Configuration of an IBM Spectrum Scale stretch cluster in an export services environment: a sample use case
This page describes a stretch cluster with NFS, SMB, and Object protocols that are enabled, installed, and deployed using the installation toolkit.
Overview of the stretch cluster use case
A single GPFS™ cluster is defined over three geographically separate sites: two production sites and a tiebreaker site. One or more file systems are created, mounted, and accessed concurrently from the two active production sites that are connected over a reliable WAN network.
- Separate the set of available disk volumes into two failure groups. Define one failure group at each of the active production sites.
- Create a replicated file system. Specify a replication factor of 2 for both data and metadata.
With two copies of the data in separate locations, if one site has an unrecoverable disaster, you can recover from a single site with no data loss. Data from two separate sites can share namespace and be accessed by either site. CES groups are enabled to control traffic to the local site. For more information, see Synchronous mirroring with GPFS replication
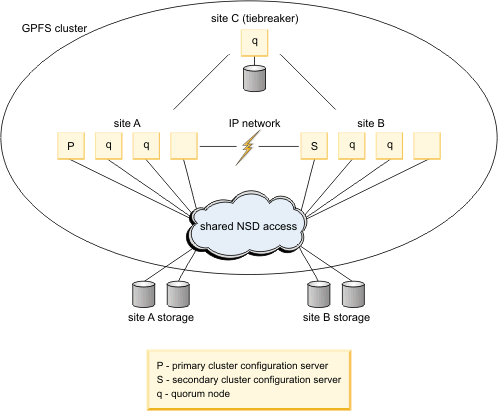
About the tested use case
The stretch cluster in this use case was configured as active-active, meaning that clients can read and write data from either site of the cluster. For more information, see Synchronous mirroring with GPFS replication You can also configure an active-passive stretch cluster. For more information, see An active-passive GPFS cluster. You can replicate data with GPFS in two ways: synchronous replication and asynchronous replication with Active File Management (AFM). Because there are some differences between the two options, you need to understand both options in order to choose the solution that best fits your use case.
Synchronous replication
- your data is always available
- you can read and write in both locations
- you do not have to perform recovery actions from applications except for changing the IP address/hostname.
Because data is synchronously replicated, the application gets consistent data and no data is lost during failover or failback. Synchronous replication requires a reliable high-speed, low latency network between sites, and it has a performance impact on the application when the failback occurs.
Asynchronous replication with AFM
Asynchronous replication with AFM can work on a high latency network. Because data is asynchronously replicated, all updates might not be replicated when a failure occurs. Therefore, the application needs to be able to tolerate data loss and to run recovery operations to fail back. This setup is usually two separate GPFS clusters instead of one cluster at multiple geographical sites.
Limitations of a stretch cluster that uses GPFS synchronous replication
- The IBM Spectrum Scale™ installation toolkit cannot deploy protocols if the CES networks across the two sites cannot communicate. For more information, see Limitations of the installation toolkit .
- If the Object protocol and the CES networks are separate and cannot communicate across the two sites, then object can use only one site to read and write data. For guidance on setup, refer to Configuration of object for isolated node and network groups.
- If your implementation requires you to set up Spectrum Scale IBM Spectrum Scale for object to one site, you will not have a seamless failover if you lose all of the protocol nodes on that site. You need to change the object ring configuration so that it points back to the CES Group that is available on the other site. For details, see Configuration of object for isolated node and network groups.
- When you have object enabled on one site and that entire site goes
down unexpectedly, you might have to recover your endpoints manually since you can no longer ping
them. In this case, refer to the steps provided in the OpenStack documentation: https://docs.openstack.org/keystone/pike/install/keystone-install-rdo.html.Note: A deployment has a high chance of failure if the CES networks at each site cannot communicate with each other. For more information, see Limitations of the installation toolkit . For this use case, the cluster was deployed with protocols with separate VLAN’d networks on each site; however, those networks are able to communicate with each other.
Using the spectrumscale installation toolkit to install a stretch cluster
When you set up a stretch cluster, it is important to understand the physical setup of the storage and how it maps from each site to each file system and failure group. Figure 2 shows the tested configuration where each site (A and B) has storage that is only seen by the NSD servers in that site.
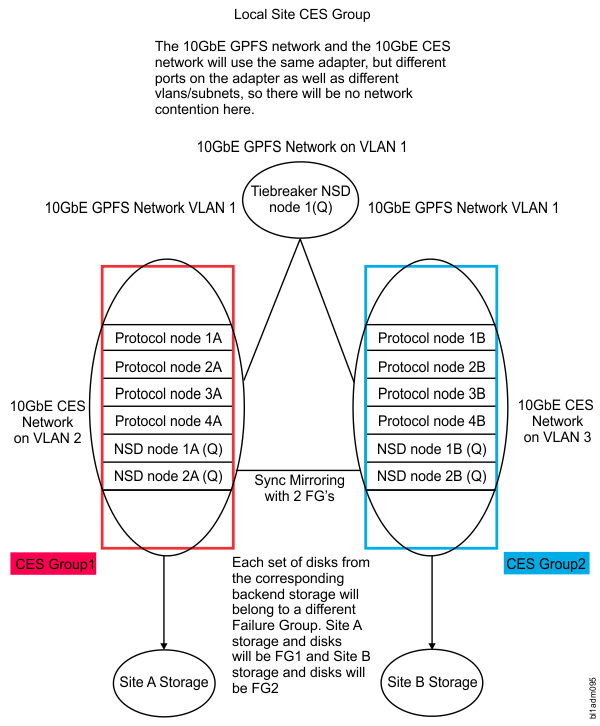
For this use case example, the installation toolkit was used to install the IBM Spectrum Scale software. You can find the installation toolkit by changing directories to where it was extracted (the default 5.0.x.x extraction path follows. This path might vary depending on the code level).
cd /usr/lpp/mmfs/5.0.x.x/installer
- Designate a setup node by issuing the following
command:
./spectrumscale setup -s InstallNodeIPThe setup node is used to run all of the toolkit commands and to specify the protocol and NSD nodes.
- Specify the protocol and NSD nodes by issuing the following commands:
./spectrumscale node add protocol1A -a -p -g ./spectrumscale node add protocol2A -a -p -g ./spectrumscale node add protocol3A -p ./spectrumscale node add protocol4A -p ./spectrumscale node add protocol1B -p ./spectrumscale node add protocol2B -p ./spectrumscale node add protocol3B -p ./spectrumscale node add protocol4B -p ./spectrumscale node add nsd1A -n -q ./spectrumscale node addnsd2A -n -q ./spectrumscale node add nsd1B -n -q ./spectrumscale node add nsd2B -n -q ./spectrumscale node add nsd3C -n -qThe -s argument identifies the IP address that nodes use to retrieve their configuration. This IP address is one associated with a device on the installation node. (The IP address is automatically validated during the setup phase.)
The -q argument indicates the quorum nodes that are to be configured in the cluster. To keep the cluster accessible during a failure, configure most of the quorum nodes to have GPFS active. In this use case, there are five quorum nodes, therefore three must be active to keep the cluster accessible. These nodes were chosen specifically because they are the least likely to become inaccessible at the same time. Because nsd1A and nsd2A are at one site, nsd1B and nsd2B are at a second site, and nsd3C is at a third site, the likelihood of more than three going down at a time is minimal.
No manager nodes were specified with the -m argument, but by default, if no -m argument is specified, the installation toolkit automatically sets the protocol nodes to manager nodes, leaving an even balance across both sites.
The GUI node designations are specified with the -g argument to be on protocol nodes that reside on the same site, but you can choose to have a single GUI, two GUIs on one site, or two GUIs on different sites. In this case, two GUIs were tested on a single site.
- Define NSD mappings to physical disks and assign those NSDs to failure groups and file systems.
The following example NSDs are designated as dataAndMetadata; however, if you have the capacity
(disk space and disk speed), set up Metadata disks on SSDs for the best
performance.
./spectrumscale nsd add -p nsd1A -s nsd2A -u dataAndMetadata -fs ces -fg 2 /dev/mapper/lun_8 ./spectrumscale nsd add -p nsd1B -s nsd2B -u dataAndMetadata -fs ces -fg 1 /dev/mapper/lun_1 ./spectrumscale nsd add -p nsd1B -s nsd2B -u dataAndMetadata -fs gpfs0 -fg 2 /dev/mapper/lun_6 ./spectrumscale nsd add -p nsd2B -s nsd1B -u dataAndMetadata -fs gpfs0 -fg 2 /dev/mapper/lun_4 ./spectrumscale nsd add -p nsd1B -s nsd2B -u dataAndMetadata -fs gpfs0 -fg 2 /dev/mapper/lun_10 ./spectrumscale nsd add -p nsd2B -s nsd1B -u dataAndMetadata -fs gpfs0 -fg 2 /dev/mapper/lun_24 ./spectrumscale nsd add -p nsd2A -s nsd1A -u dataAndMetadata -fs gpfs0 -fg 1 /dev/mapper/lun_2 ./spectrumscale nsd add -p nsd1A -s nsd2A -u dataAndMetadata -fs gpfs0 -fg 1 /dev/mapper/lun_3 ./spectrumscale nsd add -p nsd2A -s nsd1A -u dataAndMetadata -fs gpfs0 -fg 1 /dev/mapper/lun_4 ./spectrumscale nsd add -p nsd1A -s nsd2A -u dataAndMetadata -fs gpfs0 -fg 1 /dev/mapper/lun_5 ./spectrumscale nsd add -p nsd3C -u descOnly -fs gpfs0 -fg 3 /dev/sda ./spectrumscale nsd add -p nsd3C -u descOnly -fs ces -fg 3 /dev/sdbEach file system, ces or gpfs0, has multiple disks that have primary and secondary servers at each site. This ensures that the file system stays online when an entire site goes down. With multiple primary and secondary servers for each disk and failure group that is local to each site, the GPFS replication keeps the data up to date across both sites. A disk with a primary and secondary server on site A belongs to failure group 1, and a disk with a primary and secondary server on site B belongs to failure group 2. This enables the two-way replication across the failure groups, meaning that one replica of data is kept at each site. The nsd3C node is known as the tiebreaker node. The physical disks that reside on that node /dev/sda and /dev/sdbare are designated as ‘descOnly’ disks and are local to that node and are their own failure group. The descOnly argument indicates that the disk contains no file data or metadata. it is used solely to keep a copy of the file system descriptor. It is recommended to have that tiebreaker node in a separate geographical location than the other two sites.
- Set up the file system characteristics for two-way replication on both the ces and gpfs0 file
systems by issuing the following
command:
./spectrumscale filesystem modify -r 2 -mr 2 ces ./spectrumscale filesystem modify -r 2 -mr 2 gpfs0This sets the metadata and data replication to 2.
- Designate file system paths for protocols and for object by issuing the following
commands:
./spectrumscale config protocols -f ces -m /ibm/ces ./spectrumscale config object -f gpfs0 -m /ibm/gpfs0 - Set the cluster name by issuing the following
command:
./spectrumscale config gpfs -c gumby.tuc.stglabs.ibm.com - Install the stretch cluster by issuing the following
command:
./spectrumscale install --precheck ./spectrumscale install - Set up the IP lists by issuing the following
command:
./spectrumscale config protocols -e 10.18.52.30,10.18.52.31,10.18.52.32,10.18.52.33,10.18.60.30,10.18.60.31,10.18.60.32,10.18.60.33 ./spectrumscale filesystem list - Enable the protocols by issuing the following
commands:
./spectrumscale enable nfs ./spectrumscale enable smb ./spectrumscale enable object - Configure object by issuing the following
commands:
./spectrumscale config object -o Object_Fileset ./spectrumscale config object --adminpassword ./spectrumscale config object --databasepassword - Configure authentication by issuing the following
command:
./spectrumscale auth file ad ./spectrumscale node list - Deploy the stretch cluster by issuing the following
commands:
./spectrumscale deploy --precheck ./spectrumscale deploy - After the deployment completes, check the AD setup and status.
For the use case, the same AD server was on both sites, but you can use any authentication type in a stretch cluster that is supported on a single-site IBM Spectrum Scale cluster. Note that because a stretch cluster is still one cluster, more than one authentication method per site is not supported.
To check the status of the cluster's authentication issue either of these commands mmuserauth service list or mmuserauth service check --server-reachability.
Issue the mmuserauth service list command. The system displays information similar to the following:FILE access configuration : AD PARAMETERS VALUES ------------------------------------------------- ENABLE_NFS_KERBEROS false SERVERS 10.18.2.1 USER_NAME Administrator NETBIOS_NAME stretch_cluster IDMAP_ROLE master IDMAP_RANGE 10000-1000000 IDMAP_RANGE_SIZE 10000 UNIXMAP_DOMAINS DOMAIN1(10000000-299999999) LDAPMAP_DOMAINS none OBJECT access configuration : LOCAL PARAMETERS VALUES ------------------------------------------------- ENABLE_KS_SSL false ENABLE_KS_CASIGNING false KS_ADMIN_USER admin
Userauth file check on node: protocol1A
Checking nsswitch file: OK
AD servers status
NETLOGON connection: OK
Domain join status: OK
Machine password status: OK
Service 'gpfs-winbind' status: OK
Userauth object check on node: protocol1A
Checking keystone.conf: OK
Checking wsgi-keystone.conf: OK
Checking /etc/keystone/ssl/certs/signing_cert.pem: OK
Checking /etc/keystone/ssl/private/signing_key.pem: OK
Checking /etc/keystone/ssl/certs/signing_cacert.pem: OK
Service 'httpd' status: OKPossible steps to convert an IBM Spectrum Scale cluster to a stretch cluster
- Add the nodes from the second and third sites to the original cluster either manually or by using the spectrumscale toolkit.
- Create the tiebreaker disks on the third site.
- If replicating an existing file system, use the mmchfs command to set the replicas of data and metadata blocks to 2. If you are creating a new file system, ensure that the replication factor is set to 2 when it is created. For details, see the section Using the spectrumscale installation toolkit to install a stretch cluster.
- Restripe your file system by issuing the mmrestripefs <filesystem> -R command.
- Enable CES on the protocol nodes that you have added to the configuration.
- Create CES groups on both sites.
Configuring the stretch cluster
- Set up some basic tuning parameters. For the use case, the following tuning parameters were used to improve the performance and reliability of the cluster. Tuning parameters will vary significantly depending on the hardware resources in your environment.
For details on each parameter, see Parameters for performance tuning and optimization. The use case was tested with readReplicaPolicy=fastest which is the recommended setting. A known limitation with readReplicaPolicy=fastest is that with networks that add ~3 ms latency (which are common in such installations) there is no substantial difference between local and remote disks (assuming the disk latency might be in the 40/50ms range). Thus, you might still read data from the remote site. Therefore, it is acceptable to use readReplicaPolicy=local to ensure the data is written/read on the local site as long as the local servers are on the same subnet as the clients and the remote servers are not. The readReplicaPolicy=fastest setting will work with either network topology, both sites on the same subnet or each site on the its own subnet, as long as there is a measurable difference in the I/O access time.mmchconfig readReplicaPolicy=fastest mmchconfig unmountOnDiskFail=yes -N nsd3 mmchconfig workerThreads=1024 -N cesNode mmchconfig -ipagepool=43G -N protocol1A mmchconfig -ipagepool=31G -N protocol2A mmchconfig pagepool=48G -N protocol3A mmchconfig pagepool=48G -N protocol4A mmchconfig pagepool=48G -N protocol1B mmchconfig pagepool=48G -N protocol2B mmchconfig pagepool=48G -N protocol3B mmchconfig pagepool=48G -N protocol4B mmchconfig pagepool=12G -N nsd1A mmchconfig pagepool=16G -N nsd1B mmchconfig pagepool=12G -N nsd2B mmchconfig pagepool=12G -N nsd3C mmchconfig maxFilesToCache=2M mmchconfig maxMBpS=5000 -N cesNodes - Set up the CES nodes.
CES group are needed when the CES networks on each site cannot communicate with each other. By having each site's local nodes in the same CES group, the administrator is able to control where the CES IPs failover to when there is an issue with a specific protocol node. If CES groups are not set up, a CES IP from Site A might attempt to failover to a node on Site B, and because there is no adapter for that IP to alias to on Site B (assuming different subnets), the failover will not succeed. CES groups make it easy to manage what CES nodes can host what CES IPs.
Set the CES nodes in the cluster to the corresponding groups by issuing the mmchnode --ces-group command (CES group names are not case-sensitive). For example:mmchnode --ces-group SiteA -N protocol1A mmchnode --ces-group SiteA -N protocol2A mmchnode --ces-group SiteB -N protocol1B mmchnode --ces-group SiteB -N protocol2BIn the example, protocol nodes protocol1A and protocol2A are set to the Site A CES group, protocol nodes protocol1Band protocol2B are set to the Site B CES group.
For detailed instructions, see Setting up Cluster Export Services groups in an IBM Spectrum Scale cluster.
- Assign CES IPs to the corresponding CES groups. This ensures that IPs that reside on nodes in
Site A do not fail over to nodes that reside in Site B and vice versa. Issue the mmces
address change command. For
example:
mmces address change --ces-ip 10.18.52.30,10.18.52.31,10.18.52.32,10.18.52.33 --ces-group SiteA mmces address change --ces-ip 10.18.60.30,10.18.60.31,10.18.60.32,10.18.60.33 --ces-group SiteB - To verify the CES groups your nodes belong to, issue the mmces node list
command. The sample output is as
follows:
Node Name Node Flags Node Groups -------------------------------------------------------------- 10 protocol1B none siteB 11 protocol2B none siteB 12 protocol3B none siteB 13 protocol4B none siteB 6 protocol1A none siteA 7 protocol2A none siteA 8 protocol3A none siteA 9 protocol4A none siteA - To verify the CES groups your CES IPs belong to, issue the mmces address list
command. The sample output is as
follows:
Address Node Group Attribute ------------------------------------------------------------------------- 10.18.52.30 protocol1AsiteAobject_singleton_node,object_database_node 10.18.52.31 protocol2AsiteA none 10.18.52.32 protocol3AsiteA none 10.18.52.33 protocol4AsiteA none 10.18.60.30 protocol1BsiteB none 10.18.60.31 protocol2BsiteB none 10.18.60.32 protocol3BsiteB none 10.18.60.33 protocol4BsiteB none
A load balancer is recommended for the protocol stack to cater to a site loss. The load balancer will ensure that you do not encounter issues if using DNS Round Robin when a site goes down and that the host name in the DNS server can resolve all of the IP addresses.
Using NFS, SMB, and Object with a Stretch Cluster
Using NFS and SMB protocols is similar to using a Spectrum Scale cluster that is in one geographical location. All clients can read and write to either site and to any CES IP that they connect with depending on access. If a single protocol node fails at one site, a normal IP failover will still occur within the site, and the client seamlessly fails over with NFS I/O continuing. SMB clients, however, might need to be reconnected. On failures, clients can reconnect to another cluster node because the IP addresses of failing nodes are transferred to another healthy cluster node. Windows SMB clients automatically open a new connection without additional intervention, but the application that is running I/O may need to be restarted. Object has a few more limitations. See the section “Limitations regarding a Stretch Cluster using GPFS synchronous replication” for details. In summary, if your CES networks cannot communicate across sites, you must choose a single site and its CES group to configure with object. During a full site outage, you will need to make the manual fixes described in the Limitations section. A single protocol node failure will still work but you will need to retry after the CES IP moves to a new node within the CES group.
Monitoring and administering a stretch cluster
Monitoring your stretch cluster is the same as monitoring a cluster in a single location, except for the disk setup, and knowing when your disks are down and what site is affected. You can see the disk status using the mmlsdisk command. The sample output is as follows:
disk driver sector failure holds holds storage
name type size group metadata data status availability pool
------------ -------- ------ ----------- -------- ----- ------------- ------------------------
nsd22 nsd 512 2 Yes Yes ready up system
nsd23 nsd 512 2 Yes Yes ready up system
nsd24 nsd 512 2 Yes Yes ready up system
nsd25 nsd 512 2 Yes Yes ready up system
nsd26 nsd 512 1 Yes Yes ready up system
nsd27 nsd 512 1 Yes Yes ready up system
nsd28 nsd 512 1 Yes Yes ready up system
nsd29 nsd 512 1 Yes Yes ready up system
nsd30 nsd 512 1 Yes Yes ready up system
nsd31 nsd 512 3 No No ready up systemflag value description
------------------- ------------------------ -----------------------------------
-m 2 Default number of metadata replicas
-M 3 Maximum number of metadata replicas
-r 2 Default number of data replicas
-R 3 Maximum number of data replicasIf the default number of data and metadata replicas is set to two, this will indicate that you have no disk failures and that your data is being replicated across both failure groups.
Issue the mmlsdisk ces command. The sample output is as follows:
disk driver sector failure holds holds storage
name type size group metadata data status availability pool
------------ -------- ------ ----------- -------- ----- ------------- ------------------------
nsd20 nsd 512 2 Yes Yes ready up system
nsd21 nsd 512 1 Yes Yes ready up system
nsd32 nsd 512 3 No No ready up system
If you lose access to one site’s storage due to maintenance, network issues, or hardware issues, the disks in the cluster are marked as down and the mmhealth node show command results shows them as down. This is acceptable because the stretch cluster can keep operating when an entire site goes down. There can be a negative impact on performance while one site is down, but that is expected.
To see the disk cluster status for the use case, issuing the mmlsdisk gpfs0 command shows the following information:
disk driver sector failure holds holds storage
name type size group metadata data status availability pool
------------ -------- ------ ----------- -------- ----- ------------- ------------------------
nsd22 nsd 512 2 Yes Yes ready down system
nsd23 nsd 512 2 Yes Yes ready down system
nsd24 nsd 512 2 Yes Yes ready down system
nsd25 nsd 512 2 Yes Yes ready down system
nsd26 nsd 512 1 Yes Yes ready up system
nsd27 nsd 512 1 Yes Yes ready up system
nsd28 nsd 512 1 Yes Yes ready up system
nsd29 nsd 512 1 Yes Yes ready up system
nsd30 nsd 512 1 Yes Yes ready up system
nsd31 nsd 512 3 No No ready up systemFor the use case, the results of the mmhealth node show -N nsd2B disk command show three disks:
Node name: nsd2B
Node status: FAILED
Status Change: 17 min. ago
Component Status Status Change Reasons
------------------------------------------------------------------------------------
GPFS FAILED 17 min. ago gpfs_down, quorum_down
NETWORK HEALTHY 10 days ago -
FILESYSTEM DEPEND 17 min. ago unmounted_fs_check(gpfs1, ces, gpfs0)
DISK DEPEND 17 min. ago disk_down(nsd20, nsd22, nsd23)
PERFMON HEALTHY 10 days ago -To see all of the failed disks, issue the mmhealth node show nsd2B command (without the -N attribute). For the use case, the system displays the following information:
Node name: nsd2B
Component Status Status Change Reasons
------------------------------------------------------------------------
DISK DEPEND 18 min. ago disk_down(nsd20, nsd22, nsd23)
nsd1 DEPEND 18 min. ago -
nsd10 DEPEND 18 min. ago -
nsd11 DEPEND 18 min. ago -
nsd12 DEPEND 18 min. ago -
nsd13 DEPEND 18 min. ago -
nsd14 DEPEND 18 min. ago -
nsd15 DEPEND 18 min. ago -
nsd16 DEPEND 18 min. ago -
nsd17 DEPEND 18 min. ago -
nsd18 DEPEND 18 min. ago -
nsd19 DEPEND 18 min. ago -
nsd2 DEPEND 18 min. ago -
nsd20 DEPEND 18 min. ago disk_down
nsd22 DEPEND 18 min. ago disk_down
nsd23 DEPEND 18 min. ago disk_down
nsd24 DEPEND 18 min. ago disk_down
nsd25 DEPEND 18 min. ago disk_down
nsd3 DEPEND 18 min. ago -
nsd4 DEPEND 18 min. ago -
nsd5 DEPEND 18 min. ago -
nsd6 DEPEND 18 min. ago -
nsd7 DEPEND 18 min. ago -
nsd8 DEPEND 18 min. ago -
nsd9 DEPEND 18 min. ago -
Event Parameter Severity Active Since Event Message
-------------------------------------------------------------------------------------
disk_down nsd20 WARNING 16 min. ago Disk nsd20 is reported as not up
disk_down nsd22 WARNING 16 min. ago Disk nsd22 is reported as not up
disk_down nsd23 WARNING 16 min. ago Disk nsd23 is reported as not up
disk_down nsd24 WARNING 16 min. ago Disk nsd24 is reported as not up
disk_down nsd25 WARNING 16 min. ago Disk nsd25 is reported as not upAfter the issue is resolved, restart the disks and make sure that the data and metadata replicas are intact. First, ensure that GPFS is active on all nodes. Next, issue the mmchdisk <filesystem> start-a command. This informs GPFS to try to access the disks that are marked down and, if possible, to move them back into the up state. This is accomplished by first changing the disk availability from down to recovering. The file system metadata is then scanned and any missing updates (replicated data that was changed while the disk was down) are repaired. If this operation is successful, the availability is then changed to up. If the metadata scan fails, availability is changed to unrecovered. This could occur if too many disks are down. The metadata scan can be re-initiated later by issuing the mmchdisk command again. If more than one disk in the file system is down, all of the disks that are down must be started at the same time by issuing mmchdisk <filesystem> start -a. If you start them separately and metadata is stored on any disk that remains down, the mmchdisk start command fails.
mmnsddiscover: Attempting to rediscover the disks. This may take a while ...
mmnsddiscover: Finished.
nsd2A: Rediscovered nsd server access to nsd26.
nsd2A: Rediscovered nsd server access to nsd28.
nsd3C: Rediscovered nsd server access to nsd31.
sdn2B: Rediscovered nsd server access to nsd23.
nsd1B: Rediscovered nsd server access to nsd23.
nsd2B: Rediscovered nsd server access to nsd24.
nsd1B: Rediscovered nsd server access to nsd24.
nsd1A: Rediscoverensd server access to nsd29.
nsd2A: Rediscovered nsd server access to nsd30.
nsd2A: Rediscoved red nsd server access to nsd27.
nsd2B: Rediscovered nsd server access to nsd25.
nsd2B: Rediscovered nsd server access to nsd22.
nsd2A: Rediscovered nsd server access to nsd25.
nsd2A: Rediscovered nsd server access to nsd22.
Scanning file system metadata, phase 1 ...
33 % complete on Fri Feb 3 11:46:41 2017
66 % complete on Fri Feb 3 11:56:57 2017
100 % complete on Fri Feb 3 11:58:24 2017 Scan completed successfully.
Scanning file system metadata, phase 2 ...
Scan completed successfully.
Scanning file system metadata, phase 3 ...
8 % complete on Fri Feb 3 11:58:29 2017
16 % complete on Fri Feb 3 11:58:32 2017
23 % complete on Fri Feb 3 11:58:35 2017
…
91 % complete on Fri Feb 3 11:59:18 2017
95 % complete on Fri Feb 3 11:59:22 2017
98 % complete on Fri Feb 3 11:59:25 2017
100 % complete on Fri Feb 3 11:59:26 2017
Scan completed successfully.
Scanning file system metadata, phase 4 ...
Scan completed successfully.
Scanning user file metadata ...
2.37 % complete on Fri Feb 3 11:59:46 2017 ( 2473984 inodes with total 672770 MB data processed)
3.86 % complete on Fri Feb 3 12:00:07 2017 ( 4734976 inodes with total 1094807 MB data processed)
4.59 % complete on Fri Feb 3 12:00:27 2017 ( 7880704 inodes with total 1301307 MB data processed)
5.30 % complete on Fri Feb 3 12:00:47 2017 ( 11003904 inodes with total 1501577 MB data processed)
6.01 % complete on Fri Feb 3 12:01:07 2017 ( 14077952 inodes with total 1703928 MB data processed)
6.70 % complete on Fri Feb 3 12:01:27 2017 ( 17154048 inodes with total 1896877 MB data processed)
7.36 % complete on Fri Feb 3 12:01:47 2017 ( 20135936 inodes with total 2084748 MB data processed)
7.97 % complete on Fri Feb 3 12:02:07 2017 ( 22512640 inodes with total 2257626 MB data processed)
8.21 % complete on Fri Feb 3 12:02:27 2017 ( 23322624 inodes with total 2327269 MB data processed)
8.39 % complete on Fri Feb 3 12:02:48 2017 ( 24182784 inodes with total 2377108 MB data processed)
8.52 % complete on Fri Feb 3 12:03:09 2017 ( 25182208 inodes with total 2414040 MB data processed)
8.64 % complete on Fri Feb 3 12:03:29 2017 ( 26166272 inodes with total 2447380 MB data processed)
…
96.58 % complete on Fri Feb 3 12:36:40 2017 ( 198458880 inodes with total 27362407 MB data processed)
96.82 % complete on Fri Feb 3 12:37:00 2017 ( 202438144 inodes with total 27430464 MB data processed)
97.06 % complete on Fri Feb 3 12:37:20 2017 ( 206526720 inodes with total 27498158 MB data processed)
97.30 % complete on Fri Feb 3 12:37:40 2017 ( 210588672 inodes with total 27567944 MB data processed)
97.46 % complete on Fri Feb 3 12:38:00 2017 ( 266730496 inodes with total 27612826 MB data processed)
97.52 % complete on Fri Feb 3 12:38:20 2017 ( 302344960 inodes with total 27629694 MB data processed)
97.59 % complete on Fri Feb 3 12:38:40 2017 ( 330066432 inodes with total 27648547 MB data processed)
100.00 % complete on Fri Feb 3 12:38:52 2017 ( 394185216 inodes with total 27657707 MB data processed)
Scan completed successfully.The recovery time for this command can vary depending on how much data was written while the disks were down. If the disks were down for a long time (greater than 24 hours) and a lot of data was written in that time, it is expected that the mmchdisk command could take quite a while to complete. The time needed to bring up the disks depends on the quantity of data changed during the time the disks were down. This command is run while the file data remains accessible to the applications so I/O clients can continue to operate.
IBM Spectrum Scale stretch cluster use case conclusion
Each use case for a stretch cluster will vary. The sample use case represents one tested configuration. For more information see the following topics:
Synchronous mirroring with GPFS replication
Synchronous mirroring with GPFS replication
An active-passive GPFS cluster
Limitations of the installation toolkit
Configuration of object for isolated node and network groups
https://docs.openstack.org/keystone/pike/install/keystone-install-rdo.html
Parameters for performance tuning and optimization
Setting up Cluster Export Services groups in an IBM Spectrum Scale cluster