GDPC インフラストラクチャーと GDPC 固有の前提条件
地理的に分散した Db2® pureScale® クラスター (GDPC) をセットアップする前に、いくつかの条件を満たす必要があります。
ベスト・プラクティスの構成のガイドライン
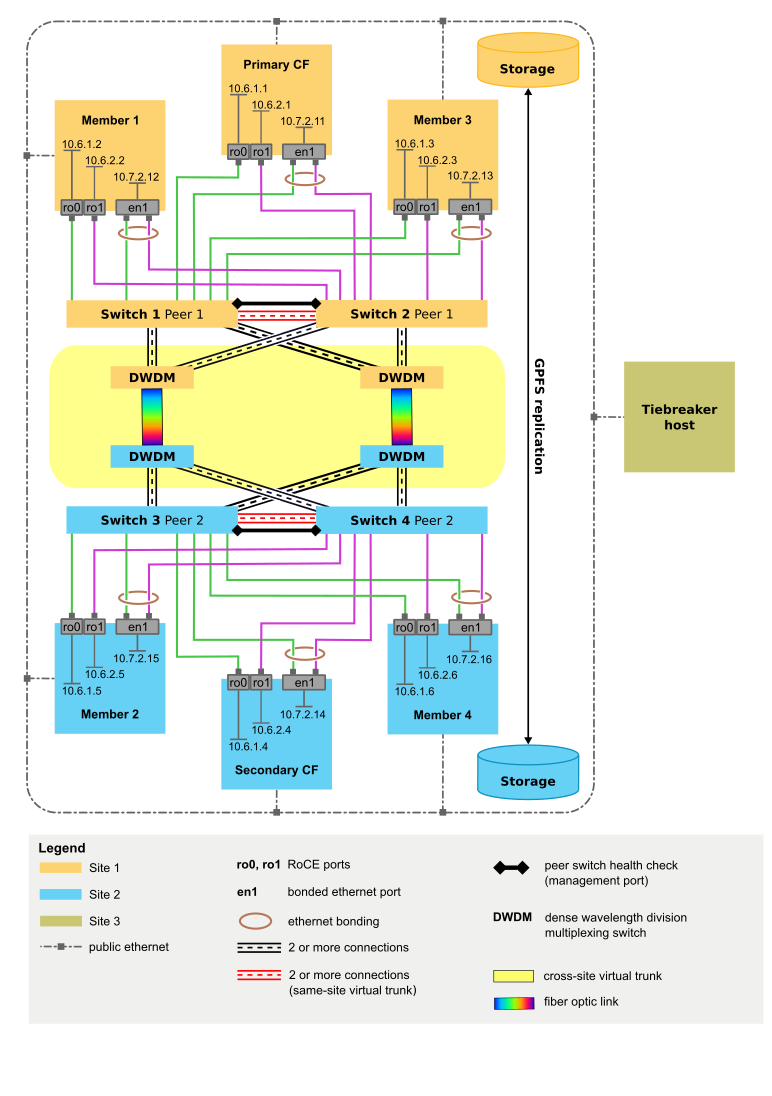
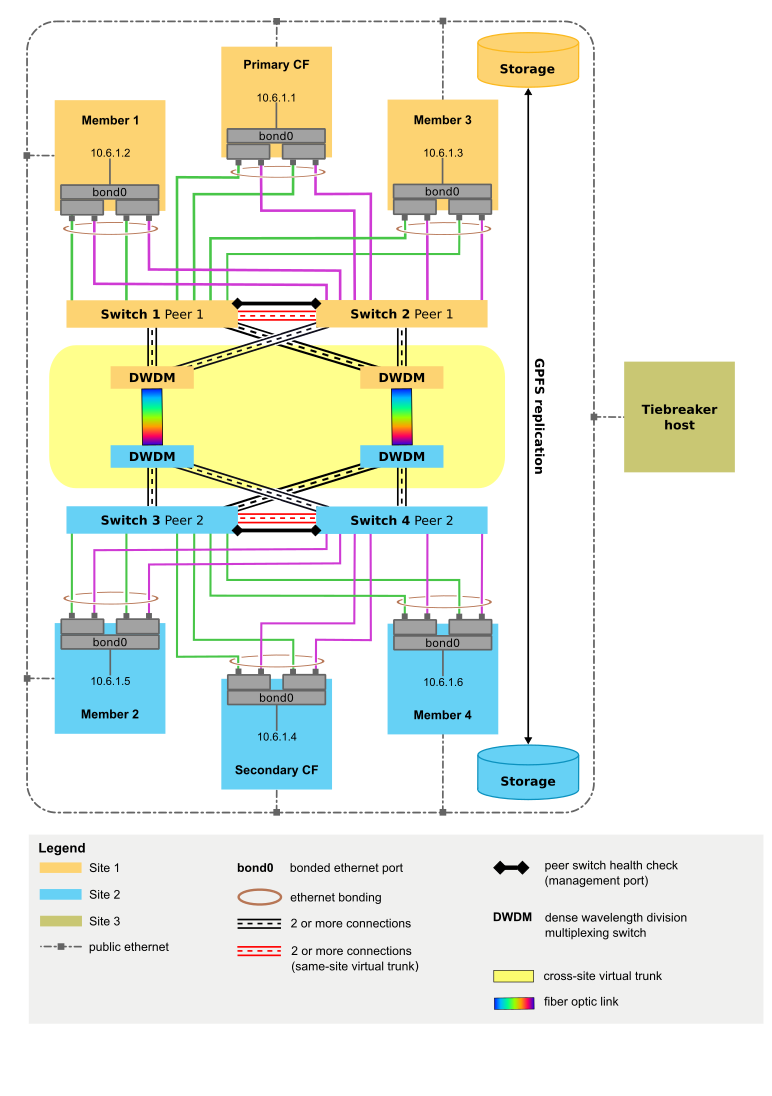
- 地理的に離れた 3 つのサイトが、信頼できる TCP/IP リンクを介して相互に通信します。 さらに、RoCE または Infiniband による RDMA ネットワーク・リンクまたは 2 つ目のプライベート TCP/IP ネットワーク (メンバー/CF 通信用) をメンバーおよび CF のホストで使用できます。 メンバーと CF が存在する 2 つのサイトは、データベース・トランザクションを処理する実動サイトです。 3 つ目のサイトはクォーラム・ノード (タイブレーカー・ホスト) として機能します。
- マジョリティー・ノード・クォーラムは、RSCT ピア・ドメインと IBM® Spectrum Scale クラスターの両方でクラスター・クォーラム・メカニズムとして使用されます。
- 2 つの実動サイトの構成:
- サイト間は、距離が 50 キロメートル未満で、必要に応じて長距離中継器を使用して WAN またはダーク・ファイバーで接続し、単一の IP サブネットを構成する必要があります。 距離が短いほどパフォーマンスが向上します。 ワークロードが極端に軽い場合は、これより長い距離 (最大で 70 あるいは 80 キロメートル) でも可能な場合があります。 詳細については、以下の図を参照してください。
図1: GDPC の最適な候補 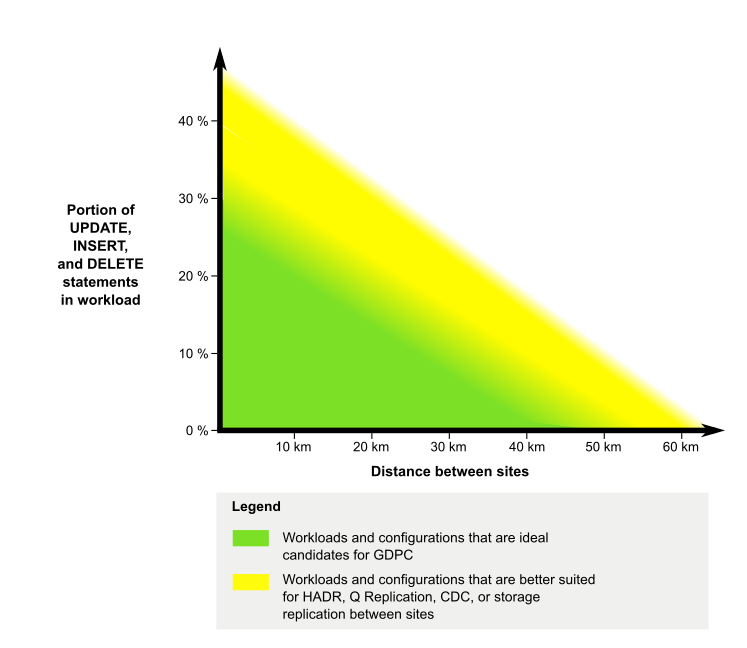
- 実動サイトごとに、CF が 1 つと、ホスト/LPAR およびメンバーが同数ずつ存在します。
- 実動サイトごとに、そのサイト専用のローカル SAN コントローラーが 1 つ以上存在します。 SAN は、 Db2 pureScale インスタンスに使用される LUN に両方の実動サイトから直接アクセスできるようにゾーニングされています。 1 つ目のサイトの各 LUN が、2 つ目のサイトに同サイズの対応する LUN を持つように、サイト間で LUN 間の 1 対 1 のマッピングが必要です。
- IBM Spectrum Scale の同期複製は、ストレージ複製メカニズムとして使用されます。
- メンバー/CF の通信に TCP/IP を使用する場合は、以下のようにします。
- 帯域幅と冗長性を向上させるために、メンバーと CF の通信に複数のアダプター・ポートを使用します。
- 各メンバー/CF ですべてのアダプター・ポートを結合して、1 つのイーサネット・インターフェースを形成します。 この結合インターフェースは、 IBM Spectrum Scale ハートビート・ネットワークだけでなく、メンバーと CF の通信にも使用されます。
- 完全に冗長化した形で構成した合計 4 台のスイッチ (サイトごとに二重化スイッチ) を使用します。
- メンバー/CF 通信に RoCE を使用する場合は、以下のようにします。
- 帯域幅と冗長性を向上させるために、メンバーと CF の通信に複数のアダプター・ポートを使用します。
- 完全に冗長化した形で構成した合計 4 台のスイッチ (サイトごとに二重化スイッチ) を使用します。
- IBM Spectrum Scale ハートビート・ネットワークとして、各メンバーおよび CF に追加の結合プライベート・イーサネット・ネットワーク・インターフェースをセットアップします。
- メンバー/CF の通信に Infiniband を使用する場合は、以下のようにします。
- アダプター・ポートはメンバー/CF あたり 1 つのみ、スイッチはサイトあたり 1 台のみサポートされます。 このインターフェースは、 IBM Spectrum Scale ハートビート・ネットワークだけでなく、メンバーと CF の通信にも使用されます。
- サイト間は、距離が 50 キロメートル未満で、必要に応じて長距離中継器を使用して WAN またはダーク・ファイバーで接続し、単一の IP サブネットを構成する必要があります。 距離が短いほどパフォーマンスが向上します。 ワークロードが極端に軽い場合は、これより長い距離 (最大で 70 あるいは 80 キロメートル) でも可能な場合があります。 詳細については、以下の図を参照してください。
- 3 番目のサイトでは、以下のようにします。
- クラスター・タイブレーカー専用のホストとして機能する、クラスター内の他のホストとオペレーティング・システム・レベルが同じ単一のホスト (メンバーでも CF でもない)
- ホスト名に関連付けられる IP アドレスは、クラスター内の他のホストと同じ IP ネットワーク上になければなりません。 つまり、同じクラスター内のすべてのホスト(メンバー、CF、およびタイブレーカーホスト)は、それぞれの /etc/hostsファイルに指定されるホスト名とIPアドレスを使用して、ホスト間でTCP /IPpingを実行しなければなりません。
- 2 つの実動サイト内の SAN にアクセスできる必要はありません。
- クラスター内の各共有ファイル・システムに対して /dev 内のデバイスを 1 つ割り当てます。 これらのデバイスにユーザー・データは保管されません。これらのデバイスは、リカバリーの目的でファイル・システム構成データを保管するためにのみ使用され、ファイル・システム・ディスク・クォーラムのタイブレーカー・ディスクとして機能します (注: このクォーラムはファイル・システム・レベルであり、 IBM Spectrum Scale クラスター・クォーラムではありません)。これらのデバイスのサイズ要件は最小です。 一般に、50 MB から 100 MB のデバイスで十分です。
- ローカルの物理ディスクまたは論理ボリューム (LV) をこのデバイスとして使用できます。 LV を構成する場合は、以下のガイドラインを使用してください。
- 同じボリューム・グループ (VG) の中にそれぞれの論理ボリュームを作成します。
- ボリューム・グループに物理ディスクを 1 つ以上割り当てます。 実際の数は、必要な論理ボリューム数によって決まり、必要な論理ボリューム数は共有ファイル・システム数によって決まります。 可能であれば、冗長化するために、2 つの物理ボリュームを使用してください。
- ボリューム・グループ・クォーラム検査がサポートされており ( AIX®など)、複数の物理ボリュームがボリューム・グループに割り当てられているプラットフォームでは、クォーラム検査が無効になっていることを確認してください。
- サポートされる限り、すべての構成でスイッチ 4 台の構成を使用します。 クラスターのスイッチが 2 台か 4 台かにかかわらず、すべてのスイッチが同じモデルで、同じファームウェア・レベルを実行する必要があります。
サポート・マトリックス
| プラットフォーム | 最小 OS レベル | メンバーと CF の通信用のネットワーク・タイプ | サポートされるアダプター・ポート (単一または複数) | 主要な実動サイトのスイッチ数 |
|---|---|---|---|---|
| AIX | 6.1 TL9 SP5 7.1 TL3 SP5 (IV72952) |
Infiniband (IB) | 単一 | 1 |
| AIX | 6.1 TL9 SP5 7.1 TL3 SP5 (IV72952) |
10GE RoCE | 複数 | 2 |
| AIX | 6.1 TL9 SP5 7.1 TL3 SP5 (IV72952) |
TCP/IP | 複数 | 2 |
| Red Hat Enterprise Linux (RHEL) | 7.1 | Infiniband (IB) | 単一 | 1 |
| Red Hat Enterprise Linux (RHEL) | 7.1 | 10GE RoCE | 複数 | 2 |
| Red Hat Enterprise Linux (RHEL) | 7.1 | TCP/IP | 複数 | 2 |
| SuSE Linux Enterprise Server (SLES) | 11 SP2 | Infiniband (IB) | 単一 | 1 |
| SuSE Linux Enterprise Server (SLES) | 11 SP2 | 10GE RoCE | 複数 | 2 |
| SuSE Linux Enterprise Server (SLES) | 11 SP2 | TCP/IP | 複数 | 2 |
オペレーティング・システム前提条件の詳細については、 Db2 pureScale Feature のインストール前提条件を参照してください。
このページの最新の更新情報については、 http://www.ibm.com/support/docview.wss?uid=swg21977337 を参照してください。
スイッチ 4 台の GDPC 構成のスイッチ要件
通常、単一サイトの高可用性 Db2 pureScale クラスターは、帯域幅を拡大して冗長性を提供するために、複数の物理スイッチ間リンク (ISL) で接続されたデュアル・スイッチを使用してデプロイされます。 複数の ISL が 2 台のスイッチ間にネットワーク・ループを形成しないように、Link Aggregation Control Protocol (LACP) をセットアップします。
2 つの主要な実動サイトのそれぞれで二重化スイッチを使用する GDPC にも、これと同様の概念が当てはまります。 等しく冗長化して帯域幅を増加させるために、ペアごとに複数の物理リンクを使用してスイッチを相互に接続する必要があります。 目的は、同じサイト内にある 2 台のスイッチを、1 つの論理的なスイッチとして機能するように構成することです。 これに加えて、すべてのクロスサイト・リンクを 1 つの論理リンクとしてセットアップすると、2 つのスイッチを持つ単一サイト Db2 pureScale クラスターと同等のループフリー・トポロジーが作成されます。
各サイトに論理的なスイッチを形成し、2 つの論理的なスイッチが互いを 1 つのエンティティーとして扱うように設定するには、LACP だけでは不十分です。 追加のプロトコルや構成がスイッチに必要になります。 必須プロトコルのいくつかは、ほとんどのスイッチ・モデルで提供されている IEEE 標準です。 エンタープライズ・レベルの特定のスイッチ・モデルでしか使用できないプロプラエタリー機能もあります。そのような機能の名前はベンダーによって異なります。 このため、すべてのスイッチ・モデルが 4 台スイッチ GDPC デプロイメントに適しているとは限りません。 以下に、必須のスイッチ機能をすべてリストし、各機能の概要を示しています。これをガイドラインとして使用し、対象スイッチのユーザー・マニュアルを参照して、適しているかどうか判断してください。
- リンク集約制御プロトコル (LACP)-IEEE 802.3ad
単一サイトの Db2 pureScale クラスターと同様に、LACP は、同じサイト内の 2 つのスイッチ間の接続と、2 つのサイト間のスイッチ間の接続を構成する必要があります。
- フロー制御 - IEEE 802.3x
単一サイトの Db2 pureScale クラスターと同様に、フロー制御 (Global Pause とも呼ばれる) は、ネットワーク輻輳が発生したときにパケットがドロップされないようにするために使用されます。 BNT スイッチの場合は、 vLAG ISL ポートを除く、すべての Db2 pureScale 関連ポートで有効にします。
- サイト内仮想トランク・サポートサイト内仮想トランク・サポートは、次の機能を提供する必要があります。
- サイト内の ISL 障害を 1 つまたはすべて検出できるように、2 台のスイッチをペアにする。
- すべての ISL に障害が発生した場合は、一方のスイッチが、他方のスイッチ上のすべてのポートまたは少なくともサイト間 ISL ポートを強制的にダウンさせる。 一般に、これを簡単に実行するために、ピア・スイッチ間に追加したヘルス・チェックのための接続が使用されます。
これは IEEE 標準には含まれておらず、すべてのスイッチ・モデルで使用できるわけではありません。 この機能を提供しているベンダーのいくつかを以下に示します。- ブレード・ネットワーク・テクノロジー (BNT): 仮想トランク・サポートは、仮想リンク集約グループ (vLAG) と呼ばれます。 サイト内仮想トランクは vLAG ISL と呼ばれています。
- Cisco: 仮想トランク・サポートは Virtual Port Channel (vPC) と呼ばれています。 サイト内仮想トランクは vPC ピア・リンクと呼ばれています。
- Juniper: 仮想トランク・サポートは Multichassis Link Aggregation Group (MC-LAG) と呼ばれています。 サイト内仮想トランクはシャーシ間リンク (ICL) と呼ばれています。
- ピア・スイッチのヘルス・チェック
サイト内仮想トランクでは、同じサイト内の 2 台のスイッチがピアとして機能します。 ベンダーによっては、1 次および 2 次の管理ロールを割り当てることもできます。 実装形態にかかわらず、2 台のスイッチは重要なヘルス情報やキープアライブ情報を頻繁に交換します。 ほとんどのベンダーは、この重要な通信のために別個のリンクを使用することを推奨しています。 このリンクを、仮想トランクに含めてはいけません。 使用可能な場合は、スイッチ管理ポートを使用するのがベスト・プラクティスです。 スイッチ管理ポートが使用不可の場合、このタイプのトラフィックでは専用ポートと VLAN が必要となります。
これは IEEE 標準には含まれておらず、すべてのスイッチ・モデルで使用できるわけではありません。 この機能を提供しているベンダーのいくつかを以下に示します。- ブレード・ネットワーク・テクノロジー (BNT): この機能は、 vLAG ISL ヘルス・チェックをセットアップすることで提供されます。
- Cisco: この機能は、vPC キープアライブ・リンクをセットアップすると使用可能になります。
- Juniper: この機能は、シャーシ間制御プロトコル (ICCP) を構成すると使用可能になります。
- サイト間仮想トランク・サポート
スイッチは、3 台以上のスイッチからの複数の物理接続を集約する機能を備えている必要があります。 また、この集約によって使用可能な帯域幅が縮小してはいけません。 BNT スイッチでは、すべてのサイト間リンクを集約して単一の vLAG にすることで、この機能を利用できます。
- スイッチでの IP インターフェースの作成IP インターフェースは、通常、スイッチが存在するネットワークの IP サブネットを表します。 Db2 GDPC では、次に示す 2 つの異なる目的のために IP インターフェースが使用されます。
- 初期セットアップ時に、すべてのホストとすべてのスイッチの間の接続の正常性テストとして使用できます。
- アダプターに障害が発生した場合に、ホストが起動しているどうか調べることができる ping 可能な代替 IP アドレスとして機能します。
サイト間接続
サイト間の接続は、地理的に分散した Db2 pureScale クラスター (GDPC) における主要なインフラストラクチャーです。 Db2 pureScale 環境は、メンバーとクラスター・ファシリティー (CF) の間で多くのメッセージを交換します。 GDPC 構成では、そのような多くのメッセージがサイト間のリンクを行き来します。
InfiniBand 高速相互接続の場合、Obsidian Strategies の Longbow InfiniBand エクステンダー・テクノロジーにより、2 つのサイトの高速相互接続ネットワークの 2 つの部分を透過的に接続し、比較的距離がある場合でも GDPC 全体で RDMA 操作を行うことができます。 サイト間相互接続の両側のペアでエクステンダーを使用することで、サイトからローカルへの高速相互接続スイッチへの高速相互接続の接続、およびそれを介したメンバーと CF への接続が可能になります。 エクステンダーは、高速相互接続のトラフィックを、サイト間相互接続 (「ダーク・ファイバー」または 10 GB WAN 接続) で送受信されるパケットに変換し、またその逆も行います。
エクステンダー自体がメッセージ・プロトコルに与える待ち時間はごくわずかです。 単一サイトの Db2 pureScale クラスターと比較した場合、サイト間メッセージの追加の待ち時間の大部分は、距離の単純な事実から生じます。グラス・ファイバーでの 1 キロメートルの伝送により、さらに 5 マイクロ秒の遅延が追加されます。 したがって、例えば、サイト間の距離が 10km である場合は、ほとんどのタイプのメッセージで追加される待ち時間は、(10km x 5 マイクロ秒/km) x 往復の 2 = 100 マイクロ秒となります。 実際的には、書き込みアクティビティーより読み取りアクティビティーの割合の方が高いワークロードは、CF とのメッセージ交換が実行される回数が少ない傾向にあるため、サイト間の追加の待ち時間による影響は少ないといえます。
現在の Longbow IB エクステンダーは、(ダーク・ファイバー /WAN リンクの容量に応じて) エンドポイント間の 4X 幅単一データ速度 (SDR) または 10 GB データ速度で作動します。 冗長性または追加のサイト間キャパシティーが必要な場合、Longbow ユニットをサイト間で複数のペアにしてグループ化できます (図 1 参照)。 また、さまざまな Longbow モデルがさまざまなフィーチャーを提供しており、それぞれ特定の状況で役立ちます。例えば、E-100 および X-100 モデルでの暗号化などです。これは、サイト間相互接続が共有されているかパブリックで、セキュリティー・ポリシー上暗号化が必要な場合に重要です。 現在のすべての Longbow モデルは GDPC でサポートされています。 モデルの選択、WAN またはファイバーの使用、あるいはトランシーバーの波長の選択などの特定の構成やその他の特性については、ここでは指定しません。それらは、使用する物理インフラストラクチャーや実施されている IT ポリシーに基づいて選択してください。 Longbow IB エクステンダーについて詳しくは、Obsidian Research にお問い合わせください。 (http://www.obsidianresearch.com/)
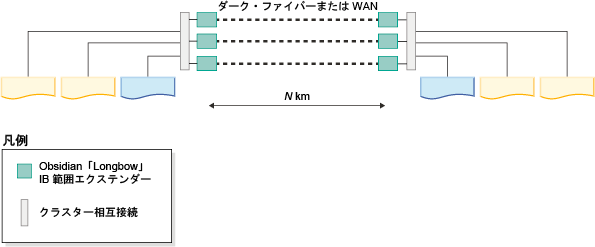
10GE RoCE および TCP/IP ネットワークの場合、特殊な中継器は必要ありません。 データの長距離伝送には、通常、ネットワーク業者からリースされた既存の大都市圏ネットワーク・インフラストラクチャーを利用します。 図 1 および 2 は、データの長距離伝送のために高密度波長分割多重方式 (DWDM) のトランスミッターとレシーバーを使用する例を示しています。
3 サイト構成
GDPC は 2 つのメイン・サイト「A」と「B」で構成されています。それぞれに、同じ数のメンバーと CF があります。 例えば、サイト「A」に 2 つのメンバーと 1 つの CF がある場合、サイト「B」にも 2 つのメンバーと 1 つの CF が必要です。 各メイン・サイトに、物理マシンも同じ数を置くことをお勧めします。 例えば、片方のサイトに 4 つの LPAR を持つマシンが 1 つあり、他方のサイトには 2 つずつ LPAR を持つマシンが 2 つある状態はお勧めしません。 考慮すべきクラスタリングの主な概念は、「クォーラム」という概念です。 「クォーラム」とは、クラスターが動作可能であり続けるために、クラスター内でオンラインである必要のあるコンピューター・システムの数を指します。 クォーラムには、操作クォーラムと構成クォーラムの 2 種類があります。 操作クォーラムは、クラスター上のソフトウェア・サービスが作動するために必要です。 構成クォーラムは、クラスターへの新しいコンピューター・システムの追加など、クラスターに対する構成変更を適用するために必要です。 構成クォーラムは、厳密にクラスター内のオンライン・コンピューター・システムの過半数を必要とします。したがって、例えば、6 つのコンピューター・システムで構成されるクラスターでは、クラスターの構成を更新するには、そのうちの少なくとも 4 つのコンピューター・システムがオンラインである必要があります。
非 GDPC 環境では、操作クォーラムは通常、タイブレーカー・ディスクを使用して達成されます。 クラスター内にオンラインのコンピューター・システムが半分しかない (または半分のそれぞれが同時にオンラインであるネットワーク区画で、他方の半分へのネットワーク接続がない) 場合、「タイブレーカー」ディスク装置はクラスターのどちらか半分が獲得できます。 これにより、運用クォーラムを達成し、クラスターのその勝利半分でソフトウェア・サービス (つまり、 Db2 pureScale インスタンス) を実行することができます。 ネットワーク分割が発生した場合、採用されなかったほうの半分は、クラスター・ファイル・システムのデータにアクセスできないように、クラスターから隔離されます。 しかし、ディスク・タイブレーカーに対する要件として、単一のタイブレーカー・ディスクはクラスター内の各コンピューター・システムからアクセス可能である必要があります。 GDPC 環境では、このディスクは物理的に 2 つのサイトのいずれかに存在しなければなりません。こうすることで、2 つのサイト間で完全なネットワーク分割が発生した場合に、他方のサイトが操作クォーラムを獲得できないようにします。 奇数のノードを持つクラスターの場合、操作クォーラムにはオンライン・ノードの過半数が必要です。 ただし、クラスター内に偶数のノードがあり、オンライン・ノードが同数で分割される場合は、どちらのサブクラスターが操作クォーラムを取得するかをタイブレーカー・ディスクが決定します。 クラスターの半分がダウンした場合、オンラインであるサブクラスターがタイブレーカーに要求してクォーラムを取得します。
GDPC 環境は厳密な過半数クォーラム・セマンティクスに依存しており、サイト障害の際にクォーラムを維持するために 1 つの追加タイブレーカー・ホスト T が必要です。 このタイブレーカー・ホスト T は、2 つのメイン・サイトにあるマシンと同じアーキテクチャー・タイプである必要があります。 例えば、同じオペレーティング・システムを実行しなければなりませんが、同じハードウェア・モデルは必要ありません。 ベスト・プラクティスは、クラスター内のすべてのコンピューター・システムで、実行する OS レベルも同じにすることです。 この追加のホストは、Db2 メンバーも CF も実行しません。
タイブレーカーホストが2つのメインサイトのいずれかに物理的に配置されている2サイト構成では、ホストTを含むサイトに障害が発生した場合、運用クォーラムまたは構成クォーラムを達成できません。 したがって、データ処理サイト (サイト A またはサイト B) のいずれかに影響を与える障害が発生した場合に連続可用性を実現するために、タイブレーカー・ホスト T が別の 3 番目のサイト (サイト C) に物理的に配置される 3 サイト構成を使用することがベスト・プラクティスです。これは、サイト C と残存データ処理サイトの間でマジョリティーを確立できるためです。 連続可用性のため 3 サイト構成では、各サイトの各コンピューター・システムがクラスター内の他の各コンピューター・システムに ping できる限り、3 つのサイトをすべて異なる IP サブネットにすることができます。 サイト「C」も高速相互接続の接続を必要としません。 サイト「A」と「B」のみが、単一の高速相互接続サブネットが両方のサイトに広がる高速相互接続の接続を必要とします。
問題判別に役立てるために、すべてのサイトのすべてのコンピューター・システムのシステム・クロックを同じタイム・ゾーンに構成することをお勧めします。
ファイアウォールの設定
クラスター内の各メンバーおよび CF にネットワーク・レベルのファイアウォールがセットアップされている場合、すべての pureScale ホスト間での通信が可能となるように関連するポートを開いてください。 Db2 メンバーおよび CF プロセスに必要な TCP/IP ポートについては、 スクリーニング・ルーター・ファイアウォール を参照してください。 Db2 クラスター・サービスに必要な TCP/IP ポートについては、 Db2 クラスター・サービス・ポートの使用情報セクション を参照してください。
ゾーニングされた SAN ストレージ
GDPC では、サイト「A」と「B」の両方のサイトに、互いのディスクへ直接アクセスする権限が必要です。 そのため、データ・センターにわたって SAN を拡張するためのオプションが複数用意されています。 オプションには、ATM または IP ネットワークを直接介したファイバー・チャネル (FC) トラフィックの転送、または IP を介して SCSI コマンドを転送するための iSCSI の使用があります。 ダーク・ファイバーは最も高速であると考えられますが、最も高価なオプションであるともいえます。
IBM Spectrum Scale 同期複製
GDPC にない標準的なクラスターは、複製されていない構成で IBM Spectrum Scale ソフトウェアを使用します。 このような場合、特定のファイル・システムに対するすべての IBM Spectrum Scale ディスク・アクティビティーは、単一の IBM Spectrum Scale 障害グループになります。 ディスクが複製されない場合、ディスク障害によってファイル・システム・データの一部がアクセス不能のままになる可能性があります。 ただし、GDPC の場合、 IBM Spectrum Scale レプリケーションがサイト A & B 間で使用されるのは、サイト全体で障害が発生した場合に、存続しているサイトでデータのコピー全体を確実に使用できるようにするためです。
GDPC 構成では、 IBM Spectrum Scale レプリケーションを利用して、ファイル・システム・データのコピー全体を独自の障害グループに保持するように各サイトを構成します。 クラスター内でクォーラムが維持されている限り、サイト障害 (障害グループの 1 つが失われたかアクセス不能) が発生した場合に、他のサイトではファイル・システムへの読み取り/書き込みアクセスを続行できます。
タイブレーカー・ホスト T では、複製された IBM Spectrum Scale ファイル・システムごとに、小さいディスクまたは区画をファイル・システム・クォーラム・ディスクとして使用する必要があります。 各ディスクまたはパーティションのストレージの量は、およそ 50 MB です。これらのディスクまたはパーティションは、ホスト T のみがアクセス可能であればよく、ファイル・システム記述子を保管するためにのみ使用されます。 ファイル・システム記述子のみの保管に使用されるディスクまたはパーティションに対する入出力アクティビティーは、非常に限られています。 この目的のために物理ボリュームのすべてを使用するのは無駄であり、必ずしも実用的ではありません。この場合は、小さなボリュームを構成すれば十分です。 また、デバイス・タイプとして論理ボリューム (LV) を使用することもできます。
単一サイトのパフォーマンスへの影響
別々のサイトにあるクラスター・メンバー間の距離を大きくとると、メッセージ待ち時間が、グラス・ファイバー 1 キロメートルにつき 5 マイクロ秒増加します。 場合によっては、接続にシグナル・リピーターが含まれていたり、接続が他のアプリケーションと共有されていたりすると、待ち時間はより長くなります。
GDPC 構成で発生するパフォーマンス・オーバーヘッドは、距離の他にも、使用中のワークロードによって異なります。 ワークロード内の書き込みアクティビティー (INSERT、UPDATE、DELETE) の割合が高くなるほど、メンバーから CF に送信する必要のあるメッセージ数が増え、実行する必要のあるディスク書き込み数 (とくにトランザクション・ログへの書き込み) が増えます。 このようなディスク書き込み数が増えると、通常は特定の距離でのオーバーヘッドを増やすことになります。 逆に、読み取り (SELECT) アクティビティーの割合が高くなるほど、メッセージ数とディスク書き込み数が減り、オーバーヘッドが減ります。 このため、2 つのサイト間の距離が 50 キロメートル未満で、書き込みよりもコンテンツを読み取るワークロード (SELECT) の割合が高い場合 (例: 読み取りアクティビティーが 80% 以上) は、GDPC が最も適しています。
Db2 pureScale 環境は、ハードウェアまたはソフトウェアの障害が原因でホストに障害が発生した場合のダウン時間が最小限になるように設計されています。 ハードウェア障害が発生した場合、データの破損を避けるためには、システムを入出力から隔離する必要があります。 ホストは、入出力分離されると、 Db2 pureScale インスタンス内のクラスター・ファイル・システムによって使用されるストレージ・デバイスにアクセスできなくなり、入出力の試行はブロックされます。 ダウン時間を最小化するためのテクノロジーとして重要な部分の 1 つは、SCSI-3 Persistent Reserve (PR) です。
SCSI-3 PR が使用可能になっていない場合は、 IBM Spectrum Scale ディスク・リースの有効期限メカニズムを使用して、障害が発生したシステムを隔離します。 通常これは、リースの満了を待機する必要が生じるためにリカバリー時間が増加する原因となります。