Environment : IBM BigInsights 4.2
Step 1: Download the dataset
We are using the dataset from UCI Machine Learning Repository – SMS Spam Collection Data Set.
For more details refer –
https://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection
Download the dataset – https://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip
Unzip and upload the file (SMSSpamCollection) to HDFS (/tmp).
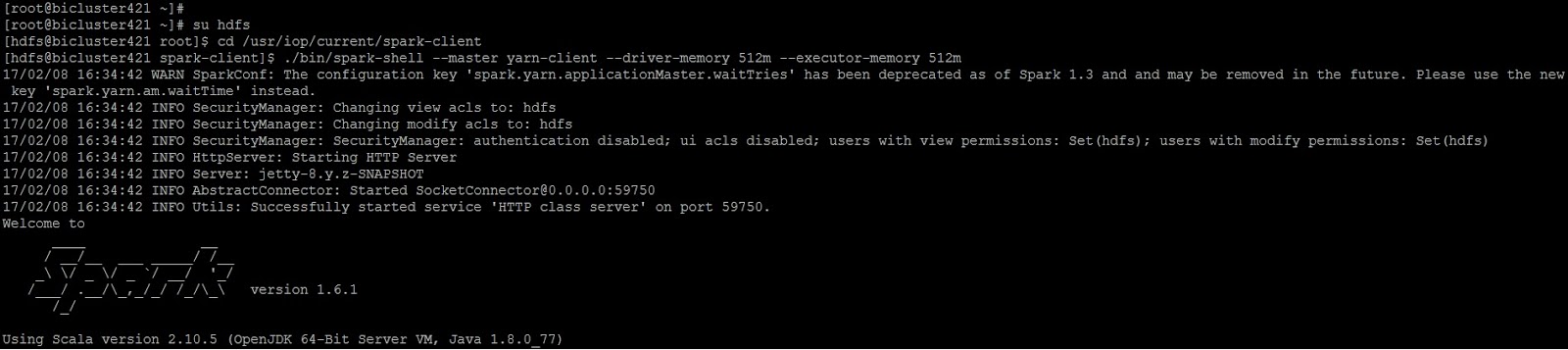
Step 2: Login to Spark Shell
su hdfs
cd /usr/iop/current/spark-client
./bin/spark-shell –master yarn-client –driver-memory 512m –executor-memory 512m
Step 3: In Scala prompt, run below commands
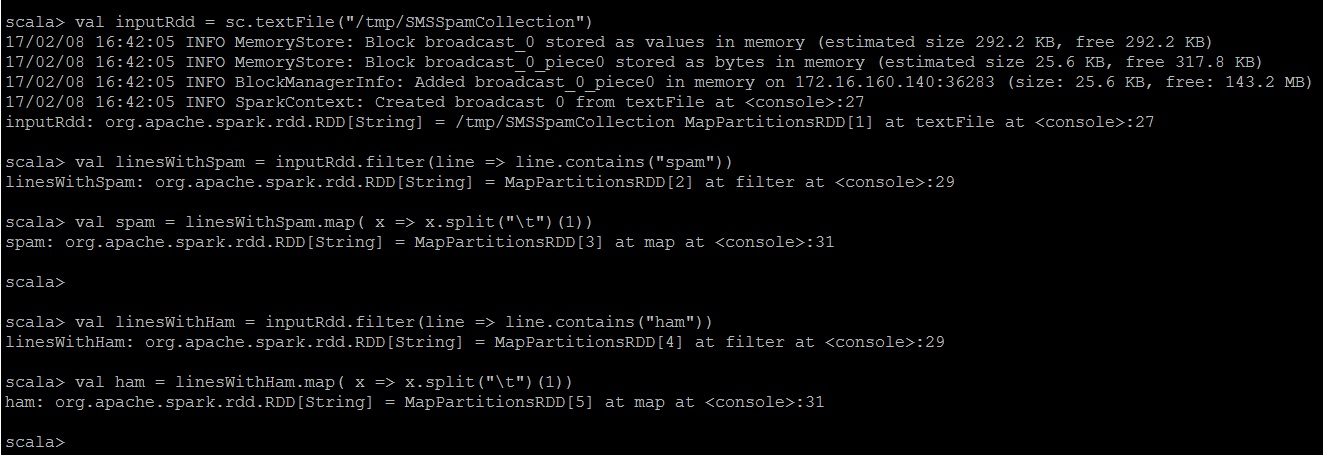
# Read the dataset.
val inputRdd = sc.textFile(“/tmp/SMSSpamCollection”)
# Get the records that are Spam and Ham
val linesWithSpam = inputRdd.filter(line => line.contains(“spam”))
val spam = linesWithSpam.map( x => x.split(“\t”)(1))
val linesWithHam = inputRdd.filter(line => line.contains(“ham”))
val ham = linesWithHam.map( x => x.split(“\t”)(1))
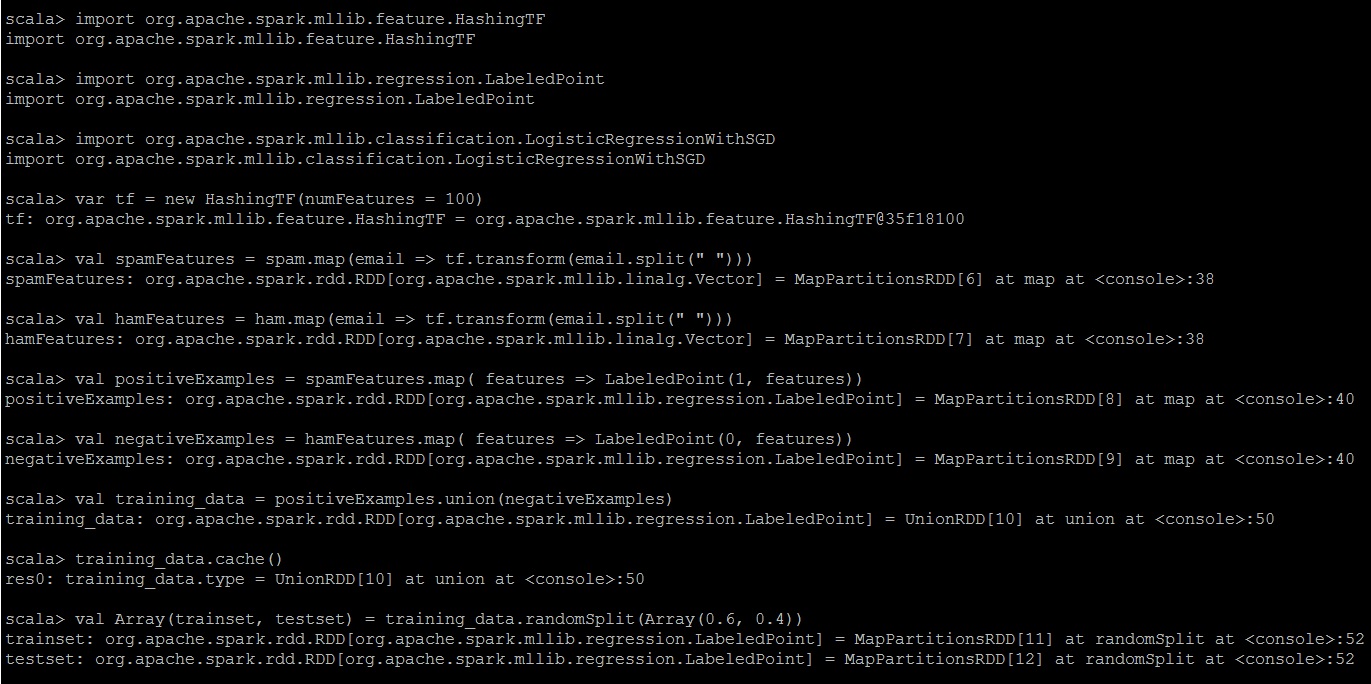
# Import the required mllib classes
import org.apache.spark.mllib.feature.HashingTF
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.classification.LogisticRegressionWithSGD
# Convert the text to vector of 100 features based on term frequency.
var tf = new HashingTF(numFeatures = 100)
val spamFeatures = spam.map(email => tf.transform(email.split(” “)))
val hamFeatures = ham.map(email => tf.transform(email.split(” “)))
# Label the Spam as 1 and ham as 0.
val positiveExamples = spamFeatures.map( features => LabeledPoint(1, features))
val negativeExamples = hamFeatures.map( features => LabeledPoint(0, features))
val training_data = positiveExamples.union(negativeExamples)
# cache the training data
training_data.cache()
# We use 60% of dataset for training and remaining for testing the model.
val Array(trainset, testset) = training_data.randomSplit(Array(0.6, 0.4))
# We use Logistic Regression model, and make predictions with the resulting model
val lrLearner = new LogisticRegressionWithSGD()
val model = lrLearner.run(trainset)
val predictionLabel = testset.map( x => (model.predict(x.features), x.label))
val accuracy = predictionLabel.filter(r => r._1 == r._2).count.toDouble / testset.count
println(“Model accuracy : ” + accuracy)
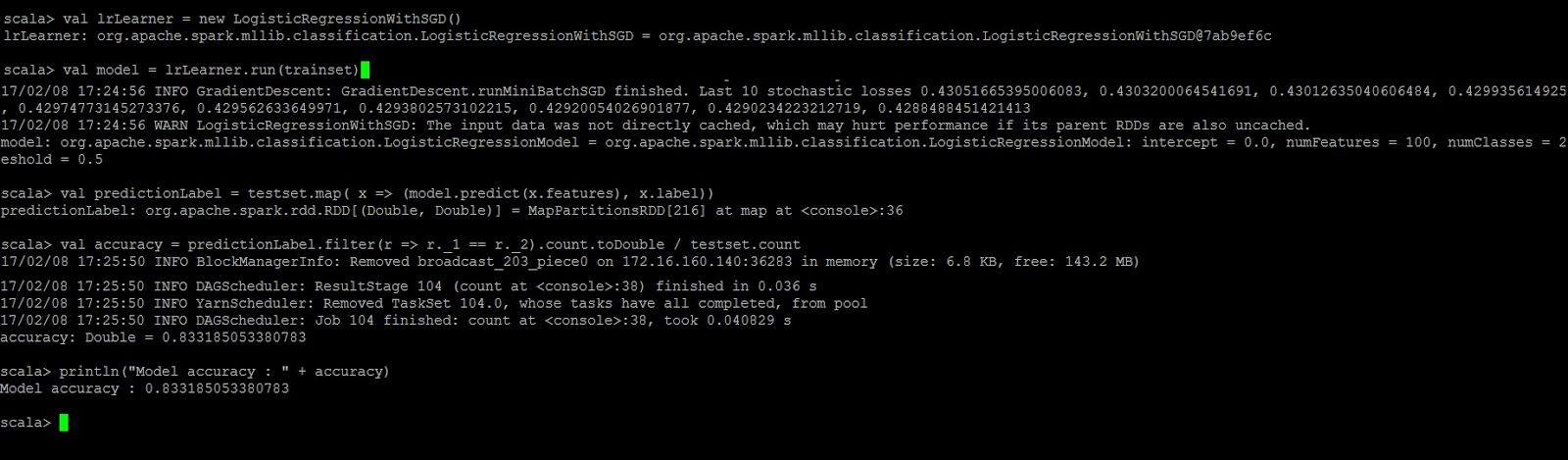
Thus, we are able to create and run the model to predict the Spam or Ham.