Range partitioner
Divides a data set into approximately equal-sized partitions, each of which contains records with key columns within a specified range. This method is also useful for ensuring that related records are in the same partition.
A range partitioner divides a data set into approximately equal size partitions based on one or more partitioning keys. Range partitioning is often a preprocessing step to performing a total sort on a data set.
In order to use a range partitioner, you have to make a range map. You can do this using the Write Range Map stage, which is described in Write Range Map stage.
The range partitioner guarantees that all records with the same partitioning key values are assigned to the same partition and that the partitions are approximately equal in size so all nodes perform an equal amount of work when processing the data set.
An example of the results of a range partition is shown below. The partitioning is based on the age key, and the age range for each partition is indicated by the numbers in each bar. The height of the bar shows the size of the partition.
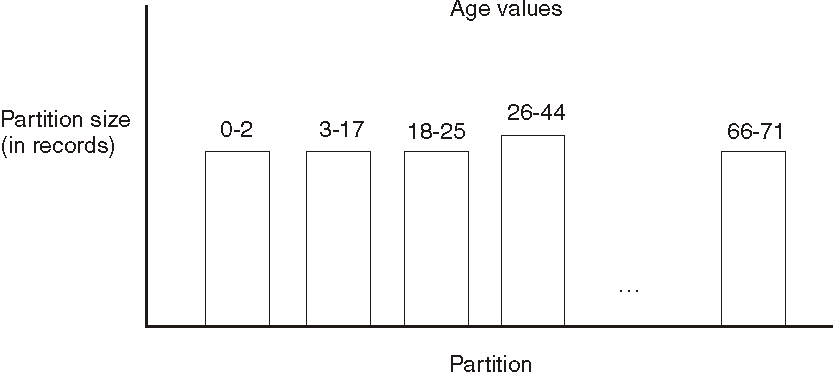
All partitions are of approximately the same size. In an ideal distribution, every partition would be exactly the same size.
However, you typically observe small differences in partition size. In order to size the partitions, the range partitioner uses a range map to calculate partition boundaries. As shown above, the distribution of partitioning keys is often not even; that is, some partitions contain many partitioning keys, and others contain relatively few. However, based on the calculated partition boundaries, the number of records in each partition is approximately the same.
Range partitioning is not the only partitioning method that guarantees equivalent-sized partitions. The random and round robin partitioning methods also guarantee that the partitions of a data set are equivalent in size. However, these partitioning methods are keyless; that is, they do not allow you to control how records of a data set are grouped together within a partition.
In order to perform range partitioning your job requires a write range map stage to calculate the range partition boundaries in addition to the stage that actually uses the range partitioner. The write range map stage uses a probabilistic splitting technique to range partition a data set. This technique is described in Parallel Sorting on a Shared- Nothing Architecture Using Probabilistic Splitting by DeWitt, Naughton, and Schneider in Query Processing in Parallel Relational Database Systems by Lu, Ooi, and Tan, IEEE Computer Society Press, 1994. In order for the stage to determine the partition boundaries, you pass it a sorted sample of the data set to be range partitioned. From this sample, the stage can determine the appropriate partition boundaries for the entire data set.
When you come to actually partition your data, you specify the range map to be used by clicking on the property icon, next to the Partition type field, the Partitioning/Collection properties dialog box appears and allows you to specify a range map.