 IBM InfoSphere Information Analyzer, Version 9.1.0
IBM InfoSphere Information Analyzer, Version 9.1.0
The data classification analysis function is the process of assigning columns into meaningful categories that can be used to organize and focus subsequent analysis work.
The following attributes in IBM® InfoSphere® Information Analyzer can be used for data classification.
For the system-inferred data class, a column is categorized into one of the following system-defined data classification designations:
There are multiple system reports that can display the columns and their data class designation.
The initial data classification designation for a column is inferred by the system during column analysis processing after the column's frequency distribution has been created. The system uses an algorithm that factors in the cardinality, data type, uniqueness, and length of the column's data values to infer its likely data class. Under certain conditions, the algorithm might not be able to produce a specific data class designation, in which case the system assigns a designation of UNKNOWN.
During column analysis review, the system-inferred data classification of the column for review is presented. You can accept that inference as true or override that inference based on their knowledge or research of the column and its data.
The system automatically applies the data classification algorithm to each column whenever it performs column analysis processing. Using a system algorithm, InfoSphere Information Analyzer analyzes key information about the column to derive the most probable data class that the column belongs to. This system-inferred data classification designation is then recorded in the repository as the inferred selection and by default becomes the chosen selection, as shown in the following example.
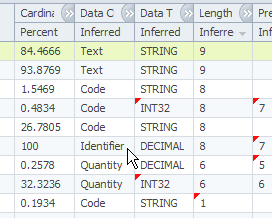
You views the system-inferred data classification designation during the column analysis review of columns. At the detailed column view, data classification has its own tab for viewing results. On this panel, you can accept the system-inferred data class or override the system's inference by selecting another data classification designation. If you override the system-inferred data class selection, the new selection is recorded in the repository as the chosen selection. The process is completed when you mark the data classification function for the column as reviewed.
Typically, you might know each column by its name or alias so the decision to accept or override the system-inferred data classification is straightforward. However, when there is little or no familiarity with the column, a close inspection of the frequency distribution values and the defined data type will help you either confirm the system-inferred data class or choose another more appropriate data class.
For example, a common situation occurs when the column is a numeric data type and the choice is between CODE or QUANTITY data class. In general, CODE tends to have a lower cardinality with a higher frequency distribution count per data value than QUANTITY does, but there can be exceptions (for example, a Quantity Ordered field).
Frequently a column that is obviously an INDICATOR (the column name often includes the word/string ‘Flag') is inferred as a CODE because the presence of a third or fourth value in the frequency distribution (for example, “Y”, “N”, and null). In those cases, it is recommended that the column's data class be set to INDICATOR and that the extra values be marked as Incomplete or Invalid from the Domain Analysis screen or even corrected or eliminated in the source (for example, convert the nulls to “N”).
Also, sometimes choosing between CODE and IDENTIFIER can be a challenge. In general, if the column has a high percentage of unique values (for example, frequency distribution count equal to 1), it is more likely to be an IDENTIFIER data class.
Another data classification issue is the need to maintain the consistency of data classification designations across columns in the data environment. A common problem is a column (for example, customer number) that is the primary key of a table and thus has all the characteristics of an IDENTIFIER. However, the same column might also appear in another table as a foreign key and have all the characteristics of a CODE, even though it is in essence still an IDENTIFIER column. This is particularly true where the set of valid codes exist in a Reference Table and the codes are simultaneously the values and the identifiers.
With regard to data marked with an UNKNOWN data classification, the most common condition is that the values are null, blank, or spaces, and no other inference could be made. In this situation, the column is most likely not used and the field should be marked accordingly with a note or with a user-defined classification (such as EXCLUDED or NOT USED). In some scenarios, this might represent an opportunity to remove extraneous columns from the database; while in data integration efforts, these are fields to ignore when loading target systems.
You have only one decision to make for each column in data classification. You either accept the system-inferred data class or override the inferred data class by selecting another.
After that decision has been made, you can mark the column reviewed for data classification; or, you can add the optional data subclass and user class designations prior to marking the review status complete.
However, data classification provides a natural organizing schema for subsequent analysis, particularly for data quality controls analysis. The following table indicates common evaluation and analysis necessary based on each system-inferred data class. You can establish particular criteria for analysis based on user-defined data classes.
| Data class | Properties analysis | Domain analysis | Validity and format analysis |
|---|---|---|---|
| Identifier | Evaluate for Data Type, Length, Nulls, Unique Cardinality |
|
|
| Indicator | Evaluate for Length, Nulls, Constant Cardinality |
|
Mark Invalid values |
| Code | Evaluate for Length, Nulls, Constant Cardinality |
|
Mark Invalid values |
| Date/Time | Evaluate for Data Type, Nulls, Constant Cardinality |
|
|
| Quantity | Evaluate for Data Type, Precision, Scale |
|
|
| Text | Evaluate for Data Type, Length, Nulls, Unique, or Constant Cardinality | Evaluate for Default values, format requirements, and special characters |
|
There are no system performance considerations for the data classification function.
 Release date: 2012-12-14
Release date: 2012-12-14
 PDF version of this information:
IBM InfoSphere Information Analyzer Methodology and Best Practices Guide
PDF version of this information:
IBM InfoSphere Information Analyzer Methodology and Best Practices Guide