Analyse des traces et des appels
Examinez les traces dans Unbounded Analytics, où vous pouvez analyser les traces et les appels collectés par Instana. Pour vous permettre de comprendre comment une application se comporte avec chaque appel, nous surveillons chacun de ces appels au fur et à mesure qu'ils entrent dans le système.
Affichage des traces
- Dans la barre latérale, cliquez sur Applications.
- Dans le tableau de bord Applications, sélectionnez une application ou un service
- Dans le tableau de bord de l'application ou des services, cliquez sur Analyse des appels.
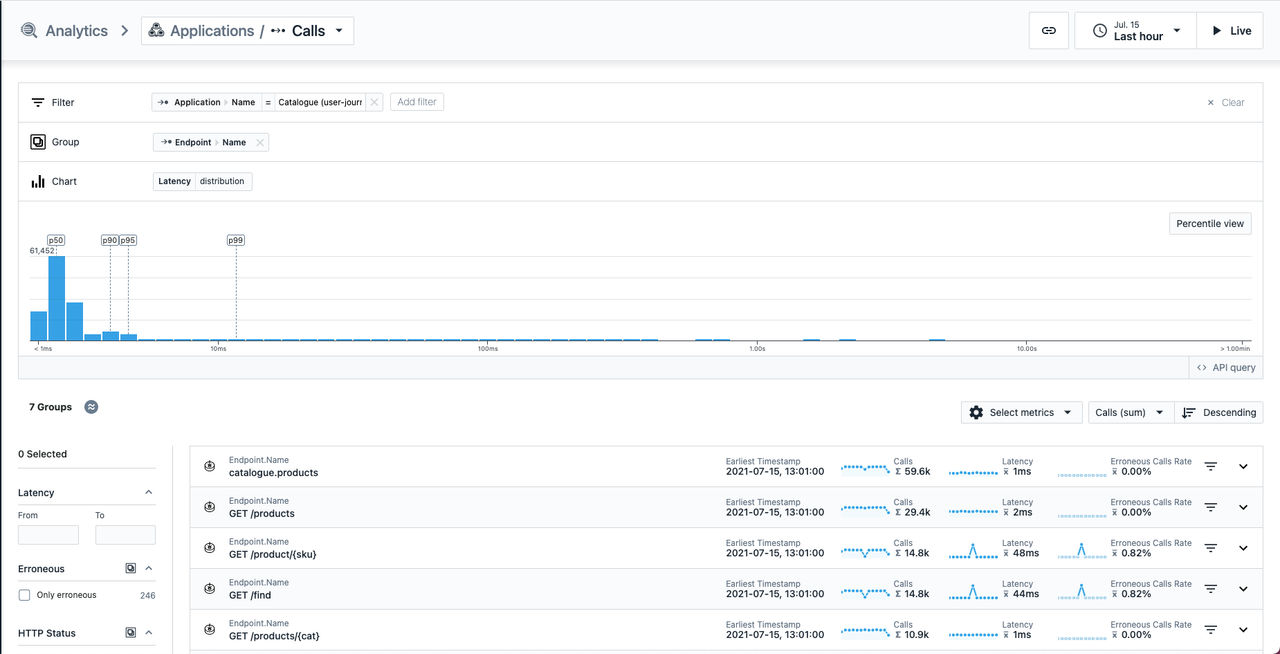
- Dans le tableau de bord Analyse, vous pouvez analyser les appels par application, service et nœud final, en ventilant les données qu'Instana présente respectivement en fonction des noms de service, de nœud final et d'appel. Dans la section « Applications », sélectionnez « Appels » ou « Traçages ».
- Cliquez sur un groupe, puis sélectionnez une trace.
Affichage de l'analyse des traces

Filtrage et regroupement de traces ou des appels
Dans le tableau de bord Analyse, les traces ou les appels peuvent être filtrés et regroupés à l'aide de balises arbitraires. Dans l'analyse des appels, les filtres peuvent être connectés à l'aide des opérateurs logiques AND et OR et regroupés à l'aide de crochets. Dans Analyse des traces, seul l'opérateur AND est disponible.
Il existe deux méthodes de filtrage de données :
- Générateur de requête
- Barre latérale de filtrage
Les deux peuvent être utilisés seuls, mais les meilleurs résultats sont obtenus lorsqu'ils sont combinés.
Générateur de requête
Utilisez le générateur de requêtes dans le tableau de bord Analytics pour filtrer l'ensemble de résultats initial. En cliquant sur Ajouter un filtre, vous pouvez appliquer les balises application.name, service.name et endpoint.name, ainsi que les balises d'entité d'infrastructure, telles que agent.tag ou host.name, à la source et à la destination d'un appel. Par défaut, elles s'appliquent à la destination. Pour désigner la source, cliquez sur le sélecteur situé avant le nom de balise et sélectionnez source. En combinant la source et la destination, vous pouvez créer des requêtes telles que Afficher tous les appels entre ces deux services ou Afficher tous les appels émis depuis ma « production » agent.zone vers le « test » agent.zone. La sélection d'une source ou d'une destination n'est pas disponible pour les balises d'appel, telles que call.http.path ou call.tag, qui sont des propriétés sur l'appel lui-même, indépendantes de la source ou de la destination.
Pour appliquer un regroupement, cliquez sur Ajouter un groupe et sélectionnez l'une des balises. Le regroupement par défaut utilise la balise de nom de nœud final (endpoint.name). Pour inspecter les traces et les appels individuels qui correspondent aux filtres, vous pouvez soit développer le groupe pour qu'il pointe dans les résultats, soit cliquer sur Mettre en évidence ce groupe pour supprimer le regroupement et filtrer davantage les résultats en fonction de la valeur du groupe sélectionné. Les balises peuvent être appliquées à la source ou à la destination de l'appel, de sorte que vous pouvez exécuter des requêtes telles que Afficher tous les appels vers ce service ventilés par appelant. Les appels qui ne correspondent à aucun groupe sont affichés dans un groupe spécial nommé Tag not present. Par exemple, avec agent.zone , il s'agit des appels sans la balise'agent.zone'. Pour supprimer le agent.zone non concordant des résultats, appliquez un filtre supplémentaire à l'aide de l'opérateur is present . Le regroupement par source et par destination n'est pas disponible également dans l'analyse des traces, car les groupes disponibles dans cette vue sont indépendants de la source ou de la destination d'un appel.
L'exemple précédent permet un filtrage par application Catalogue (user-journey) et répertorie les appels regroupés par nom de noeud final.
Barre latérale de filtrage
À partir des résultats obtenus grâce aux filtres du générateur de requêtes, il est possible d'explorer rapidement les données en appliquant des filtres supplémentaires dans la barre latérale de filtrage du tableau de bord Analytics.

Les éléments de la même catégorie de balise seront concaténés via l'opérateur ORlogique, et les différentes catégories de balise seront concaténées à l'aide de l'opérateur AND logique. Tous les filtres sélectionnés dans la barre latérale de filtrage sont appliqués aux filtres du générateur de requêtes déjà en place via une opération logique « ET ». L'en-tête de la barre latérale de filtrage affiche le nombre total d'éléments sélectionnés pour toutes les balises et vous permet de désactiver rapidement tous les filtres appliqués à la barre latérale.
Attention: Notez que plusieurs sélections pour une seule balise ne sont actuellement pas prises en charge sur Analyze Traces.
Dans l'exemple précédent, nous filtrons par application Catalogue (user-journey) dans le générateur de requêtes ET par services catalogue-demo OU discount-svc sélectionnés dans la barre latérale de filtrage.
Pour regrouper rapidement les résultats selon l'un des critères de la barre latérale de filtrage, cliquez sur le bouton de regroupement situé à côté de chaque critère pouvant faire l'objet d'un regroupement. Il s'agit d'un moyen rapide de configurer le regroupement dans le générateur de requêtes, comme décrit précédemment. A l'instar de la possibilité de regroupement en fonction d'une balise de barre latérale de filtrage spécifique, il est également possible d'annuler à nouveau le regroupement en cliquant sur le bouton d'annulation du regroupement sur une balise actuellement utilisée pour le regroupement.
Limitations connues
Regroupement des appels par balises de journal: lors du regroupement des appels par log.level ou log.message, le groupe spécial Tag not present ne sera pas représenté comme c'est le cas pour les autres balises.
Distribution de la latence
La latence des traces et des appels peut être inspectée à l'aide du graphique de distribution de la latence. Lorsque vous sélectionnez une plage de latence sur le graphique, les filtres sont ajustés en conséquence. Les résultats dans le tableau comme suit seront mis à jour pour afficher uniquement les traces ou les appels dans la plage de temps d'attente spécifiée.

Vue de trace
Pour afficher une vue de trace, dans le tableau de bord Analyse, sélectionnez un groupe, puis cliquez sur la trace. La sélection d'un appel affiche l'appel dans le contexte de sa trace.

Informations récapitulatives
Les informations récapitulatives d'une trace sont les suivantes :
- Nom de la trace (généralement une entrée HTTP).
- Nom du service dans lequel elle s'est produite.
- Type ou technologie
- Les principaux indicateurs clés de performance :
- Sous-appels à d'autres services.
- Nombre d'appels erronés.
- Nombre d'erreurs dans la trace.
- Nombre d'avertissements dans la trace.
- Durée de la trace. Intervalle entre le début du premier appel et la fin du dernier appel dans une trace.
Chronologie
La chronologie d'une trace affiche ce qui suit :
- Moment de démarrage de la trace.
- Ordre chronologique des services appelés dans la trace.
Blocage des chaînes d'appels à partir de l'élément racine (span) Sur les systèmes à trois niveaux simples, la profondeur type est de quatre niveaux. En revanche, sur les systèmes avec une architecture distribuée de services ou de micro-services, vous aurez des icicles beaucoup plus longs. Lorsque vous avez de longs sous-appels de la trace ou des modèles d'appel périodiques, comme un appel HTTP par entrée de base de données, la chronologie vous donne une excellente vue d'ensemble de la structure d'appel.
Pour afficher les détails de l'intervalle, cliquez sur l'intervalle dans le graphique chronologique. Pour afficher les détails de l'endroit où le temps a été passé dans un appel spécifique, survolez l'appel affiché sur le graphique chronologique.
Les détails de l'appel incluent les types de temps suivants:
Self:Temps passé par l'appel en dehors des appels en aval (c'est-à-dire le temps passé dans l'appel).Waiting:Temps passé par l'appel à attendre la fin de tous les appels en aval.Network:Différence de temps entre leExit Span Timede l'appelant et leEntry Span Timede l'appel.Total:Temps total d'un appel.
services
Les services répertoriés sous le graphique chronologique récapitulent tous les appels par service et répertorie le nombre d'appels, le temps cumulé et les erreurs qui se sont produites. Chaque service a sa propre couleur (dans cet exemple, shop est bleu, productsearch est vert). Sélectionnez un service pour afficher ses informations dans le tableau de bord des applications et des services.
Appels

L'arborescence de trace affiche la structure des appels de service en amont et en aval, ainsi que le type de l'appel. Pour explorer des appels spécifiques, développez et réduisez des parties individuelles de l'arborescence de trace. Sélectionnez un appel pour afficher ses informations dans le tableau de bord des services et des nœuds finaux.
Appels orphelins
Un appel est considéré comme orphelin si son appel parent est manquant. Un appel peut être manquant pour diverses raisons, par exemple parce qu'il n'est pas encore terminé ou qu'il est envoyé à un autre outil APM. Etant donné que la relation parent-enfant détermine la position d'un appel dans une arborescence d'appels, la position d'un appel orphelin est inconnue. L'appel orphelin est directement associé à l'appel racine. Une icône d'indicateur s'affiche sur le bord entre la racine et l'appel orphelin.

Informations sur l'appel
Pour afficher la barre latérale des informations d'un appel, sélectionnez l'appel dans le graphique chronologique. Les détails affichés incluent la source et la destination de l'appel, les erreurs, un code d'état, ainsi que la trace de pile.
Enregistrer les traces
Pour enregistrer manuellement une courbe affichée dans la mémoire à long terme (pour une durée maximale de 13 mois), cliquez sur le bouton « Enregistrer la courbe ». Vous pouvez également enregistrer automatiquement la trace en restant sur la vue « Détails de la trace » pendant au moins 15 secondes. Cependant, la conservation à long terme de traces volumineuses n'est pas prise en charge.
Capture des journaux et des erreurs
Instana capture automatiquement les erreurs lorsqu'un service renvoie une réponse erronée ou qu'un journal avec le niveau ERROR ou WARN (ou similaire selon le framework) a été détecté.
Agrégation automatique des appels de sortie courts
Instana s'efforce toujours de vous donner la meilleure compréhension des interactions du service, tout en réduisant au minimum l'impact sur l'application. Cependant, dans certains cas, il faut qu' Instana e à supprimer des données pour y parvenir.
Un problème courant dans les systèmes est le problème de requête 1+N , qui décrit une situation dans laquelle le code effectue un appel de base de données pour obtenir une liste d'éléments, suivi de N appels individuels pour extraire les éléments individuels. Le problème peut être résolu en n'effectuant qu'un seul appel et en y joignant les autres appels.
L'icône en regard du nom de l'appel indique le nombre de demandes traitées par lots. Les informations d'appel correspondent à celles de l'appel de service le plus significatif, par exemple, la demande ayant la durée la plus élevée ou comportant des erreurs. La durée et le nombre d'erreurs de l'appel affiché sont agrégés à partir de tous les appels traités par lots.

L'agrégation des interactions de service se fait uniquement dans les limites suivantes :
- Modèles d'accès fréquents et répétitifs de type similaire
- Les appels de service individuels prennent moins de 10 ms
- Le délai entre les appels est inférieur à 10 ms
Capture des paramètres
Pour des raisons liées à l'impact, les capteurs de traçage d' Instana, pour l'instant, ne capturent pas automatiquement les paramètres ni les valeurs de retour des méthodes. Pour capturer des données supplémentaires sur la demande, utilisez les kits SDK.
Tâches longues
En raison de délais d'attente, d'une charge élevée ou de tout autre nombre de conditions d'environnement, les appels peuvent nécessiter un temps important avant de répondre. Les traces peuvent contenir des dizaines, voire des centaines, de ces appels. Étant donné que Instana vise à fournir le plus rapidement possible des informations de traçage à l'utilisateur, les segments d'exécution de longue durée sont dans un premier temps remplacés par un espace réservé. Lorsque la plage à exécution longue est finalement renvoyée, la marque de réservation est à nouveau remplacée par les informations d'appel correctes.
Traitement par lots des traces
En raison des performances élevées et de la nature quasi en temps réel du pipeline de traitement de l'étendue, les étendues qui arrivent en retard et de manière asynchrone sont traitées de manière légèrement différente lorsqu'elles sont liées à la trace résultante. Une zone d'information de la vue Trace est présentée à l'utilisateur et fournit des informations sur une trace syntaxiquement incorrecte.
Pour les utilisateurs d' Instana, les effets suivants peuvent se produire :
- Dans la vue Trace, tous les sous-appels de la trace ne sont pas présentés.
- Des traces distinctes avec le même ID de trace sont répertoriées et présentent partiellement la trace globale.
- Il se peut qu'un appel ne soit pas mappé à la perspective d'application correspondante, puis qu'il soit manqué dans Unbounded Analytics.
- Il se peut qu'un appel ne soit pas mappé au service correspondant, puis qu'il soit manqué dans Unbounded Analytics.
- La mappe de flux peut afficher des nombres d'appels incohérents.
- La mappe de flux peut afficher des mappages de service incohérents.

Dans cette situation, certains intervalles arrivent après l'intervalle de 2 secondes lorsque la trace résultante a déjà été traitée. Cette approche présente toutes les étendues capturées, mais certaines des corrélations peuvent ne pas être correctes.
Cela peut entraîner les anomalies suivantes dans le modèle de données d' Instana :
- Une étendue d'exit et l'étendue d'entrée correspondante peuvent ne pas être fusionnées en un seul appel.
- Il se peut qu'un appel ne soit pas mappé au service approprié.
- Il se peut qu'un appel ne soit pas lié à l'appel parent correct.
- Un appel peut manquer des balises d'infrastructure.
- Il se peut qu'un appel ne soit pas ou qu'il soit mappé de manière incorrecte à une perspective d'application.
L'image suivante présente une trace similaire, avec toutes les étendues traitées dans le contexte de l'étendue racine et donc liées à la trace dans un seul lot:

Données approximatives
Les traces et les appels sont conservés pendant 7 jours. Après cette période, vous voyez un indicateur de données approximatif du nombre d'appels conservés et de l'estimation du nombre d'appels d'origine. Les traces et les appels qui se produisent rarement peuvent ne pas être représentés dans de tels scénarios.
timepicker commence il y a plus de 7 jours et se termine au cours des 7 derniers jours, l'ensemble de cette période sera analysé à partir de données approximatives, même si des données complètes sont disponibles pour une partie de cette période. Si vous souhaitez analyser un jeu de données complet, assurez-vous que l'intervalle sélectionné commence au cours des 7 derniers jours.
Des métriques précises des perspectives d'application sont conservées au cours des 31 derniers jours. Lorsque vous développez un groupe ou que vous le supprimez pour afficher des appels individuels, vous ne pouvez voir que les appels conservés et l'indicateur de données approximatives.
Au-delà de 31 jours, les métriques et les appels seront approximatifs.

Remarque concernant la précision de l'échantillonnage pour les indicateurs au niveau des appels
Le système utilise un échantillonnage aléatoire basé sur le hachage de l'identifiant de trace, ce qui garantit un échantillonnage cohérent au niveau de la trace. Cela a toutefois des implications lors de l'analyse des indicateurs au niveau des appels :
- L'échantillonnage s'effectue par trace, et non par appel. Si le nombre d'appels par trace varie considérablement, les données au niveau des appels peuvent être faussées.
- Par exemple, une seule trace exceptionnelle comportant plus d'un million d'appels peut avoir un impact considérable sur les indicateurs au niveau des appels si le système l'inclut dans l'échantillonnage.
- Il s'agit d'un comportement normal, et non d'un défaut. Cela illustre le fonctionnement de l'échantillonnage par traces.
Limitations
HTTP Les paramètres qui ne comportent pas de nom sont ignorés lors de l'analyse des appels et ne peuvent pas être utilisés pour le filtrage ou le regroupement. Par exemple, dans un appel avec la chaîne de =val1&key=val2requête, seul le paramètre key nommé avec la valeur val2 est reconnu. Le paramètre sans =val1 nom est ignoré. Cependant, la chaîne de requête complète reste visible dans les détails de l'appel.