Storage
Many containerized workloads, including several core RHOCP services, require a persistent storage solution to maintain data persistence when pods are deleted or restarted. The variety of storage types, like file, block, and object storage enable options that you need to consider depending on the implementation and workload.
RHOCP uses the Kubernetes Persistent Volume (PV) framework to allow cluster administrators to provision persistent storage for a cluster. The Kubernetes persistent volume (PV) framework allows RHOCP users to request persistent volumes without any knowledge of the underlying storage. The users use Persistent Volume Claims (PVCs) to request PV resources, without having specific knowledge of the underlying physical storage infrastructure. PV resources on their own are not scoped to any single project. They can be shared across the entire RHOCP cluster and claimed from any project. After a PV is bound to a PVC, that PV cannot be bound to any additional PVCs. Consider that PVs represent a piece of existing storage in the cluster that was either statically provisioned by the cluster administrator or dynamically provisioned.
Storage Classes
The following storage options apply:
- Block Storage (used to store data files on Storage Area Networks (SANs) or cloud-based storage environments)
- File Storage (as file-level or file-based storage, is normally associated with Network Attached Storage (NAS) technology)
- Object Storage (breaks up data files into pieces that are called objects and stores those objects in a single repository, which can be spread out across multiple networked systems)
Differentiators are the supported attachment modes and data handling characteristics: ReadWriteOnce, ReadOnlyMany, ReadWriteMany, which have influence on the requirements for shared or nonshared data across RHOCP nodes.
For many applications, nonshared storage options are perfectly suitable and sufficient. However, for some use cases you require shared storage. One of those use cases is for databases running in RHOCP with entities in different nodes, accessing the same data.
The RHOCP internal container image registry requires ReadWriteMany type of storage and therefore shared storage is required as well.
Overview Storage Options
There are multiple options to add persistence to containerized workload. The needs of customers and applications differ. In addition to IBM Fusion Data Foundation, other options for providing persistence to an Red Hat OpenShift cluster on IBM Z and IBM® LinuxONE are listed in the table below.
With IBM Fusion, a comprehensive suite for storage infrastructure has been introduced.
| Solution | Usage scenario | Storage classes | Access options |
|---|---|---|---|
| Local Storage Operator | Operator used to create PVs from Local Volumes with SCSI-over-FCP and DASD volumes | ||
| iSCSI | manually provisioned | ReadWriteOnce, ReadOnlyMany | |
| Fibre Channel | manually provisioned | ReadWriteOnce, ReadOnlyMany | |
| IBM Block Storage CSI driver | ISV provided driver for storage attachments using iSCSI and FCP | ||
| NFS | Generic and commonly used network attached persistent shared storage | file | ReadWriteMany |
| IBM Storage Scale | Extremely scalable IBM product for file and object storage access. Deployed externally to the Red Hat OpenShift cluster | file, object | ReadWriteOnce, ReadWriteMany |
| IBM Cloud Native Storage Access (CNSA) | A cross-cluster mount capability to attach an RHOCP cluster to an IBM Storage Scale cluster | file, object | ReadWriteOnce, ReadWriteMany |
| IBM Storage Ceph | Scalable and resilient open source storage for storage access | object, file, and block | ReadWriteOnce, ReadWriteMany |
| IBM Fusion Data Foundation (also known as Red Hat OpenShift Data Foundation) | Versatile multi-purpose storage access based on Ceph. Tightly integrated into the Red Hat OpenShift ecosystem | object, file, and block | ReadWriteOnce, ReadWriteMany |
| IBM Fusion | IBM storage offering, which wraps IBM Storage Scale and IBM Fusion Data Foundation in a unified install and configuration experience for container workload | object, file, and block | ReadWriteOnce, ReadWriteMany |
NFS, IBM Storage Scale, and IBM Fusion Data Foundation are the most relevant solutions, especially if storage needs to be shared across applications (ReadWriteMany).
- NFS is well-known and popular. NFS can be integrated with the Red Hat OpenShift platform. NFS has several limitations, such as supporting file storage only or being constrained by scalability and high availability.
- IBM Storage Scale adds valuable capabilities in terms of parallel file systems and data sharing between architectures. A strength of IBM Storage Scale is its amazing scalability in terms of both performance and amount of data that is stored in globally distributed clusters. IBM Storage Scale is a preferred option for AI applications and data lakes across the globe. IBM Storage Scale also provides many API protocols to interact with. Data tiering is another signature feature of IBM Storage Scale. IBM Storage Scale is not limited to containerized workloads and container-native storage, but also finds its use in classic legacy workload. IBM Storage scale also provides sophisticated patterns for high availability and disaster recovery by using IBM technologies like IBM Geographically Dispersed Parallel Sysplex (GDPS). IBM Storage Scale focuses on general-purpose file storage, but recently also added S3 Object Storage access to Cloud providers. Storage Scale is deployed in a cluster of its own, external to the Red Hat OpenShift cluster, which runs the containerized applications.
- IBM Fusion Data Foundation (also known as Red Hat OpenShift Data Foundation) supports all three common storage classes, file, block, and object storage. One of the biggest advantages of Red Hat OpenShift Data Foundation is that it is closely coupled with the Red Hat OpenShift ecosystem and its user experience. This makes is an excellent choice for general-purpose storage for containerized workload. Under the hood, it is based on well-known and well-accepted open source components such as NooBaa, Rook, and Ceph. With NooBaa, a storage infrastructure can federate to build true hybrid cloud topologies, which span multiple cloud vendors and on-premises deployments. This allows for flexible data tiering. Backup, disaster recovery and high availability are based on a Red Hat software stack, which includes Red Hat Advanced Cluster Manager (RHACM) and Open API for Data Protection (OADP).
- IBM Fusion is IBM's strategic offering for container-native storage. It integrates IBM Fusion Data Foundation and IBM Storage Scale into a unified install and configuration experience. Additional data platform, protection, and cluster services include further value in addition to the core storage platforms.

[NOTE]
- For details on IBM Fusion Data Foundation and IBM Fusion, see IBM Storage Fusion and IBM Storage Fusion Data Foundation Reference Architecture.
- IBM Fusion Data Foundation can be licensed as part of IBM Fusion. Nevertheless, you can purchase subscriptions for Red Hat OpenShift Data Foundation Essentials and Red Hat OpenShift Data Foundation Advanced by Red Hat in parallel.
More details can be found in the following sections and in Understanding persistent storage
Local Storage Operator
The Local Storage Operator is not installed in Red Hat OpenShift Container Platform by default. You need to install and configure this operator to enable local volumes in your cluster.
During installation of RHOCP, you cannot use the Local Storage Operator.
Details can be found in Persistent storage using local volumes.
Depending on the Hypervisor used, the architecture of leveraging local storage using the local storage operator can slightly vary. The following two images show the detailed components of the stack for KVM and z/VM.
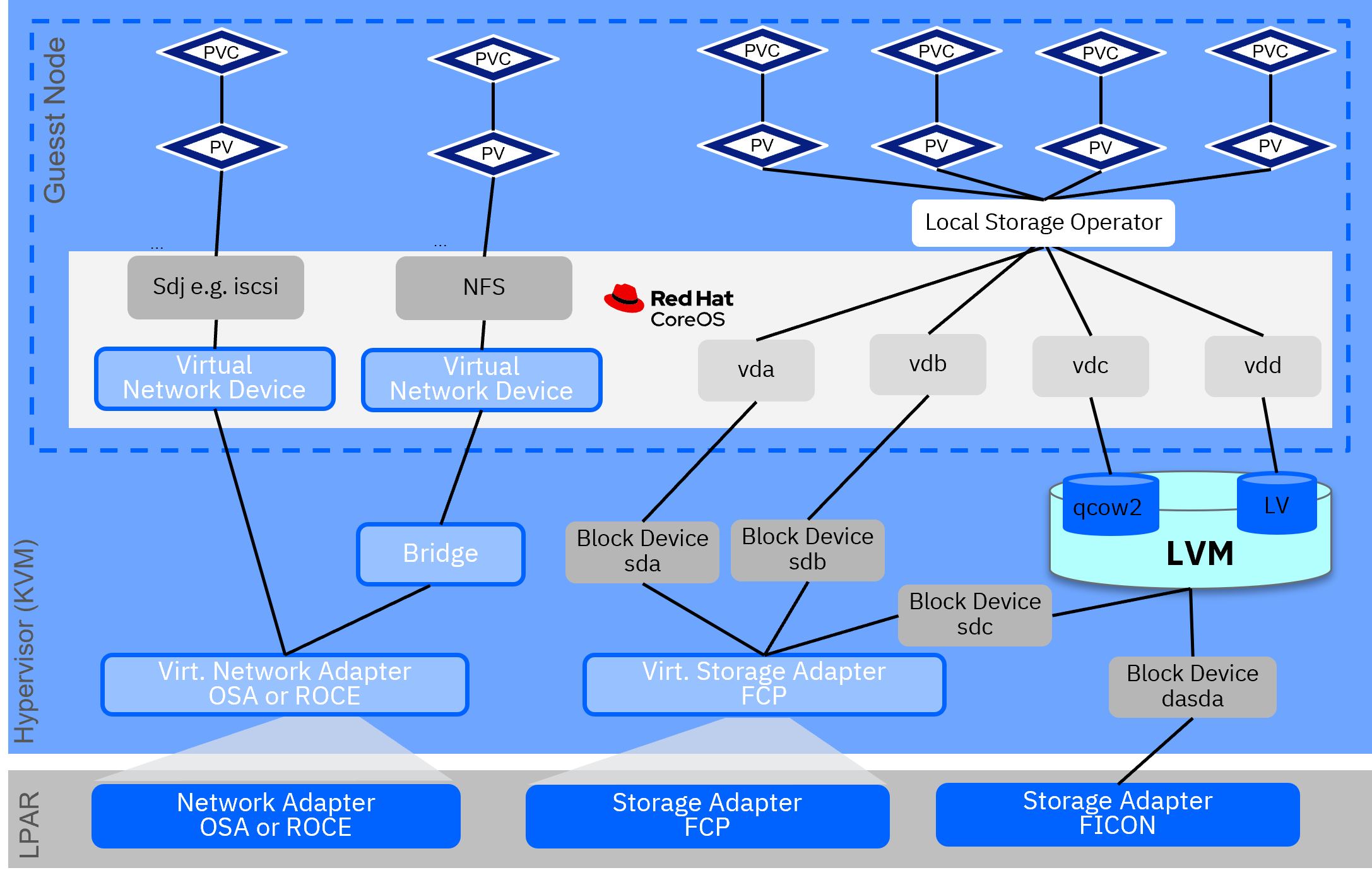
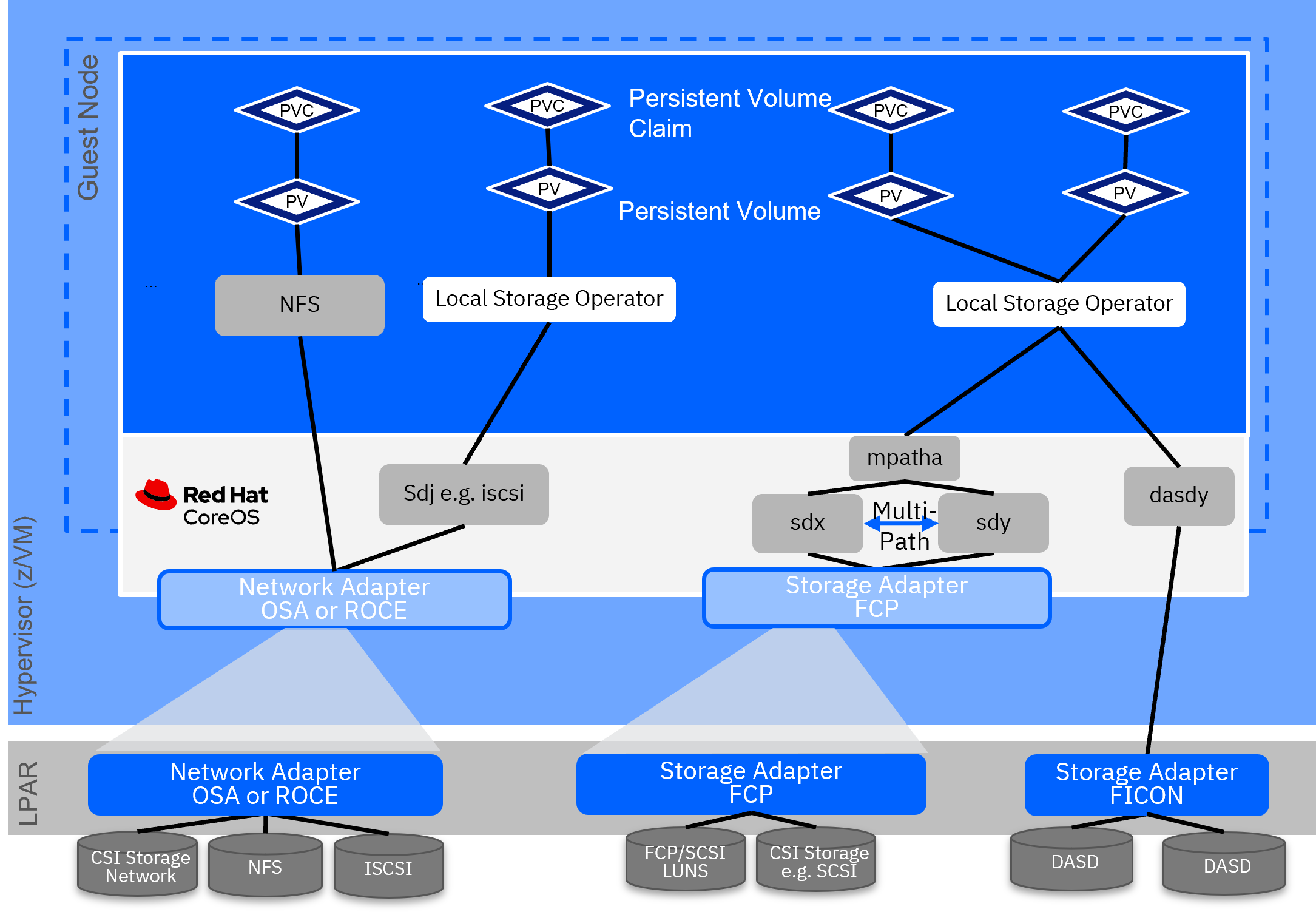
Local Storage Volume
RHOCP can be provisioned with persistent storage by using local volumes by using the Local Storage Operator.
This is the easiest way to provide disks to the control plane nodes as there is no additional configuration of RHOCP. All the instance volumes are stored directly on the disk local to the compute service.
Local persistent volumes (PV) allow accessing local storage devices, by using the standard PVC (Persistent Volume Claim) interface.
Local volumes can be used without manually scheduling pods to nodes because the system is aware of the PV volume.
Local volumes are still subject to the availability of the underlying node and are not suitable for all applications.
Local volumes can be used only as a statically created Persistent Volume.
For many applications, local storage options are perfectly suitable and sufficient. Nevertheless, for some use cases you require shared storage. One of those use cases is setting up the RHOCP image registry. A typical choice for providing storage for RHOCP image registry is to use NFS.
Prerequisites
- The Local Storage Operator is installed.
- Local disks are attached to the Red Hat OpenShift Container Platform nodes.
HostPath
A hostPath Volume in a Red Hat OpenShift Container Platform cluster mounts a file or directory from the host node’s file system into your pod. Most pods do not need a hostPath Volume, but it does offer a quick option for testing if required.
The cluster administrator must configure pods to run as privileged. This grants access to pods running on the same node. Red Hat OpenShift Container Platform supports hostPath mounting for development and testing on a single-node cluster.
A host path volume is provisioned statically.
NFS
Red Hat OpenShift Container Platform clusters can be provisioned with persistent shared storage by using shared storage in NFS servers. Persistent Volumes (PVs) and Persistent Volume Claims (PVCs) provide a convenient method for sharing a volume across a project because the NFS attached PV is of type RedWriteMany.
The NFS-specific information that is contained in a PV definition can also be defined directly in a Pod definition. Doing so does not create the volume as a distinct cluster resource, making the volume more susceptible to conflicts.
- Provisioning
- Storage must exist in the underlying infrastructure before it can be mounted as a volume in Red Hat OpenShift Container Platform.
- Requirements to provision NFS volumes
-
- NFS servers with storage paths defined
- Export the paths
Container Storage Interface (CSI)
The Container Storage Interface (CSI) allows Red Hat OpenShift Container Platform to consume storage from storage back ends that implement the CSI interface as persistent storage.
Storage Vendors prove those CSI drivers for their own storage solutions.
IBM provides CSI drivers to attach enterprise storage:
- IBM Block Storage CSI driver, supporting IBM Storage Virtualize and IBM Spectrum Accelerate product portfolios
- IBM Storage Scale CSI driver, supporting IBM Storage Scale and IBM Elastic Storage® Server
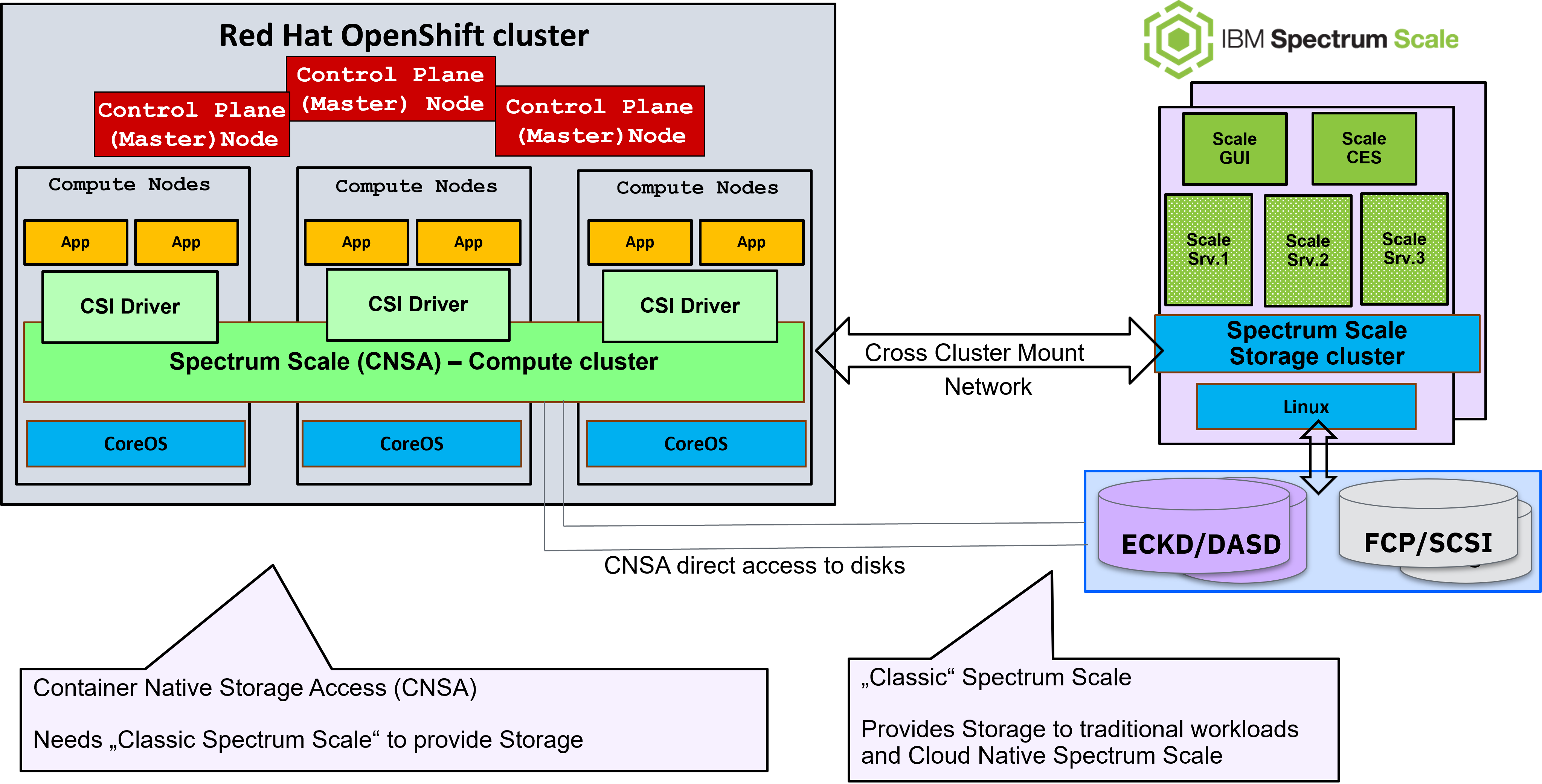
IBM Storage Scale Container Native Storage Access (CNSA)
What if you could use one storage solution for all your data, like databases and containers and have shared file systems. Share data in different environments and IT architectures, use automatic storage tiering with the fastest storage device for the most frequently accessed data and your backup and secure archive would be automated in the tiering process.
A comprehensive storage software family from IBM, the IBM Storage™ Suite is available and can change the economics of storage on-premises and in hybrid Multicloud environments.
One of the fundamental components is IBM Storage Scale®, which is platform-independent, software-defined storage. IBM Storage Scale for Linux on IBM Z implements a clustered file system and has many features beyond common shared data access. It includes data replication, policy-based storage management, and multi-site operations. It provides superior capabilities of resiliency, scalability, and high performance for data and file management - built upon IBM General Parallel File System (GPFS™). IBM Storage Scale implements high availability and reliability with no single point of failure.
It can run on IBM Z, IBM® LinuxONE, IBM Power, and on x86 machines. The attached storage can be FICON-attached DASD or FCP/SCSI-attached storage from IBM and other vendors. IBM Storage Scale offers native, high-performance, and scalable access to file and object data via almost all standard storage protocols, including OpenStack®, Swift, Amazon S3, CIFS, NFS, HDFS, and Red Hat® OpenShift Container Platform via the Containers Storage Interface (CSI).
You can implement the storage cluster next to your RHOCP cluster and take advantage of the reduced latency by using internal networks and the new 'direct access' feature gives direct access to disks and reduces the network communication for just IBM Storage Scale control information.
To install an IBM Storage Scale cluster see Getting started with IBM Storage Scale for IBM Z
Figure 4 illustrates the architecture of an RHOCP cluster that uses the Cloud Native Storage Access (CNSA) components to connect to a Storage Scale storage cluster. To plan, setup, and install the environment, see IBM Storage Scale for Red Hat OpenShift Container Platform on IBM Z and IBM® LinuxONE.
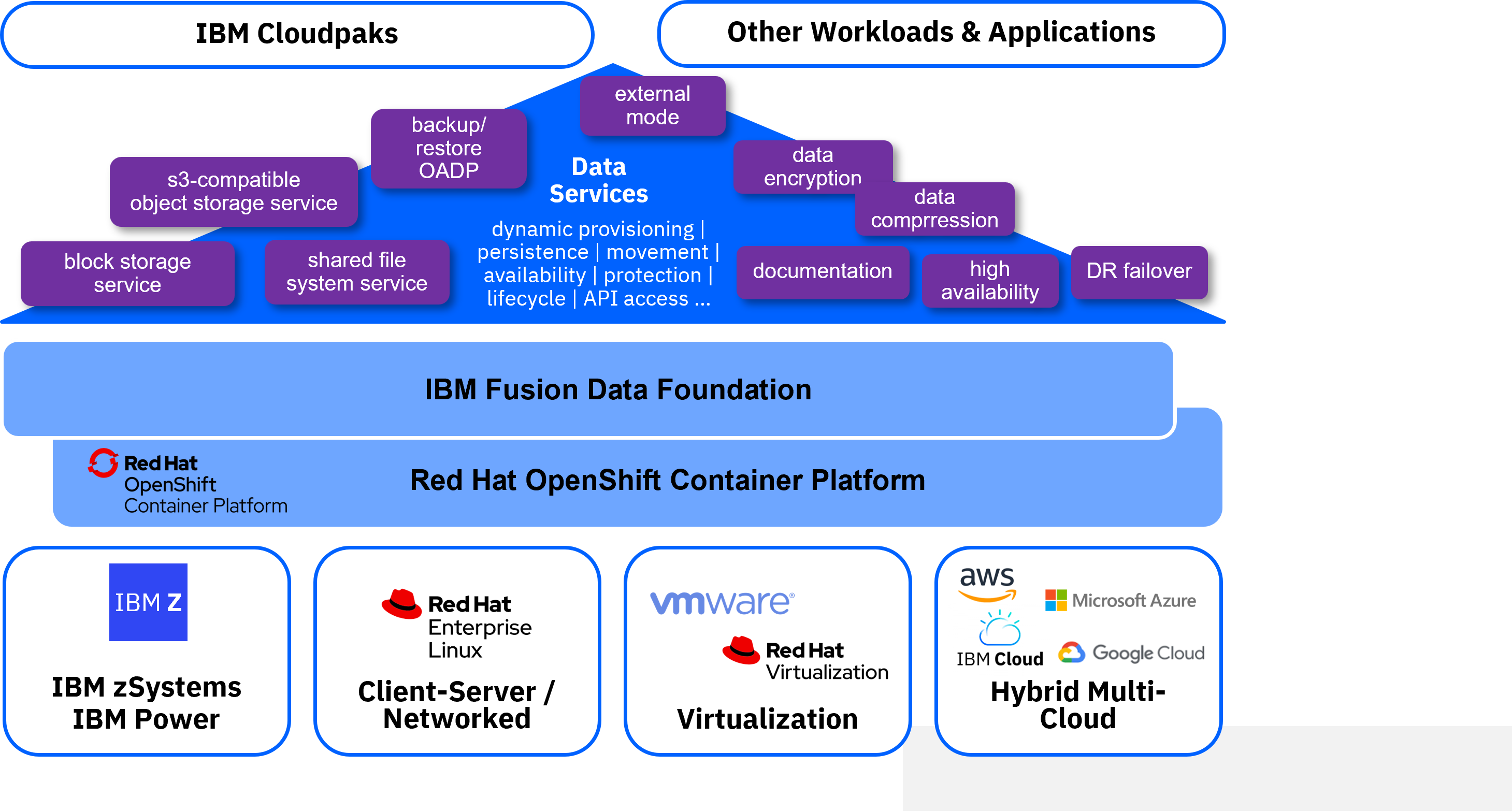
IBM Fusion and IBM Fusion Data Foundation
Container workloads are stateless by definition. This fundamental assumption makes their lifecycle easy and efficient to orchestrate. A container is easily portable and can be scaled up and down at ease. A container can be restarted and be moved between servers at any time. But this implies that any permanent persistence needs to be provided separately.
Adding persistence to containers to make them stateful is exactly the focus of IBM Storage Data Foundation, also known as Red Hat OpenShift Data Foundation.
IBM Fusion Data Foundation provides software-defined storage for containerized applications. It manages storage resources for the application containers to work with and helps ensure that persistence is strictly decoupled from the orchestration of containers. Engineered as the data and storage services platform for RHOCP, IBM Fusion Data Foundation helps teams develop and deploy applications quickly and efficiently across hybrid cloud and multicloud container deployments.
Based on OpenShift Container Platform and IBM Fusion Data Foundation, an enterprise can achieve a unified access to data services across different applications and infrastructure environments.
This includes:
- Federate underlying storage infrastructure to single abstracted repository
- Separate storage provisioning from storage consumption
- Deal with different kinds of data and storage classes
Additional resources: