See information about the latest product version
Message tree copying
When a message passes through a Compute node, a copy of the message tree can be taken (specified by the Compute Mode property) for recovery reasons. If the Compute node changes the message during processing, or if it generates an exception, the message tree can be recovered to a point earlier in the message flow. This process of copying the message tree either in whole or part is called message tree copying.
- Minimize the number of message tree copies: It is recommended to minimize the number of Compute nodes in a message flow.
- Look for substitutes instead of using Compute node: For example, a Filter node might be used which does not copy the tree because ESQL references only the data in the message tree without updating it. Or using the Compute Mode property to control which components are used by default in the output message.
- Produce a smaller message tree in the first place: A smaller tree costs less to copy. You can produce a smaller message tree in the following ways:
- Use smaller messages: Message size versus Message tree
- Use compact parsers, such as XMLNSC and RFH2C: Selecting a parser
- Use Opaque parsing
- Use Partial parsing
- Reduce the number of times the whole tree is copied: Reducing the number of Compute nodes (ESQL or Java™) helps to reduce the number of times that the whole tree needs to be copied. Avoid designs where you have one Compute node that is followed immediately by another in particular.
- Copy portions of the tree at the branch level if possible rather than copying individual leaf nodes. This process works only where the structure of the source and destination are the same but it is worth doing if possible. For example, if we use the following input message:
and use the following code to copy the Address branch to the output:<Request> <Parent> <Address> <City>Colorado Springs</City> <State>CO</State> </Address> </Parent> </Request>
The following message tree is copied:SET OutputRoot.XMLNSC.Target.Address = InputRoot.XMLNSC.Request.Parent.Address;<Target> <Address> <City>Colorado Springs</City> <State>CO</State> </Address> </Target> - Copy data to the Environment tree and work with it in Environment so that the message tree does not have to be copied every time that you run a Compute node. Environment is a scratchpad area that exists for each invocation of a message flow. The contents of Environment are accessible across the whole of the message flow. For example, if we use the following input message:
and use the following code to copy the Address branch to the Environment:<Request> <Parent> <Address> <City>Colorado Springs</City> <State>CO</State> </Address> </Parent> </Request>
Then the environment can be used throughout the flow, for example:CREATE LASTCHILD OF Environment DOMAIN 'XMLNSC' NAME 'XMLNSC'; SET Environment.XMLNSC = InputRoot.XMLNSC;
These examples result in the following message tree:SET OutputRoot.XMLNSC.Target.Address = Environment.XMLNSC.Request.Parent.Address;<Target> <Address> <City>Colorado Springs</City> <State>CO</State> </Address> </Target> - Where possible, set the Compute Mode property on the node to exclude the message. The Compute Mode property controls which components are used by default in the output message. You can select the property to specify whether the Message, LocalEnvironment, and Exception List components that are either generated in the node or contained in the incoming message are used. For more information, see Compute node.
- The first Compute node in a message flow can copy InputRoot to Environment. Intermediate nodes then read and update values in the Environment instead of using the InputRoot and OutputRoot correlations.
- In the final Compute node of the message flow OutputRoot must be populated with data from Environment. The MQOutput node then serializes the message as usual. Serialization does not take place from Environment.
While the use of the Environment correlation is good from a performance point of view, be aware that any updates made by a node that then generate an exception remains in place. There is no back-out of changes as there is when a message tree copy was made before the node exception. For more information, see ESQL coding practices and Environment and Local Environment considerations.
Types of parser copy
When you create a changed output message, the message flow needs to copy the message tree. Nodes such as the Compute node, mapping nodes, and DecisionService node have input and output trees where the output trees are often different from the input trees. In other language nodes such as the JavaCompute node, Java plugin nodes, and .NET nodes, one or many output messages can be created. When you consider memory usage and performance in general, you must take care to determine when the message tree is copied.
When a tree is copied between different domains, the whole of the input tree must be parsed so that it can be copied to the new domain. This behavior is referred to as an unlike parser copy. Each individual field in the source message must be individually transferred to the target domain so that the correct structure and field types apply.
SET OutputRoot = InputRoot;
SET OutputRoot.MQMD = InputRoot.MQMD;
SET OutputRoot.XMLNSC = InputRoot.XMLNSC;SET OutputRoot = InputRoot;
SET Output.Properties.CorrelId = X'010203040506070809101112131415161718192021222324';However, if the codepage changes during a routing, then an MQInput node must inflate the output tree to reserialize the new bitstream.
SET OutputRoot = InputRoot;SET
Output.Properties.CodedCharSetId = 500;The MQInput node parses the output tree that it was passed. But it is important to know that even in this scenario, the original input tree that is received on the input node is not parsed. The high-speed bitstream copy for an unchanged message tree can be useful, and in fact large message handling techniques depend on this process.
In a Compute node, the InputRoot tree is not modifiable. So this technique relies on a high-speed bitstream copy to transfer the tree to the OutputRoot, such that the InputRoot is never inflated.
Don't change a message tree and copy it
Do not change a message tree, and then copy it unnecessarily in other nodes.
Compute1:
- SET OutputRoot = InputRoot;
- SET OutputRoot.XMLNSC.TestCase.LastUpdated = CURRENT_TIMESTAMP;
Compute2:
- SET OutputRoot = InputRoot;
- INSERT INTO Database.myDB .......The general advice that is given is for the message flow developer to ensure that all the updates are done to the message tree in the same node. However, in a flow where subflows are written by other message flow developers, then this behavior might not always be possible.
Therefore, in this type of scenario it would be better for the second Compute node Compute2 not to issue the SET OutputRoot = InputRoot command, and instead set the ComputeMode property so that it is not Message.These settings mean that the node is not going to propagate a new/changed OutputRoot, and as such propagates the one it received.
The same technique can be used if Compute2 were updating the LocalEnvironment with routing information. Here the ComputeMode property must be set to LocalEnvironment.
Always copy at the parser folder level for the bitstream transfer to take place
When a message tree is copied, the high-speed bitstream transfer takes place only at the parser folder level. So SET OutputRoot.XMLNSC = InputRoot.XMLNSC considers creating the target XMLNSC folder using a bitstream copy as shown in the following example:
SET OutputRoot.XMLNSC.TestCase = InputRoot.XMLNSC.TestCaseParsers must be created when not copying to OutputRoot
SET Environment.Variables.XMLNSC = InputRoot.XMLNSC;As the target field is in the Environment tree, an XMLNSC parser is not automatically created in the target, and as such an unlike parser copy takes place. This process means that the bitstream copy cannot take place, and the whole of the source tree is parsed and then copied to the Environment tree. The consequence of this behavior is that any XML-specific field types are lost. For example, if the Environment tree were copied back to the OutputRoot tree then any attributes would now be tags.
CREATE FIELD Environment.Variables.XMLNSC DOMAIN('XMLNSC');
SET Environment.Variables.XMLNSC = InputRoot.XMLNSC;The same is true of the other language APIs when message trees are copied. The target element must be created specifying an owning parser before the copy takes place. Although ESQL OutputRoot has the special behavior such that the SET statement creates parsers for the direct children of OutputRoot, it is not true if OutputRoot is passed into a PROCEDURE/FUNCTION as a row variable. At this point, the ROW variable representation of OutputRoot no longer has the behavior of OutputRoot. This behavior is why OutputRoot is a globally recognized correlation name throughout all ESQL procedures and functions, and as such does not need to be passed in as a ROW variable.
Avoid overwriting fields when a tree is copied
When a message tree is copied, any existing children of target message tree field are detached first. Detaching fields is not the same as deleting fields. Detaching fields means that they are still in scope, but are no longer attached to the tree. As such, the detached fields cannot be reused by the parser, and might cause more message tree fields to be created than intended.
DECLARE inputRef REFERENCE TO InputRoot.DFDL.Parent.RepeatingRecord[1];
WHILE LASTMOVE(inputRef) = TRUE DO
SET OutputRoot.XMLNSC.TestCase = inputRef
DECLARE recordBytes BLOB ASBITSTREAM(OutputRoot.XMLNSC.TestCase)
INSERT INTO Database.myDB(Records) VALUES(recordBytes);
MOVE inputRef NEXTSIBLING NAME 'RepeatingRecord';
END WHILE;DECLARE inputRef REFERENCE TO InputRoot.DFDL.Parent.RepeatingRecord[1];
WHILE LASTMOVE(inputRef) = TRUE DO
SET OutputRoot.XMLNSC.TestCase = inputRef
DECLARE recordBytes BLOB ASBITSTREAM(OutputRoot.XMLNSC.TestCase)
-- Record is now serialized, delete the Output fields we no longer need;
DELETE FIELD OutputRoot.XMLNSC.TestCase;
INSERT INTO Database.myDB(Records) VALUES(recordBytes);
MOVE inputRef NEXTSIBLING NAME 'RepeatingRecord';
END WHILE;Forcing a copy of the message tree fields when required
In some message flow implementations, it might be necessary to ensure that the message tree fields are copied instead of the bitstream copy taking place.
SET OutputRoot.XMLNSC.*[] = InputRoot.XMLNSC.*[]Avoid copying the message tree even when you alter it
Transformation nodes can produce an entirely different message from the original that was on an input terminal. For this reason, InputRoot and OutputRoot references are provided so that the different message trees can be accessed.
SET OutputRoot = InputRoot;
SET OutputRoot.XMLNSC.TestCase.myField = 'An updated field';DECLARE inputRef REFERENCE TO InputRoot;
SET inputRef.XMLNSC.TestCase.myField = 'An updated field';For this ESQL, the ComputeMode property must be changed so that the original input tree is propagated. Although updating the Input trees directly is efficient, care must be taken that this behavior does not affect upstream node processing in the message flow. If a constant input tree is propagating multiple times to a subflow, then the message flow ensures that the input tree is unchanged. This ESQL example means the input tree that was propagated would get modified, and so all other propagations see the updated value.
Setting a field to NULL is NOT the same as deleting it
- SET OutputRoot.XMLNSC.TestCase = NULL;
- DELETE FIELD OutputRoot.XMLNSC.TestCase;
XML, XMLNS, and XMLNSC are not the same domains
Although XML, XMLNS, and XMLNSC are all XML domains, they are not the same domain when you copy a message tree. Therefore, the efficient bitstream transfer does not take place when the tree is copied between these domains with SET OutputRoot.XMLNSC = InputRoot.XML; for example.
Both XML and XMLNS are deprecated and should be used only for legacy message flows.
Avoiding tree copying
Sometimes you might need to use a Compute node, but do not need to change the tree. In these situations the Compute node should be configured to use only LocalEnvironment, which avoids a tree copy for the payload.
In the following example, a Compute node is used to inspect a version field in the header of a payload, and then propagates to a label with the content of the version:
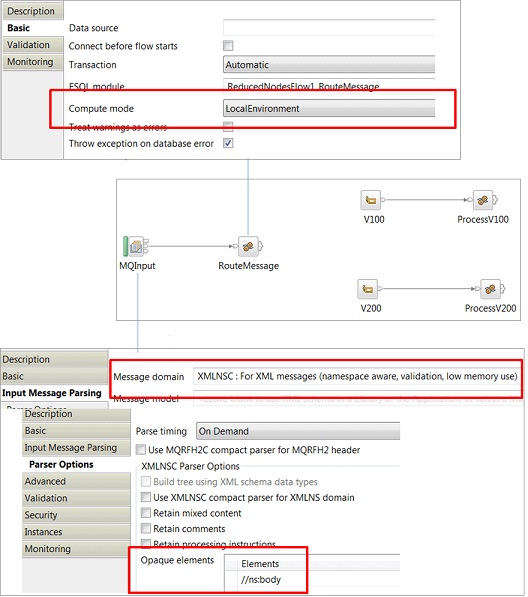
To further improve performance, the Input node parses only the header portion of the payload, the body is configured for opaque parsing. A full parse of the body is then performed in the subsequent nodes as needed.
DECLARE rVersion REFERENCE TO InputRoot.XMLNSC.ns:Inventory.ns:header.ns:version;
PROPAGATE TO LABEL(rVersion);
RETURN FALSE;Message tree copying summary
| Don't change a message tree and copy it | If a message tree is ever changed, then the bitstream copy cannot take place, and extra parsing is needed. |
| Always copy at the parser folder level for the bitstream transfer to take place | When a message tree is copied, the high-speed bitstream transfer takes place only at the parser folder level. |
| Parsers must be created when not copying to OutputRoot | Only the OutputRoot correlation name in ESQL has the special property that a parser is created for parser name folders. Not copying to OutputRoot means that the bitstream copy cannot take place, and the whole of the source tree is parsed and then copied to the Environment tree. |
| Avoid overwriting fields when a tree is copied | When a message tree is copied, any existing children of target message tree field are detached first. Detaching fields is not the same as deleting fields, so they are still in scope, but are no longer attached to the tree. |
| Setting a field to NULL is NOT the same as deleting it | When you attempt to improve the memory usage of message tree usage, setting a field to NULL should never be used. |
| XML, XMLNS, and XMLNSC are not the same domains | The efficient bitstream transfer does not take place when the tree is copied between these domains. Both XML and XMLNS are deprecated. |
- Don't change a message tree and copy it:
- Always copy at the parser folder level for the bitstream transfer to take place:
- Parsers must be created when not copying to OutputRoot
- Avoid overwriting fields when a tree is copied
- Forcing a copy of the message tree fields when required
- Setting a field to NULL is NOT the same as deleting it
- XML, XMLNS, and XMLNSC are not the same domains
- Avoid tree copying
bj60033_.htm |
 Last updated:
2016-08-12 11:20:23
Last updated:
2016-08-12 11:20:23