Environment : BigInsights 4.2
1) Create a queue for Spark from Yarn Queue Manager
Here I am allocating 50% of resources to default queue and rest 50% to Spark Jobs. You can configure the queues based on your use case. You can also create hierarchial queues based on your need.
Login to Ambari UI and go to Yarn Queue Manager

The default queue is configured to use 100% resources. You need to modify the Capacity and Max Capacity to 50%.

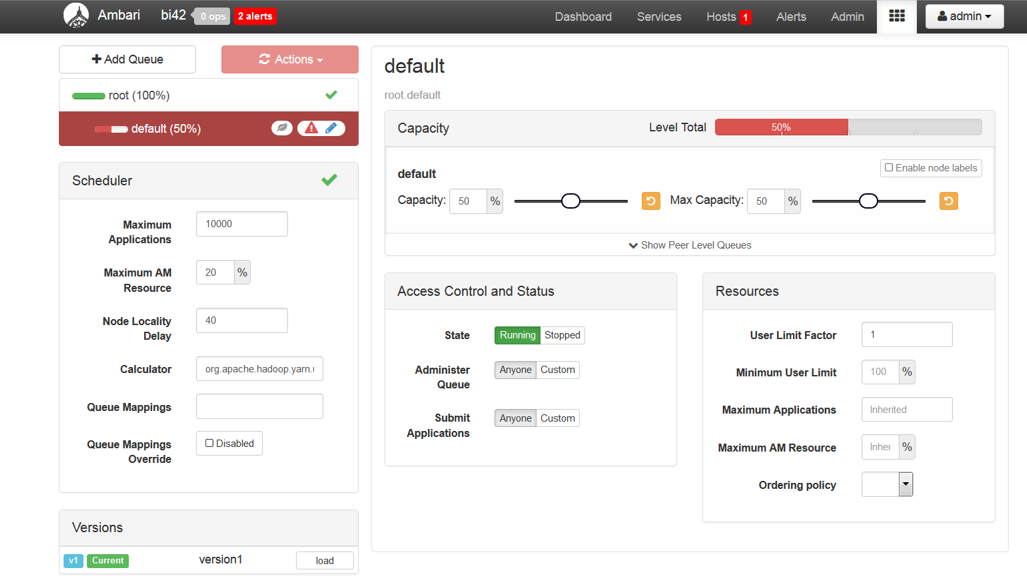
Save the changes by clicking the tick button as shown bellow.
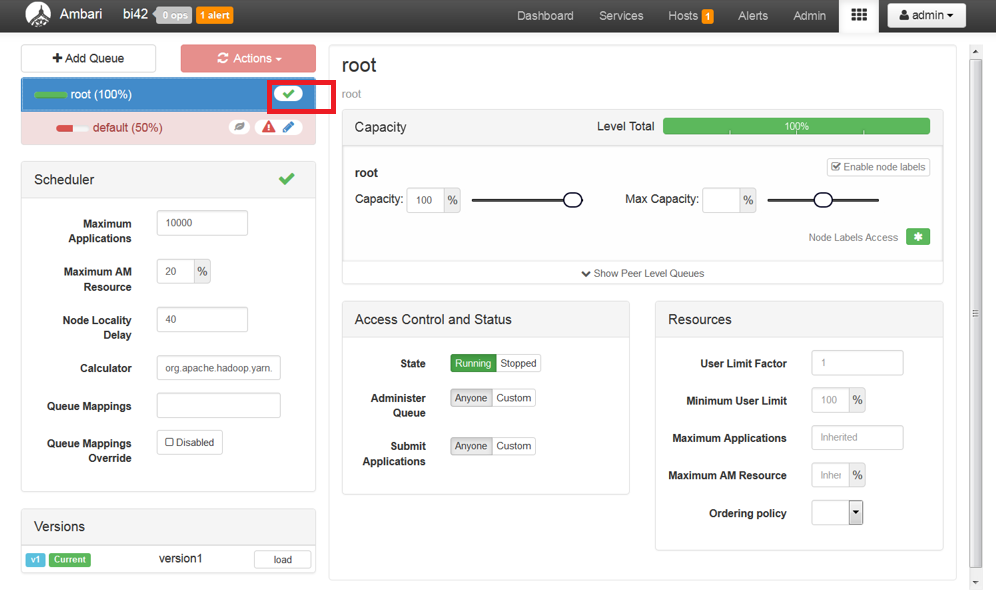
Now, click on +Add Queue button and create a new queue for Spark Jobs.
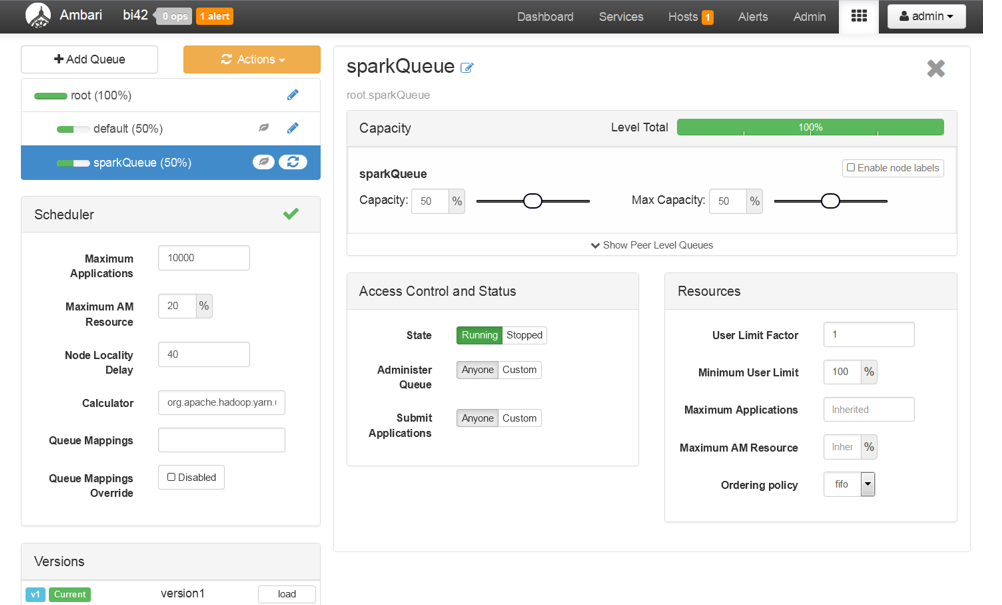
Save and refresh the queues.

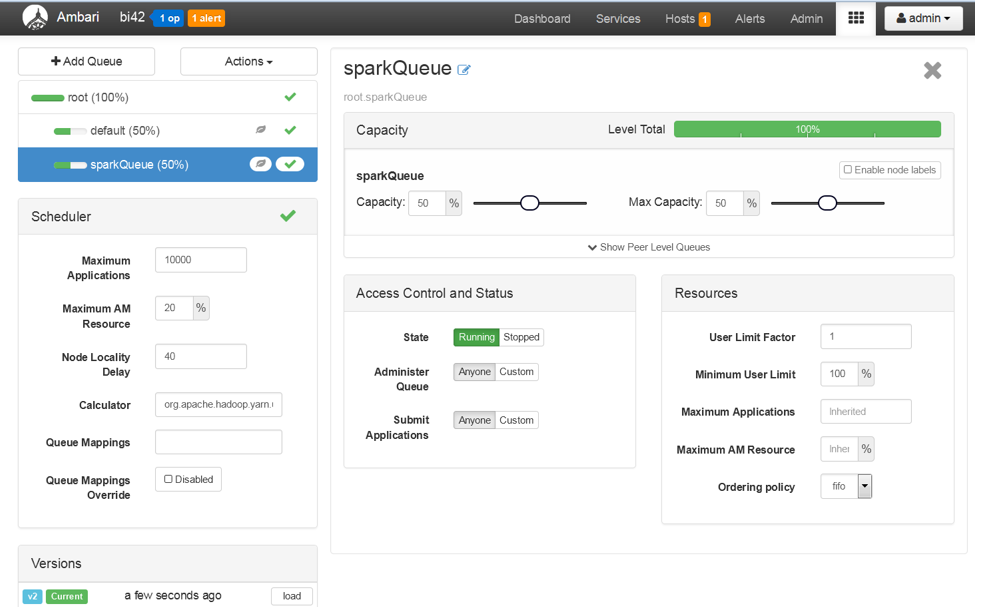
Open the Resource Manager UI and confirm the Queues configured.

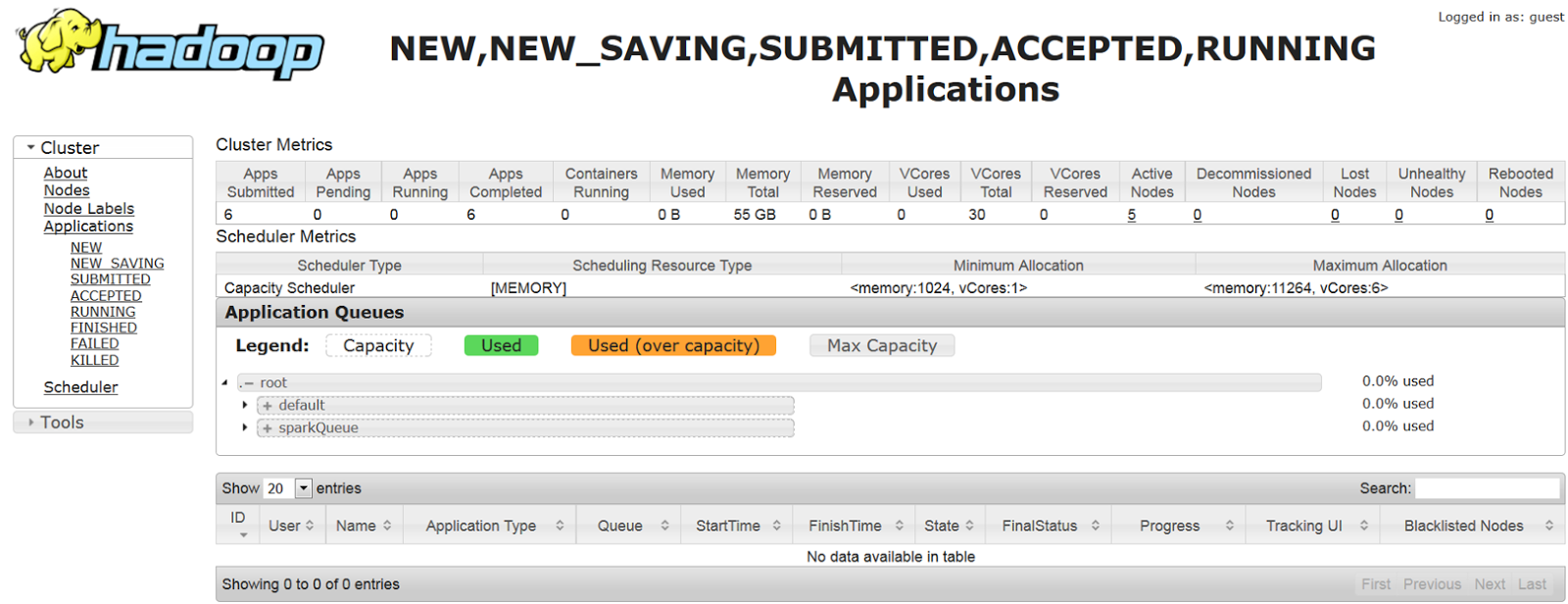
2)Submit a Spark job to the queue
Login to the cluster and submit the job to the spark Queue.

In the Yarn Resource Manager UI, you can see the job is running in the new queue

In the logs, you can see the output from the spark job.

Thus, you are able to run the Spark Jobs in different Queue.