HISAM Reorganization Unload utility (DFSURUL0)
Use the HISAM Reorganization Unload utility (DFSURUL0) to unload and reorganize HISAM databases and create secondary indexes in HISAM databases.
Use the HISAM Reorganization Unload utility to:
- Unload a HISAM database.
- Create reorganized output, which you can use as input to either the Database Recovery utility or the HISAM Reorganization Reload utility (DFSURRL0).
- Format the index work data sets that the Prefix Resolution utility (DFSURG10) creates so they can be used by the HISAM Reorganization Reload utility (DFSURRL0). The HISAM Reorganization Reload utility uses the data sets to create a secondary index or to merge records from the index work data sets with a shared secondary index, if one exists.
The DFSURUL0 blocks the output to the block size of the output device for devices other than 3380s. If the device is a 3380, a block size of 23 KB is used unless the logical record length is larger than 23 KB. If the logical record length is larger than 23 KB, the block size is 32 KB rounded down to an even multiple of the logical record length. Because the blocking factor is determined at execution time, you must use IBM® standard labels on all output volumes.
If a new DBD is generated with new sizes, first unload the database using the new DBD. Then run DFSMS Access Method Services to delete the old data sets and to define new data sets containing the new block sizes and logical record lengths (or, rather, their logical equivalents in VSAM, that is, control interval size and LRECLs). You can then reload the databases by using the HISAM Reorganization Reload utility (DFSURRL0). If you want to specify control interval or record sizes different from the DBD, then code CHNG=CARD in columns 50-80 of the Utility Control Statement and use a CHANGE control statement to specify the new sizes. Otherwise, use CHNG=DBD in this field.
The Utility Control Facility can also perform the functions of this utility.
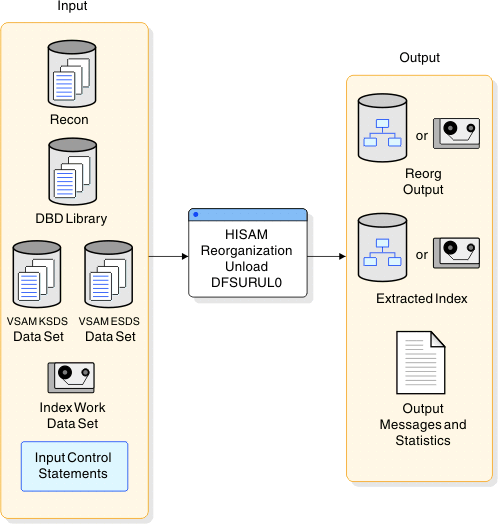
The following figure is a flow diagram of this utility.
Subsections:
Restrictions
The following restrictions apply to use of the HISAM Reorganization Unload utility:
- This utility cannot unload a PSINDEX database. The HD Reorganization Unload utility (DFSURGU0) is used to unload the PSINDEX database.
- The HISAM Reorganization Unload utility cannot make structural changes or changes to database organizations. Use the HD Reorganization Unload (DFSURGU0) and HD Reorganization Reload (DFSURGL0) utilities for these purposes.
- This utility cannot unload a HISAM database if the database contains logical child segments that have direct address logical parent pointers.
- This utility cannot unload a SHISAM database.
- Do not use this utility to unload or reload a shared secondary index that has alias names that are not registered to DBRC. If you do, IMS™ issues message DFS194W to indicate that the database referenced by the PSB is not registered with DBRC. IMS then treats the database as if exclusive use was specified for the subsystem by the user.
- Sequential buffering does not support this utility.
- The DFSURUL0 utility works on full-function non-HALDB databases only.
- Utilities that alter databases cannot be run while the database is quiesced.
- A Fast Path secondary index database cannot be input to DFSURUL0. To reorganize a Fast Path secondary index database, issue an IDCAMS REPRO command. To recover a Fast Path secondary index database, use either the Database Recovery utility (DFSURDB0) or an index builder tool from any IMS vendor product.
Prerequisites
Currently, no prerequisites are documented for the DFSURUL0 utility.
Requirements
The requirements for the DFSURUL0 utility include:
- To use this utility for recovery purposes, you must use the HISAM Reorganization Reload utility (DFSURRL0) to reload the database before applying changes to the database. If you do not immediately reload the database before applying changes, the segments are reloaded into a different location. The logs that are created between unload and reload refer to the old location, making recovery impossible.
- If a write error has occurred for the database and the database has not been recovered, you must perform recovery before you run this utility. If the database is registered with DBRC, and if this utility uses DBRC, the fact that a write error has occurred and recovery has not been performed is known to DBRC, and DBRC rejects the authorization request of this utility.
- A new DBD must have the same name as the old DBD. Both old and new DBDs can exist in the system if two separate libraries are used and the appropriate library is referenced at unload and reload times.
Recommendations
Currently, no recommendations are documented for the DFSURUL0 utility.
Input and output
The primary input to the DFSURUL0 utility is a VSAM KSDS or ESDS data set to be reorganized. The primary output of the DFSURUL0 utility is a reorganized VSAM KSDS or ESDS unload data set.
The following table identifies inputs and outputs for the DFSURUL0 utility.
| Input | Output |
|---|---|
| RECON | Output messages and statistics |
| DBD library | Extracted index |
| VSAM KSDS data set | Reorganization output |
| VSAM ESDS data set | |
| Index work data set | |
| Input control statements |
Example output report
The HISAM Reorganization Unload utility provides messages and statistics about the database contents for each data set group. In addition, the utility provides an audit trail. The following figure is an example of the output messages and statistics this utility produces.
H I E R A R C H I C A L I N D E X E D S E Q U E N T I A L
D A T A B A S E R E O R G A N I Z A T I O N U N L O A D
D A T A S E T G R O U P S T A T I S T I C S
DATA BASE - DIVNTZ04
PRIMARY DD- DBHVSAM1
OVERFLOW DD- DBHVSAM2
PRIMARY ROOTS OVERFLOW ROOTS OVERFLOW DEPENDENTS
IN OUT DELETED IN DELETED IN OUT
3 3 0 0 0 2 2
TOTAL NUMBER OF RECORDS OUT =10
COPY 1 ON VOLUME(S)- USER02
ROOT OVERFLOW CHAINS (#) DEPENDENT OVERFLOW CHAINS (#) ROOTS W/OUT OVERFLOW CHAINS (BYTES)
NO. LONGEST SHORTEST AVG NO. LONGEST SHORTEST AVG NO. LONGEST SHORTEST AVG
0 0 0 0.00 2 1 1 1.00 0 0 0 0.00
S E G M E N T L E V E L S T A T I S T I C S
MAXIMUM AVERAGE MAXIMUM AVERAGE SEGMENT SEGMENT TOTAL SEGMENTS AVERAGE COUNT PER
TWINS TWINS CHILDREN CHILDREN NAME LEVEL BY SEGMENT TYPE DATA BASE RECORD
1 1.00 12 8.00 J1 1 3 1.00
2 1.00 2 0.66 J2 2 3 1.00
1 0.33 1 1.00 J3 3 1 0.33
1 1.00 0 0.00 J4 4 1 0.33
2 1.33 3 1.75 J5 2 4 1.33
1 1.00 2 0.75 J6 3 4 1.33
1 0.50 1 0.50 J7 4 2 0.66
1 0.50 0 0.00 J8 5 1 0.33
2 1.00 3 1.66 J9 2 3 1.00
1 1.00 0 0.00 J10 3 3 1.00
0 0.00 0 0.00 J11 4 0 0.00
2 0.66 0 0.00 J7P 3 2 0.66
0 0.00 0 0.00 J12 2 0 0.00
0 0.00 0 0.00 J13 3 0 0.00
0 0.00 0 0.00 J14 4 0 0.00
0 0.00 0 0.00 J13X 3 0 0.00
TOTAL SEGMENTS IN DATA SET GROUP=27 AVG DATA SET GROUP RECORD LENGTH=203 BYTES
If you select any options for this execution, various messages are generated and appear immediately following the page heading.
Following the message for each data set group, the heading DATA SET GROUP STATISTICS appears.
- DATA BASE
- Database name.
- PRIMARY DD
- VSAM KSDS ddname of the data set group.
- OVERFLOW DD
- VSAM ESDS ddname of the data set group.
- PRIMARY ROOTS
- Statistics related to root records in the VSAM KSDS:
- IN
- Number of old VSAM KSDS roots that were read
- OUT
- Number of new VSAM KSDS roots that were written
- DELETED
- Number of old VSAM KSDS roots that were deleted
- OVERFLOW ROOTS
- Statistics related to old roots in the VSAM ESDS:
- IN
- Number of old VSAM ESDS roots that were read
- DELETED
- Number of old VSAM ESDS roots that were deleted
- OVERFLOW DEPENDENTS
- Statistics related to dependent records in the VSAM ESDS:
- IN
- Number of old dependent records in the VSAM ESDS that were read
- OUT
- Number of new dependent records in the VSAM ESDS that were written
- TOTAL NUMBER OF RECORDS OUT
- Number of records, both VSAM KSDS roots and VSAM ESDS dependents,
that were written. This total includes at least one header record.
It might also include two or more statistics records—one or
more at the beginning of the data set that was used as a table initialization
record for the Reload program, and one or more at the end of the data
set containing totals that were unloaded by segment type so that the
HISAM Reload utility can compare the numbers reloaded with those unloaded.
A statistics table record consists of 20 bytes for each segment type in the DBD, plus a 28 byte header for each LRECL that is needed to contain the entire statistics record. The approximate number of LRECLs that are required to contain the statistics record can be determined by applying the following formula: (Number of segment types x 20)/(LRECL)
Multiplying the results by 2 gives the approximate number of LRECLs added to the total number of records written.
- COPY 1 ON VOLUME(S) - volser1
- The primary output data set has successfully completed. The list of volume serial numbers indicates which volumes were used and the order of their use. If a second copy was requested and the second copy successfully completed, another message, COPY 2 ON VOLUME(S) - volser2, is included.
- ROOT OVERFLOW CHAINS (#)
- Statistics dealing with root records in a VSAM KSDS that have
overflow chains to root records in a VSAM ESDS:
- NO.
- Number of roots with overflow chains
- LONGEST
- Largest number of VSAM ESDS roots chained off one VSAM KSDS root
- SHORTEST
- Smallest nonzero number of VSAM ESDS roots chained off one VSAM KSDS root
- AVERAGE
- Average number of VSAM ESDS roots chained off one VSAM KSDS root (of those with chains)
- DEPENDENT OVERFLOW CHAINS (#)
- Statistics dealing with VSAM KSDS roots that had dependents in
VSAM ESDS:
- NO.
- Number of roots with VSAM ESDS-dependent records
- LONGEST
- Largest number of VSAM ESDS-dependent records chained off one root
- SHORTEST
- Smallest nonzero number of VSAM ESDS-dependent records chained off one root
- AVERAGE
- Average number of VSAM ESDS-dependent records chained off one root (of those roots which had dependents)
- ROOTS WITHOUT OVERFLOW CHAINS (BYTES)
- Statistics dealing with VSAM KSDS roots which had no dependents:
- NO.
- Number of roots without dependent chains
- LONGEST
- Largest database record (in bytes) with no VSAM ESDS-dependent records
- SHORTEST
- Shortest database record (in bytes) with no VSAM ESDS-dependent records
- AVERAGE
- Average database record length (in bytes) of those roots with no VSAM ESDS-dependent records
The SEGMENT LEVEL STATISTICS section contains the following fields.
- MAXIMUM TWINS
- Maximum number of segments of this type encountered under an immediate parent segment. At the root level, this value is always 1.
- AVERAGE TWINS
- Average number of segments of this type encountered under an immediate parent segment. This value is carried out to two decimal places.
- MAXIMUM CHILDREN
- Maximum number of child segments (at all subordinate levels) under a given parent.
- AVERAGE CHILDREN
- Average number of child segments (at all subordinate levels) under a given parent. This value is carried out to two decimal places. The lowest level segment in any hierarchic path has a value of zero in this field type.
- SEGMENT NAME
- Segment name to which this line of statistics applies.
- SEGMENT LEVEL
- The hierarchic level of this segment in the database.
- TOTAL SEGMENTS BY SEGMENT TYPE
- Count of the occurrences of this segment type in the entire database.
The count field in the level 1 segment type reflects the total number
of database records (root segments) in the database.
When a database is part of a shared secondary index database, the segment occurrence count always appears under the first segment name. All other segment name counts are zero.
- AVERAGE COUNT PER DATABASE RECORD
- A count of the average number of occurrences of this segment type within a given database record. The value is carried to two decimal places.
Following the individual segment type statistics for this data set group are the following two fields:
- TOTAL SEGMENTS IN DATA SET GROUP
- The total number of segments in the data set group.
- AVERAGE DATA SET GROUP RECORD LENGTH
- The average length in bytes of the portion of the database record stored in this data set group.
JCL specifications
The DFSURUL0 utility is run as a standard z/OS® job. The JCL specifications for the DFSURUL0 utility include a JOB statement, the EXEC statement, and the DD statements. One or more utility control statements must be included with the JCL statements.
The following JCL statements are required:
- A JOB statement that you define to meet the specifications of your installation.
- An EXEC statement
- DD statements that define inputs and outputs
EXEC statement
The EXEC statement for the DFSURUL0 utility uses a specific format.
The EXEC statement must be in the form:
PGM=DFSRRC00,PARM='ULU,DFSURUL0'The normal IMS positional parameters, such as SPIE, BUF, and DBRC, can follow the program name in the PARM field.
DD statements
The DFSURUL0 utility uses a number of required and optional DD statements.
The DFSURUL0 utility uses the following DD statements:
- STEPLIB DD
- Points to IMS.SDFSRESL, which contains the IMS nucleus and required action modules. If STEPLIB is unauthorized (because libraries that are not APF authorized are concatenated to IMS.SDFSRESL), you must include a DFSRESLB DD statement.
- DFSRESLB DD
- Points to an APF-authorized library that contains the IMS SVC modules.
- IMS DD
- Defines the library that contains the DBD that describes the database to be reorganized (DSN=IMS.DBDLIB,DISP=SHR). This data set must reside on a direct-access device.
- SYSPRINT DD
- Defines the message and statistics output data set. The data set can reside on a tape, direct-access device, or printer, or it can be routed to the output stream. DCB parameters specified for this data set are RECFM=FBA and LRECL=133. BLKSIZE must be provided on the SYSPRINT DD statement and must be a multiple of 133.
- SYSIN DD
- Defines the input control statement data set. This data set can reside on a tape, or a direct-access device, or it can be routed through the input stream.
- vsamksds DD
- Defines the VSAM KSDS that is to be reorganized. The ddname must
match the name in the DBD that describes this data set. It must also
appear on the utility control statement in the SYSIN data set of this
job step. One DD statement of this type must be present for each VSAM
KSDS that is to be reorganized.
This DD statement represents the primary data set of the HISAM database. If you are creating a secondary index, you must provide one or more DD statements. Each DD statement represents a secondary index data set that is to be reorganized.
- vsamesds DD
- Defines the VSAM ESDS to be reorganized. The ddname must match the name in the DBD that describes this data set. One DD statement of this type must be present for each VSAM ESDS that is to be reorganized.
- dataout1 DD
- Defines the first copy of the reorganized output data set. One
DD statement of this type is required for each VSAM data set group
to be reorganized. It can be any name, but the name must appear in
the associated utility control statement. The data set must reside
on either a tape or a direct-access device.
This output data set can be used as an image copy data set. To register the unload data set as an image copy with DBRC, you must reload the database by using the HISAM Reload utility.
- dataout2 DD
- Defines the second copy of the reorganized output data set. This
optional statement is required only if two copies of the output are
requested. Specifying multiple output copies can be advantageous;
if a permanent error occurs on one copy, and the second volume continues
to the normal end of job, a total rerun is not required.
The same requirements described for the dataout1 DD statement apply to dataout2.
- indexwrkds DD
- Describes the output data set ddname (DFSURIDX) from the Prefix Resolution program that contains secondary index information. This statement is required if the utility control statement is type 'X'; otherwise, it is optional. The ddname must match the name starting in position 40 of the control statement.
- DFSEXTDS DD
- Writes an unloaded version of the records that have been split out from a shared secondary index as specified in control statements. DFSEXTDS DD is optional and is required only if 'E' is specified in position 3 of the utility control statement. The DCB attributes are determined dynamically, based on the output device type and the VSAM LRECLs that are used. You must use standard labels.
- DFSVSAMP DD
- Describes the data set that contains the buffer information the
DL/I buffer handler requires. This DD statement is required.
The data set can reside on a tape or direct-access device, or it can be routed through the input stream.
- SYSUDUMP or SYSABEND DD
- Defines a dump data set. These DD statements are optional. If both statements are present, the last occurrence is used for the dump.
- RECON1 DD
- Defines the first Database Recovery Control (DBRC) RECON data set. This RECON1 data set must be the same RECON1 data set that the control region is using.
- RECON2 DD
- Defines the second DBRC RECON data set. This RECON2 data set must be the same RECON2 data set that the control region is using.
- RECON3 DD
- Defines the optional RECON data set DBRC uses when an error is
encountered in RECON1 or RECON2. This RECON3 data set must be the
same RECON3 data set that the control region is using. Restriction: If you are using dynamic allocation, do not use these RECON data set ddnames.
Return codes
The HISAM Reorganization Unload utility produces return codes preceded (in the case of errors) by numbered messages to the SYSPRINT data set that more fully explain the results of program execution.
The return codes are as follows:
- Code
- Meaning
- 0
- All requested operations completed successfully.
- 4
- One or more operations did not complete successfully.
- 8
- Severe errors caused the job to terminate.
- 12
- A combination of return codes 4 and 8 occurred.
- 16
- The ddname SYSIN could not be opened.