 |
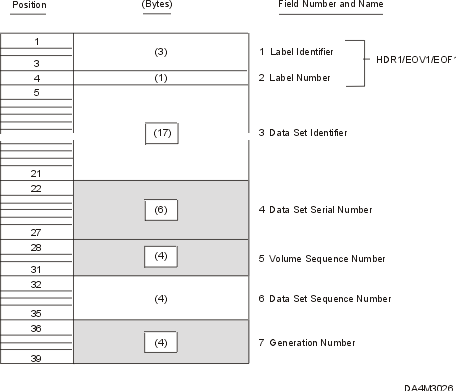
IBM standard data set label 1 is 80 characters in length and describes
the associated data set. The format is used for header labels (HDR1),
end-of-volume trailer labels (EOV1), and end-of-data-set trailer labels
(EOF1). Data set label 1 is always followed by data set label 2 when
the system is writing labels. Data set label 1 is recorded in EBCDIC
on 9-track tape units, or in BCDIC on 7-track tape units.
Figure 1 shows the format of data set label
1. The shaded areas represent fields that the operating system writes
in the label, but that are not used or verified during processing.
The contents and processing of each field of the label are described
below. The processing descriptions refer to the following system control
blocks: - Communication vector table (CVT)
- Data control block (DCB)
- Data extent block (DEB)
- Job file control block (JFCB)
- Unit control block (UCB)
1—Label Identifier (3 bytes) - Contents: Three characters that identify the label are
as follows:
-
- HDR
- Header label (at the beginning of a data set)
- EOV
- Trailer label (at the end of a tape volume, when the data set
continues on another volume)
- EOF
- Trailer label (at the end of a data set).
- Processing: The system checks this field to verify that
the record is an IBM standard data set label.
For input data sets,
the system checks the label identifier to determine whether data set
processing is to be continued. When the system finds an EOV label,
it performs volume switching. When the system finds an EOF label,
it passes control to the user's end-of-data routine or continues processing
with a concatenated data set.
If the DD statement specifies
OPTCD=B for an input data set, the trailer label identifier (EOV or
EOF) is not used to determine whether a volume switch is necessary. If more volumes are available, the system performs the switching.
If no volumes are available, the system passes control to the user's
end-of-data routine or continues processing with a concatenated data
set.
When creating trailer labels, the EOV routine writes EOV
in this field, and the close routine writes EOF.
2—Label Number (1 byte) - Contents: The relative position of this label within a
set of labels of the same type; it is always a 1 for data set label
1.
- Processing: Verified and written in conjunction with Field
1 to identify this label as HDR1, EOV1, or EOF1.
3—Data Set Identifier (17 bytes) - Contents: The rightmost 17 bytes of the data set name
(includes GxxxxVyy if the data set is part of a generation
data group). If the data set name is less than 17 bytes, it is left-justified
and the remainder of this field is padded with blanks. If the name
contains embedded blanks or other special characters, you must enclose
the name in apostrophes on the DD statement that requests this data
set. z/OS MVS JCL User's Guide lists the restrictions that apply to enclosing a data set
name in apostrophes. The apostrophes do not appear in the data set
identifier field.
- Processing: For input, this name is compared to the user-specified
data set name found in the JFCB. This ensures that the correct data
set is being processed.
For output, the data set name in the existing
label is verified in conjunction with password protection to determine
whether the existing data set can be overwritten. If protection is
not specified, the data set name is not checked.
For input
and output, when DFSMSrmm is used, the first file data set identifier
is compared with the last 17 characters of the first file data set
name recorded in the DFSMSrmm control data set. If there is no match,
then the volume is rejected. This check ensures that the correct volume
is mounted.
MVS can accept generation data group members written
in VSE/ESA format. That is, on input, the operating system can verify
the file name field on a VSE/ESA tape, excluding the generation and
version number as a level of qualification, and verifies the generation
and version number fields in addition to the file name field.
When creating labels for a new data set, the user-specified data
set name is obtained from the JFCB and recorded in this field.
4—Data Set Serial Number (6 bytes) - Contents: The volume serial number of the tape volume
containing the data set. For multivolume data sets, this field contains
the serial number of the first volume of the aggregate. The content
requirements are the same as for the volume serial number field in
the volume label.
- Processing: If this field has inconsistent values in the
volumes in a volume set as described in Figure 1 and Figure 2, the system
writes a warning message. This warns that one of the volumes might
be the wrong volume. The message number is IEC709I. When creating
labels, the serial number is obtained from the UCB and recorded in
this field.
5—Volume Sequence Number (4 bytes) - Contents: A number (0001 to 9999) that indicates the order
of the volume within the multivolume aggregate. This number is always
0001 for a single volume data set.
- Processing: If this field does not have a value one greater
than the previous volume in a volume set as described in Figure 1 and Figure 2, the system writes a warning message IEC709I. This warns
the volumes might be out of order. When creating labels, the open
routine writes 0001 in this field if the data set sequence number
is 1; otherwise, the open routine copies the corresponding value from
an earlier label on the volume. The EOV and close routines write a
number that is one higher than on the previous volume.
6—Data Set Sequence Number (4 bytes)
7—Generation Number (4 bytes) - Contents: If the data set is part of a generation data
group, this field contains a number from 0001 to 9999 indicating the
absolute generation number. The first generation is recorded as 0001.
If the data set is not part of a generation data group, this field
contains blanks.
- Processing: Not used or verified. The generation number
is available as part of the data set name in Field 3 of this label.
When creating labels, the system checks the JFCB to determine
if the data set is part of a generation data group. If so, the generation
number is obtained from the last part of the data set name in the
JFCB. Otherwise, this field is recorded as blanks.
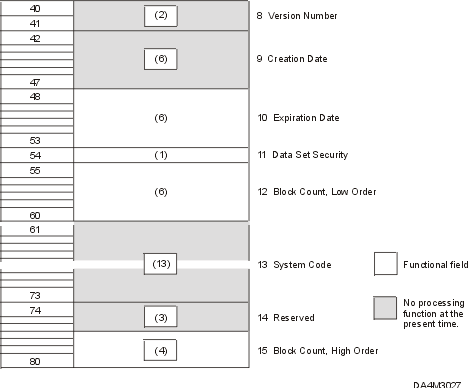
8—Version Number (2 bytes) - Contents: If the data set is part of a generation data
group, this field contains a number from 00 to 99 indicating the version
number of the generation (the first version is recorded as 00). If
the data set is not part of a generation data group, this field contains
blanks.
- Processing: Not used or verified. The version number is
available as part of the data set name in Field 3 of this label.
When creating labels, the system checks the JFCB to determine if
the data set is part of a generation group. If so, the version number
is obtained from the last part of the data set name in the JFCB. Otherwise,
this field is recorded as blanks.
9—Creation Date (6 bytes) - Contents: Date when the data set was created. The date
is shown in the format cyyddd, where:
c = century (blank=19; 0=20; 1=21; etc.)
yy = year (00-99)
ddd = day (001-366)
Note: The century code gives the first two digits of the year, not the actual century.
For example, a blank which translates into 19 indicates a year in
the 1900s, not in the nineteenth century.
- Processing: Not verified. When the system creates labels,
the date is obtained from the JFCB. If a data set is allocated using
JCL, the creation date is the date when allocation begins for the
job step responsible for creating the data set. If a data set is allocated
dynamically, the creation date is the date when allocation begins
for the data set.
10—Expiration Date (6 bytes) - Contents: Year and day of the year the data set may be
scratched or overwritten. The date is shown in the format cyyddd,
where:
c = century (blank=19; 0=20; 1=21; etc.)
yy = year (00-99)
ddd = day (001-366)
Note: The century code gives the first two digits of the year, not the actual century.
For example, a blank that translates into 19 indicates a year in the
1900s, not in the nineteenth century.
- Processing: For input, not used or verified. For output,
the expiration date in the existing label is compared to the current
date. If the date in the label is greater than the current date, the
operator receives a message and is given the option of using the tape
or mounting another. Other data sets that follow on the same volume
expire on the same day.
If you enter 99365 or 99366, the system
permanently retains your data sets, even after 1999. Do not use those
dates as expiration dates. Use them as no-scratch dates only. On a
tape written on OS/400, 99999 may be specified as a no-scratch date.
z/OS does not honor that as a no-scratch date on tapes.
The
expiration dates of scratch SMS-managed tape volumes, in both automatic
and manual tape libraries are ignored. DFSMSrmm can override the expiration
date or reject the volume without the operator's intervention.
When creating labels, the system obtains the expiration date
from the JFCB. If you do not specify a retention period or expiration
date, the expiration date is recorded as zeros, and the data set expires.
DFSMSrmm uses the expiration date to update the volume information
in its control data set. For data sets without an expiration date,
DFSMSrmm assigns one using the DFSMSrmm default retention period,
but the label field is left as zeros.
11—Data Set Security (1 byte) - Contents: A code number indicating the security status
of the data set is as follows:
-
- 0
- No password protection
- 1
- Password protection. Additional identification of the data set
is required before it can be read, written, or deleted. The password
is ignored if the volume is RACF defined.
- 3
- Password protection. Additional identification of the data set
is required before it can be written or deleted. The password is ignored
if the volume is RACF defined.
- Processing: For input, the system inspects this field
on a single volume data set, on each concatenated data set, and on
each volume of a multivolume data set. If protection is specified
in this field, the system verifies the password furnished by the operator
(or the user if under TSO) and sets a security indicator in the JFCB.
For output, the system inspects this field in the existing HDR1
label. If security is specified, the existing data set cannot be overwritten
until the system verifies the password and the data set name in Field
3 of this label. If you specify a data set name different from the
one in Field 3, and the data set is the first one on the first or
only volume, the operator is requested to remove the tape and mount
a scratch tape, even though you requested a specific volume. If the
data set is not the first one on the volume or this is not the first
volume of a multivolume data set, the system abnormally terminates
the task.
When the second or later data set on a volume is
created, and there is no HDR1 label with which to determine security
protection, open reads the EOF1 label of the preceding data set on
the volume. The data set security level in the EOF1 label must match
the security level requested for the new data set. If they are not
equal, the system abnormally terminates the task. If the security
levels are equal and indicate no security protection, open processing
continues. If security protection is indicated, the system requests
a password and verifies that the password furnished by the operator
allows access to the data set name in the EOF1 label, the preceding
data set. It is important to note that, in this case, only the 17-byte
data set name in the EOF1 label is available. Therefore, either the
data set name must be 17 or fewer characters in length, or the last
significant 17 characters of the full data set name must be entered
in the PASSWORD data set. It is recommended that password-protected
tape data sets limit their data set names to 17 or fewer characters,
or that the last 17 characters of the data set name be entered in
the password data set together with the full data set name.
When the system creates labels, the user's request for security is
determined from the indicator in the JFCB.
12—Block Count, Low Order (6 bytes) - Contents: This field in the trailer label shows the low
order six digits of the number of data blocks in the data set on the
current volume. This field in the header label always contains zeros
(000000).
- Processing: The DCB count is increased as the data set
is read. The final DCB count is compared with the count in fields
12 and 15 in the trailer label at end of data or end of volume. If
the counts do not agree, a user exit entry in the DCB exit list determines
whether processing will continue or abnormally terminate. A block
count discrepancy causes processing to abnormally terminate if the
appropriate user exit entry is not provided.
For read backward,
the verification process is reversed. The trailer label count is recorded
in the DCB and decreased as the data set is read. The final DCB count
should be zero, which equals the count in the header label.
When the system creates labels, the block count in the header label
is set to zeros. The block count in the trailer label is obtained
from the DCB.
If the data set was created with an EXCP DCB
that had no device-dependent section, the block count is written as
zero and is not verified.
13—System Code (13 bytes) - Contents: A unique code that identifies the system: ‘IBM
OS/VS 370’.
- Processing: Not used or verified.
14—Reserved (3 bytes) - Contents: Reserved for possible future use—contains blanks.
- Processing: Not used or verified. When creating labels,
the system writes blanks in this field.
15—Block Count, High Order (4 bytes) - Contents: High order four digits of a ten-digit block
count. This field in a header label always contains blanks. If the
data set contains more than 999999 blocks on the volume, this field
contains up to four higher order digits. Of these four digits, the
system changes high order zeroes to blanks when creating the trailer
label.
- Processing: See field 12.



|
 z/OS DFSMS Using Magnetic Tapes
z/OS DFSMS Using Magnetic Tapes
 Copyright IBM Corporation 1990, 2014
Copyright IBM Corporation 1990, 2014