In this example,a z/OS UNIX System Services (z/OS UNIX) file is
edited and copied. The logical record length of the output data set
is less than that of the input data set.
//DISKDISK JOB ...
//STEP1 EXEC PGM=IEBGENER
//SYSPRINT DD SYSOUT=A
//SYSUT1 DD PATH='/dist3/stor44/sales.mon',FILEDATA=TEXT,PATHOPTS=ORDONLY,
// LRECL=100,BLKSIZE=1000,RECFM=FB
//SYSUT2 DD DSNAME=NEWSET,UNIT=disk,DISP=(NEW,KEEP),
// VOLUME=SER=111113,DCB=(RECFM=FB,LRECL=80,
// BLKSIZE=640),SPACE=(TRK,(20,10))
//SYSIN DD *
GENERATE MAXFLDS=4,MAXGPS=1
EXITS IOERROR=ERRORRT
GRP1 RECORD IDENT=(8,'FIRSTGRP',1),FIELD=(21,80,,60),FIELD=(59,1,,1)
GRP2 RECORD FIELD=(11,90,,70),FIELD=(69,1,,1)
/*
The control statements are as follows:
- SYSUT1 DD defines the input file. Its name is /dist3/stor44/sales.mon.
It contains text in 100–byte records. The record delimiter is
not stated here. The file might be on a non-System/390 system that
is available via NFS, Network File System.
- SYSUT2 DD defines the output data set (NEWSET). Twenty tracks
of primary storage space and ten tracks of secondary storage space
are allocated for the data set on a disk volume. The logical record
length of the output records is 80 bytes, and the output is blocked.
- SYSIN DD defines the control data set, which follows in the input
stream.
- GENERATE indicates that a maximum of four FIELD parameters are
included in subsequent RECORD statements and that one IDENT parameter
appears in a subsequent RECORD statement.
- EXITS identifies the user routine that handles input/output errors.
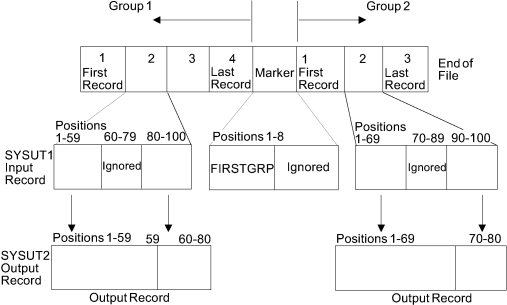
Figure 1 shows how a sequential input data set is
edited and copied.
Figure 1. How a Sequential Data Set is Edited and Copied
- The first RECORD statement (GRP1) controls the editing of the
first record group. FIRSTGRP, which appears in the first eight positions
of an input record, is defined as being the last record in the first
group of records. The data in positions 80 through 100 of each input
record are moved into positions 60 through 80 of each corresponding
output record. (This example implies that the data in positions 60
through 79 of the input records in the first record group are no longer
required; thus, the logical record length is shortened by 20 bytes.)
The data in the remaining positions within each input record are transferred
directly to the output records, as specified in the second FIELD parameter.
- The second RECORD statement (GRP2) indicates that the remainder
of the input records are to be processed as the second record group.
The data in positions 90 through 100 of each input record are moved
into positions 70 through 80 of the output records. (This example
implies that the data in positions 70 through 89 of the input records
from group 2 are no longer required; thus, the logical record length
is shortened by 20 bytes.) The data in the remaining positions within
each input record are transferred directly to the output records,
as specified in the second FIELD parameter.
 z/OS DFSMSdfp Utilities
z/OS DFSMSdfp Utilities


 Copyright IBM Corporation 1990, 2014
Copyright IBM Corporation 1990, 2014