スキャン・シェアリング とは、他のスキャンによる処理を利用するスキャン機能のことです。 共有作業の例としては、ディスク・ページ読み取り、ディスク・シーク、バッファー・プール内容の再利用、圧縮解除などがあります。
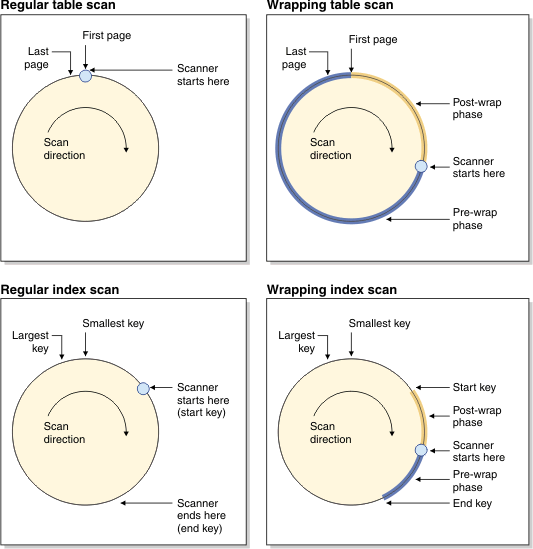
大きな表の表スキャンまたはマルチディメンション・クラスタリング (MDC) ブロック索引スキャンなどの負荷の大きなスキャンの場合、他のスキャンとページ読み取りを共有するのが適していることがあります。 そうした共有スキャンは表内の任意の点から開始して、既にバッファー・プール内にあるページを活用できます。 共有スキャンが表の最後に到達すると、先頭から継続され、開始点に到達すると完了します。 これは、
ラッピング・スキャン と呼ばれます。
図 1 は、表と索引の両方について、通常のスキャンとラッピング・スキャンの違いを示しています。
図1: 通常のスキャンとラッピング・スキャンの概念ビュー
デフォルトでスキャン・シェアリング・フィーチャーは有効にされていて、スキャン・シェアリングと折り返しが適格かどうかは SQL コンパイラーによって自動的に判別されます。 実行時に、コンパイル時には把握されていなかった要因に基づいて、適格なスキャンが共有または折り返しを行うこともあれば、行わないこともあります。
共有スキャナーは、
共有グループ で管理されます。 こうしたグループは、共有の利点を最大化できるように、可能な限り長期間に渡りそのメンバーを一緒に維持します。 他のスキャンより速いスキャンがあると、ページ共有の利点が失われる可能性があります。 そのような場合、最初のスキャンがアクセスするバッファー・プール・ページが、その共有グループ内の他のスキャンがアクセスできるようになる前に、バッファー・プールから消去されてしまうことがあります。 データ・サーバーは、同じ共有グループ内にある 2 つのスキャンの距離を、それらの間にあるバッファー・プール・ページ数によって測定します。 またデータ・サーバーは、スキャンの速度をモニターします。 同じスキャン・グループ内にある 2 つのスキャンの距離が長くなり過ぎる場合には、バッファー・プール・ページを共有できない恐れがあります。 こうした可能性を減らすには、速度の速いスキャンをスロットル化して、データ・ページが消去される前に遅いスキャンがそうしたページにアクセスできるようにします。
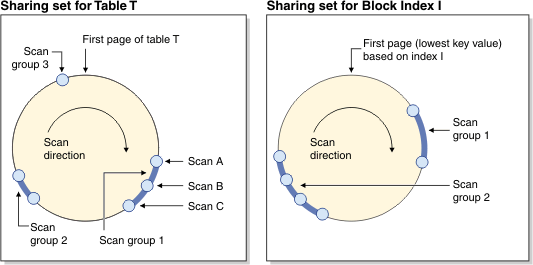
図 2 は、2 つの共有セットを示しています。1 つは表用、もう 1 つはブロック索引用です。
共有セット は、同じアクセス・メカニズム (例えば、表スキャンまたはブロック索引スキャン) を使用して同じオブジェクト (例えば、表) にアクセスしている共有グループの集合です。 表スキャンの場合、ページ読み取り順序はページ ID の昇順で、ブロック索引スキャンの場合、ページ読み取り順序はキー値の昇順です。
図2: 表とブロック索引のスキャン・シェアリングの共有セット
またこの図は、バッファー・プール内容を複数のグループで再利用する方法も示しています。 スキャン C について考えてみます。これは、グループ 1 の先行スキャンです。 以下のスキャン (A と B) は C と一緒にグループ化されています。それぞれがよく似ていて、C がバッファー・プールに入れたページを再利用する可能性が高いからです。
優先度の高いスキャナーは優先度の低いスキャナーによってスロットルされることはなく、その代わりに別の共有グループに移動する可能性があります。 優先度の高いスキャナーは、グループ内の優先度の低いスキャナーが実行中の作業から益を受けられるグループ内に配置できます。 それは、その益が受けられる限りはそのグループ内に留まります。 速度の速いスキャナーをスロットルするか、(スキャナーが検出する場合に) より速い共有グループに移動して、データ・サーバーはその共有が最適化された状態を保つように共有グループを調整します。
スキャン・シェアリングに関する情報を表示するには、db2pd コマンドを使用できます。 例えば、個々の共有スキャンの場合、db2pd 出力にはスキャン速度、およびスキャンがスロットルされた時間などのデータが表示されます。 共有グループの場合、このコマンド出力にはグループ内のスキャン数、グループによって共有されるページ数が表示されます。
EXPLAIN_ARGUMENT 表には、表スキャンと索引スキャンについてのスキャン・シェアリング情報が含まれる新しい行があります。この表の内容をフォーマット設定および表示するには db2exfmt コマンドを使用できます。
オプティマイザー・プロファイルを使用すれば、スキャン・シェアリングに関してコンパイラーが行った決定をオーバーライドできます (アクセス・タイプ を参照)。 このようなオーバーライドは、特別な必要性が生じた場合にのみ使用します。例えば、結果セット内のレコードの反復可能順序が必要なものの、ORDER BY 文節 (ソートを起動する場合がある) を使用しない場合には、折り返しヒントが役立ちます。 それ以外の場合は、 Db2® サービスからの要求がない限り、これらの最適化プロファイルを使用しないことをお勧めします。