数据流触发器
数据流触发器概述
数据流触发器是事件框架根据数据流中发生的事件启动任务的指令。 您也可以使用数据流触发器,在 JDBC 查询消费者源处理完所有可用数据后停止数据流。
- 事件生成
- 事件框架生成与流程相关的事件和与阶段相关的事件。 框架仅在流开始和停止时生成流事件。 当发生与阶段相关的特定行为时,该框架就会生成阶段事件。 产生事件的操作因阶段而异,与阶段处理数据的方式有关。
- 任务执行
- 要触发任务,需要一个执行器。 执行阶段在数据收集器或外部系统中执行任务。 执行器每次接收到一个事件,就会执行指定的任务。
- 事件存储器
- 要存储事件信息,可将事件传递给目标。 目标机将事件记录写入目标机系统,就像写入其他数据一样。
流量事件生成
事件框架会在数据收集器流的生命周期中特定点生成流事件。 您可以配置流程属性,将每个事件传递给执行器或另一个流程 ,以进行更复杂的处理。
- 流量启动
- 流程启动事件在流程初始化时生成,在流程启动后立即生成,在各个阶段初始化之前生成。 这可以为执行器在各阶段初始化前执行任务留出时间。
- 流量停止
- 流动 停止事件已生成 当 流动 停止时,无论是手动停止、程序停止还是由于故障停止。 停止事件在所有阶段完成处理和清理临时资源(如删除临时文件)后生成。 这样,执行器就可以在流程处理完成后、 流程完全停止前执行任务。
- 虚拟处理 - 与阶段事件不同, 流程事件不会由您在画布中配置的阶段进行处理。 它们会传递给您在流程属性中配置的事件消费者。
事件消费者不会显示在流程的画布中。 因此,数据预览中也不会显示流量事件。
- 一次性事件 - 您只能在流程属性中为每种事件类型配置一个事件消费者:一个用于开始事件,一个用于停止事件。
必要时,您可以将流程事件传递给另一个流程。 在事件消耗流程中,您可以根据需要添加多个阶段,以进行更复杂的处理。
使用流量事件
您可以在独立流量中配置流量事件。 配置 flow 事件时,可以将其配置为由执行器或其他 flow 消耗。
当执行器可以执行您需要的所有任务时,将事件传递给执行器。 您可以为每种事件类型配置一个执行器。
当您需要在消费流中执行更复杂的任务时,可将事件传递给另一个流 ,例如将事件传递给多个执行器或一个执行器和目标进行存储。
转交给执行人
您可以配置流程 ,将每种事件类型传递给一个执行阶段。 这样就可以在流程开始或停止时触发任务。 您可以分别配置每种事件类型的行为。 您还可以放弃任何不想使用的事件。
- 在流程属性中,选择要消耗事件的执行器。
- 在流程属性中,配置执行器以执行任务。
示例
假设您想在流量开始时发送一封电子邮件。 首先,将流程配置为使用电子邮件执行器来处理流程启动事件。 由于不需要 "停止 "事件,因此只需使用默认的 "丢弃 "选项即可:
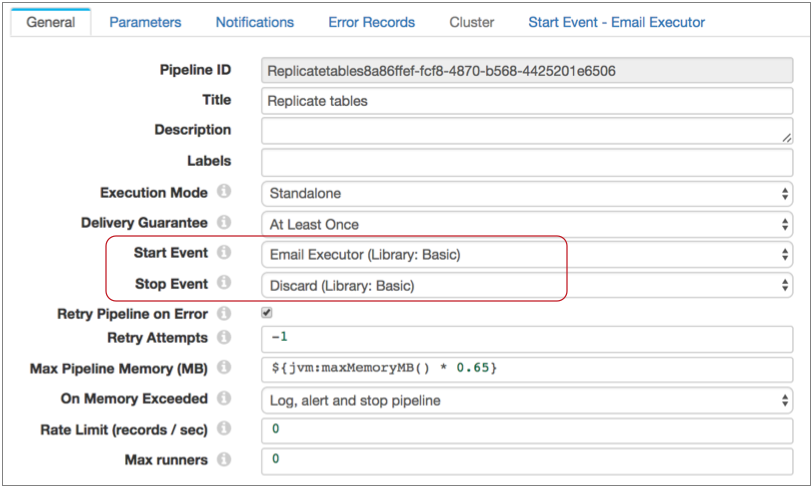
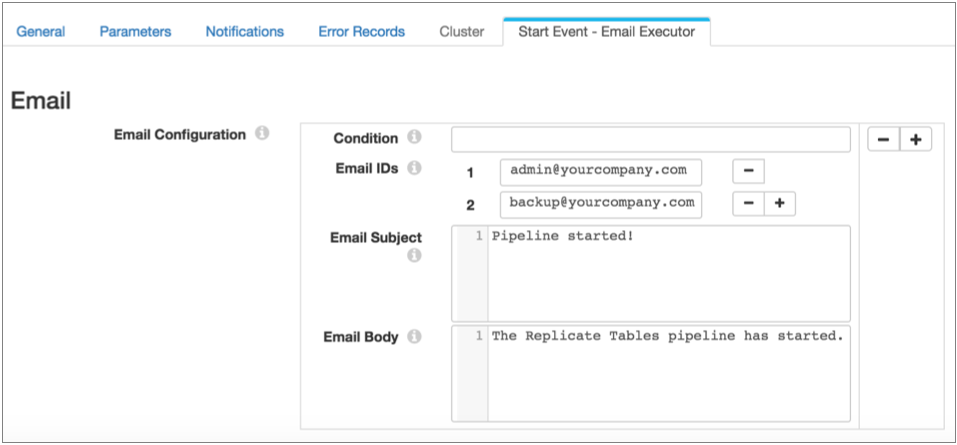
然后,在流程属性中配置电子邮件执行器。 您可以配置发送电子邮件的条件。 如果省略条件,执行器会在每次收到事件时发送电子邮件:
舞台事件生成
您可以配置某些阶段来生成事件。 根据不同阶段处理数据的方式,每个阶段产生的事件也不尽相同。 有关各阶段事件生成的详细信息,请参阅阶段文档中的 "事件生成"。
| 暂存 | 当舞台... |
|---|---|
| Amazon S3 消息来源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| Azure Blob Storage 消息来源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| Azure 数据湖存储 Gen2 来源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| Azure 数据湖存储 (传统) Gen2 源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| 目录来源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| 文件尾部来源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| Google BigQuery 消息来源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| Google Cloud Storage 消息来源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| Groovy 脚本源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| JavaScript 脚本源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| JDBC 多种消费者来源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| JDBC 查询消费者来源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| Jython 脚本源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| MongoDB Atlas 源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| Oracle 散装货源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| Oracle 疾病预防控制中心资料来源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| Oracle CDC 客户端源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| Oracle 多种消费者来源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| Oracle XStream 源 |
|
| Salesforce 消息来源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| Salesforce 批量 API 2.0 来源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| SAP HANA 查询消费者来源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| SFTP/FTP/FTPS 客户端来源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| SQL Server CDC 客户端源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| SQL Server 更改跟踪源 |
更多信息,请参阅源文件中的 " 事件生成 "。 |
| 网络客户端源 |
更多信息,请参阅源文件中的事件生成。 |
| 窗口聚合处理器 |
更多信息,请参阅处理器文档中的事件生成。 |
| Groovy 评估处理器 |
更多信息,请参阅处理器文档中的事件生成。 |
| JavaScript 评估员处理器 |
更多信息,请参阅处理器文档中的事件生成。 |
| Jython 评估处理器 |
更多信息,请参阅处理器文档中的事件生成。 |
| TensorFlow 评估员处理器 |
如需更多信息,请参阅处理器文档中的 “事件生成”部分。 |
| 网络客户端处理器 |
更多信息,请参阅目标文档中的事件生成。 |
| 窗口聚合处理器 |
更多信息,请参阅处理器文档中的事件生成。 |
| Amazon S3 目标 |
更多信息,请参阅目标文档中的事件生成。 |
| Azure Blob Storage 目标 |
更多信息,请参阅目标文档中的事件生成。 |
| Azure 数据湖存储 Gen2 目标 |
更多信息,请参阅目标文档中的事件生成。 |
| Google Cloud Storage 目标 |
更多信息,请参阅目标文档中的事件生成。 |
| 地方金融服务目标 |
更多信息,请参阅目标文档中的事件生成。 |
| SFTP/FTP/FTPS 客户端目标 |
更多信息,请参阅目标文档中的事件生成。 |
| Snowflake 文件上传目标 |
更多信息,请参阅目标文档中的 事件生成。 |
| 网络客户端目标 |
更多信息,请参阅目标文档中的事件生成。 |
| ADLS Gen2 文件元数据执行器 |
更多信息,请参阅执行器文档中的事件生成。 |
| Amazon S3 执行人 |
更多信息,请参阅执行器文档中的事件生成。 |
| Databricks Job Launcher 执行器 |
如需了解更多信息,请参阅执行器文档中的 “事件生成” 部分。 |
| Databricks 查询执行器 |
如需更多信息,请参阅执行器文档中的 “事件生成”部分。 |
| Google BigQuery 执行人 |
更多信息,请参阅执行器文档中的事件生成。 |
| Google Cloud Storage 执行人 |
|
| JDBC 查询执行器 |
更多信息,请参阅执行器文档中的事件生成。 |
| Snowflake 执行人 |
更多信息,请参阅执行器文档中的事件生成。 |
使用舞台事件
您可以根据自己的需要,以任何方式使用与舞台相关的活动。 为阶段事件配置事件流时,可以向流中添加其他阶段。 例如,您可以使用流选择器将不同类型的事件路由到不同的执行器。 但不能将事件流与数据流合并。
- 任务执行流将事件路由到执行器以执行任务。
- 事件存储流将事件路由到目标 ,以存储事件信息。
任务执行流
任务执行流将事件记录从事件生成阶段路由到执行阶段。 执行器每次收到事件记录时都会执行一项任务。
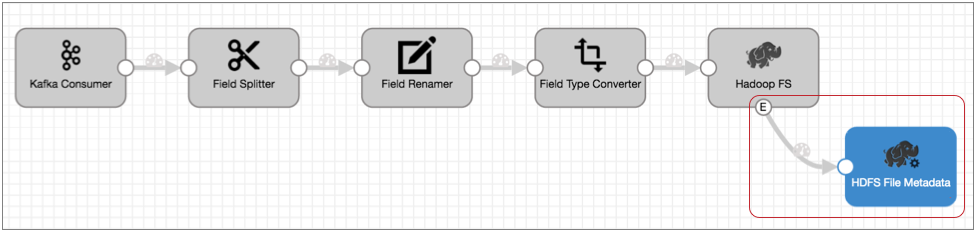
例如,您有一个从 Kafka 读取文件并将文件写入 HDFS 的流程 :

Hadoop FS 关闭文件时,您希望将文件移动到不同的目录,并将文件权限更改为只读。
保持流程的其他部分不变,您可以在 Hadoop FS 目标中启用事件处理,将其连接到 HDFS 文件元数据执行器,并将 HDFS 文件元数据执行器配置为文件和更改权限。 由此产生的流程是这样的
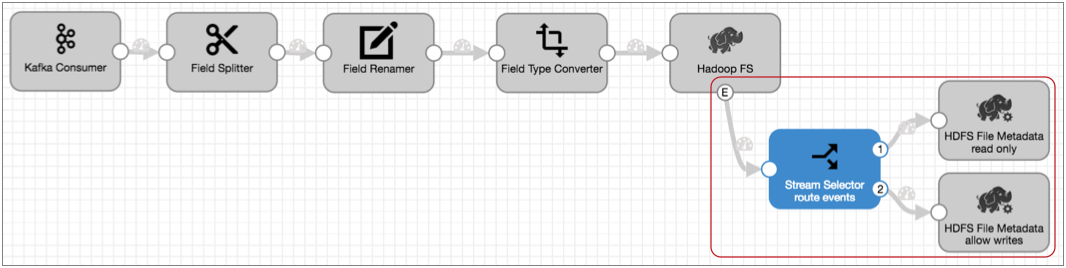
如果需要根据文件名或位置设置不同的权限,可以使用流选择器对事件记录进行相应的路由,然后使用两个 HDFS File Metadata 执行器来更改文件权限,如下所示:
事件存储流
事件存储流将事件记录从事件生成阶段路由到目标。 目标将事件记录写入目标系统。
事件记录包括记录头属性和记录字段中的事件信息。 在将事件记录写入目标机之前,您可以在事件流中添加处理器来丰富事件记录。
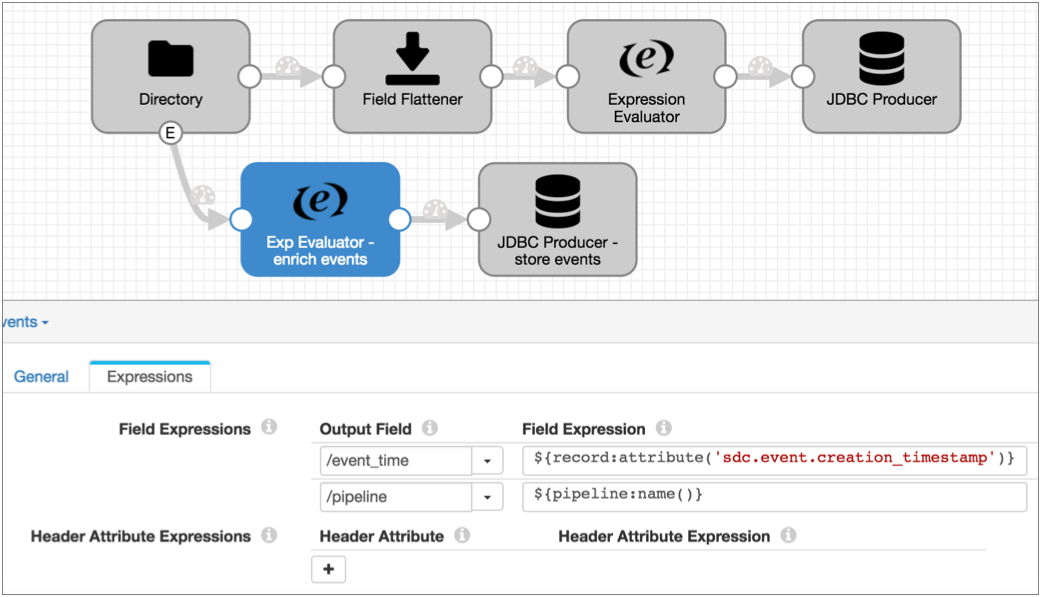
例如,您有一个使用目录源处理网络日志的流程 :

Directory 每次开始和完成读取文件时都会生成事件记录,事件记录包括一个包含文件路径的字段。 出于审计目的,您希望将这些信息写入数据库表中。
在保持流程其余部分不变的情况下,您可以启用目录源的事件处理功能,并按如下步骤将其连接到 JDBC Producer:

${record:attribute('sdc.event.creation_timestamp')}${flow:name()}表达式评估器和最终流程如下所示:
执行程序
执行器在收到事件记录时执行任务。
- ADLS Gen2 文件元数据执行器
- 收到事件后,在 Azure Data Lake Storage Gen2 中更改文件元数据、创建空文件或删除文件或目录。
- Amazon S3 执行人
- 为指定的内容创建新的 Amazon S3 对象,复制水桶内的对象,或在收到事件后为现有的 Amazon S3 对象添加标签。
- Databricks Job Launcher 执行器
- 为每个事件启动 Databricks 作业。
- Databricks 查询执行器
- 收到事件后在 Databricks 上运行 Spark SQL 查询。
- 电子邮件执行人
- 收到事件后,向配置的收件人发送自定义电子邮件。 您可以选择配置一个条件来决定何时发送电子邮件。
- Google BigQuery 执行人
- 收到事件后,在 Google BigQuery 上运行一个或多个 SQL 查询。
- Google Cloud Storage 执行人
- 为指定内容创建新的 Google Cloud Storage 对象,复制或移动项目中的对象,或在收到事件时为现有对象添加元数据。
- 管道完成执行器
- 收到事件时停止流程 ,将流程过渡到完成状态。 允许流程在停止前完成所有预期处理。
- JDBC 查询执行器
- 使用 JDBC 连接到数据库,并运行一个或多个指定的 SQL 查询。
- SFTP/FTP/FTPS 客户端执行器
- 连接到 SFTP、FTP 或 FTPS 服务器,并在收到事件时移动或删除文件。
- 外壳执行器
- 为每个事件执行用户定义的 shell 脚本。
- Snowflake 执行人
- 将 Snowflake File Uploader 目标缓存的整个文件加载到 Snowflake 表中。
逻辑配对
您可以根据自己的需要以任何方式使用事件。 下表概述了事件生成与执行器和目标的一些逻辑配对。
流动事件
| 流量事件类型 | 活动消费者 |
|---|---|
| 流量启动 |
|
| 流量停止 |
|
来源活动
| 事件发生源 | 活动消费者 |
|---|---|
| Amazon S3 |
|
| Azure Blob Storage |
|
| Azure Data Lake Storage Gen2 |
|
| Azure Data Lake Storage Gen2(旧版) |
|
| 目录 |
|
| 文件实时跟踪 |
|
| Google BigQuery |
|
| Google Cloud Storage |
|
| JDBC 多表消费者 |
|
| JDBC 查询消费者 |
|
| MongoDB Atlas |
|
| Oracle 批量加载 |
|
| Oracle CDC |
|
| Oracle CDC 客户 |
|
| Oracle 多表消费者 |
|
| Oracle Xstream |
|
| Salesforce |
|
| Salesforce Bulk API 2.0 |
|
| SAP HANA 查询消费者 |
|
| SFTP/FTP/FTPS 客户端 |
|
| SQL Server 变化跟踪 |
|
| Web 客户端 |
|
处理器事件
| 事件发生处理器 | 活动消费者 |
|---|---|
| Groovy 评估程序 |
|
| JavaScript 评估程序 |
|
| Jython 评估程序 |
|
| TensorFlow 评估程序 |
|
| Web 客户端 |
|
| 窗口聚合器 |
|
目标活动
| 事件生成目标 | 活动消费者 |
|---|---|
| Amazon S3 |
|
| Azure Blob Storage |
|
| Azure Data Lake Storage Gen2 |
|
| Google Cloud Storage |
|
| 本地文件系统 |
|
| SFTP/FTP/FTPS 客户端 |
|
| Snowflake 文件上传程序 |
|
执行者事件
| 事件生成执行器 | 活动消费者 |
|---|---|
| ADLS Gen2 文件元数据执行器 |
|
| Amazon S3 |
|
| Databricks Job Launcher 执行器 |
|
| Databricks 查询执行器 |
|
| Google BigQuery 执行人 |
|
| Google Cloud Storage 执行人 |
|
| JDBC 查询执行器 |
|
| Snowflake 执行人 |
|
事件记录
事件记录是在发生阶段或流程事件时创建的记录。
大多数事件记录都会在记录头中传递一般事件信息,如事件发生的时间。 它们还可以在记录字段中包含特定事件的详细信息,如关闭的输出文件的名称和位置。
文件尾部源生成的事件记录是个例外--它们包括记录字段中的所有事件信息。
事件记录头属性
除标准记录头属性外,大多数事件记录还包括事件信息记录头属性,如事件类型和事件发生时间。
${record:attribute('sdc.event.creation_timestamp')}请注意,所有记录头属性都是字符串值。 有关使用记录标题属性的更多信息,请参阅记录标题属性。
| 事件记录头属性 | 描述 |
|---|---|
| sdc.event.type | 事件类型。 由生成事件的阶段定义。 有关事件生成阶段可用事件类型的信息,请参阅阶段文档。 |
| sdc.event.version | 整数,表示事件记录类型的版本。 |
| sdc.event.creation_timestamp | 舞台创建事件时的时间戳。 |
目录
- 您可以在任何流程中使用事件框架,使其逻辑符合您的需求。
- 事件框架生成与流程相关的事件和与阶段相关的事件。
- 您可以在独立流中使用流事件。
- 流量事件在流量开始和停止时产生。 有关详情,请参阅流程事件生成。
- 您可以将每个流程事件类型配置为传递给单个执行器或另一个流程 ,以进行更复杂的处理。
- 舞台事件根据舞台的处理逻辑生成。 有关事件生成阶段的列表,请参阅阶段事件生成。
- 事件生成事件记录 ,以传递与事件相关的信息,如关闭文件的路径。
各阶段生成的事件记录各不相同。 有关阶段事件的描述,请参阅事件生成阶段文档中的 "事件记录"。 有关流量事件的描述,请参阅流量事件记录。
- 在最简单的使用案例中,您可以将阶段事件记录路由到目标 ,以保存事件信息。
- 您可以将舞台事件记录路由到执行舞台,这样它就能在收到事件后执行任务。
有关逻辑事件生成和执行器配对的列表,请参阅逻辑配对。
- 您可以将处理器添加到阶段事件的事件流或流事件的消费流中。
例如,您可以添加一个表达式评估器,在将事件记录写入目标之前,将事件生成时间添加到事件记录中。 或者,您可以使用流选择器将不同类型的事件记录路由到不同的执行器。
- 在处理舞台事件时,不能将事件流与数据流合并。
- 您可以使用开发数据生成器和至事件开发阶段来生成用于流程开发和测试的事件。 有关开发阶段的更多信息,请参阅开发阶段。
有关如何使用事件框架的示例,请参阅本章前面的案例研究。