Troubleshooting
Problem
Inserts into Hive Partitioned table using the Hive Connector are running slow and eventually failing while writing huge number of records.
Symptom
Job execution would be slow and a new map reduce job would be created for every record that is being inserted into the table.
Cause
Datadirect JDBC Driver for Hive does not yet support batch inserts into a partitioned table.
Environment
Hive Connector in the target context and writing into a partitioned table.
Diagnosing The Problem
Using the Hadoop / Hive admin console, typically ambari console, one can monitor the applications that are getting created for the Hive inserts and notice that every insert is being executed in a separate MapReduce job.
Resolving The Problem
One can use the staging table to insert into the Hive partitioned table.
Please follow the instructions provided below to configure the Hive Connector to write into a partitioned Hive table using the staging table.
1. Set the Enabled Partitioned Write to No in the Hive Connector
2. Provide the staging table in Table name property of the Hive Connector. This will be a temporary table, which is non-partitioned and the data will be loaded into it.
3. Use the Set Hive parameters property to set the following hive parameters
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
4. Use the AfterSQL property to run the SQL in the following format
INSERT INTO <PARTITION_TABLE> PARTITION(<PART_COLUMNS>.....) SELECT COLUMNS FROM <STAGING_TABLE_PROVIDED_IN_TABLE_NAME_PROPERTY>
5. In the select clause, ensure that the partitioned keys are added at the end.
For example, if the partitioning keys are C1, and C2, ensure that the select statement lists all other columns before the partitioning keys as shown below.
INSERT INTO <PARTITION_TABLE> PARTITION(<PART_COLUMNS>) SELECT <NON_PART_COLUMNS>, <PART_COLUMNS> FROM <STAGING_TABLE_PROVIDED_IN_TABLE_NAME_PROPERTY>
Refer to the screenshots below for steps to configure the Connector
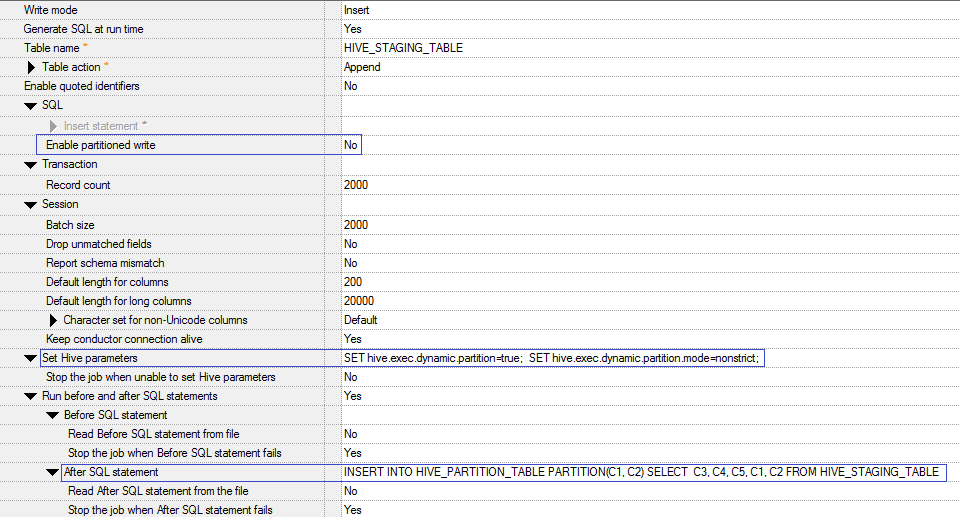
FIG - 2 : Screenshot showing the table definitions along with the partitions

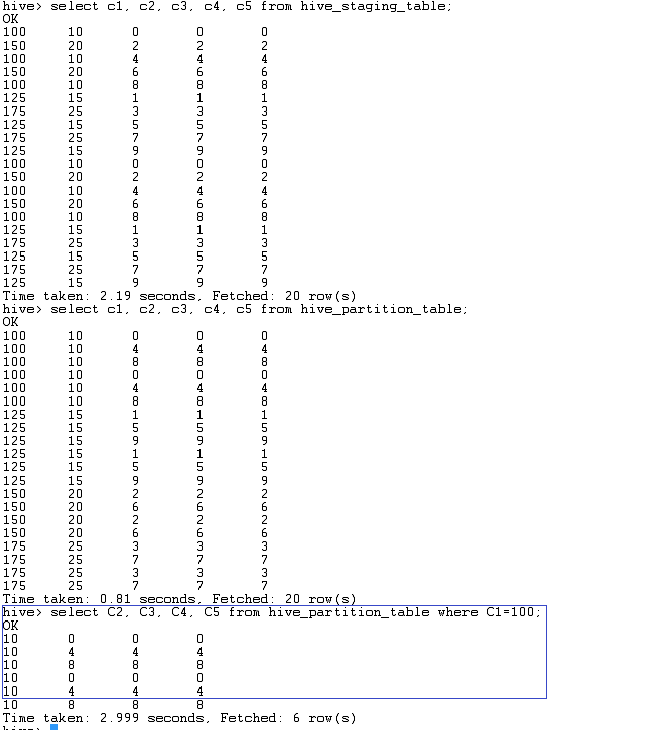
FIG - 3 : Screenshot showing the sample data from the staging as well as the partitioned table
Was this topic helpful?
Document Information
Modified date:
16 June 2018
UID
swg22003058