White Papers
Abstract
This paper describes the fundamental architecture of the IBM Data Virtualization Manager for z/OS technology.
Content
IBM Data Virtualization Manager for z/OS (DVM) is the only z-resident data virtualization technology that takes full advantage of the IBM Z platform for secure, scalable access to accurate, on-time data at a moment’s notice.
There are three main reasons why an enterprise would choose to incorporate this technology in their data processing methodology:
- Real-time query - provides real-time access to in-place data
- Optimization - speeds up high-volume data retrieval and leverages zIIP optimization
- Modernization - provides a data service layer for your API economy, such as REST, in order to access native data on Z without application changes
DVM is different from other so-called virtualization or replication tools because there is no need for specialized training or expert database skills. You can work with data structures that use Virtual Tables and Virtual Views that are familiar to you, and provide users and applications read/write access to IBM z/OS and enterprise data sources in real-time.
Virtual, integrated views of data enable organizations to access their mainframe data without having to move, replicate, or transform it-saving time and expense. DVM offers organizations the potential to modernize the way they develop applications and simplify access to an extensive number of traditional non-relational IBM Z data sources. DVM incorporates various interface approaches for accessing data that leverages IBM Z Integrated Information processors (zIIP) to redirects up to 99% of workloads. The amount of zIIP offload activity varies with different types of workloads depending on the data source, access method, and effective SQL operations in use. The DVM server supports IBM-supported hardware ranging from z196 to the latest IBM models, running IBM z/OS v1.13 or later.
The technology supports traditional database applications such as Db2 for z/OS, IMS, IDMS, and ADABAS. Additionally, typical mainframe file systems, such as sequential files, ZFS, VSAM files, log-stream, and SMF can also be accessed. DVM reduces overall mainframe processing usage and costs by redirecting processing otherwise meant for GPPs to zIIPs. DVM provides comprehensive, consumable data that can be readily accessible by any application or business intelligence tooling to address consumer demand and stay ahead of the competition.
Key features:
- Provides a layer of abstraction that shields developers from unique data implementation
- Virtualizes Z and non-Z data sources in place in real-time
- Supports modern APIs, such as JDBC, ODBC, SOAP, and REST (requires z/OS Connect EE)
- Supports MapReduce for faster data access
- Offloads up to 99% of General Processing to lower-cost zIIP specialty engines
- Supports Db2 & IMS Direct for efficient large data retrievals
- Supports data encryption
Technical Components
As with CICS, Db2, and IMS, DVM runs on the z/OS as a started task that stays running to service client requests. As a resident, it acts as a modern data server, providing secure access to mainframe data that use modern APIs, and provides virtual, integrated views of data residing on IBM Z. Users and applications have read/write access to IBM Z data in place, without having to move or replicate the data. It performs these tasks at high speed, without more processing costs. By unlocking IBM Z data that use popular, industry-standard APIs, you save time and money.
Developers can readily combine IBM Z data with other enterprise data sources to gain real-time insight, accelerate deployment of traditional mainframe, and modern mobile applications. Figure 1 provides a logical view of the DVM architecture. Data consumers and providers that interact with DVM are listed on the left side of the diagram. While not an exhaustive representation of all the types of applications, tools, or repositories needing access to data in a relational format, the graphic illustrates the demand for data across all areas of an enterprise.

Figure 1. Data Virtualization Manager for z/OS architecture
These data consumers connect to the DVM Server through APIs that use JDBC, ODBC, DRDA drivers over available network ports. However, the more common web or mobile interface applications connect by using IBM z/OS Connect Enterprise Edition (zCEE) that leverage RESTful APIs.
The right side of the illustration represents common z/OS and non-z/OS data sources, both structured and semi-structured. Once data sets are virtualized, the DVM server supports the joining of supported data sources as referenced to IBM documentation for DVM.
SQL Engine and Query Optimization
The DVM Server, depicted in Figure 1, enables applications to access virtualized enterprise data in real-time by using ANSI 92 / 99 SQL statements.
Query Processing by SQL Engine
DVM enables the user to define any content as a data source to create a virtual table to map to what is stored within the metadata of the DVM Server. When a user executes a database call, the SQL engine reads the mapping and builds a table structure in memory. As a virtual table or virtual view is materialized, the SQL engine analyzes the best access path to fetch data by using proprietary parallelism algorithms that are built into the product. The SQL engine then applies filters and functions against retrieved data for the SQL statement issued.
When a query is received by the SQL engine, the SQL statement is parsed as part of PREPARE processing. During the parsing operation, individual subtables referenced in the query are identified and associated virtual table definitions consulted. For data sources with indexes, the SQL is examined to see whether index key fields are used in the predicate. The use of key fields can reduce the amount of data fetched and can be used to optimize joining data with other virtual tables. If MapReduce is in operation, retrieval of each data is apportioned out to separate threads, and when possible, WHERE predicates are pushed down to MapReduce threads to limit the total amount of data fetched.
WHERE Predicate PUSHDOWN
Predicate PUSHDOWN is a common federation technique that takes advantage of filtering at a data source. Certain parts of SQL queries (the filtering predicates) can be “pushed” to where the data lives. Predicate PUSHDOWN is an optimization technique that can drastically reduce query and processing time by filtering data earlier within data access. Depending on the processing framework, predicate PUSHDOWNs can optimize your query by doing things like filtering data before it is transferred over the network, as part of pre-load into memory, or by skipping the READ of entire files or chunks of files.
Join Processing
When processing joins between two tables, the DVM SQL engine uses previous executions to identify the smaller table and then loads the smaller one into memory, matching the entries from the larger table. Approaching join operations in this manner helps to optimize the use of memory and speeds processing.
Referential Integrity
Referential integrity (RI) is outside the scope of the DVMServer. Non-relational data sources, such as VSAM, do not have a built-in RI layer. RI can be accomplished within the application by validating records before they are written or updated. For deletes, the application needs to address data integrity and references by making sure other identified records exist. Otherwise, databases can support referential integrity between tables. Db2 for z/OS is designed to manage its own referential integrity by using DDL statements to define primary and foreign keys and rules. When these tables are virtualized the DVM Server sends DML statements to the Db2 subsystem for processing when the Db2 Direct-access method is not used. Db2 referential integrity rules are maintained for Insert, Update, and Deletes.
Virtual Parallel Data
Virtual Parallel Data (VPD) is a scalability feature that is built into the DVM runtime. VPD simulates a data cache for the DVM server to access any file or database once so that applications can share or use the file or database simultaneously across highly concurrent client tasks. Figure 2 shows the I/O relationship between the DVM SQL engine and cached data. VPD is perfect for data sets that are frequently accessed but are not dynamically changing throughout the day.
The first query against the VPD will create the group and I/O begins immediately to populate the cache. An initial I/O is performed once and buffered in one or more large, 64-bit memory objects. If there are multiple groups comprising a VPD, they all share the buffered results. Each VPD request can specify its own degree of parallelism using the MapReduceClient (MRC) and MapReduceClientCount (MRCC) configuration parameters with the JDBC driver.

Figure 2. DVM Virtual Parallel Data
VPD also allows multiple requests to run with asymmetrical parallelism, separately tuning the number of I/O threads and the number of client or SQL engine threads. When I/O is limited to a single task, VPD allows parallelism in SQL as shown in Table 1. These results demonstrate how a VPD data cache can greatly improve execution time for SQL over increasing concurrent usage. Instantiating the VPD will enable a readily accessible cache of data and avoid subsequent and concurrent access requests to disk. This reduces the I/O processing for the system, improves latency, and speeds up the query performance. VPD cache can be refreshed daily or as scheduled.
SQL: SELECT * FROM ED_ALL_COLS_PS_CMPSTRP6
Data set: RSTEZST.HLO.DBHLOEXM.UNLOAD.CMPSTRIP.SYSREC
Rows: 14,000,000Bytes: 1,484,000,000
| Test Environment | No. SQL threads | I/O threads | Elapsed Time (sec) |
|---|---|---|---|
| MR=N | 1 | 1 | 25.234 |
| MR=Y | 1 | 6 | 24.488 |
| VPD with MRCC | 6 | 1 | 10.821 |
| MRCC | 6 | 6 | 8.954 |
Table 1. Asymmetrical parallelism
Flatten Arrays
It is common to encounter arrays within a data record (ex: OCCURS clause in COBOL copybook). The DVM Server provides options for how arrays can be processed. Arrays can either be flattened into a fixed-length row or normalized into a main or subtable virtualization table pair.
VSAM data sets can include multiple occurrences of a value. For example, a single record within a VSAM file describing billing information can contain the last years’ worth of payments. A relational structure, would either be represented as two tables within a normalized design or a single table with multiple records representing a single occurrence of each record for one occurrence within the VSAM file.
Metadata Repository
The DVM server maintains a metadata repository, which is a collection of information that describes the data that can be accessed by the DVM server. The DVM server uses all that information to connect to the data source, convert SQL calls into the original data sources access method, and return results to the application.
To access data, you must first virtualize the data as a table by defining a virtual table as a container for all the attributes associated with the data source. When an SQL statement is issued against a VSAM record, for example.
The DVM server retrieves the fields from the metadata repository that represent the data set. The server then converts the SQL into native VSAM I/O calls and returns the data to the requester. This approach allows data to stay in place and enables the structured, unstructured mainframe databases and files to be represented in a relational format. The DVM server establishes an implicit table schema to file formatting.
The DVM server processes data in real-time avoids creating copies of data and supports transactions that write back to the original data sources, whether online or offline, on-premises, or in the cloud. Data is not cached, nor does DVM require a specific API schema, so organizations have flexibility regarding API naming conventions.
DVM catalog tables
All metadata is stored within the DVM server. Metadata is also known as DVM catalog tables. Applications that use DVM’s SQL engine through JDBC or ODBC can use SQL to view this data. You can also transfer (or access) DVM metadata from COBOL, PL/I, MFS maps, and stored procedures into a library or lifecycle management system for optimized use, as shown in Figure 3.

Figure 3. DVM catalog Tables
The following metadata objects are stored as members in the map data set:
- Virtual Tables (VSAM, IMS, Db2, Adabas, IDMS, sequential, and so on)
- Virtual Views
- Application artifacts (IMS DBD, IMS PSB, COBOL copybooks, PL/I structure, and assembler DSECTs)
- Stored Procedures
- Remote target systems
- Virtual source Libraries
- Web services
The metadata repository is stored as members within IBM Z Partitioned data sets (PDSs). Metadata maps are loaded from data set members and cached in memory each time the DVM data server is started. Maps for virtual tables are automatically added to auto-generated system catalog tables, which can be queried through standard SQL. When new data maps are created by using the DVM Studio, or through a batch import utility, each new data map is imported into its respective mapped data set and refreshed in the online catalog cache.
DVM catalog tables can be queried and are valuable for understanding the relationships between entities, which are useful in joining tables.
- SQLENG. TABLES
- SQLENG.COLUMNS
- SQLENG.COLUMPRIVS
- SQLENG.PRIMARYKEYS
- SQLENG.PROCEDURES
- SQLENG.STATISTICS
- SQLENG.TABLEPRIVS
- SQLENG.FOREIGNKEYS
- SQLENG.SPECIALCOLS
- SQLENG.TABLES
Parallel Processing through MapReduce
The DVM server optimizes performance through a multi-threaded z/OS-based runtime engine that uses parallel I/O and MapReduce. With parallel I/O, threads are running in parallel to simultaneously fetch data from the data source and return the result to the client, as depicted in Figure 4. Each interaction initiated by a distributed data consumer or application runs under the control of a separate z/OS thread.
MapReduce significantly reduces the query elapsed time by splitting queries into multiple threads, which run in parallel and aggregate the data into a single result set. DVM reduces the cost and complexity of data movement through data integration with Hadoop, EDW, Cloud, and other distributed sources through SQL calls to join large disparate data sources together for simplified access.

Figure 4. Parallel IO and MapReduce with DVM
As mentioned earlier, the DVM server uses PREDICATE PUSHDOWN and index keys where possible. When joins are used, DVM pushes down the appropriate filters that apply separately to each of the disparate data sources involved in the join.
z/OS-resident Optimization
DVM is a resident of z/OS and because it was written in IBM® Enterprise Metal C for z/OS®, it can be complied to optimize the latest version of the Z hardware it runs on. With each new generation of Z hardware, DVM uses instruction-level performance improvements automatically. Upon starting a DVM task, DVM loads the optimized modules for the generation of the Z processor in service. DVM is purposely designed to reduce Supervisor Calls (SVCs) and provides up to 99% zIIP-eligibility. The DVM server, while not Java-based, runs almost entirely in Enclave SRB mode, where resources used to process transactions can be accounted to the transaction, rather than to the address space in which the transaction runs.
DVM can provide performance benefits in reading large data sets by circumventing Db2 and IMS Subsystems. DVM can access and read the underlying VSAM data sets that are used by IMS and Db2 for z/OS. This reduces the total cost of ownership for the solution and improves performance for bulk-load operations. As a Z-resident software solution, the DVM server provides significant optimizations:
- Dynamic parallelism against large z/OS data sets – Logical partitioning of Flat, VSAM IMS, Db2 Log Streams, Adabas, IDMS, and so on
- Use of Pageable Large Frames for DAT reduction•Use of Single Instruction Multiple Data SIMD
- Use of optimized AIOCB TCP/IP APIs•Use of Shared Memory Objects for inter-process communication significantly reduces data movement
- High-Speed Tracing facility built on Data In Virtual (DIV) services
- An ACEE cache that is tied into ENF 71, which avoid accessing the RACF database and easily keep the cache in sync
- The unique use of zEDC for improvements in network I/O compression
- Prebuilt infrastructure for DVM to CICS interfaces, eliminating 5 out of the 6 API calls required to use EXCI
- Automatically “compiled” DVM REXX to execute REXX as zIIP-eligible and in cross-memory mode (PASN ne SASN ne HASN). However, HLLs provide a minimum opportunity for zIIP eligibility. DVM REXX is representative of this poor zIIP eligibility.
zIIP Eligibility& Data Compression
The IBM Z Systems-Integrated Information Processor (zIIP) shown in Figure 5, is a dedicated specialty processor designed to operate asynchronously with the General Purpose Processor (GPP) on a mainframe system for specific workloads. zIIP processors also help to manage containers and hybrid Cloud interfaces, as well as facilitate system recovery, assist with several types of analytics, and system monitoring.
zIIP engines deliver\low cost, high performance (often greater than the speed of your GPPs), and are generally not fully leveraged. zIIPs can handle specialized workloads, such as large data queries over Db2, Java, and Linux, in order to redirect processing from GPPs. The DVM server automatically detects the presence of zIIP engines and transitions qualifying workloads from the GPP to a zIIP engine. The result is reduced mainframe processing usage and cost.

Figure 5. System Z Integrated Information Processor
Additionally, the DVM server takes full advantage of IBM's zEnterprise Data Compression (zEDC) in z/OS 2.1, along with the Integrated Accelerator for zEnterprise Data Compression. In recent models of IBM Z hardware, data compression is performed by the integrated compression co-processor, which allows sharing large amounts of compressed data with the DVM server, delivering reductions in data transfer latency, improved CPU utilization, and disk space savings.
DVM Studio
The Data Virtualization Manager Studio is an Eclipse-based user interface add-in shipped with the DVM server. It allows both experienced and novice mainframe developers and administrators to readily define virtual tables from non-relational data and allows developers to generate code snippets in a broad range of APIs and interfaces. Figure 6 shows the client connection between the DVM Studio and the DVM Server.

Figure 6. Eclipse-based DVM Studio
The DVM Studio is distributed with a Java Database Connectivity (JDBC) JVM 1.4 or higher. The DVM Studio can connect to the DVM server and use either the JDBC driver to connect to the server or by using an HTTP call. The DVM Studio offers an application development environment that simplifies application development through an automated code generation utility and supports modern programming languages. It provides views, wizards, and editors that allow you to build, develop, and transform mainframe applications into web services and components.
System programmers and DBAs typically collaborate to identify data sets on the mainframe and create schema-related artifacts that describe underlying data as a first step to using the Studio. Once the artifacts are available and properly describe the associated descriptors for data types, column descriptions, and so on, they can be easily mapped and provisioned for use by the DVM Studio.
Once underlying data sets, such as databases, VSAM files, system files, and tapes are discoverable through the DVM Studio, DBAs and Developers can define virtual tables and views for more productive use. Developers can leverage the DVM Studio as a complementary IDE-like framework to their primary source control environments by creating and publishing a web service or generating development code by using SQL. The DVM Studio has a built-in code generator capability that is perfect for creating code snippets in your favorite programming language. The code generator products code snippets in Python, R Studio, Spark, Scala, Java, Jupyter Notebooks, and more. Figure 7 shows the workflow for a DBA or Developer in the DVM Studio.

Figure 7. Publishing a web service by using the DVM Studio
You can generate and publish web services directly from the DVM Studio, or automatically generate Db2 user-defined table functions (UDTFs) as part of a Virtual Data Facility. This technique leverages the Db2 for z/OS subsystem as an Information Hub and redirects applications through Db2 for access to other mainframe and non-mainframe data sources. IBM's Db2 distributed databases offer a built-in data federation engine that uses nicknames or remote tables in a similar manner. Figure 8 illustrates the Virtual Table wizard and SQL editor.

Figure 8. Data Virtualization Manager studio
The DVM Studio is used to define virtual objects, such as virtual source libraries, virtual tables, virtual collections, and virtual views on the host DVM Server. Administrators can easily create Virtual Tables and Views and apply predicates.
- Virtual source libraries exist on the mainframe and point to the information (metadata) required to virtualize the source data
- Virtual tables provide a physical mapping to the data that you want to access from the data source. After the virtual table is defined, use it to generate and execute SQL. The resulting SQL is used to read and extract the mapped data from the mainframe.
- Virtual views can be defined across one or more virtual tables, from which you can generate SQL queries. A virtual view contains the columns from more than one database object within or across homogeneous and heterogeneous data sources.
Integrated DRDA Facility (IDF)
Peer-to-Peer configuration
IDF connects a DVM server to another DVM server to offer seamless access throughout your data ecosystem. IDF enables access to a peer DVM server and a shared view of locally virtualized data objects, like virtual tables and views. IDF provides access advantages by allowing data sources to be accessed by local clients running on a specific z/OS LPAR or participating in a sysplex environment to access data residing on an entirely differently z/OS LPAR or sysplex.
Imagine your organization has a data center in North America and another in Australia, each running IMS, and each having its own inventory databases. In order to reconcile their inventory systems, it would require a manual process. By installing DVM on each LPAR and connecting to each server as illustrated in Figure 9, each data center can view each other’s virtualized data by right-clicking on any of those tables. DVM adds it to the metadata on their server. IDF peer-to-peer makes it look like the data is all local and available no matter where it resides. Instead, you can run SQL to perform join operations, rather than copying the data and writing Cobol or PL/I programs to do the reconciliation.
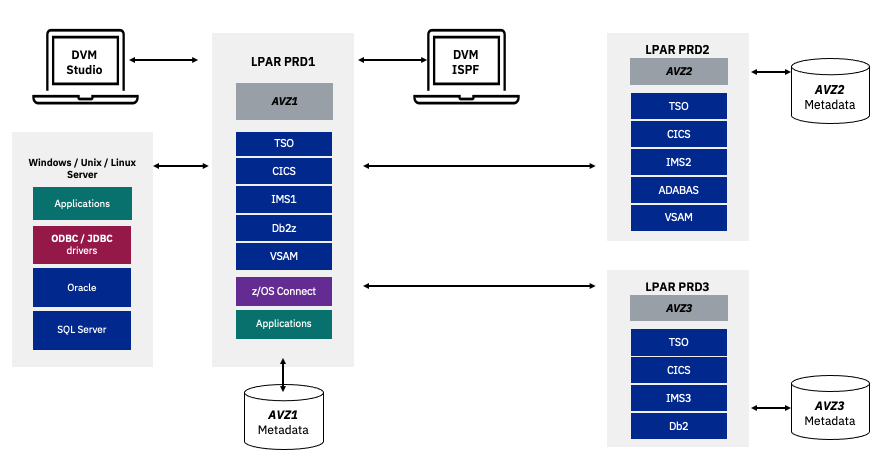
Figure 9. The Data Virtualization Manager studio
Db2 Information Hub
In another scenario, there is a data source on LPAR PRD2, but it’s not on a shared disk or available for access on all your LPARS. Most of the users and applications are running on LPAR PRD1 and have requirements to access the data because they want to join with Db2, which is running on PRD1. Users on either PRD1 or PRD2 can now retrieve data from Db2 and join it with virtualized data on PRD2 by leveraging IDF.
You can also leverage DVM and IDF as a Db2 data hub by connecting DVM and Db2 through the DRDA server, enabling complete data distribution. Distributed requests and access are protocols that involve populating data attributes in the Communication Database housed in the Db2 catalog. Once the Db2 subsystems are configured for a DRDA connection, DVM supports a full-featured implementation where your Db2 applications have transactional access to all participating data sources. IDF uses a three-part naming convention to map to the remote data objects, whereby it identifies data based on location.
Within the same application, you can simultaneously update many different data sources without needing to direct applications individually to each host.
DVM Endpoint Connections
DVM provides a highly flexible connection framework that offers a wide range of client access methods to the DVM Server, as shown in Figure 10.

Figure 10. DVM and endpoint technical view
Drivers
Any C, C++, or Java application can access mainframe data with the DVM SQL engine and its ODBC and JDBC drivers. The communication between the driver and the DVM server is a proprietary communication buffer protocol (CMBU) or communication buffer.
Two ports are dedicated to handling these requests with two different levels of security. The orange connector depicts an SSL-enabled connection method to a port that is configured with a TLS encryption protocol, and the blue connector depicts a non-SSL connection method to an unencrypted port as shown in Figure 11. IBM recommends the use of secure ports. These ODBC and JDBC drivers are also included in the IBM Cloud Pack for Data as part of the built-in connector framework used to define connections with remote data sources.

Figure 11. DVM communication buffer protocol (CMBU)
The ODBC driver can be used to connect many C and C++ applications to the DVM server. There are many programming languages for use with the ODBC protocol, such as Python. Java applications can potentially use the JDBC driver to connect to the DVM server. Certain languages, such as python can make use of our code to connect and execute a request.
DVM Parser and Data Mapping Facility
The DVM Parser is primarily used to parse mainframe source language (COBOL, PL/I, IMS DBD & PSB, Natural) and generate a Data Mapping Facility XML document that describes the logical data mapping to the physical data. The Data Mapping Facility is the component of DVM that is responsible for creating a virtual table and virtual views, as well as defining the metadata (XML document) used for mapping access to the physical data.
The parser is a component of the DVM server and can be invoked through Job Control Language (JCL) batch jobs. A version of the parser is also distributed with the DVM Studio installation (mainly targeting Windows, but potentially Unix, Linux, and Mac platforms). The DVM Studio distributed version of the Parser is typically used to generate an internal XML representation of the source document. It then uses this information through its various wizards to ultimately generate the DVM metadata for the scenario in question (that is, the Cobol copybook layout is transformed into DVM metadata format).
The DVM Studio uses a combination of the Data Mapping Facility (DMF) and the parser to build the definition of virtual tables and views used by DVM, as illustrated in Figure 12.

Figure 12. DVM Parser
The parser is used to read the Source metadata and transform it into the DVM metadata format. Some of the source metadata types that the DVM server can accept are listed in Table 2.
| Data Source | Access Method | Source Metadata | Physical File |
|---|---|---|---|
|
Sequential
VSAM
|
COBOL copybook | PDS data set | |
| Db2 for z/OS |
Pass-thru
Direct
UDTF
|
||
| IMS DB |
DBCTL
ODBA
Direct
|
DBD, PSB | |
| ADABAS | ADABAS FDT | ||
| SMF |
HTML
DSECT
|
Sequential | |
| Syslog | DSECT | Sequential | |
| Slog stream | DSECDT | Sequential |
Table 2. Artifacts required to create Virtual tables by data source
DS-Client API Interface
The DS-Client API interface provides an alternative to connecting your high-level language applications running on z/OS directly to a DVM server. For consumers who don't leverage UDTF’s as part of an IDF usage pattern where Db2 for z/OS is leveraged as an Information or Data Hub..
The DS-Client API supports the ability to connect COBOL, PL/1, and Natural applications to DVM’s virtualized data. The DS-Client requires modifications to both the application and connection configuration for the AVZCLIEN subroutine. A parameter list needs to be added to your application and used with subroutine calls in order to gain access and read/write data in this manner.
- OPEN
- SEND
- RECV
- CLOSE
OPEN creates a session with the DVM server and obtains shared memory used to send the SQL result sets to the application program. The SEND subroutine call is issued following an OPEN subroutine call in order to send the SQL request to the server. A RECV subroutine call is issued to retrieve the SQL results from the shared memory object created during the OPEN subroutine call. Once the data is retrieved, a CLOSE subroutine call can be issued, which terminates the session with the DVM server and releases resources.
z/OS Connect Enterprise Edition
z/OS Connect EE empowers a wide community of developers with a simple and intuitive way to consume data and services on IBM Z through RESTful APIs. The DVM implementation can combine with IBM z/OS Connect EE for an easy-to-use interface in developing REST interfaces that access mainframe data sources, non-mainframe sources like SQL/NoSQL stores, and Big Data technologies, such as Spark and Hadoop. REST interfaces can be developed to combine multiple data sources. Developers don’t see the underlying complexities of the data structures and their locations.
The z/OS Connect server has a DVM WebSphere Optimized Local Adapter (WOLA) service provider, which is an API that allows DVM to communicate, as shown in Figure 13.

Figure 13. z/OS Connect Enterprise Edition (EE) and DVM WebSphere Optimized Local Adapter (WOLA)
Any virtualized data on the mainframe can be accessed through REST calls or through a web browser with the z/OS Connect Enterprise Edition server. The z/OS Connect server is deployed on the mainframe, separate from DVM, and listens to HTTP or HTTPS calls from the browser, or any HTTP clients.
Java Database Connectivity Gateway (JGate)
DVM also includes the JDBC Gateway server (JGate), which is used to connect to distributed databases. It is installed separately on Linux, Unix, Windows, or Unix System Services (USS) systems. In order to access non-standard or non-DRDA-enabled data sources, the JGate server is needed, as shown in Figure 14.
Certain RDBMS vendors require a specific licensing component that would provide a DRDA-compliant data source. The DVM server connects to the JDBC Gateway server that uses a DRDA server. For instance, Oracle connects by way of an Oracle JDBC driver. Once the connection is established, data can be virtualized by using the DVM Studio.

Figure 14. JGate DRDA connectivity
Connection and Port Security
When it comes to deployment, system administrators and system programmers can configure connections and port security. DVM supports Secure Sockets Layer (SSL) and is transparently supported by the Application Transparent Transport Layer Security (AT-TLS), an IBM TCP/IP facility. The DVM Server recognizes and enables SSL connections and sessions automatically. Any port that has a secure connection sends data in an encrypted format. DVM maintains the security and access credentials of the calling user based on the enterprise security manager in use. (RACF, ACF2, Top Secret).
SSL can be used to secure ODBC, JDBC, and HTTP network communications between the DVM Server and the DVM Studio. For HTTP, web services can be defined to support SSL by using the default setting of TLS 1.2.
For role-based authorization, users can access the DVM Server by using AES, DVM domain-based, Microsoft Transaction Server, and Kerberos. The default authentication has a proprietary encryption mechanism when the login request is sent to the Host.
AES uses the Diffie-Hellman key exchange, and domain-based access verifies that the user is authenticated by a domain-based system. Windows platforms require that the user first logs on to an NT domain. For the UNIX platforms, the local machine must be a member of a NIS domain, and the password database used to authenticate the user must be NIS-mapped. Table 3 lists client endpoint characteristics and configuration details.
| Endpoint | Connection Method | Server Configuration Parameter | Secured Login | Security PARM (INOO) |
|---|---|---|---|---|
| DVM JDBC/ODBC driver |
Non-SSL
SSL enabled
|
OEPORTNUMBER (non-encrypted)
OESSLPORTNUMBER, SSL, SSLAUTODETECT, SSLCLIENTAUTH
SSLCLIENTNOCERT, SSLUSERID
|
YES (SAFUID/PWD) |
|
| DVM Eclipse Studio |
HTTP
HTTPS
|
WSOEPORT (non-encrypted)
WSOESSLPORT, SSL, SSLAUTODETECDT, SSLCLIENTAUTH, SSLCLIENTNOCERT, SSLUSERID
|
YES (SAF UID/PWD) |
|
| JGate Server (DVM as Client) |
Non-SSL
SSL enabled
|
DEFINE DATABASE PORT (<port number>) (non-encrypted)
DEFINE DATABASE PORT (<port number> SSL) (encrypted)
|
YES | DRDA SECMEC |
| DRDA (DVM as Client) |
Non-SSL
|
DEFINE DATABASE TYPE (MEMBER/GROUP/ZOSDRDA/ORACLE/MSSQL/QMFDRDA) PORT (<port number>) (non-encrypted) | YES | DRDA SECMEC |
| DRDA (DVM as Client) | SSL enabled | PORT (<port number> SSL) (encrypted) | YES | DRDA SECMEC |
| Integrated DRDA Facility (IDF) |
Non-SSL
SSL enabled
|
IDF
IDFPORT (non-encrypted)
|
YES (SAF UID/PWD) |
SECMEC
|
|
zCEE WOLA DVM
Service Provider
|
Non-SSL
SSL enabled
|
HTTP Port inserver.xml
HTTPS Port in server.xml
|
YES
(UID/PWD) |
Liberty Server.xml httpPort |
| JDBC Gateway DRDA Listener |
Non-SSL
SSL enabled
|
Default configuration
JVM configuration for jsse2.overrideDefaultTLS
JVM configuration for jsse2.overrideDefaultProtocol
|
YES | DRDA SECMEC |
| JDBC Gateway Administrator Console |
Non-SSL
SSL enabled
|
Port in jgate.properties
HTTPS port in jgate.properties
|
YES (UID/PWD) |
Creds stored in an application-managed file with encryption |
Table 3. DVM Endpoint security configuration parameters
Summary
Due to its unique architecture, DVMsupports real-time data virtualization technology that enables seamless access to mainframe relational and non-relational data for use with data analytics, Big Data, mobile, and web solutions.
DVM is the only technology in the market that can be used by any client application program, any loading process, or any mainframe program to read/update/delete any data structure on or off of the mainframe. All underlying data structures are abstracted from the user through these common usage patterns:
- Create virtual and integrated views of data to access mainframe data without having to move, replicate, or transform your source data.
- Enable access, update, and join functions on your mainframe data with other enterprise data with modern APIs in real-time.
- Mask your mainframe data implementations from application developers to safely expose mainframe assets as APIs into mobile and cloud applications. Additionally, developers can use ANSI SQL functions to retrieve any data in Mainframe and LUW environments.
[{"Type":"SW","Line of Business":{"code":"LOB10","label":"Data and AI"},"Business Unit":{"code":"BU059","label":"IBM Software w\/o TPS"},"Product":{"code":"SS4NKG","label":"IBM Data Virtualization Manager for z\/OS"},"ARM Category":[{"code":"a8m0z000000cxAOAAY","label":"SQL Engine"}],"Platform":[{"code":"PF035","label":"z\/OS"}],"Version":"All Version(s)"}]
Product Synonym
DVM
Was this topic helpful?
Document Information
Modified date:
23 June 2021
UID
ibm16447183