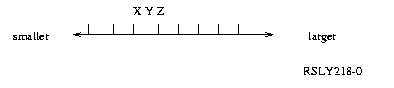Arithmetic instructions are primarily designed to compute numeric results; they operate on numeric scalars of the following types: binary, zoned decimal, packed decimal, binary floating-point, and decimal floating-point. Throughout this section, and in the MI instruction descriptions themselves, the term floating-point comprises both binary floating-point and decimal floating-point. Note that decimal floating-point is not a directly-supported data type for non-bound program instructions, for which decimal floating-point operands may only be accessed as arrays of characters. Decimal floating-point is a directly-supported data type for bound program instructions.
The result of an arithmetic operation is placed in the receiver based on the characteristics of the result and the attributes of the receiver.
Signed Binary Computation
The following rules apply to signed binary operands in arithmetic instructions:
An attempt to complement the maximum negative value causes a size exception.
Truncation is performed on the left; a size exception is signaled when significant high order digits are lost. Significant high-order digits are lost if all of the bits truncated on the left are not equal to the sign bit of the truncated result. The rightmost 16 or 32 bits of the result are placed in the receiving field for 2-byte and 4-byte binary receivers, respectively.
Padding is done on the left by propagating the sign from the high-order bit.
A zero result in a computation has a positive sign.
As a program attribute, binary size exceptions can be suppressed. When this attribute is used, the signed binary field will contain the appropriate truncated value. The OVRPGATR instruction will allow the binary size exception program attribute to be changed within the program.
Unsigned Binary Computation
The following rules apply to unsigned binary operands in arithmetic instructions:
Truncation is performed on the left; a size exception is signaled when significant high order digits are lost.
Padding is done on the left by propagating zeros.
Assigning a negative value to an unsigned binary field will cause a size exception.
As a program attribute, binary size exceptions can be suppressed. When this attribute is used, the unsigned binary field will contain the appropriate truncated value. The OVRPGATR instruction will allow the binary size exception program attribute to be changed within the program.
Packed Decimal Computation
The following rules apply to packed decimal operands in arithmetic instructions.
All digits are checked for valid encoding of hex 0 through hex 9. If an invalid digit is detected, a decimal data exception is signaled.
All signs are checked for valid encoding as follows:
Hex B or hex D means the value is negative.
Hex A, hex C, hex E, or hex F means the value is positive.
An invalid sign causes the decimal data exception to be signaled.
As a program attribute, the decimal data exception can be suppressed on the CPYNV instruction which does not use data pointers. When this attribute is used, as the instruction copies the source to the target an invalid sign is forced to a positive sign and an invalid digit is forced to zero. The OVRPGATR instruction will allow this program attribute to be changed within the program.
If alignment is necessary, source operands are aligned based on the assumed decimal point by truncating digits or padding with zeros on the right. Fractional digits that can affect the value to be placed in the receiving field participate in the calculation of the result.
If necessary, the operands are expanded to the length needed to perform the operation by padding with zeros on the left.
When aligning a source operand, if more than 31 decimal digits are required to contain the aligned value, a decimal point alignment exception is signaled. The exception is signaled when nonzero digits must be truncated from the left end of the aligned value to conform to a length of 31 decimal digits.
Length adjustment and decimal point alignment are performed at the left and right ends of the result, respectively, by truncating digits or padding with zeros to match the precision of the receiver operand. If nonzero digits are lost in truncating at the left, a size exception is signaled. If the optional round form of an instruction is being used, rounding on the right end occurs if any digits are truncated.
The sign of a receiver operand value is always set independently of any truncation and/or padding that could have taken place (that is, in the rightmost 4 bits of the rightmost byte of the result).
Arithmetic results are given the preferred sign (hex F for positive and hex D for negative). Zero values are given the preferred positive sign.
The four high-order bits of the leftmost byte of a packed receiver field with an even number of digits contains a value of hex 0 when no size exception is signalled. If a size exception is signaled then the value in this position is not predictable.
Zoned Decimal Computation
The rules for zoned decimal operands in arithmetic instructions are the same as those for packed decimal operands. In addition, the zone portion of each nonsigned digit in the receiver operand is set to a hex F.
Binary Floating-Point (BFP) Computation
The following rules apply to binary floating-point operands in computational instructions.
Binary floating-point operations are performed for instructions for which any of the operands are specified as binary floating-point. Fixed-operations are performed for instructions for which all operands are specified as either fixed-point binary or fixed-point decimal.
Certain computational attributes for binary floating-point operations can be controlled on a thread basis through use of the Store and Set Computational Attributes (SSCA) instruction. A default set of computational attributes is in effect when a thread is initiated. The computational attributes can be set by an invocation and are in effect for subsequent invocations unless changed with the Store and Set Computational Attributes (SSCA) instruction. When processing returns to an invocation from subsequent invocations, the computational attributes are reset to the attributes that were in effect when the invocation gave up control. Refer to the Store and Set Computational Attributes (SSCA) instruction for details about managing the computational attributes for a thread.
Alignment of the binary point, if necessary, is performed according to the requirements of the particular operation.
The operands are expanded to the length needed, or converted to the type needed according to the requirements of the particular operation. This occurs when an intermediate result is formed.
When all operands are binary floating-point and of the same length, operations are performed as if to infinite precision. This occurs unless specified otherwise in the particular instruction. These operations are only subject to one rounding error when the result is stored in the receiver.
When at least one of the operands is binary floating-point, but all operands are not binary floating-point of the same length, operations may not be performed as if to infinite precision. The result is formed using the short or long format, depending upon the precision required, to adequately provide for the requirements of the specified operation. Conversions of input values to the binary floating-point format appropriate for the operation are subject to rounding errors when the input value is not an integer value. The calculation of the result is also subject to a rounding error. A rounding error can also occur when the result is stored in the receiver. Therefore, these operations are subject to multiple rounding errors in the value stored in the receiver.
Binary floating-point operations produce an intermediate result that is a normalized number, signed zero, infinity, or a NaN binary floating-point value.
When the result is a normalized number, it is produced as if it were infinitely precise and unlimited in exponent range, unless stated otherwise in the specific instruction, or the operation involved conversions as previously stated. The normalized number may be the result of internal calculations that produced an internal result that did not satisfy the definition of a normalized number. In this case, a normalization operation is performed on the internal result; this operation appropriately shifts the bits of precision, while adjusting the exponent, until the leading one bit is just to the left of the binary point. The exponent is regarded as if its range were unlimited.
For an intermediate result value of signed 0, infinity, or an NaN, assigning this result to the receiver simply means representing its value in the receiver format.
If the receiver is fixed-point, an infinity or an NaN value causes the invalid floating-point conversion exception to be signaled. See "FLOATING-POINT EXCEPTIONS" for details. A signed 0 value is represented as the appropriate 0 value in the receiver format.
If the receiver is binary floating-point, the assignment of the result does not alter the result value to another type of binary floating-point value, as can happen for an intermediate result that is a normalized number.
When an intermediate result value of a normalized number is assigned to the receiver, the result may require an adjustment because it is outside the range of normalized numbers that can be represented in the receiver.
If the receiver is fixed-point, the normalized number is converted to the format of the receiver. Also, it is adjusted to the precision of the receiver under control of the rounding mode currently in effect for the thread unless overridden by specifying the optional round form of an instruction. The optional round form of an instruction is only allowed for operations that specify fixed-point receivers. Due to the possible adjustment in precision, the floating-point inexact result exception condition can be detected. Additionally, the assignment of the result value to the receiver can result in the signaling of the invalid floating-point conversion exception.
If the receiver is binary floating-point, the system performs several steps to provide for properly representing the normalized number in the receiver.
The initial step is to check for the floating-point underflow condition. This is done by verifying that the signed exponent of the result is not less than the minimum value (-126 for short format or -1022 for long format) for representation of normalized numbers in the receiver format. If it is not less than the minimum value, the operation continues with the rounding step. If it is less than the minimum value, a floating-point underflow exception condition may or may not be detected depending upon the mask state of the exception. When the exception is masked, the intermediate result is adjusted, as if to infinite precision, to a denormalized number appropriate for the format of the receiver, and the operation continues with the rounding step. The intermediate denormalized result is produced by shifting the significand of the intermediate result right and incrementing the exponent until the exponent attains the receiver format's fixed value for denormalized numbers (-126 for short format or -1022 for long format). As a result of the rounding step, the floating-point underflow occurrence indicator is set if the intermediate denormalized result cannot be represented in the receiver format. In this case, the intermediate denormalized result may be adjusted back to a normalized number, to signed 0, or remain a denormalized number. In any case, the result is no longer exact and, therefore, forces the floating-point underflow occurrence indicator to be set.
The next step, rounding, chooses a representation in the format of the result field for the intermediate result. The intermediate result is regarded to be of infinite precision. The rounding mode currently in effect controls the adjustment of the result value. If the adjustment of the result value causes a loss of nonzero digits from the significand, a floating-point inexact result exception condition is detected. As previously noted, detection of the inexact result condition on the adjustment of an intermediate denormalized result forces the setting of the floating-point underflow occurrence indicator regardless of the value to which the result is adjusted. In conjunction with the process of rounding, a check for the floating-point overflow condition is performed. This is done by verifying that the signed exponent of what is the rounded result, or what would have been the rounded result if the exponent range was unlimited, is not greater than the maximum value (127 for short format or 1023 for long format) for representation of normalized numbers in the receiver format. If it is not, the operation continues with the final step, which assigns the value of the intermediate result into the receiver. If it is, the floating-point overflow exception condition is detected. See the discussion of floating-point exceptions provided below for details.
The final step is to represent the value of the adjusted intermediate result in the binary floating-point element specified as the receiver. The adjusted value of the intermediate result may still be a normalized number, or it may have been altered to a denormalized number or signed 0.
Binary floating-point fields can only represent numeric values as normalized numbers, denormalized numbers, or signed 0. Therefore, the concept of an unnormalized number (one which would allow for a variable exponent in conjunction with one or more leading 0 bits prior to the first significand 1 bit) does not exist and cannot be represented.
BFP Rounding Modes
Four binary floating-point rounding modes are supported. For example, assume y is the infinitely precise number that is to be rounded. In addition, assume that y is bracketed most closely by x and z, where x is the largest representable value less than y, and z is the smallest representable value greater than y. Note that x or z may be infinity. The following diagram shows this relationship of x, y, and z on a scale of numerically progressing values where the vertical bars denote values representable in a floating-point format.Figure 1. Relationship of x, y, and z
If y is not exactly representable in the receiving field format, the rounding modes change y as follows:
Round to nearest with round to even in case of a tie is the default rounding mode in effect when a thread is initiated. For this rounding mode, y is rounded to the closer of x or z. If they are equally close, the even one (the one whose least significant bit is a 0) is chosen. For the purposes of this mode of rounding, infinity is treated as if it were even. Except when y is rounded to a value of infinity, the rounded result will differ from the infinitely precise result by at most half of the least significant digit position of the chosen value. This rounding mode differs slightly from the decimal round algorithm performed for the optional round form of an instruction. This rounding mode would round a value of 0.5 to 0, whereas the decimal round algorithm would round that value to 1.
Round toward positive infinity mode indicates that directed rounding upward is to occur. For this mode, y is rounded to z.
Round toward negative infinity mode indicates that directed rounding downward is to occur. For this mode, y is rounded to x.
Round toward zero mode indicates that truncation is to occur. For this mode, y is rounded to the smaller (in magnitude) of x or z.
BFP Conversions
Conversions between binary floating-point integers and fixed-point integer formats (binary or decimal with no fractional digits) will be exact, unless the number of significant digits of a source decimal value exceeds the precision constraints of a binary floating-point receiver.
Conversions between binary floating-point numbers and fixed-point decimal numbers are performed such that all the decimal digits specified for the decimal number are either used in or produced from the conversion. However, the precision provided by binary floating-point fields is not as great as that provided by fixed-point decimal fields. The short format provides unique representation of a maximum of 7 significant decimal digits of precision, and the long format provides for a maximum of 15. The leftmost nonzero digit of the decimal number is considered the start of the significant digits of the number.
When the system converts a fixed-point decimal value to binary floating-point, significant digits of the source decimal field beyond 7 (for short format) or 15 (for long format) may not be saved in the binary floating-point field; their only function is to provide for rounding and uniqueness of the conversion.
When the system converts a binary floating-point value to fixed-point decimal, significant digits produced in the receiver beyond the first 7 (for short format) or the first 15 (for long format) are correct relative to the specific source binary floating-point value. These digits, which exceed the precision constraints of the binary floating-point field, serve to provide for uniqueness of conversion and should be considered only as precise as the calculations that produced the binary floating-point number. The floating-point inexact result exception provides a means of detecting loss of precision in binary floating-point calculations.
When a round to nearest operation occurs, conversion from binary floating-point to decimal and back to binary floating-point is identical as long as the decimal string provides for a precision of 9 significant decimal digits for short format conversions and 17 significant decimal digits for long format conversions.
BFP Sign Issues
The sign of a product or a quotient is the exclusive OR of the operands' signs. The sign of a sum or of a difference differs from at most one of the operands' signs following the standard rules of algebra. The previous rules apply even when operands or results are 0 or infinite. The only exception is when the sum of two operands with opposite signs (or the difference of two operands with like signs) is exactly 0; the sign of that sum (or difference) depends on the current rounding mode for the thread.
For round toward negative infinity mode, the sign is -.
For all other rounding modes, the sign is +.
Conversions from binary floating-point preserve the source sign when the result is zero, except that the sign of zero cannot be represented in fixed-point binary results, and a packed or zoned decimal zero result is always positive. (In contrast, the source sign is always preserved when converting decimal floating-point to packed or zoned decimal)
BFP Special Values
Quiet NaNs (QNaNs) in source operands are moved into binary floating-point receivers. Signaling NaNs (SNaNs) in source operands are changed to QNaNs and moved into binary floating-point receivers when the floating-point invalid operand exception is masked. If more than one source operand is a NaN, then the NaN moved into the receiver is the NaN with the largest fraction field value. For the purpose of the comparison, all of the input NaNs are considered quiet. Additionally, if the binary floating-point receiver is longer than the source field that supplied the NaN, the resulting QNaN is set with the fraction field value from the source padded with 0 bits on the right out to the float receiver fraction field length. The sign field of the NaN set into the receiver is preserved with the value it contained in the source.
SNaNs in source operands force detection of the floating-point invalid operand exception. An exception to this is when a numeric value operation copies the value represented in a source binary floating-point element to a receiver of the same format. This is defined as a simple move operation and the invalid floating-point operation exception is not detected if the source represents an SNaN.
Infinity values in source operands can be used in arithmetic operations according to the standard rules of algebra. They produce a correctly signed infinity value in the receiver, unless otherwise specified by a specific instruction. Negative infinity compares less than every finite value, and every finite value compares less than positive infinity.
BFP Examples
The following are examples of binary floating-point computations. See the discussion of binary floating-point elements for an explanation of the syntax used in these examples.
This example shows an add operation (A = B + C) executed as an Add Numeric instruction (ADDN A,B,C) involving all short format operands.
Initially, the add operation is shown as:
Element Value in Hexadecimal
Conceptional Numeric Value
Comments
C
3F800000
0 NUM +1.00000000000000000000000
Value of C, +1
B
40400000
+1 NUM +1.10000000000000000000000
Value of B, +3
__
_________
______________________________________
(add operation produces)
A
40800000
+2 NUM +1.00000000000000000000000
Result value +4
Internally, the addition operation is shown as:
C
+1 NUM +0.10000000000000000000000
Aligned value of C
B
+1 NUM +1.1000000000000000000000
Value of B
__
_____________________________________
(add operation produces)
+1 NUM +10.000000000000000000000000
The internal result
*
(normalization operation produces)
+2 NUM +1.0000000000000000000000000
The intermediate result
*
(rounding operation produces)
A
+2 NUM +1.00000000000000000000000
Value of A
This example shows an add operation (A = B + C) executed as an Add Numeric instruction (ADDN A,B,C) involving all short format operands with the round to nearest rounding mode in effect.
Initially, the addition operation is shown as:
Element Value in Hexadecimal
Conceptional Numeric Value
Comments
C
3FFFFFFE
0 NUM +1.11111111111111111111110
Value of C, almost +2
B
407FFFFC
+1 NUM +1.11111111111111111111100
Value of B, almost +4
__
________
______________________________________
(add operation produces)
A
40BFFFFE
+2 NUM +1.01111111111111111111110
Result value, almost +6
Internally, the addition operation is shown as:
C
+1 NUM +0.111111111111111111111110
Aligned value of C
B
+1 NUM +1.11111111111111111111100
Value of B
__
______________________________________
(add operation produces)
+1 NUM +10.111111111111111111110110
The internal result
*
(normalization operation produces)
+2 NUM +1.0111111111111111111110110
The intermediate result
*
(rounding operation produces)
A
+2 NUM +1.01111111111111111111110
Value of A
Decimal Floating-Point
Decimal Floating-Point (DFP) Computation
The following considerations apply to decimal floating-point (DFP) operands in computational instructions.
DFP Number Representation
A DFP finite number consists of three components: a sign bit, a signed exponent, and a coefficient. The signed exponent is a signed binary integer. The coefficient consists of a number of decimal digits, which are to the left of the implied decimal point. The least-significant digit of the coefficient is called the units digit. The numerical value of a DFP finite number is represented as (-1)sign × coefficient × 10exponent and the unit value of this number is (1 × 10exponent), which is called the quantum.
DFP finite numbers are not normalized. This allows leading zeros and trailing zeros to exist in the coefficient. This unnormalized DFP number representation allows some values to have redundant forms; each form represents the DFP number with a different combination of the coefficient value and the exponent value. For example, 1000000 × 105 and 10 × 1010 are two different forms of the same numerical value. A form of this number representation carries information about both the numerical value and the quantum of a DFP finite number. In the first form, the quantum is 1 × 105, whereas in the second form, the quantum is 1 × 1010.
The significant digits of a DFP finite number are the digits in the coefficient beginning with the most significant nonzero digit and ending with the units digit.
DFP Data Format
DFP numbers and NaNs (see Classes of DFP Data, below) may be represented in any of three data formats: DFP32, DFP64, or DFP128. These are otherwise known as 4-byte, 8-byte, and 16-byte decimal floating-point formats, respectively. The contents of each data format represent encoded information. Special codes are assigned to NaNs and infinities. Different formats support different sizes in both coefficient and exponent.
DFP32 is a storage format only. That is, DFP32 values may be loaded, stored, copied, and converted to other data types; but no computation or comparison operations are provided for DFP32 values. Such values may be converted to DFP64 or DFP128 before participating in computation or comparison, with results subsequently converted back to DFP32 for storage.
The sign is encoded as a one-bit binary value. The coefficient is encoded as an unsigned decimal integer in two distinct parts. The leftmost digit of the coefficient is encoded as part of the combination field; the remaining digits of the coefficient are encoded in the coefficient continuation field. Similarly, the exponent is represented in two parts. However, prior to encoding, the exponent is converted to an unsigned binary value called the biased exponent by adding a bias value which is a constant for each format. The two leftmost bits of the biased exponent are encoded in the combination field, and the remaining 6, 8, or 12 bits (depending on the format) are encoded in the biased exponent continuation field.
Fields Within the Data Format
The DFP data representation comprises four fields, as described below for each of the three formats:
Table 1. Bit positions for DFP data format fields
Format
S
C
BEC
CC
DFP32
0
1:5
6:11
12:31
DFP64
0
1:5
6:13
14:63
DFP128
0
1:5
6:17
18:127
The fields are defined as follows:
Sign bit (S)
The sign bit is in bit 0 of each format, and is zero for plus and one for minus.
Combination field (C)
This is a 5-bit field which contains the encoding of NaN or infinity, or the two leftmost bits of the biased exponent (BEhigh) and the leftmost digit (LMD) of the coefficient. The following tables show the encoding. Note that there are insufficient bits to encode the value BEhigh = 11b.
Table 2. Encoding of the C field for special symbols
Table 3. Encoding of the C field for finite numbers
LMD
BEhigh = 00b
BEhigh = 01b
BEhigh = 10b
0
00000
01000
10000
1
00001
01001
10001
2
00010
01010
10010
3
00011
01011
10011
4
00100
01100
10100
5
00101
01101
10101
6
00110
01110
10110
7
00111
01111
10111
8
11000
11010
11100
9
11001
11011
11101
Biased Exponent Continuation field (BEC)
For DFP finite numbers, this field contains the remaining bits of the biased exponent. For NaNs, the leftmost bit in this field is used to distinguish a Quiet NaN from a Signaling NaN; the remaining bits in a source operand are ignored, and they are set to zeros in a target operand by most operations. For infinities, bits in this field of a source operand are ignored, and they are set to zeros in a target operand by all operations.
Coefficient Continuation field (CC)
For DFP finite numbers, this field contains the remaining coefficient digits. For NaNs, this field may be used to contain diagnostic information. For infinities, contents in this field of a source operand are ignored, and they are set to zeros in a target operand by most operations. The CC field is a multiple of 10-bit blocks. The multiple depends on the format. Each 10-bit block is called a Densely Packed Decimal (DPD) block, and represents three decimal digits.
Summary of DFP Data Formats
The properties of the three DFP formats are summarized in the following table:
Table 4. Summary of DFP formats
Property
DFP32
DFP64
DFP128
Format length (bits)
32
64
128
Combination length (bits)
5
5
5
Biased exponent continuation length (bits)
6
8
12
Maximum biased exponent
191
767
12,287
Coefficient continuation length (bits)
20
50
110
Precision (digits), p
7
16
34
Maximum exponent, Xmax
90
369
6111
Minimum exponent, Xmin
-101
-398
-6176
Exponent bias
101
398
6176
Largest (in magnitude) normal number, Nmax
(107 - 1) × 1090
(1016 - 1) × 10369
(1034 - 1) × 106111
Smallest (in magnitude) normal number, Nmin
1 × 10-95
1 × 10-383
1 × 10-6143
Smallest (in magnitude) subnormal number, Dmin
1 × 10-101
1 × 10-398
1 × 10-6176
Classes of DFP Data
There are six classes of DFP data, which include numeric and nonnumeric entities. The numeric entities include the Zero, Subnormal Number, Normal Number, and Infinity data classes. The nonnumeric entities include the Quiet NaN and Signaling NaN data classes. The value of a DFP finite number, including zero, subnormal number, and normal number, is a quantization of the real number based on the data format.
Zeros
Zeros have a zero coefficient and any representable value in the exponent. A +0 is distinct from -0, and zeros with different exponents are distinct, except that comparison treats them as equal.
Subnormal Numbers
Subnormal numbers have values that are smaller than Nmin and greater than zero in magnitude. Intuitively, a subnormal number is one that cannot be represented in a particular DFP data format without using leading zeros.
Normal Numbers
A normal number is a nonzero finite number whose magnitude is between Nmin and Nmax inclusively.
Infinities
An infinity is represented by the bit pattern 11110 in the combination field. When an operation is defined to generate an infinity as the result, a default infinity is sometimes supplied. A default infinity has all bits in the BEC and CC fields set to zeros.
When used as a source operand, the contents of the BEC and CC fields of an infinity are usually ignored. In all cases, the BEC field of a generated infinity contains all zeros.
Infinities can participate in most arithmetic operations and give a consistent result. In comparisons, any +&infinity. compares greater than any finite number, and any -&infinity. compares less than any finite number. All +&infinity. are compared equal and all -&infinity. are compared equal.
Signaling and Quiet NaNs
A NaN (Not-a-Number) is represented by the bit pattern 11111 in the combination field. There are two types of NaNs: Signaling and Quiet. A Signaling NaN (SNaN) is distinguished from a Quiet NaN (QNaN) by the leftmost bit in the BEC field: '0' for the QNaN, and '1' for the SNaN. A special QNaN is sometimes supplied as the default QNaN for a disabled invalid-operand exception; it has a plus sign, and all bits in the BEC and CC fields are set to zeros.
Normally, source QNaNs are propagated during operations so that they will remain visible at the end. When a QNaN is propagated, the sign is preserved, the decimal value of the CC field is preserved, and the contents in the BEC field are set to zero.
A source SNaN generally causes an invalid-operand exception. If the exception is masked, the SNaN is converted to a corresponding QNaN which is propagated. The differences between an SNaN and the corresponding QNaN are that the contents of the BEC field of the QNaN are set to zero, and the CC field value from the SNaN is encoded in the CC field of the QNaN.
When more than one source operand for an operation is a NaN, the NaN which is propagated is unpredictable, except that a corresponding QNaN for a source SNaN will be chosen in preference over a source QNaN.
DFP Execution Model
DFP operations are performed as if they first produce an intermediate result with infinite precision and having unbounded range. The intermediate result is then rounded to the destination's precision according to one of the eight DFP rounding modes. If the rounded result has only one form, it is delivered as the final result; if the rounded result has redundant forms, then an ideal exponent is used to select the form of the final result. The ideal exponent determines the form, not the value, of the final result. See section Formation of Final Result, below, for a description of how the ideal exponent is determined for each operation.
Rounding
Rounding takes a number regarded as infinitely precise and, if necessary, modifies it to fit the destination's precision. The destination's precision of an operation defines the set of permissible resultant values. For most operations, the destination's precision is the target-format precision, and the permissible resultant values are those values representable in the target format. For some special operations, the destination precision is constrained by both the target format and some additional restrictions, and the permissible resultant values are a subset of the values representable in the target format.
Let Y be the intermediate result of a DFP operation. Y may or may not fit in the destination's precision. If Y is exactly one of the permissible representable resultant values, then the final result in all rounding modes is Y. Otherwise, either X or Z is chosen to approximate the result, where X < Y < Z, and X and Z are the nearest permissible resultant values.
Figure 2. Relationship of X, Y, and Z
Round to Nearest, Ties to Even
Choose the value that is closer to Y (X or Z). In case of a tie, choose the one whose units digit would have been even in the form with the largest common quantum of the two permissible resultant values. However, an infinitely precise result with magnitude at least (Nmax + 0.5Q(Nmax)), where Q(Nmax) is the quantum of Nmax, is rounded to infinity with no change in sign.
Round toward Zero
Choose the smaller in magnitude (X given a positive infinitely precise result, or Z given a negative infinitely precise result).
Round toward Positive Infinity
Choose Z.
Round toward Negative Infinity
Choose X.
Round to Nearest, Ties Away from Zero
Choose the value that is closer to Y (X or Z). In case of a tie, choose the larger in magnitude (Z given a positive infinitely precise result, or X given a negative infinitely precise result). However, an infinitely precise result with magnitude at least (Nmax + 0.5Q(Nmax)), where Q(Nmax) is the quantum of Nmax, is rounded to infinity with no change in sign.
Round to Nearest, Ties toward Zero
Choose the value that is closer to Y (X or Z). In case of a tie, choose the smaller in magnitude (X given a positive infinitely precise result, or Z given a negative infinitely precise result). However, an infinitely precise result with magnitude greater than (Nmax + 0.5Q(Nmax)), where Q(Nmax) is the quantum of Nmax, is rounded to infinity with no change in sign.
Round Away from Zero
Choose the larger in magnitude (Z given a positive infinitely precise result, or X given a negative infinitely precise result).
Round to Prepare for Shorter Precision
Choose the smaller in magnitude (X given a positive infinitely precise result, or Z given a negative infinitely precise result). If the selected value is inexact and the units digit of the selected value is either 0 or 5, then the digit is incremented by one and the incremented result is delivered. In all other cases, the selected value is delivered. When a value has redundant forms, the units digit is determined by using the form that has the smallest exponent.
Rounding Mode Specification
Unless otherwise specified in the MI instruction definition, the rounding mode used by an operation is the current decimal floating-point rounding mode. Note that the current decimal floating-point rounding mode is distinct from the current binary floating-point rounding mode. The current DFP rounding mode can be retrieved programmatically using the RETCA MI instruction, modified using the SETCA MI instruction, and both retrieved and set using the SSCA MI instruction. The eight possible DFP rounding modes are encoded in the current DFP rounding mode as follows:
Table 5. Encoding of Current DFP Rounding Mode
Encoding
Mode
0 0 0
Round to nearest, ties to even (default)
0 0 1
Round toward zero
0 1 0
Round toward positive infinity
0 1 1
Round toward negative infinity
1 0 0
Round to nearest, ties away from zero
1 0 1
Round to nearest, ties toward zero
1 1 0
Round away from zero
1 1 1
Round to prepare for shorter precision
Formation of Final Result
An ideal exponent is defined for each DFP operation that produces a DFP data operand.
Use of Ideal Exponent
For all DFP operations, if the rounded intermediate result has only one form, then that form is delivered as the final result. If the rounded intermediate result has redundant forms and is exact, then the form with the exponent closest to the ideal exponent is delivered. If the rounded intermediate result has redundant forms and is inexact, then the form with the smallest exponent is delivered.
The following table specifies the ideal exponent for each operation, given that E1 is the exponent of operand 1, and E2 is the exponent of operand 2 (if present).
Table 6. Summary of Ideal Exponents
Operations
Ideal Exponent
Add
min(E1,E2)
Subtract
min(E1,E2)
Multiply
E1+E2
Divide
E1-E2
Quantize
E1
Convert between DFP formats
E1
Convert from binary
0
Convert from packed decimal
0
Convert from decimal form
0
Arithmetic Operations
Four arithmetic operations are provided: Add, Subtract, Multiply, and Divide.
Sign of Arithmetic Result
The following rules govern the sign of an arithmetic operation when the operation does not yield an exception. They apply even when the operands or results are zeros or infinities.
The sign of the result of an add operation is the sign of the source operand having the larger magnitude. When the sum of two operands with opposite signs is exactly zero, the sign of the result is positive in all rounding modes except Round toward Negative Infinity, in which case the sign is negative.
The sign of the result of the subtract operation x-y is the same as the sign of the result of the add operation x+(-y).
The sign of the result of a multiply or divide operation is the exclusive-OR of the signs of the source operands.
Compare Operations
For finite numbers, comparisons are performed on values, not forms. All redundant forms of a DFP number are treated as equal.
Comparisons are always exact and cannot cause an inexact exception.
Comparison ignores the sign of zero. That is, +0 equals -0.
Infinities with like sign compare equal. That is, +&infinity. equals +&infinity., and -&infinity. equals -&infinity..
For almost all instructions, a NaN compares as unordered with any other operand, whether a finite number, an infinity, or another NaN, including itself. The DFPCMP (Perform Decimal Floating-Point Comparison) instruction, however, provides an artificial ordered comparison of NaNs.
For comparison instructions other than DFPCMP(Perform Decimal Floating-Point Comparison), if at least one of the comparands is a NaN, a floating-point invalid operand condition is detected.
Quantum Adjustment Operations
The Quantize operation is used to adjust a DFP number to the form that has the specified target exponent.
Conversion Operations
There are two kinds of conversion operations: data-format conversion and data-type conversion.
Data-Format Conversion
The Convert Decimal Floating-Point to Decimal Floating-Point (CVDFPDFP) instruction is used to convert a 4-byte, 8-byte, or 16-byte DFP operand to a DFP value of a different length. This operation may either provide a widening or a narrowing effect.
When converting a finite number to a wider format, the result is exact. When converting a finite number to a narrower format, the source operand is rounded to the target-format precision.
When converting a finite number, the ideal exponent of the result is the source exponent.
When converting an SNaN between DFP32 and DFP64, it may be converted to
an SNaN without causing an invalid-operand exception.1 When converting an SNaN between DFP32 and DFP128, or between DFP64 and DFP128, the invalid-operand exception occurs; if the invalid-operation exception is disabled, the result is then converted to the corresponding QNaN.
Data-Type Conversion
Operations are provided to convert a number between the DFP data type and signed binary; between DFP and unsigned binary; between DFP and packed decimal; and between DFP and decimal form.
Conversion of a signed or unsigned 64-bit binary integer to a DFP128 number is always exact.
Conversion of a DFP number to a signed or unsigned 64-bit binary integer results in an invalid-operand exception when the converted value does not fit into the target format, or when the source operand is an infinity or NaN.
Floating-Point Exceptions
The following floating-point exception conditions can be detected during floating-point operations:
Floating-point overflow
Floating-point underflow
Floating-point zero divide
Floating-point inexact result
Floating-point invalid operand
Floating-point invalid conversion
Associated with each of the first five exceptions is a set of mask and occurrence bits. Floating-point invalid conversion has an exception occurrence bit, but uses the floating-point invalid operand mask bit.
The mask bit determines whether an exception is signaled. If the mask bit is 0, the exception is considered to be masked and is not signaled. If the mask bit is 1, the exception is considered to be unmasked and is signaled. When a thread is initiated, the default mask bit values specify that the floating-point inexact result is masked, and all other exceptions are unmasked. The mask bits can be tested and set with the Store And Set Computational Attributes (SSCA), Retrieve Computational Attributes (RETCA), and Set Computational Attributes (SETCA) instructions. The result of floating-point exceptions can vary depending upon whether the exception is masked or unmasked.
The occurrence bit records the occurrence of the exception condition whether or not the exception is masked when it is detected. A value of 1 is set to indicate an exception condition has occurred. A value of 0 indicates that the exception condition has not occurred. When a thread is initiated, the default occurrence bit values are all 0's. The occurrence bits can be set (0 or 1) with the Store And Set Computational Attributes (SSCA) instruction, or with the Set Computational Attributes (SETCA) instruction.
Floating-Point Overflow
Binary Floating-Point
A floating-point overflow condition is detected whenever the largest finite number that can be represented in the format of the floating-point receiver is exceeded in magnitude by what would have been the rounded floating-point result if the range of the exponent was unlimited. For this to occur, the signed exponent of the result must exceed 127 for a short format receiver or 1023 for a long format receiver.
The occurrence of the floating-point overflow condition is indicated through the setting of the floating-point overflow occurrence bit.
The setting of the floating-point overflow mask affects the result of the operation as follows:
If the exception is masked, the exception is not signaled, the floating-point inexact result is detected, and the result of the operation is determined by the rounding mode and the sign of the intermediate result as follows:
Round to nearest mode produces infinity with the sign of the intermediate result.
Round toward zero mode produces the receiver format's largest finite number with the sign of the intermediate result.
Round toward negative infinity mode produces the receiver format's largest finite number for positive overflows, and negative infinity for negative overflows.
Round toward positive infinity mode produces the receiver format's most negative finite number for negative overflows, and positive infinity for positive overflows.
If the exception is not masked, the exception is signaled, the value of the receiver operand is unpredictable, and the exception data available depends upon the operation being performed.
An overflow detected on a conversion operation from the long to the short floating-point format results in a long format value rounded to a short format precision to be provided in the exception data.
An overflow detected on a conversion operation from a decimal form of a floating-point value, on the scaling operation performed in the SCALE instruction, or on certain cases of the Compute Math Function instruction (CMF1, CMF2) causes a long format system default QNaN value to be provided in the exception data.
An overflow detected on an arithmetic operation causes a long format value to be provided in the exception data. For a short format receiver, the long format value provided is rounded to short format precision. For a long format receiver, the long format value provided is a correctly rounded significand, a correct sign, and a modified exponent. The modified exponent is set from the overflowed normal biased exponent minus a bias adjust value of 1536. This bias adjust value (1536) translates overflowed biased exponents as nearly as possible to the middle of the representable biased exponent range for the long format. An exception handler can then be provided with appropriate information for later reconstruction of the correct result. The following diagram summarizes the relationships among the overflowed values for the signed exponent, the normal biased exponent, and the modified biased exponent.
Table 7. Floating point overflow
Overflowed Exponent
Signed
Normal Biased
Modified Biased
Minimum value
1024
2047
511
Maximum value
2047
3070
1534
Decimal Floating-Point
A floating-point overflow condition is detected whenever the largest finite number that can be represented in the format of the floating-point receiver is exceeded in magnitude by what would have been the rounded floating-point result if the range of the exponent were unbounded. For this to occur, the signed exponent of the result must exceed 191 for a DFP32 receiver, 767 for a DFP64 receiver, or 12,287 for a DFP128 receiver.
The occurrence of the floating-point overflow condition is indicated through the setting of the floating-point overflow occurrence bit.
The setting of the floating-point overflow mask affects the result of the operation as follows:
When the overflow exception is unmasked, the following actions are taken:
The infinitely precise result is divided by 10&alpha.. That is, the exponent adjustment &alpha. is subtracted from the exponent. This is called the wrapped result. The exponent adjustment for all operations, except for narrowing operations from one DFP format to another, is 576 for DFP64, and 9216 for DFP128. For narrowing operations, the exponent adjustment is 192 for the source format of DFP64, and 3072 for the source format of DFP128.
The wrapped result is rounded to the target-format precision. This is called the wrapped rounded result.
If the wrapped rounded result has only one form, it is provided to the receiver. If the wrapped rounded result has redundant forms and is exact, the result of the form that has the exponent closest to the wrapped ideal exponent is provided. If the wrapped rounded result has redundant forms and is inexact, the result of the form that has the smallest exponent is provided. The wrapped ideal exponent is the result of subtracting the exponent adjustment from the ideal exponent.
When the overflow exception is masked, the following actions are taken:
The floating-point inexact result condition is detected.
The result provided to the receiver is determined by the rounding mode and the sign of the intermediate result as follows.
Table 8. Decimal floating-point overflow results when exception is disabled
Rounding Mode
Positive Intermediate Result
Negative Intermediate Result
Round to Nearest, Ties to Even
+&infinity.
-&infinity.
Round toward Zero
+Nmax
-Nmax
Round toward Positive Infinity
+&infinity.
-Nmax
Round toward Negative Infinity
+Nmax
-&infinity.
Round to Nearest, Ties Away from Zero
+&infinity.
-&infinity.
Round to Nearest, Ties toward Zero
+&infinity.
-&infinity.
Round Away from Zero
+&infinity.
-&infinity.
Round to Prepare for Shorter Precision
+Nmax
-Nmax
Floating-Point Underflow
Binary Floating-Point
A floating-point underflow condition may be detected when a result that is not 0 is examined prior to rounding and is found to have too small an exponent to be represented in the format of the receiver without being denormalized. For the underflow condition to exist, the signed exponent of the result must be less than -126 for a short format receiver or less than -1022 for a long format receiver.
The value (0 or 1) of the floating-point underflow mask bit affects the detection of the exception condition as well as the result of the operation.
If the exception is masked (bit value equals 0), the underflow condition is only detected and indicated through the setting of its related occurrence bit if the denormalized number for the intermediate result cannot be exactly represented in the floating-point receiver. In this case, the floating-point receiver is set with a value that is produced by first denormalizing the unrounded result, then rounding, then moving the result to its receiver. Only the occurrence bit for underflow is set, the underflow exception is not signaled.
If the exception is not masked (bit value equals 1), the floating-point underflow condition is indicated through the setting of the floating-point underflow occurrence bit and the exception is signaled whenever the signed exponent of the result is too small for a normalized number to be represented in the receiver. The value of the receiver operand is unpredictable, and the exception data available depends upon the operation being performed.
A long format value rounded to short format precision is available if an underflow condition is detected on a conversion operation from the long to the short floating-point format.
A long floating-point system default QNaN value is available if an underflow condition is detected on a conversion from a decimal form of a floating-point value, on the scale operation performed for the SCALE instruction, or on the Compute Math Function (CMF1, CMF2) instructions.
A long format value is available if an underflow condition is detected on an arithmetic operation. For a short format receiver, the long format value available is rounded to short format precision. For a long format receiver, the long format value available is a correctly rounded significand, a correct sign, and a modified exponent. The modified exponent is set from the underflowed normal biased exponent plus 1536. This bias adjust value translates underflowed biased exponents as nearly as possible to the middle of the representable biased exponent range for the long format. This provides the appropriate information to an exception handler for later reconstruction of the correct result. The following diagram summarizes the relationship between the underflowed values for the signed exponent, the normal biased exponent, and the modified biased exponent.
Table 9. Floating point underflow
Underflowed Exponent
Signed
Normal Biased
Modified Biased
Maximum value
-1022
1
1537
Minimum value
-2148
-1125
411
The maximum underflowed exponent value in the previous diagram occurs when rounding of the underflowed value increases its value back above the underflow threshold.
The minimum underflowed exponent value in the previous diagram occurs when two minimum valued denormalized numbers are multiplied together to produce an intermediate result with a signed exponent of the indicated value.
Decimal Floating-Point
A floating-point underflow condition may be detected when a result, computed as though both the precision and exponent range were unbounded, would be nonzero and less than the receiver format's smallest normal number, Nmin, in magnitude. The infinitely precise result is said to be tiny.
The value (0 or 1) of the floating-point underflow mask bit affects the detection of the exception condition as well as the result of the operation.
If the exception is masked (bit value equals 0), the underflow condition is only detected and indicated through the setting of its related occurrence bit if: (a) the infinitely precise result is tiny; and (b) the delivered result value differs from what would have been computed, had both the precision and the exponent range been unbounded.
The infinitely precise result is rounded to the precision of the receiver.
The rounded result is provided to the receiver. If the rounded result has redundant forms, the form with exponent closest to the ideal exponent is provided.
If the exception is not masked (bit value equals 1), the floating-point underflow condition is indicated through the setting of the floating-point underflow occurrence bit, and the exception is signaled, whenever the infinitely precise result is tiny.
The infinitely precise result is multiplied by 10&alpha.. That is, the exponent adjustment &alpha. is added to the exponent. This is called the wrapped result. The exponent adjustment for all operations is 576 for DFP64, and 9216 for DFP128.
The wrapped result is rounded to the receiver's precision. This is called the wrapped rounded result.
If the wrapped rounded result has only one form, it is provided to the receiver. If the wrapped rounded result has redundant forms and is exact, the form with exponent closest to the wrapped ideal exponent is provided. If the wrapped rounded result has redundant forms and is inexact, the form with the smallest exponent is provided. The wrapped ideal exponent is the result of adding the exponent adjustment to the ideal exponent.
Floating-Point Zero Divide
A floating-point zero divide condition is detected for floating-point division if the divisor is zero and the dividend is a finite nonzero number. The floating-point zero divide condition is indicated through the setting of the floating-point zero divide occurrence bit. The setting of the floating-point zero divide mask bit affects the result of the operation.
If the exception is masked (bit value equals 0), the result of the operation is a correctly signed infinity value (exclusive OR of the operands' signs), and the exception is not signaled.
If the exception is not masked (bit value equals 1), the operation is suppressed, and the exception is signaled.
These actions are identical for both binary and decimal floating-point operations.
Floating-Point Inexact Result
A floating-point inexact result condition is detected (in the absence of the floating-point invalid operand exception condition) if the rounded result of an operation is not exact.
The rounded result of an operation is not exact when the rounding operation on an intermediate result causes a loss of nonzero significand digits in representing the value of the result in the receiver. This applies to fixed-point receivers of floating-point operations as well as to floating-point receivers.
The result of an operation is not exact when a floating-point overflow condition occurs while that condition is masked. The receiver is set at either infinity, or the receiver format's largest magnitude finite number.
The floating-point inexact result condition is indicated by the floating-point inexact result occurrence bit.
If the floating-point inexact result exception is either masked or unmasked, the rounded or overflowed result is moved to the receiver. If the exception is masked (bit value equals 0), the exception is not signaled. If the exception is not masked (bit value equals 1), the exception is signaled.
These actions are identical for both binary and decimal floating-point operations.
Floating-Point Invalid Operand
A floating-point invalid operand condition is detected when an operand is invalid for the operation to be performed:
A source operand is a signaling NaN. (However, when converting from DFP32 to DFP64, or from DFP64 to DFP32, an SNaN in the receiver's format is produced without delivering an exception.)
Addition of infinities of different signs or subtraction of infinities of the same sign.
Multiplication of 0 times infinity.
Division of 0 by 0, or infinity by infinity.
Computing a math function for certain operand combinations. Refer to the documentation for the Compute Math Function instructions (CMF1 and CMF2) for details.
Floating-point values compare unordered, and no branch or indicator options are specified for the unordered, negation of unordered, equal, or negation of equal conditions when the Compare Numeric Value (CMPNV) instruction is executed.
Floating-point values compare unordered during any other comparison operation.
An unordered resultant condition occurs on a computational instruction when the result is a NaN, and branch or indicator conditions are specified, but none of the unordered, negation of unordered, zero, or negation of zero conditions are selected.
A DFP quantize operation would result in a coefficient having more significant digits than the receiver's precision.
Binary Floating-Point
The floating-point invalid operand condition is indicated by the floating-point invalid operand occurrence bit.
The value (0 or 1) of the floating-point invalid operand mask bit affects the result of the operation.
If the exception is masked (bit value equals 0), the exception is not signaled.
If the exception condition is detected on a comparison operation, and the condition is caused by an invalid operand associated with the specified branch or indicator options, the receiving field (if applicable) is left intact with the calculated result of the operation.
If the exception is detected during an operation in which a floating-point result is to be stored, the result of the operation is a QNaN value.
If the exception was due to one or more operands being an SNaN, then the input NaN with the largest fraction field value is propagated into the receiver with its mask state set to masked. All of the input NaNs are considered to be QNaNs for the compare operation. Additionally, if the receiver format is longer than the source field that supplied the NaN, the resulting QNaN is set with the fraction field value from the source, and padded with 0 bits on the right out to the float receiver fraction field length.
If the exception was not due to an operand being an SNaN, then the resulting QNaN that is propagated into the receiver is the system default QNaN which is appropriately represented in the receiver format.
If the exception is not masked, the exception is signaled and the value of the receiver operand is unpredictable. The exception data available indicates whether or not the exception was detected due to an invalid branch or indicator option.
Decimal Floating-Point
The floating-point invalid operand condition is indicated by the floating-point invalid operand occurrence bit.
The value (0 or 1) of the floating-point invalid operand mask bit affects the result of the operation.
If the exception is masked (bit value equals 0), the exception is not signaled.
If the operation is an arithmetic or quantize operation, or a conversion between two DFP formats, a QNaN is provided to the receiver.
If the operation is a conversion from DFP to signed binary, the receiver is set to the most positive 64-bit signed binary integer if the source operand is positive, or to the most negative 64-bit signed binary integer if the source operand is negative or a NaN.
If the operation is a conversion from DFP to unsigned binary, the receiver is set to the most positive 64-bit unsigned binary integer regardless of the value of the source operand.
If the exception is unmasked (bit value equals 1), the exception is signaled and the value of the receiver operand is implementation-dependent.
Floating-Point Invalid Conversion
Conversion operations from floating-point to other formats can cause the floating-point invalid conversion exception to be signaled. This exception can be masked by clearing the floating-point invalid operand exception flag in the computational attributes. Masking suppresses invalid conversion exceptions for decimal floating-point operations, but does not suppress those exceptions for binary floating-point operations. For details of this exception, refer to the invalid floating-point conversion (hex 0C0C) exception documentation.
The user is advised not to develop a dependency on an SNaN being converted silently from DFP32 to DFP64 or vice versa, as this may change in future implementations.