Supported data sources in Data Virtualization
Data Virtualization supports the following relational and nonrelational data sources on IBM® Cloud Pak for Data.
- IBM data sources
- Third-party data sources
- User-defined data sources
- Data sources accessed by using remote connectors
See also Supported data sources in Cloud Pak for Data.
- Size limits
- Data Virtualization supports virtualization of tables with a row size up to 1 MB, and up to 2048 columns in a table. However, the number of columns that Data Virtualization can preview depends on many factors, such as the data types of the columns. Currently, preview is limited to 200 columns.
- Comment attributes
- When virtual tables are created, Data Virtualization does not include comment attributes that were assigned to data source objects. This limitation applies to all data sources.
- Data types
- Some data types in your data source might not be supported in Data Virtualization. These limitations are documented in the following tables. Data Virtualization might also map some data types in your data source to alternate data types. These mappings are based on underlying Db2® Big SQL mappings. For more information, see Data types in Db2 Big SQL.
IBM data sources
The following table lists the IBM data sources that you can connect to from Data Virtualization.
| Connection type | Limitations | More information |
|---|---|---|
| IBM Cloud® Compose for MySQL | ||
| IBM Cloud Databases for MongoDB | IBM Cloud Databases for MongoDB is available as beta.
The following MongoDB data types are supported in Data Virtualization: INT32, INT64, DOUBLE, STRING, BOOLEAN, DATE, and BINARY. |
|
| IBM Cloud Databases for PostgreSQL |
This connection is optimized to take advantage of the query capabilities in this data source. |
|
| IBM Cloud Object Storage |
This connection requires special consideration in Data Virtualization. See Connecting to IBM Cloud Object Storage in Data Virtualization. For limitations, see Data sources in object storage in Data Virtualization. |
|
| Data Virtualization |
Important: Do not create a connection to your Data
Virtualization
instance.
See also Manually creating a Data Virtualization connection in the catalog. |
|
| IBM Data Virtualization Manager for z/OS® |
This connection is optimized to take advantage of the query capabilities in this data source. |
|
| IBM Db2 |
|
This connection is optimized to take advantage of the query capabilities in this data source. |
| IBM Db2 Big SQL |
This connection is optimized to take advantage of the query capabilities in this data source. |
|
| IBM Db2 Event Store | ||
| IBM Db2 for i | ||
| IBM Db2 for z/OS | ||
| IBM Db2 Hosted | ||
| IBM Db2 on Cloud | The NCHAR and NVARCHAR types are not supported in Data Virtualization. | |
| IBM Db2 Warehouse | ||
| IBM Informix® | INTERVAL, BIGINT, and BIGSERIAL data types are not supported in Data Virtualization. For more information, see Exceptions occur when using the Connect for JDBC Informix driver. | |
| IBM Netezza® Performance Server |
|
This connection is optimized to take advantage of the query capabilities in this data source. |
| IBM Planning Analytics |
|
Third-party data sources
The following table lists the third-party data sources that you can connect to from Data Virtualization.
| Connection type | Limitations | More information |
|---|---|---|
| Amazon RDS for MySQL |
|
This connection is optimized to take advantage of the query capabilities in this data source. |
| Amazon RDS for Oracle |
|
This connection is optimized to take advantage of the query capabilities in this data source. |
| Amazon RDS for PostgreSQL |
This connection is optimized to take advantage of the query capabilities in this data source. |
|
| Amazon Redshift | SPATIAL, SKETCH, and SUPER data types are converted to CLOB in Data Virtualization. |
This connection is optimized to take advantage of the query capabilities in this data source. |
| Amazon S3 |
This connection requires special consideration in Data Virtualization. See Connecting to Amazon S3 in Data Virtualization.
|
|
| Apache Derby |
This connection is optimized to take advantage of the query capabilities in this data source. |
|
| Apache Hive |
|
This connection is optimized to take advantage of the query capabilities in this data source. |
| Ceph |
This connection requires special consideration in Data Virtualization. See Connecting to Ceph in Data Virtualization. For limitations, see Data sources in object storage in Data Virtualization. |
|
| Cloudera Impala |
This connection is optimized to take advantage of the query capabilities in this data source. |
|
| Denodo | ||
| File system |
Important: This type of connection is not recommended for use in IBM Cloud Pak for
Data. Connect to files in your
file system by using a remote connector. For more information, see Accessing data sources by using remote connectors in Data Virtualization.
|
|
| Google BigQuery |
This connection requires special consideration in Data Virtualization. See Connecting to Google BigQuery in Data Virtualization.
|
This connection is optimized to take advantage of the query capabilities in this data source. |
| Greenplum | ||
| MariaDB |
|
This connection is optimized to take advantage of the query capabilities in this data source. |
| Microsoft Azure SQL Database | ||
| Microsoft SQL Server |
|
This connection is optimized to take advantage of the query capabilities in this data source. |
| MongoDB |
|
|
| MySQL (My SQL Community Edition) (My SQL Enterprise Edition) |
|
This connection is optimized to take advantage of the query capabilities in this data source. |
| Oracle |
|
This connection is optimized to take advantage of the query capabilities in this data source. |
| PostgreSQL |
This connection is optimized to take advantage of the query capabilities in this data source. |
|
| Salesforce.com | ||
| SAP ASE | ||
| SAP Business Warehouse (BW) (Using the SAP OData connection type) |
If your SAP Business Warehouse (BW) data source is not configured to expose its CatalogService, you must specify an explicit service (or a list of services) by using the DataDirect ServiceList connection property. Include this ServiceList connection property in the SAP Gateway URL connection property. You can check the CatalogService by using an HTTP
request. For example
You cannot preview or query nonreadable tables due to the following reasons:
|
|
| SAP HANA and SAP HANA on SAP Cloud Platform |
This connection requires special consideration in Data Virtualization. See Connecting to SAP HANA in Data Virtualization and Connecting to SAP HANA on SAP Cloud Platform in Data Virtualization. To configure pushdown of VARCHAR predicates to SAP HANA, apply the following steps.
Note: You must ensure that you have no trailing blanks in the varchar data and
that the collating sequence in Data
Virtualization is the same as on the remote SAP HANA data source.
If you preview SAP HANA data sources that contain data with a data type of TINYINT, you see inaccurate data for some rows of type TINYINT. However, you can virtualize the data source. Only preview is affected. |
This connection is optimized to take advantage of the query capabilities in this data source. |
| SAP OData |
You cannot preview or query nonreadable tables due to the following reasons:
|
|
| SAP S/4HANA (Using the SAP OData connection type) |
You cannot preview or query nonreadable tables due to the following reasons:
|
|
| Snowflake |
This connection requires special consideration in Data Virtualization. See Connecting to Snowflake in Data Virtualization.
|
This connection is optimized to take advantage of the query capabilities in this data source. |
| Teradata Teradata JDBC Driver 17.00 Copyright (C) 2015 - 2017 by Teradata. All rights reserved. IBM provides embedded usage of the Teradata JDBC Driver under license from Teradata solely for use as part of the IBM Watson® service offering. |
|
This connection is optimized to take advantage of the query capabilities in this data source. |
User-defined data sources
The following table lists the user-defined data sources that you can connect to from Data Virtualization.
| Connection type | Limitations | More information |
|---|---|---|
| Generic JDBC |
This connection requires special consideration in Data Virtualization. See Connecting to data sources with a generic JDBC driver in Data Virtualization. |
Data sources in object storage in Data Virtualization
You can use data that is stored as files on IBM Cloud Object Storage, Amazon S3, or Ceph data sources to create virtual tables. To access data that is stored in cloud object storage, you must create a connection to the data source where the files are located.
You can segment or combine data from one or more files to create a virtual table. Accessing files in object storage in Data Virtualization is built on Db2 Big SQL capabilities that use Hadoop external table support. For more information, see CREATE TABLE (HADOOP) statement.
Terminology
- A bucket is a logical abstraction that is used to provide a container for data. There is no folder concept in object storage; only buckets and keys. Buckets can be created only in IBM Cloud Object Storage, Amazon S3, or Ceph interfaces. They cannot be created in Data Virtualization.
- A file path is the complete path to the file where you want to store data. The S3 file system implementation allows zero-length files to be treated like directories, and file names that contain a forward slash (/) are treated like nested directories. The file path includes the bucket name, an optional file path, and a file name. In object storage, the file path is used when a table is created. All files in the same path contribute to the table data. You can add more data by adding another file to the file path.
- A partition is data that is grouped by a common attribute in the schema. Partitioning divides the data into multiple file paths, which are treated like directories. Data Virtualization can discover and use partitions to reduce the amount of data that queries must process, which can improve performance of queries that use predicates on the partitioning columns.
Best practices
- File formats
- Data
Virtualization supports PARQUET (or PARQUETFILE), ORC (optimized row columnar), CSV
(comma-separated values), TSV (tab-separated values), and JSON file formats. No other file formats
are supported.
- For PARQUET (or PARQUETFILE), file extensions are not required. Metadata is extracted from the data file.
- For ORC, file extensions are not required. Metadata is extracted from the data file.
- For CSV and TSV files, the .csv or .tsv file extension is required.
- For JSON files, the .json file extension is required. JSON files must be
coded so that each line is a valid JSON object. Lines must be separated by a newline character
(
\n). The JSON Lines text format, also called newline-delimited JSON, is the only supported JSON format. This format stores structured data that can be processed one record at a time.
Note: All other file formats return an error. For more information, see Error message when you try to use an unsupported file format in Cloud Object Storage. - Organizing data
-
- If your object storage data is accessed through a virtualized table, the files that you want to virtualize must be within a single file path and within a single bucket, and the bucket must include at least one file that you add to the cart. All the files in this file path are part of the virtualized table. When more data is added to the table (new files are created in the file path), the data is visible when you access the virtualized table. All files in the file path must use the same file format so that they are virtualized as one table.
- If you want to virtualize the files in multiple file paths as one table, you can virtualize the bucket that contains all of the files. For example, if you have file paths A/B/C/T1a, A/B/C/T1b, A/B/D/T1c, and A/B/D/T1d, you can virtualize the file path A/B/. All the files in that path and nested paths will be part of the accessible object.
- Do not create two objects (tables, schemas, or columns) with the same name, even if you use delimited identifiers and mixed case. For example, you cannot have a table t1 and another table that is named T1. These names are considered to be duplicate names in object storage (Hive). For more information, see Identifiers.
- When new data is added to the file path for a virtualized table, consider running the following
command to ensure that the metadata cache is updated to see the new
data.
CALL SYSHADOOP.HCAT_CACHE_SYNC(<schema>, <object>)For more information, see the HCAT_CACHE_SYNC stored procedure.
- When new partitions are added to the file path for the virtualized
table, click Refresh partitions in the overflow menu on the
Virtualized data page to identify new partitions.
You can also run the following command in the SQL interface to identify the new partitions that were added.
MSCK REPAIR TABLE <table-name>For more information, see MSCK REPAIR TABLE.
- Optimizing query performance
-
- Use a compact file format such as ORC or Parquet to minimize network traffic, which improves query performance.
- Don't use the STRING or TEXT data type. Use the VARCHAR(n) data type, with
n set to a value that is appropriate for the column data. Use the following
command to alter the table to define an appropriate length for the
column.
ALTER TABLE <schema>.<table> ALTER COLUMN <col> SET DATA TYPE VARCHAR(<size>) - Partition your data by using Hive style partitioning. Partitioned data is grouped by a common
attribute. Data
Virtualization can use partitions to reduce the amount of data that queries must
process. Querying the entire data set might not be possible or even necessary. You can use
predicates in your queries that include the partitioning columns to improve performance.
For example, a school_records table that is partitioned on a year column, segregates values by year into separate file paths. A
WHEREcondition such asYEAR=1993,YEAR IN (1996,1995), orYEAR BETWEEN 1992 AND 1996scans only the data in the appropriate file path to resolve the query.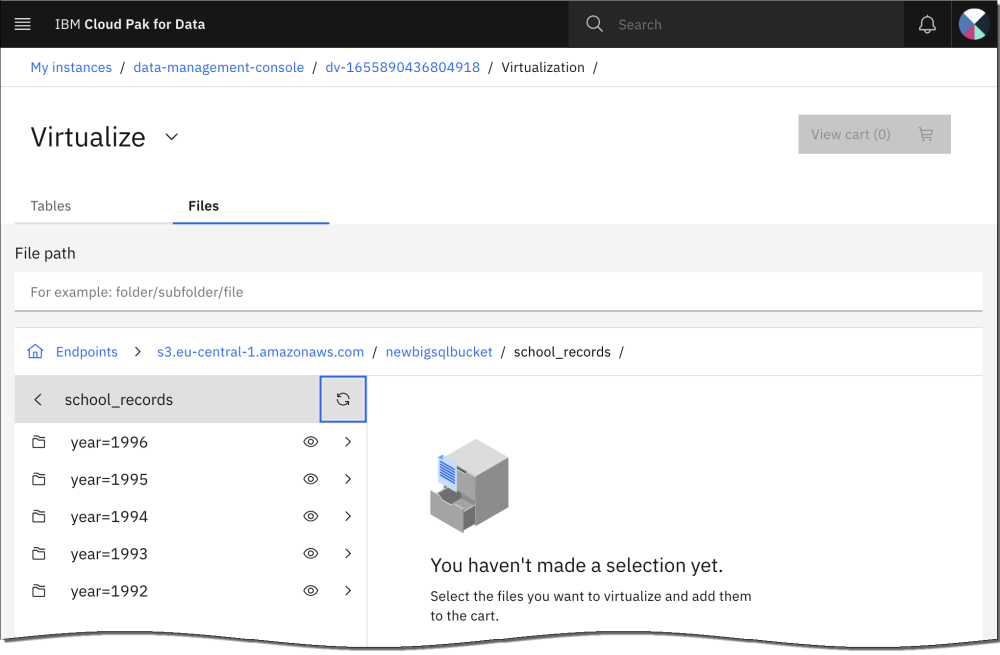
- Define partitioned column types accurately. By default, partitioned character columns are assumed to be STRING type, which is not recommended. Redefine the partitioned columns to an appropriate data type.
- Collect statistics on the data that is being queried. Data Virtualization uses the ANALYZE command to collect statistics on virtualized tables over object storage. You can collect statistics in the web client or by using SQL. For more information, see Collecting statistics in Data Virtualization.
Limitations
- Only UTF-8 character encoding is supported in Data Virtualization for text files in CSV, TSV, or JSON format. Cloud Object Storage binary formats such as ORC or PARQUET are unaffected because they transparently encode character types.
- Data Virtualization does not support the TIME data type in a virtualized table over object storage.
- Data Virtualization does not support preview of compressed files. For more information, see Error message when you virtualize a compressed file in Cloud Object Storage.
- You cannot connect to a data source in cloud object storage by using credentials that are stored in a vault.
- Preview of assets in cloud object storage shows only the first 200 columns of the table.
- Data
Virtualization does not support flat file encoding such as
quoteChar, which allows you to specify how strings are delimited in a flat file. For more information, see Unexpected preview or query results for virtualized tables over flat files in Data Virtualization. - Before you remove a connection to Cloud Object Storage, you must remove all virtualized tables in the object storage connection. If a connection is removed and you try to remove a table in that connection, you see an error. See Credential error message when you remove a virtualized table in object storage.
See also Restrictions
in CREATE TABLE
(HADOOP) statement.