Technical Blog Post
Abstract
50 DB2 Nuggets #4 : Tech Tip - Explaining Blocked Transaction on HADR Primary - Brewer's CAP Theorem
Body
There are situations where in a HADR environment, transaction on the Primary are blocked(applications will seem to hang) when the HADR database is in peer state and there is a network event (network congestion/network down or the Primary does not receive ACK from the Standby-Standby log buffer full). This can be explained with the help of Brewer's CAP theorem.
Brewer's CAP Theorem:
Brewer's CAP theorem states that, in a Distributed Computer System, we can guarantee only two of the following simultaneously:
- Consistency (all nodes see the same data at the same time)
- Availability (a guarantee that every request receives a response about whether it was successful or failed)
- Partition tolerance (the system continues to operate despite arbitrary message loss or failure of part of the system)
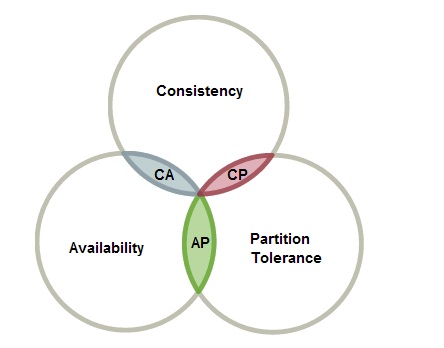
Figure 1. Venn Diagram above shows that there can be only 2 of Consistency(C), Availability (A) or Partition tolerance(P) at a given time
Now putting that in terms of DB2 HADR for a LOGGED OPERATION:
| Consistency (C) | Data is the SAME on Primary and Standby |
| Availability (A) | Clients are ALWAYS able to connect and get a response (i.e no blocking) |
| Partition Tolerance (P) | Network/Communication failure (think of Network Latency or Not receiving an ACK from Standby where required) |
Basically the theorem says that in the presence of a partition event (like a network outage between the 2 HADR nodes) there MUST BE a tradeoff between availability and consistency.
HADR sync modes are the primary dial to control C vs. A tradeoffs:
Sync Modes:
Transaction are committed on the Primary after relevant logs have been written to disk on Primary and:
| Sync Mode | Sync Mode Implication on Standby | Relation to CAP |
| SYNC | logs have been written to disk on Standby as well | Highest C (Data guaranteed on Standby) |
| NEARSYNC | Logs are received into memory on Standby | More C |
| ASYNC | Logs sent to the Standby on the Network (Don't wait for ACK) | More A |
| SUPERASYNC | Don't wait for Standby!! | Highest A (No guarantee) |
In SYNC mode, the total time for a log write = Σ (Primary_Log_Write + Log_Send + Standby_Log_Write + Ack_Message)
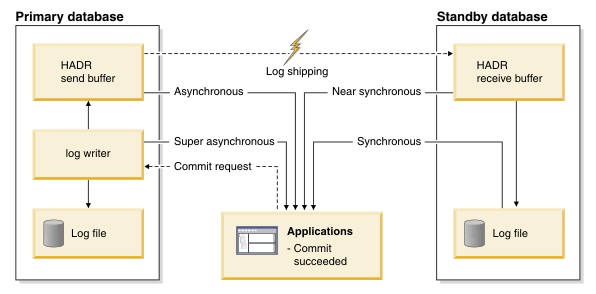
Figure 2: Shows the various sync modes
Further fine tuning C vs A :
Parameters:
| Config Parameter | Config Implication | Relation to CAP |
| HADR_TIMEOUT | How long to wait before considering communication failure. Till we reach this time we are still considered PEER | More C |
| HADR_PEER_WINDOW | In case of communication failure, how long to wait before actually breaking the connection | More C |
| HADR_PEER_WAIT_LIMIT | How long to wait before disconnecting Primary and Standby if transaction are BLOCKED on the Primary | More A |
When both HADR_PEER_WINDOW and HADR_PEER_WAIT_LIMIT are set:
The maximum time before Primary disconnects from Standby = HADR_PEER_WINDOW + HADR_PEER_WAIT_LIMIT
Additional Config Parameters:
| Config Parameter | Parameter Implication |
| DB2_HADR_BUF_SIZE | For increasing the HADR standby log receive buffer size |
| DB2_HADR_SOSNDBUF | Maximizing TCP throughput |
| DB2_HADR_SORCVBUF | Buffering for HADR log shipping |
Higher DB2_HADR_BUF_SIZE and DB2_HADR_SOSNDBUF/DB2_HADR_SORCVBUF implies that there is no P, hence there is C and A.
In situation where we see the Transaction being blocked on the Primary, it is because the HADR setup is in favor of C vs A. For example:
1. Sync Mode = SYNC/NEARSYNC
2. There is a Partition event (standby log buffer full/network failure)
Then we see blocking on Primary i.e no A. In such situations we can tune:
- HADR_PEER_WAIT_LIMIT - (to get AP)
- DB2_HADR_BUF_SIZE - (to get CA)
- DB2_HADR_SOSNDBUF/DB2_HADR_SORCVBUF - (to get CA)
Note: Starting v10.1 we have introduced a new parameter 'HADR_SPOOL_LIMIT'. Log data that is sent by the primary is written, or spooled, to disk on the standby if it falls behind in log replay. The standby can later on read the log data from disk.
Bada Bing Bada Boom!! :)
References:
http://www.cs.berkeley.edu/~brewer/cs262b-2004/PODC-keynote.
http://berb.github.io/diploma-thesis/community/061_challenge.html
[{"Business Unit":{"code":"BU058","label":"IBM Infrastructure w\/TPS"},"Product":{"code":"SSEPGG","label":"Db2 for Linux, UNIX and Windows"},"Component":"","Platform":[{"code":"PF025","label":"Platform Independent"}],"Version":"","Edition":"","Line of Business":{"code":"LOB10","label":"Data and AI"}}]
UID
ibm11141432