How To
Summary
t検定は、2群の量的変数(スケール尺度の数値変数)の平均値を比較して「A群とB群の平均値に有意な差があるといえるか?」を検定する分析です。パラメトリック検定に分類されますので、データが正規分布である必要があります(探索的分析で正規分布をしていない場合は中央値や順位を検定するノンパラメトリック検定を検討)。3群以上の量的変数の平均値の差の検定は分散分析となります。
Steps
1. t検定の概要
2群の量的変数(スケール尺度の数値変数)の平均値を比較して「A群とB群の平均値に有意な差があるといえるか?」を検定する分析です。パラメトリック検定に分類されますので、データが正規分布である必要があります(探索的分析で正規分布をしていない場合は中央値や順位を検定するノンパラメトリック検定を検討)。3群以上の量的変数の平均値の差の検定は分散分析となります。
明治時代末期に、ペンネーム「Student」ことウィリアム・ゴセット(ギネスビール勤務、大学の指導教官はカイ2乗検定のカール・ピアソンで、絶賛して応用した分散分析を発表したのがフィッシャーと、当時の業界は狭かった)が、麦の品種や樽ごとの成分比較を、小サンプルでの違いがデータ全体に通用するかの証明方法として、匿名で出した「t分布についての論文」が元になっております(以前社員が学会でビールのレシピをばらしてしまったため、当時のギネスビールは社員の学会参加不可だったので匿名)。
データの持ち方に応じて複数の実行方法があります。
(A)[分析]→[平均の比較]→[1サンプルのt検定]をクリックし、[検定値]を比較対象の平均値として、投入した[検定変数]の変数全体を1グループ(サンプル)としてその平均値とデータ全体を比較する。
(B)[分析]→[平均の比較]→[独立したサンプルのt検定]をクリックし、グループ化変数]にある[グループ1]と[グループ2]に定義したカテゴリーごとに平均値を比較する(ノンパラメトリック検定の「Mann–WhitneyのU検定」 「 Wilcoxonの順位和検定」に対応)。
(C) [分析]→[平均の比較]→[対応のあるサンプルのt検定]をクリックし、対応する[変数1]の平均値と[変数2]の平均値を比較する(ノンパラメトリック検定の「 Wilcoxonの符号付き順位検定」に対応) 。
2. 対応アプリケーション
SPSS Statistics Base
3-1. t検定の実行(1サンプルのt検定)
サンプルデータセット:
Windows「C:\Program Files\IBM\SPSS\Statistics\26\Samples\Japanese\brakes.sav」
MacOS「/Applications/IBM/SPSS/Statistics/26/Samples/Japanese/brakes.sav」
分析内容:スケール尺度変数「製造したディスクブレーキの直径」の平均値は、想定の平均値「322mm」と比べて差があるか。
操作手順:
1.SPSS Statisticsを起動し、「brakes.sav」を開きます。
2.メニューの[分析]→[平均の比較]→[1サンプルのt検定]をクリックし、[検定変数]に変数「ディスク ブレーキの直径 (mm) 」を投入し、 [検定値]にキーボードで「322」と入力し、[OK]で実行します。
結論となる出力は[1サンプルの検定]テーブルの[有意確率(両側)]です。
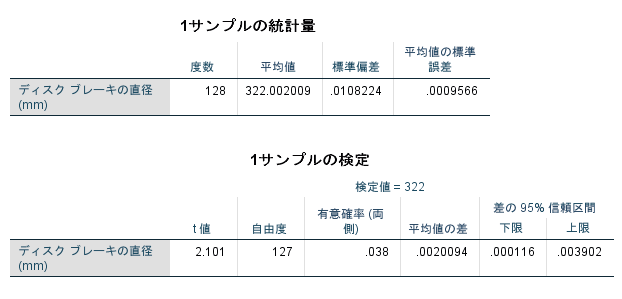
「ディスクブレーキの直径の平均値は、想定の平均値322mmと比べて差がない」という帰無仮説が、有意確率が有意水準(0.050)未満の場合に棄却されて、 「ディスクブレーキの直径の平均値は、想定の平均値322mmと比べて有意に差がある」という対立仮説が採用されます。具体的な差はテーブル表にあるとおり「0.0020094」となります。
とりあげたサンプルで生じているこちらが用意した平均との差「0.0020094」は、すべての製造したディスクブレーキにも生じる平均との差と言えます。
(他の分析例)機械が製造した日本のボール1,000個の反発係数の平均値は、アメリカのボールの0.4と比べて統計的に差があると言えるか。
3-2. t検定の実行(独立したサンプルのt検定)
サンプルデータセット:
Windows「C:\Program Files\IBM\SPSS\Statistics\26\Samples\Japanese\creditpromo.sav」
MacOS「/Applications/IBM/SPSS/Statistics/26/Samples/Japanese/creditpromo.sav」
分析内容:「従来の販促資料」グループと「新販促資料」グループとで、スケール尺度変数「受注までにかかった販促費用」の平均に差があるか。
操作手順:
1.SPSS Statisticsを起動し、「creditpromo.sav」を開きます。
2.メニューの[分析]→[平均の比較]→[独立したサンプルのt検定]をクリックし、[検定変数]に変数「販売促進期間に費やした金額(ドル) 」を投入し、 [グループ化変数]に変数「配布資料の種類」を投入し、[グループの定義]ボタンをクリックして[グループの定義]ダイアログの[特定の値を使用]を選択して、この変数の値「0」「1」をそれぞれ入力して[続行]ボタンをクリックし、 [独立したサンプルのt検定]ダイアログに戻って[OK]で実行します。
結論となる出力は[独立サンプルの検定]テーブルの[2つの母平均の差の検定]にある[有意確率(両側)]です。
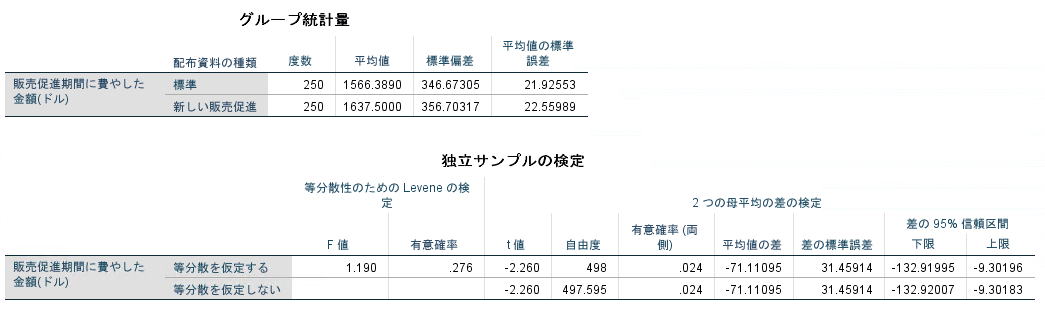
帰無仮説は「従来の販促資料と新販促資料とで、受注までにかかった販促費用に差はない」なので、有意確率が有意水準以上であれば、仮説がそのまま採用されて「従来の販促資料と新販促資料とで、受注までにかかった販促費用に差はない」となり、有意確率が有意水準未満であれば、仮説が棄却されて対立仮説が採用されて 「従来の販促資料と新販促資料とで、受注までにかかった販促費用に有意な差がある」となります 。
その前に帰無仮説が「等分散を仮定する」の「等分散性のためのLeveneの検定」が実施されており、この値が有意水準以上であれば帰無仮説「等分散を仮定する」の結果を、有意水準未満であれば対立仮説「等分散を仮定しない」の結果を採用します 。
ということで、この分析では「従来の販促資料と新販促資料とで、受注までにかかった販促費用に有意な差(具体的には費用削減)がある」となります。
(他の分析例)「教材Aを使用」グループと「教材Bを使用」グループとで、スケール尺度変数「TOEICの点数」の平均に差があるか。
3-3. t検定の実行(対応のあるサンプルのt検定)
サンプルデータセット:
Windows「C:\Program Files\IBM\SPSS\Statistics\26\Samples\Japanese\dietstudy.sav」
MacOS「/Applications/IBM/SPSS/Statistics/26/Samples/Japanese/dietstudy.sav」

分析内容:スケール尺度変数「ダイエット開始前」と「ダイエット後」とで、「体重(および中性脂肪)」に差があるか。
操作手順:
1.SPSS Statisticsを起動し、「dietstudy.sav」を開きます。
2.メニューの[分析]→[平均の比較]→[対応あるサンプルのt検定]をクリックし、 [対応ある変数]の[ペア1]の[変数1]に「中性脂肪」、 [ペア1]の[変数2]に「中性脂肪の最終測定」、 [ペア2]の[変数1]に「体重」、 [ペア2]の[変数2]に「体重の最終測定」を、それぞれ投入して[OK]をクリックします。
結論となる出力は[対応サンプルの検定]テーブルの[有意確率(両側)]です。
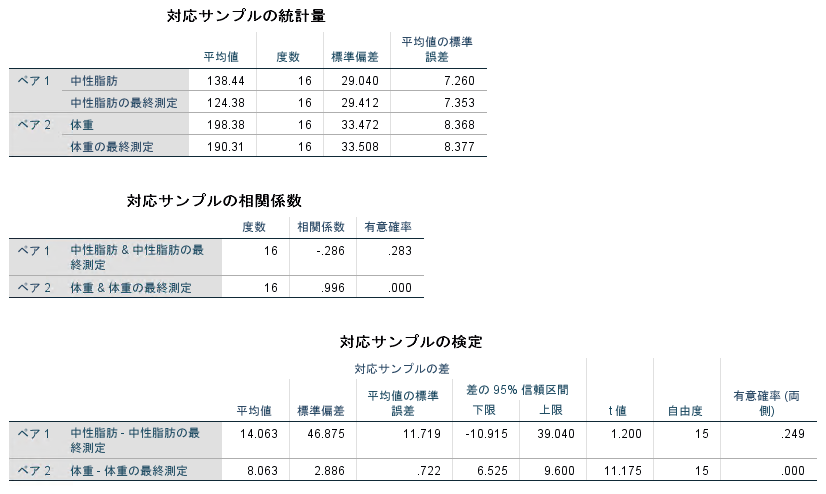
ペア2の帰無仮説は「ダイエット開始前の体重とダイエット後の体重とで、有意な差はない」なので、有意確率が有意水準以上であれば、帰無仮説がそのまま採用されて「ダイエット開始前の体重とダイエット後の体重とで、有意な差はない」となり、有意確率が有意水準未満であれば、帰無仮説が棄却されて対立仮説が採用されて 「ダイエット開始前の体重とダイエット後の体重とで、有意な差がある」となります 。
この分析ではペア1の帰無仮説は「ダイエット開始前の中性脂肪とダイエット後の中性脂肪とで、有意な差はない」 が有意確率0.249でそのまま採用されて「ダイエット開始前の中性脂肪とダイエット後の中性脂肪とで、有意な差はない」 という結論になり、具体的な差はあってもこのサンプルの結果が全体にも通用するとは証明出来ないことになります。
(他の分析例)「Youtubeにある適当な英語のカラオケを1日1曲歌う」を始める前と続けた後とで、スケール尺度変数「TOEICの点数」の平均に差があるか。
Document Location
Worldwide
Was this topic helpful?
Document Information
Modified date:
13 April 2020
UID
ibm11104171