Using data queues
Data queues are a type of system object that you can create, to which one high-level language (HLL) procedure or program can send data, and from which another HLL procedure or program can receive data.
The receiving program can be already waiting for the data, or can receive the data later.
The advantages of using data queues are:
- Using data queues frees a job from performing some work. If the job is an interactive job, this can provide better response time and decrease the size of the interactive program and its process access group (PAG). This, in turn, can help overall system performance. For example, if several workstation users enter a transaction that involves updating and adding to several files, the system can perform better if the interactive jobs submit the request for the transaction to a single batch processing job.
- Data queues are the fastest means of asynchronous communication between two jobs. Using a data queue to send and receive data requires less overhead than using database files, message queues, or data areas to send and receive data.
- You can send to, receive from, clear, retrieve the contents or description of a data queue and change some attributes of a data queue in any HLL procedures or programs by calling APIs QSNDDTAQ, QRCVDTAQ, QCLRDTAQ, QMHRDQM, QMHQRDQD, and QMHQCDQ without exiting the HLL procedure or program or calling a CL procedure or program to perform the data queue operation.
- When receiving data from a data queue, you can set a time out such that the job waits until an entry arrives on the data queue. This differs from using the EOFDLY parameter on the OVRDBF command, which causes the job to be activated whenever the delay time ends.
- More than one job can receive data from the same data queue. This has an advantage in certain applications where the number of entries to be processed is greater than one job can handle within the required performance restraints. For example, if several printers are available to print orders, several interactive jobs could send requests to a single data queue. A separate job for each printer could receive from the data queue, either in first-in-first-out (FIFO), last-in-first-out (LIFO), or in keyed-queue order.
- Data queues have the ability to attach a sender ID to each message being placed on the queue. The sender ID, an attribute of the data queue which is established when the queue is created, contains the qualified job name and current user profile.
In addition to these advantages, you can journal your data queues. This allows you to recover the object to a consistent state, even if the object was in the middle of some change action when the abnormal initial program load (IPL) or crash occurred. Journaling also provides for replication of the data queue journal to a remote system (using remote journal for instance). This lets the system reproduce the actions in a similar environment to replicate the application work.
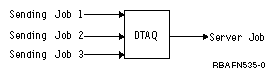
The following example shows how data queues work. Several jobs place entries on a data queue. The entries are handled by a server job. This might be used to have jobs send processed orders to a single job that would do the printing. Any number of jobs can send to the same queue.
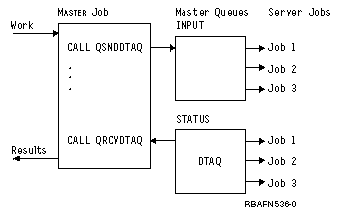
Another example using data queues follows. A primary job gets the work requests and sends the entries to a data queue (by calling the QSNDDTAQ program). The server jobs receive the entries from the data queue (by calling the QRCVDTAQ program) and process the data. The server jobs can report status back to the primary job using another data queue.
Data queues allow the primary job to route the work to the server jobs. This frees the primary job to receive the next work request. Any number of server jobs can receive from the same data queue.
When no entries are on a data queue, server jobs have the following options:
- Wait until an entry is placed on the queue
- Wait for a specific period of time; if the entry still has not arrived, then continue processing
- Do not wait, return immediately.
Data queues can also be used when a program needs to wait for input from display files, ICF files, and data queues at the same time. When you specify the DTAQ parameter for the following commands:
- Create Display File (CRTDSPF) command
- Change Display File (CHGDSPF) command
- Override Display File (OVRDSPF) command
- Create ICF File (CRTICFF) command
- Change ICF File (CHGICFF) command
- Override ICF File (OVRICFF) command
you can indicate a data queue that will have entries placed on it when any of the following happens:
- An enabled command key or Enter key is pressed from an invited display device
- Data becomes available from an invited ICF session
Jobs running on the system can also place entries on the same data queue as the one specified in the DTAQ parameter by using the QSNDDTAQ program.
An application calls the QRCVDTAQ program to receive each entry placed on the data queue and then processes the entry based on whether it was placed there by a display file, an ICF file, or the QSNDDTAQ program.
Support is available to optionally associate a data queue to an output queue by using the Create Output Queue (CRTOUTQ) or Change Output Queue (CHGOUTQ) command. The system logs entries in the data queue when spooled files are in ready (RDY) status on the output queue. A user program can determine when a spooled file is available on an output queue by using the Receive Data Queue (QRCVDTAQ) API to receive information from a data queue.