Detection and reporting of fabric problems
There are several tools that can be used to assist in the detection and analysis of fabric problems. This topic briefly describes some of these tools.
RMF reports
- Channel path activity report
- Device activity report
- I/O queueing activity report
- FICON Director activity report
- Enterprise Disk Systems (ESS) report
See z/OS RMF Report Analysis for more information about these reports.
DISPLAY M=DEV command
The DISPLAY M=DEV command allows you to display the route through the storage area network (SAN) fabric for a specific device and channel path by specifying the ROUTE keyword. The routing information includes all of the switches and ports that are in the path from the channel to the device. If the HEALTH keyword is specified, health information such as the utilization, optical signal strength, and the state of each port ID is also displayed. Reporting of routing and health information will only be performed when the channel is connected to a switch and the control unit definition for the channel path is defined in the I/O configuration with a two-byte link address. See the description of the D M=DEV command in Displaying system configuration information for more information about the syntax for this command.
In the routing portion of the display output, information for each switch in the path is displayed, which includes its domain and switch type. The definition of the switch type depends upon the number of switches in the path between the channel and device, and the position of the switch within the path. If there is only one switch, the switch type is shown as Only Director. If there is more than one switch, the first switch is known as the Source Director and the last switch is known as the Destination Director. If there are any switches between the source director and the destination director, each of those switches is known as an Intermediate Director.
For each entry and exit port, information about what is physically and logically connected to that port is displayed under the From and To columns. A physical connection means that the port is connected via a fibre optic link to a channel, control unit, or another switch. That is, there is a physical link between the port and the other end of the link. A logical connection means that frames from this port are routed to one or more ports on the same switch. However, there is no physical link between these ports.
- For entry ports, the physical connection appears under the From column and represents either a channel, control unit, or a single port on another switch. The logical connection appears under the To column and represents a single port or a group of ports on the same switch, depending on the routing and grouping methods.
- For exit ports, the logical connection appears under the From column and always represents a single entry port on the same switch. The physical connection appears under the To column and represents either a channel, control unit, or a single port on another switch.
For example, the entry port on the first switch (source director) is physically connected to a channel but logically connected to one or more exit ports on the same switch. The exit ports on the first switch are logically connected to the entry port on that switch, but are physically connected via ISLs to entry ports on the next switch.
Note that the definition of what is considered an entry port or exit port depends on the direction of the display request: channel to device (TODEV) or device to channel (FROMDEV). For example, when TODEV is specified, the port that is connected to the channel is considered an entry port and the port connected to the control unit is considered an exit port. However, if FROMDEV is specified, the roles are reversed.
When a port is connected to a channel, Chan appears under the From or To columns of the display, depending on which direction was specified. Likewise, when a port is connected to a control unit, CU appears in the display.
When an entry or exit port is connected to a single switch port, the domain and port number are displayed as a four-digit number under the From or To columns.
When an entry port is connected to multiple ports on the current switch, a dynamic or aggregate group number is displayed under the To column, depending on the routing and grouping methods used. This is described in more detail later.
When an entry port uses static routing, the exit port or aggregate group number assigned to the port and the number of alternate paths are displayed. Detailed information about the alternate paths is not displayed.
When an entry port uses dynamic routing, the set of eligible exit ports is assigned a dynamic group number. This group number appears in two places. First, it appears under the Dyn column for the exit port to show which ports make up the dynamic group. Second, it appears under the To column for the entry port to show that it is associated with this dynamic group of ports. The value that is assigned for the dynamic group number is switch vendor-specific.
When a set of entry or exit ports are part of an aggregate group of ports, those ports are assigned an aggregate group number. This group number appears in two places. First, it appears under the Agg column to show which ports make up the aggregate group. Second, if I/O requests are being statically routed from an entry port to this aggregate set of ports, then the aggregate group number appears under the To column of the entry port. The value that is assigned for the aggregate group number is switch vendor-specific.
- The % transmit/receive utilization indicates the percent utilization of the total transmit or receive bandwidth available at the port.
- The % transmit delay is the percent of time that the frame transmission was delayed because no buffer credits were available on the port. The % receive delay is the percent of time that the port was unable to receive frames because all receive frames were utilized.
- The error count is the number of errors detected on the port affecting the transmission or receipt of frames on the port. This is a sum of the errors counted over the fabric diagnostic interval, which is set to 30 seconds by z/OS®.
- The optical signal column indicates the signal strength of the fibre optic signal being transmitted/received by this port, in units of dBm.
Example 1: Static routing with aggregate links
Figure 1 shows an example of static routing, where frames for the I/O exchange go to one assigned port.
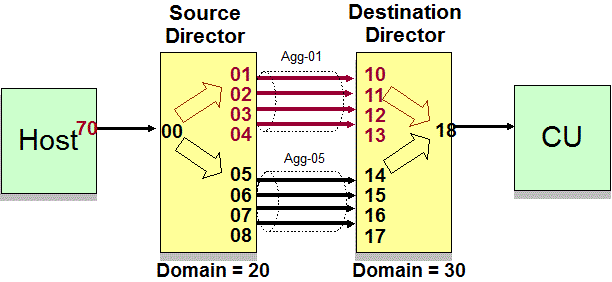
D M=DEV command output for Example 1
The DISPLAY command in this example is requesting the routing and fabric health information for a specific path, from the channel port 70 to the port for device 2000 (TODEV). The output shown here includes only the routing and health portions of the message. Other information from the D M=DEV command that precedes this information is not shown.
D M=DEV(2000,(70)),ROUTE=TODEV,HEALTH
IEE583I hh.mm.ss DISPLAY M 058
DEVICE sdddd STATUS=ONLINE
Source to destination routing information follows:
Switch Domain=20, Type=Source Director
Group
Port Type From To Agg Dyn Speed Misc
00 Entry Chan Agg-01 .. .. 8G Static Alt=1
01 Exit 2000 3010 01 .. 8G
02 Exit 2000 3011 01 .. 8G
03 Exit 2000 3012 01 .. 8G
04 Exit 2000 3013 01 .. 8G
Switch Domain=30, Type=Destination Director
Group
Port Type From To Agg Dyn Speed Misc
10 Entry 2001 3018 01 .. 8G Static Alt=1
11 Entry 2002 3018 01 .. 8G Static Alt=1
12 Entry 2003 3018 01 .. 8G Static Alt=1
13 Entry 2004 3018 01 .. 8G Static Alt=1
18 Exit Mult CU .. .. 8G ......From the example output, you can see that the route from the channel to the device travels through two switches, domains 20 and 30, with domain 20 being the source director and domain 30 being the destination director. The channel is connected to entry port 00 on switch domain 20, as indicated by the From column for that port. The To column for the same port indicates that I/O requests originating from this port are routed to aggregate 01. From the Group Agg column, you can also determine that aggregate 01 consists of exit ports 01, 02, 03, and 04 on the switch. Each of these exit ports is connected to a different port on switch domain 30, as shown in the To column for the ports. For example, port 03 routes I/O to port 12 on domain 30. The speed listed is the negotiated speed, in gigabits per second.
The information for the destination director 30 can be interpreted in a similar manner. Entry ports 10,11,12, and 13 are all within aggregate group 01 and route the I/O requests to port 18 on the same switch. Notice that port 18 will have data routed to it from multiple entry ports on the switch. Since there is not a single originating port to identify, the From column contains Mult. Port 18 is not part of an aggregate group and therefore contains .. in that column. The control unit is connected to port 18.
Note that, in this static routing example, the data for aggregate 05 is not displayed; however, the information in the Misc column indicates that I/Os are statically routed and there is one alternate route defined.
Health display for Example 1
The following output shows the health display for Example 1:
Health information follows:
Fabric Health=Port Error
Switch Domain=20, Health=No health issues
%Util %Delay Error Count Opt Signal
Port Health Trn/Rcv Trn/Rcv Trn/Recv Trn/Recv
00 Port Normal 0/0 0/0 0/0 -4.8/-6.6
01 Port Normal 0/0 0/0 0/0 -2.4/-2.0
02 Port Normal 0/0 0/0 0/0 -2.4/-2.1
03 Port Normal 0/0 0/0 0/0 -4.9/-6.6
04 Port Normal 0/0 0/0 0/0 -2.1/-2.3
Switch Domain=30, Health=Port Error
%Util %Delay Error Count Opt Signal
Port Health Trn/Rcv Trn/Rcv Trn/Recv Trn/Recv
10 Port Fenced 0/0 0/0 0/0 ../-6.7
11 Port Normal 0/0 0/0 0/0 -2.4/-2.7
12 Port Normal 0/0 0/0 0/0 -2.1/-2.4
13 Port Normal 0/0 0/0 0/0 -2.4/-2.1
18 Port Normal 0/0 0/0 0/0 -2.4/-2.1This example of the health data shows that there is a health problem within the fabric, on switch domain 30, as shown by the fabric and switch text Port Error. Switch domain 20 shows no health problems, but port 10 on switch domain 30 shows that the port has been fenced. The text provided in the fabric health, switch health, and port health is switch vendor-specific. If any data is not valid, .. is displayed in the appropriate column.
Example 2: Dynamic routing
Figure 2 shows an example of dynamic routing, where frames for the I/O exchange may be routed to any of the eligible ports. Each of the dynamic paths consists of two aggregate groups. Aggregate group 01 (Agg-01) consists of ports 01 and 02 and aggregate group 03 (Agg-03) consists of ports 03 and 04.
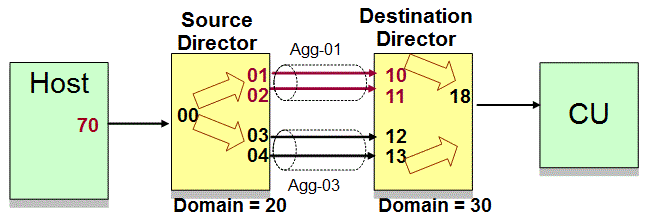
D M=DEV command output for Example 2
The DISPLAY command in this example is requesting the routing information for a specific path from the channel port 70 to the port for device 2000 (TODEV):
D M=DEV(2000,(70)),ROUTE=TODEV
IEE583I hh.mm.ss DISPLAY M 058
DEVICE sdddd STATUS=ONLINE
Source to destination routing information follows:
Switch Domain=70, Type=Source Director
Group
Port Type From To Agg Dyn Speed Misc
00 Entry Chan Dyn-01 .. .. 8G Dynamic
01 Exit 2000 3010 01 01 8G
02 Exit 2000 3011 01 01 8G
03 Exit 2000 3012 03 01 8G
04 Exit 2000 3013 03 01 8G
Switch Domain=30, Type=Destination Director
Group
Port Type From To Agg Dyn Speed Misc
10 Entry 2001 3018 01 .. 8G
11 Entry 2002 3018 01 .. 8G
12 Entry 2003 3018 03 .. 8G
13 Entry 2004 3018 03 .. 8G
18 Exit Mult CU .. .. 8GYou can interpret the output in this example in a similar manner as in D M=DEV command output for Example 1. It shows that the route direction is from the channel to the device and travels through two switches. The entry and exit ports for each switch in this route are identified, along with the entity to which the port is connected on both ends. Notice that dynamic routing is being used, as noted by the Misc column. I/O requests for device 2000 originating from CHPID 70 are dynamically routed to dynamic group 01. The Group Dyn column shows that exit ports 01, 02, 03, and 04 are all in dynamic group 01, and the Group Agg column shows that these exit ports are in two distinct aggregate groups, 01 and 03. Dynamic routing does not apply to the ports on switch domain 30 for I/O requests in this direction; therefore, those ports contain .. in the Group Dyn column. In the dynamic routing scenario, all ports are displayed.
Health checks
This topic describes some of the health checks that can help detect and analyze fabric problems.
Command response time monitoring and reporting
The command response (CMR) time monitor detects any abnormally high command response time that could indicate a SAN problem. CMR time is a component of response time and measures the round trip delay of the fabric, along with minimal channel and control unit involvement. By monitoring this measurement and comparing it among the paths to a control unit, fabric problems, such as hardware errors, misconfiguration, and congestion, can be more easily detected. In addition, inconsistent command response times will trigger fabric monitoring which is described in Fabric monitoring and reporting.
The CMR health check (IOS_CMRTIME_MONITOR) reports on any exceptions detected by the monitor. The check issues an exception if at least one control unit in the system has a path with an average CMR time that is significantly higher than the other paths to the control unit. See IBM Health Checker for z/OS User's Guide for more information about this health check.
The following example shows the command response time health check report output. In this example, the threshold value is 3, and the ratio value is 5. This means that, for an exception to be reported, the average command response time must be greater than three milliseconds, and the CHPID with the highest average CMR time must be at least five times greater than the CMR time for the CHPID with the lowest average response time.
CHECK(IBMIOS,IOS_CMRTIME_MONITOR)
SYSPLEX: LOCAL SYSTEM: SY1
START TIME: 04/23/2013 15:29:05.310858
CHECK DATE: 20100501 CHECK SEVERITY: MEDIUM
CHECK PARM: THRESHOLD(3),RATIO(5),XTYPE(),XCU()
IOSHC113I Command Response Time Report
The following control units show inconsistent average command response
(CMR) time based on these parameters:
THRESHOLD = 3
RATIO = 5
CMR TIME EXCEPTION DETECTED AT: 04/23/2013 15:25:08.971846
CONTROL UNIT = 0500
ND = 002107.000.IBM.PK.000000000002
ENTRY EXIT CU I/O AVG
CHPID LINK LINK INTF RATE CMR
14 B153 B177 0001 16.486 2.560
44 B353 B375 0012 13.245 5.592
16 B055 B277 0013 13.245 25.60
46 B154 B376 0104 13.112 4.941
47 B155 B377 0105 0 ***
* Medium Severity Exception *
IOSHC112E Analysis of command response (CMR) time detected one or
more control units with an exception.In the example output, you can see that the CMR time for CHPID 16 is the highest, and is greater than five times that of CHPID 14, which reports the lowest average response time. Also, note that CHPID 47 does not indicate an average response time, which means it is offline or has no significant data to report.
I/O rate monitoring and reporting
The I/O rate monitor detects any control units in the system that are reporting inconsistent I/O rates for their attached channel paths. I/O rate is the number of I/O requests started down the channel path, per second. The system typically distributes I/O requests equally across all paths for a control unit. When the system determines that there is a performance problem with a path, it will direct I/O requests away from that path, resulting in inconsistent I/O rates across the paths. Therefore, a lower than average I/O rate can be a symptom of potential problems in the fabric. By monitoring this measurement and comparing it among the paths to a control unit, fabric problems similar to those detected by the CMR monitor can be surfaced. In addition, an inconsistent I/O rate will trigger fabric monitoring, which is described in Fabric monitoring and reporting.
The I/O rate health check (IOS_IORATE_MONITOR) reports exceptions detected by the I/O rate monitor. The check issues an exception if at least one control unit in the system has a total I/O rate across all of its channel paths that exceeds a user-specified threshold value, and at least one path with an I/O rate significantly lower than that of the channel path with the highest I/O rate for the control unit. The I/O rate health check runs on a zEnterprise® EC12 (zEC12) or later processor. See IBM Health Checker for z/OS User's Guide for more information about this health check.
The following example shows the I/O rate health check report. In this example, the threshold value of 100 indicates that the total I/O rate across all of the CHPIDs must exceed 100 I/Os per second, which it does. The ratio value of 2 means that any CHPID that has an I/O rate of less than a factor of 2 (that is, one-half) of the CHPID with the highest I/O rate would be flagged.
CHECK(IBMIOS,IOS_IORATE_MONITOR)
SYSPLEX: LOCAL SYSTEM: SY1
START TIME: 04/22/2013 08:44:14.271360
CHECK DATE: 20120430 CHECK SEVERITY: MEDIUM
CHECK PARM: THRESHOLD(100),RATIO(2),XTYPE(),XCU()
IOSHC133I I/O Rate Report
The following control units show inconsistent I/O rates based on these
parameters:
THRESHOLD = 100
RATIO = 2
I/O RATE EXCEPTION DETECTED AT: 04/22/2013 08:44:14.254730
CONTROL UNIT = 0500
ND = 002107.000.IBM.PK.000000000002
ENTRY EXIT CU I/O AVG IOR
CHPID LINK LINK INTF RATE CMR EXC
14 B153 B177 0001 39.603 2.560 *
44 B353 B375 0012 101.38 2.112
16 B055 B277 0013 98.019 2.134
46 B154 B376 0104 50.693 2.048
47 B155 B377 0105 *** ***
* Medium Severity Exception *
IOSHC132E Analysis of I/O rates detected one or
more control units with an exception.Notice that the I/O rate for CHPID 14 is less than half that of CHPID 44 and, therefore, is marked with an asterisk in the IOR EXC column. If there are multiple paths that were significantly below the threshold, all such CHPIDs would be marked as having an exception. Also note that CHPID 47 is likely offline, as indicated by the *** for the I/O rate.
Fabric monitoring and reporting
- Command response time monitoring or I/O rate time monitoring detected a discrepancy.
- The switch presents an alert message indicating a problem within the fabric.
- An IFCC or interface time out occurs due to errors that occurred between the channel and source port or the CU and the destination port.
Fabric monitoring and reporting can only occur when the channel is connected to a switch device and the control unit definition for the path is defined in the IODF with a two-byte link address.
Until the route is healthy (no unusual conditions are detected for an extended period of time), diagnostic information about the affected source or destination route will be obtained from the switch by the monitor at an internally defined interval. Many routes can be monitored simultaneously.
The fabric monitor health check (IOS_FABRIC_MONITOR) exposes possible issues by generating exceptions and reports for the routes being monitored. The routing and health data obtained by the monitor is reproduced in the report for analysis. The content and format of this data is similar to the output of the D M=DEV command (described in DISPLAY M=DEV command) with the ROUTE=BOTH, HEALTH options. See IBM Health Checker for z/OS User's Guide for more information about this health check.
The following example shows the output for the fabric monitor health check report. In this example, an exception is being reported because port 81 on switch C3 is fenced. The complete routing and health information for the path is provided for diagnostic purposes.
CHECK(IBMIOS,IOS_FABRIC_MONITOR)
START TIME: 04/29/2013 17:34:09.652404
CHECK DATE: 20130329 CHECK SEVERITY: MEDIUM
CHECK PARM: LOG(YES),SHOW(LATEST)
IOSHC120I Fabric Health Report
The following channel paths show fabric health issues:
FABRIC HEALTH EXCEPTION DETECTED AT: 04/29/2013 17:31:18.301627
CHPID=00, Entry link=C181, Exit link=C310, Suspect port=**
Source to destination routing information follows:
Switch Domain=C1, Type=Source Director
Group
Port Type From To Agg Dyn Speed Misc
00 Entry Chan Dyn-01 .. .. 8G Dynamic
81 Exit C100 C381 .. 01 8G
82 Exit C100 C382 .. 01 8G
Switch Domain=C3, Type=Destination Director
Group
Port Type From To Agg Dyn Speed Misc
81 Entry C181 C310 .. .. 8G
82 Entry C182 C310 .. .. 8G
10 Exit Mult CU .. .. 8G
Health information follows:
Fabric Health=Port Error
Switch Domain=C1, Health=No health issues
%Util %Delay Error Count Opt Signal
Port Health Trn/Rcv Trn/Rcv Trn/Recv Trn/Recv
00 Port Normal 0/0 0/0 0/0 -4.5/-7.4
81 Port Normal 0/0 0/0 0/0 -2.4/-2.9
82 Port Normal 0/0 0/0 0/0 -4.5/-7.4
Switch Domain=C3, Health=Port error
%Util %Delay Error Count Opt Signal
Port Health Trn/Rcv Trn/Rcv Trn/Recv Trn/Recv
81 Port Fenced 0/0 0/0 0/0 ../-6.7
82 Port Normal 0/0 0/0 0/0 -2.4/-2.1
10 Port Normal 0/0 0/0 0/0 -4.5/-7.4
Destination to source routing information follows:
Switch Domain=C3, Type=Source Director
Group
Port Type From To Agg Dyn Speed Misc
10 Entry CU Dyn-02 .. .. 8G Dynamic
81 Exit C310 C181 .. 02 8G
82 Exit C310 C182 .. 02 8G
Switch Domain=C1, Type=Destination Director
Group
Port Type From To Agg Dyn Speed Misc
81 Entry C381 C100 .. .. 8G
82 Entry C382 C100 .. .. 8G
00 Exit Mult Chan .. .. 8G
Health information follows:
Fabric Health=Port Error
Switch Domain=C3, Health=Port Error
%Util %Delay Error Count Opt Signal
Port Health Trn/Rcv Trn/Rcv Trn/Recv Trn/Recv
10 Port Normal 0/0 0/0 0/0 -2.4/-7.4
81 Port Fenced 0/0 0/0 0/0 ../-7.4
82 Port Normal 0/0 0/0 0/0 -2.4/-7.4
Switch Domain=C1, Health=No health issues
%Util %Delay Error Count Opt Signal
Port Health Trn/Rcv Trn/Rcv Trn/Recv Trn/Recv
81 Port Normal 0/0 0/0 0/0 -2.4/-7.4
82 Port Normal 0/0 0/0 0/0 -2.4/-7.4
00 Port Normal 0/0 0/0 0/0 -2.4/-7.4
* Medium Severity Exception *
IOSHC119E Fabric health issues have been detected
Dynamic routing consistency reporting
The dynamic routing health check (IOS_DYNAMIC_ROUTING) identifies any inconsistencies in the dynamic routing support within the SAN. In order for dynamic routing to function properly, dynamic routing must be supported at all endpoints, the channel and connected devices, communicating through the switches. When dynamic routing is enabled in the SAN, the health check will verify that the processor and attached DASD, tape, and non-IBM devices defined as type CTC support dynamic routing and will identify those endpoints that do not. See IBM Health Checker for z/OS User's Guide for more information about this health check.
The following example shows the output for the dynamic routing health check report. In this example, dynamic routing is enabled in the SAN; however, there are two storage controllers that do not support dynamic routing.
CHECK(IBMIOS,IOS_DYNAMIC_ROUTING)
SYSPLEX: LOCAL SYSTEM: SY1
START TIME: 06/26/2013 12:31:18.246880
CHECK DATE: 20130601 CHECK SEVERITY: MEDIUM
IOSHC144I Dynamic routing is enabled in the SAN but not supported
by the following controllers:
NODE DESCRIPTOR
002107.932.IBM.75.000000000002
002107.951.IBM.75.000000004F01
* Medium Severity Exception *
IOSHC142E Dynamic routing inconsistencies were detected
…