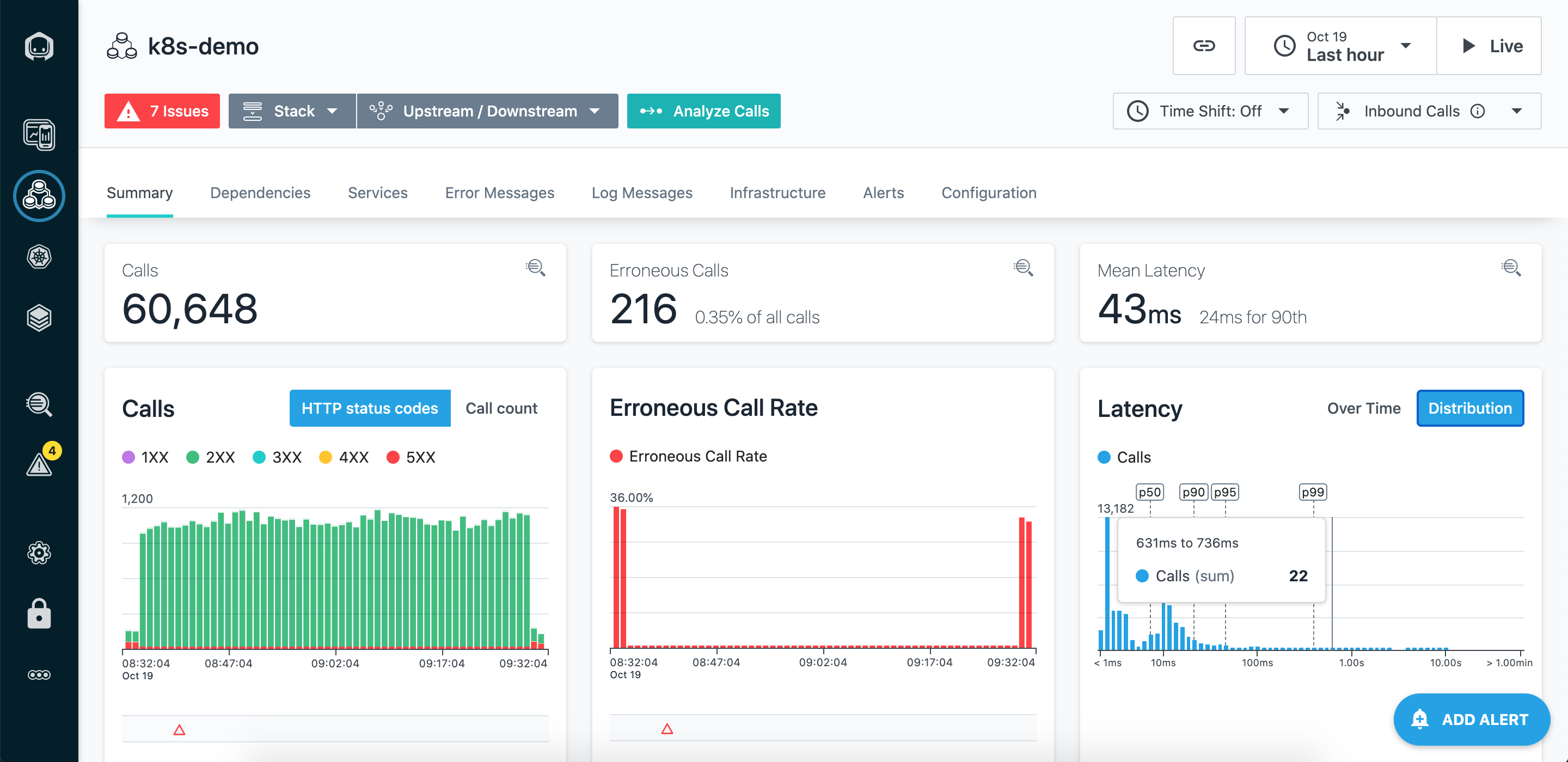
アプリケーションのモニタリング
Instana は、次世代の APM と、それらのサービス、エンドポイント、およびアプリケーション・パースペクティブのアプリケーション階層を紹介しています。 主な目的は、ビジネスのサービス品質のモニターを簡素化することです。 トレースやコンポーネントセンサーから収集されたデータに基づき、 Instana は、実装されているサービスから直接、アプリケーション環境を把握します。
従来の Application Performance Management (APM) ソリューションでは、アプリケーションのパフォーマンスと可用性を管理します。
APM ツール用のアプリケーションは、エージェントを使用してモニターされるコード・ランタイム (JVM や CLR など) の静的セットです。 通常、アプリケーションは各エージェントで構成パラメーターとして定義されます。
この概念は、従来型の 3 層アプリケーションに適したモデルでしたが、最新の (マイクロ) サービス・アプリケーションには有効ではありません。 サービスは、必ずしも 1 つのみのアプリケーションに属するとは限りません。 例えば、ある企業のオンラインストアと実店舗の両方で利用されているクレジットカード決済サービスを考えてみましょう。 各サービスをアプリケーションとして定義すれば、この問題は解決するかもしれませんが、それによって次のような新たな課題が生じます:
- 監視すべきアプリケーションが多すぎる :すべてのサービスをアプリケーションとして扱うと、数百から数千ものアプリケーションが生じてしまう。 データが過剰になるため、ダッシュボードを用いたアプリケーションの監視は現実的ではなくなってしまう。
- 文脈の欠如 :各サービスを個別に扱うと、依存関係や、問題の全体的な文脈におけるそのサービスの役割を理解することが難しくなる。
サマリー
待ち時間の分布
レイテンシの分布図は、アプリケーション、サービス、またはエンドポイントのレイテンシに関連する問題を調査するのに最適です。 チャート上でレイテンシの範囲を選択し、「Analyticsで表示」メニューを使用することで、 Unbounded Analytics 内で特定の呼び出しをさらに詳しく確認できます。
インフラに関する課題と変化
[概要 ] タブには、アプリケーション、サービス、またはエンドポイントに関連するインフラストラクチャの問題や変更が表示されます。 この情報は、誤検知率やレイテンシの増加など、注目すべきアプリケーション指標の変化との相関関係を特定するのに役立ちます。
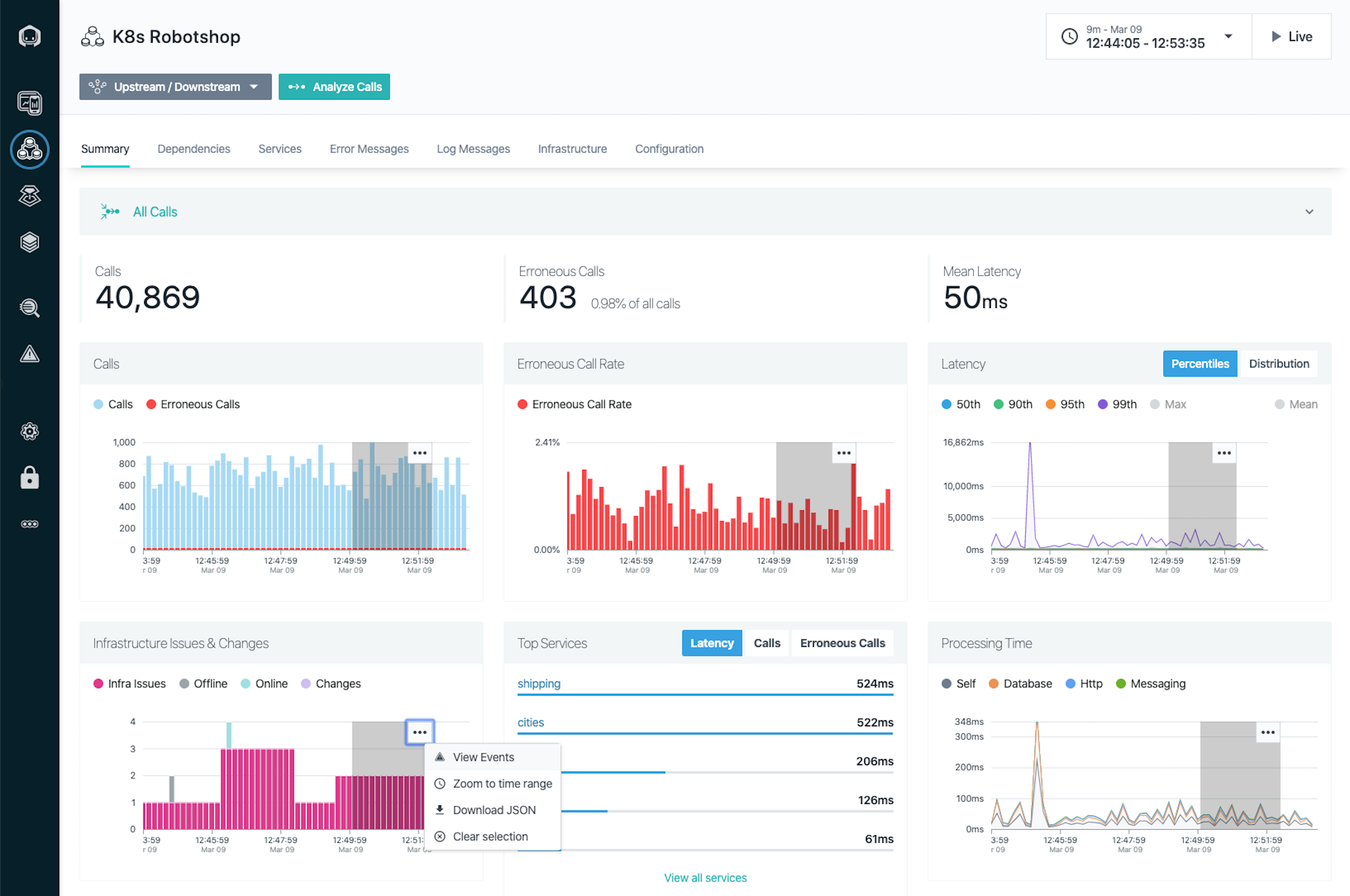
特定の問題または変更について詳しく知るには、チャート上で目的の時刻範囲を選択し、 イベントの表示 メニュー項目をクリックします。これにより、 イベント ビューが表示されます。
処理時間
「 処理時間 」チャートは、アプリケーション、サービス、またはエンドポイント自体での処理にどれだけの時間が費やされているか、Selfまた下流の依存関係への呼び出しにどれだけの時間が費やされているかを把握するのに役立ちます。これらは、 DatabaseHttp、 RpcMessaging、 SDK、、、などの呼び出しタイプごとに分類されています。
たとえば、サービス Shop への呼び出しのレイテンシが である場合 1000ms、サービス Shop がサービス Payment に対して HTTP 呼び出しを行い(これにかかる時間は 300ms )、さらにサービス Catalog に対して別のデータベース呼び出しを行い(これにかかる時間は 200ms)、サービス Shop 自身の処理時間は となる 1000-300-200=500ms。
タイム・シフト
指標を過去の期間と比較するには、画像に示されているような 「タイムシフト 」機能をご利用いただけます。 ヒストリカル・データに対してメトリックを比較する場合は、精度が低下することに注意してください。

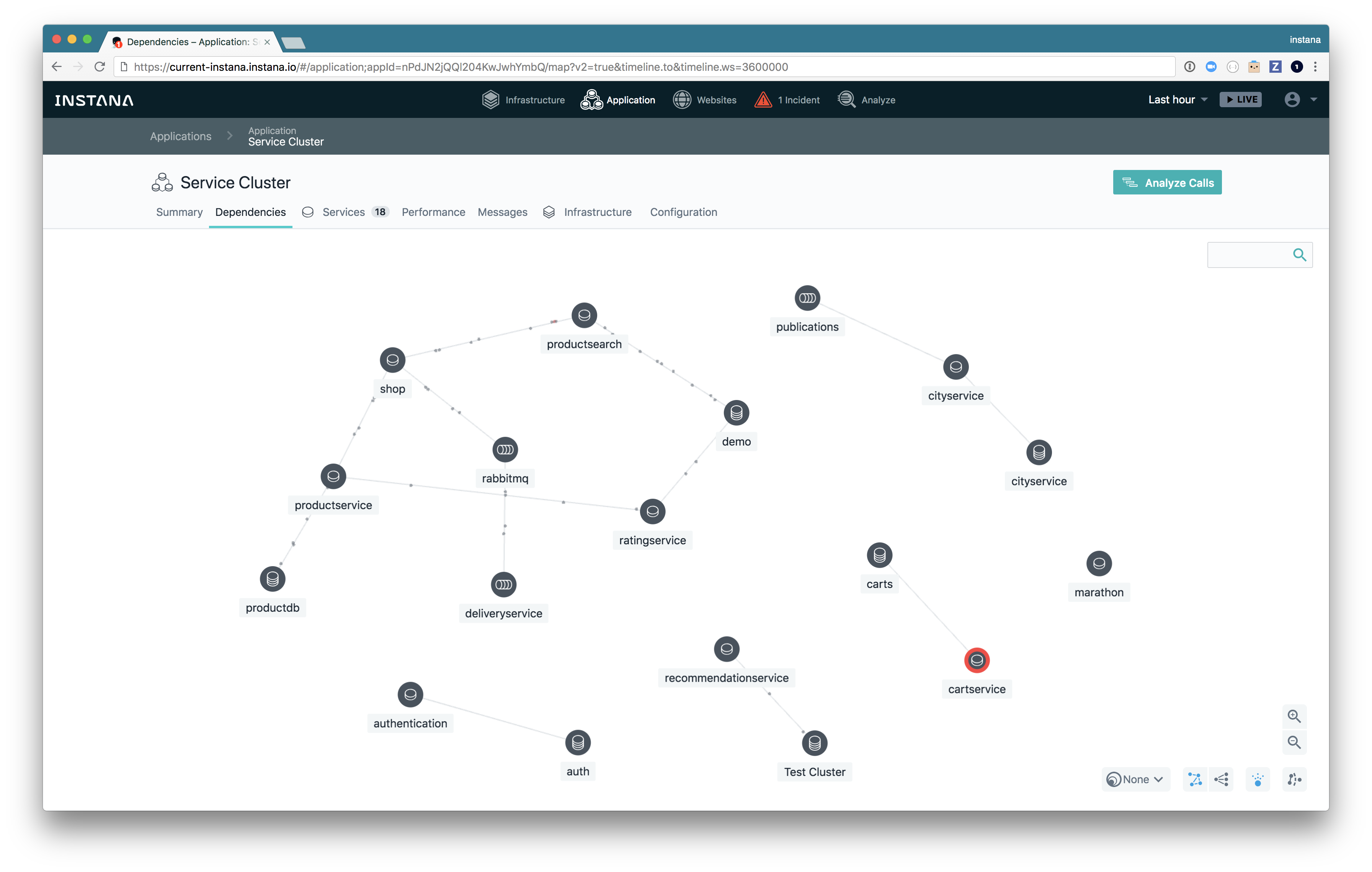
アプリケーション依存関係マップ
依存関係マップは、アプリケーションごとに使用可能であり、以下を提供します。
- アプリケーション内のサービス依存関係の概要。
- 通信パスとスループットを把握できる、サービス間の呼び出しのビジュアル表示。
- アプリケーションのアーキテクチャーを迅速に理解できる各種レイアウト。
- サービス・ビュー (ダッシュボード、フロー、呼び出し、および問題) への快適なアクセス。
エラー・メッセージ
エラーメッセージとは、サービスのコード実行中に発生したエラーから収集されたメッセージのことです。 たとえば、処理中に例外がスローされ、アプリケーションコードによってキャッチまたは処理されなかった場合、その例外は 「エラーメッセージ 」タブに一覧表示されます。 例えば、サーブレットの doGet メソッドで未処理の例外が発生すると、要求は HTTP 500 で応答されることになります。
ログ・メッセージ
ログメッセージは、監視対象のロギングライブラリやフレームワークから収集されます。 たとえば、 サポートされているライブラリの一覧にある「ロギング」のセクションを参照してください。 サービスがロギングライブラリを通じて「重大」 WARN 以上の深刻度のログメッセージを書き込むと、そのメッセージは 「ログメッセージ 」タブに表示されます。 また、キャプチャされたログメッセージは、そのトレースのコンテキスト内でトレースの詳細に表示されます。 ERROR 以上の重大度でログ・メッセージが書き込まれた場合は、エラーとしてマークされます。 深刻度が以下のログ WARN メッセージは追跡されません。
インフラストラクチャー
「アプリケーションの視点」ビューまたは「サービス」ダッシュボードから、 「インフラストラクチャの監視 」ビューに表示されている対応するインフラストラクチャコンポーネントに移動することができます。
「モニター対象外」インフラストラクチャー・コンポーネント
アプリケーションやサービスのインフラストラクチャ構成要素のリストには、場合によっては「監視対象外」のホスト、コンテナ、またはプロセスが含まれることがあります。
「監視対象外」というコンポーネントは、サービスへの呼び出しの一部またはすべてについて、特定のインフラストラクチャ・コンポーネントと関連付けることができなかったことを示しています。 サービスは「論理的な」エンティティであり、通常は監視対象のプロセスを通じてインフラストラクチャのコンポーネントと関連付けられています。 これは、監視対象外であるものの、ホスト名とパスを基にサービスやエンドポイントが作成されているサードパーティのWebサービスには適用されません。 ホストやプロセスが特定されていないため、これらのサービスは「不明」というインフラストラクチャ・コンポーネントに関連付けられています。
スマート・アラート
構成されているすべてのスマート・アラートのリストが表示されます。 アラートをクリックして、その構成の表示、変更、または改訂履歴の表示を行います。 必要に応じて、アラートの無効化や削除も行うことができます。
アラートの追加方法については、 「スマートアラート」 のドキュメントをご覧ください。
時間範囲の調整
Instana のダッシュボードや分析で使用される期間設定は、タイムピッカーで選択した期間と若干異なる場合があります。 ダッシュボードまたは分析の時刻範囲では、最初の部分バケットと最後の部分バケットが除外されます。 例えば、1月20日午後3時15分にタイムピッカーで「 過去24時間」のプリセットを選択すると、時間範囲は January–3:00 までに調整されます。 この調整は、それぞれのグラフの細分度が 30 分であるために行われます。 時刻範囲の調整により、同じページ上のさまざまなウィジェット間の整合性が確保され、部分的なバケットが予期しないメトリック・トレンド (例えば、呼び出し回数の減少) として誤って解釈されることが回避されます。
概算データ
Analyticsでダッシュボードを表示したり、過去7日間を超える特定の期間についてクエリを実行したりすると、一部のウィジェットに「推定データインジケーター」が表示される場合があります。これは、 Instana がクエリを処理するために、統計的に有意なトレースや呼び出しの数を絞り込んでアクセスしていることを示すものです。 例:
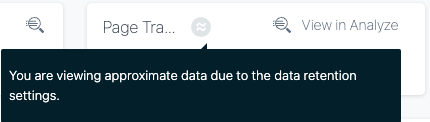
めったに発生しないトレースおよび呼び出しは、そのようなシナリオでは表示されない可能性があります。
コールレベルの指標におけるサンプリング精度に関する注記
このシステムは、トレースIDのハッシュ値に基づくランダムサンプリングを採用しており、これによりトレースレベルでの一貫したサンプリングが保証されます。 しかし、これはコールレベルの指標を分析する際に、いくつかの点で影響を及ぼします:
- サンプリングは呼び出しごとではなく、トレースごとに行われます。 トレースの規模(たとえば、トレースあたりの呼び出し数)に大きなばらつきがある場合、呼び出しレベルのデータに偏りが生じる可能性があります。
- たとえば、 2.4 万回以上の呼び出しを含む単一のトレースが、システムによってサンプリング対象に含まれた場合、呼び出しレベルのメトリクスに大きな影響を与える可能性があります。
- これは想定された動作であり、不具合ではありません。 これは、トレースベースのサンプリングがどのように機能するかを示しています。