Technical Blog Post
Abstract
Avoiding data modeling issues, part 2
Body
Introduction
In the previous entry, we reviewed the purpose of metadata in a Content Manager context, two different design approaches and the purpose and uses for object stores. With these basics covered, today's entry will review property templates, classes, folders and choice lists.
Properties
Properties are the mechanism by with IBM FileNet Content Manager defines the metadata to be collected about an object. In general, a property defines the data type, cardinality (single- or multi-valued), whether a value is required and more. In the first part of this series, we described how metadata is generally used to help find a document, therefore properties are generally what help define how a document can be found in the system.
Before I get into the details on properties, there is a small bit of my background I would like to share as a preface to this discussion. Back in 2000-2002, I worked for a web content management firm in Bethesda, Maryland called eGrail (which was ultimately acquired by FileNet). One thing I learned from my time there was to, as much as possible, design interfaces with the user in mind. If you make it simple for your end users to understand then they are more likely to use the system. The following recommendations tend to flow out of that principle.
Keep it Simple
One common problem I have seen when working with customers is a general lack of simplicity in the design of their taxonomy model. Or more specifically, the defined model includes a number of properties that make sense from a developer’s prospective, but not from an end user’s. When looking the data model, it is worth asking whether a user will understand what the property is supposed to contain. If it is not obvious what a property is for or why it is necessary, the quality of data provided for that property may be suboptimal.
Descriptive Property Names
A second issue to keep in mind when building a data model in Content Manager is that often the first help end users will see are the names given properties. This is especially true of Workplace and Workplace XT deployments. While confusing property names can be overcome with proper training or documentation, it is likely better to simply select a more descriptive name for the properties to begin with.
Properties Describe a Document
Another issue that I have seen when working with customers is a tendency to try and copy all possible fields from the document itself into the metadata for the object. While there may be very good reasons for doing so in a specific application, it is as likely that rekeying large amounts of document information into metadata may not be useful. For example, in the case of a customer document, the metadata model could very well include not just the customer identifying number, but may also include first name, last name, address, etc. In this case, there are two questions worth asking: will a document really be searched for by customer name and how will any customer name changes be handled.
Much of the time, the search will be based on an customer number or account number. I would also suspect that the customer name to customer ID number is stored in a separate system that can be treated as system of record. If that is the case, then why not rely on that system to maintain the current (and maybe history) information for cross reference purposes. The front end application could then query this system or service for the customer number, then turn to Content Manager to retrieve the required documents. There is an additional layer of capability available in Content Manager to help in the above situation, but that will be covered later in this series.
More Properties == More “Whitespace”
One additional problem with too many properties or an unclear taxonomy scheme is what a coworker of mine calls the “whitespace” problem. Look at the two theoretical classes below. One has two required properties (plus Document Title) and the other has nine non-required properties. What can happen in this case is instead of entering metadata for the nine properties, a user could check in the document with no metadata. However, with the second class where there are two well defined required properties, an end user must enter values for those properties before committing the document.
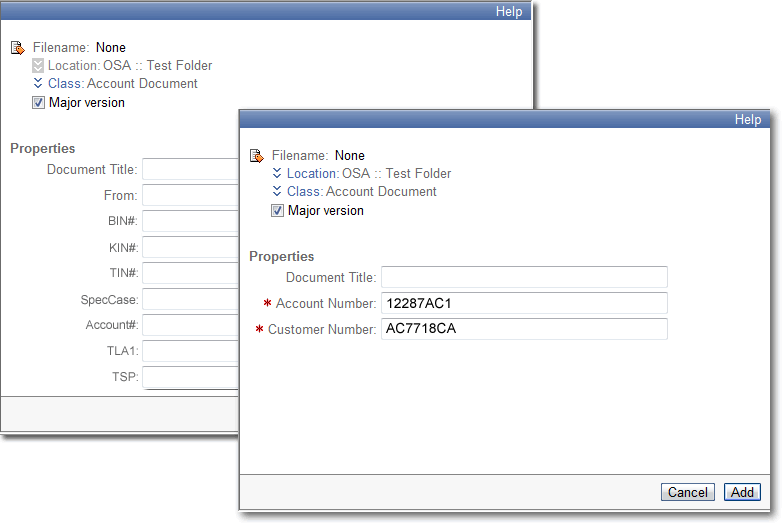
I have personally worked with a system that had this kind of structure. The default class had about fourteen properties, none of which made any sense. Since this system was also using foldering to help find the documents, when I checked in a document, I never entered any properties. In the end, the system was useable because we built a folder structure that worked, but the properties were wasted because none of us ever used them.
Classes
Once the properties have been defined, the type of documents or content to be stored need to be defined. In Content Manager, that structure is defined through classes. In the same way that a Java class defines the properties and methods, a Content Manager class defines the properties collected, how a document’s content is stored and the content lifecycle.
When creating classes, there are two basic organizational methods that can be used. Classes can be created along organizational/functional lines or by content types. Organizational grouping works by defining classes by business unit, geographical region or any other organizational group that works. Content-based classes help organize document based on their type, such as presentations, meeting notes, report, etc. Just like the top down, bottom up discussion in part one, the appropriate way of creating classes varies by organization and business driver. Neither one is necessarily better than the other, and which is appropriate may be driven by business or technical requirements.
Regardless of the approach selected, there are a number of guidelines to keep in mind:
Object Oriented Design Principles
The basic deign of the Content Engine is object oriented and allows for application of OO-based design principles of reuse, sharing and sub-classing. In the same way a Java application could have a base class and subclasses that further define the behavior, a Content Engine class can be sub-classed, with the subclass inheriting the properties of the parent.
In a top-down based metadata structure, this would allow the common properties to be placed on the base, or parent class and then each organization to add subclasses to further define the structure and customize to the specific requirements. Furthermore, the Content Engine allows for searching across classes by searching on the parent class. For example, if the model has two kinds of customer documents that share a parent class of customer document, an application or stored search can find both kinds of documents by searching the parent customer class.
Share Properties
Even if it is not possible to apply sub-classing to a given data model, it is still possible to share properties across multiple classes. Doing so can still help facilitate cross-class searching. In addition, creating additional property templates and adding them to classes will result in additional columns in the object store database. From a performance aspect, sharing properties also helps because adding an index to a single column will then speed retrievals for multiple classes.
Another advantage to sharing properties can be consistency. If every class uses the same property for first name, last name or identifier, then end users will come to understand this and be able to move from line of business or class to class with little retraining.
Default instance security
While not technically a part of the object model, security is an important consideration in designing a Content Manager system. Content Manager affords an enterprise quite a bit of flexibility in securing content. However, a good starting point for many systems is a class’s default instance security. This defines the default security for all new instances of a document or object and can provide a simple way to ensure that documents committed are properly secured. Default Instance Security works by copying the ACL defined on the class’s default instance security tab, replacing #CREATOR-OWNER with the user creating the object and then using that ACL on the new document.
Folders
Another element of a Content Manager data model can be folders. In Content Manager, folders offer a way of grouping like documents together in a single, retrievable container. As a general rule, folders are useful for smaller, browsable datasets. Browsable datasets could include office documents or any set of documents that naturally lend themselves to one grouping. Workplace, Workplace XT and FileNet Integration for Microsoft Office make it easy to apply this kind of structure.
However, if folders are improperly used, it can have a performance impact when browsing or retrieving objects. In addition, foldering is not a substitute for proper metadata and searching for a large dataset. The reasons are two fold:
- If the dataset in an application is greater than a couple of hundred items, end users will not be browsing for the document, as it is too cumbersome. Instead, it would be better to enable the users to search for the document(s) necessary
- If the number of items in a given folder reaches a high enough number (sometimes as little as 50), Workplace and Workplace XT requires the user to page through the list. This means increasing the number of clicks or adding time to finding the document(s) desired.
If folders are deemed necessary, there are a small number of recommendations to keep in mind:
- Limit the number folders or items at a given level to between 20 and generally no more than a couple hundred
- Ensure the structure is self-explanatory. If the users are not sure what the structure is ad what it means, the end result could be lost documents and confusion.
- Ensure the structure works for the organization as a whole
Part 3 of this series will look further into alternate or additional ways of storing and applying metadata to help meet these challenges.
UID
ibm11281880