Import from CSV options
You specify the .csv import options to describe the format of the input .csv file and to enable alignment to the target mapping specification.
Location and name
- Mapping Specification Name
- Type a name for the mapping specification that you are importing. The name must be unique within the project. The name can contain any character and can be 1 to 255 characters in length.
- UTF-8 Encoding
- Select to specify that the mappings are imported in the UTF-8 character set. Select this option if the .csv file that you are importing is in UTF-8 character set. Otherwise, the .csv file is interpreted in the default encoding of the computer on which the IBM® InfoSphere® FastTrack client is installed.
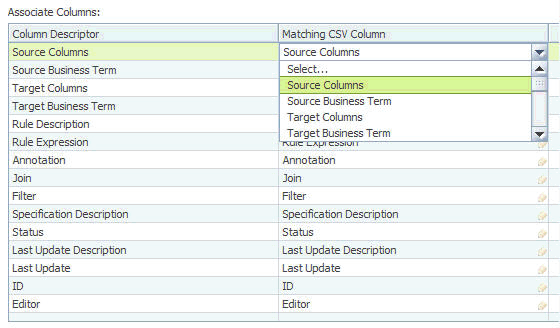
Columns and mapping rows
Use this pane to specify column headers for the mappings and the mapping rows that are to be imported.
- Start import from row
- Click to specify the number of the first row of mappings in the .csv file. Look in the .csv file to obtain this number. Include the column header when you are determining the first row. The mapping rows must be grouped together.
- Select multiple columns
- Move available columns from within the Set Import Options window or the Set Import Lookup Options window. From the Selected Columns table, you can move the selected columns up or down to arrange them in any desired order. You can also select multiple csv file columns to format into one mapping specification field. Source and target names are joined together with a period (.) character, all other names are joined together with a space.
- End import from row
- Click to specify the number of the last row of mappings in the
.csv file. If the .csv file contains only one mapping and no column
headers row, the number for the Start Import from Row can
be the same as the number for the End Import from Row.Important: If you are also importing lookups, make sure the lookup rows are not included here where you are specifying mapping rows.
- Delimiter
- Click to specify a character that separates columns of data in both the mapping and lookup sections in the .csv file. You must specify a delimiter, and the delimiter must be the same character for the entire .csv file.
- Add Date Format
- Specify the data format for dates appearing within the CSV file.
- Use first row as column headers
- Check this box to specify that the first row of the .csv file mapping section, as defined in Start Import from Row, is used to label the .csv file columns for mappings. The text for column headers is displayed as it appears in the .csv file to the import mapping table.
If you choose Select Multiple columns, another dialog opens in which you can select the columns to combine in a specific order to make a mapping specification column.
- table.column
- schema.table.column
- database.schema.table.column
- host.database.schema.table.column
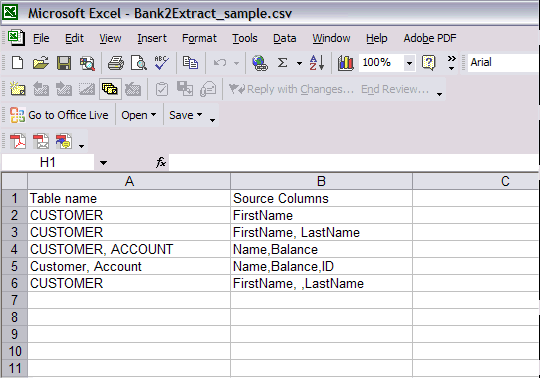
- If you select CUSTOMER from Table name (Column A) and FirstName from Source Columns (Column B), the result would be CUSTOMER.FirstName.
- If you select CUSTOMER from Column A and FirstName, LastName from Column B, the result would be CUSTOMER.FirstName, CUSTOMER.LastName.
- If you select CUSTOMER, ACCOUNT from Column A and Name,Balance from Column B, the result would be CUSTOMER.Name, ACCOUNT.Balance.
- If you select Customer, Account from Column A and Name,Balance,ID from Column B, the result would be Customer.Name, Customer.Balance, Customer.ID.
- If you select CUSTOMER from Column A and FirstName, ,LastName from Column B, the result would be CUSTOMER.FirstName, CUSTOMER. , CUSTOMER.LastName.
All but one item listed refer to attributes of a mapping. Specification Description applies to the entire mapping specification.
If you do not want to specify any matching columns, leave "None" as the selection for "Matching CSV Column".
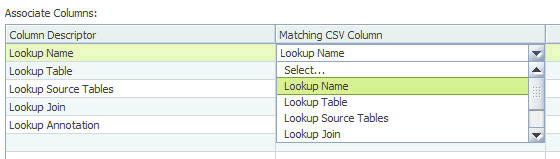
Lookups
In IBM InfoSphere FastTrack, a lookup definition is used to retrieve more information about an entity from a lookup table, given a key. The lookup definition binds the lookup table to a mapping specification, allowing columns of the lookup table to be used as source columns in the mapping specification. In this pane, you specify the use of lookups and specify the items to import as part of a lookups.
- Start import from row
- Click to specify the number of the first row of lookups in the
.csv file. Look in the .csv file to obtain this number. Include the
column header when you are determining the first row. The rows of
lookups in the .csv file must be grouped together.Tip: If you are importing lookups but cannot specify a start row, make sure the lookup rows are not included the mapping import rows.
- End import from row
- Click to specify the number of the last row of lookups in the .csv file. If the .csv file contains only one lookup and no column headers row, the number for the Start Import from Row can be the same as the number for the End Import from Row.
- Use first row as column headers
- Check this box to specify that the first row of .csv file lookups section, as defined in Start Import from Row, is used to label the .csv file columns for lookups. The text for column headers is displayed is as it appears in the .csv file to the import lookups table.
For the items listed, select the item that you want to import and the column in the .csv file to use as the column header for the item. The list in the drop-down box shows the column headers that are contained in the .csv file.
Data source names
Use this pane to specify use of either the full name of the data source or to customize the name.
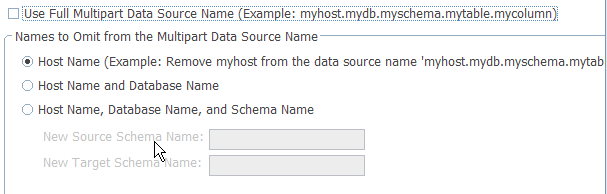
- Use full multipart data source name
- Select to specify use of the complete data source name, as provided
in the .csv file. The multipart name refers to the complete name that can display in IBM InfoSphere FastTrack. That multipart name consists of the host name, the schema name, the table name, and the column name. Using all parts of that name is considered a full path. By default, the table and column names in the mapping specification are associated with the full path.
- host name
- The identifier you created when you configured your data sources.
- schema name
- The schema is the unique user ID under which the table was created.
- table name
- A table name represents a table that can contain rows and columns of data.
- column name
- A column name represents a cell in a table that might contain data.
Do not check this box if you want to omit part of the data source name.
Tip: If the multipart data source name in the .csv file has a different name for host, database, or schema than the name that exists in the metadata repository, then leave this box unchecked and use the omit options to help find the matching data source in the metadata repository. - Names to Omit from the Multipart Data Source Name
- Click to specify the parts of the data source that you want to
omit.
- Host name, database name, and schema name
- You provide a replacement schema name for the source and target
columns that are referenced in your mappings.
- Host Name
- Remove the host name from the full multipart name.
- Host Name and Database Name
- Remove the host name and database name from the full multipart name.
- Host Name, Database Name, and Schema Name
- Remove the host name, database name, and schema name from the full multipart name. You provide a replacement schema name to be used.
- Case-sensitive matching for data source names
- Select to specify import of data sources names in the .csv file
that match the names of data sources in the metadata repository, including
the use of upper and lowercase. If this box is checked, only data
source names that are an exact match with the metadata repository
are imported. If this box is unchecked, data source names in the .csv
file are matched and mapped to the first instance of data source names
in the metadata repository, even if the use of letter case differs.
For example, the .csv file contains the data source name, "account". The metadata repository contains a data source name that is similar but differs in the use of letter case: ACCOUNT. If this box is checked, the data source becomes a candidate column because the data source names do not match. If this box is unchecked, the data source name 'account' in the .csv file is matched to the first instance of the data source name in the metadata repository, ACCOUNT.
Tip: Do not use this check box if the use of letter case in the .csv file differs from the metadata repository, and data source names in the metadata repository are unique.
Preview
View columns, mappings, and lookups before import begins. Warning messages are listed. You can review import warning messages and determine whether or not to take action.