The objective of capacity planning is to have enough spare capacity to handle any likely increases in workload, and enough buffer capacity to absorb normal workload spikes between planning iterations. Capacity planning helps organizations operate efficiently.
DVM for z/OS can service many Virtual Tables over 35+ different data sources running natively on all versions of z/OS, including z15 for both 32-bit and 64-bit instruction sets. The inherent architecture leverages MapReduce's capability to create parallel threads at the DVM Server level, as well as the client driver for inbound requests.
DVM for z/OS virtualization architecture is zIIP™ eligible and works to help balance processing capacity for specific applications without affecting their total million service units (MSU) rating or machine model designation. When workload is dispatched onto a zIIP™ processor, the processing cycles used do not contribute to the MSU count and therefore do not impact software usage charges. Adding new applications to IBM Z more cost-effective, especially when compared to competing platforms such as distributed systems or public cloud.
IT capacity planning revolves around how an organization can meet the storage, computer hardware, software, and connection infrastructure demands over some time horizon. Organizations require flexibility in scaling resources, typically the Servers, CPU, and Memory.
The DVM for z/OS architecture provides key technologies to facilitate the needs of any organization. One or more DVM Server instances can be leveraged to support the following:
- Offers improved User concurrency
- The ability to distribute workloads
- High availability for when failover or relocation of workloads is required
- High availability for outages related to a hardware problem, network failure, or required maintenance
- zIIP™ eligibility - facilitates cost reduction for production environments and provides more CPU processing availability by delivering up to 99% utilization.
- MapReduce improves elapsed time reduction and overall performance.
- DVM Server memory allows the execution of complex SQL with the benefits of improved response time. Server memory or cache maintains the metadata, as opposed to physical data, to enhance SQL processing.
- Key-based access methods provide direct access to backend data files servicing popular databases running on the mainframe, such as Db2 for z/OS and IMS.
Key capacity planning areas are specific to the physical Server, available storage (both on disk and in memory), Network, Power, and Cooling. Cost drives discussions for new implementations and projected demand and growth. Capacity planning needs to accommodate a balance of workloads involved in the Cloud, external service providers or hosted solutions, and an overall increase in the number of networked devices.
Common workload types
It's commonplace to run wide-ranging workloads (mixtures of batch, transactions, web services, database queries, and updates) that are driven by transaction managers, database systems, web servers, and Message queuing and routing functions.
There are three primary workload types used to evaluate capacity planning. Each workload type has unique impacts on resources with the added independent variable of time.
- Transaction-based workloads - typically small amounts of data processed and transferred per transaction delivered to many users. Interactions between the user and the system are nearly real-time. Mission-critical applications, therefore, require continuous availability, high performance, data protection, and data integrity. Transactions represent ATM transactions such as deposits, withdrawals, inquiries or transfers, supermarket payments with debit or credit cards, and online purchases.
- Web-based workloads - enterprises shift functions and applications to online activity for greater access and improved usability through an application programming interface (API), such as Java™, where they can be written to run under a Java™ virtual machine (JVM). The advantage is that applications become independent of the operating system in use.
- Batch processing - run without user interaction, where the job reads and processes data in bulk, perhaps Terabytes of data, and produces output, such as billing statements. Mainframe systems are equipped with sophisticated job scheduling software that allows data center staff to submit, manage, and track the execution and out-of-batch jobs. Key characteristics are larger amounts of data, that represent many records, run in a predefined batch window, and can consist of the execution of hundreds or thousands of jobs in a pre-established sequence.
- Mixed workloads - consist of a combination of online transactions, web-based, and batch processing that perform analytic processing, real-time analytics, Machine Learning, and Artificial Intelligence.
As a result, organizations need to monitor their current capacity to establish a baseline and understand future business needs for any capacity needed to scale as the organization grows. z/OS provides the ability for capacity provisioning, workload management, fine-tuning your system for prioritization, scheduling, and resource allocation through WLM, z/OSMF, RMF, and CPM.
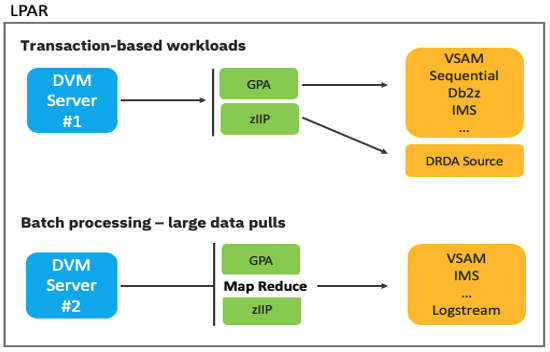
As a mainframe middleware application, the DVM Server also has the ability to fine-tuning based on workload demands. The DVM Server determines the optimal method to access the underlying data for the various workload types.
Figure 1. DVM server manages both transaction and batch processing
Table 1 depicts models based on the current processing volume for any business and the maximum resources are required for the next planning iteration.
| Workload Type |
No. of Servers |
GPA |
zIIP processors |
| Transactional |
1-5 |
16 Gigabytes |
4 |
| Batch processing (large data pulls) |
>5 |
32 Gigabytes |
>5 |
Table 1. Initial recommendations based on workload type
The volume of data within a data source and the type of DML operations against that data are key considerations for assessing capacity planning. DML operations that represent complex JOINs with predicates, GROUP BY clauses, or aggregate functions require more processing to complete.
It is possible to configure multiple JDBC Gateway Servers along with the DVM Server to access distributed (non-mainframe) data to accommodate high transactional processing or reading large volumes of data without negatively impacting latency or server processing. The amount of memory allocated to userspace can be adjusted to better accommodate a larger number of users and overall concurrency.
Monitoring workloads
Workload management is critical in defining, assigning, reporting, monitoring, and managing performance goals. These activities help you understand how many resources, such as CPU and storage, can help meet demands for a given environment. IBM provides foundation tools for monitoring the end-to-end health and capacity of a system or LPAR. These are widely available and likely core to any mainframe environment:
- Tools provided by IBM for capacity planning (monitoring)
- SMF – System Management Facility
- RMF – Resource Monitoring Facility
- CPM - Capacity Provisioning Manager
The DVM Server can virtualize System Management Facility (SMF) records to help monitor the overall current capacity of the DVM Server and manipulate output through standard ANSI SQL syntax. The DVM Server also has an ISPF panel and workload generators to help evaluate the current capacity and performance levels of the DVM Server.
A Command-Line tester utility can also be used to help measure the performance of the DVM Server. This utility can be requested from IBM Support and downloaded for your use. It is not currently included in the DVM for z/OS packaged software or as part of PTF maintenance releases.
Monitoring capacity with SMF records
The SMF data recorded as part of Record type 72 Sub Type 3 provides the actual resource consumption and response time of the DVM server.
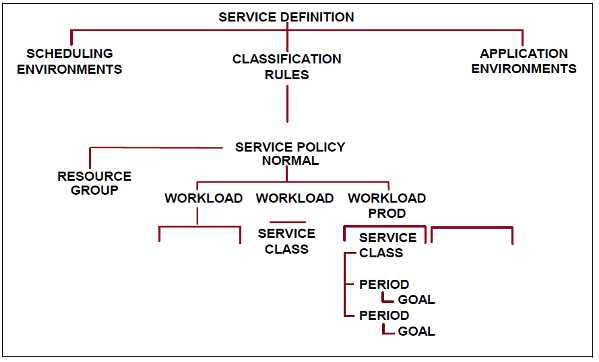
This example illustrates key workload management elements within a Service Definition, including service policy, resource group, workload, service class, service class period number, and goals.
Figure 2. Workload management elements
The workload Manager control section provides SMF output to understand details related to the Service policy, workload, service report, class name, and workload data.
The service Class Served section shows the name of the service classes being served and the number of times the address space runs in the named service class.
The Resource Group section contains information about the resource group to which the service class or tenant report class belongs. The minimum and maximum capacity values for various Resource Groups.
- Percentage of the LPAR share
- Percentage of a single processor capacity
- Memory Limit
- MSU/H
- Combined general purpose and specialty processor consumption
Service/Report Class Period section contains goals and actual measured values for each service and reports class period.
Response Time Distribution section contains response time distribution buckets built around a midpoint that is calculated based on the goal of the associated service class period. The response time distribution count table shows the number of transactions completed as a percentage of the midpoint.\
SMF output from all these sections can be virtualized by creating Virtual Views containing SQL queries. The SMF output helps analyze the capacity requirements in terms of CPU or Storage.
Monitoring performance using SMF Record 249 Subtype 06
DVM SMF 249 provides a more granular output when compared to a standard SMF 30 record. The DVM SMF 249 can state where the CPU is used more specifically and can log each inbound client request in the DVM Server.
Each SMF transaction record contains information about all the work performed on behalf of a requesting client for each transaction. Inbound client requests can trigger zero, one, or more SQL operations to be executed. Many Subtype 06 SMF records can be written in high volume environments because a single SMF record is created for each transaction.
- Detailed CPU time based on Server (client-server request)
- Detailed CPU time based on Server (non-SOAP web request)
- Detailed output on each SQL statement run
- CPU and zIIP details based on each query by combining data from Type 01 and Type 0
AVZ.STORAGE is used to record the private and virtual storage that is used by the DVM Server address space in 15-minute intervals.
| Column |
Description |
| PRODUCT_SUBSYSTEM |
The 4-character DVM subsystem ID |
| INTERVAL_START |
The start time of summary activity |
| MAXIMUM_USERS |
The maximum number of users allowed |
| SUBPOOL |
The name of virtual storage information |
| BELOW_16M |
Amount of memory in use under 16 Megabytes |
| ABOVE_16M |
Amount of memory in use over 16 Megabytes |
| SMFID |
The SMFID as defined within the DVM Server |
Table 2. AVZ.STORAGE definition
Monitoring by using DVM ISPF panels
The DVM server keeps track of a subset of system resources and can be viewed that uses option F.4 on its ISPF interface.
The DVM ISPF interface provides fairly good information on the type of request coming into the DVM Server by tracking the source of these inputs, the time it takes to execute, and so on. This information is useful and helps administrators to understand workloads running on the DVM Server.
Figure 3. DVM ISPF panel
Capacity planning for future growth
Although they aren't exact numbers, mainframe capacity planners find CPU hours, MIPS, and MSUs as good indicators for the ability to hand workloads.
To meet the future needs of the business, organizations need to plan for upgrading z Systems® hardware or for making more enhancements, such as adding zIIP and zAAP specialty processors for cost-beneficial and optimal performance.
Much of the planning for the DVM Server has more to do with configuration and use, rather than entirely on increases in existing or additions of new workloads. To determine the optimal number of servers needed to manage workloads, an iterative approach is recommended, whereby the number of DVM Server instances can require adjusting. The number of DVM servers generally ranges between one and three for a given environment, based upon the workload demands.
Customer Example
A customer needed to validate if their DVM Server could sustain a transactional workload using a JDBC connection to meet sub-second response time objectives. The scenario resulted in configuring each DVM Server to run 300 concurrent threads and by managing the SQL rate per thread up to 4,000 statements per second. The example configuration allowed for the ability to easily scale across multiple servers in their simulated environment.
The example is a simulated workload driven by using a SQL load testing tool, based on the CPU configuration, data (VSAM), and SQL complexity. This example is for reference only and specific to this particular customer environment and set of requirements.
General recommendations
This section details some general recommendations to obtain the best performance for an environment running several DVM Servers focusing on execution time, parallelism, and ability to service concurrency for an active system.
- Allocate 8 or 16 Gigabytes of memory for the DVM Server. Allocate more memory based on the complexity of DML, such as heterogeneous JOINs.
- Workload-based Server definitions (Transactional vs Large Data pulls)
- Group data sources based on the business model
- Choose the appropriate data access modes (multiple access methods are available)
- Write SQL statements whose result set size matches the LPAR configuration
Free capacity in GPA buffer to protect against unexpected workload spikes, server outages, or performance regressions in your code. It is recommended to have more free capacity of 30%.
| Triggers |
Recommendations |
| No. of DVM servers |
- Perform load balancing with WLM over multiple DVM servers that use the same port
- Distribute workloads across multiple DVM servers
- Investigate implementing High Availability that uses VIPA
|
| 8 - 16 Gigabytes of Memory |
- Allows better concurrency
- Allows complex SQL to be better processed
- Allows large data pulls to be processed
- More memory improves query response time
|
| Parallelism |
- Implement Driver or Server-level parallelism
- Configure MRC and MRCC to execute a single request over multiple threads
- Configure the use of Virtual Parallel Data (VPD)
|
| Access Method |
- For 'keyed' data that use Database Control (open thread access is preferred)
- Open Database Access (ODBA) for concurrent access to data
- Use IMS direct or DB2 direct for read-only access to bypass related subsystems
- Distributed Relational Database Architecture™ (DRDA)
|
| General processors |
- Recommend a minimum of 2 General processors for an initial configuration |
| zIIP specialty engines |
- Improves latency and transition of GP processing to zIIP processors |
Table 3. General recommendations for performance for capacity planning
Scaling for growth with the DVM server
The DVM Server is confirmed to support > 1,000 tables through internal testing without any impact to local processing or memory and successfully tested up to 15,000 Virtual Tables. The architecture is designed to perform well for environments with many Virtual Tables.
DVM for z/OS supports IBM Parallel Sysplex, which is a cluster of IBM mainframes that act together as a single system image. Sysplex is often used for disaster recovery and combines data sharing and parallel computing to allow a cluster of up to 32 systems to share a workload for high performance and High Availability.
Specific usage for IMSplex is not currently supported. IMSplex is a set of IMS systems working together to share resources or message queues (or both) and workload. Basic support exists for ODBA, which is needed to support IMSplex but not currently sufficient for a connection to IMSplex with access to multiple IMS regions.
Database Administrators can stop and start servers as needed for either maintenance or for addressing the need for scalability of workloads. Flexibility also exists for managing across Sysplexes or for use in providing a Highly Available solution.
There is no significant use or accumulation of resources associated with DVM Servers that would require they be restarted routinely or as part of scheduled maintenance.
The DVM for z/OS architecture can start and run multiple DVM Servers concurrently to help address high levels of user concurrency or thread concurrency. The use of multiple DVM servers is easily managed through scripting and can be performed in minutes to help satisfy peak operations or general scalability for business applications.
Memory consumptionIn many cases, it is recommended to add 8 - 16 GB of memory virtual storage per system. Allocating more memory helps to avoid staging data on each participating Z system. Based on a customer's complexity of SQL, JOINs, other types of operations that can be performed in memory, more capacity can be needed depending on current usage.
The number of Virtual Tables (VT) does not degrade performance, but the number of virtual tables joined into a complex SQL can exceed the total memory that is allocated to the SQL Engine. The number of columns, length of columns, data types, and the number of records materialized in physical memory need to be monitored.
The number of SQL statements running concurrently depends upon the memory allocated vs (the size of the result set record, number of records read, number of users, and so on). Writing optimized SQL statements can reduce the workload required for a Z System.
zIIP processing
The DVM server has the ability to run in Service Request Block (SRB) mode, which allows significant portions of workloads to be offloaded onto zIIP processors (in some cases up to 99%). This delivers a low-cost benefit for organizations because they're able to offload workloads onto much more cost-effective specialty engines, in comparison to General Processors.
ZIIP eligibility varies based on the access path to underlying data structures, as well as DVM-specific operations performed on that data. Offload also varies across DBCTL, Java™, and combinations of z/OS Connect, IMS Connect, and IMS-Direct, for example. Each data source has a specific range of zIIP eligibility.
- DBCTL does not provide any zIIP eligibility
- Java™ offers unrestrained zIIP eligibility by using DRDA
- Java™ workloads originating outside of the Z system do not benefit from zIIP eligibility
- z/OS Connect-IMS Connect delivers a portion of zIIP eligibility
- IMS-Direct for larger data pulls to support analytics is fully zIIP eligible (non-TXN environment)
However IMS, operations are General Processor bound for DBCTL, however, subsequent processing of that data executed within the DVM Server (for example, JOINs) has a degree of zIIP-eligibility. Based on experience, approximately 40% of total SQL operations can be offloaded for zIIP processing. Since the calling method (DRDA) is restricted to general processes, the zIIP offload is attributed to DVM instrumented code. This processing is separate and independent of any initial IMS operations.
zIIP-eligible workloads using the IMS-Direct access method to perform large data pulls, the DVM server processes up to 99% of eligible processing when zIIP processors are available on the Z system. Highly transactional workloads running against IMS data perform better using the DBCTL access method.
When new applications are not currently at their full productive state, it is difficult to gauge the overall impact. Adding zIIP processors can alleviate demand on central processors, ad more IMS workloads are added over time.
Using MapReduce for parallelism
DVM for z/OS supports parallel processing and can be configured as per the processing needs of an organization. The DVM Server supports various types of parallel processing like MRC, MRCC, and VPD, both at the driver level and server level. MapReduce does not have the same effectiveness for SQL statements using Order By or Group By clauses.
- Reduction in batch execution time can be achieved through DVM tuning parameters.
- A controlled benchmark performed by IBM demonstrates the effectiveness of the DVM Server for both zIIP processing and parallelism. Both advantages are shown in Table 4, Table 5, and Table 6.
| Row Labels |
Sum of CPU Time (ms) |
Sum of zIIP Time (ms) |
Sum of IICP Time (ms) |
Sum of zIIP NTime (ms) |
% zIIP eligibility |
| DVM1 |
7099.03 |
5609.55 |
1389.58 |
5609.55 |
98.59% |
Table 4. Sample test results for zIIP utilization for virtualized data
Table 5 shows how parallelism allows for maximum utilization of GPA and zIIP, providing organizations with the best use of existing resources for persisted data with no changes to application or environment. It is not uncommon to see improvements up to 1,000% depending upon the number of zIIP engines allocated.
- Test cases 4 and 2 have similar configurations
- The degree of parallelism of 8 reduces the overall elapsed time from 89.68 minutes to 17 minutes
- Adding three more zIIP specialty engines shown in Test Cast #8 reduces elapsed time to 13.82 minutes. This is an 85% improvement in query execution time.
| Test Case |
GPP |
No. of zIIP Engines |
Degree of Parallelism |
Elapsed time in minutes |
SMT |
| 1 |
8 |
8 |
8 |
118.96 |
1 |
| 2 |
8 |
5 |
0 |
98.68 |
1 |
| 3 |
8 |
5 |
4 |
27.05 |
1 |
| 4 |
8 |
5 |
8 |
17.14 |
1 |
| 5 |
8 |
5 |
8 |
20.84 |
2 |
| 6 |
8 |
5 |
10 |
17.00 |
2 |
| 7 |
8 |
5 |
16 |
15.73 |
2 |
| 8 |
8 |
8 |
8 |
13.83 |
1 |
| 8 |
8 |
8 |
8 |
17.62 |
2 |
| 10 |
8 |
8 |
16 |
11.72 |
2 |
Table 5. The impact of parallelism on the elapsed time
Performance differences by access method
DVM for z/OS supports various types of access methods when connecting to target data sources and organizations can choose the appropriate access method based on transactional needs.
If a full load of Db2z is required, it can be better to assess the ability to perform a Db2-direct read, which gives both benefits in terms of speed (elapsed time) and zIIP utilization, as it is SRB enabled. Following are some sample timings based on IUD operations that use the Integrated Data Facility (IDF) access method with DVM. Table 6 illustrates some variation regarding access methods to mainframe and non-mainframe data sources.
| Access |
Insert |
Update |
Delete |
| IMS (DBCTL) |
99.93443898 |
99.3218316 |
99.21321732 |
| IMS (OTT) |
99.95473499 |
99.3764378 |
99.36438997 |
| IMS Direct |
99.87326988 |
99.8436479 |
99.99232788 |
| DB2 pass-through |
99.32632198 |
99.3476346 |
99.38136378 |
| DB2 Direct |
99.73467337 |
99.6431871 |
99.67346731 |
| VSAM |
84.62641988 |
77.337337 |
81.2397289 |
| Jgate - Oracle |
97.83463378 |
97.2623789 |
97.32113628 |
Tables 6. Sample access methods and performance impacts with the same degree of parallelism, GPA, and zIIP resources
Workload Balancing
Inbound connections are automatically directed to the DVM Server instance that has the most available resources. To determine which instance handles a request, the DVM Server evaluates the number of connections currently being handled by each instance, as well as the availability of virtual storage (over and under the 16-MB line).
Load balancing is transparent to the client application. An application uses a port number to connect to an instance, and the instance determines whether it or a separate instance is better equipped to handle the session. If another instance is a better choice, the session is transferred.
Best practices for deploying the DVM server
After a successful proof of concept, the next phase involves identifying a Test and Development environment where you can realize the power of DVM. From a data virtualization architecture standpoint, using DVM requires knowledge of the data sources, data format, and access method to virtualize data on disk. The following are building blocks for progressing your idea to productive use in your organization:
- Access to the data sources
- Access to copybooks
- Naming conventions
- Test data
You should make a list of all the data sources you need to fulfill the requirement. There is a chapter in this Redbook focused on performing a Project Survey. This survey approach is a good way to ensure that you are thinking through all aspects of data virtualization. Once you have a list of data sources, make certain you have read and write access to the data. For data sources that don't have their own metadata, like flat files or VSAM files, you will need a copybook to map the data. These copybooks are always stored in separate libraries and you need access to these libraries. Read access is enough to get started.
Another important topic involves establishing naming conventions for the objects you are going to create. Take into consideration that there are likely objects in several different environments with like-named data sources and schema. You need to be able to distinguish which environment each object belongs to. Also, naming conventions are important when migrating objects into a production environment. The application developers may provide standards and conventions for their particular business applications.
You will need enough test data for development purposes that balances out production-like samples for the amount and variety of data that applications perform SQL operations on. Ensure that the data used is of high accuracy. Many times, it is possible to obtain a subset of masked production data to initially populate your environment. This ensures that your Test environment emulates some key characteristics of your system of record (SOR).
Developing queries
Once you have set up your environment, you can start developing your queries. The DVM server is ANSI SQL-92 compliant. Future releases will iterate toward compliance with ANSI SQL-99. For example, the following query successfully executes using the DVM server:
- SELECT * FroM table LIMIT 10;
But a similar query using the TOP operator is not currently supported by the DVM server:
- SELECT TOP 10 * FROM table;
Creating virtual tables
Virtual tables are the data objects needed to map to existing data. In the case where your data source is Db2 for z/OS, the DVM server will use the Db2 catalog to map the data. In the case where your data source is VSAM or a flat file, a copybook is needed to map the data. Many times System Programmers have knowledge of the copybooks, their layout, and where they map to data on disk. You can find more detail in the Manage and monitor chapter of this Redbook on how to create virtual tables using the DVM Studio or the ISPF interface for DVM.
Combining data from different data sources
The DVM server can combine different data sources into a single data source. Each of the data sources is defined by a Virtual Table that maps to the location and data. By creating a Virtual View, you have the ability to combine individual Virtual Tables into a uniform and fully transformed set of records. This view can be defined by the selected columns and joined by a unique id common to both data sets. Then a query predicate can be applied to the definition of the view to filter or reduce the result sets according to the operators in your structured query language (SQL).
You can select a base Virtual table to include as part of a new Virtual View, and then modify the DDL for the new view to include all other virtual tables. You can also check to validate the DDL syntax before finalizing your new Virtual View.
Creating a query
Once you have created the objects you need (a virtual table, virtual view, or a Db2 table), you can easily create a query from them by using the DVM Studio. The query can be adapted to be less or more restrictive. You can determine which columns and the subset of data are needed for extraction. Nearly all ETL data workflow can be written using SQL syntax for the selection, cleansing, and curation of data. In many ways, leveraging predefined data models in the form of virtual tables and views will allow for greater sophistication in your design.
Testing
Queries can easily be tested to verify your results beforehand in both the DVM Studio or as part of an existing application. You can test the query directly in the DVM Studio by selecting the query on the panel and press <F5>, or select the query, then right-click and select the option 'Execute SQL'.
Embedding your query in an application
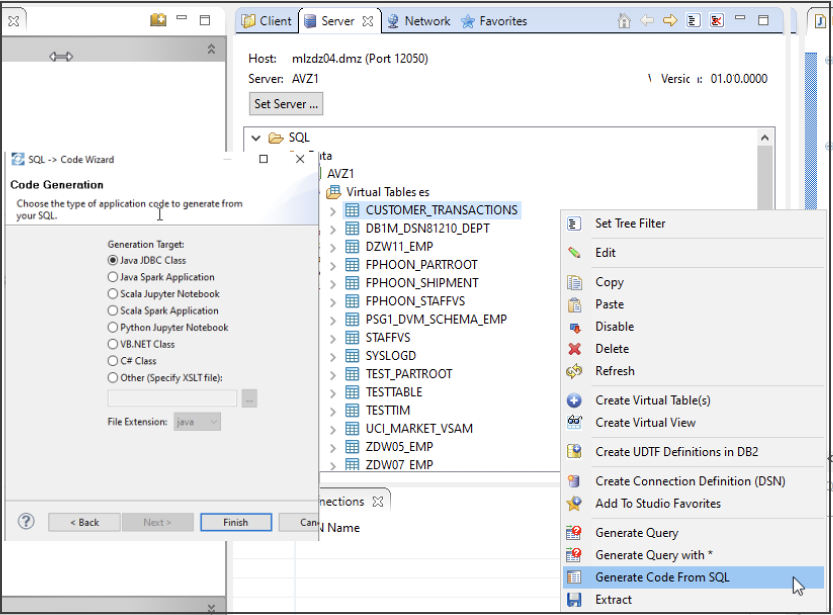
Once your query is ready for a functional test it can be embedded into any application, such as Java. DVM can generate Java code snippets based on your query, which can then be paste into a Java application, compiled, and then run. Right-clicking on the virtual table or virtual view presents the 'Generate Code from SQL' option, as seen in Figure 4.
Figure 4. Generate Code from SQL option
The DVM Studio delivers programmer productivity capability that complements standard development IDEs by allowing you to modify your SQL (mark toggle field 'Compose the SQL field') or generate a select to match any modern programming API of choice. Code can be generated in any of the following modern programming languages showing in Figure 5.
Figure 5. Code generation in the DVM Studio
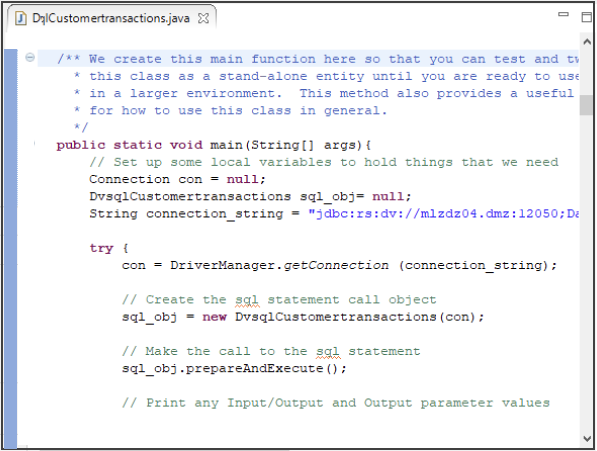
The generated code includes associated object handling, Java classes, the defined SQL statement, and JDBC connection string with user credentials for successful execution. Generated code can be immediately tested in the DVM Studio by putting the cursor anywhere in the Java code and then right-click and select 'Run as' > 'Java application' and the result will be shown in in the Console view in Figure 6.
Figure 6. DVM Studio generated Java code
The quality assurance phase of deployment is to make certain that the solution you want to implement is not going to harm your production environment. It is a necessary step before promoting finished products into production. Deploying applications in the Test environment requires that user(s) have proper credentials and access to data sources and that the required metadata from the DVM server associated with Virtual Tables and Views represent the original data from the Development environment. IF a different user is leveraging this code then that when the Java code was created, the Java code then needs to be generated again using the correct user credentials.
It's recommended that your Test environment mimics your production environment as much as possible. This means the test data should be identical to the production environment, but with data obfuscation or masking as needed, to ensure appropriate data privacy and protection of potentially sensitive data. Moving applications into production is no different than moving an application from Development to Test. However, both DVM administrative tasks and requirements around High Availability are typically critical to the reliability and resiliency of business-critical applications.
Administration of the DVM server in production
A bigger concern for organizations revolves around providing seamless access to underlying mainframe data. However, the DVM server controls access by using RACF (or any other security module you use on IBM Z). The DVM server captures information for each user attempting access to the mainframe data sets and controls access for users attempting to access non-mainframe data sources, as well.
Access to the DVM server should be limited
The client User id accessing the DVM server is like any RACF User id with data access. the main tasks within the DVM server in a production environment are to create and maintain metadata for production data sources (by a DBA), as well as perform ongoing monitoring of the IBM Z system (System Programmer).
High Availability configurations
When you are running a parallel Sysplex in your production environment on IBM Z, usually with Db2 for z/OS in Data Sharing mode, you need to adapt your installation to accommodate the complexities for multiple DVM servers (within and across LPARs), shared resources, and DVIPA connections.
- Multiple DVM server instances
Each LPAR within your Parallel Sysplex may need to have an active DVM server because individual servers cannot connect to other servers without additional configuration. Each DVM server needs to be connected to the local Db2 subsystem, for example, if you use Db2 for z/OS.
- Shared resources
All resources required by the DVM server (data sources, copybooks, configuration files, and metadata catalogs) need to be on a shared DASD. This way, all the DVM servers within your Parallel Sysplex can use the same information.
- WLM and DVIPA connections
In a production environment, it is recommended to connect your DVM server(s) to the workload balancer you are using (for example, Workload Manager) and enable DVIPA connections to each of your DVM servers. This will allow WLM to balance the workload between the servers in your Sysplex. It also allows the workflow to continue uninterrupted in the case the servers in your Sysplex go down, or a complete LPAR goes off-line for any reason.
[{"Type":"SW","Line of Business":{"code":"LOB10","label":"Data and AI"},"Business Unit":{"code":"BU059","label":"IBM Software w\/o TPS"},"Product":{"code":"SS4NKG","label":"IBM Data Virtualization Manager for z\/OS"},"ARM Category":[{"code":"a8m0z000000cxAYAAY","label":"Java Gateway"},{"code":"a8m0z000000cxAOAAY","label":"SQL Engine"}],"Platform":[{"code":"PF035","label":"z\/OS"}],"Version":"All Version(s)"}]