How To
Summary
Power Systems gain there massive performance with lots a technology this series details many of them.
Objective

Originally, written in 2012 for the DeveloperWorks AIXpert Blog for POWER7 but updated in 2019 for POWER8 and POWER9.
Steps
Before we look further into memory affinity we need to recap on the scheduling of processes and process threads of a multi-threaded process to simultaneous multi-threading (SMT) processors like POWER.
- POWER5 and POWER6 had two modes of SMT off (one thread) and on (two threads) - with SMT=on two processes run at the same time (in the same clock cycle) on the CPU-core but using the different logical units inside of the CPU-core (units like the integer maths (there is more than one), floating point maths (there is more than one), compare and branch, instruction fetch etc).
- With POWER7 we have off or SMT=2 and SMT=4. With SMT=4 we get four programs/processes (or four threads of execution) at the same time.
- With POWER8 and POWER9 SMT = 8 is available. The valid modes are the SMT = 1, 2, 4 and 8. SMT=8 further increases the workload throughput and POWER9 made the threads much stronger.
This is a technique that boost performance when there are lots of processes and/or threads to run at the same time - which is fairly typical most larger server commercial workloads. But note:
- If we have only one process per CPU-core to run, SMT=off (some times also called SMT=1) would make the whole CPU-core available and so more efficient = faster in executing.
- If we have only two processes per CPU-core to run, SMT=2 would make the CPU-core split between them - due to the sharing of the logical units you don't get twice the number of instructions executed as occasionally both will want to run using the same units and one has to wait. It very much depends on the instruction mix of the processes, which is impossible to predict but typically with server workloads we see an improvement in the number of instructions executed in the region of 30 to 40%.
- If we have four process per CPU-core to run, SMT=4 would make the CPU-core be shared out between them all - similar to SMT=2 we don't get four times the processing done. With typical server workloads, we see an improvement in the number of instructions executed in the region of 40 to 60%. This SMT=4 is only currently available in POWER7 and a significant "internal to the CPU" design improvements have been made to make sure SMT=4 does yield the performance boost - it was not a simple doubling of the threads but adding parallelism to the CPU-core.
Also note that as SMT increases the number of instructions executed by a single thread on the CPU-core goes down but then as we are running more threads the throughput goes up. This is a small tradeoff - the response time of a single transaction may go up a little but then we have many more transactions actually on the CPU and so not waiting long periods (in CPU terms) to actually get our program on to the CPU-core.
In this article, we cover just SMT=1, 2 and 4 mode but the same principals apply to SMT=8
This is summarised in the following graph:
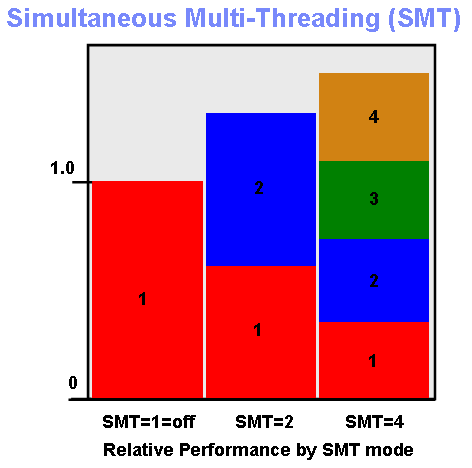
You can read up on SMT elsewhere - this is simply a reminder before we go on.
Logical CPUs
In AIX, each Simultaneous Multi-Thread is called a logical CPU - the AIX kernel can allocate a process or process thread to a Logical CPU. For a lot of the time these are treated as a regular CPU - i.e. for reporting utilisation, the run queue and processes marked as currently running (executing) on a CPU.
In AIX, each Simultaneous Multi-Thread is called a logical CPU - the AIX kernel can allocate a process or process thread to a Logical CPU. For a lot of the time these are treated as a regular CPU - i.e. for reporting utilisation, the run queue and processes marked as currently running (executing) on a CPU.
Intelligent Threading
With the AIX versions that run on POWER7, we had a new processor feature that controls the SMT mode for each CPU-core individually - this means if there is not enough processes for the four or two SMT threads, AIX switches SMT to a lower number for efficiency. If there is only one process available to run on a CPU-core, AIX will, after a very short period, move the process to the first thread and go SMT=1 - so the SMT threads 2, 3 and 4 are not used. If there are just two processes then they will migrate to SMT threads 1 and 2 and we will see threads 3 and 4 unused. We will see this in the following worked example. Us sometimes cynical techies thought this "Intelligent Threading" was just marketing going into over-drive but it turns out there is real technology here and it is good too as we can see it in action! AIX favours for performance:
With the AIX versions that run on POWER7, we had a new processor feature that controls the SMT mode for each CPU-core individually - this means if there is not enough processes for the four or two SMT threads, AIX switches SMT to a lower number for efficiency. If there is only one process available to run on a CPU-core, AIX will, after a very short period, move the process to the first thread and go SMT=1 - so the SMT threads 2, 3 and 4 are not used. If there are just two processes then they will migrate to SMT threads 1 and 2 and we will see threads 3 and 4 unused. We will see this in the following worked example. Us sometimes cynical techies thought this "Intelligent Threading" was just marketing going into over-drive but it turns out there is real technology here and it is good too as we can see it in action! AIX favours for performance:
- SMT=1 on thread 1
- SMT=2 on threads 1 and 2
- SMT=4 on all four threads
Worked Example of Scheduling process threads to CPU threads
So when AIX comes to schedule processes or their threads to CPU-cores it does need to be aware of the SMT based Logical CPUs to make maximum use of the CPU-cores.
So when AIX comes to schedule processes or their threads to CPU-cores it does need to be aware of the SMT based Logical CPUs to make maximum use of the CPU-cores.
For an example, we have a virtual machine (LPAR) with entitlement of 1.5 (Uncapped) and a virtual processor count of 4 and AIX is set to SMT=4 on our POWER7 and above computers so each of these CPU-cores has four SMT threads. Just for the record this is Firmware 730 and AIX 7.1 TL01. As a diagram it would look like the following diagram:
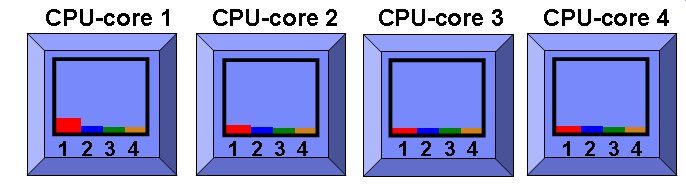
Four CPU-cores (in blue boxes) each with SMT=4 so that is 16 logical CPUs. Note some have a little use as AIX daemons run now and again.
So let us start a busy program that is single threaded to make life easy and we might get the following use:
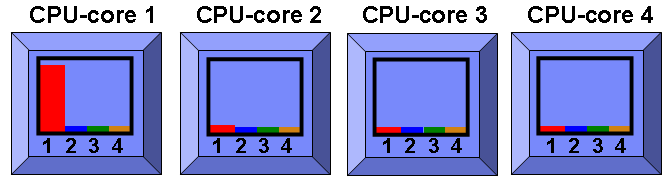
AIX has allocated the process to the first CPU-core and the first SMT thread - in computer terms all the CPU's are equal so it could have chosen any but it does seem to go for the lower CPU numbers first - this is probably just the way the CPU-cores are ordered internally when it searches for the first free CPU-core - it will also be running on the first of the four SMT threads. If you are quick you might see it start elsewhere and get migrated - this is because (as far as I know) the fork() and exec() functions get the process started local to the process that created the program - this is normally the ksh that ran your program. If the program is short lived this makes sense.
In the following diagram, we start a second program that uses roughly a whole CPU:
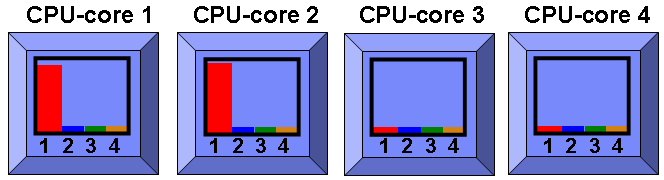
Here we see it went for the 2nd CPU-core and not the second SMT thread of the first CPU-core. Why is this? Well the virtual machine has a virtual processor count of 4 so it can spread out across 4 CPU-cores. If it had gone for the CPU-core 1 2nd SMT thread the two processes would have been sharing the CPU-core. Remember that this means each process would be running slightly slower and they occasionally clash in wanting to both use a particular internal unit. So this would not give us the best performance. We have plenty of CPU-cores available so AIX decides "why not use them for maximum performance and minimum transaction times?"
IN the following diagram it shows something that you will see if you sit and watch a virtual machine running for a minute or two:
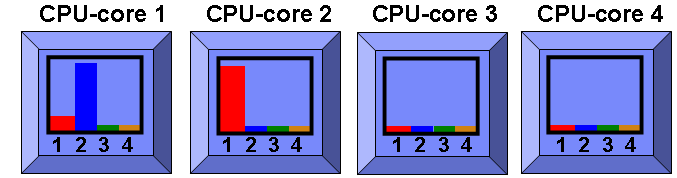
Here the first running program has been bumped to the second SMT thread on CPU-core1. What I think is happening here is that there are roughly 40 AIX daemons running on a regular copy of AIX. If a few of them get to run to do their regular checks or housework then AIX spots we have say three programs all running on the first SMT thread - it will let that happen for a very short time thinking that it might be a very short lived mode as a process might stop. But then it thinks "OK lets go SMT=2 and use two SMT threads to concurrently run these programs as this is cheap - no cache misses as they all share the same L1, L2 and L3 caches.
If the daemons then quickly finish and go to sleep then as in the following diagram AIX decides it is better to go SMT=1 so the single process can have all the CPU so we go back to the previous mode as below:
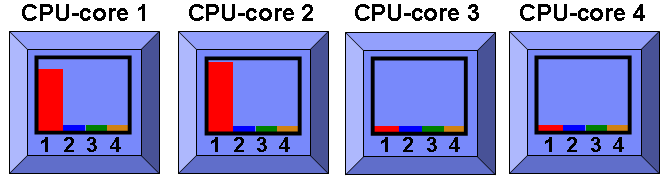
So lets keep adding more "spinning" programs as in the following diagram:
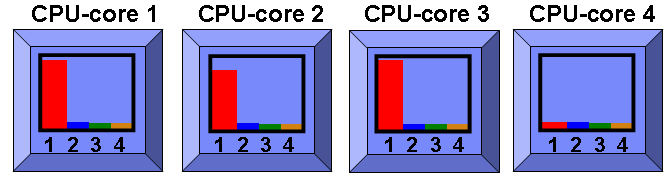
And one more so we have four busy programs:
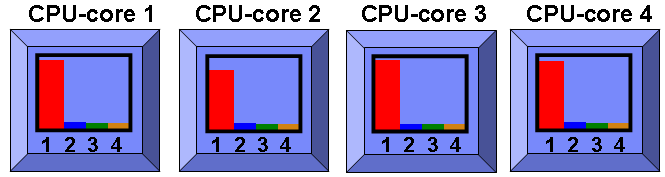
Now let us make a few observations:
- The Entitlement is 1.5 but with just 4 busy programs we are using all four CPU-cores (four as we have virtual processor = 4).
- The four physical CPU-cores are now 100% in use.
- As we have SMT=1 so each program is getting 100% of the CPU-core it is running one.
- If you take the average use of the SMT threads (Logical CPU) this virtual machine looks like it is 25% used - when it is 100% used.
Now let us complicate things by adding one more program as in the following diagram:
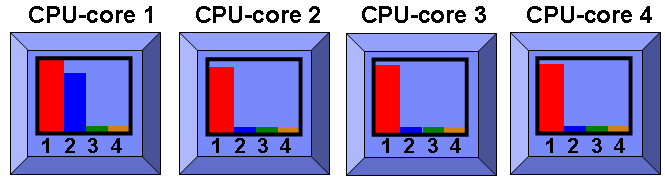
Here 5 programs will not fit neatly on four CPU-cores. So one CPU-core is changed to SMT=2 and runs two programs. You might have guessed this. So we add a sixth program and you get the following:
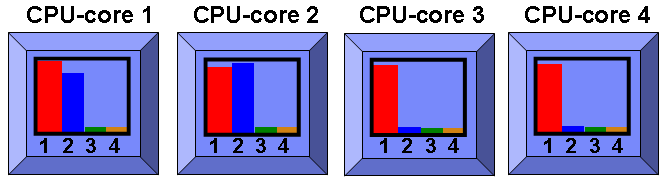
As you expect it now is running two CPU-cores in SMT=2. On these two CPU-cores the individual programs are running slightly slower as they are having to share the CPU-core internal units but they are making much more progress than if they were taking turns running on the processor.
Let now got to eight programs running as we see in te following diagram:
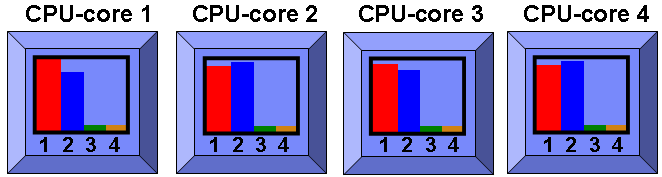
Yes, you guessed it - all CPU-cores are now running SMT=2 and the programs are shared out across all 8 SMT threads.
Now let us make a few observations:
- The Entitlement is 1.5 but with 8 busy programs we are using all four CPU-cores (four as we have virtual processor = 4).
- The four physical CPU-cores are now 100% in use.
- As we have SMT=2 so each program is getting a shared of the CPU-core internal units - not 100%. If you measure performance in transactions per second, web hits per second or batch tasks complete per second - as an example - you might have an SMT boost of 40%. Put another way, we are now doing 140% of the work that we reached when we had just 4 program running. You might like to think that each program is now running on 70% of the CPU-core so the 2 times 70% gives you the 140%. This is just a way of thinking about what is happening as an example.
So let us add one more program as in the following diagram:
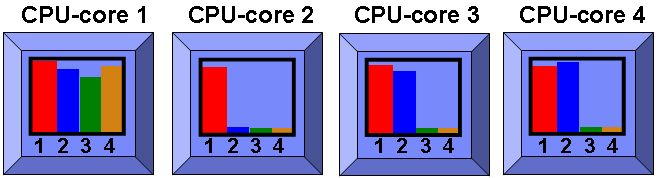
I am pretty sure that one caught you out - I was not expecting it either the first-time :-)
There is no SMT=3 mode. SMT can be 1 (off), 2 and 4. So to run the extra program CPU-core 1 was put into SMT=4 and so two new SMT threads are available. AIX works out that it might as well use both and then puts CPU-core 2 in to SMT=1 as it no longer needs the other SMT thread. We have an interesting configuration here as the virtual machines is running SMT=1 and SMT=2 and SMT=4 on its various CPU-cores - all to maximise efficiency.
There is no SMT=3 mode. SMT can be 1 (off), 2 and 4. So to run the extra program CPU-core 1 was put into SMT=4 and so two new SMT threads are available. AIX works out that it might as well use both and then puts CPU-core 2 in to SMT=1 as it no longer needs the other SMT thread. We have an interesting configuration here as the virtual machines is running SMT=1 and SMT=2 and SMT=4 on its various CPU-cores - all to maximise efficiency.
Adding one more program, see as in the following diagram:

OK, we understand that as CPU-core 2 has gone SMT=1 for the extra program.
Now lets jump to 16 programs:
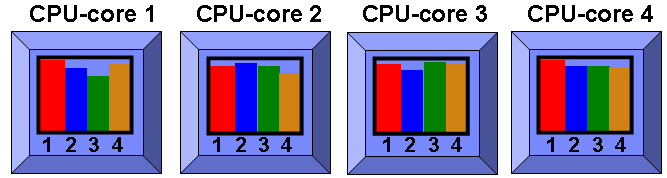
Here all CPU-cores are SMT=4 and there is one program running on each of the 16 SMT thread (also called Logical CPUs).
Now let us make a few observations:
- The Entitlement is 1.5 but with 16+ busy programs we are using all four CPU-cores (four as we have virtual processor = 4).
- The four physical CPU-cores are now 100% in use.
- As we have SMT=4 so each program is getting a share of the CPU-core internal units - not 100%. If you measure performance in transactions per second, web hits per second or batch tasks complete per second - as an example - you might have an SMT boost of 60%. Put another way, we are now doing 160% of the work that we reached when we had just 4 program running. You might like to think that each program is now running on 40% of the CPU-core so the 4 times 40% gives you the 160%. This is just a way of thinking about what is happening as an example.
As we add more programs nothing much changes as we are at the SMT maximum. The run queue gets higher but the programs take turns on the CPU-core.
AIX will try to allocate the same CPU-core every time a program gets execution time - this helps as the memory cache for the program will already have cache lines from the previous time slot on the CPU. Of course, if we go below the 16 runnable programs AIX will migrate programs to other less used CPU-cores to make sure all CPUs are working hard.
AIX will try to allocate the same CPU-core every time a program gets execution time - this helps as the memory cache for the program will already have cache lines from the previous time slot on the CPU. Of course, if we go below the 16 runnable programs AIX will migrate programs to other less used CPU-cores to make sure all CPUs are working hard.
The same happens but you can't see it if say lots of programs one a particular CPU-core stop but it sill has a number to run. AIX will migrate programs so each CPU-core has a similar number of programs to run so that some programs don;t suffer starvation due to being unlucky and on a CPU-core with a long list of programs to work though.
Advanced Points
1) Did you notice that with the 4 programs (processes), 8 programs and 16 programs - in all three cases, all four physical CPU-cores were 100% in use?
In our simple typical scenario example, we got to 100% four physical CPU-cores busy and then went 60% faster just by pushing the CPUs harder with more programs (processes).
This makes for some very interesting discussions about a machine running at 100% busy but still has plenty of headroom for lots more work!
It also causes confusion with the stats from performance tools. Particularly, the Utilisation stats of logical CPUs.
In our simple typical scenario example, we got to 100% four physical CPU-cores busy and then went 60% faster just by pushing the CPUs harder with more programs (processes).
This makes for some very interesting discussions about a machine running at 100% busy but still has plenty of headroom for lots more work!
It also causes confusion with the stats from performance tools. Particularly, the Utilisation stats of logical CPUs.
2) If you want to get the maximum out of your POWER7 or above virtual machine you need to plan to use SMT=4 and for that you need lots of programs simultaneously running. If you don't have enough runnable processes in your virtual machine then SMT=4 can't be used - we can't force a program to run if it is waiting for an external event!! You should be monitoring your run queue compared with the SMT threads available. In intensive workloads, perhaps the run queue should be twice or three times the SMT threads.
3) So what can you do to get to SMT=4?
- There may be application or middle-ware tuning options to use more concurrency?
- Start more programs or arrange over lapping batch tasks.
- This may sound strange but reduce your virtual processor number. This frees up CPU-cores for other virtual machines to use and means your virtual machine will use a higher SMT number.
- May people think that Entitlement is the most important number and you just double the entitlement (or a similar ratio) to work out a virtual processor number. We will point out it is vital to get virtual processor numbers right or lower for efficiency in the next blog.
4) I get many questions trying to compare POWER6 to POWER7 but we have to remember the two processors are very different and gain performance in different ways:
- POWER6 is in order execution and POWER7 is out of order - this is an important internal to the CPU architecture
- POWER7 (4.1 GHz) generally is lower frequencies compared to POWER6 (4.7 GHz) / POWER6+ (5 GHz)
- POWER6 is 2 CPU-cores per chip and POWER7 is 8 CPU-cores per chip
- POWER6 is SMT=2 maximum and POWER7 is SMT=4 maximum and Intelligent Threading
- POWER6 has off chip Level 3 memory cache and POWER7 has on chip Level 3 memory cache - it is larger and shared
- More functions were add wit POWER8 and POWER9 but in a similar manor as POWER7 with larger and faster memory caches and SMT=8.
Monitoring both machines and then asking for explanations for the differences in the stats is largely pointless as they are getting their performance levels in very different ways.
5) I like to make a comparison it to comparing two cars
- car A has a 2.5 Litre engine, 4 cylinders and 4 gears
- car B has a 2.0 Litre engine, 6 cylinders, turbo charger and 5 gears
You find that car B has an engine RPM slightly higher while cruising at 100 MPH and you want an explanation? Well the two cars are generating horse-power in completely different ways.
- Is a higher RPM better or worse?
- Why do you care?
It is better to go back to the performance tuning fundamentals:
- Are users complaining about response times?
- What is the transactions rates or batch run times?Look to the regular tuning options for better performance?
- If you updated AIX perhaps it is worth switching off those historic tuning options that no one can explain and take a fresh look?
- - - The End - - -
Additional Information
Other places to find Nigel Griffiths IBM (retired)
Document Location
Worldwide
[{"Business Unit":{"code":"BU058","label":"IBM Infrastructure w\/TPS"},"Product":{"code":"SWG10","label":"AIX"},"Component":"","Platform":[{"code":"PF002","label":"AIX"}],"Version":"All Versions","Edition":"","Line of Business":{"code":"LOB08","label":"Cognitive Systems"}},{"Business Unit":{"code":"BU054","label":"Systems w\/TPS"},"Product":{"code":"HW1W1","label":"Power -\u003EPowerLinux"},"Component":"","Platform":[{"code":"PF016","label":"Linux"}],"Version":"All Versions","Edition":"","Line of Business":{"code":"","label":""}},{"Business Unit":{"code":"BU058","label":"IBM Infrastructure w\/TPS"},"Product":{"code":"SWG60","label":"IBM i"},"Component":"","Platform":[{"code":"PF012","label":"IBM i"}],"Version":"All Versions","Edition":"","Line of Business":{"code":"LOB57","label":"Power"}}]
Was this topic helpful?
Document Information
Modified date:
13 June 2023
UID
ibm11126083