HD Reorganization Unload utility (DFSURGU0)
Use the HD Reorganization Unload utility (DFSURGU0) to reorganize IMS™ full-function databases, to change IMS full-function database structures, and to record information about logical relationships that are used by IMS full-function databases.
The DFSURGU0 utility is usually paired with the HD Reorganization Reload utility (DFSURGL0), which reloads IMS full-function databases by reading the unload data set that is created by the DFSURGU0 utility.
- Unload an HDAM, PHDAM, HIDAM, PHIDAM, PSINDEX, or HISAM database to a sequential data set.
- Unload a subset of PHDAM, PHIDAM, or PSINDEX partitions by including the appropriate utility control statement. If you do not include a utility control statement when running this utility against a HALDB database, the DFSURGU0 utility unloads the entire database.
- Generate a data set with prefix information (if logical relationships exist).
- Make structural changes to a HDAM, PHDAM, HIDAM, PHIDAM, or HISAM database.
- Record logical parent, logical twin, and logical child pointer fields, and the counter fields that are associated with logical parents in a database.
- Convert databases to HALDB partitioned databases and fall back from HALDB.
The DFSURGU0 utility can also make certain structural changes to a database during the process of reorganization if you replace the original DBD of the database that is being reorganized with a new version of the DBD that reflects the structural changes.
- Delete an existing segment type from the DBD, provided all segments of this type were deleted from the database prior to execution of the HD Reorganization Unload utility.
- Add new segment types to the new DBD, provided they do not change either the hierarchic relationships among existing segment types or the concatenated keys of logically related segments.
- Change, add, or delete any field statement except the one for the sequence field of a segment; however, IMS makes no attempt to alter the data content of a segment.
- Change existing segment lengths on fixed-length segments. IMS cannot alter the data content, however, except to truncate
data if the segment is made smaller.
If the segment length is increased, binary zeros are used as fill characters for the added portion of the segment. It is your responsibility to replace the extended portion of the segment by running an application program in update mode under IMS.
- Change the DL/I access method. OSAM format can be changed to VSAM format or VSAM format to OSAM. Any DL/I access method can be changed except for HDAM or PHDAM, which cannot be changed to either indexed method. HISAM, HIDAM, and PHIDAM can be changed to HDAM or PHDAM.
- Change segment pointer options for HDAM, PHDAM, HIDAM, and PHIDAM databases. If,
however, the database contains logical relationships and if counter, LT, or LP pointers
are changed, the Database Prereorganization utility must be rerun. If changing from
physical to virtual pairing, all occurrences of the segment that will become virtual
must be deleted. Virtual pairing is not supported for HALDB. Note: This restriction does not apply to HALDB databases.
To accomplish the unload operation, the utility functions as an application program and issues a series of unqualified GN calls to DL/I. A complete pointer integrity validation is not performed as a by-product of executing the Unload utility.
When unloading databases, the HD Reorganization Unload utility adds a prefix to each unloaded segment to support reorganization. The prefix that is created for segments unloaded from a non-HALDB database is different that the prefix created for segments that are unloaded from HALDB databases.
The prefix that is created for segments that are unloaded from non-HALDB databases is mapped by the macro DFSURGUF.
The prefix that is created for segments that are unloaded from a HALDB database is mapped by the macro DFSURGUP. DFSURGUP includes the indirect list key (ILK) and the extended pointer set (EPS) if the unloaded segment is a logical child.
Usually, an ILK contains the relative byte address (RBA), the partition ID, and the partition reorganization number of the segment when it was first created, as shown in the following figure. However, if you are migrating an HD database to HALDB, the DFSURGU0 utility creates a migration ILK that contains a partition ID of zero and the field that normally contains the reorganization number contains the number of the data control block (DCB) on DASD from which the target segment was read.

The functions of this utility can be performed by the Utility Control Facility.
The following figure is a flow diagram of the HD Reorganization Unload utility.
Restrictions
- The Utility Control Facility is not supported for HALDBs.
- After running the DFSURGU0 utility, do not update the database until the database is reloaded. Any updates that are made after the unload files are created will be lost if the unload files are used to reload the database.
- Names of existing segment types must not be changed.
- An unload that uses the MIGRATE control statement can be performed only on non-HALDBs.
- You cannot change the DL/I access method of a HDAM or a PHDAM database to use an indexed access method.
- Do not use the HD Reorganization Unload utility:
- When changing from bidirectional virtual pairing to bidirectional physical pairing, if any logical child segments have been deleted from either the physical or logical path but not from both paths.
- When changing a real logical child from one logically related database to another.
- When reorganizing a prime or secondary index, use the HISAM reorganization utilities for an index database, with exception for PSINDEX.
- If a write error has occurred for the database, and the database has not been recovered. The recovery must be executed before this utility is executed. If the database is registered with DBRC, and this utility uses DBRC, then the fact that a write error has occurred and recovery has not been performed is known to DBRC and DBRC rejects the authorization request of this utility.
- The DFSURGU0 utility will work on full-function (HALDB and non-HALDB) databases only.
- Utilities that alter databases cannot be run while the database is quiesced.
- VSAM data set sharing options must allow multiple readers.
- To prevent unpredictable results, key ranges must start and end on partition boundaries. One or more partition's worth of data can be unloaded, but must be unloaded into one data set as HD Reload supports only a single data set as input.
- The KEYRANGE option is only valid after a MIGRATE= statement. It is not valid after a MIGRATX= statement.
- The KEYRANGE option requires unload of the DLI database with IRLM=N, DBRC=N and DISP=SHR for database data sets.
- The migration reload must use DBRC=Y and requires allocating the RECON data sets containing the new HALDB partition definitions, either with JCL or dynamically using DBRC RECON MDA members.
Prerequisites
- If you are deleting an existing segment type from a DBD, before you execute the DFSURGU0 utility, you must first delete all segments of the type to be deleted from the database.
Requirements
- The DFSURGU0 utility must be executed against the DBD describing the current structure of the database
- To change the data set format of a HALDB database from OSAM format to VSAM format or VSAM format to OSAM format, you must delete and redefine the HALDB definition in the RECON data set.
- When unloading an HDAM or PHDAM database for a MIGRATX HD unload, the randomizing module and any IMS user exit routines, such as compression and sparse index, must be included in the JOBLIB. A sparse index is not required for a normal HD unload.
- If you are increasing the length of a fixed length segment length, you must replace the binary zeros that are used as filler in the extended portion of the segment by using an application program running in update mode under IMS.
- Segment pointer options for HDAM, PHDAM, HIDAM, and PHIDAM databases can be changed.
If, however, the database contains logical relationships and if counter, LT, or LP
pointers are changed, the Database Prereorganization utility must be rerun. If changing
from physical to virtual pairing, all occurrences of the segment that will become
virtual must be deleted. Virtual pairing is not supported for HALDB. Note: Because virtual pairing is not supported by HALDB, the requirement to delete all segments that will become virtual does not apply to HALDB.
- If you are converting a secondary index database that has non-unique keys to HALDB, you must include separate JCL steps to sort and merge the unload records and create new /SX values prior to inputting them into the HD Reorganization Reload utility. When /SX values are generated in the unload record for non-unique keys the HALDB DBD must be changed to accommodate the /SX prior to performing the reload step.
- If you are converting a secondary index database that uses symbolic pointing to HALDB, you must include separate JCL steps to sort and merge the unload records. For examples of the sort and merge JCL, see Sort and merge unload records for secondary indexes that use symbolic pointing.
- If you are converting a database that has secondary indexes to a HALDB partitioned
database, you must run the DFSURGU0 utility to unload each secondary index database. The
DFSURGU0 utility reads the primary database to resolve the source and target segments
that are needed to construct the indirect list entry key (ILK) and extended pointer set
(EPS) information for the conversion unload record that is destined for the new PSINDEX.
The sequential processing of secondary index segments causes many random reads of the
primary database.
These random accesses of the primary database across multiple secondary index unloads causes poor overall performance of the migration unload of DL/I secondary index databases to HALDB PSINDEX.
For example, if a single primary database has seven secondary index databases and each migration unload job takes thirteen hours, then the total time spent unloading all of the secondary index databases would be 7 x 13, or 91 hours. A significant portion of this time is spent reading the prime database multiple times.
- When you use the HD Unload utility to migrate from non-HALDB's to HALDB's, you can increase performance of MIGRATE= by using the KEYRANGE option to run multiple unload jobs in parallel. This is most useful when migrating non-HALDB's that are very large, or have a large amount of logically related segments.
- For the KEYRANGE option:
- Both fromkeyval and tokeyval should be copied from output of a DBRC LIST.DB batch command and pasted into the HDUNLOAD SYSIN DD statement.
- VSAM data set share options of (3,3) are recommended.
- To maximize performance, unload a key range of a single partition in one step followed by a migration reload of the corresponding HALDB partition.
An additional EXEC parameter, DFSDF, must be specified to use this utility with an IMS catalog database that is not registered in the RECON data set. DFSDF= specifies the 3-character suffix of the DFSDFxxx member of the IMS.PROCLIB data set that contains the names of your unregistered IMS catalog databases. The names are specified with the UNREGCATLG parameter of the DATABASE statement. For example:
//HDUNLOAD EXEC PGM=DFSRRC00, // PARM=(ULU,DFSURGU0,DFSCD000,,,,,,,,,,,N,N,,,,,,,,,,,,,,,,,,,,,,,,,, // 'DFSDF=CAT')Replace the 3-character suffix CAT with the suffix of the DFSDFxxx member that specifies the unregistered IMS catalog database names.
Recommendations
Currently, there are no recommendations documented for the DFSURGU0 utility.
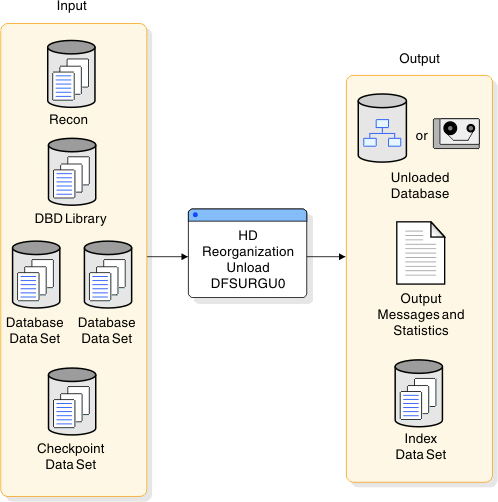
Input and output
The primary input for the DFSURGU0 utility is a database data set, although other inputs are also necessary. The primary output of the DFSURGU0 utility is an unload data set. Other output can include a checkpoint data set and output messages and unload statistics.
| Input | Output |
|---|---|
| RECON | Checkpoint data set |
| DBD library | Output messages and statistics |
| Database data set | Unloaded data set |
| Checkpoint data set |
The HD Reorganization Unload utility provides output messages and statistics. An example of the messages and statistics obtained from this utility is shown in the following figure.
H I E R A R C H I C A L D I R E C T D A T A B A S E R E O R G A N I Z A T I O N U N L O A D PAGE 01
DFS343W DDNAME DFSUCKPT WAS SPECIFIED AS DD DUMMY OR WAS OMITTED FOR FUNCTION DU
DFS342I RESTART NOT REQUESTED, NORMAL PROCESSING BEGINS
DFS344W DDNAME FOR SECOND COPY WAS NOT SUPPLIED, 1 COPY REQUESTED FOR FUNCTION DU
COPY 1 ON VOLUME(S) - USER02
DFS340I DATABASE DHONTZ04 HAS BEEN SUCCESSFULLY UNLOADED BY FUNCTION DU
D A T A B A S E S T A T I S T I C S
SEGMENT LEVEL STATISTICS RECORD LEVEL STATISTICS
MAXIMUM AVG MAXIMUM AVG SEGMENT SEGMENT TOTAL SEGMENTS AVG COUNT PER
TWINS TWINS CHILDREN CHILDREN NAME LEVEL BY SEG TYPE DB RECORD
1 1.00 8 7.00 K1 1 3 1.00
1 0.66 3 2.50 K2 2 2 0.66
2 1.50 1 0.66 K3 3 3 1.00
1 0.66 0 0.00 K4 4 2 0.66
2 1.66 1 0.60 K5 2 5 1.66
1 0.60 0 0.00 K6 3 3 1.00
4 2.00 0 0.00 K8 2 6 2.00
0 0.00 0 0.00 K9 2 0 0.00
0 0.00 0 0.00 K10 3 0 0.00
0 0.00 0 0.00 K11 3 0 0.00
0 0.00 0 0.00 K12 4 0 0.00
0 0.00 0 0.00 K13 4 0 0.00
0 0.00 0 0.00 K14 3 0 0.00
0 0.00 0 0.00 K15 3 0 0.00
H I E R A R C H I C A L D I R E C T D B R E O R G U N L O A D PAGE 02
TOTAL SEGMENTS IN DATABASE=24 AVERAGE DATABASE RECORD LENGTH=300 BYTES
DFS339I FUNCTION DU HAS COMPLETED NORMALLY RC=0Following the page heading are the various messages that are generated as a result of the options that are selected for this execution.
The message "COPY 1 ON VOLUME(S) - volser1" appears if the primary output data set successfully completed. The list of volume serial numbers indicates which volumes were used and the order of their use. If a second copy was requested and successfully completed, the message "COPY 2 ON VOLUME(S) - volser2" appears. The heading "DATABASE STATISTICS" follows the messages.
- MAXIMUM TWINS
- The maximum number of segments of this type encountered under an immediate parent segment. At the root level, this value is always 1.
- AVERAGE TWINS
- The average number of segments of this type encountered under an immediate parent segment. This value is carried out to two decimal places.
- MAXIMUM CHILDREN
- The maximum number of child segments (at all subordinate levels) under a given parent.
- AVERAGE CHILDREN
- The average number of child segments (at all subordinate levels) under a given parent. This value is carried out to 2 decimal places. The lowest level segment in any hierarchic path has a value of zero in this field type.
- SEGMENT NAME
- The segment name to which this line of statistics applies.
- SEGMENT LEVEL
- The hierarchic level of this segment in the database. The segment descriptions are mapped from top to bottom, in the same order in which they were described in the DBD.
- TOTAL SEGMENTS BY SEGMENT TYPE
- The count of the number of occurrences of this segment type in the entire database. The count field in the level 1 segment type reflects the total number of database records (root segments) in the database.
- AVERAGE COUNT PER DATABASE RECORD
- A count of the average number of occurrences of this segment type within a given database record. The value is carried to two decimal places.
Following the individual segment type statistics is a count of the total number of all segments in the database and the average database record length in bytes. The average database record length includes both the data length and the prefix size. The product of the number of segments at level 1 times the average database record length gives the total number of bytes in the database. Because all physically stored records might not use all available data positions, this figure can only be used as an approximation of the data set space required.
JCL specifications
- A JOB statement that you define to meet the specifications of your installation.
- An EXEC statement
- DD statements defining inputs and outputs
The output from the HD Reorganization Unload utility is an operating system variable blocked sequential data set. Because output is blocked to the maximum size that the output device can handle, standard labels must be used on output volumes.
EXEC statement
PGM=DFSRRC00,PARM='ULU,DFSURGU0,dbdname'The parameters ULU and DFSURGU0 describe the utility region. dbdname is the name of the DBD that describes the database to be reorganized. The normal IMS positional parameters such as SPIE, BUF, and DBRC can follow dbdname.
DD statements
The input, output, and resource data sets used by the DFSURGU0 utility are identified by DD statements.
The DFSURGU0 utility uses the following required and optional DD statements:
- STEPLIB DD
- Points to IMS.SDFSRESL, which contains the IMS nucleus and required action modules. If STEPLIB is unauthorized by having unauthorized libraries concatenated to IMS.SDFSRESL, a DFSRESLB DD statement must be included.
- DFSRESLB DD
- Points to an authorized library that contains the IMS SVC modules.
- IMS DD
- Defines the library that contains the DBD that describes the database to be
reorganized (that is, DSN=IMS.DBDLIB,DISP=SHR). This data set must reside on a direct-access device.Note:
 If you are unloading a HALDB database for which a HALDB alter operation
was started but the online change function was not done, you still need to specify the
DBD library that contains the original, unaltered DBD, regardless of the fact that
some or all of the segments in the database might now conform to a format that is
defined by the altered DBD. IMS automatically
gets the altered DBD information from the staging ACB library and requires the
original, unaltered DBD for comparison.
If you are unloading a HALDB database for which a HALDB alter operation
was started but the online change function was not done, you still need to specify the
DBD library that contains the original, unaltered DBD, regardless of the fact that
some or all of the segments in the database might now conform to a format that is
defined by the altered DBD. IMS automatically
gets the altered DBD information from the staging ACB library and requires the
original, unaltered DBD for comparison.
- SYSPRINT DD
- Defines the message and statistics output data set. The data set can reside on a tape, direct-access device, or printer, or be routed through the output stream. DCB parameters specified for this data set are RECFM=FBA and LRECL=121. BLKSIZE must be provided on the SYSPRINT DD statement and must be a multiple of 121.
- SYSIN DD
- Optional data set that defines the input control statement data set only to HALDB and fallback. If the SYSIN data set is omitted, the entire HALDB is unloaded. If the SYSIN data set is specified but does not contain anything, the entire HALDB is unloaded. This data set can reside on a tape, or a direct-access device, or it can be routed through the input stream.
- DFSUCKPT DD
- Defines the data set to be used to take checkpoints. If checkpoints are not required, do not use this statement. This data set usually resides on a direct-access device; however, a tape volume can be used.
- DFSURSRT DD
- Defines the checkpoint data set if a restart is to be attempted. Omit this statement
if you are not attempting a restart. If you are attempting a restart, ensure that the
statement references the same data set that the DFSUCKPT DD statement referenced when
the last checkpoint was taken. This data set normally resides on a direct-access device;
however, a tape volume can be used.
The DFSURSRT DD statement writes a special checkpoint record to the checkpoint data set and to the output data sets. If a restart is required, the checkpoint record is obtained from the checkpoint data set, the output volumes are positioned, and the proper position is established within the database. The statistics table records are read, and the main storage tables are properly initialized. The program then continues with normal processing.
- DFSURGU1 DD
- Defines the primary output data set. The data set can reside on either a tape or a direct-access device. This DD statement is required.
- DFSURGU2 DD
- Defines the secondary output data set. Use this DD statement if you are requesting two
copies of the output. The data set can reside on either a tape or a direct-access
device.
Multiple copies of the database can be produced. The advantage in specifying two copies is that if an I/O error occurs during execution, the utility continues to completion on the other copy. Performance would be somewhat diminished in this instance, but a total rerun would not be necessary.
- database DD
- Defines the database data set to be reorganized. One statement must be present for
each data set that is named in the DBD that describes the database being reorganized.
The ddname must match the ddname in the DBD.
If you are unloading a HALDB database, do not include the database DD statement. HALDB uses dynamic allocation. If you use the integrated HALDB Online Reorganization function, dynamic allocation automatically selects the appropriate A–J or M–V prefix for the data set name.
If this is a HIDAM database, DD statements must also exist for the data sets that represent the index. The DD statements used to relate to the index must contain ddnames specified in the DBD for the index database. No DD statements are required for whatever secondary indexes are associated with this database.
This data set must reside on a direct-access device.
- DFSVSAMP DD
- Describes the data set that contains the buffer pool information required by the DL/I
buffer handler.
The data set can reside on a tape, direct-access device, or be routed through the input stream. This statement is required.
- DFSCTL DD
- Describes the data set containing SBPARM control statements which request activation
of sequential buffering. Conditional activation of sequential buffering might improve
the buffering performance of OSAM DB data sets and reduce the job elapsed time.
The DFSCTL file can be either a sequential data set or a member of a PDS. The record format must be either F, FB, or FBS and the record length must be 80. The data set can reside on a direct-access device, a tape, or be routed through the input stream.
- DFSWRKnn
- Where nn is the number of secondary indexes (not less than 01). The DFSWRKnn data set is where the secondary index migration unload records are written.
- DFSSRTnn
- Where nn is the number of secondary indexes (not less than 01). The DFSSRTnn data set
is the sort control statements that are used for a corresponding DFSWRKnn. Note: The DFSSRTnn and DFSWRKnn data sets are allocated in the order of the secondary-index definition in the DBD. The utility does not attempt to relate a secondary index name to the suffix of the DFSSRTnn or DFSWRKnn DD statements or data sets. Secondary indexes use the next DFSSRTnn and DFSWRKnn data set pair in ascending order.
- SYSABEND DD or SYSUDUMP DD
- Define a dump data set. If either statement is supplied, any return code greater than 4 causes an abend U0347. If both statements are present, the last occurrence is used for the dump.
- RECON1 DD
- Defines the first DBRC RECON data set.
- RECON2 DD
- Defines the second DBRC RECON data set.
- RECON3 DD
- Defines the optional DBRC RECON data set used when an error is encountered in RECON1
or RECON2. This RECON data set must be the same RECON data set as the control region is
using.
Do not use these RECON data set ddnames if you are using dynamic allocation.
Return codes
The DFSURGU0 utility issues one or more of the following return codes upon completion:
- Code
- Meaning
- 0
- Database unload completed successfully.
- 4
- One or more warning messages were issued.
- 8
- A serious error occurred or copy 1 has an I/O error.
- 12
- A combination of return codes 4 and 8 occurred.
- 16
- Database unload did not complete successfully.