Java センサーの設定
Instana エージェントをインストールすると、 Java センサーとトレーサーが自動的に設定されます。 追加の設定を一切行わなくても、メトリクスと分散トレーシングを提供します。 ただし、以下のセクションで説明するように、設定をカスタマイズすることは可能です。
JVM の監視に関する詳細については、 「 Java 仮想マシンの監視 ( JVM )」 を参照してください。
アプリケーション名のカスタマイズ
このアプリケーション名は、 Instana 内の「 Java 」アプリケーションを識別するものです。 アプリケーション名は、自動設定と手動設定の2つの方法で設定できます。
自動命名
通常、 Instana は以下の情報源からアプリケーション名を自動的に取得します:
アプリケーション
.jarファイル:この.jarファイル内では、以下の標準属性が利用可能ですMETA-INF/Manifest.MF:Implementation-Title=Demo App Implementation-Version=1.0.0ビルドツールを使用すれば、アプリケーションをビルドする際に両方の属性を設定できます。 詳細については、『 Oracle 』のドキュメントを参照してください。
コマンドライン:名前が利用できない場合、 Java ツールがJVMを表示するのと同じ方法で、コマンドラインを使用して名前を検索します。
システムプロパティ:ファイル
.jarから名前が取得できない場合、 Instana は、Tomcatコンテナなど-Dcatalina.home、さまざまなシステムプロパティを調べます。
手動での命名
アプリケーション名を変更するには、次のいずれかの方法を使用してください:
JVM の初期化時に名前を設定する:アプリケーション名を明示的に設定するには、 JVM を起動する際に `name`
-Dcom.instana.agent.jvm.name="My Custom Name"属性を指定してください。既存のシステムプロパティを使用する:エージェントが既存のカスタムシステムプロパティを使用するように設定するには、エージェント
configuration.yamlファイルにプロパティのリストを指定します。 現存する最初の物件は、 JVM と名付けられています:
com.instana.plugin.java:
name-properties:
- 'acme.app'
- 'DEPLOYMENT'
ポーリング間隔のカスタマイズ
エージェントの ` configuration.yaml ` ファイルにある `poll_rate` パラメータを使用することで、 Instana がデータやメトリクスを収集するために JVM をポーリングする頻度を設定できます。
ポーリング間隔の設定
com.instana.plugin.java:
poll_rate: 1 # Value is in seconds. Default value is 1 second.
JMX のカスタムメトリクスの設定
監視する JMX のメトリクスを設定するには、次の例に示す configuration.yaml ようにagentファイルを編集します
com.instana.plugin.java:
jmx:
# JMX is NOT hot-reloaded and needs to be set before a JVM is discovered.
# Supported attribute types are Number and Boolean
# delta calculation is only supported for Number
- object_name: 'java.lang:type=Compilation'
metrics:
- attributes: 'TotalCompilationTime'
type: 'delta' # delta will report the change to the previous second
- object_name: 'java.lang:type=ClassLoading'
metrics:
- attributes: 'LoadedClassCount'
type: 'absolute' # absolute will report the value as-is
前の例では、以下の種類のメトリクスが指定されています:
delta: カウンターなど、時間の経過とともに値が増加し、その相対的な変化が注目される場合に使用されます。absolute: メトリクスにアクセスするたびに実際の値を表示するために使用されます。
指定された属性は、 Number (または や などのそのサブ Doubleクラスの Integer いずれか)であるか、数値 String を表す でなければなりません。
ワイルドカードパターンを使用した JMX メトリクスの設定
には、 Java ObjectName APIobject_name のドキュメントで指定されているワイルドカードパターンが含まれている場合があります。
次の例は、ワイルドカードパターンを使用した設定を示しています:
com.instana.plugin.java:
jmx:
- object_name: 'kafka.*:type=*-metrics,client-id=*,*'
metrics:
- attributes: 'incoming-byte-rate'
type: 'absolute'
- attributes: 'incoming-byte-total'
type: 'absolute'
- attributes: 'outgoing-byte-rate'
type: 'absolute'
- attributes: 'outgoing-byte-total'
type: 'absolute'
JMX のカスタムメトリクスの表示
JVM のダッシュボードでは、「 JMX 」のメトリクスが、「 JMX のカスタムメトリクス 」の下に表示されます。
Java のトレース計測の設定
Instana ホストエージェントをインストールすると、デフォルトの(SDK非対応の) Java トレース計測機能はデフォルトで有効になりますが、 OpenTracing 計測機能および Java トレースSDK は有効になりません。
Java のトレース計測機能を無効にする
デフォルトでは、すべての Java プロセスに対して Java のトレース機能が無効になっています。 すべてのプロセスに対して、または特定のプロセスに対して無効にすることができます。
すべての Java プロセスで無効にする
すべてのプロセスに対して、デフォルトの Java トレース機能無効化するには、エージェント configuration.yaml ファイルを次のように設定してください:
com.instana.plugin.javatrace:
instrumentation:
enabled: false
Java のトレース機能を手動で有効にするには、 を に enabled: false 設定してください true。
単一の Java プロセスに対して無効にする
Java デフォルトでは、すべての Java プロセスでトレース機能が無効になっています。
Java プロセスのトレース機能無効化には、次のいずれかのオプションを使用してください:
- Java 仮想マシン( JVM )の引数として、
-Dinstana.java.tracer.enabled=falseシステムプロパティを追加します。 - **
INSTANA_JAVA_TRACER_ENABLED=false**システム環境変数を追加します。
計測プラグインの無効化
特定の計測プラグインを無効にすることで、オーバーヘッドを軽減したり、特定の技術をトレース対象から除外したりすることができます。 詳細については、 「計測プラグインの無効化」 を参照してください。
OpenTracing の計測機能を有効にする
「 Java Trace」の OpenTracing による計測を有効にするには、エージェント configuration.yaml ファイルを次のように設定してください:
com.instana.plugin.javatrace:
instrumentation:
opentracing: true
OpenTracing の計測機能を無効にするには、 を opentracing: false に設定してください false。
Java トレースSDKの有効化
Java Trace SDK を有効にするには、SDK アノテーションのスキャン対象となるパッケージのリストを以下のように指定して、エージェント configuration.yaml 設定ファイルを構成してください。 デフォルトでは、SDK アノテーションについてスキャンされるパッケージはありません。
com.instana.plugin.javatrace:
instrumentation:
sdk:
packages:
- 'com.instana.backend'
- 'com.instana.frontend'
Java Trace SDK を無効にするには、セクション packages 全体をコメントアウトしてください。
中間スパンを捕捉する
Instana Kafka Streamsおよび WebMethods Integration Serverにおいて、 Java アプリケーションの中間スパンをキャプチャできます。 ただし、この機能はデフォルトでは無効になっています。
この機能を有効にするには、以下のセクションを参照してください:
Kafka ストリームの中間スパンを有効にする
Kafka Streams では、すべてのストリーム・オペレーターが中間スパンとしてキャプチャーされます。 この機能は、大量のデータが流入する場合に、アプリケーションのパフォーマンスに影響を与えます。 実稼働環境ではこの機能を使用 しないでください 。
Kafka ストリームの中間スパンをキャプチャできるようにするには、 エージェント configuration.yaml ファイルに以下の行を追加してください:
com.instana.plugin.javatrace:
instrumentation:
plugins:
Kafka011StreamIntermediate: true
WebMethods Integration Server での内部サービス呼び出しを有効にする
WebMethods Integration Server では、すべてのサービス呼び出しを中間スパンとしてキャプチャする機能を有効にできます。 しかし、サーバーが重いワークロードを処理する場合、この機能はアプリケーションのパフォーマンスに影響を与える可能性がある。
WebMethods Integration Server で内部サービス呼び出しのキャプチャを有効にするには、 エージェント設定ファイル ` YAML ` に以下の行を追加してください:
com.instana.plugin.javatrace:
instrumentation:
plugins:
WebmethodsIntermediate: true
webMethods Integration サーバーで内部サービス呼び出しがキャプチャされる際に、中間スパンが生成されることによるパフォーマンスの低下を防ぐため、内部サービス呼び出しのキャプチャを有効にする設定に加えて、 エージェントの設定ファイル( YAML ) に以下の行を追加してください
com.instana.plugin.javatrace:
instrumentation:
enableIntermediateSpanOpt: true
plugins:
WebmethodsIntermediate: true
enableIntermediateSpanOpt: trueスタックトレースの取得を無効にする
Java Tracerは、終了スパンおよび中間スパンのスタックトレースをキャプチャします。 ただし、エントリスパンに対するスタックトレースは、デフォルトでは無効になっています。 アプリケーションのスタックが深かったり、1つのリクエストで複数のスパンが発生したりする場合、スタックトレースの取得はアプリケーションのパフォーマンスに影響を与える可能性があります。 パフォーマンスの問題が発生している場合は、スタックトレースを無効にすることでパフォーマンスを最適化できます。
スタックトレースの取得を無効にするには、 JVM を次のプロパティを指定して起動してください:
-Dinstana.tracing.stack.exit=-1 -Dinstana.tracing.stack.log=-1
次の例は、スタックトレースの取得を無効にする方法を示しています:
$ java -Dinstana.tracing.stack.exit=-1 -Dinstana.tracing.stack.log=-1 -jar application.jar
スパン相関の設定
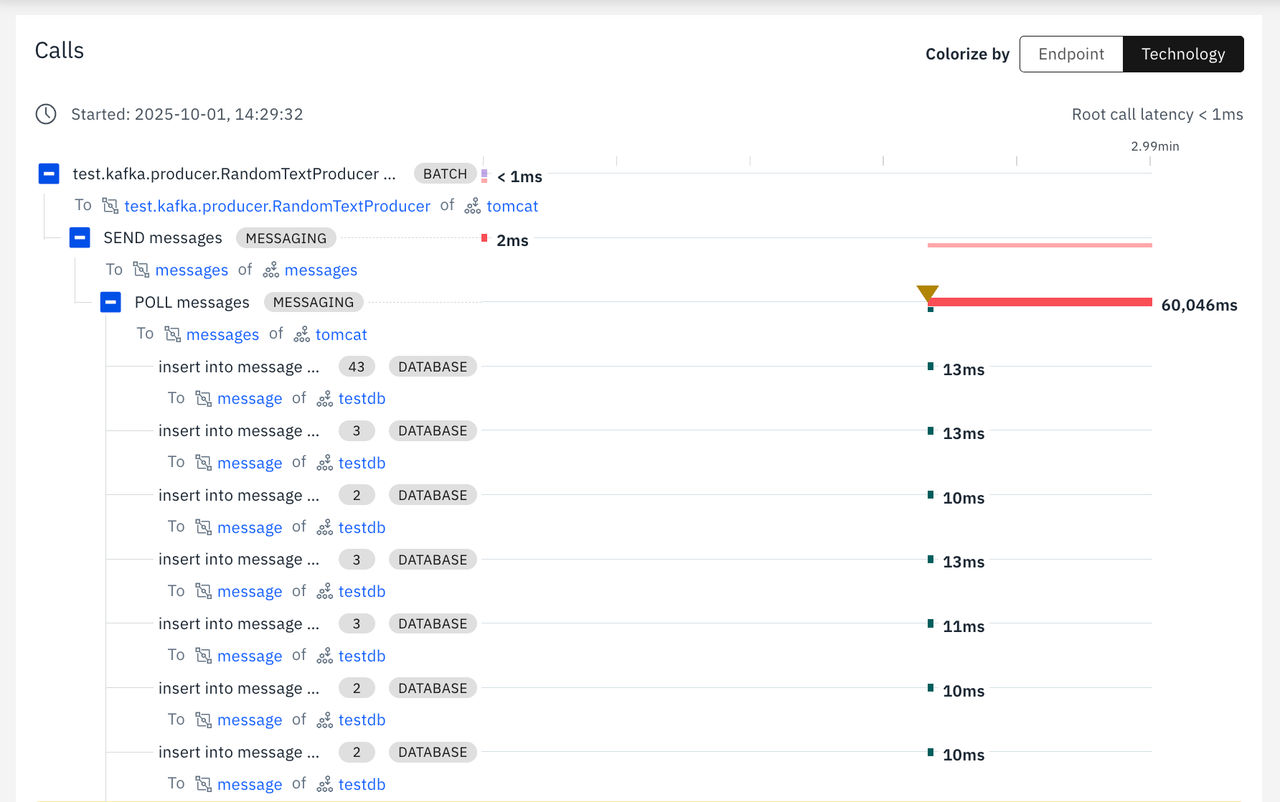
デフォルトでは、コンシューマーがメッセージを取得する際、受信操作全体を表す単一のスパンが生成され、すべてのメッセージが1つのスパンにまとめられます。 トレースの粒度を高めるために、メッセージ単位での相関分析を有効にする設定オプションが用意されています。
可観測性の向上のための Kafka スパン相関の設定
Kafka のユーザーがメッセージを取得する際、 Instana は通常、ポーリング操作全体を表す単一のspanを生成します。 つまり、1回のポーリングで取得されたすべてのメッセージは単一のPOLLスパンにまとめられるため、個々のメッセージがどのように処理されているかを把握しにくくなる可能性があります。
トレースの粒度を高めるため、 Instana には、メッセージがバッチ処理で消費される場合でも、個々の送信および受信操作ごとに相関付けを有効にする設定オプションが用意されています。 これにより、メッセージごとに個別のスパンを作成できるようになり、メッセージ単位の処理についてより詳細な分析が可能になります。
この instana.kafka.correlate.send.receive フラグを有効にすると、レコードが個別に処理される際に実行される操作を確認できるようになります。
そのフラグが役立つ場合
個別のレコード処理:
@KafkaListener(topics = "topicName", containerFactory = "kafkaListenerContainerFactory")
public void listen(ConsumerRecord<?, ?> record)
{
// Process single record
// DB operations, Kafka sends, etc.
}この場合、このフラグを有効にすると、個々のレコードの処理中に実行されるデータベースへの書き込み操作や Kafka への送信操作を確認できるようになります。
このフラグの使用が推奨されない場合
一括操作によるバッチ処理:
@KafkaListener(topics = "topicName")
public void receive(List<ConsumerRecord<?, ?>> consumerRecords) {
// Direct bulk operations without iterating through individual records
}レコードがバッチ処理として消費され、一括操作(データベースへの一括書き込みなど)が直接実行される場合、このフラグは有用ではなく、POLLスパン内の下流の呼び出しが隠れてしまう可能性があります。
バッチ処理に関する推奨事項
バッチ処理のユースケースでは、アプリケーションの起動時に特定の JVM を除外するようにシステムプロパティを設定することで、このフラグを無効にできます。 この設定により、下流の呼び出しが引き続き可視化されます。
java -jar -Dcom.instana.kafka.correlate.send.receive=false app.jar混合処理モデルに関する重要な考慮事項
アプリケーションで、 Kafka のバッチ・リスナー(バッチ処理)と標準の Kafka リスナー(単一レコード処理)の両方を使用している場合は、この instana.kafka.correlate.send.receive フラグに関する以下の制限事項に注意してください。
フラグが無効になっている場合、単一レコードの Kafka リスナーは、処理を個別のPOLLスパンとして表示しなくなります。 その代わりに、アプリケーションではレコードを個別に処理しているにもかかわらず、すべてのダウンストリーム呼び出しがそのスパン下にグループ化された単一のPOLLスパンとして表示されます。
Kafka のスパン相関を有効にするには、以下のいずれかの設定を使用してください:
- エージェントの設定:エージェント
configuration.yaml設定ファイルを構成します。com.instana.tracing: kafka: correlateEverySendReceive: true # possible values: true or false注:エージェント
configuration.yamlファイルを編集した後、エージェントまたはアプリケーションを再起動してください。 - 環境変数の設定:以下の例のように環境変数を設定してください:
INSTANA_KAFKA_CORRELATE_SEND_RECEIVE=true # possible values: true or false - システムプロパティの設定: JVM を起動する際に、以下のプロパティを設定してください:
-Dcom.instana.kafka.correlate.send.receive=true # possible values: true or false
以下の画像は、この設定を有効にした場合と無効にした場合で、スパン相関がどのように動作するかを示しています。

Instana で「 Kafka 」のスパン相関機能を完全に無効にするには、以下のいずれかの設定を使用してください:
- エージェント構成:
com.instana.tracing: kafka: correlateEverySendReceive: false - 環境変数の設定:環境変数を設定します。
INSTANA_KAFKA_CORRELATE_SEND_RECEIVE=false - システムプロパティの設定: JVM を起動する際に
-Dcom.instana.kafka.correlate.send.receive=false、このオプションを指定してください。
不要なデータの取り込みを防ぐため、この instana.kafka.correlate.send.receive フラグはデフォルトで無効になっています。
トレースの相関設定
Instana IBM Db2、 WebLogic、 T3、 IBM MQ、および Kafka などのテクノロジーでは、トレースに Java Tracerを使用しているため、トレースの相関関係機能はデフォルトで無効になっています。 これらのテクノロジーでトレースの相関関係を有効にするには、以下のセクションを参照してください:
IBM Db2 のトレース相関の設定
IBM Db2 のトレース相関を設定するには、以下の設定オプションのいずれかを使用してください:
エージェントの設定:エージェント
configuration.yaml設定ファイルを次のように設定してください:com.instana.tracing: db2: trace-correlation: true db2CorrelationMode: dont-override db2CorrelationDelimiter: '|' db2CorrelationField: ClientHostname環境変数の設定:以下の環境変数を設定してください:
INSTANA_DB2_TRACE_CORRELATION=true INSTANA_DB2_TRACE_CORRELATION_MODE=dont-override INSTANA_DB2_TRACE_CORRELATION_DELIMITER='|' INSTANA_DB2_TRACE_CORRELATION_FIELD=ClientHostnameシステムプロパティの設定: JVM のインストルメンテーション設定で、以下のシステムプロパティを設定してください:
-Djdbc.db2.correlation.enable=true -Djdbc.db2.correlation.mod=dont-override -Djdbc.db2.correlation.delimiter=| -Djdbc.db2.correlation.field=ClientHostname
TraceId その伝播 SpanId)は無効になっています。 伝播は、 Db2 のクライアント情報プロパティを使用して行われます。 相関フィールドは、デフォルトでフィールド ClientHostname 名を に設定します。 デフォルトの区切り文字は. です |。 相関モードが (デフォルト override )に設定されている場合、相関データは既存の値を上書きします。 ただし、この設定が「」になっていない override場合、相関データは既存の値に追加されます。WebLogic の構成 T3 トレースの相関付け
エンタープライズ・ Java ・Bean(EJB)の呼び出しでは、 WebLogic および T3 との相関関係がサポートされています。
WebLogics T3 のトレース相関を設定するには、以下の設定オプションのいずれかを使用してください:
エージェントの設定:エージェント
configuration.yaml設定ファイルを次のように設定してください:# General Tracing Settings com.instana.tracing: weblogic: trace-correlation: true環境変数の設定:以下の環境変数を設定してください:
INSTANA_WEBLOGIC_EJB_TRACE_CORRELATION=trueシステムプロパティの設定: JVM のインストルメンテーション設定で、以下のシステムプロパティを設定してください:
-Dcom.instana.weblogic.ejb.trace.correlation=trueこの設定は、 T3 間の通信が WebLogic サーバー間で行われる場合にのみ機能します。 ただし、 WebLogic クライアントを WebLogic サーバー以外で使用する場合、相関分析は行えません。
WeblogicRpcIntermediate: WebLogic の RPC コールトレースにおいて、リモートプロシージャコール( RPC )の中間コールスパンを有効にするには、エージェントconfiguration.yamlファイルを次のように設定する必要があります。 「 RPC 」の中間コールスパンを有効にすると、同じ WebLogic Server内の RPC コールを確認できるようになります。com.instana.plugin.javatrace: instrumentation: enableIntermediateSpanOpt: true plugins: WeblogicRpcIntermediate: trueWeblogicRpcIntermediate不要なデータの取り込みを防ぐため、デフォルトでは無効になっています。システムが中間スパンを作成する際に発生するパフォーマンス低下の問題を回避するには、
enableIntermediateSpanOptを有効にすることができます。
IBM MQ のトレース相関機能を有効にする
一部の IBM MQ コンシューマークライアントでは、 IBM MQ メッセージに余分なヘッダーデータが含まれていると、メッセージ処理エラーやメッセージの拒否が発生する可能性があります。 したがって、 IBM MQ Java アプリケーションでは、デフォルトで Instana トレースヘッダーの相関機能は有効になっていません。
本番環境で IBM MQ のトレース相関機能を有効にする前に、 非本番環境でテストを行う必要があります。 トレースの相関関係を有効にした後、 IBM MQ クライアントアプリケーションでエラーが発生した場合は、以下の手順でトラブルシューティングを行ってください
- アプリケーションを変更できる場合は、 Instana によって追加される IBM MQ ヘッダーデータを無視するように、アプリケーションを更新してください。 IBM MQ クライアントの設定変更に関するサポートが必要な場合は、 IBM MQ のサポートまでお問い合わせください。
- アプリケーションを変更できない場合は、 IBM MQ のトレース相関機能を有効にしないでください。
IBM MQ でトレースの相関機能を有効にするには、次のいずれかの設定オプションを使用してください:
エージェントの設定:以下の例に示すように、エージェント
configuration.yamlファイルを編集してください:# General Tracing Settings com.instana.tracing: ibm-mq: trace-correlation: true ibmmq-optin-queues-regexp: '^QueueName.*'トレースの相関を有効にしたいキュー名をフィルタリングするために、正規表現
ibmmq-optin-queues-regexpの値を設定します。 正規表現値はオプションであり、欠落している場合、トレース相関はすべてのキューに適用されます。この構成は、以下のいずれかのシナリオで選出されます。
- JVMが起動するとき
- Java Tracerが更新されたとき
- Instana エージェントが約15分間停止した後
実行時にホット・リロードされません。 この機能は最適化されているため、エージェントを素早く再始動してもこの構成変更が反映されない可能性があります。 構成変更には、完全な再インスツルメンテーションが必要です。
システムプロパティの設定:あるいは、次の例に示すように、 IBM MQ クライアントを含むアプリケーションJVMでシステムプロパティを指定することもできます
-Dinstana.ibm.mq.trace.correlation.enable=true -Dcom.instana.ibm.mq.trace.optin.queues="^QueueName.*"
IBM MQ センサーは、ユーザー・エクジット( IBM MQ 向けのサーバーサイド・トレーシング)を使用して、トレース機能も提供します。 IBM MQ センサーについて詳しくは、IBM MQ のモニターを参照してください。
Kafka のトレース相関ヘッダーの設定
Java Tracer で使用される Kafka トレース相関ヘッダーのヘッダー形式を有効にするには、次のいずれかの設定オプションを使用してください:
エージェントの設定:エージェント
configuration.yaml設定ファイルを構成します。 詳細については、「 Instana 」ホストエージェントを参照してください。環境変数の設定:以下の例のように環境変数を設定してください:
INSTANA_KAFKA_HEADER_FORMAT= both # possible values: binary, both, string有効な値は、
string、、またはbinaryですboth。システムプロパティの設定: JVM を起動する際に、以下のプロパティを設定してください:
-Dcom.instana.kafka.trace.header.format=binary # possible values: binary, both, string
Kafka のトレース相関機能を完全に無効にするには、以下の設定オプションのいずれかを使用してください:
- エージェントの設定: Instana host-agent を参照してください。
- 環境変数の設定:環境変数を設定しますが
INSTANA_KAFKA_TRACE_CORRELATION=false、このオプションの使用は推奨されません。 - システムプロパティの設定: JVM を起動する際に
-Dcom.instana.kafka.trace.correlation=false、このオプションを指定してください。
詳しくは、 Kafka ヘッダー・マイグレーションを参照してください。
スパンのバッチ処理の設定
スパン・バッチ処理とは、複数のスパンを結合し、それらを個別に送信するのではなく、バッチ単位でエージェントに送信する機能です。 スパンバッチ処理が有効になっている場合、名前、タイプ、および継続時間(10ミリ秒未満)が同じスパンは集約されます。 通常、データベースへの呼び出しなど、高頻度かつ短時間の処理はまとめて実行されます。
次の図は、spanのバッチ処理の実装を示しています。 ダッシュボードには5つのサブコールが表示されており、そのうち3つはバッチ処理され、「コール」セクションに一覧表示されています。
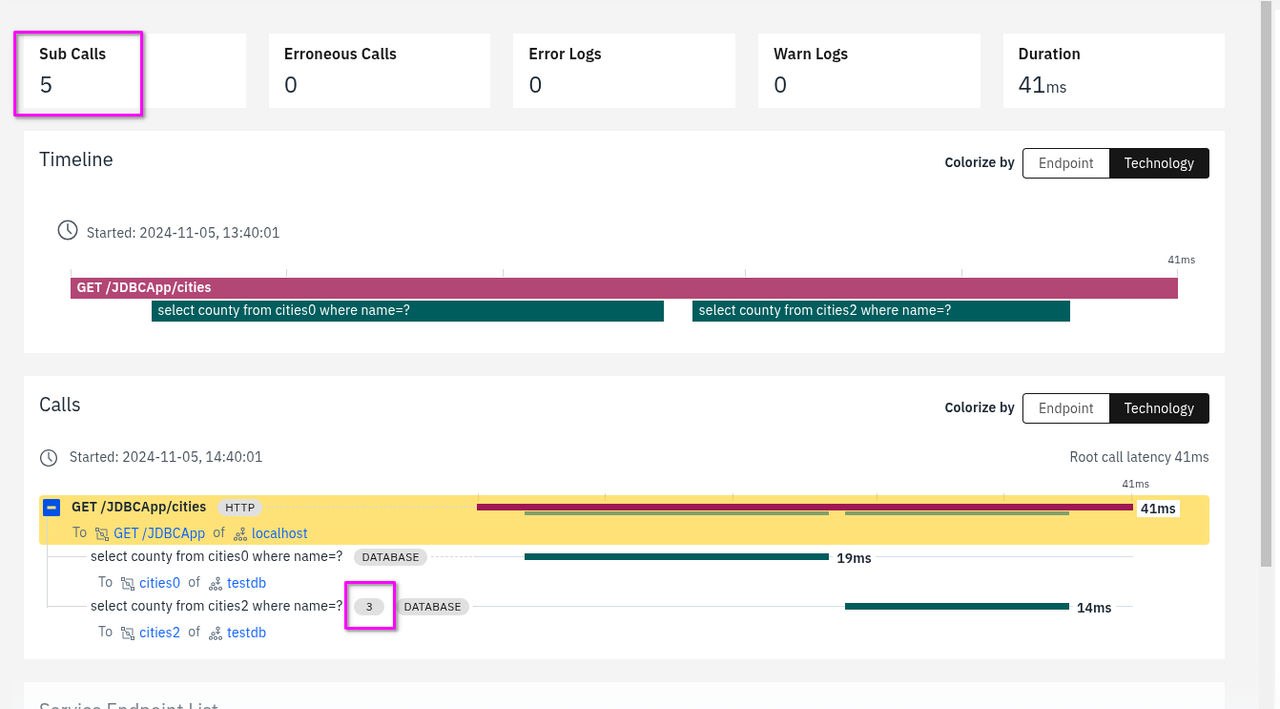
INSTANA_SPANBATCHING_ENABLED を に設定してください true。以下のアプリケーションでは、スパンバッチ処理が自動的に有効になります:Aerospike、Amazon s3、 Cassandra、Data Grid、 DynamoDB,、 Elasticsearch、FTP、 Google Cloud、Bigtable、 Google Cloud storage、HBase、 Hazelcast、 IMS、 JavaMail,、Kinesis、 LDAP、 Memcached、 MongoDB,、 Neo4j、および Redis。
Data Gridおよび JDBC については、特定のスパン結合戦略が採用されています。 詳細については、 「スパン・バッチ処理戦略」 を参照してください。
スパンバッチ処理を無効にする
スパンバッチ処理を無効にすると、送信される個々のスパンの数が増え、データ量が増加します。
スパンバッチ処理を無効にするには、以下の設定オプションのいずれかを使用してください:
エージェントの設定: エージェントの設定ファイルを次のように設定してください:
com.instana.plugin.javatrace: instrumentation: spanBatchingEnabled: false環境変数の設定:環境変数を次のように設定してください:
INSTANA_SPANBATCHING_ENABLED=falseシステムプロパティの設定: JVM の計測対象環境において、システムプロパティを次のように設定してください:
-DspanBatchingEnabled=false
WebLogic の RPC 中間スパンにおけるスパンバッチ処理を無効にする
中間スパンのバッチ処理を行うと、親スパンがマージされ、親子関係が切断されるため、子スパンが孤立した状態になります。 RPC の-intermediateスパンに対するバッチ処理を無効にすると、この問題は発生せず、トレース構造も正しく維持されます。 WebLogic RPC の中間スパンに対するスパンバッチ処理を無効にするには、以下の設定オプションのいずれかを使用してください:
エージェントの設定: エージェントの設定ファイル (<agent_install_dir>/etc/instana/configuration.yaml)を次のように設定してください:
com.instana.tracing: batching: disabled: - rpc-intermediate環境変数の設定:環境変数を次のように設定してください:
INSTANA_TRACING_BATCHING_DISABLED=rpc-intermediate
Data Gridおよび JDBC のスパンに対するスパン・バッチ処理戦略
Data Gridや JDBC などのアプリケーションでは、スパン・バッチ処理に対して以下のカスタム・バッチ処理戦略を実装しています:
データグリッド:連続するスパンにおいて、および
datagrid.operationの両方がdatagrid.cacheName同じ値を持つ場合にのみ、スパンは結合されます。 この条件が満たされた場合にのみ、スパンバッチ処理が有効になります。JDBC :以下の種類のスパンバッチ処理戦略がサポートされています:
デフォルトのバッチ処理 (デフォルトで有効)
JDBC のspan属性の値にかかわらず、スパンは結合されます。
カスタムバッチ処理 (オプション)
連続するスパンにおいての値が同一
JDBC.statementである場合にのみ、スパンは結合されます。
JDBC のスパンに対するカスタムバッチ処理を有効にする
JDBC のスパンでカスタムバッチ処理を有効にすると、取り込まれるデータのサイズが増加します。
JDBC のスパンでカスタムバッチ処理を有効にするには、以下の設定オプションのいずれかを使用してください:
エージェントの設定: エージェントの設定ファイルを次のように設定してください:
com.instana.plugin.javatrace: instrumentation: customJDBCSpanBatchingEnabled: true環境変数の設定:環境変数を次のように設定してください:
INSTANA_CUSTOM_JDBC_SPANBATCHING_ENABLED=trueシステムプロパティの設定: JVM の計測対象環境において、システムプロパティを次のように設定してください:
-DcustomJDBCSpanBatchingEnabled=true
スパン抑制の設定
Instana Java Tracer には、高負荷時にスパンを抑制し、リソースの過剰な消費を防ぐためのメカニズムが組み込まれています。 デフォルトでは、トレース機能は、1秒あたりの発生率が240スパンを超える場合、終了スパンおよび中間スパンの表示を抑制します。 この動作はシステムの安定性を維持するのに役立ちますが、次のような問題を引き起こす可能性があります:
- トレース内の欠落したスパン
- 孤立スパン(親を持たないスパン)
図 4. 孤立したスパン 
スパン抑制が発生すると、エージェントは次の例に示すようなメッセージをログに記録します:
Suppressed span(s) due to high number of short (< 4 ms) spans (SpanMonitor rate: 0.870 (last span: spring-rest 0-2486541141927097937:7078946718854091545:-2486541141927097937, duration: 3941 ms, erroneous: false, http.method: GET, http.host: example.com, http.url: http://example.com/api/testB,
http.size: 11, http.status: 200)スパン抑制制御パラメータ
スパン抑制は、以下の設定パラメータを使用して設定できます:
- minspanduration: このパラメータは、スパン期間の最小値を指定します(デフォルト:4 ms)。 この値より短いスパンは省略されます。
com.instana.plugin.javatrace: instrumentation: minspanduration: 1 - span-suppression-start: このパラメータは、抑制が開始されるスパンレートの閾値を設定します。 この値より低い場合、スパンは抑制されません。 ただし、レートがこの値を超えると、抑制は徐々に強まり、最大で毎秒5000スパン(すべてのスパンが抑制される状態)に達します。 たとえば、このパラメータが に設定されている
3000場合、スパンレートが 1 秒あたり 3000 スパンを超えたときにのみ、抑制が開始されます。com.instana.plugin.javatrace: instrumentation: span-suppression-start: 3000
span-suppression-start 取り込み量が増える可能性があります。ロギングレベルの設定
Instana で、ロギングレベルを有効または無効にできます。 Instana 以下のロギングレベルに対応しています:
OFFERRORWARN
ロギングレベルが設定されると、それより優先順位の高いすべてのロギングレベルがトレースに含まれます。 たとえば、が設定されている ERROR 場合、ログレベル ERROR とが FATAL トレースされます。
ユーザー定義のログレベルを有効にする
ロギングレベルを設定するには、以下の設定オプションのいずれかを使用してください:
- システムプロパティの設定: を
ERRORまたは にinstana_log_level_capture設定WARNします。 - 環境変数の設定:を または
ERRORにINSTANA_LOG_LEVEL_CAPTURE設定してくださいWARN。
無効なロギングレベル(たとえば、 INFO や TRACE)を指定した場合、エージェントのログに以下の警告が記録され、デフォルトのロギングレベル WARN が使用されます。
The value 'INFO' for 'INSTANA_LOG_LEVEL_CAPTURE' is not valid. Valid values are 'WARN', 'ERROR' and 'OFF'.
ロギングプラグインの無効化
すべてのロギングプラグインのロギングを無効にするには、以下の設定オプションのいずれかを使用できます:
エージェントの設定: Java のトレース設定を行い、エージェントの configuration.yaml ファイル内のすべてのロギングプラグインを無効にします:
com.instana.plugin.javatrace: instrumentation: plugins: Logging: falseシステムプロパティの設定:設定する
instana_log_level_capture="OFF"。- 環境変数の設定:設定する
INSTANA_LOG_LEVEL_CAPTURE="OFF"。注: エージェントの ` configuration.yaml ` ファイルを編集した後は、エージェントまたはアプリケーションを再起動する必要があります。
互換性のないエージェントを実行しているJVM向けに Java Tracerを設定する
Instana エージェントは、以下のいずれかのエージェントも実行しているJVMを自動的に監視しません:
- AppDynamics
- DataDog
- Dynatrace
- Glow Root
- Kanela、Kamon インスツルメンテーション・エージェント
- ManageEngine APM Insight Java エージェント
- New Relic
- Oracle Java Flight Recorder
- Java 用の OpenTelemetry インスツルメンテーション
- Riverbed AppInternals
- Spring Loaded
- Wily Introscope (CA Application Performance Management および Broadcom DX Application Performance Management とも呼ばれる)
これらのエージェントのいずれかを実行しているJVMを監視するには、エージェント configuration.yaml 設定ファイルを次のように設定してください:
com.instana.plugin.javatrace:
trace-jvms-with-problematic-agents: true
クラスを無視する
パッケージ内の特定のクラスまたは複数のクラスに対するインストルメンテーションを無効にするには、次の設定オプションのいずれかを使用できます:
エージェントの設定:エージェント
configuration.yamlファイルで、 Java トレースセンサーが特定のパッケージ内の1つまたは複数のクラスの計測を無視するように、次のように設定します:com.instana.plugin.javatrace: instrumentation: ignoredClass: "^ClassName or PackageName"たとえば、パッケージ
org.apache.derby内のすべてのクラスの計測機能を無効にするには、次の設定を使用します:com.instana.plugin.javatrace: instrumentation: ignoredClass: org.apache.derby.注: エージェントconfiguration.yamlファイルを編集した後は、エージェントまたはアプリケーションを再起動してください。システムプロパティの設定:以下の例のように
ignoredClass="^ClassName or PackageName"設定してください:-DignoredClass=org.postgresql環境変数の設定:設定する
IGNORED_CLASS_NAME="^ClassName or PackageName"。
エンドポイントを無視する
この機能により、特定のトレースや呼び出しを除外することで、不要なデータの取り込みを減らすことができます。 このフィルタリング方法により、トレースの収集が絞り込まれます。 トレースを無効にするには、以下の Java のTracer設定のいずれかでこのパラメータを定義してください:
この機能は、以下の技術で利用可能です:
- DynamoDB
- Redis
- Kafka
エンドポイントを無視する際の考慮事項
「エンドポイントの無視」機能を設定する前に、スパンのフィルタリングに関する以下のルールを確認してください:
- あるトレースが無視されると、それに続くすべての下流のトレースも同様に無視されます。
- を使用して
*、すべてのエンドポイント、メソッド、またはコマンドを無視します。 - エンドポイントの値( Kafka のトピック名や Redis のコマンドなど)は、サービス間で一貫しています。
- メソッド名は、プログラミング言語や技術によって異なる場合があります。 サービスの適切なメソッドとエンドポイントを確認するには、 Instana のUIを参照してください。
以下の Instana のUIスクリーンショットは、設定に適切なメソッドとエンドポイントを特定するための視覚的な参考資料となります:

「エンドポイントの無視」機能は、メソッド名が完全に一致する場合にのみ動作します。 フィルタリング対象として、正しいメソッド名を使用していることを確認してください。
エージェントの構成
エージェントを通じて設定を行うことで、すべてのサービスのエンドポイントをグローバルに無視することができます。
無視するエンドポイントを設定するには、次の例に示すように、エージェント設定ファイルの セクション com.instana.tracing.ignore-endpoints で、監視対象から除外するエンドポイントを指定します
com.instana.tracing:
ignore-endpoints:
# Filtering by Method Name
redis:
- 'get'
- 'type'
dynamodb:
- 'query'
# Filtering by Method Name and Endpoint for Kafka
kafka:
- methods: ["consume"]
endpoints: ["topic1", "topic2"] # Exclude consume calls for topic1 and topic2
- methods: ["consume", "publish"]
endpoints: ["topic3"] # Exclude both consume and send calls for topic3
- methods: ["*"]
endpoints: ["topic4"] # Exclude all methods for topic4
- methods: ["consume"]
endpoints: ["*"] # Exclude consume method for all topics前の例では、記載されたフィルタリングオプションに対して、以下のトレースは無視されます:
メソッドによるフィルタリング( Redis および DynamoDB )
GETおよびTYPERedis 内のコマンドQUERYDynamoDB 内のコマンド
メソッドとエンドポイントによるフィルタリング( Kafka のみ)
CONSUMEKafkatopic2およびすべての下流トレースにおける およびtopic1に対するメソッドCONSUMEおよびPUBLISH、topic3Kafka およびすべての下流トレースにおける手法- Kafka 内のすべてのメソッド
topic4(*)およびすべての下流のトレース CONSUMEすべてのトピック (*) およびすべてのダウンストリーム・トレースに対するメソッド
メソッドのオプション
Kafka メソッドでは、以下のオプションを使用できます:
- 消費者
consume: そしてpoll - プロデューサー
publish: およびsend
Kafka のエンドポイント数に制限はありません。 したがって、エンドポイントの数が多すぎると、パフォーマンスに影響を及ぼす可能性があります。 したがって、 Kafka のエンドポイントサイズの設定については、慎重に検討してください。 Redis また、 DynamoDB のエンドポイント一覧の表示件数は10件までに制限されています。
Kafka 「エンドポイントを無視する」には、の使用状況に基づいて設定を統合できる *という重要な機能があります。 次の例はこの特徴を示しています:
ignore-endpoints:
kafka:
- methods: [ "consume", "publish" ]
endpoints: [ "topic1", "topic2" ]
- methods: [ "consume" ]
endpoints: [ "topic3" ]
- methods: [ "*" ] # Applied to all methods
endpoints: [ "topic4" ]
- methods: [ "consume", "publish" ]
endpoints: [ "*" ] # Applied to all topics前の例では、記載されたフィルタリングオプションに対して、以下のトレースは無視されます:
- 最後のエントリで および
publish*メソッドconsumeに対して が適用されているため、すべてのトピックが無視されます。 この場合、他のすべてのエントリは上書きされます。 - 以前の設定はすべて無効になります。
環境変数
サービスごとにエンドポイントをフィルタリングするには、環境 INSTANA_IGNORE_ENDPOINTS 変数を使用して無視するエンドポイントを設定できます。
この環境変数を使用すると、メソッドやエンドポイントに基づいてトレースを除外することができます。
INSTANA_IGNORE_ENDPOINTS=redis:get,type;dynamodb:query,scan;kafka:publish,consumeこの設定では、以下のトレースがフィルタリングされます:
GETおよびTYPERedis 内のコマンドQUERYおよびSCANDynamoDB 内のコマンドPUBLISHおよび、すべてのエンドポイントに対する KafkaCONSUME内のメソッド
Kafka では、エンドポイントを無視するための環境変数を適用できますが、一度に指定できるのはエンドポイント1つとメソッド1つだけです。
INSTANA_IGNORE_ENDPOINTS=kafka:topic1,topic2,topic3,topic4,topic5,topic6,topic7,topic8,topic9,topic10,topic11Kafka では、 Redis や DynamoDB, とは異なり、エンドポイントの数は 10 に制限されません。 したがって、リストのサイズがパフォーマンスに影響を与える可能性があるため、慎重に検討する必要があります。
Kafka のメソッドオプションを使用して、環境変数を次のように設定します:
INSTANA_IGNORE_ENDPOINTS=kafka:consume,publish
OR
INSTANA_IGNORE_ENDPOINTS=kafka:poll,send
OR
INSTANA_IGNORE_ENDPOINTS=kafka:*システム・プロパティー
また、 Java システムプロパティを使用して、無視するエンドポイントを設定することもできます。 次の例は、システムプロパティを使用して無視するエンドポイントを設定する方法を示しています:
java -Dinstana.ignore-endpoints="redis:get,type;dynamodb:query,scan;kafka:publish,consume" -jar application-jarKafka では、エンドポイントを無視するためのシステムプロパティを適用できますが、一度に指定できるメソッドとエンドポイントはそれぞれ1つだけです。
java -Dinstana.ignore-endpoints="kafka:topic1,topic2,topic3,topic4,topic5,topic6,topic7,topic8,topic9,topic10,topic11" -jar application-jarKafka では、 Redis や DynamoDB, とは異なり、エンドポイントの数は 10 に制限されません。 したがって、リストのサイズがパフォーマンスに影響を与える可能性があるため、慎重に検討する必要があります。
Kafka のメソッドオプションを使用して、システムプロパティを次のように設定します
java -Dinstana.ignore-endpoints="kafka:consume,publish" -jar application-jar
OR
java -Dinstana.ignore-endpoints="kafka:poll,send" -jar application-jar
OR
java -Dinstana.ignore-endpoints="kafka:*" -jar application-jarスパン注釈の制限
デフォルトでは、1つのSpanに対して最大10個の注釈を追加し、 Instana のUIに表示することができます。
注釈の上限を増やす
Instana SDK を使用中に、Span に注釈をさらに追加する必要がある場合は、監視対象の JVM で以下のシステムプロパティを設定することで、この制限を引き上げることができます:
-Dinstana.tracing.annotation.size=<desired_limit>たとえば、制限を20に増やすには、アプリケーションを次のように起動します:
java -Dinstana.tracing.annotation.size=20 -jar application.jar- アノテーションの上限を増やすと、監視対象アプリケーションのメモリ使用量が増加します。 利用可能なシステムリソースに応じて値を調整してください
- システムプロパティを設定した後、変更を反映させるには JVM を再起動してください。
Java Tracer によって取得されたすべてのアノテーションの完全な一覧については、 「 Java のトレースアノテーション」 を参照してください。
誤ったスタックトレースの取得
トランザクション処理量が多いアプリケーションでは、スタックトレースの取得が重大なパフォーマンス上のオーバーヘッドとなる可能性があります。特に、操作の大部分が正常に完了し、スタックトレース情報が不要な場合には、その傾向が顕著です。 そのような場合、誤ったスタックトレースを取得する代わりに、関連する情報を得られるように最適化された手法を用いてスタックトレースを取得します。
以下の設定オプションのいずれかを使用することで、エラーが発生したスパンについてのみスタックトレースの取得を有効にすることができます。 エラーが発生したスパンについてのみスタックトレースを取得することで、正常に完了したスパンのスタックトレースをスキップし、パフォーマンスを向上させるとともにデータ取り込み量を削減できます。
エージェントの構成
エージェントの設定ファイルに以下の設定を行ってください:
com.instana.tracing:
stack.capture.timing: error動作 :エラーが発生したスパン(メタデータにエラーが含まれるスパン )についてのみスタックトレースをキャプチャします。これにより、正常に完了したスパンのスタックトレースを除外することで、パフォーマンスが向上し、取り込まれるデータ量が削減されます。
環境変数
お使いの INSTANA_TRACING_STACK_CAPTURE_TIMING 環境で、環境変数を次のように設定し、エクスポートしてください:
export INSTANA_TRACING_STACK_CAPTURE_TIMING=error- この変数を、アプリケーションが実行される環境で定義してください。
- アプリケーションを再始動して、変更を有効にします。
システム・プロパティー
以下のプロパティーを設定します。
-Dcom.instana.tracing.stack.capture.timing=error このシステムプロパティを使用するには、アプリケーションの起動時に次の引数を指定する必要があります:
java -Dcom.instana.tracing.stack.capture.timing=error -jar application.jarフィルタリングの設定
属性に基づいて特定のスパンを除外することで、トレースデータの量を削減できます。 この機能により、データ取り込みのコストを最適化し、アプリケーション監視のニーズに最も関連性の高いトレースに焦点を当てることができます。
HTTP および JDBC のスパンに対してフィルタリングが可能です。 エージェント configuration.yaml 設定ファイルを通じてフィルタリングルールを設定し、URL、SQL文、 HTTP メソッドなどの属性に基づいてスパンを除外することができます。
主な特長:
- HTTP エンドポイントのフィルタリング : HTTP のスパンを除外し、子スパンおよび下流のトレースを自動的に非表示にします。
- JDBC スパンフィルタリング :下流のトレースを抑制することなく、データベースのスパンを除外します。
- 柔軟な一致 :完全一致、先頭一致、末尾一致、部分一致、およびワイルドカード(
'*'*)パターンをサポートしています。 - 動的設定 :初期設定後は、アプリケーションを再起動することなく変更が反映されます。
フィルタリングの設定に関する詳細情報(設定構文、スパン属性、例、制限事項など)については、 「フィルタリングの設定」 を参照してください。
Open Liberty の誤ったスパンキャプチャを有効にする
Open Liberty Server では、エラーのあるスパンのキャプチャを有効にすることで、無効なコンテキストを持つリクエストをキャプチャできます。 この機能により、無効なコンテキストを含むリクエストが大量に発生した場合でも、アプリケーションからのデータ取り込み量を増加させることができます。 本番環境でこの機能を有効にする際は、十分にご注意ください。
Open Liberty で、無効なコンテキストを持つリクエストエントリのスパンをキャプチャできるようにするには、エージェント configuration.yaml ファイル(*instanaAgentDir*/etc/instana/configuration.yaml)に以下の行を追加してください:
com.instana.plugin.javatrace:
instrumentation:
plugins:
LibertyHttpChannelEntry: true