多线程流程
多线程流程概览
多线程流程是一种数据收集器 流程 , 其源支持并行执行,使一个流程可以在多个线程中运行。
多线程数据流可在一个数据采集器上的单个数据流中处理大量数据,从而充分利用数据采集器上的所有可用 CPU。 使用多线程流时 ,确保为流和数据收集器分配足够的资源。
多线程数据流可兑现为数据流配置的交付保证,但不保证批次数据的处理顺序。
运作方式
配置多线程流程时,需要指定源用于生成数据批次的线程数。 您还可以配置数据收集器用于执行流处理的最大流运行器数量。
流程运行器是一个无源流程实例 —— 流程的实例包括流程中的所有处理器、执行器和目标 ,并处理源之后的所有流程处理。
源会根据与之配合的源系统执行多线程处理,但以下内容适用于所有生成多线程流的 源 :
启动流程时, 源会根据源中配置的多线程属性创建多个线程。 数据收集器会根据 flow Max Runners 属性创建若干流量运行程序,以执行流量处理。 每个线程连接到源系统,创建一批数据,并将该批数据传递给可用的流水运行器。
每个流程运行程序一次处理一个批次,就像在单线程上运行的流程一样。 当数据流速度减慢时, 数据流运行程序会闲置等待,直到需要时才会定期生成空批次。 您可以配置运行程序空闲时间流属性,以指定时间间隔或选择退出空批次生成。
多线程流程与单线程流程一样,会保留每个批次中记录的顺序。 但是,由于 批次由不同的流程运行程序处理,因此无法确保批次写入目标的顺序。
例如,下面是一个多线程流程。 HTTP Server 源处理来自 HTTP 客户端的 HTTP POST 和 PUT 请求。 配置源时 ,需要指定要使用的线程数,在本例中就是最大并发请求属性:
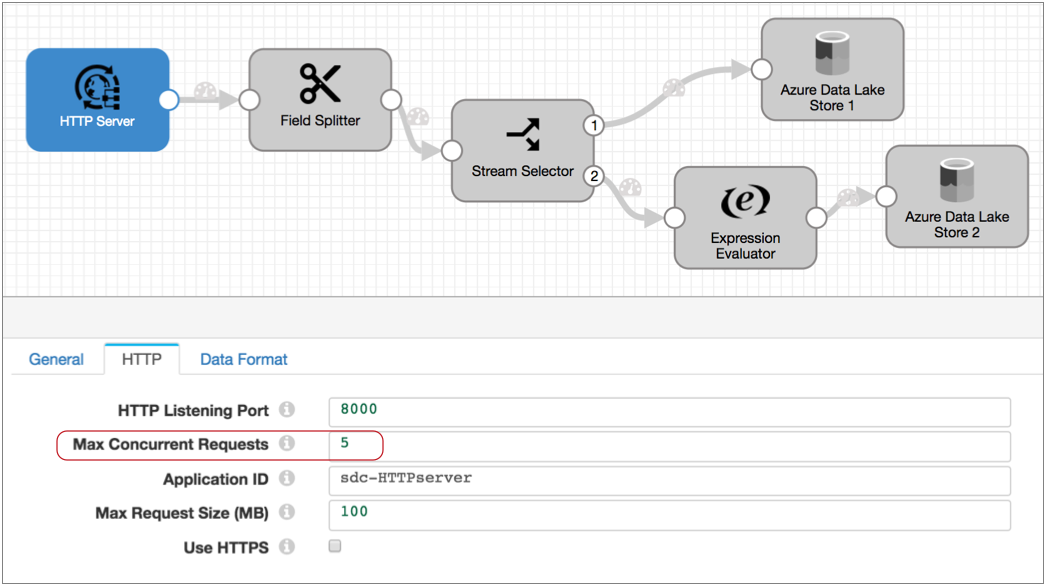
假设您将流程配置为退出 Max Runners 属性。 执行此操作后, Data Collector 会生成与线程数量相匹配的流量运行程序。
将最大并发请求设置为 5 时,当您启动流程时, 源会创建五个线程, 数据收集器会创建五个流程运行程序。 接收到数据后, 源会将一个批次传递给每个流程运行器进行处理。
从概念上讲,多线程流程是这样的:
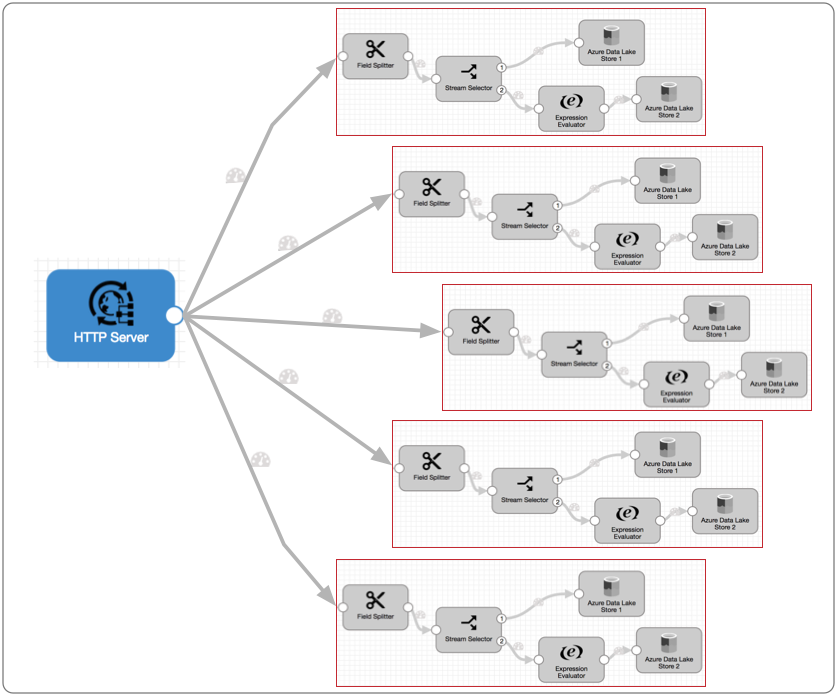
每个流程运行程序都执行与流程其余部分相关的处理。 在将一批数据写入流量 目标 (在本例中为 Azure Data Lake Store 1 和 2)后, 流量运行器可用于处理另一批数据。 每个批次的处理和写入都尽可能快,与其他流水号处理的批次无关,因此批次的写入顺序可能与读取顺序不同。
在任何时刻,五个流程运行器都可以各自处理一个批次,因此这种多线程流程一次最多可处理五个批次。 当输入数据变慢时, 流量运行器就会处于闲置状态,一旦数据流增加,就会立即投入使用。
多线程流的来源
- Amazon S3 - 读取存储在 Amazon S3 中的对象。
- 亚马逊 SQS 消费者 - 从亚马逊简单队列服务(SQS)中的队列读取数据。
- Azure Blob Storage - 从 Microsoft Azure Blob Storage 读取数据。
- Azure 数据湖存储 Gen2 - 从 读取数据。 Microsoft Azure Data Lake Storage Gen2
- Azure 数据湖存储 (传统) Gen2 - 从 读取数据。 Microsoft Azure Data Lake Storage Gen2
- Azure IoT/Event Hub Consumer - 从 Microsoft Azure Event Hub 读取数据。
- CoAP 服务器 - 监听 端点,处理所有授权 请求的内容。 CoAP CoAP
- Couchbase - 从 Couchbase 服务器读取数据。
- 目录 - 从目录中读取完全写入的文件。
- Elasticsearch - 从 Elasticsearch 集群读取数据。
- Google Pub/Sub 订阅器 - 从 Pub/Sub 订阅器接收信息。 Google
- Groovy 脚本 - 运行 Groovy 脚本创建数据收集器记录。
- HTTP Server - 监听 HTTP 端点,并处理所有授权 HTTP POST 和 PUT 请求的内容。
- IBM Db2 - 从 IBM Db2 数据库读取数据。
- JavaScript 脚本 - 运行 脚本以创建 JavaScript 数据收集器记录。
- JDBC Multitable Consumer - 通过 连接从多个表读取数据库数据。 JDBC
- Jython 脚本 - 运行 Jython 脚本以创建数据收集器记录。
- Kafka 多主题消费者 - 从 集群中的多个主题读取数据。 Kafka
- Kinesis 消费者 - 从 Kinesis 集群读取数据。
- Oracle 批量加载 - 从多个 数据库表中读取数据,然后停止 Oracle 数据流。
- Oracle Multitable Consumer - 从多个 数据库表中读取数据。 Oracle
- Pulsar 消费者 - 从 Apache Pulsar 主题读取信息。
- REST 服务 -- 监听 HTTP 端点,解析所有授权请求的内容,并将响应发送回原始 REST API。 作为微服务流程的一部分使用。
- Salesforce Bulk API 2.0 - 使用 从 读取数据 Bulk API。 Salesforce Salesforce 2.0
- Snowflake 批量源 - 从多个 表读取数据,然后停止 Snowflake 数据流。
- TCP 服务器 - 在指定端口上监听,并通过 TCP/IP 连接处理传入的数据。
- UDP 多线程源 - 从一个或多个 UDP 端口读取消息。
- WebSocket 服务器 - 监听 端点,处理所有授权 请求的内容。 WebSocket WebSocket
- 开发数据生成器 - 生成用于开发和测试的随机数据。
各个源使用不同的属性,并根据其所使用的源系统执行不同的处理。 有关源代码如何执行多线程处理的详细信息,请参阅源代码文档中的 "多线程处理"。
处理器缓存
由于多线程流使用多个流运行器来运行多个无源流实例,因此多线程流中的处理器缓存可能与在单线程上运行的流不同。
一般来说,当处理器缓存数据时,处理器的每个实例只能缓存通过特定流道的数据。 在配置多线程流量时,请务必考虑这种行为。
例如,如果将查找处理器配置为创建本地缓存,则查找处理器的每个实例都会创建自己的本地缓存。 这应该不成问题,因为高速缓存通常是用来提高流量性能的。
记录复制处理器是个例外。 记录重复数据消除器最多可缓存指定数量或时间的记录以供比较。 在多线程流程中使用时,缓存中的记录会在流程运行程序之间共享。
调整螺纹和流道
- 线程数
- 配置源的最大线程数或并发数。
- 流道
- 使用 Max Runners 流量属性配置流量运行器的最大数量。
例如,您有一个 Kinesis 消费者从 4 个碎片读取数据的流程。 在源文件中,您将线程数设置为 4。 此外, 流量最大运行器属性的默认值为 0,这将为线程创建相匹配的流量运行器数量--在本例中为 4。 启动流程作业并让其运行一段时间后, 在监控作业时,您可以回头检查并在“实时摘要”选项卡中找到以下直方图:
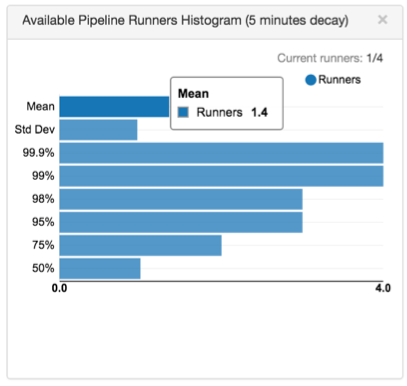
直方图显示,平均值为 1.4 ,这意味着在任何时候,都可能有 1.4 可用的选手。
如果这是流量的峰值负载,这意味着您可以将流量中使用的流道数量减少到 3 个,而不会牺牲太多性能。 如果其他地方需要使用数据收集器资源,并且不介意对流量性能造成轻微影响,则可以将流量运行程序的数量减少到 2 个。
资源使用情况
由于每个流运行程序都在源后执行与流相关的所有处理,因此多线程流中的每个线程所需的资源与在单线程上运行的相同流大致相同。
在处理多线程流时 ,应监控数据收集器的资源使用情况,并在适当时增加数据收集器 Java 堆的大小。
多线程流程摘要
以下几点试图总结有关多线程流的关键细节:
- 使用多线程源创建多线程流程。 此时,您可以使用以下资料来源 :
- Amazon S3 - 读取存储在 Amazon S3 中的对象。
- 亚马逊 SQS 消费者 - 从亚马逊简单队列服务(SQS)中的队列读取数据。
- Azure Blob Storage - 从 Microsoft Azure Blob Storage 读取数据。
- Azure 数据湖存储 Gen2 - 从 读取数据。 Microsoft Azure Data Lake Storage Gen2
- Azure 数据湖存储 (传统) Gen2 - 从 读取数据。 Microsoft Azure Data Lake Storage Gen2
- Azure IoT/Event Hub Consumer - 从 Microsoft Azure Event Hub 读取数据。
- CoAP 服务器 - 监听 端点,处理所有授权 请求的内容。 CoAP CoAP
- Couchbase - 从 Couchbase 服务器读取数据。
- 目录 - 从目录中读取完全写入的文件。
- Elasticsearch - 从 Elasticsearch 集群读取数据。
- Google Pub/Sub 订阅器 - 从 Pub/Sub 订阅器接收信息。 Google
- Groovy 脚本 - 运行 Groovy 脚本创建数据收集器记录。
- HTTP Server - 监听 HTTP 端点,并处理所有授权 HTTP POST 和 PUT 请求的内容。
- IBM Db2 - 从 IBM Db2 数据库读取数据。
- JavaScript 脚本 - 运行 脚本以创建 JavaScript 数据收集器记录。
- JDBC Multitable Consumer - 通过 连接从多个表读取数据库数据。 JDBC
- Jython 脚本 - 运行 Jython 脚本以创建数据收集器记录。
- Kafka 多主题消费者 - 从 集群中的多个主题读取数据。 Kafka
- Kinesis 消费者 - 从 Kinesis 集群读取数据。
- Oracle 批量加载 - 从多个 数据库表中读取数据,然后停止 Oracle 数据流。
- Oracle Multitable Consumer - 从多个 数据库表中读取数据。 Oracle
- Pulsar 消费者 - 从 Apache Pulsar 主题读取信息。
- REST 服务 -- 监听 HTTP 端点,解析所有授权请求的内容,并将响应发送回原始 REST API。 作为微服务流程的一部分使用。
- Salesforce Bulk API 2.0 - 使用 从 读取数据 Bulk API。 Salesforce Salesforce 2.0
- Snowflake 批量源 - 从多个 表读取数据,然后停止 Snowflake 数据流。
- TCP 服务器 - 在指定端口上监听,并通过 TCP/IP 连接处理传入的数据。
- UDP 多线程源 - 从一个或多个 UDP 端口读取消息。
- WebSocket 服务器 - 监听 端点,处理所有授权 请求的内容。 WebSocket WebSocket
- 开发数据生成器 - 生成用于开发和测试的随机数据。
- 与基本的单线程流程不同,多线程流程无法保证数据的顺序。
批次内的数据是按顺序处理的,但由于批次是快速创建并传递给不同线程的,因此批次的顺序会在写入流 目标时发生变化。
- 对信息进行缓存的处理器通常会为每个数据流实例设置单独的缓存。 记录重复器是个例外,它可以识别所有流程运行器中的重复记录。
- 要优化性能和资源使用,请检查可用流量运行程序柱状图,查看流量运行程序是否得到有效使用。
- 我们建议监控流量的资源使用情况和数据收集器的堆使用情况,并根据需要增加它们。