连续可用性
无论是计划的系统维护还是极端情况 (例如,当多个组件同时发生故障时) , IBM Db2 pureScale Feature 都旨在不间断地继续处理传入数据库请求。 所有活动 成员 之间的自动负载均衡意味着始终实现最佳资源利用率,这有助于保持应用程序响应时间较低。
计划外事件
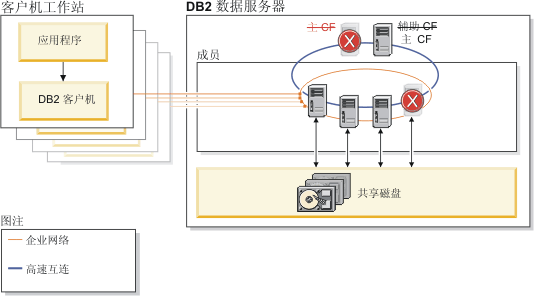
强壮的脉动信号检测确保能够快速确定并隔离发生故障的组件。 从组件故障中进行恢复是完全自动的,不需要进行任何干预。
如果 成员 在处理数据库请求时失败,那么会立即从系统的其余部分对其进行防护。 在故障期间,共享磁盘存储器上的大部分数据仍可供处理数据库请求的活动 成员 使用。 在 Db2 pureScale Feature 完成自动 成员 崩溃恢复之前,只有在发生故障的 成员 上运行的数据暂时由保留锁定持有。
发生软件故障后,将在其原始主机上重新启动 成员 ,并执行恢复。 成员 在恢复完成后立即恢复事务处理。 发生硬件故障后, 成员 将在另一主机 (称为 轻量级重新启动的进程) 上重新启动,以便可以恢复数据。 当其原始主机再次可用时, 成员 将故障恢复到该主机,然后重新启动并恢复处理。
在主 集群高速缓存设施上发生软件或硬件故障后,辅助的双工 集群高速缓存设施 会自动接管主角色。 此接管对应用程序是透明的,并且由于 集群高速缓存工具之间的锁定和高速缓存信息的连续双工,因此仅导致最小延迟。 该实例仍然可用。
计划内事件
Db2 pureScale 环境中的系统维护旨在尽可能减少中断。 您可以在不停止 Db2 pureScale 实例或影响数据库可用性的情况下进行系统升级。
要对 成员执行系统维护,请将其停顿。 在完成 (排出) 成员 上的现有事务后,使 成员 脱机并执行系统维护。 在维护期间,新的事务请求会自动定向到其他活动的 成员,这是一个对应用程序透明的进程。
在完成维护并重新启动 成员后,它将在重新加入实例后立即开始再次处理数据库事务。