider the Internet of Things and see that all the physical objects around us have a useful place in the world of information, we see that our information assets can be viewed from a more traditionally physical perspective as well.
Databases are one of the most important assets that we have in an organization, certainly equal to our physical assets. As we consider the value in all the physical sensor information available, telling us who entered and exited every building, showing us through RFID tags what components flowed through an assembly line and so on, we should recognize the value of sensors on our databases as well.
I’ll focus on a particular type of sensor, one that provides a stream of the data changes occurring in the database. IBM’s Cloudant database provides a REST API that delivers a sensor stream of changes. IBM InfoSphere Data Replication can provide a sensor stream of changes from your distributed and mainframe-based relational databases, as well as from non-relational databases such as IMS and VSAM.
The original role for data replication technology was to enable low impact and low latency data movement. Data replication technology captures the changes occurring on the source database quickly and with minimal impact on that database and without requiring any changes in the database application. InfoSphere Data Replication captures changes from the database recovery logs. These traits make it ideal as a sensor.
Data replication has always had a role as an audit tool. Government regulations require certain industries to maintain an audit tail for their key data. Traditionally data mining was rarely done on these audit trails (let’s call them database sensor logs). The database sensor logs were kept primarily to meet the regulatory requirements.
Over time some industries have begun performing analytics on these sensor logs. Banks are using machine learning techniques to identify potential fraud events. Cell phone companies have been using streaming analytics to identify upsell opportunities. This use of analytics will grow as the Internet of Things continues to drive better analytics tools and create more data scientists experienced at working with sensor data.
I am often talking with clients as they begin to create an exploratory zone. They all understand the importance of having a copy of their database data in this exploratory zone and are interested in data replication technology as a way of maintaining a current copy of that database data. For exploratory zones that are being built around Hadoop it is easy to explain the advantages of using a database sensor log to provide that data as it suits the natural processing model of HDFS and Hive. Data replication can provide the sensor log as a series of files stored in HDFS and the data scientist can create Hive views over those files that can allow them to see either the entire audit trail or collapse that audit trail to just show the latest contents. Access to an audit trail is essentially a free side effect of the most practical method to provide data scientists with a current copy of the data and suits the general philosophy that one should not discard data on the way into your exploratory zone.
Most of our clients are just beginning the process of discovering the valuable questions that can be answered using this sensor log. An interesting difference between a database sensor log and a conventional physical sensor log is that the physical sensor log is often the primary source for both the current state of the physical object and the history of that state. You may learn both the current temperature of the engine block and the changes in that temperature over time. Many of the ideas discussed around the Internet of Things, such as the connected car, are primarily leveraging the information about the current state. This sort of analytics around the current state is already in place for databases. If you want to look at the Internet of Things to seed your thinking about what you may be able to get from database sensor logs you need to focus on those that are dependent on the history, not just the current state.
The use of personal fitness trackers to identify when a person with mobility issues may have fallen is an example that requires history. It seems quite similar to the fraud detection example that is already being done with database sensor logs. Some aspects of the connected car do depend on history, tracking the changes over time between two different sensors, say RPM and oil pressure, to ensure they maintain the expected relationship as they change. This might be comparable to comparing the database sensor log with the click stream from your application to confirm how many clicks it is taking to make specific types of updates to your system of record.
I think we are just scratching the surface here. I’m interested to see what other answers we will find. I encourage you to add a database sensor log to the assets you make available to your data scientists.
Compatibility of CDC/IIDR agents (engines), Management Console & Access Server
The following rules apply with respect to what Versions of Management Console (MC), Access Server, and CDC agents (engines) will inter-operate.
These rules apply to any CDC 6.x or higher release.
1) The MC and AS must be at the exact same release level
2) The CDC source and target agents (engines) can be at different release levels
3) The MC version must be >= the most recent CDC source or target agent (engine)
What Happened to InfoSphere CDC?
This post is the answer to one of the FAQs found in License Tips for IBM Data Replication .- Are the older products still being supported?
- Yes, as of the date of this post, they are. They are supported until IBM announces an end of service. If you ever have a question about whether an end of support has been announced, see the IBM Software Support Lifecycle pages on ibm.com.
- How do you move from your old InfoSphere CDC product to IIDR?
-
- If your InfoSphere CDC is on UNIX or Windows, you should see IIDR show up in your Passport Advantage account on March 12, 2013 if your shop is current on its InfoSphere CDC S&S (subscription and support).
- If your InfoSphere CDC is on z/OS, then your IBM sales team will talk to you about a special bid as mentioned in the original IIDR announcement letter.
A new IBM Redbook about InfoSphere CDC is available
Data Replication's Enhanced Apply for Netezza
IBM's Table Compare Utility and CDC
To understand when you might want to use asntdiff, understand the basics of how it works.
- asntdiff accepts two queries as input and compares the result sets.
- You can use almost any query you can write against source and target tables.
So, the first reason to consider asntdiff is times when differential refresh's restrictions could be overcome by writing queries to get the result sets you need. For example, asntdiff may be an alternative if one of the following differential refresh restrictions applies to your replication configuration:
- Differential refresh is only available for tables that use Standard replication.
- Derived columns in the source table are not supported.
- Target columns are ignored if they are mapped to derived expressions, constants, or journal control fields.
- Key columns of the target table must be mapped directly to columns in the source table.
Next, asntdiff is independent of data replication and can be started from a command line. Among other things, this means:
- It can made part of a z/OS batch job and scheduled.
- It can be used while a CDC subscription is running
* Yes, technically, you could already use asntdiff with CDC on UNIX or Window since it comes in so many IBM products on UNIX and Windows. However, if you wanted to use it on z/OS, you could only get it through Replication Server. It's now in InfoSphere Data Replication as well.
CDC and IMS Replication Compatibility
- IBM InfoSphere Data Replication (IIDR), v10
- InfoSphere IMS Replication for z/OS, v10
- InfoSphere Classic Change Data Capture for z/OS, v10 (for use with IMS)
One question that comes up is whether the two IMS replication products are compatible with either the new Data Replication product or the existing InfoSphere CDC products. The answer is yes - the IMS products are compatible with both new and existing products that contain the CDC technology. IMore specifically, they can provide IMS changed data to any data replication solution that you can build with IBM's CDC technology. For example, you can create unidirectional (one-way) subscriptions that feed IMS changed data to any database that can be targeted by CDC:
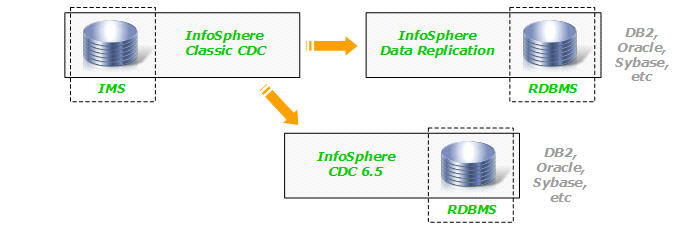
- IBM recommends you use the CDC technology in IIDR if you do not own InfoSphere CDC.
- The target DB2 can be DB2 for z/OS, DB2 LUW, or DB2 for System i.
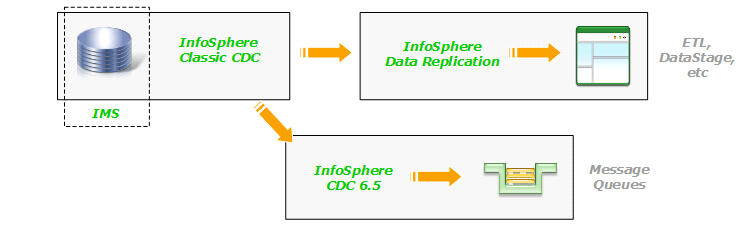
An IBM Redbook About CDC for DB2 z/OS
Product Synonym
CDC;CDD;IDR;IIDR;IBM Data Replication
Was this topic helpful?
Document Information
Modified date:
06 December 2019
UID
ibm11098999