Scan sharing refers to the ability of one
scan to exploit the work done by another scan. Examples of shared
work include disk page reads, disk seeks, buffer pool content reuse,
decompression, and so on.
Heavy scans, such as table scans or multidimensional clustering
(MDC) block index scans of large tables, are sometimes eligible for
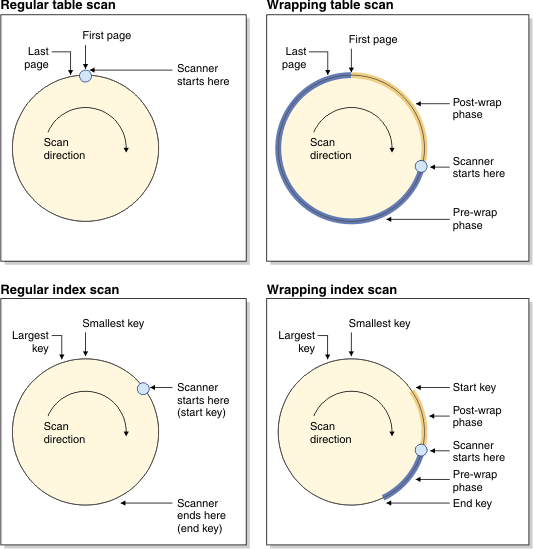
sharing page reads with other scans. Such shared scans can start at
an arbitrary point in the table, to take advantage of pages that are
already in the buffer pool. When a sharing scan reaches the end of
the table, it continues at the beginning and finishes when it reaches
the point at which it started. This is called a wrapping scan. Figure 1 shows the difference
between regular scans and wrapping scans for both tables and indexes.Figure 1. Conceptual view of regular and
wrapping scans
The scan sharing feature is enabled by default, and eligibility
for scan sharing and for wrapping are determined automatically by
the SQL compiler. At run time, an eligible scan might or might not
participate in sharing or wrapping, based on factors that were not
known at compile time.
Shared scanners are managed in share groups. These
groups keep their members together as long as possible, so that the
benefits of sharing are maximized. If one scan is faster than another
scan, the benefits of page sharing can be lost. In this situation,
buffer pool pages that are accessed by the first scan might be cleared
from the buffer pool before another scan in the share group can access
them. The data server measures the distance between two scans in the
same share group by the number of buffer pool pages that lies between
them. The data server also monitors the speed of the scans. If the
distance between two scans in the same share group grows too large,
they might not be able to share buffer pool pages. To reduce this
effect, faster scans can be throttled to allow slower scans to access
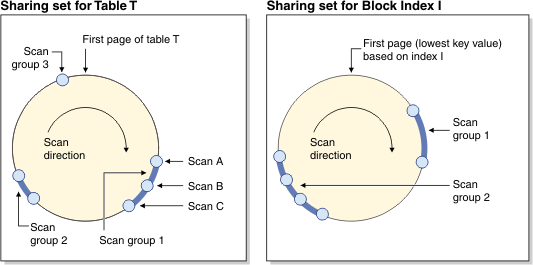
the data pages before they are cleared. Figure 2 shows two sharing sets,
one for a table and one for a block index. A sharing set is
a collection of share groups that are accessing the same object (for
example, a table) through the same access mechanism (for example,
a table scan or a block index scan). For table scans, the page read
order increases by page ID; for block index scans, the page read order
increases by key value.Figure 2. Sharing
sets for table and block index scan sharing
The figure also shows how buffer pool content is reused within
groups. Consider scan C, which is the leading scan of group 1. The
following scans (A and B) are grouped with C, because they are close
and can likely reuse the pages that C has brought into the buffer
pool.
A high-priority scanner is never throttled by a lower priority
one, and might move to another share group instead. A high priority
scanner might be placed in a group where it can benefit from the work
being done by the lower priority scanners in the group. It will stay
in that group for as long as that benefit is available. By either
throttling the fast scanner, or moving it to a faster share group
(if the scanner encounters one), the data server adjusts the share
groups to ensure that sharing remains optimized.
You can use the db2pd command to view information
about scan sharing. For example, for an individual shared scan, the db2pd output
will show data such as the scan speed and the amount of time that
the scan was throttled. For a sharing group, the command output shows
the number of scans in the group and the number of pages shared by
the group.
The EXPLAIN_ARGUMENT table has new rows to contain scan-sharing
information about table scans and index scans (you can use the db2exfmt command
to format and view the contents of this table).
You can use optimizer profiles to override decisions that the compiler makes about scan sharing
(see Access types). Such overrides are for use only when a special need arises; for example,
the wrapping hint can be useful when a repeatable order of records in a result set is needed, but an
ORDER BY clause (which might trigger a sort) is to be avoided. Otherwise, it is recommended that you
not use these optimization profiles unless requested to do so by Db2® Service.