Surveillance des applications
Instana présente la nouvelle génération d'APM avec sa hiérarchie d'applications, ses points de terminaison et ses perspectives applicatives qui les relient. L'objectif principal est de simplifier la surveillance de la qualité des services de votre entreprise. À partir des données recueillies via les traces et les capteurs des composants, l' Instana e identifie votre environnement applicatif directement à partir des services en cours d'exécution.
Les solutions Application Performance Management (APM) traditionnelles concernent la gestion des performances et de la disponibilité des applications.
Une application pour les outils APM est un ensemble statique de moteurs d'exécution (par exemple, le moteur.NET ( JVM ) ou le CLR) qui sont surveillés à l'aide d'un agent. Normalement, l'application est définie en tant que paramètre de configuration dans chaque agent.
Ce concept, qui était un bon modèle pour les applications classiques à 3 niveaux, ne fonctionne plus dans les applications de (micro)services modernes. Un service n'appartient pas toujours à une seule application. Prenons par exemple un service de paiement par carte bancaire utilisé à la fois sur la boutique en ligne d'une entreprise et dans ses points de vente. Définir chaque service comme une application pourrait résoudre ce problème, mais cela soulève les nouveaux défis suivants :
- Trop d'applications à surveiller : considérer chaque service comme une application en génère des centaines, voire des milliers. La surveillance des applications à l'aide de tableaux de bord devient impossible en raison de la surcharge de données.
- Perte de contexte : le fait de traiter chaque service séparément rend difficile la compréhension des dépendances ou du rôle du service dans le contexte plus large d'un problème.
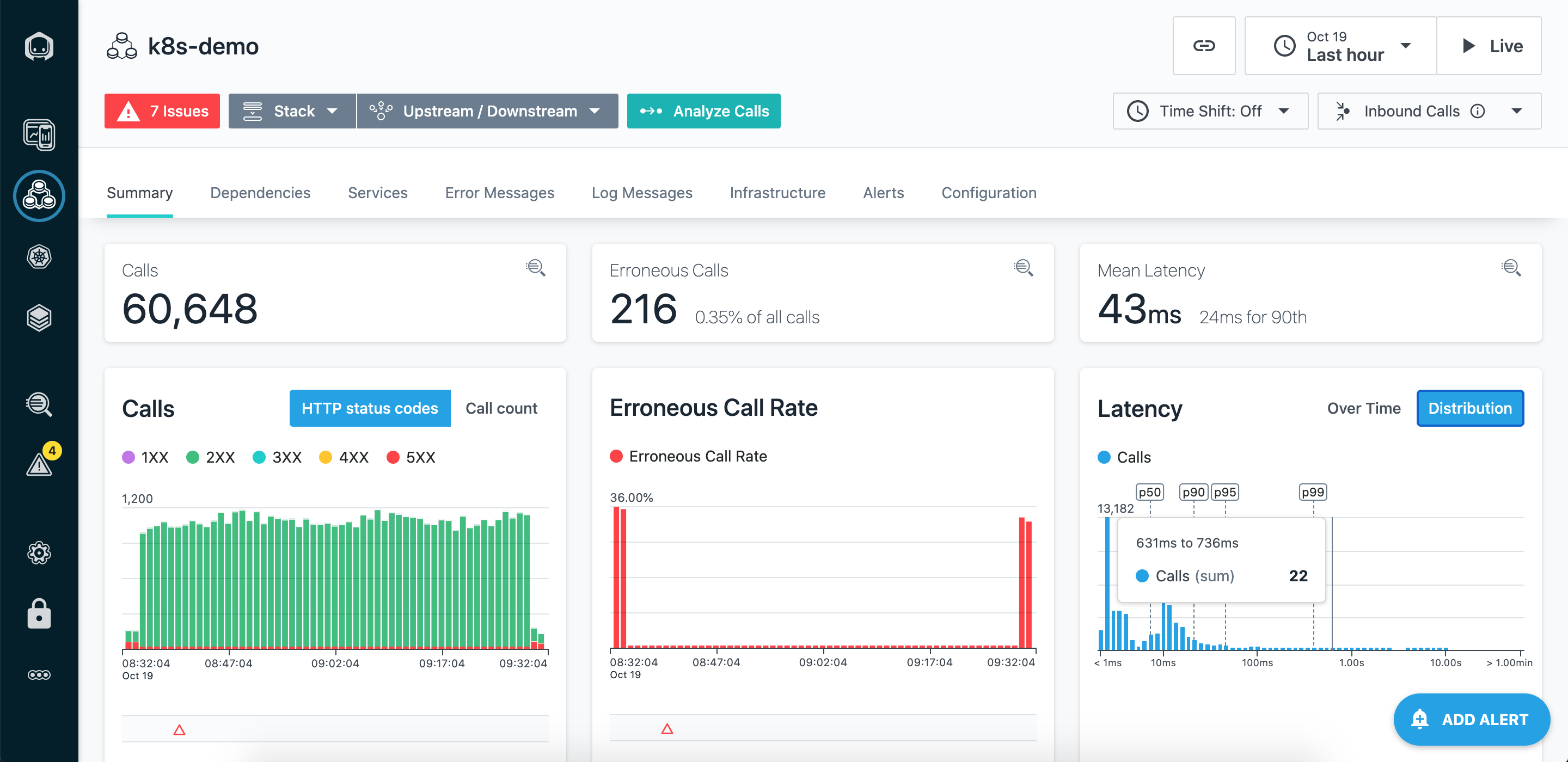
Récapitulatif
Distribution de la latence
Le graphique de répartition de la latence est idéal pour analyser les problèmes liés à la latence de vos applications, services ou terminaux. Vous pouvez sélectionner une plage de latence sur le graphique et, à l'aide du menu « Afficher dans Analytics », explorer plus en détail les appels concernés dans Unbounded Analytics.
Problèmes et changements liés à l'infrastructure
L'onglet « Résumé » affiche les problèmes et les modifications d'infrastructure liés à vos applications, services ou points de terminaison. Ces informations vous aident à identifier les corrélations avec des variations significatives des indicateurs d'application, telles qu'une augmentation du taux d'appels erronés ou de la latence.
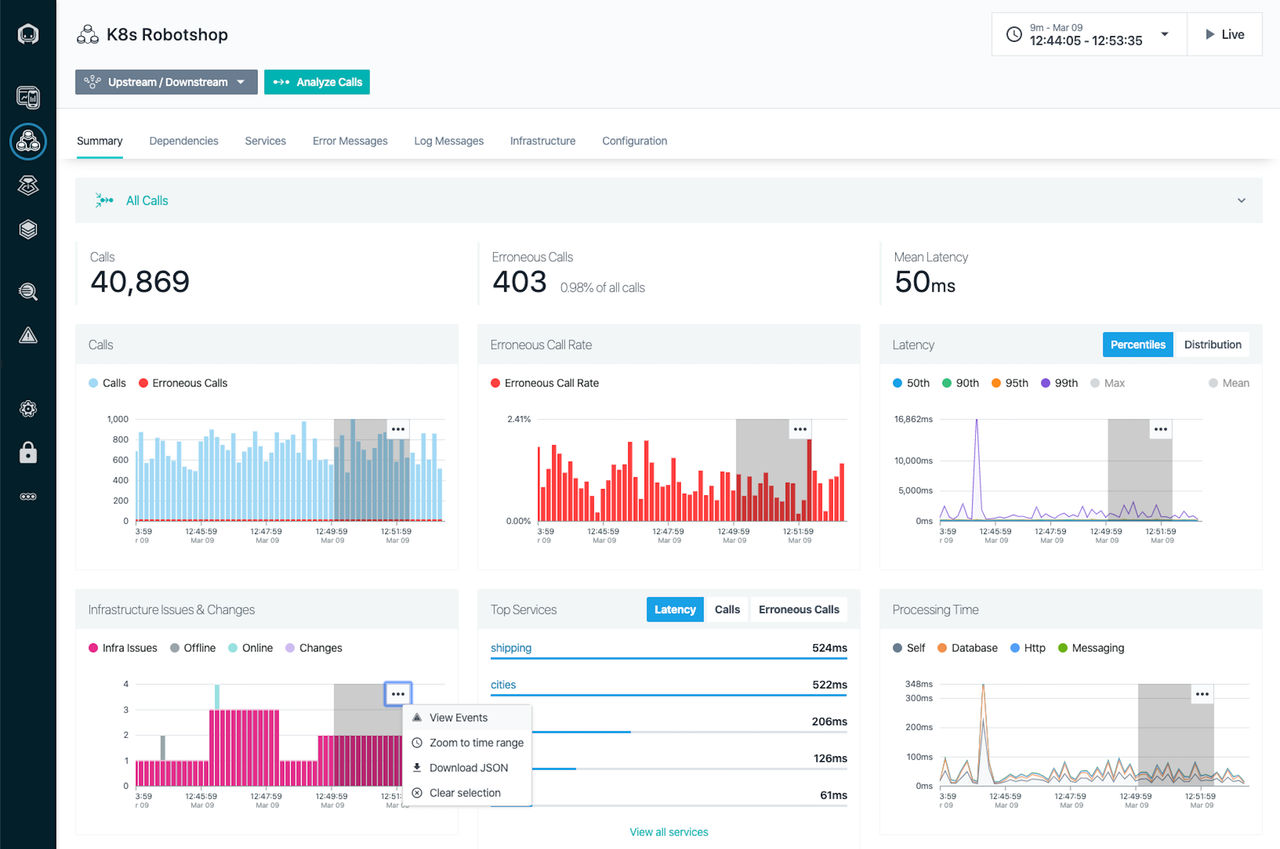
Pour en savoir plus sur des problèmes ou des modifications spécifiques, sélectionnez un intervalle de temps souhaité dans le graphique et cliquez sur l'option de menu Afficher les événements , qui vous permet d'accéder à la vue Evénements .
Temps de traitement
Le graphique « Temps de traitement » vous aide à comprendre combien de temps est consacré au traitement au sein d'une application, d'un service ou d'un point de terminaison lui-même (Self), et combien de temps est consacré à l'appel des dépendances en aval, le tout ventilé par type d'appel, tel que Http, Database, Messaging Rpc,, SDK, etc.
Par exemple, si la latence d'un appel vers le Shop service est 1000msde, que ce Shop service effectue un appel vers le Payment service via l' HTTP, qui prend 300ms , puis un autre appel vers la base de données du Catalog service, qui prend 200ms, le temps de traitement propre du Shop service est de 1000-300-200=500ms.
Décalage horaire
Pour comparer les indicateurs à des périodes antérieures, vous pouvez utiliser la fonctionnalité « Time Shift », comme le montre l'image. Gardez à l'esprit que la précision peut être réduite lorsque vous comparez des indicateurs à des données historiques.

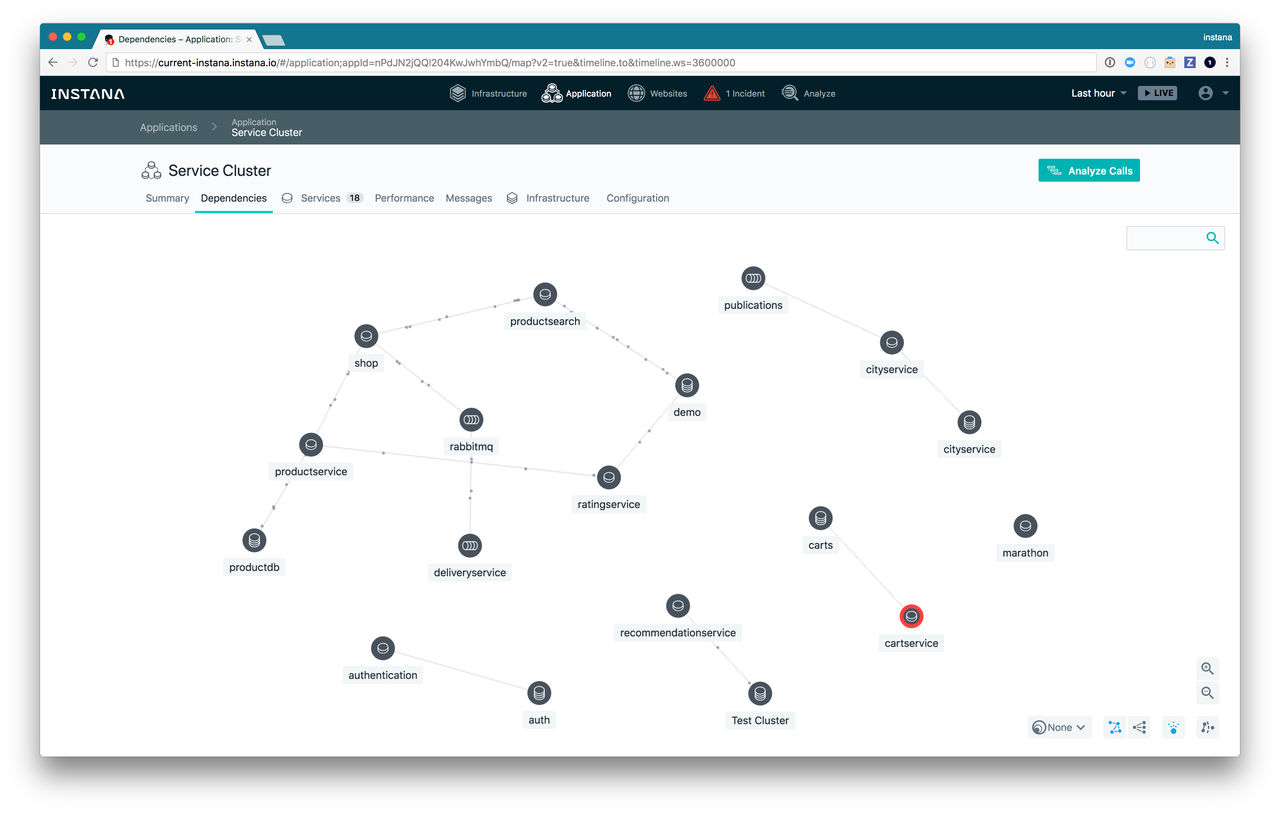
Mappe des dépendances d'application
La mappe de dépendances est disponible pour chaque application et fournit:
- un aperçu des dépendances des services dans l'application ;
- une représentation visuelle des appels entre les services pour comprendre les chemins de communication et le débit ;
- différentes présentations pour comprendre rapidement l'architecture de l'application ;
- un accès confortable aux vues de service (tableaux de bord, flux, appels et problèmes).
Messages d'erreur
Les messages d'erreur sont des messages générés à partir des erreurs survenues lors de l'exécution du code d'un service. Par exemple, si une exception est levée pendant le traitement et qu'elle n'est ni interceptée ni gérée par le code de l'application, elle apparaît dans l'onglet « Messages d'erreur ». Une exception non traitée dans la méthode doGet d'un servlet qui entraîne la réponse HTTP 500 à la demande, est un exemple.
Messages de journal
Les messages de journalisation sont collectés à partir de bibliothèques ou de frameworks de journalisation instrumentés. Par exemple, consultez la section « Journalisation » dans la liste des bibliothèques prises en charge. Lorsqu'un service enregistre un message de journalisation de niveau « grave » WARN ou supérieur via une bibliothèque de journalisation, ce message s'affiche dans l'onglet « Messages de journalisation ». De plus, les messages de journalisation capturés s'affichent dans les détails de la trace, dans le contexte de celle-ci. Si un message de journal a été enregistré avec un niveau de gravité ERROR ou supérieur, il est signalé comme une erreur. Les messages de journal dont le niveau de gravité est inférieur à ne WARN sont pas pris en compte.
Infrastructure
Depuis la vue « Perspective de l'application » ou le tableau de bord « Services », il est possible d'accéder au composant d'infrastructure correspondant affiché dans la vue « Surveillance de l'infrastructure ».
Composant d'infrastructure « non surveillé »
La liste des composants d'infrastructure d'une application ou d'un service peut parfois inclure un hôte, un conteneur ou un processus « non surveillé ».
Le composant « Non surveillé » indique que, pour tout ou partie des appels adressés à un service, il n'a pas été possible de les associer à un composant d'infrastructure spécifique. Les services sont des entités « logiques » et sont généralement associés à des composants d'infrastructure par le biais du processus surveillé. Cela ne s'applique pas aux services Web tiers, qui ne font pas l'objet d'une surveillance mais pour lesquels des services et des points de terminaison sont tout de même créés en fonction du nom d'hôte et du chemin d'accès. Comme aucun hôte ni processus n'est identifié, ces services sont associés au composant d'infrastructure « Inconnu ».
Alertes intelligentes
Affichez la liste de toutes les alertes intelligentes configurées. Cliquez sur une alerte pour afficher sa configuration, la modifier ou afficher son historique de révision. Si nécessaire, vous pouvez également désactiver ou retirer l'alerte.
Pour savoir comment ajouter une alerte, consultez la documentation sur les alertes intelligentes.
Réglage de la plage horaire
La période utilisée dans les tableaux de bord ou les analyses d' Instana s peut légèrement différer de la période sélectionnée dans le sélecteur de date. Le tableau de bord ou l'intervalle d'analyse exclut le premier et le dernier compartiment partiel. Par exemple, si vous sélectionnez l'option prédéfinie « Dernières 24 heures » dans le sélecteur d'heure à 15h15 le 20 janvier, la plage horaire est ajustée de 15h30 le 19 January–3:00 le 20 janvier. Cet ajustement est effectué car la granularité respective du graphique est de 30 minutes. L'ajustement de l'intervalle de temps garantit la cohérence entre les différents widgets sur la même page et évite une mauvaise interprétation des intervalles partiels en tant que tendance de métrique inattendue, par exemple, une baisse du nombre d'appels.
Données approximatives
Lorsque vous consultez un tableau de bord ou effectuez une requête dans Analytics sur une période spécifique dépassant les sept derniers jours, il se peut que l'indicateur de données approximatives s'affiche sur différents widgets; celui-ci sert à signaler qu' Instana utilise un nombre réduit de traces et d'appels statistiquement significatifs pour traiter les requêtes. Exemple :
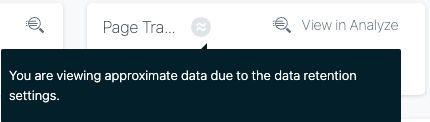
Les traces et les appels qui se produisent rarement peuvent ne pas être représentés dans de tels scénarios.
Remarque sur la précision de l'échantillonnage pour les indicateurs au niveau des appels
Le système utilise un échantillonnage aléatoire basé sur le hachage de l'identifiant de trace, ce qui garantit un échantillonnage cohérent au niveau de la trace. Cela a toutefois des implications lors de l'analyse des indicateurs au niveau des appels :
- L'échantillonnage s'effectue par trace, et non par appel. Si les caractéristiques des traces varient considérablement (par exemple, le nombre d'appels par trace), les données au niveau des appels peuvent être faussées.
- Par exemple, une seule trace comportant plus d'un million d'appels 2.4 peut avoir un impact considérable sur les indicateurs au niveau des appels si le système l'inclut dans l'échantillonnage.
- Il s'agit d'un comportement normal, et non d'un défaut. Cela illustre le fonctionnement de l'échantillonnage par traces.