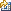IBM® InfoSphere™ DataStage® and QualityStage デザイナー を使用して、ジョブの作成、管理、およびデザインを行います。デザイナー・クライアントは、 表の定義とメタデータ・サービスのアクセスにも使用できます。
多くのソースからの 表定義 (例えば、表定義の 1 つのソースは IBM InfoSphere Information Analyzer からのメタデータです) をインポート、作成、編集できます。 表を編集または表示するときには、図 1で示すように、「表定義」ウィンドウが開きます。
このウィンドウには次のページがあります。
InfoSphere DataStage and QualityStage デザイナー は、 メタデータ・リポジトリーにアクセスして、統合プロジェクトおよび組織のエンタープライズ・データに関する現在のメタデータにリアルタイムにアクセスできるようにします。 デザイナー・クライアントを使用して、メタデータ Bridges または InfoSphere Information Analyzer によって生成されたデータにアクセスします。 メタデータへのアクセス権のあるデザイナーに対して、 以下のようなサービスが提供されます。
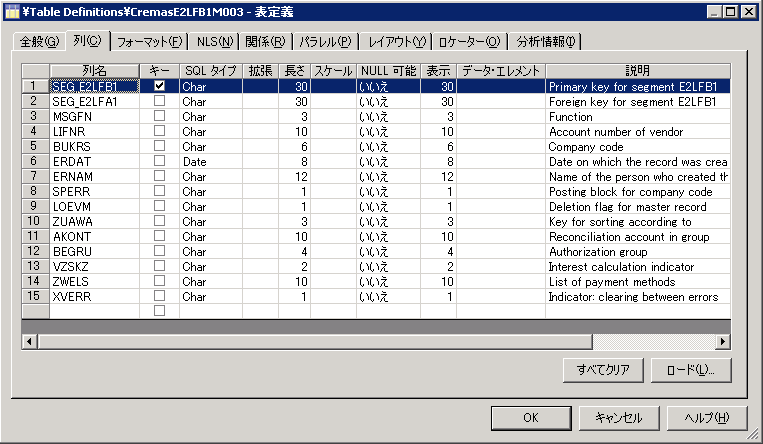
InfoSphere DataStage and QualityStage デザイナー の オプションの 1 つで、InfoSphere DataStage のコンテキスト内での ジョブ間または表定義間の差分を示します。図 2 は、 デザイナー・クライアントの関連エディターへのリンク付きのテキスト・レポートを示します。共有コンテナーやルーチンなどの、ジョブのサブセットの差分も 表示できます。このレポートは、オプションで XML ファイルとして保存することができます。
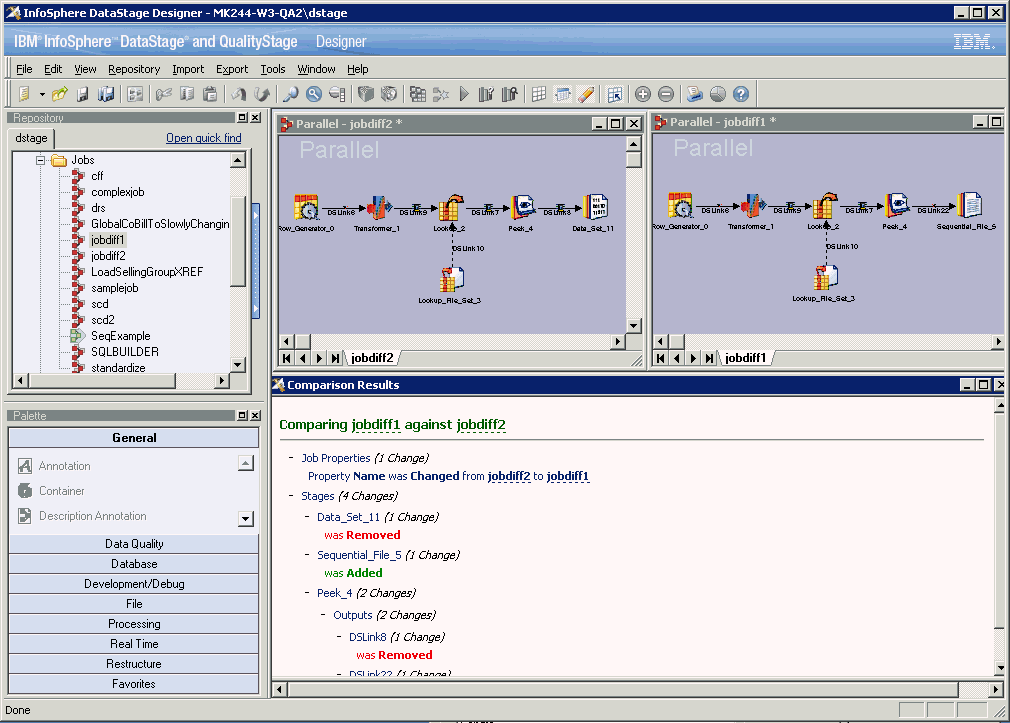
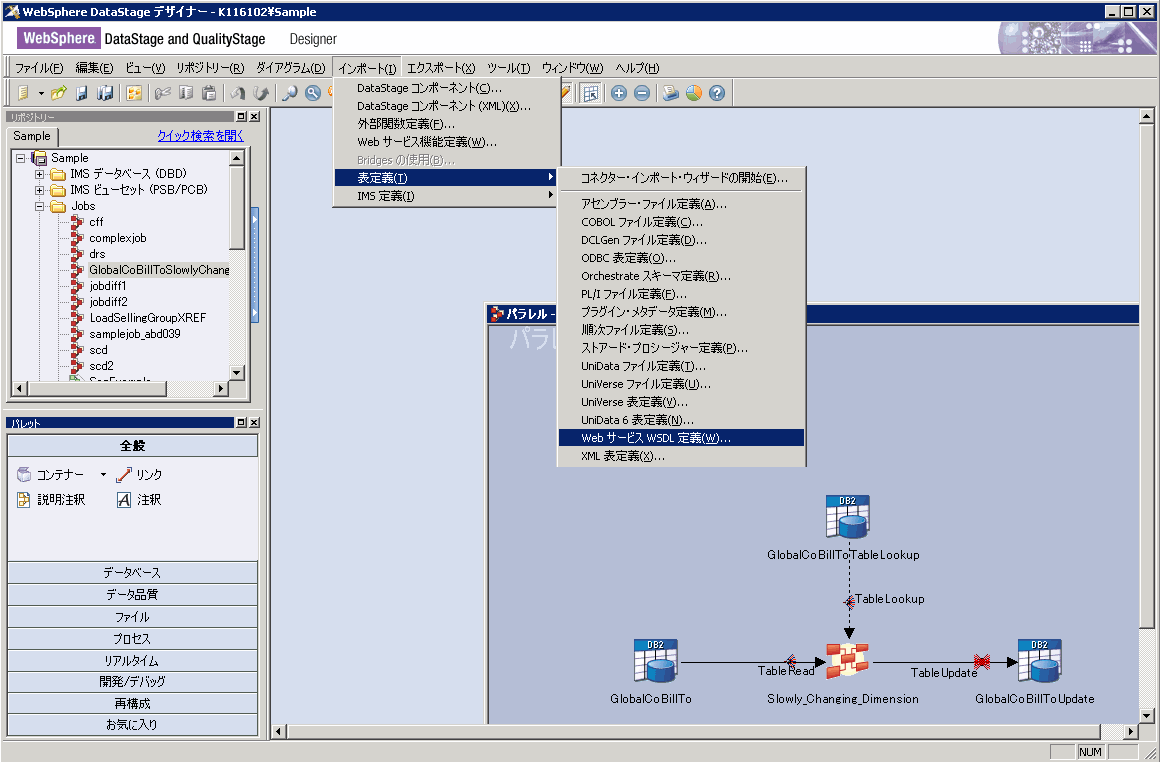
デザイナー・クライアントを使用する場合は、 図 3に示すように、作成するジョブのタイプと、ジョブの作成方法を選択します。
異なるジョブ・タイプには、パラレル、メインフレーム、ジョブ・シーケンスがあります。 ジョブ・テンプレートによって、カスタマイズできる定義済みジョブ・プロパティーを 指定することにより、ジョブを迅速にビルドすることができます。またジョブ・テンプレートは、ジョブとジョブ・デザイナー間で 共通する基本情報も提供します。
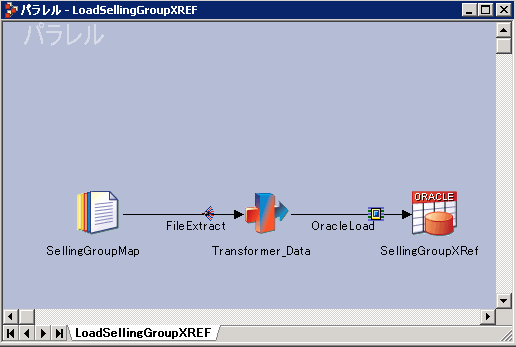
「デザイナー・キャンバス」ウィンドウとツール・パレットを 使用して、図 4で示すようにジョブのデザイン、編集、および保存ができます。
図 4では、次の 3 つのステージが含まれる最も基本的な IBM InfoSphere DataStage ジョブが 示されます。
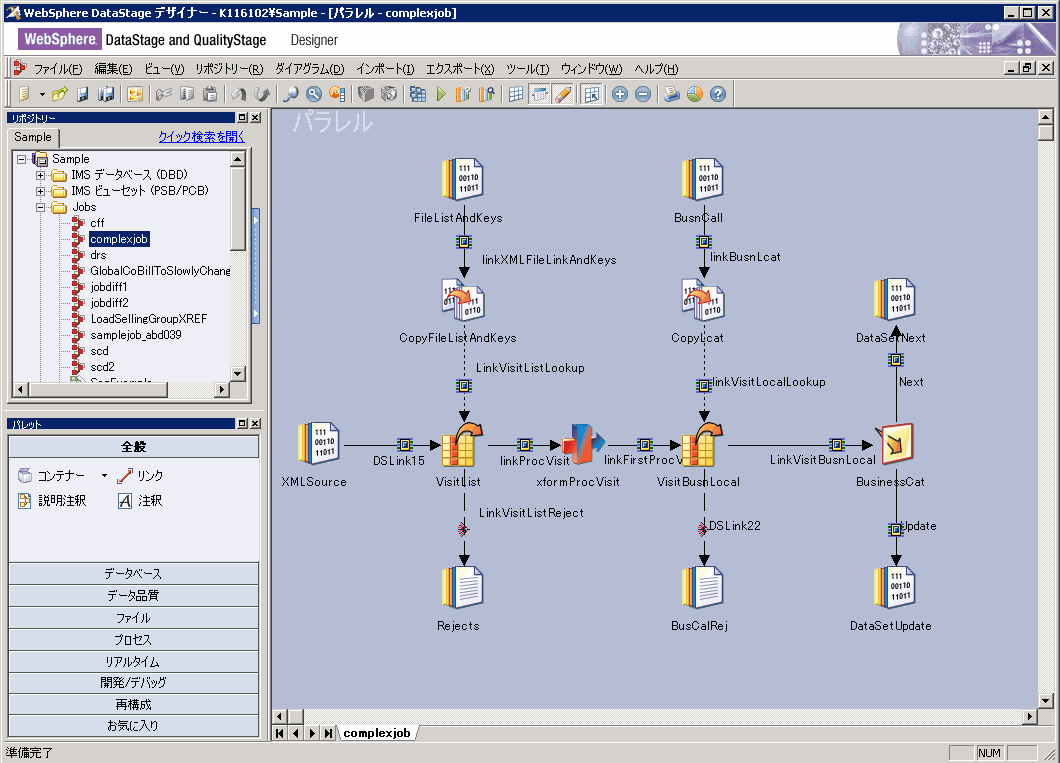
IBM InfoSphere DataStage ジョブ は、企業のデータ統合のニーズに合わせて高度化することができます。図 5 は、さらに複雑な ジョブの例です。
デザイナー・クライアントを使用して 統合プロセスを作成し、続いて個々のステージの詳細を追加します。 この方式を使用すると、ジョブにまたがるコンポーネントをビルドし、再利用することができます。 デザイナー・クライアントにより、最も複雑で手間のかかる統合プロセスでも定義する必要の あるコーディングを最小化します。
個々のデータ・ソースと処理手順が、 ジョブ・デザインのステージです。ステージは、データ・フローにリンクしています。 ステージをツール・パレットからキャンバスにドラッグします。このパレットには、 図 6に示されているように、ステージを編成する ためにカスタマイズできるステージとグループのアイコンが含まれています。
ステージの準備が整うと、 データの向きにしたがって相互にリンクします。例えば、図 4のように、 2 件のリンクが追加されます。
ステージ・プロパティー・エディターから、 個々のリンクの表定義をロードするか、リポジトリーから定義を選択して、これをリンクにドラッグします。
ジョブ内の個々のステージには、ステージがデータを実行または処理する方法を指定するプロパティーがあります。 ステージ・プロパティーには、Sequential File ステージのファイル名、 Sort ステージのソートする列と昇順 - 降順、Database ステージのデータベースの表名などが 含まれます。 個々のステージ・タイプは、グラフィカル・エディターを使用します。
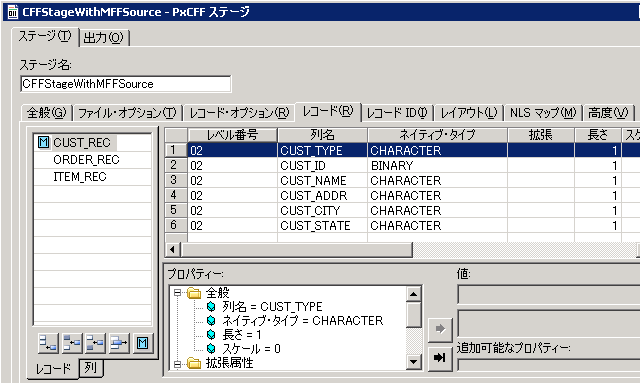
Complex Flat File (CFF) ステージによって、 単一ファイルに多くのレコード・フォーマットがあるデータ・ファイルの 読み取り/書き込みが可能になります。図 7 では、3 個の レコードが結合されています。このステージは、固定長および可変長レコードの両方を サポートし、論理トランザクション内の異なるレコード・タイプのデータを 処理対象の 1 つのデータ・レコードに結合します。例えば、 顧客、オーダー、ユニット・データを結合できます。
CFF ステージと Slowly Changing Dimension ステージは、 改善されたユーザビリティーと、より速い実装に対応するファースト・パスの概念を提供します。ファースト・パスによって、 ステージの処理に必要なステージ・プロパティーの画面と表を参照することができます。 タブの左下にある「i」マークにマウスを置くと、ヘルプが表示されます。
Transformer ステージには、 1 つの 1 次入力リンク、複数の参照入力リンク、複数の出力リンクがあります。 メイン・データの入力ソースからのリンクは、1 次入力リンクとして 指定されます。参照リンクは、ルックアップ操作に使用します。例えば、 変更される実データを提供するのではなく、データの変更方法に影響を及ぼす可能性のある情報を提供します。
入力列は左側に、出力列は右側に表示されます。 上部ペインには、列と出力仕様詳細が表示されます。 下部ペインには、列メタデータが表示されます。
一部のデータを変更せずに Transformer ステージを通過させる必要がある場合でも、 たいていは、入力列からのデータを最初に変換する必要があります。 そのような処理は、式を入力するか、出力仕様と呼ばれるデータに適用する変換処理を選択することで指定できます。 IBM InfoSphere DataStage には数多くの組み込み機能 があり、出力仕様の内部で使用できます。また、カスタム変換処理関数を定義することもできます。 これは、定義後、再利用のためにリポジトリーに保管されます。
出力リンク全体に作用する 制約を指定することもできます。制約は、出力リンクに渡される前にデータが満たす必要のある基準を指定する式です。
分析的システム向けの 標準的デザインは、セントラル・ファクト表から構成されるディメンショナル・データベースに 基づいています。セントラル・ファクト表は、主キーが 1 つだけのより小規模のディメンション表の単一レイヤーで 囲まれています。このデザインは、スター・スキーマとしても認識されています。
通常、スター・スキーマ・データは、顧客情報、売上データ、その他の重要なビジネス情報 を取り込むトランザクションおよびオペレーショナル・システムに あります。トランザクション・システムと分析的システムの主な相違点の 1 つに、 過去を正確に記録する必要性があります。 分析的システムは、マネージャーが戦略的決定ができるように、頻繁にトレンドを見極める必要が あります。例えば、売上のトラッキング・データマートにおける製品定義は、 数多くの製品について、長期間にわたって変更されることの多いディメンションです。 ただし、このディメンションは、変更が遅いのが通常です。1 つの主要な変換処理および移動 の課題は、長期間にわたりこれらのディメンションで発生する変更をシステムが どのように追跡するかということです。多くの場合、ディメンションはごくまれにしか 変更されません。
図 8では、標準的な主キーと、 製品の売上保存ユニット (PRODSKU) を示しています。
Slowly Changing Dimension (SCD) ステージは、 スター・スキーマ・データベース構造のコンテキスト内でディメンション表のソース・データを処理します。このステージにより、 既存のディメンション (タイプ 1 変更として認識されています) の上書き、行の保存中の更新 (タイプ 2 として認識されています)、 または両方のタイプの混合が可能になります。 ロードするデータを準備するため、SCD ステージは、スター・スキーマの変更ディメンションごとに 以下のプロセスを実行します。
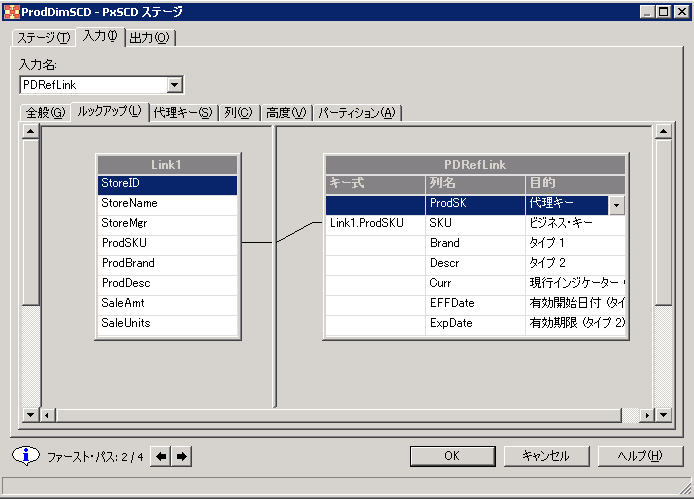
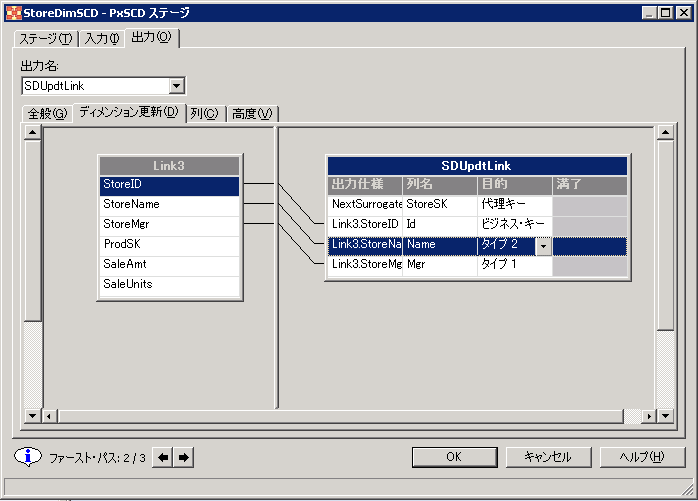
タイプ 2 の更新では、新規の代理主キーを指定した新規行が ディメンション表に挿入され、変更を取り込みます。ディメンションを記述するすべての行に、 最新のインスタンスとヒストリカル・ディメンションを固有に識別する属性が 含まれます。図 9 は、新製品ディメンションを 再定義して、ディメンション表に入れるデータを組み込む方法を示しています。 データには、代理キー、有効期限日付、通貨標識も含まれます。
最後に、新規レコードがディメンション表に (すべての代理キーと ともに) 書き込まれ、時間をかけて製品ディメンションの変更を反映します。 製品の売上保存ユニットに変更がなくても、データベース構造によって ユーザーが前のバージョンの製品と現在のバージョンの製品の売上を 識別することができます。
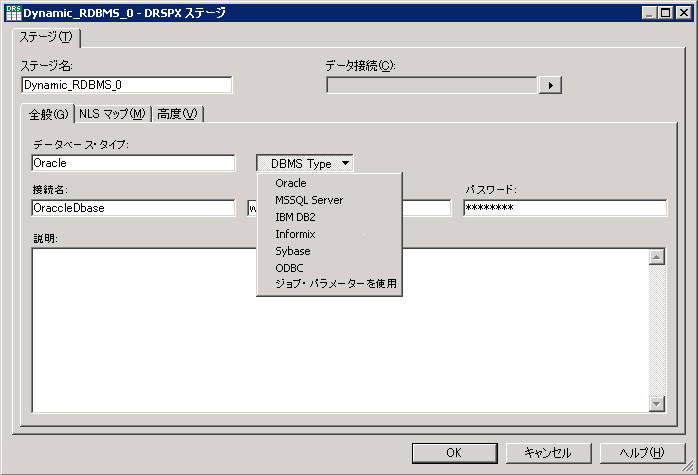
IBM InfoSphere DataStage は、 ほとんどすべてのデータベース管理システムに対する固有の接続を提供しますが、 Dynamic Relational ステージにより、デザイン時ではなく実行時に、 タイプ (例えば、Oracle、IBM DB2®、または SQL Server) の結合を指定できます。 Dynamic Relational ステージは、 データベースからデータを読み取るか、データベースにデータを書き込みます。図 10 は、 データベース・タイプ、名前、ユーザー ID、接続に使用するパスワードなどのデータベース・ステージに 関する一般情報を示しています。パスワードは暗号化されます。
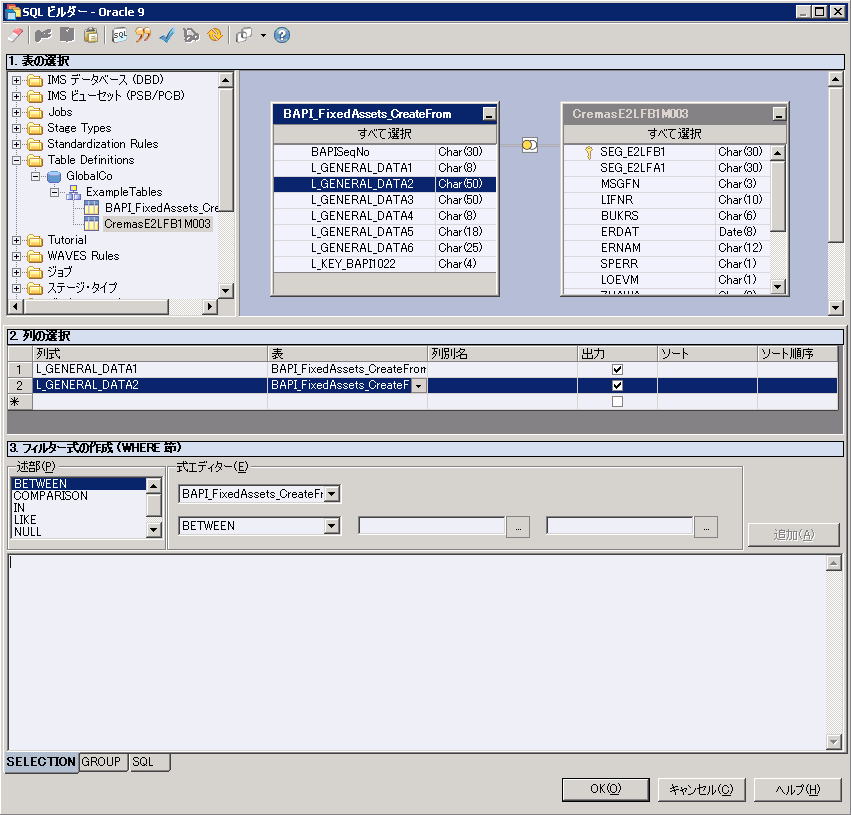
データベース・ソースを定義するための SQL 式を使用する必要のある開発者に対し、SQL ビルダー・ユーティリティーは、 SQL 照会ステートメントを単純なものから複雑なものまでビルドするためのグラフィカル・インターフェースを提供します。 SQL ビルダーは DB2、Oracle、SQL Server、Teradata、および ODBC データベースをサポートします。 ODBC は広範囲のデータベースで機能する SQL をビルドするために使用できますが、 データベース固有のパーサーを使用すると、データベース固有の機能を 利用することができます。図 11 は、適格な SQL 照会を 作成する際に、SQL ビルダーが開発者にどのようなガイドを提供するかを示しています。
IBM InfoSphere DataStage の グラフィカル・ジョブ・シーケンスを使用して、実行するジョブのシーケンスを指定できます。このシーケンスには、 制御情報も含まれます。例えば、このシーケンス内のジョブが成功したか失敗したかによって、 シーケンスは異なるアクションを示します。 ジョブ・シーケンスを定義してから、ディレクター・クライアント、コマンド・ライン、API を 使用して、シーケンスのスケジュールと実行ができます。シーケンスはリポジトリーとディレクター・クライアントで ジョブとして表示されます。
ジョブ・シーケンスのデザインは、ジョブのデザインと似ています。 InfoSphere DataStage and QualityStage デザイナー でジョブ・シーケンスを作成し、(ステージではなく) アクティビティーをツール・パレットから追加します。 次に、アクティビティーを互いに (リンクではなく) トリガーを指定して結合して、制御フローを定義します。 それぞれのアクティビティーにはプロパティーがあり、トリガー式でテストして、 シーケンスの先にある他のアクティビティーに渡すことができます。 アクティビティーにはパラメーターもあり、ジョブ・パラメーターとルーチン引数を指定します。
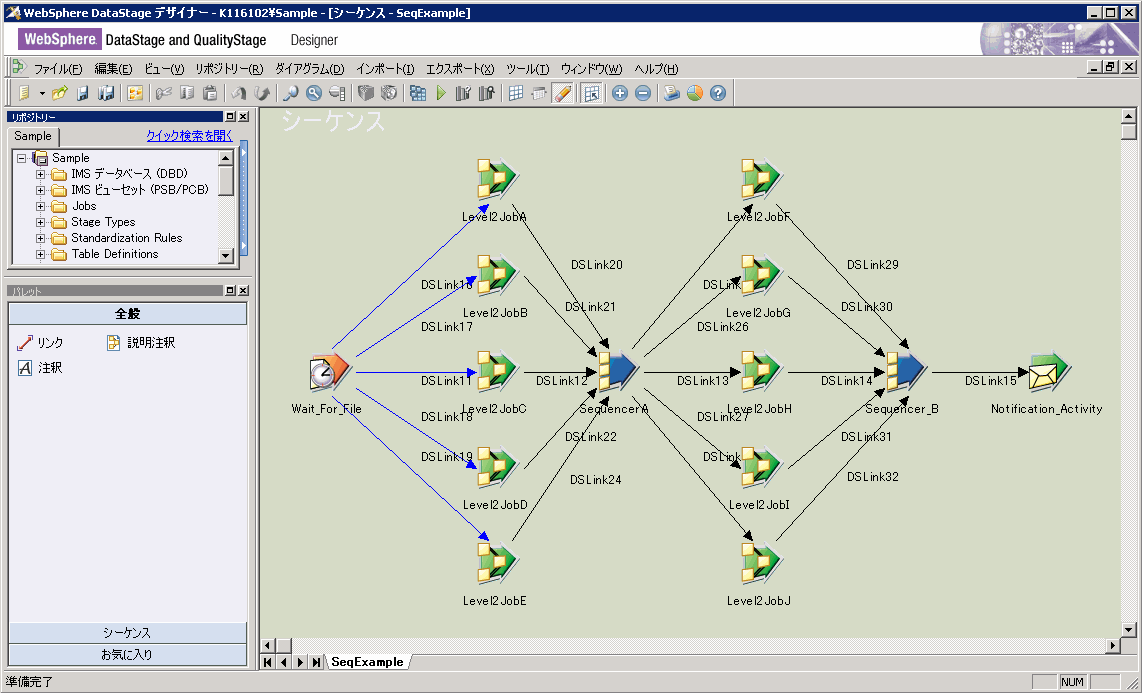
ジョブ・シーケンスにもプロパティーがあり、また、続くアクティビティーに渡すことができるパラメーターを指定できます。図 12の サンプル・ジョブ・シーケンスでは、受信ファイルでトリガーされる標準的なシーケンスを示しています。ジョブには例外処理、 ループ処理、フロー制御も含まれます。
ジョブ・シーケンスでは、以下のタイプのアクティビティーがサポートされています。
デザイナー・クライアントは、プロジェクト・データを管理し、 メタデータ・リポジトリー内に保管された項目の表示と編集を可能にします。この機能によって、 別の IBM InfoSphere DataStage システム間の 項目のインポートとエクスポートおよび他のツールによるメタデータの交換ができます。メタデータ・リポジトリーの項目で レポートを要求できます。
デザイナー・クライアントには、以下の機能があります。
図 13では、 表定義のインポートに関するデザイナー・クライアントのウィンドウが示されます。
InfoSphere DataStage and QualityStage デザイナーによって、 IBM InfoSphere DataStage 開発、 テスト、および実稼働環境間でジョブを移動するためのコンポーネントのインポートとエクスポートができるようになります。ジョブなどの リポジトリー内のどんなコンポーネントでもインポートとエクスポートができます。
エクスポート機能は、 リポジトリーのオブジェクトを記述する XML 文書の生成でも重要です。この文書を表示するためには Web ブラウザーを使用できます。デザイナー・クライアントには、XML 文書から InfoSphere DataStage コンポーネントをインポートするためのインポート機能も組み込まれています。
 このトピックは、以下にも含まれています。IBM InfoSphere Information Server イントロダクション.
このトピックは、以下にも含まれています。IBM InfoSphere Information Server イントロダクション.