Implementing high availability and disaster recovery
High availability (HA) and disaster recovery (DR) are requirements for production deployments that use IBM Fusion Data Foundation. A crucial consideration is removing single points of failure on the various layers of the environment. The goal is to avoid planned and unplanned outages and ensure continuous operation.
The considerations for HA and DR include the following:
- All layers of the environment must be included to secure continuous operations of the workload.
- Application development and DevOps need to ensure that new services can be deployed and operated without downtime that is also known as rolling updates.
- The operational procedures are well defined and consider HA and DR.
IBM virtualization and the IBM Z platform provide best practices and mechanisms for setting up highly available environments, including replication, failover, and shifting of workload between systems. This makes it a perfect match for ensuring continuous operations (for example, redundancy of hardware elements). Red Hat OpenShift Container Platform (RHOCP) adds with its cluster-based implementation, the ability for automatic failover of workloads within the same cluster.
In addition to the considerations for high availability, there are several topologies, which can be applied to implement disaster recovery and involve a second data center site for redundancy. In case of a disaster the secondary site takes over and run the entire workload. Each site is referred to as an availability zone.
The first set of topologies is based on the Red Hat OpenShift software stack. High availability and disaster recovery are implemented in software. This implementation adds an abstraction layer, which is application-scoped and hardware agnostic.
- High availability with a single stretched cluster across 3 availability zones.
- Regional disaster recovery: 2 separate clusters with asynchronous replication of data and active/passive configuration.
- Metro disaster recovery: 2 separate clusters in a active/active configuration and with synchronous replication of data in an external IBM Storage Ceph environment, which is stretched across the data centers.
A hardware-based option to achieve disaster recovery is based on IBM Geographically Dispersed Parallel Sysplex (GDPS) technology, which is implemented based on mirroring of the storage hardware and agnostic to the running applications. GDPS allows synchronous and asynchronous mirroring for metro and global distance. GDPS also adds management capabilities for nodes and network switches.
The different topologies for HA and DR are described in the following sections.

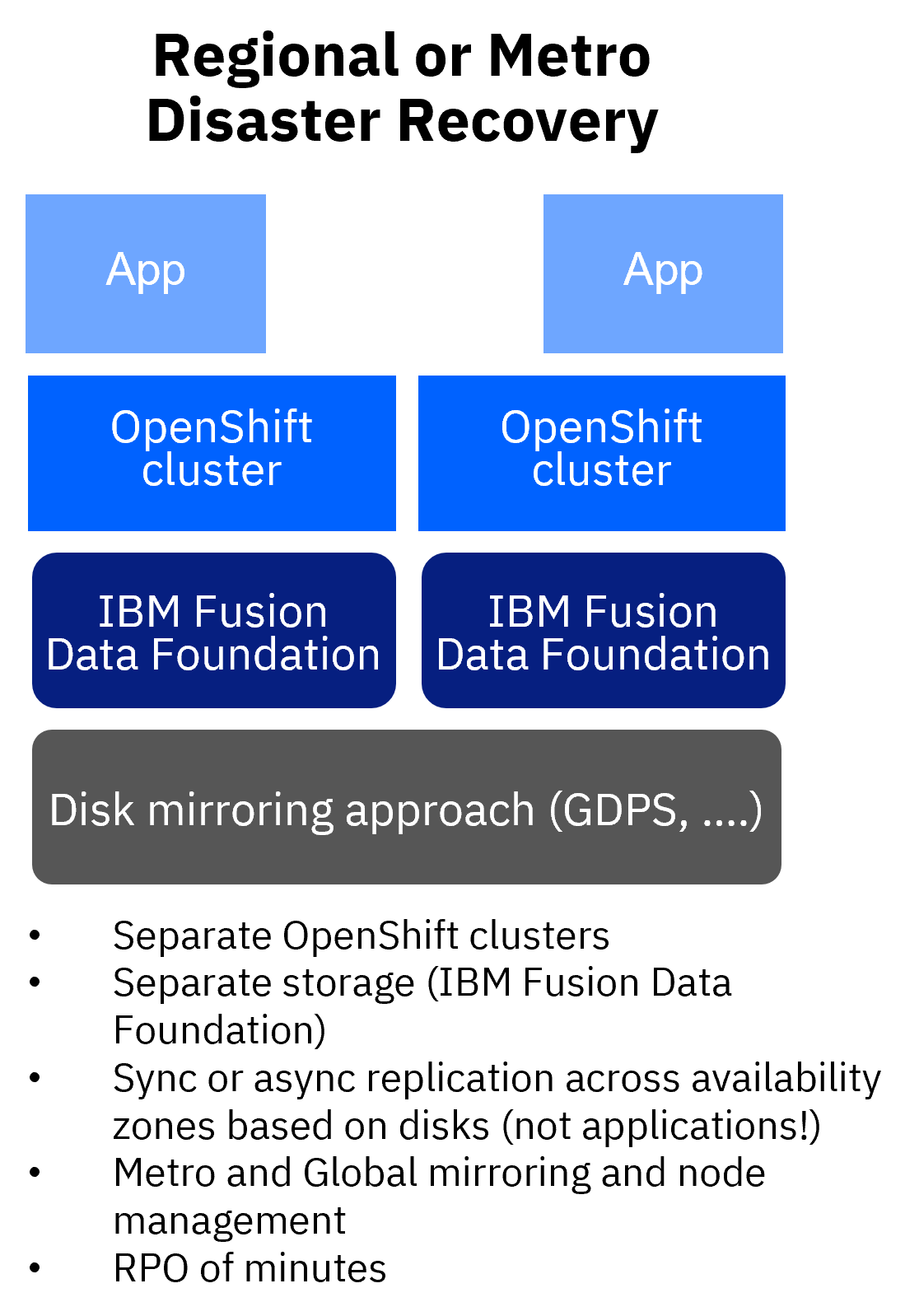
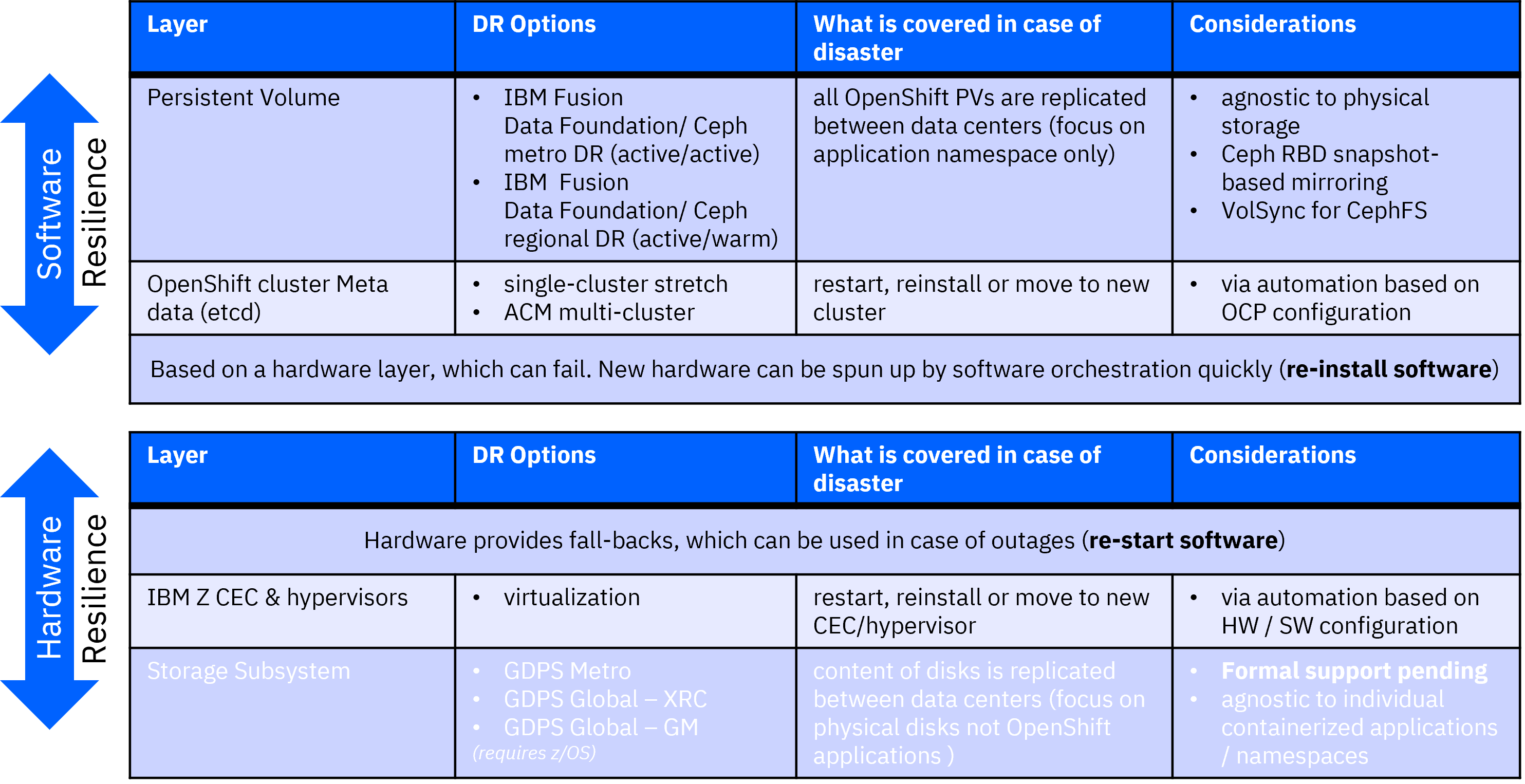
It needs to be emphasized that the mentioned DR topologies using the Red Hat OpenShift software stack are based on the fundamental assumption that hardware is unreliable and software must implement resilience. As this assumption is not true for IBM Z, the combination of resilience in software combined with resilience in hardware results in a reliable overall system.
The hardware-based resilience is focused on keeping a system alive by all means by using redundancy. The software-based resilience replaces failing instances immediately with new software deployments created fresh from a CI/CD pipeline and automation. This different point of view is often referred to as dealing with precious "pets" versus abundant "cattle".
