 |
 >>-OUTFIL------------------------------------------------------->
.-,--------------------------------------------------------------.
V |
>----+-FNAMES=-+-ddname---------+---------------------------------+-+-><
| | .-,------. | |
| | V | | |
| '-(---ddname-+-)-' |
+-FILES=-+-suffix---------+----------------------------------+
| | .-,------. | |
| | V | | |
| '-(---suffix-+-)-' |
+-STARTREC=n-------------------------------------------------+
+-ENDREC=n---------------------------------------------------+
+-SAMPLE=-+-n-----+------------------------------------------+
| '-(n,m)-' |
+-+-INCLUDE=-+-(-logical expression-)-+-+--------------------+
| | +-ALL--------------------+ | |
| | '-NONE-------------------' | |
| +-OMIT=-+-(-logical expression-)-+----+ |
| | +-ALL--------------------+ | |
| | '-NONE-------------------' | |
| '-SAVE--------------------------------' |
+-ACCEPT=n---------------------------------------------------+
| .-,----------. |
| V | |
+-PARSE=(---definition-+-)-----------------------------------+
| .-,----. |
| V | |
+-+-+-OUTREC=-+-(---item-+-)-+----------+-+--------------+-+-+
| | '-BUILD=--' +-,VTOF----+ '-,VLFILL=byte-' | |
| | '-,CONVERT-' | |
| | .-,----. | |
| | V | | |
| +-OVERLAY=-(---item-+-)----------------------------------+ |
| | .-,----. | |
| | V | | |
| +-FINDREP=-(---item-+-)----------------------------------+ |
| | .-,---------------. | |
| | V | | |
| '---IFTHEN=(clause)-+-+------------+---------------------' |
| '-IFOUTLEN=n-' |
+-FTOV-------------------------------------------------------+
+-VLTRIM=byte------------------------------------------------+
+-VLTRAIL=string---------------------------------------------+
+-REPEAT=n---------------------------------------------------+
+-+-SPLIT-----+----------------------------------------------+
| +-SPLITBY=n-+ |
| '-SPLIT1R=n-' |
+-NULLOFL=-+-RC0--+------------------------------------------+
| +-RC4--+ |
| '-RC16-' |
+-LINES=n----------------------------------------------------+
| .-,----. |
| V | |
+-HEADER1=-(---item-+-)--------------------------------------+
| .-,----. |
| V | |
+-TRAILER1=-(---item-+-)-------------------------------------+
| .-,----. |
| V | |
+-HEADER2=-(---item-+-)--------------------------------------+
| .-,----. |
| V | |
+-TRAILER2=-(---item-+-)-------------------------------------+
'-| |-------------------------------------------------------'
>>-OUTFIL------------------------------------------------------->
.-,--------------------------------------------------------------.
V |
>----+-FNAMES=-+-ddname---------+---------------------------------+-+-><
| | .-,------. | |
| | V | | |
| '-(---ddname-+-)-' |
+-FILES=-+-suffix---------+----------------------------------+
| | .-,------. | |
| | V | | |
| '-(---suffix-+-)-' |
+-STARTREC=n-------------------------------------------------+
+-ENDREC=n---------------------------------------------------+
+-SAMPLE=-+-n-----+------------------------------------------+
| '-(n,m)-' |
+-+-INCLUDE=-+-(-logical expression-)-+-+--------------------+
| | +-ALL--------------------+ | |
| | '-NONE-------------------' | |
| +-OMIT=-+-(-logical expression-)-+----+ |
| | +-ALL--------------------+ | |
| | '-NONE-------------------' | |
| '-SAVE--------------------------------' |
+-ACCEPT=n---------------------------------------------------+
| .-,----------. |
| V | |
+-PARSE=(---definition-+-)-----------------------------------+
| .-,----. |
| V | |
+-+-+-OUTREC=-+-(---item-+-)-+----------+-+--------------+-+-+
| | '-BUILD=--' +-,VTOF----+ '-,VLFILL=byte-' | |
| | '-,CONVERT-' | |
| | .-,----. | |
| | V | | |
| +-OVERLAY=-(---item-+-)----------------------------------+ |
| | .-,----. | |
| | V | | |
| +-FINDREP=-(---item-+-)----------------------------------+ |
| | .-,---------------. | |
| | V | | |
| '---IFTHEN=(clause)-+-+------------+---------------------' |
| '-IFOUTLEN=n-' |
+-FTOV-------------------------------------------------------+
+-VLTRIM=byte------------------------------------------------+
+-VLTRAIL=string---------------------------------------------+
+-REPEAT=n---------------------------------------------------+
+-+-SPLIT-----+----------------------------------------------+
| +-SPLITBY=n-+ |
| '-SPLIT1R=n-' |
+-NULLOFL=-+-RC0--+------------------------------------------+
| +-RC4--+ |
| '-RC16-' |
+-LINES=n----------------------------------------------------+
| .-,----. |
| V | |
+-HEADER1=-(---item-+-)--------------------------------------+
| .-,----. |
| V | |
+-TRAILER1=-(---item-+-)-------------------------------------+
| .-,----. |
| V | |
+-HEADER2=-(---item-+-)--------------------------------------+
| .-,----. |
| V | |
+-TRAILER2=-(---item-+-)-------------------------------------+
'-| |-------------------------------------------------------'
Additional Parameters for OUTFIL
.-,----.
V |
>>-+-SECTIONS=-(---item-+-)-+----------------------------------><
+-NODETAIL---------------+
+-BLKCCH1----------------+
+-BLKCCH2----------------+
+-BLKCCT1----------------+
+-REMOVECC---------------+
'-IFTRAIL=(updates)------'
OUTFIL control statements allow you to create one or more output
data sets for a sort, copy, or merge application from a single pass
over one or more input data sets. You can use multiple OUTFIL statements,
with each statement specifying the OUTFIL processing to be performed
for one or more output data sets. OUTFIL processing begins after
all other processing ends (that is, after processing for exits, options,
and other control statements).
OUTFILE can be used as an alias for OUTFIL.
OUTFIL statements support a wide variety of output data set tasks,
including: - Creation of multiple output data sets containing unedited or edited
records from a single pass over one or more input data sets.
- Creation of multiple output data sets containing different ranges
or subsets of records from a single pass over one or more input data
sets. In addition, records that are not selected for any subset can
be saved in a separate output data set.
- Conversion of variable-length record data sets to fixed-length
record data sets.
- Conversion of fixed-length record data sets to variable-length
record data sets.
- A wide variety of parsing, editing, and reformatting tasks
including:
- The use of fixed position/length fields or variable
position/length fields. For fixed fields, you specify the starting
position and length of the field directly. For variable fields, such
as delimited fields, comma separated values (CSV), tab separated values,
blank separated values, keyword separated fields, null-terminated
strings (and many other types), you define rules that allow DFSORT
to extract the relevant data into fixed parsed fields, and then use
the parsed fields as you would use fixed fields.
- Insertion of blanks, zeros, strings, current date,
future date, past date, current time, sequence numbers, decimal constants,
and the results of arithmetic expressions before, between, and after
the input fields in the reformatted records.
- Sophisticated conversion capabilities, such as find and replace, hexadecimal display, bit display, translation of EBCDIC letters from lowercase
to uppercase or uppercase to lowercase, translation of characters
from EBCDIC to ASCII and from ASCII to EBCDIC, translation of
characters using the ALTSEQ translation table, conversion of numeric
values from one format to another, left justify or left-squeeze (remove
leading blanks or all blanks and shift left), and right-justify or
right-squeeze (remove trailing blanks or all blanks and shift right).
- Sophisticated editing capabilities, such as control of the way
numeric fields are presented with respect to length, leading or suppressed
zeros, thousands separators, decimal points, leading and trailing
positive and negative signs, and so on.
- Twenty-seven pre-defined editing masks are available for commonly
used numeric editing patterns, encompassing many of the numeric notations
used throughout the world. In addition, a virtually unlimited number
of numeric editing patterns are available via user-defined editing
masks.
- Transformation
of SMF, TOD, and ETOD date and time values to more usable forms.
- Conversion of input date fields of one type (CH,
ZD, PD, 2-digit year, 4-digit year, Julian, Gregorian) to corresponding
output date fields of another type or to a corresponding day of the
week.
- Various types of arithmetic operations for input
date fields.
- Selection of a character constant, hexadecimal constant, or input
field from a lookup table for output, based on a character, hexadecimal,
or bit string as input (that is, lookup and change).
- Creation of the reformatted records in one of the following ways:
- By building the entire record one item at a time.
- By only overlaying specific columns.
- By performing find and replace operations.
- By using sophisticated conditional logic or group
operations to choose how different records are reformatted.
- Highly detailed three-level (report, page, and section) reports
containing a variety of report elements you can specify (for example,
current date, current time, edited or converted page numbers, character
strings, and blank lines) or derive from the input records (for example,
character fields; unedited, edited or converted numeric input fields;
edited or converted record counts; and edited or converted totals,
maximums, minimums, and averages for numeric input fields).
- Creation of multiple output records from each input record, with
or without intervening blank output records.
- Repetition and sampling of data records.
- Splitting of data records in rotation among a set of output data
sets.
- Updating counts and totals in an existing trailer
(last) record based on the current data records.
The parameters of OUTFIL are grouped by primary purpose as follows:
- FNAMES and FILES specify the ddnames of the OUTFIL
data sets to be created. Each OUTFIL data set to be created must
be specifically identified using FNAMES or FILES in an OUTFIL statement.
By contrast, the SORTOUT data set is created by default if
a DD statement for it is present. The term "SORTOUT data set" denotes
the single non-OUTFIL output data set, but in fact, the SORTOUT ddname
can be used for an OUTFIL data set either explicitly or by default.
If SORTOUT is identified as an OUTFIL
ddname, either explicitly (for example, via FILES=OUT) or by default
(OUTFIL without FILES or FNAMES), the data set associated with the
SORTOUT ddname will be processed as an OUTFIL data set rather than
as the SORTOUT data set.
OUTFIL data sets have characteristics
and requirements similar to those for the SORTOUT data set, but there
are differences in the way each is processed. The major differences
are that an E39 exit routine is not entered for OUTFIL data sets,
and that OUTFIL processing does not permit the use of the LRECL value
to pad fixed-format OUTFIL records. (DFSORT will automatically determine
and set an appropriate RECFM, LRECL, and BLKSIZE for each OUTFIL data
set for which these attributes are not specified or available.)
For
a single DFSORT application, OUTFIL data sets can be intermixed with
respect to VSAM and non-VSAM, tape and disk, and so on. All of the
data sets specified for a particular OUTFIL statement are processed
in a similar way and thus are referred to as an OUTFIL group.
(That is, you group OUTFIL data sets that use the same operands by
specifying them on a single OUTFIL statement.) For example, the first
OUTFIL statement might have an INCLUDE operand that applies to an
OUTFIL group of one non-VSAM data set on disk and another on tape;
a second OUTFIL statement might have OMIT and OUTREC operands that
apply to an OUTFIL group of one non-VSAM data set on disk and two
VSAM data sets.
Records
are processed for OUTFIL as they are for SORTOUT, after all other
DFSORT processing is complete. Conceptually, you can think of an OUTFIL
input record as being intercepted at the point between being passed
from an E35 exit and written to SORTOUT, although neither an E35 exit
nor SORTOUT need actually be specified with OUTFIL processing. With
that in mind, see Figure 1 for
details on the processing that occurs prior to processing the OUTFIL
input record. In particular: - Records deleted by an E15 or E35 exit, an INCLUDE, OMIT or SUM
statement, or the SKIPREC or STOPAFT parameter are not available for
OUTFIL processing
- If records are reformatted by an E15 exit, an INREC or OUTREC
statement, or an E35 exit, the resulting reformatted record is the
OUTFIL input record to which OUTFIL fields must refer.
- STARTREC starts processing for an OUTFIL group at a specific
OUTFIL input record. ENDREC ends processing for an OUTFIL
group at a specific OUTFIL input record. SAMPLE selects a sample
of OUTFIL input records for an OUTFIL group using a specific interval
and number of records in that interval. Separately or together, STARTREC,
ENDREC, and SAMPLE select a range of records to which subsequent OUTFIL
processing will apply.
- INCLUDE, OMIT, and SAVE select the records to be
included in the data sets of an OUTFIL group. INCLUDE and OMIT operate
against the specified fields of each OUTFIL input record to select
the output records for their OUTFIL group (all records are selected
by default). SAVE selects the records that are not selected for any
other OUTFIL group.
Whereas the INCLUDE
and OMIT statements apply to all input records, the INCLUDE and OMIT
parameters apply only to the OUTFIL input records for their OUTFIL
group. The INCLUDE and OMIT parameters have all of the logical expression
capabilities of the INCLUDE and OMIT statements.
- ACCEPT limits the number of OUTFIL input
records accepted for processing for an OUTFIL group. A record is
accepted if it is not deleted by STARTREC, ENDREC, SAMPLE, INCLUDE
or OMIT processing. ACCEPT limits the number of records to which
subsequent OUTFIL processing will apply.
- PARSE, OUTREC, BUILD, OVERLAY, FINDREP, or IFTHEN reformat
the output records for an OUTFIL group. These parameters
allow you to rearrange, edit, replace, remove and
change fixed position/length fields or variable position/length fields
from the OUTFIL input records and to insert blanks, zeros, strings,
current date, future date, past date, current time, sequence numbers,
decimal constants, and the results of arithmetic expressions.
OVERLAY
allows you to change specific existing columns without affecting the
entire record.
FINDREP allows you to do various
find and replace operations.
IFTHEN clauses allow you to reformat
different records in different ways according to the criteria you
specify. IFOUTLEN can be used with IFTHEN clauses to set the output
LRECL.
OUTREC or BUILD gives you complete control over the items
in your reformatted records and the order in which they appear, and
also allows you to produce multiple reformatted output records from
each input record, with or without intervening blank output records.
VTOF or CONVERT can
be used with OUTREC or BUILD to convert variable-length input records
to fixed-length output records.
VLFILL can
be used to allow processing of variable-length input records which
are too short to contain all specified OUTREC or BUILD fields.
Whereas
the FIELDS, BUILD, OVERLAY, FINDREP, and IFTHEN
parameters of the OUTREC statement apply to all input records, the
OUTREC, BUILD, OVERLAY, FINDREP, and IFTHEN
parameters of the OUTFIL statement apply only to the OUTFIL input
records for its OUTFIL group. In addition, the OUTREC and BUILD parameters
of the OUTFIL statement support the forward slash (/) separator for
creating blank records and new records, whereas the FIELDS and BUILD
parameters of the OUTREC statement do not.
- FTOV can be used to convert fixed-length input records
to variable-length output records. FTOV can be used with or without
OUTREC , BUILD, OVERLAY, FINDREP, or IFTHEN.
- VLTRIM can be used to remove the trailing bytes with a
specified value, such as blanks, binary zeros or asterisks, from variable-length
records. VLTRIM can be used with or without FTOV.
- VLTRAIL can be used to insert a character
string or hexadecimal string at the end of variable-length records.
VLTRAIL can be used with or without FTOV or VLTRIM.
- REPEAT can be used to repeat each output record a specified
number of times.
- SPLIT, SPLITBY, or SPLIT1R splits the output
records in rotation among the data sets of an OUTFIL group.
With
SPLIT, the first output record is written to the first OUTFIL data
set in the group, the second output record is written to the second
data set, and so on. When each OUTFIL data set has one record, the
rotation starts again with the first OUTFIL data set.
SPLITBY
can be used to rotate by a specified number of records rather than
by one record, for example, records 1-10 to the first OUTFIL data
set, records 11-20 to the second OUTFIL data set, and so on. When
each OUTFIL data set has n records, the rotation starts again with
the first OUTFIL data set.
SPLIT1R can be used to
rotate once by a specified number of records. SPLIT1R continues with
the last OUTFIL data set instead of rotating back to the first OUTFIL
data set. When each OUTFIL data set has n records, the last OUTFIL data set will have the remainder of the records even
if that is more than n.
- LINES, HEADER1, TRAILER1, HEADER2, TRAILER2, SECTIONS,
and NODETAIL indicate that a report is to be produced for
an OUTFIL group, and specify the details of the report records to
be produced for the report. Reports can contain report records for
a report header (first page), report trailer (last page), page header
and page trailer (at the top and bottom of each page, respectively),
and section headers and trailers (before and after each section, respectively).
Data
records for the report result from the inclusion of OUTFIL input
records. All of the capabilities of the OUTREC, BUILD, OVERLAY, FINDREP, or IFTHEN parameters are available to
create reformatted data records from the OUTFIL input records. Each
set of sequential OUTFIL input records, with the same binary value
for a specified field, results in a corresponding set of data records
that is treated as a section in the report.
The length for
the data records must be equal to or greater than the maximum report
record length. OUTFIL data sets used for reports must have or will
be given ANSI control character format ('A' as in, for example, RECFM=FBA
or RECFM=VBA), and must allow an extra byte in the LRECL for the carriage
control character that DFSORT will add to each report and data record.
DFSORT uses these carriage control characters to control page ejects
and the placement of the lines in your report according to your specifications.
DFSORT uses appropriate carriage controls (for example, C'-' for triple
space) in header and trailer records when possible, to reduce the
number of report records written. DFSORT always uses the single space
carriage control (C' ') in data records. Although these carriage control
characters may not be shown when you view an OUTFIL data set (depending
upon how you view it), they will be used if you print the report.
- BLKCCH1, BLKCCT1 or BLKCCH2 can be used avoid
forcing a page eject for the report header, report trailer or first
page header, respectively, by using a blank instead of a '1' for
the ANSI control carriage character of its first line.
- REMOVECC can be used to remove the ANSI control characters
from a report. In this case, an 'A' is not added to or required for
the RECFM and an extra byte is not added to or required for the LRECL.
- IFTRAIL can be used to update count and total
values in an existing trailer (last) record based on the current
data records.
- Figure 1 illustrates the order in
which OUTFIL records and parameters are processed.
Figure 1. OUTFIL
Processing Order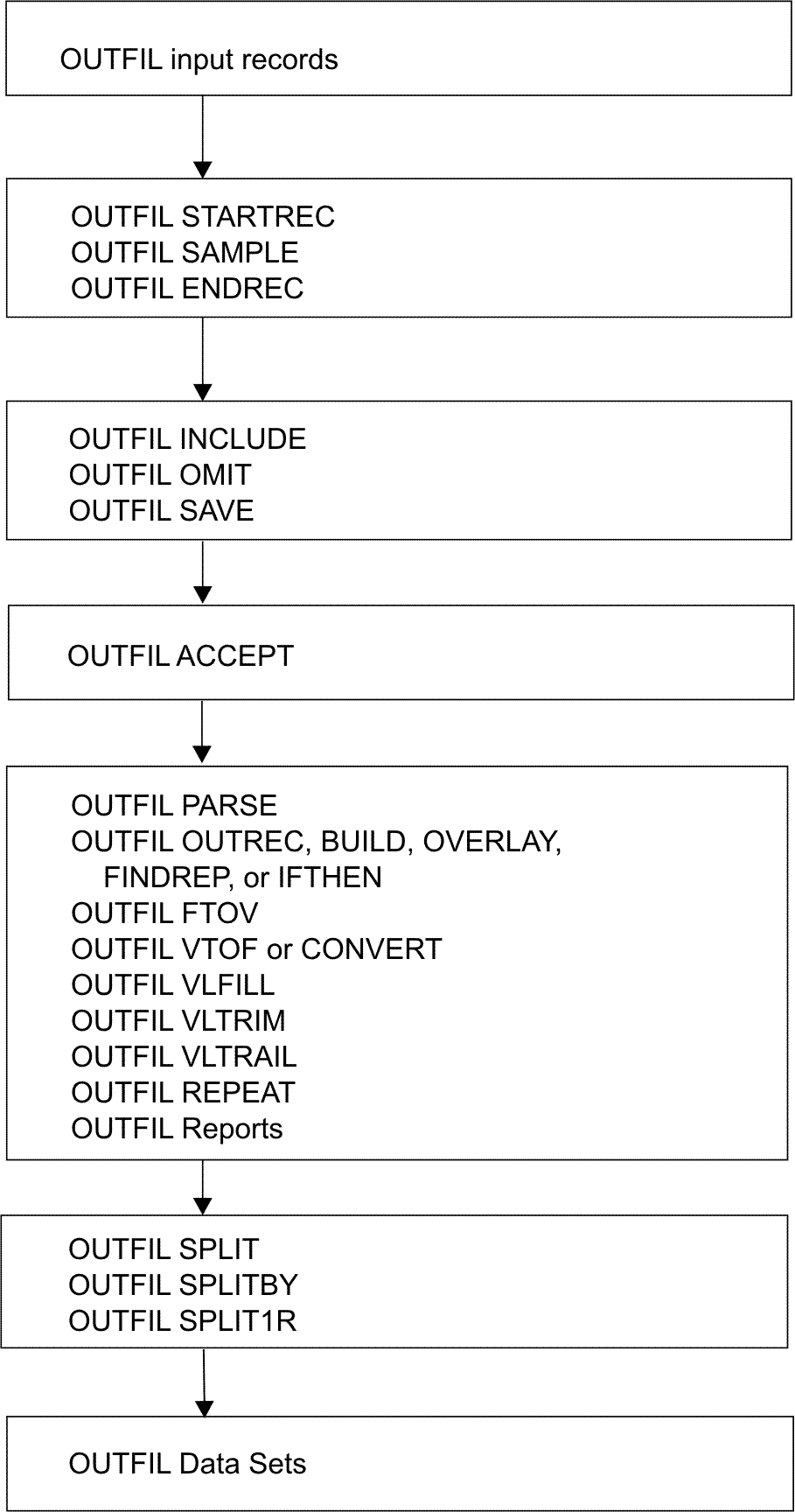
Note: - DFSORT accepts but does not process the following OUTFIL operands:
BLKSIZE=value, BUFLIM=value, BUFOFF=value, CARDS=value, CLOSE=value,
DISK, ESDS, EXIT, FREEOUT, KSDS, LRECL=value, NOTPMK, OPEN=value,
OUTPUT, PAGES=value, PRINT, PUNCH, REUSE, RRDS, SPAN, SYSLST, TAPE,
and TOL.
- Sample syntax is shown throughout this section. Complete OUTFIL
statement examples are shown and explained under OUTFIL features—examples.
- FNAMES
>>-FNAMES=--+-ddname-------------+-----------------------------><
| .-,----------. |
| V | |
'-(-----ddname---+-)-'
Specifies ddnames associated with the OUTFIL data
sets for this OUTFIL statement. The ddnames specified using the FNAMES
and FILES parameters constitute the output data sets for this OUTFIL
group to which all of the other parameters for this OUTFIL statement
apply.
If FNAMES specifies the ddname in effect for the SORTOUT data set (that is, whichever is in effect among
ddname from SORTOUT=ddname, ccccOUT from SORTDD=cccc, or SORTOUT) DFSORT
will treat the data set associated with that ddname as an OUTFIL data
set rather than as the SORTOUT data set. - ddname
- specifies a 1- through 8-character ddname. A DD statement must
be present for this ddname.
Sample Syntax: OUTFIL FNAMES=(OUT1,OUT2,PRINTER,TAPE)
OUTFIL FNAMES=BACKUP
Default
for FNAMES: If neither FNAMES nor FILES is specified for an OUTFIL
statement, the default ddname is: - ddname if SORTOUT=ddname is in effect
- ccccOUT if SORTDD=cccc is in effect and SORTOUT=ddname is not
in effect
- SORTOUT if neither SORTOUT=ddname nor SORTDD=cccc is in effect.
- FILES
>>-FILES=--+-d---------------+---------------------------------><
+-dd--------------+
+-OUT-------------+
| .-,-------. |
| V | |
'-(---+-d---+-+-)-'
+-dd--+
'-OUT-'
Specifies suffixes for ddnames to be associated
with the OUTFIL data sets for this OUTFIL statement. The ddnames
specified using the FNAMES and FILES parameters constitute the output
data sets for this OUTFIL group to which all of the other parameters
for this OUTFIL statement apply.
If FILES specifies the ddname
in effect for the SORTOUT data set (that is, whichever is in effect
among ddname from SORTOUT=name, ccccOUT from SORTDD=cccc,
or SORTOUT), DFSORT will treat the data set associated with that
ddname as an OUTFIL data set rather than as the SORTOUT data set. - d
- specifies the 1-character suffix to be used to form the ddname
SORTOFd or ccccOFd if SORTDD=cccc is in effect. A DD statement must
be present for this ddname.
- dd
- specifies the 2-character suffix to be used to form the ddname
SORTOFdd or ccccOFdd if SORTDD=cccc is in effect. A DD statement must
be present for this ddname.
- OUT
- specifies the suffix OUT is to be used to form the ddname SORTOUT
or ccccOUT if SORTDD=cccc is in effect. A DD statement must be present
for this ddname.
Sample Syntax: OUTFIL FILES=(1,2,PR,TP)
OUTFIL FILES=OUT
Default for
FILES: If neither FNAMES nor FILES is specified for an OUTFIL
statement, the default ddname is: - ddname if SORTOUT=ddname is in effect
- ccccOUT if SORTDD=cccc is in effect and SORTOUT=ddname is not
in effect
- SORTOUT if neither SORTOUT=ddname nor SORTDD=cccc is in effect.
- STARTREC
>>-STARTREC=n--------------------------------------------------><
Specifies the OUTFIL input record at which OUTFIL
processing is to start for this OUTFIL group. OUTFIL input records
before this starting record are not included in the data sets for
this OUTFIL group.
- n
- specifies the relative record number. The value for n starts at
1 (the first record) and is limited to 28 digits (15 significant digits).
Sample Syntax: OUTFIL FNAMES=SKIP20,STARTREC=21
Default
for STARTREC: 1.
- ENDREC
>>-ENDREC=n----------------------------------------------------><
Specifies the OUTFIL input record at which OUTFIL
processing is to end for this OUTFIL group. OUTFIL input records
after this ending record are not included in the data sets for this
OUTFIL group.
The ENDREC value must be equal to or greater than
the STARTREC value if both are specified on the same OUTFIL statement. - n
- specifies the relative record number. The value for n starts
at 1 (the first record) and is limited to 28 digits (15 significant
digits).
Sample Syntax: OUTFIL FNAMES=TOP10,ENDREC=10
OUTFIL FNAMES=FRONT,ENDREC=500
OUTFIL FNAMES=MIDDLE,STARTREC=501,ENDREC=2205
OUTFIL FNAMES=BACK,STARTREC=2206
Default for
ENDREC: The last OUTFIL input record.
- SAMPLE
>>-SAMPLE=-+-n-----+-------------------------------------------><
'-(n,m)-'
Specifies a sample of OUTFIL input records to
be processed for this OUTFIL group. The sample consists of the first
m records in every nth interval.
- n
- specifies the interval size. The value for n starts at 2 (sample
every other record) and is limited to 28 digits (15 significant digits).
- m
- specifies the number of records to be processed in each interval.
The value for m starts at 1 (process the first record in each interval)
and is limited to 28 digits (15 significant digits). If m is not
specified, 1 is used for m. If m is specified, it must be less than
n.
Sample Syntax: * PROCESS RECORDS 1, 6, 11, ...
OUTFIL FNAMES=OUT1,SAMPLE=5
* PROCESS RECORDS 1, 2, 1001, 1002, 2001, 2002
OUTFIL FNAMES=OUT2,SAMPLE=(1000,2),ENDREC=2500
* PROCESS RECORDS 23, 48, 73
OUTFIL FNAMES=OUT3,STARTREC=23,ENDREC=75,SAMPLE=25
* PROCESS RECORDS 1001, 1002, 1003, 1101, 1102, 1103, ...
OUTFIL FNAMES=OUT4,STARTREC=1001,SAMPLE=(100,3)
Default
for SAMPLE: None; must be specified.
- INCLUDE
>>-INCLUDE=-+-(logical expression)-+---------------------------><
+-ALL------------------+
'-NONE-----------------'
Selects the records to be included in the data
sets for this OUTFIL group.
The INCLUDE parameter operates in
the same way as the INCLUDE statement, except that:
- The INCLUDE statement applies to all input records; the INCLUDE
parameter applies only to the OUTFIL input records for its OUTFIL
group.
- FORMAT=f can be specified with the INCLUDE statement, but not
with the INCLUDE parameter. Thus, you can use FORMAT=f and p,m or
p,m,f fields with the INCLUDE statement, but you must only use p,m,f
fields with the INCLUDE parameter. For example:
INCLUDE FORMAT=BI,
COND=(5,4,LT,11,4,OR,21,4,EQ,31,4,OR,
61,20,SS,EQ,C'FLY')
OUTFIL INCLUDE=(5,4,BI,LT,11,4,BI,OR,21,4,BI,EQ,31,4,BI,OR,
61,20,SS,EQ,C'FLY')
- D2 format can be specified with the INCLUDE statement, but not
with the INCLUDE parameter.
See INCLUDE control statement for complete details.
- logical expression
- specifies one or more relational conditions logically combined
based on fields in the OUTFIL input record. If the logical expression
is true for a given record, the record is included in the data sets
for this OUTFIL group.
- ALL
- specifies that all of the OUTFIL input records are to be included
in the data sets for this OUTFIL group.
- NONE
- specifies that none of the OUTFIL input records are to be included
in the data sets for this OUTFIL group.
Sample Syntax: OUTFIL FNAMES=J69,INCLUDE=(5,3,CH,EQ,C'J69')
OUTFIL FNAMES=J82,INCLUDE=(5,3,CH,EQ,C'J82')
Default
for INCLUDE: ALL.
- OMIT
>>-OMIT=-+-(logical expression)-+------------------------------><
+-ALL------------------+
'-NONE-----------------'
Selects the records to be omitted from the data
sets for this OUTFIL group.
The OMIT parameter operates in
the same way as the OMIT statement, except that: - The OMIT statement applies to all input records; the OMIT parameter
applies only to the OUTFIL input records for its OUTFIL group.
- FORMAT=f can be specified with the OMIT statement, but not with
the OMIT parameter. Thus, you can use FORMAT=f and p,m or p,m,f fields
with the OMIT statement, but you must only use p,m,f fields with the
OMIT parameter. For example:
OMIT FORMAT=BI,
COND=(5,4,LT,11,4,OR,21,4,EQ,31,4,OR,
61,20,SS,EQ,C'FLY')
OUTFIL OMIT=(5,4,BI,LT,11,4,BI,OR,21,4,BI,EQ,31,4,BI,OR,
61,20,SS,EQ,C'FLY')
- The D2 format can be specified with the OMIT statement, but not
with the OMIT parameter.
See OMIT control statement and INCLUDE control statement for complete details.
- logical expression
- specifies one or more relational conditions logically combined
based on fields in the OUTFIL input record. If the logical expression
is true for a given record, the record is omitted from the data sets
for this OUTFIL group.
- ALL
- specifies that all of the OUTFIL input records are to be omitted
from the data sets for this OUTFIL group.
- NONE
- specifies that none of the OUTFIL input records are to be omitted
from the data sets for this OUTFIL group.
Sample Syntax: OUTFIL FILES=01,OMIT=NONE
OUTFIL OMIT=(5,1,BI,EQ,B'110.....')
OUTFIL FNAMES=(OUT1,OUT2),
OMIT=(7,2,CH,EQ,C'32',OR,18,3,CH,EQ,C'XYZ')
Default
for OMIT: NONE.
- SAVE
>>-SAVE--------------------------------------------------------><
Specifies that OUTFIL input records not included
by STARTREC, ENDREC, ACCEPT, SAMPLE, INCLUDE
or OMIT for any other OUTFIL group are to be included in the data
sets for this OUTFIL group. SAVE operates in a global fashion over
all of the other OUTFIL statements for which SAVE is not specified,
enabling you to keep any OUTFIL input records that would not be kept
otherwise. SAVE will include the same records for each group for which
it is specified.
Sample Syntax: OUTFIL INCLUDE=(8,6,CH,EQ,C'ACCTNG'),FNAMES=GP1
OUTFIL INCLUDE=(8,6,CH,EQ,C'DVPMNT'),FNAMES=GP2
OUTFIL SAVE,FNAMES=NOT1OR2
Default for SAVE: None;
must be specified.
- ACCEPT
>>-ACCEPT=n----------------------------------------------------><
Specifies the number of OUTFIL input records to
be accepted for processing for this OUTFIL group. A record is accepted
if it is not deleted by STARTREC, ENDREC, SAMPLE, INCLUDE or OMIT
processing for the group. After n OUTFIL input records have been
accepted, additional OUTFIL input records are not included in the
data sets for this OUTFIL group.
- n
- specifies the number of records to be accepted. The value for
n starts at 1 and is limited to 28 digits (15 significant digits).
ACCEPT=n operates in a similar way to the ENDREC=n
option. However, whereas ENDREC=n stops processing OUTFIL input records
for a group at relative record n, ACCEPT=n stops processing
OUTFIL input records for a group after n records have been "accepted".
If both ACCEPT=n and ENDREC=n are specified, processing will stop
when the first criteria is met.
Sample Syntax: OUTFIL FNAMES=OUT1,INCLUDE=(11,3,CH,EQ,C'D51'),ACCEPT=3
OUTFIL FNAMES=OUT2,STARTREC=5,SAMPLE=1000,ACCEPT=12
Default
for ACCEPT: None; must be specified.
- PARSE
.-,-------------------------------------------------.
| .-,----------------------------. |
V V | |
>>-PARSE=(---+-%n=---+--(----+-FIXLEN=m-----------------+-+--)-+-)-><
+-%nn=--+ +-+-ABSPOS=p-+-------------+
+-%nnn=-+ | +-ADDPOS=x-+ |
'-%=----' | '-SUBPOS=y-' |
| .-,--------------------. |
| V | |
+---+-STARTAFT=string--+-+-+
| +-STARTAFT=an------+ |
| +-STARTAFT=BLANKS--+ |
| +-STARTAT=string---+ |
| +-STARTAT=an-------+ |
| +-STARTAT=BLANKS---+ |
| '-STARTAT=NONBLANK-' |
| .-,------------------. |
| V | |
+---+-ENDBEFR=string-+-+---+
| +-ENDBEFR=an-----+ |
| +-ENDBEFR=BLANKS-+ |
| +-ENDAT=string---+ |
| +-ENDAT=an-------+ |
| '-ENDAT=BLANKS---' |
+-+-PAIR=APOST-+-----------+
| '-PAIR=QUOTE-' |
'-REPEAT=v-----------------'
This
operand allows you to extract variable position/length fields into
fixed parsed fields. Parsed fields (%n, %nn or
%nnn) can be used where fixed position/length fields (p,m) can
be used in the BUILD (or OUTREC) or OVERLAY operands as described
later in this section.
Note: Although you can use
%n (%0-%9), %nn (%00-%99) or %nnn (%000-%999) for a parsed field,
for convenience in this book %nn will be used in general when
referring to a parsed field. %n, %0n or %00n can be used interchangeably
for parsed field n (for example, %1, %01 or %001 for parsed field
1). %nn or %0nn can be used interchangeably for parsed field nn (for
example, %12 or %012 for parsed field 12).
PARSE can be
used for many different types of variable fields including delimited
fields, comma separated values (CSV), tab separated values, blank
separated values, keyword separated fields, null-terminated
strings, and so on. You can assign up to 1000 parsed
fields (%0-%999) to the variable fields you
want to extract.
Note that if all of the fields in your records
have fixed positions and lengths, you don't need to use PARSE. But
if any of the fields in your records have variable positions or lengths,
you can use PARSE to treat them as fixed parsed fields in BUILD or
OVERLAY. You can mix p,m fields (fixed fields) and %nn fields (parsed
fields) in BUILD and OVERLAY.
For each %nn parsed field, you
define where the data to be extracted starts and ends, and the length
(m) of the fixed field to contain the extracted data. For example,
if your input records contained CSV data as follows: AA,BBBB,C,DDDDD
EEEEE,,F,GG
HHH,IIIII,JJ,K
and you wanted to reformat the data into
fixed positions like this: AA BBBB C DDDDD
EEEEE F GG
HHH IIIII JJ K
you could use this OUTFIL
statement: OUTFIL PARSE=(%01=(ENDBEFR=C',',FIXLEN=5),
%02=(ENDBEFR=C',',FIXLEN=5),
%03=(ENDBEFR=C',',FIXLEN=5),
%04=(FIXLEN=5)),
BUILD=(1:%01,11:%02,21:%03,31:%04)
The
PARSE operand: - assigns %01 to the first parsed field, and defines it as starting
at position 1 and ending before the next (first) comma with a fixed
length of 5 bytes
- assigns %02 to the second parsed field, and defines it as starting
after the (first) comma and ending before the next (second) comma
with a fixed length of 5 bytes
- assigns %03 to the third parsed field, and defines it as starting
after the (second) comma and ending before the next (third) comma
with a fixed length of 5 bytes
- assigns %04 to the fourth parsed field, and defines it as starting
after the (third) comma and ending after 5 bytes with a fixed length
of 5 bytes
You can start extracting data: - at a specific position (ABSPOS=p), a relative position (ADDPOS=x
or SUBPOS=y)
- after the start of one or more specific strings (STARTAFT=string),
alphanumeric character sets (STARTAFT=an) or blanks (STARTAFT=BLANKS)
- at the start of one or more specific strings (STARTAT=string),
alphanumeric character sets (STARTAT=an) or blanks (STARTAT=BLANKS)
or a nonblank (STARTAT=NONBLANK).
You can end extracting data: - before the start of one or more specific strings (ENDBEFR=string),
alphanumeric character sets (ENDBEFR=an) or blanks (ENDBEFR=BLANKS),
- at the end of one or more specific strings (ENDAT=string),
alphanumeric character sets (ENDAT=an) or blanks (ENDAT=BLANKS)
- after a specified number of bytes (FIXLEN=m without ENDBEFR
or ENDAT).
For STARTAFT=an, STARTAT=an, ENDBEFR=an
and ENDAT=an, you can specify one of the following for an to indicate
the alphanumeric character set you want to use: - UC: Uppercase characters (A-Z)
- LC: Lowercase characters (a-z)
- MC: Mixed case characters (A-Z, a-z)
- UN: Uppercase and numeric characters (A-Z, 0-9)
- LN: Lowercase and numeric characters (a-z, 0-9)
- MN: Mixed case and numeric characters (A-Z, a-z, 0-9)
- NUM: Numeric characters (0-9)
Multiple STARTAFT/STARTAT strings, UC, LC,
MC, UN, LN, MN, NUM, BLANKS or NONBLANK can be used for a %nn parsed
field to search for more than one string, set of characters, blanks
or a nonblank. The first search satisfied is used.
Multiple ENDBEFR/ENDAT strings, UC, LC, MC, UN, LN,
MN, NUM, or BLANKS can be used for a %nn parsed field to search for
more than one string, set of characters or blanks. The first search
satisfied is used.
For each record, each %nn and % parsed field
you define is processed according to the suboperands you define, in
the following order: - ABSPOS or ADDPOS or SUBPOS
- STARTAFT, STARTAT and PAIR
- ENDBEFR, ENDAT and PAIR
- FIXLEN
As each %nn parsed field is processed, data is extracted
according to the suboperands you specify.
In addition, as each
%nn or % parsed field is processed, the Start Pointer for the next
parsed field advances through the record according to the suboperands
you specify. By default, for the first parsed field, the Start Pointer
is set to position 1 for fixed-length records or to position 5 for
variable-length records, and the Start Pointer for each subsequent
%nn parsed field uses the Start Pointer as set by the previous %nn
parsed field. For any parsed field, the Start Pointer advances as
follows depending on the suboperands specified,
and may advance more than once (for example, if STARTAFT and ENDBEFR
are both specified, or if STARTAT and FIXLEN are both specified): - if ABSPOS=p is specified, the Start Pointer is set to position
p.
- if ADDPOS=x is specified, the Start Pointer is incremented by
x.
- if SUBPOS=y is specified, the Start Pointer is decremented by
y.
- if STARTAFT=string or STARTAT=string is specified, the search
for string starts at the Start Pointer. If string is found, the Start
Pointer is set to the byte after the end of the string. If string
is not found, the current parsed field and any subsequent parsed fields
contain all blanks.
- if STARTAFT=an or STARTAT=an is specified, the search
for the character in the specified alphanumeric set starts at the
Start Pointer. If a character in the set is found, the Start Pointer
is set to the byte after the character. If a character in the set
is not found, the current parsed field and any subsequent parsed fields
contain all blanks.
- if STARTAFT=BLANKS or STARTAT=BLANKS is specified, the search
for blanks starts at the Start Pointer. If a blank is found, the
Start Pointer is set to the next nonblank. If a blank is not found,
the current parsed field and any subsequent parsed fields contain
all blanks.
- if STARTAT=NONBLANK is specified, the search for a nonblank starts
at the Start Pointer. If a nonblank is found, the Start Pointer is
set to the nonblank. If a nonblank is not found, the current parsed
field and any subsequent parsed fields contain all blanks.
- if ENDBEFR=string or ENDAT=string is specified, the search for
string starts at the Start Pointer. If string is found, the Start
Pointer is set to the byte after the end of the string. If string
is not found, data for this parsed field is extracted up to the end
of the record. Subsequent parsed fields contain all blanks.
- if ENDBEFR=an or ENDAT=an is specified, the search
for the character in the specified alphanumeric set starts at the
Start Pointer. If a character in the set is found, the Start Pointer
is set to the byte after the character. If a character in the set
is not found, data for this parsed field is extracted up to the end
of the record. Subsequent parsed fields contain all blanks.
- if ENDBEFR=BLANKS or ENDAT=BLANKS is specified, the search for
blanks starts at the Start Pointer. If a blank is found, the Start
Pointer is set to the next nonblank. If a blank is not found, data
for this parsed field is extracted up to the end of the record. Subsequent
parsed fields contain all blanks.
- if ENDBEFR and ENDAT are not specified and FIXLEN=m is specified,
the Start Pointer is set m bytes past the start of the extracted data.
- if the Start Pointer advances past the end of the record, PARSE
processing stops.
For example, if you had these records as input: 11*+23 NEW MAXCC=00 (Monica) 18
1*-6 OLD MAXCC=04 (Joey) -2735
232*+86342 SHR MAXCC=04 (Rachel) 0
and you wanted this
output: Monica MAXCC=00 +000023 011 18
Joey MAXCC=04 -000006 001 -2735
Rachel MAXCC=04 +086342 232 0
you could use
this OUTFIL statement: OUTFIL FNAMES=OUT1,
PARSE=(%00=(ENDBEFR=C'*',FIXLEN=3),
%01=(ENDBEFR=BLANKS,FIXLEN=6),
%02=(STARTAT=C'MAX',FIXLEN=8),
%03=(STARTAFT=C'(',ENDBEFR=C')',FIXLEN=6),
%04=(STARTAFT=BLANKS,FIXLEN=5)),
BUILD=(%03,11:%02,21:%01,SFF,M26,LENGTH=7,
30:%00,UFF,M11,LENGTH=3,35:%04,JFY=(SHIFT=RIGHT))
For
this example, the Start Pointer advances as follows for the first
record: - For %00: Set Start Pointer to position 1. Start searching for
'*' end string at position 1. Extract '11' (per
ENDBEFR=C'*'). Set Start Pointer after '*' (at '+').
- For %01: Start searching for end blank at the Start Pointer (at
'+'). Extract '+23' (per ENDBEFR=BLANKS). Set Start Pointer after
the blanks (at 'N').
- For %02: Start searching for 'MAX' start string at the Start
Pointer (at 'N'). Extract 'MAXCC=00' (per FIXLEN=8). Increment Start
Pointer by m (8) bytes from the start of the extracted string (at
blank after '00').
- For %03: Start searching for '(' start string at Start Pointer
(at blank after '00'). Set Start Pointer after '(' (at 'M'). Start
searching for ')' end string at Start Pointer (at 'M'). Extract 'Monica'
(per ENDBEFR=C')'). Set Start Pointer after ')' (at blank after ')').
- For %04: Start searching for start blank at the Start
Pointer (at blank after ')'). Extract '18 ' (per FIXLEN=5).
If the Start Pointer advances past the end
of the record, PARSE processing stops. For example, if you had these
input records: First=George Last=Washington
First=John Middle=Quincy Last=Adams
and you used this
OUTFIL statement: OUTFIL FNAMES=OUT1,
PARSE=(%00=(STARTAFT=C'First=',ENDBEFR=C' ',FIXLEN=12),
%01=(STARTAFT=C'Middle=',ENDBEFR=C' ',FIXLEN=12),
%02=(STARTAFT=C'Last=',ENDBEFR=C' ',FIXLEN=12)),
BUILD=(%00,%01,%02)
the %01 parsed field (middle
name) is not found in the first record, so PARSE processing stops
and the %02 parsed field is set to blanks. You can handle this kind
of possible missing field situation by using IFTHEN PARSE instead
of PARSE. For example: OUTFIL FNAMES=OUT1,
IFTHEN=(WHEN=INIT,
PARSE=(%00=(STARTAFT=C'First=',ENDBEFR=C' ',FIXLEN=12))),
IFTHEN=(WHEN=INIT,
PARSE=(%01=(STARTAFT=C'Middle=',ENDBEFR=C' ',FIXLEN=12))),
IFTHEN=(WHEN=INIT,
PARSE=(%02=(STARTAFT=C'Last=',ENDBEFR=C' ',FIXLEN=12)),
BUILD=(%00,%01,%02))
By default, the Start Pointer
is set to 1 (F) or 5 (V) for each IFTHEN PARSE, so the missing middle
name in the first record does not prevent the last name from being
extracted. See the discussion of "IFTHEN" for more
information on IFTHEN PARSE.
You must define each %nn field
with PARSE before you use it in BUILD or OVERLAY, so generally you
would want to specify PARSE before BUILD or OVERLAY. If you define
a %nn field with PARSE, but do not use it in BUILD or OVERLAY, data
will not be extracted for that parsed field.
Each %nn parsed
field (%0-%999) can only be defined once per
run with PARSE, but can be used as many times as needed in BUILD or
OVERLAY.
The %nn parsed fields defined for a particular source
(INREC, OUTREC or OUTFIL) can only be used in the BUILD or OVERLAY
operands for that source. Generally, you will only use PARSE for
one source (for example, INREC) per run. But you could define a separate
set of %nn parsed fields for each source, if needed. For example,
you could define %21 and %22 for the INREC statement, %101,
%102 and %103 for the OUTREC statement, %40 and %45 for OUTFIL
statement 1, and %30, %31 and %32 for OUTFIL statement 2. You could
then use %21 and %22 for INREC BUILD or OVERLAY, %102
and %103 for OUTREC BUILD or OVERLAY, %40 and %45 for OUTFIL
statement 1 BUILD or OVERLAY, and %30, %31 and %32 for OUTFIL statement
2 BUILD or OVERLAY. Note that you could not, for example, use %21
and %22 for OUTREC BUILD or OVERLAY.
If you specify PARSE=(...),IFTHEN=(...)
or IFTHEN=(...),PARSE=(...), DFSORT will terminate. If you need to
specify PARSE with IFTHEN, specify it within one or more individual
IFTHEN clauses, as appropriate. For details, see the description of
"IFTHEN".
- %n, %nn or %nnn
- Assigns %n, %nn or %nnn to a parsed field.
The variable-length data defined for the parsed field is extracted
to a fixed length area (padded with blanks or truncated as appropriate)
and can be used where a p,m field can be used
in BUILD or OVERLAY.
n can be 0 to 9, nn can be
00 to 99, and nnn can be 000 to 999 but each %n, %nn or %nnn value
can only be defined once per run. This gives you a maximum of 1000
parsed fields per run.
%0 to %9 will be treated
as equivalent to %00 to %09. %010 to %099 will be treated as equivalent
to %10 to %99. You can define parse field n with %n, %0n or %00n;
you can use %n, %0n and %00n interchangeably. You can define
parse field nn with %nn or %0nn; you can use %nn and %0nn interchangeably.
Sample
Syntax
OUTFIL PARSE=(%99=(ABSPOS=6,STARTAT=C'KW=(',ENDAT=C')',FIXLEN=20),
%10=(ENDBEFR=UC,ENDBEFR=C'$',FIXLEN=5),
%03=(STARTAFT=BLANKS,FIXLEN=10)),
OVERLAY=(1:1,5,%3,C'=',%99,1:1,36,SQZ=(SHIFT=LEFT),%010)
- %
- Specifies a parsed field to be ignored. No data is extracted,
but the starting point for the next parsed field advances according
to the suboperands specified. Use % when you don't need the data
from a particular field, but you do need to get to the next field.
For example, if we had the four CSV fields shown earlier as input,
but we only wanted to extract the first and fourth fields, we could
use this OUTFIL statement:
OUTFIL PARSE=(%01=(ENDBEFR=C',',FIXLEN=5),
%=(ENDBEFR=C','),
%=(ENDBEFR=C','),
%04=(FIXLEN=5)),
BUILD=(1:%01,11:%04,21:%01,HEX)
Data is extracted
for %01 (first field) and %04 (fourth field), but not for % (second
and third fields).
- FIXLEN=m
- Specifies the length (m) of the fixed area to contain the extracted
variable-length data for this %nn fixed parsed field. m can be 1
to 32752. You must specify FIXLEN=m for each %nn parsed field. FIXLEN=m
is optional for a % ignored field.
When %nn is specified in BUILD
or OVERLAY, the variable-length data is extracted to the fixed area
and then used for BUILD or OVERLAY processing. The fixed area always
contains m bytes. If the extracted data is longer than m, the fixed
area contains the first m bytes of the extracted data (the data is
truncated on the right to m bytes). If the extracted data is shorter
than m, the fixed area contains the extracted data padded with blanks
on the right to m bytes. If no data is extracted, the fixed area
contains all blanks.
The length m from FIXLEN=m for fixed parsed
fields (%nn) corresponds to the length (m) for fixed fields (p,m).
Keep in mind that %nn fields are left-aligned and may be padded on
the right with blanks. You must ensure that the data in each %nn
field and its length (m) are valid for the way you want to use that
%nn field in BUILD or OVERLAY. For example, if you had these records
as input: 123,8621
1,302
18345,17
and you wanted this output: 1.23 86.21
0.01 3.02
183.45 0.17
you could use this OUTFIL statement: OUTFIL PARSE=(%00=(ENDBEFR=C',',FIXLEN=5),
%01=(FIXLEN=5)),
BUILD=(%00,UFF,EDIT=(IIT.TT),2X,%01,UFF,EDIT=(IIT.TT))
Note
that the 5-byte extracted parsed fields for %00 are left-aligned and
padded with blanks (b) like this: 123bb
1bbbb
18345
and the 5-byte extracted parsed fields for %01 are
left-aligned and padded with blanks (b) like this: 8621b
302bb
17bbb
Thus, you cannot use numeric formats like ZD or
FS for these parsed fields, but you can use UFF. Note also that you
must ensure that m from FIXLEN=m for each %nn parsed field is valid
for the specific BUILD or OVERLAY item in which you use %nn. For
example, you could use 1-44 as m for UFF, but you couldn't use 45
as m. If ENDBEFR and ENDAT are not specified, the Start Pointer
is set m bytes past the start of the extracted data. For example,
if you had this record as input: MAX=(ABCDEF)
and
you specified: OUTFIL PARSE=(%100=(STARTAT=C'MAX',FIXLEN=8),
%101=(FIXLEN=3),%102=(FIXLEN=1)),
BUILD=(%100,12:%101,20:%102)
The output record
would be: MAX=(ABC DEF )
Sample
Syntax
OUTFIL PARSE=(%00=(STARTAFT=C'KW=',FIXLEN=12)),
BUILD=(%00)
- ABSPOS=p
- Sets the Start Pointer for this parsed field to p. p can be 1
to 32752. By default, the Start Pointer for the first %nn parsed field
is position 1 for fixed-length records or position 5 for variable-length
records, and the Start Pointer for each subsequent %nn parsed field
is the Start Pointer set by the previous %nn field. You can use ABSPOS=p
to set the Start Pointer to position p to override the default Start
Pointer. If the resulting Start Pointer is less than
position 5 for variable length records, it will be set to position
5.
Example
If your input is: ****|BB|CCCC|
****|EEEE|FF|
and you wanted to reformat the data into
fixed positions like this: **** BB CCCC
**** EEEE FF
you could use this OUTFIL statement: OUTFIL PARSE=(%01=(ABSPOS=6,ENDBEFR=C'|',FIXLEN=4),
%02=(ENDBEFR=C'|',FIXLEN=4)),
BUILD=(1,4,X,%01,X,%02)
The initial Start Pointer
for the %01 parsed field is set to position 6 instead of to position
1.
- ADDPOS=x
- Increments the Start Pointer for this parsed field by x. x can
be 1 to 32752. By default, the Start Pointer for the first %nn parsed
field is position 1 for fixed-length records or position 5 for variable-length
records, and the Start Pointer for each subsequent %nn parsed field
is the Start Pointer set by the previous %nn field. You can use ADDPOS=x
to increment the Start Pointer by x to override the default Start
Pointer.
Sample Syntax
OUTFIL PARSE=(%00=(ENDAT=C'||',FIXLEN=10),
%01=(ADDPOS=5,STARTAFT=C';',FIXLEN=6)),
BUILD=(%00,TRAN=ALTSEQ,%01)
- SUBPOS=y
- Decrements the Start Pointer for this parsed field by y. y can
be 1 to 32752. By default, the Start Pointer for the first %nn parsed
field is position 1 for fixed-length records or position 5 for variable-length
records, and the Start Pointer for each subsequent %nn parsed field
is the Start Pointer set by the previous %nn field. You can use SUBPOS=y
to decrement the Start Pointer by x to override the default Start
Pointer. If the resulting Start Pointer is less than position 1 for
fixed-length records, it will be set to position 1. If the resulting
Start Pointer is less than position 5 for variable-length
records, it will be set to position 5.
Sample Syntax
OUTFIL PARSE=(%00=(ENDBEFR=C'|;|',FIXLEN=10),
%01=(SUBPOS=1,STARTAT=C'|',ENDAT=C'|',FIXLEN=12)),
BUILD=(%00,TRAN=ALTSEQ,%01)
- STARTAFT=string
- Data is to be extracted for this parsed field starting after the
last byte of the specified string. The search for the string begins
at the Start Pointer. If the specified string is not found, data
is not extracted for this parsed field or any subsequent parsed fields.
If the specified string is found, data is extracted to the fixed
area for this parsed field starting at the byte after the end of the
string, and the Start Pointer is set to the byte after the end of
the string.
string can be 1 to 256 characters specified using a
character string constant (C'xx...x') or a hexadecimal string constant
(X'yy...yy'). See INCLUDE control statement for
details of coding character and hexadecimal string constants.
Example
If
your input is: MAX=25,832 MIN=2,831 $4
MAX=1,275 MIN=17 %3
and you wanted your output to
contain MAX-MIN, you could use this OUTFIL statement: OUTFIL PARSE=(%00=(STARTAFT=C'MAX=',ENDBEFR=X'40',FIXLEN=6),
%01=(STARTAFT=C'MIN=',ENDBEFR=X'40',FIXLEN=6)),
OVERLAY=(50:C'DELTA: ',%00,UFF,SUB,%01,UFF,TO=ZD,LENGTH=8)
- STARTAFT=an
- Data is to be extracted for this parsed field starting after the
first character found from the specified alphanumeric set. The search
for a character in the specified set begins at the Start Pointer.
If a character in the set is not found, data is not extracted for
this parsed field or any subsequent parsed field. If a character
in the set is found, data is extracted to the fixed area for this
parsed field starting at the byte after that character, and the Start
Pointer is set to the byte after that character.
an can
be one of the following alphanumeric character sets: - UC: Uppercase characters (A-Z)
- LC: Lowercase characters (a-z)
- MC: Mixed case characters (A-Z, a-z)
- UN: Uppercase and numeric characters (A-Z, 0-9)
- LN: Lowercase and numeric characters (a-z, 0-9)
- MN: Mixed case and numeric characters (A-Z, a-z, 0-9)
- NUM: Numeric characters (0-9)
Note that STARTAFT=an is equivalent to specifying a STARTAFT=c
operand for each character in the set. For example: %=(STARTAFT=NUM)
is
equivalent to specifying %=(STARTAFT=C'0',STARTAFT=C'1',STARTAFT=C'2',STARTAFT=C'3',
STARTAFT=C'4',STARTAFT=C'5',STARTAFT=C'6',STARTAFT=C'7',
STARTAFT=C'8',STARTAFT=C'9')
You can add
more characters to a set with additional STARTAFT operands. For example,
if you wanted the lowercase characters and the $ and @ characters
for the set, you could use: %05=(STARTAFT=LC,STARTAFT=C'$',STARTAFT=C'@',FIXLEN=10)
Example
If
your input is: a123 1Stop
Z0056 2rest
q8 3go
and you wanted your output to be: 000123 STOP
000056 REST
000008 GO
you could use this OUTFIL statement: OUTFIL PARSE=(%00=(STARTAFT=MC,ENDBEFR=C' ',FIXLEN=5),
%01=(STARTAFT=NUM,FIXLEN=8)),
BUILD=(%00,UFF,EDIT=(TTTTTT),X,%01,TRAN=LTOU)
- STARTAFT=BLANKS
- Data is to be extracted for this parsed field starting at the
first nonblank after one or more blanks. The search for a blank begins
at the Start Pointer. If a blank is not found, data is not extracted
for this parsed field or any subsequent parsed fields. If a blank
is found, data is extracted to the fixed area for this parsed field
starting at the first nonblank, and the Start Pointer is set to the
first nonblank.
Example
If your input is: Frank D28
Vicky D52
and you wanted your output
to be: Frank D28
Vicky D52
you could use this OUTFIL statement: OUTFIL PARSE=(%00=(STARTAFT=BLANKS,FIXLEN=8),
%01=(STARTAFT=BLANKS,FIXLEN=3)),
BUILD=(%00,14:%01)
- STARTAT=string
- Data is to be extracted for this parsed field starting at the
first byte of the specified string. The search for the string begins
at the Start Pointer. If the specified string is not found, data
is not extracted for this parsed field or any subsequent parsed fields.
If the specified string is found, data is extracted to the fixed
area for this parsed field starting at the first byte of the string,
and the Start Pointer is set to the byte after the end of the string.
string
can be 1 to 256 characters specified using a character string constant
(C'xx...x') or a hexadecimal string constant (X'yy...yy'). See INCLUDE control statement for details of coding character
and hexadecimal string constants.
Example
If
your input is: MAX=58321 MIN=00273
MAX=01275 MIN=00017
and you wanted your output to
be: MAX=58321 MIN=00273
MAX=01275 MIN=00017
you could use this OUTFIL statement: OUTFIL PARSE=(%00=(STARTAT=C'MAX=',FIXLEN=9),
%01=(STARTAT=C'MIN=',FIXLEN=9)),
BUILD=(%00,X,%01)
- STARTAT=an
- Data is to be extracted for this parsed field starting at the
first character found from the specified alphanumeric set. The search
for a character in the specified set begins at the Start Pointer.
If a character in the set is not found, data is not extracted for
this parsed field or any subsequent parsed field. If a character
in the set is found, data is extracted to the fixed area for this
parsed field starting at that character, and the Start Pointer is
set to the byte after that character.
See STARTAFT=an previously
in this section for more information on using the available alphanumeric
character sets.
Example
If your input is: $@$321%@%$Frank
@053$Susan
%%%$$836%$Vicky
and you wanted your output to contain
the amount and name fields: 321 Frank
053 Susan
836 Vicky
you could use this OUTFIL statement: OUTFIL PARSE=(%00=(STARTAT=NUM,FIXLEN=3),
%01=(STARTAT=UC,FIXLEN=10)),
BUILD=(%00,X,%01)
- STARTAT=BLANKS
- Data is to be extracted for this parsed field starting at the
first blank. The search for a blank begins at the Start Pointer.
If a blank is not found, data is not extracted for this parsed field
or any subsequent parsed fields. If a blank is found, data is extracted
to the fixed area for this parsed field starting at the first blank,
and the Start Pointer is set to the first nonblank.
- STARTAT=NONBLANK
- Data is to be extracted for this parsed field starting at the
first nonblank. The search for a nonblank begins at the Start Pointer.
If a nonblank is not found, data is not extracted for this parsed
field or any subsequent parsed fields. If a nonblank is found, data
is extracted to the fixed area for this parsed field starting at the
nonblank, and the Start Pointer is set to the nonblank.
Example
If
your input is: Frank D28
Victoria D52
Holly D15
Roberta D52
and you wanted your output to be: Frank D28
Victoria D52
Holly D15
Roberta D52
you could use this OUTFIL statement: OUTFIL PARSE=(%00=(STARTAT=NONBLANK,ENDBEFR=BLANKS,FIXLEN=8),
%01=(FIXLEN=3)),
BUILD=(%00,14:%01)
Note: Multiple
STARTAFT/STARTAT strings, UC, LC, MC, UN, LN, MN, NUM, BLANKS or NONBLANK
can be used for a %nn parsed field to search for more than one string,
set of characters, blanks or a nonblank. The first search satisfied
is used.
Example
If your input is: 12 MAXCC=08
58 MINCC=00
MAXCC=04
and you wanted your output to be: MAXCC=08
MINCC=00
MAXCC=04
you could use this OUTFIL statement: OUTFIL PARSE=(%00=(STARTAT=C'MAXCC=',STARTAT=C'MINCC=',
FIXLEN=8)),BUILD=(%00)
- ENDBEFR=string
- Data is to be extracted for this parsed field ending before the
first byte of the specified string. The search for the string begins
at the Start Pointer. If the specified string is not found, data
is extracted to the fixed area for this parsed field up to
the end of the record, but data is not extracted for any subsequent
parsed fields. If the specified string is found, data is extracted
to the fixed area for this parsed field up to the byte before the
start of the string, and the Start Pointer is set to the byte after
the end of the string.
string can be 1 to 256 characters specified
using a character string constant (C'xx...x') or a hexadecimal string
constant (X'yy...yy'). See INCLUDE control statement for
details of coding character and hexadecimal string constants.
Example
If
your input is: Morgan Hill;California;5000:
San Jose;California;2000:
Austin;Texas;8000:
and you wanted your output to be: Morgan Hill California 5000
San Jose California 2000
Austin Texas 8000
you could use this OUTFIL
statement: OUTFIL PARSE=(%00=(ENDBEFR=C';',FIXLEN=14),
%01=(ENDBEFR=C';',FIXLEN=12),
%02=(ENDBEFR=C':',FIXLEN=4)),
BUILD=(%00,%01,%02)
ENDBEFR=X'00'
can be used to extract null-terminated strings to fixed parsed fields.
Example
If your input contains
null-terminated strings that look like this in hex: F0F5F800
F1F2F3F4F500
F9F7F2F000
F500
F0F0F3F700
and you wanted to convert the null-terminated
strings to right-aligned numeric values like this: 58
12345
9720
5
37
you could use this OUTFIL statement: OUTFIL PARSE=(%01=(ENDBEFR=X'00',FIXLEN=5)),
BUILD=(%01,UFF,EDIT=(IIIIT))
- ENDBEFR=an
- Data is to be extracted for this parsed field ending before the
first character found from the specified alphanumeric set.
The search for a character in the specified set begins at the Start
Pointer. If a character in the set is not found, data is extracted
to the fixed area for this parsed field up to the end of the record,
but data is not extracted for any subsequent parsed fields. If a
character in the set is found, data is extracted to the fixed area
for this parsed field up to the byte before that character,
and the Start Pointer is set to the byte after that character.
See
STARTAFT=an previously in this section for more information on using
the available alphanumeric character sets.
Example
If
your input is: $$$$Samantha
$052
$$$$$cat
$$358721
and you wanted to extract the leading $ characters
in each input record, you could use this OUTFIL statement: OUTFIL PARSE=(%10=(ENDBEFR=MN,FIXLEN=10)),
BUILD=(%10)
- ENDBEFR=BLANKS
- Data is to be extracted for this parsed field ending before the
first blank. The search for a blank begins at the Start Pointer.
If a blank is not found, data is extracted to the fixed area for
this parsed field up to the end of the record, but data is not extracted
for any subsequent parsed fields. If a blank is found, data is extracted
to the fixed area for this parsed field up to the byte before the
blank, and the Start Pointer is set to the first nonblank.
Example
If
your input is: 1 Frank D28 123 No
2 Loretta D52 58 Yes
and you wanted your
output to be: 0123 Frank D28
0058 Loretta D52
you could use this OUTFIL statement: OUTFIL PARSE=(%00=(STARTAFT=BLANKS,ENDBEFR=BLANKS,FIXLEN=8),
%01=(ENDBEFR=BLANKS,FIXLEN=3),
%02=(ENDBEFR=C' ',FIXLEN=4)),
BUILD=(%02,UFF,EDIT=(TTTT),X,%00,%01)
- ENDAT=string
- Data is to be extracted for this parsed field ending at the last
byte of the specified string. The search for the string begins at
the Start Pointer. If the specified string is not found, data is
extracted to the fixed area for this parsed field up to the end of
the record, but data is not extracted for any subsequent parsed fields.
If the specified string is found, data is extracted to the fixed
area for this parsed field up to the last byte of the string, and
the Start Pointer is set to the byte after the end of the string
string
can be 1 to 256 characters specified using a character string constant
(C'xx...x') or a hexadecimal string constant (X'yy...yy'). See INCLUDE control statement for details of coding character
and hexadecimal string constants.
Example
If your
input is: 12,(June)
5852,(Gracie)
and you wanted your output to be: (June)
(Gracie)
you could use this OUTFIL statement: OUTFIL PARSE=(%00=(STARTAT=C'(',ENDAT=C')',FIXLEN=12)),
BUILD=(%00)
- ENDAT=an
- Data is to be extracted for this parsed field ending at the first
character found from the specified alphanumeric set. The search
for a character in the specified set begins at the Start Pointer.
If a character in the set is not found, data is extracted to the
fixed area for this parsed field up to the end of the record, but
data is not extracted for any subsequent parsed fields. If a character
in the set is found, data is extracted to the fixed area for this
parsed field up to that character, and the Start Pointer is
set to the byte after that character.
See STARTAFT=an previously
in this section for more information on using the available alphanumeric
character sets.
Example
If your input is: A0005X2
Z081789Q331
R3M05
S52J06834
and you wanted your output to be: A0005X 2
Z081789Q 331
R3M 05
S52J 06834
you could use this OUTFIL statement: OUTFIL PARSE=(%01=(STARTAT=UC,ENDAT=UC,FIXLEN=10),
%02=(FIXLEN=5)),
BUILD=(%01,X,%02)
- ENDAT=BLANKS
- Data is to be extracted for this parsed field ending at the last
blank before a nonblank. The search for a blank begins at the Start
Pointer. If a blank is not found, data is extracted to the fixed area
for this parsed field up to the end of the record, but data is not
extracted for any subsequent parsed fields. If a blank is found,
data is extracted to the fixed area for this parsed field up to the
byte before the first nonblank, and the Start Pointer is set to the
first nonblank.
Note: Multiple ENDBEFR/ENDAT strings,
UC, LC, MC, UN, LN, MN, NUM, or BLANKS can be used for a %nn parsed
field to search for more than one string, set of characters or blanks.
The first search satisfied is used.
Example
If
your input is: 12;
58:
04/
and you wanted your output to be: 12
58
04
you could use this OUTFIL statement: OUTFIL PARSE=(%01=(ENDBEFR=C';',ENDBEFR=C':',ENDBEFR=C'/',
FIXLEN=10)),
BUILD=(%01,UFF,TO=ZD,LENGTH=2,80:X)
- PAIR=APOST
- Do not search for strings or blanks between apostrophe (') pairs.
Use POST=APOST when you might have strings you are searching for
within literals that should not satisfy the search.
Once an apostrophe
is found, searching is discontinued until another apostrophe is found.
Searching then continues after the second apostrophe of the pair.
If an unpaired apostrophe is found, strings or BLANKS will not be
recognized from that point on, so be careful not to set the Start
Pointer in the middle of an apostrophe pair.
Do not specify
PAIR=APOST if you want to search for a string containing an apostrophe,
because the string will not be searched for within the paired apostrophes.
Example
If
your input is: '23','12,567,823','5,032'
'9,903','18,321','8'
and you wanted your output to be: 23 12,567,823 5,032
9,903 18,321 8
you could use this OUTFIL
statement: OUTFIL PARSE=(%00=(ENDBEFR=C',',FIXLEN=12,PAIR=APOST),
%01=(ENDBEFR=C',',FIXLEN=12,PAIR=APOST),
%02=(FIXLEN=12)),
BUILD=(%00,UFF,EDIT=(II,III,IIT),X,
%01,UFF,EDIT=(II,III,IIT),X,
%02,UFF,EDIT=(II,III,IIT))
With PAIR=APOST,
the commas outside the apostrophe pairs satisfy the search, but the
commas within the apostrophe pairs do not satisfy the search.
- PAIR=QUOTE
- Do not search for strings or blanks between quote (") pairs.
Use POST=QUOTE when you might have strings you are searching for within
literals that should not satisfy the search.
Once a quote is found,
searching is discontinued until another quote is found. Searching
then continues after the second quote of the pair. If an unpaired
quote is found, strings or BLANKS will not be recognized from that
point on, so be careful not to set the Start Pointer in the middle
of a quote pair.
Do not specify PAIR=QUOTE if you want to search
for a string containing a quote, because the string will not be searched
for within the paired quotes.
Example
If your
input is: "23","12,567,823","5,032"
"9,903","18,321","8"
and you wanted your output to be: 23 12,567,823 5,032
9,903 18,321 8
you could use this OUTFIL
statement: OUTFIL PARSE=(%00=(ENDBEFR=C',',FIXLEN=12,PAIR=QUOTE),
%01=(ENDBEFR=C',',FIXLEN=12,PAIR=QUOTE),
%02=(FIXLEN=12)),
BUILD=(%00,UFF,EDIT=(II,III,IIT),X,
%01,UFF,EDIT=(II,III,IIT),X,
%02,UFF,EDIT=(II,III,IIT))
With
PAIR=QUOTE, the commas outside the quote pairs satisfy the search,
but the commas within the quote pairs do not satisfy the search.
Default
for PARSE: None; must be specified.
- REPEAT=v
- Repeat this parsed field v times.
REPEAT=v can be used with
% to specify v identically defined consecutive parsed fields to be
ignored. v can be 2 to 1000. For example, to ignore five consecutive
comma delimited fields, you can use: %=(ENDBEFR=C',',REPEAT=5),
which
is equivalent to using: %=(ENDBEFR=C','),
%=(ENDBEFR=C','),
%=(ENDBEFR=C','),
%=(ENDBEFR=C','),
%=(ENDBEFR=C','),
REPEAT=v can be used with %nn
to specify v identically defined consecutive parsed fields for which
data is to be extracted. v can be 2 to 1000. The parsed fields will
start with the %nn field you select and be incremented by 1 for each
repeated parsed field.
For example, to extract four consecutive
10-byte comma delimited fields as %11, %12, %13 and %14, you can use: %11=(ENDBEFR=C',',FIXLEN=10,REPEAT=4),
which
is equivalent to using: %11=(ENDBEFR=C',',FIXLEN=10),
%12=(ENDBEFR=C',',FIXLEN=10),
%13=(ENDBEFR=C',',FIXLEN=10),
%14=(ENDBEFR=C',',FIXLEN=10),
You must ensure
that the %nn fields resulting from the use of REPEAT=v are unique
for the run. For example, %21=(ENDBEFR=C',',FIXLEN=8,REPEAT=10) defines
%21-%30, so if you used any of %21-%30 separately, DFSORT would issue
an error message and terminate; the next available %nn field
would be %31.
You must also ensure that any %nnn field resulting
from the use of REPEAT=v does not exceed %999. For example, %998=(STARTAFT=C'$',FIXLEN=4,REPEAT=3)
defines %998-%1000; since %1000 is invalid, DFSORT would issue an
error message and terminate.
Example
If
your input is the following period delimited values: 11.2.30.4.55.160.7.82.95.37
10.22.3.41.5.16.72.2.5.42
3.18.33.12.7.9.52.12
and you wanted to extract
the first value, skip the next three values and then extract the last
six values to produce output like this: 011 055 160 007 082 095 037
010 005 016 072 002 005 042
003 007 009 052 012 000 000
you could use this OUTFIL
statement: OUTFIL PARSE=(%00=(ENDBEFR=C'.',FIXLEN=3),
%=(ENDBEFR=C'.',REPEAT=3),
%01=(ENDBEFR=C'.',FIXLEN=3,REPEAT=6)),
BUILD=(%00,UFF,EDIT=(TTT),X,
%01,UFF,EDIT=(TTT),X,
%02,UFF,EDIT=(TTT),X,
%03,UFF,EDIT=(TTT),X,
%04,UFF,EDIT=(TTT),X,
%05,UFF,EDIT=(TTT),X,
%06,UFF,EDIT=(TTT))
Default for
PARSE: None; must be specified.
- OUTREC, BUILD, OVERLAY, FINDREP, or IFTHEN
.-,----.
V |
>>-+-+-OUTREC=-+-(---item-+-)-+--------------------------------><
| '-BUILD=--' |
| .-,----. |
| V | |
+-OVERLAY=(-(---item-+-)---+
| .-,----. |
| V | |
+-FINDREP=(-(---item-+-)---+
| .-,---------------. |
| V | |
'---IFTHEN=(clause)-+------'
These
operands allow you to reformat the OUTFIL input records in this OUTFIL
group.
You can create the reformatted OUTFIL records in one
of the following ways using unedited, edited, or converted input fields (p,m for fixed fields, or %nn for parsed fields - see
PARSE) and a variety of constants: - BUILD or OUTREC: Reformat each record by specifying all
of its items one by one. Build gives you complete control over the
items you want in your reformatted OUTFIL records and the order in
which they appear. You can delete, rearrange and insert fields and
constants. Examples:
OUTFIL FNAMES=OUT1,BUILD=(1,20,C'ABC',26:5C'*',
15,3,PD,EDIT=(TTT.TT),21,30,80:X)
OUTFIL FNAMES=OUT2,
PARSE=(%00=(ENDBEFR=C',',FIXLEN=6),
%01=(ENDBEFR=C',',FIXLEN=5),
%=(ENDBEFR=C','),
%02=(FIXLEN=6)),
BUILD=(C'|',%01,SFF,ADD,%02,SFF,M4,LENGTH=12,
C'|',%00,C'|')
- OVERLAY: Reformat each record by specifying just the items
that overlay specific columns. Overlay lets you change specific existing
columns without affecting the entire record. Example:
OUTFIL OVERLAY=(45:45,8,TRAN=LTOU)
- FINDREP: Reformat each record by doing various
types of find and replace operations. Example:
OUTREC FINDREP=(INOUT=(C'Pigeon',C'Dove',C'Hawk',C'Eagle'))
- IFTHEN clauses: Reformat different records in different
ways by specifying how build, overlay, find/replace,
or group operation items are applied to records that meet given
criteria. IFTHEN clauses let you use sophisticated conditional logic
to choose how different record types are reformatted. Example:
OUTFIL IFTHEN=(WHEN=(1,5,CH,EQ,C'TYPE1'),
BUILD=(1,40,C'**',+1,TO=PD)),
IFTHEN=(WHEN=(1,5,CH,EQ,C'TYPE2'),
BUILD=(1,40,+2,TO=PD,X'FFFF')),
IFTHEN=(WHEN=NONE,OVERLAY=(45:C'NONE'))
You can choose to include any or all of the following
items in your reformatted OUTFIL records: - Fixed position/length fields or variable position/length
fields. For fixed fields, you specify the starting position and length
of the field directly. For variable fields, such as delimited fields,
comma separated values (CSV), tab separated values, blank separated
values, keyword separated fields, null-terminated
strings (and many other types), you define rules that allow DFSORT
to extract the relevant data into fixed parsed fields, and then use
the parsed fields as you would use fixed fields.
- Blanks, binary zeros, character strings, and hexadecimal strings.
- Current date, future date, past date, and current time
in various forms.
- Replaced or removed strings.
- Unedited input fields aligned on byte, halfword, fullword, and
doubleword boundaries.
- Hexadecimal or bit representations of binary
input fields.
- Characters translated from uppercase to lowercase,
lowercase to uppercase, ASCII to EBCDIC or EBCDIC to ASCII.
- Left-justified, right-justified, left-squeezed or right-squeezed
input fields.
- Numeric input fields of various formats converted to different
numeric formats, or to character format edited to contain signs, thousands
separators, decimal points, leading zeros or no leading zeros, and
so on.
- Decimal constants converted to different numeric formats, or to
character format edited to contain signs, thousands separators, decimal
points, leading zeros or no leading zeros, and so on.
- The results of arithmetic expressions combining fields, decimal
constants, operators (MIN, MAX, MUL, DIV, MOD, ADD and SUB) and parentheses
converted to different numeric formats, or to character format edited
to contain signs, thousands separators, decimal points, leading zeros
or no leading zeros, and so on.
- SMF, TOD, and ETOD date and time fields converted to different
numeric formats, or to character format edited to contain separators,
leading zeros or no leading zeros, and so on.
- The results of various types of arithmetic operations
for input date fields.
- Input date fields of one type (CH, ZD, PD, 2-digit
year, 4-digit year, Julian, Gregorian) converted to corresponding
output date fields of another type or to a corresponding day of the
week.
- Sequence numbers in various formats.
- A character constant, hexadecimal constant or input field selected
from a lookup table, based on a character, hexadecimal or bit constant
as input.
- A zoned decimal group identifier, a zoned decimal
group sequence number, or a field propagated from the first record
of a group to all of the records of a group.
- OUTREC or BUILD
>>-+-OUTREC=-+--(----------------------------------------------->
'-BUILD=--'
.-,--------------------------------------------.
V |
>----+----+--+-s--------------------------------+-+--)---------><
'-c:-' +-p,m--+----+----------------------+
| '-,a-' |
+-%nn------------------------------+
+-p--------------------------------+
+-+-p,m-+-,TRAN-+-LTOU---+---------+
| +-%nn-+ +-UTOL---+ |
| '-p---' +-ALTSEQ-+ |
| +-ATOE---+ |
| +-ETOA---+ |
| +-HEX----+ |
| +-UNHEX--+ |
| +-BIT----+ |
| '-UNBIT--' |
+-+-p,m-+-,HEX---------------------+
| +-%nn-+ |
| '-p---' |
+-+-p,m,f---+-+-,edit-+------------+
| +-%nn,f---+ '-,to---' |
| +-(p,m,f)-+ |
| '-(%nn,f)-' |
+-+-deccon---+--+-,edit-+----------+
| '-(deccon)-' '-,to---' |
+-+-arexp---+--+-,edit-+-----------+
| '-(arexp)-' '-,to---' |
+-+-p,m-+-+-+-,Y2x-+-+---------+-+-+
| '-%nn-' | '-,Y4x-' +-,edit---+ | |
| | +-,to-----+ | |
| | +-,todate-+ | |
| | '-,dateop-' | |
| +-,Y2x(s)--------------+ |
| +-,Y4x(s)--------------+ |
| '-,Y2xP----------------' |
+-+-p,m-+-,lookup------------------+
| '-%nn-' |
+-+-p,m-+-,justify-----------------+
| '-%nn-' |
+-+-p,m-+-,squeeze-----------------+
| '-%nn-' |
'-seqnum---------------------------'
Specifies all of the items in the reformatted OUTFIL
record in the order in which they are to be included. The reformatted
OUTFIL record consists of the separation fields, edited and unedited
input fields (p,m for fixed fields, or %nn for parsed
fields - see PARSE), edited decimal constants, edited results
of arithmetic expressions, and sequence numbers you select, in the
order in which you select them, aligned on the boundaries or in the
columns you indicate.
For variable-length records, the first
item in the BUILD or OUTREC parameter must specify or include the
unedited 4-byte record descriptor word (RDW), that is, you must start
with 1,m with m equal to or greater than 4. If you want to include
the bytes from a specific position to the end of each input record
at the end of each reformatted output record, you can specify that
starting position (p) as the last item in the BUILD or OUTREC parameter.
For example: OUTFIL OUTREC=(1,4, unedited RDW
1,2,BI,TO=ZD,LENGTH=5, display RDW length in decimal
C'|', | separator
5) display input positions 5 to end
For
fixed-length records, the first input and output data byte starts
at position 1. For variable-length records, the first input and output
data byte starts at position 5, after the RDW in positions 1-4.
You
can use the BUILD or OUTREC parameter to produce multiple reformatted
output records for each OUTFIL input record, with or without intervening
blank output records.
You can use the BUILD or OUTREC parameter
in conjunction with the VTOF or CONVERT parameter to convert variable-length
record data sets to fixed-length record data sets.
You can use
the BUILD or OUTREC parameter with the FTOV parameter to convert fixed-length
record data sets to variable-length record data sets.
You can
use the VLFILL parameter to allow processing of variable-length input
records which are too short to contain all specified BUILD or OUTREC
fields.
You can use the VLTRIM parameter in conjunction with
the BUILD or OUTREC parameter to remove specified trailing bytes from
the end of variable-length records.
You can use
the VLTRAIL parameter in conjunction with the BUILD or OUTREC parameter
to insert a string at the end of variable-length records.
The BUILD or OUTREC parameter
can be used with any or all of the report parameters (LINES, HEADER1,
TRAILER1, HEADER2, TRAILER2, SECTIONS, BLKCCH1, BLKCCH2,
BLKCCT1, and NODETAIL) to produce reports. The report parameters
specify the report records to be produced, while the BUILD or OUTREC
parameter specifies the reformatted data records to be produced. DFSORT
uses ANSI carriage control characters to control page ejects and the
placement of the lines in your report, according to your specifications.
You can use the REMOVECC parameter to remove the ANSI carriage control
characters.
When you create an OUTFIL report, the length for
the longest or only data record must be equal to or greater than the
maximum report record length. You can use the BUILD or OUTREC parameter
to force a length for the data records that is longer than any report
record; you can then either let DFSORT compute and set the LRECL,
or ensure that the computed LRECL is equal to the existing or specified
LRECL. Remember to allow an extra byte in the LRECL for the ANSI carriage
control character.
For example, if your data records are 40
bytes, but your longest report record is 60 bytes, you can use a BUILD
or OUTREC parameter such as: OUTREC=(1,40,80:X)
DFSORT
will then set the LRECL to 81 (1 byte for the ANSI carriage control
character plus 80 bytes for the length of the data records), and pad
the data records with blanks on the right.
If you don't want
the ANSI carriage control characters to appear in the output data
set, use the REMOVECC parameter to remove them. For example, if you
specify: OUTREC=(1,40,80:X),REMOVECC
DFSORT
will set the LRECL to 80 instead of 81 and remove the ANSI carriage
control character from each record before it is written.
The
BUILD or FIELDS parameter of the OUTREC statement differs from the
BUILD or OUTREC parameter of the OUTFIL statement in the following
ways: - The BUILD or FIELDS parameter of the OUTREC statement applies
to all input records; the BUILD or OUTREC parameter of the OUTFIL
statement only applies to the OUTFIL input records for its OUTFIL
group.
- The BUILD or OUTREC parameter of the OUTFIL statement supports
the slash (/) separator for creating blank records and new records;
the BUILD or FIELDS parameter of the OUTREC statement does not.
The reformatted OUTFIL output record consists of the separation
fields, edited and unedited input fields, (p,m for
fixed fields, or %nn for parsed fields - see PARSE), edited decimal
constants, edited results of arithmetic expressions, and sequence
numbers you select, in the order in which you select them, aligned
on the boundaries or in the columns you indicate.
- c:
- specifies the position (column) for a separation field, input
field, decimal constant, arithmetic expression, or sequence number,
relative to the start of the reformatted OUTFIL output record. Count
the RDW (variable-length output records only) but not the carriage
control character (for reports) when specifying c:. That is, 1: indicates
the first byte of the data in fixed-length output records and 5: indicates
the first byte of the data in variable-length output records.
Unused
space preceding the specified column is padded with EBCDIC blanks.
The following rules apply: - c must be a number between 1 and 32752.
- c: must be followed by a separation field, input field, decimal
constant, or arithmetic expression.
- c must not overlap the previous input field or separation field
in the reformatted OUTFIL output record.
- For variable-length records, c: must not be specified before the
first input field (the record descriptor word) nor after the variable
part of the OUTFIL input record.
- The colon (:) is treated like the comma (,) or semicolon (;) for
continuation to another line.
See Table 1 for
examples of valid and invalid column alignment.
- s
- specifies that a separation field (blanks, zeros, character string,
hexadecimal string, current date, future date, past
date, or current time) is to appear in the reformatted OUTFIL
output record, or that a new output record is to be started, with
or without intervening blank output records. These separation elements
(separation fields, new record indicators, and blank record indicators)
can be specified before or after any input field. Consecutive separation
elements may be specified. For variable-length records, separation
elements must not be specified before the first input field (the record
descriptor word) or after the variable part of the OUTFIL input record.
Permissible values are nX, nZ, nC'xx...x', nX'yy...yy', various date and time constants, /.../ and n/.
- nX
- Blank separation. n bytes of EBCDIC blanks (X'40') are
to appear in the reformatted OUTFIL output records. n can range from
1 to 4095. If n is omitted, 1 is used.
See Table 2 for
examples of valid and invalid blank separation.
- nZ
- Binary zero separation. n bytes of binary zeros (X'00')
are to appear in the reformatted OUTFIL output records. n can range
from 1 to 4095. If n is omitted, 1 is used.
See Table 3 for
examples of valid and invalid binary zero separation.
- nC'xx...x'
- Character string separation. n repetitions of the character string
constant (C'xx...x') are to appear in the reformatted OUTFIL output
records. n can range from 1 to 4095. If n is omitted, 1 is used. x
can be any EBCDIC character. You can specify from 1 to 256 characters.
If
you want to include a single apostrophe in the character string, you
must specify it as two single apostrophes: Required: O'NEILL Specify: C'O''NEILL'
See Table 4 for
examples of valid and invalid character string separation.
- nX'yy...yy'
- Hexadecimal string separation. n repetitions of the hexadecimal
string constant (X'yy...yy') are to appear in the reformatted
OUTFIL output records. n can range from 1 to 4095. If n is omitted,
1 is used.
The value yy represents any pair of hexadecimal digits.
You can specify from 1 to 256 pairs of hexadecimal digits.
See Table 5 for
examples of valid and invalid hexadecimal string separation.
- DATEn, DATEN(c), DATEnP
- Constant for current date. The current date
of the run is to appear in the reformatted OUTFIL output records.
DATE1, &DATE1, DATE1(c), &DATE1(c), DATE2, &DATE2,
DATE2(c), &DATE2(c), DATE3, &DATE3, DATE3(c) or &DATE3(c)
can be used to generate a character constant for the current date
of the run. DATE1P, &DATE1P, DATE2P, &DATE2P, DATE3P or &DATE3P
can be used to generate a packed decimal constant for the current
date of the run.
Table 1 shows
the form of the constant generated for each current date operand and
an example of the actual constant generated when the date of the run
is June 21, 2005 at 4:42:45 PM, using (⁄) for (c) where relevant.
yyyy represents the year, mm (for date) represents the month (01-12),
dd represents the day (01-31), ddd represents the day of the year
(001-366), hh represents the hour (00-23), mm (for time) represents
the minutes (00-59), ss represents the seconds (00-59), and c can
be any character except a blank.
Table 1. Current date constantsCurrent date constantsFormat of Operand
|
Format of Constant |
Length (bytes) |
Example of Constant |
|---|
| DATE1 |
C'yyyymmdd' |
8 |
C'20050621' |
| DATE1(c) |
C'yyyycmmcdd' |
10 |
C'2005/06/21' |
| DATE1P |
P'yyyymmdd' |
5 |
P'20050621' |
| DATE2 |
C'yyyymm' |
6 |
C'200506' |
| DATE2(c) |
C'yyyycmm' |
7 |
C'2005/06' |
| DATE2P |
P'yyyymm' |
4 |
P'200506' |
| DATE3 |
C'yyyyddd' |
7 |
C'2005172' |
| DATE3(c) |
C'yyyycddd' |
8 |
C'2005/172' |
| DATE3P |
P'yyyyddd' |
4 |
P'2005172' |
| DATE4 |
C'yyyy-mm-dd-hh.mm.ss' |
19 |
C'2005-06-21-16.52.45' |
| DATE5 |
C'yyyy-mm-dd-hh.mm.ss.nnnnnn' |
26 |
C'2005-06-21-16.52.45.602837' |
Note: You can precede each of the operands in the
table with an & with identical results.
- &DATEn, &DATEN(c), &DATEnP
- Can be used instead of DATEn, DATEn(c) and DATEnP, respectively
- DATEn+r, DATEn(c)+r, DATEnP+r
- Constant
for future date. A future date relative to the current date of the
run is to appear in the reformatted OUTFIL output records.
DATE1+d, &DATE1+d,
DATE1(c)+d, &DATE1(c)+d, DATE2+m, &DATE2+m, DATE2(c)+m, &DATE2(c)+m,
DATE3+d, &DATE3+d, DATE3(c)+d or &DATE3(c)+d can be used to
generate a character constant for a future date relative to the current
date of the run. DATE1P+d, &DATE1P+d, DATE2P+m, &DATE2P+m,
DATE3P+d or &DATE3P+d can be used to generate a packed decimal
constant for a future date relative to the current date of the run.
d is days in the future and m is months in the future. d and m can
be 0 to 9999.
Table 2 shows the
form of the constant generated for each future date operand and an
example of the actual constant generated when the date of the run
is June 21, 2005, using (/) for (c) where relevant. yyyy represents
the year, mm (for date) represents the month (01-12), dd represents
the day (01-31), ddd represents the day of the year (001-366), and
c can be any character except a blank.
Table 2. Future Date ConstantsFuture Date ConstantsFormat of Operand
|
Format of Constant |
Length (bytes) |
Example of Operand |
Example of Constant |
|---|
| DATE1+d |
C'yyyymmdd' |
8 |
DATE1+11 |
C'20050702' |
| DATE1(c)+d |
C'yyyycmmcdd' |
10 |
DATE1(/)+90 |
C'2005/09/19' |
| DATE1P+d |
P'yyyymmdd' |
5 |
DATE1P+11 |
P'20050702' |
| DATE2+m |
C'yyyymm' |
6 |
DATE2+2 |
C'200508' |
| DATE2(c)+m |
C'yyyycmm' |
7 |
DATE2(.)+25 |
C'2007.07' |
| DATE2P+m |
P'yyyymm' |
4 |
DATE2P+2 |
P'200508' |
| DATE3+d |
C'yyyyddd' |
7 |
DATE3+200 |
C'2006007' |
| DATE3(c)+d |
C'yyyycddd' |
8 |
DATE3(-)+1 |
C'2005-171' |
| DATE3P+d |
P'yyyyddd' |
4 |
DATE3P+200 |
P'2006007' |
Note: You can precede each of the operands in the table with
an & with identical results.
- &DATEn+r, &DATEn(c)+r, &DATEnP+r
- Can be used instead of DATEn+r, DATEn(c)+r and DATEnP+r, respectively.
- DATEn-r, DATEn(c)-r, DATEnP-r
- Constant
for past date. A past date relative to the current date of the run
is to appear in the reformatted OUTFIL output records.
DATE1-d, &DATE1-d,
DATE1(c)-d, &DATE1(c)-d, DATE2-m, &DATE2-m, DATE2(c)-m, &DATE2(c)-m,
DATE3-d, &DATE3-d, DATE3(c)-d or &DATE3(c)-d can be used to
generate a character constant for a past date relative to the current
date of the run. DATE1P-d, &DATE1P-d, DATE2P-m, &DATE2P-m,
DATE3P-d or &DATE3P-d can be used to generate a packed decimal
constant for a past date relative to the current date of the run.
d is days in the past and m is months in the past. d and m can be
0 to 9999.
Table 3 shows the form
of the constant generated for each past date operand and an example
of the actual constant generated when the date of the run is June
21, 2005, using (/) for (c) where relevant. yyyy represents the year,
mm (for date) represents the month (01-12), dd represents the day
(01-31), ddd represents the day of the year (001-366), and c can be
any character except a blank.
Table 3. Past Date ConstantsPast Date ConstantsFormat of Operand
|
Format of Constant |
Length (bytes) |
Example of Operand |
Example of Constant |
|---|
| DATE1-d |
C'yyyymmdd' |
8 |
DATE1-1 |
C'20050620' |
| DATE1(c)-d |
C'yyyycmmcdd' |
10 |
DATE1(-)-60 |
C'2005-04-22' |
| DATE1P-d |
P'yyyymmdd' |
5 |
DATE1P-30 |
P'20050522' |
| DATE2-m |
C'yyyymm' |
6 |
DATE2-6 |
C'200412' |
| DATE2(c)-m |
C'yyyycmm' |
7 |
DATE2(/)-1 |
C'2005/05' |
| DATE2P-m |
P'yyyymm' |
4 |
DATE2P-12 |
P'200406' |
| DATE3-d |
C'yyyyddd' |
7 |
DATE3-300 |
C'2004238' |
| DATE3(c)-d |
C'yyyycddd' |
8 |
DATE3(.)-21 |
C'2005.151' |
| DATE3P-d |
P'yyyyddd' |
4 |
DATE3P-172 |
P'2004366' |
Note: You can precede each of the operands in the table with
an & with identical results.
- &DATEn-r, &DATEn(c)-r, &DATEnP-r
- Can be used instead of DATEn-r, DATEn(c)-r and DATEnP-r, respectively.
- TIMEn, TIMEn(c), TIMEnP
- Constant for current time.
The time of the run is to appear in the reformatted OUTFIL output
records. Table 4 shows the constant generated
for each separation field you can specify along with its length and
an example using (:) for (c) where relevant. hh represents the hour
(00-23), mm represents the minutes (00-59), ss represents the seconds
(00-59), and c can be any character except a blank.
Table 4. Current time constantsCurrent time constantsSeparation Field
|
Constant |
Length (bytes) |
01:55:43 PM |
|---|
| TIME1 |
C'hhmmss' |
6 |
C'135543' |
| TIME1(c) |
C'hhcmmcss' |
8 |
C'13:55:43' |
| TIME1P |
P'hhmmss' |
4 |
P'135543' |
| TIME2 |
C'hhmm' |
4 |
C'1355' |
| TIME2(c) |
C'hhcmm' |
5 |
C'13:55' |
| TIME2P |
P'hhmm' |
3 |
P'1355' |
| TIME3 |
C'hh' |
2 |
C'13' |
| TIME3P |
P'hh' |
2 |
P'13' |
- &TIMEn, &TIMEn(c), &TIMEnP
- Can be used instead of TIMEn, TIMEn(c), and TIMEnP, respectively.
- DATE
- specifies that the current date is to appear in the reformatted
OUTFIL output records in the form 'mm/dd/yy', where mm represents
the month (01-12), dd represents the day (01-31), and yy represents
the last two digits of the year (for example, 04).
- &DATE
- can be used instead of DATE.
- DATE=(abcd)
- specifies that the current date is to appear in the reformatted
OUTFIL output records in the form 'adbdc', where a, b, and c indicate
the order in which the month, day, and year are to appear and whether
the year is to appear as two or four digits, and d is the character
to be used to separate the month, day and year.
For a, b, and c,
use M to represent the month (01-12), D to represent the day (01-31),
Y to represent the last two digits of the year (for example, 04),
or 4 to represent the four digits of the year (for example, 2004).
M, D, and Y or 4 can each be specified only once. Examples: DATE=(DMY.)
would produce a date of the form 'dd.mm.yy', which on March 29, 2004,
would appear as '29.03.04'. DATE=(4MD-) would produce a date of the
form 'yyyy-mm-dd', which on March 29, 2004, would appear as '2004-03-29'.
a,
b, c, and d must be specified.
- &DATE=(abcd)
- can be used instead of DATE=(abcd).
- DATENS=(abc)
- specifies that the current date is to appear in the reformatted
OUTFIL output record in the form 'abc', where a, b and c indicate
the order in which the month, day, and year are to appear and whether
the year is to appear as two or four digits.
For a, b and c, use
M to represent the month (01-12), D to represent the day (01-31),
Y to represent the last two digits of the year (for example, 04),
or 4 to represent the four digits of the year (for example, 2004).
M, D, and Y or 4 can each be specified only once. Examples: DATENS=(DMY)
would produce a date of the form 'ddmmyy', which on March 29, 2004,
would appear as '290304'. DATENS=(4MD) would produce a date of the
form 'yyyymmdd', which on March 29, 2004, would appear as '20040329'.
a,
b and c must be specified.
- &DATENS=(abc)
- can be used instead of DATENS=(abc).
- YDDD=(abc)
- specifies that the current date is to appear in the reformatted
OUTFIL output records in the form 'acb', where a and b indicate the
order in which the year and day of the year are to appear and whether
the year is to appear as two or four digits, and c is the character
to be used to separate the year and day of the year.
For a and
b, use D to represent the day of the year (001-366), Y to represent
the last two digits of the year (for example, 04), or 4 to represent
the four digits of the year (for example, 2004). D, and Y or 4 can
each be specified only once. Examples: YDDD=(DY-) would produce
a date of the form 'ddd-yy', which on April 7, 2004, would appear
as '098-04'. YDDD=(4D/) would produce a date of the form 'yyyy/ddd',
which on April 7, 2004, would appear as '2004/098'.
a, b and
c must be specified.
- &YDDD=(abc)
- can be used instead of YDDD=(abc).
- YDDDNS=(ab)
- specifies that the current date is to appear in the reformatted
OUTFIL output records in the form 'ab', where a and b indicate the
order in which the year and day of the year are to appear and whether
the year is to appear as two or four digits.
For a and b, use D
to represent the day of the year (001-366), Y to represent the last
two digits of the year (for example, 04), or 4 to represent the four
digits of the year (for example, 2004). D, and Y or 4 can each be
specified only once. Examples: YDDDNS=(DY) would produce a date
of the form 'dddyy', which on April 7, 2004, would appear as '09804'.
YDDDNS=(4D) would produce a date of the form 'yyyyddd', which on April
7, 2004, would appear as '2004098'.
a and b must be specified.
- &YDDDNS=(ab)
- can be used instead of YDDDNS=(ab).
- TIME
- specifies that the current time is to appear in the reformatted
OUTFIL output records in the form 'hh:mm:ss', where hh represents
the hour (00-23), mm represents the minutes (00-59), and ss represents
the seconds (00-59).
- &TIME
- can be used instead of TIME.
- TIME=(abc)
- specifies that the current time is to appear in the reformatted
OUTFIL output records in the form 'hhcmmcss' (24-hour time) or 'hhcmmcss
xx' (12-hour time).
If ab is 24, the time is to appear in the form
'hhcmmcss' (24-hour time) where hh represents the hour (00-23), mm
represents the minutes (00-59), ss represents the seconds (00-59),
and c is the character used to separate the hours, minutes, and seconds.
Example: TIME=(24.) would produce a time of the form 'hh.mm.ss',
which at 08:25:13 pm would appear as '20.25.13'.
If ab is 12,
the time is to appear in the form 'hhcmmcss xx' (12-hour time) where
hh represents the hour (01-12), mm represents the minutes (00-59),
ss represents the seconds (00-59), xx is am or pm, and c is the character
used to separate the hours, minutes, and seconds. Example: TIME=(12.)
would produce a time of the form 'hh.mm.ss xx', which at 08:25:13
pm would appear as '08.25.13 pm'.
ab and c must be specified.
- &TIME=(abc)
- can be used instead of TIME=(abc).
- TIMENS=(ab)
- specifies that the current time is to appear in the reformatted
OUTFIL output record in the form 'hhmmss' (24-hour time) or 'hhmmss
xx' (12-hour time).
If ab is 24, the time is to appear in the form
'hhmmss' (24-hour time) where hh represents the hour (00-23), mm represents
the minutes (00-59), and ss represents the seconds (00-59). Example:
TIMENS=(24) would produce a time of the form 'hhmmss', which at 08:25:13
pm would appear as '202513'.
If ab is 12, the time is to appear
in the form 'hhmmss xx' (12-hour time) where hh represents the hour
(01-12), mm represents the minutes (00-59), and ss represents the
seconds (00-59). Example: TIMENS=(12) would produce a time of the
form 'hhmmss xx', which at 08:25:13 pm would appear as '082513 pm'.
ab
must be specified.
- &TIMENS=(ab)
- can be used instead of TIMENS=(ab).
- /.../ or n/
- Blank records or a new record. A new output record is to be started
with or without intervening blank output records. If /.../ or n/
is specified at the beginning or end of OUTREC, n blank output records
are to be produced. If /.../ or n/ is specified in the middle of
OUTREC, n-1 blank output records are to be produced (thus, / or 1/
indicates a new output record with no intervening blank output records).
At
least one input field or separation field must be specified if you
use /.../ or n/. For example, OUTREC=(//) is not allowed, whereas
OUTREC=(//X) is allowed.
Either n/ (for example, 5/) or multiple
/'s (for example, /////) can be used. n can range from 1 to 255.
If n is omitted, 1 is used.
As an example, if you specify: OUTFIL OUTREC=(2/,C'Field 2 contains ',4,3,/,
C'Field 1 contains ',1,3)
an input record
containing: 111222
would produce the following
four output records: Blanks
Blanks
Field 2 contains 222
Field 1 contains 111
Note that four OUTFIL
output records are produced for each OUTFIL input record.
- p,m,a
- specifies that an unedited input field is to appear in the reformatted
OUTFIL output record.
- p
- specifies the first byte of the input field relative to the beginning
of the OUTFIL input record. The first data byte of a fixed-length
record has relative position 1. The first data byte of a variable-length
record has relative position 5, because the first four bytes are occupied
by the RDW. All fields must start on a byte boundary, and no field
can extend beyond byte 32752. See OUTFIL statements notes for
special rules concerning variable-length records.
- m
- specifies the length in bytes of the input field.
- a
- specifies the alignment (displacement) of the input field in the
reformatted OUTFIL output record relative to the start of the reformatted
OUTFIL output record.
The permissible values of a are: - H
- Halfword aligned. The displacement (p-1) of the field from the
beginning of the reformatted OUTFIL input record, in bytes, is a multiple
of 2 (that is, position 1, 3, 5, and so forth).
- F
- Fullword aligned. The displacement is a multiple of 4 (that is,
position 1, 5, 9, and so forth).
- D
- Doubleword aligned. The displacement is a multiple of 8 (that
is, position 1, 9, 17, and so forth).
Alignment can be necessary if, for example,
the data is used in a COBOL application program where items are aligned
through the SYNCHRONIZED clause. Unused space preceding aligned fields
are always padded with binary zeros.
- %nn
- specifies that an unedited parsed input field is to appear in
the reformatted OUTFIL output record. See PARSE for details of parsed
fields. See p,m,a for further details. Note that alignment (H, F,
D) is not permitted for %nn fields (for example, %nn,F results in
an error message and termination).
- p
- specifies the unedited variable part of the OUTFIL input record
(that part beyond the minimum record length) is to appear in the reformatted
OUTFIL output record as the last field. p without
m can only be used for variable-length records; not for fixed-length
records.
Attention: If 1,4,p is specified
(only RDW and variable part of record), "null" records containing
only an RDW will result if the record length is less than p.
A
value must be specified for p that is less than or equal to the minimum
OUTFIL input record length plus 1 byte.
- p,m,TRAN=keyword
- Specifies that an input field is to be translated as indicated
by the keyword.
Attention: If TRAN=keyword is used for
non-character data (for example, PD), it may have unintended consequences.
- p
- See p under p,m,a
- m
- specifies the length in bytes of the numeric field and depends
on the keyword used as indicated.
- TRAN=keyword
- specifies the type of translation to be performed. The keyword
can be one of the following:
- TRAN=LTOU
- translates lowercase EBCDIC letters (that is, a-z) to uppercase
EBCDIC letters (that is, A-Z). Other characters are not changed.
For example, the characters 'Vicky-123,x' would be replaced by 'VICKY-123,X'.
m can be 1 to 32752. The output length will be m bytes.
- TRAN=UTOL
- translates uppercase EBCDIC letters (that is, A-Z) to lowercase
EBCDIC letters (that is, a-z). Other characters are not changed.
For example, the characters 'CARRIE-005, CA' would be replaced
by 'carrie-005, ca'.
m can be 1 to 32752. The output length will
be m bytes.
- TRAN=ALTSEQ
- translates characters according to the ALTSEQ translation table
in effect. For example, the characters X'5B5C' would be replaced by
X'4040' if ALTSEQ CODE=(5B40,5C40) was in effect.
m can be 1 to
32752. The output length will be m bytes.
- TRAN=ATOE
- translates characters from ASCII to EBCDIC using the default standard
TCP/IP service ASCII-to-EBCDIC translation table. For example, with
TRAN=ATOE, the ASCII characters aB2 (X'614232') would be replaced
by the EBCDIC characters aB2 (X'81C2F2').
m can be 1 to 32752.
The output length will be m bytes.
Table 5 is
the default standard TCP/IP table used for TRAN=ATOE. Each column
shows the ASCII (A) character value on the left and its equivalent
EBCDIC (E) character value on the right.
Table 5. TRAN=ATOE
ASCII-to-EBCDIC translation TRAN=ATOE ASCII-to-EBCDIC translation
Part 1 - TRAN=ATOE ASCII-to-EBCDIC Translation
|
|---|
| A E| A E| A E| A E| A E| A E| A E| A E|
|-- --|-- --|-- --|-- --|-- --|-- --|-- --|-- --|
|00 00|10 10|20 40|30 F0|40 7C|50 D7|60 79|70 97|
|01 01|11 11|21 5A|31 F1|41 C1|51 D8|61 81|71 98|
|02 02|12 12|22 7F|32 F2|42 C2|52 D9|62 82|72 99|
|03 03|13 13|23 7B|33 F3|43 C3|53 E2|63 83|73 A2|
|04 37|14 3C|24 5B|34 F4|44 C4|54 E3|64 84|74 A3|
|05 2D|15 3D|25 6C|35 F5|45 C5|55 E4|65 85|75 A4|
|06 2E|16 32|26 50|36 F6|46 C6|56 E5|66 86|76 A5|
|07 2F|17 26|27 7D|37 F7|47 C7|57 E6|67 87|77 A6|
|08 16|18 18|28 4D|38 F8|48 C8|58 E7|68 88|78 A7|
|09 05|19 19|29 5D|39 F9|49 C9|59 E8|69 89|79 A8|
|0A 25|1A 3F|2A 5C|3A 7A|4A D1|5A E9|6A 91|7A A9|
|0B 0B|1B 27|2B 4E|3B 5E|4B D2|5B AD|6B 92|7B C0|
|0C 0C|1C 22|2C 6B|3C 4C|4C D3|5C E0|6C 93|7C 4F|
|0D 0D|1D 1D|2D 60|3D 7E|4D D4|5D BD|6D 94|7D D0|
|0E 0E|1E 35|2E 4B|3E 6E|4E D5|5E 5F|6E 95|7E A1|
|0F 0F|1F 1F|2F 61|3F 6F|4F D6|5F 6D|6F 96|7F 07|
|
| Part 2 - TRAN=ATOE ASCII-to-EBCDIC Translation |
| A E| A E| A E| A E| A E| A E| A E| A E|
|-- --|-- --|-- --|-- --|-- --|-- --|-- --|-- --|
|80 00|90 10|A0 40|B0 F0|C0 7C|D0 D7|E0 79|F0 97|
|81 01|91 11|A1 5A|B1 F1|C1 C1|D1 D8|E1 81|F1 98|
|82 02|92 12|A2 7F|B2 F2|C2 C2|D2 D9|E2 82|F2 99|
|83 03|93 13|A3 7B|B3 F3|C3 C3|D3 E2|E3 83|F3 A2|
|84 37|94 3C|A4 5B|B4 F4|C4 C4|D4 E3|E4 84|F4 A3|
|85 2D|95 3D|A5 6C|B5 F5|C5 C5|D5 E4|E5 85|F5 A4|
|86 2E|96 32|A6 50|B6 F6|C6 C6|D6 E5|E6 86|F6 A5|
|87 2F|97 26|A7 7D|B7 F7|C7 C7|D7 E6|E7 87|F7 A6|
|88 16|98 18|A8 4D|B8 F8|C8 C8|D8 E7|E8 88|F8 A7|
|89 05|99 19|A9 5D|B9 F9|C9 C9|D9 E8|E9 89|F9 A8|
|8A 25|9A 3F|AA 5C|BA 7A|CA D1|DA E9|EA 91|FA A9|
|8B 0B|9B 27|AB 4E|BB 5E|CB D2|DB AD|EB 92|FB C0|
|8C 0C|9C 22|AC 6B|BC 4C|CC D3|DC E0|EC 93|FC 4F|
|8D 0D|9D 1D|AD 60|BD 7E|CD D4|DD BD|ED 94|FD D0|
|8E 0E|9E 35|AE 4B|BE 6E|CE D5|DE 5F|EE 95|FE A1|
|8F 0F|9F 1F|AF 61|BF 6F|CF D6|DF 6D|EF 96|FF 07|
|
- TRAN=ETOA
- translates characters from EBCDIC to ASCII using the default standard
TCP/IP service EBCDIC-to-ASCII translation table. For example, with
TRAN=ETOA, the EBCDIC characters aB2 (X'81C2F2') would be replaced
by the ASCII characters aB2 (X'614232').
m can be 1 to 32752.
The output length will be m bytes.
Table 6is
the default standard TCP/IP table used for TRAN=ETOA. Each column
shows the EBCDIC (E) character value on the left and its equivalent
ASCII (A) character value on the right.
Table 6. TRAN=ETOA
ASCII-to-EBCDIC translation TRAN=ETOA ASCII-to-EBCDIC translation
Part 1 - TRAN=ETOA ASCII-to-EBCDIC Translation
|
|---|
| E A| E A| E A| E A| E A| E A| E A| E A|
|-- --|-- --|-- --|-- --|-- --|-- --|-- --|-- --|
|00 00|10 10|20 1A|30 1A|40 20|50 26|60 2D|70 D7|
|01 01|11 11|21 1A|31 1A|41 A6|51 A9|61 2F|71 88|
|02 02|12 12|22 1C|32 16|42 E1|52 AA|62 DF|72 94|
|03 03|13 13|23 1A|33 1A|43 80|53 9C|63 DC|73 B0|
|04 1A|14 1A|24 1A|34 1A|44 EB|54 DB|64 9A|74 B1|
|05 09|15 0A|25 0A|35 1E|45 90|55 A5|65 DD|75 B2|
|06 1A|16 08|26 17|36 1A|46 9F|56 99|66 DE|76 FC|
|07 7F|17 1A|27 1B|37 04|47 E2|57 E3|67 98|77 D6|
|08 1A|18 18|28 1A|38 1A|48 AB|58 A8|68 9D|78 FB|
|09 1A|19 19|29 1A|39 1A|49 8B|59 9E|69 AC|79 60|
|0A 1A|1A 1A|2A 1A|3A 1A|4A 9B|5A 21|6A BA|7A 3A|
|0B 0B|1B 1A|2B 1A|3B 1A|4B 2E|5B 24|6B 2C|7B 23|
|0C 0C|1C 1C|2C 1A|3C 14|4C 3C|5C 2A|6C 25|7C 40|
|0D 0D|1D 1D|2D 05|3D 15|4D 28|5D 29|6D 5F|7D 27|
|0E 0E|1E 1E|2E 06|3E 1A|4E 2B|5E 3B|6E 3E|7E 3D|
|0F 0F|1F 1F|2F 07|3F 1A|4F 7C|5F 5E|6F 3F|7F 22|
|
| Part 2 - TRAN=ETOA ASCII-to-EBCDIC Translation |
| E A| E A| E A| E A| E A| E A| E A| E A|
|-- --|-- --|-- --|-- --|-- --|-- --|-- --|-- --|
|80 F8|90 8C|A0 C8|B0 B5|C0 7B|D0 7D|E0 5C|F0 30|
|81 61|91 6A|A1 7E|B1 B6|C1 41|D1 4A|E1 E7|F1 31|
|82 62|92 6B|A2 73|B2 FD|C2 42|D2 4B|E2 53|F2 32|
|83 63|93 6C|A3 74|B3 B7|C3 43|D3 4C|E3 54|F3 33|
|84 64|94 6D|A4 75|B4 B8|C4 44|D4 4D|E4 55|F4 34|
|85 65|95 6E|A5 76|B5 B9|C5 45|D5 4E|E5 56|F5 35|
|86 66|96 6F|A6 77|B6 E6|C6 46|D6 4F|E6 57|F6 36|
|87 67|97 70|A7 78|B7 BB|C7 47|D7 50|E7 58|F7 37|
|88 68|98 71|A8 79|B8 BC|C8 48|D8 51|E8 59|F8 38|
|89 69|99 72|A9 7A|B9 BD|C9 49|D9 52|E9 5A|F9 39|
|8A 96|9A 97|AA EF|BA 8D|CA CB|DA A1|EA A0|FA B3|
|8B A4|9B 87|AB C0|BB D9|CB CA|DB AD|EB 85|FB F7|
|8C F3|9C CE|AC DA|BC BF|CC BE|DC F5|EC 8E|FC F0|
|8D AF|9D 93|AD 5B|BD 5D|CD E8|DD F4|ED E9|FD FA|
|8E AE|9E F1|AE F2|BE D8|CE EC|DE A3|EE E4|FE A7|
|8F C5|9F FE|AF F9|BF C4|CF ED|DF 8F|EF D1|FF FF|
|
- TRAN=HEX
- translates binary values to their equivalent EBCDIC hexadecimal
values. For example, with TRAN=HEX, X'C1F1' (C'A1') would be replaced
by C'C1F1'.
m can be 1 to 16376. The output length will be m*2
bytes
- TRAN=UNHEX
- translates EBCDIC hexadecimal values to their equivalent binary
values. For example, with TRAN=UNHEX, C'C1F1' would be replaced by
X'C1F1' (C'A1').
m can be 1 to 32752. The output length will be
(m+1)/2 bytes.
If m is odd, the last nibble will be 0. As an
example, C'C1F1F' would translate to X'C1F1F0' (C'A10').
If
an input character is not 0-9 or A-F, the equivalent nibble will be
set to 0. As an example, C'G2' will be translated to X'02'.
- TRAN=BIT
- translates binary values to their equivalent EBCDIC bit values.
For example, with TRAN=BIT, X'C1F1' (C'A1') would be replaced by
C'1100000111110001'.
m can be 1 to 4094. The output length will
be m*8 bytes
- TRAN=UNBIT
- translates EBCDIC bit values to their equivalent binary values.
For example, with TRAN=UNBIT, C'1100000111110001' would be replaced
by X'C1F1' (C'A1').
m can be 1 to 32752. The output length will
be (m+7)/8 bytes
If m is not a multiple of 8, the missing bits
on the right will be set to 0. As an example, C'1100000111111' would
translate to X'C1F8'.
If an input character
is not 0 or 1, the equivalent bit will be set to 0. As an example,
C'11100005' will be translated to X'E0'.
Sample Syntax: OUTFIL FNAMES=OUT1,
BUILD=(5,6,TRAN=UNHEX,2X,20,15,TRAN=UTOL)
- %nn,TRAN=keyword
- Specifies that a parsed input field is to be translated as indicated
by the keyword. See PARSE for details of PARSED fields. See p,m,TRAN=keyword
for details of the translation functions.
- p,TRAN=keyword
- Specifies that the variable part of the input record is to be
translated as indicated by the keyword. p,TRAN=keyword must be the
last item and can only be used for variable-length records; not for
fixed-length records. A value must be specified for p that is less
than or equal to the minimum input record length plus 1 byte. See
p,m,TRAN=keyword for details of the translation functions.
Attention: If 1,4,p,TRAN=keyword is specified (only RDW and
variable part of record), "null" records containing only an RDW will
result if the record length is less than p.
Sample Syntax: OUTFIL FNAMES=OUT2,BUILD=(1,4,5,TRAN=ETOA)
- p,m,HEX
- Can be used instead of p,m,TRAN=HEX. See p,m,TRAN=HEX for details.
- %nn,HEX
- Can be used instead of %nn,TRAN=HEX. See %nn,TRAN=HEX for details.
- p,HEX
- Can be used instead of p,TRAN=HEX. See p,TRAN=HEX for details.
- p,m,f,edit or (p,m,f),edit
- specifies that an edited numeric input field is to appear in the
reformatted OUTFIL output record. You can edit BI, FI, PD, PD0, ZD, FL,CSF, FS, UFF, SFF, DC1, DC2, DC3, DE1, DE2, DE3,
DT1, DT2, DT3, TC1, TC2, TC3, TC4, TE1, TE2, TE3, TE4, TM1, TM2, TM3
or TM4 fields using either pre-defined edit masks (M0-M26) or specific
edit patterns you define. You can control the way the edited fields
look with respect to length, leading or suppressed zeros, thousands
separators, decimal points, leading and trailing positive and negative
signs, and so on.
- p
- See p under p,m,a.
- m
- specifies the length in bytes of the numeric field. The length
must include the sign, if the data is signed. See Table 7 for permissible length values.
- f
- specifies the format of the numeric field:
Table 7. Edit
Field Formats and LengthsEdit Field Formats and LengthsFormat
Code
|
Length |
Description |
|---|
| BI |
1 to 8 bytes |
Unsigned binary |
| FI |
1 to 8 bytes |
Signed fixed-point |
| PD |
1 to 16 bytes |
Signed packed decimal |
| PD0 |
2 to 8 bytes |
Packed decimal with sign and first digit ignored |
| ZD |
1 to 31 bytes |
Signed zoned decimal |
| FL |
4 or 8 bytes |
Signed hexadecimal floating-point converted to
signed integer |
| CSF or FS |
1 to 32 bytes (31 digit limit) |
Signed numeric with optional leading floating
sign |
| UFF |
1 to 44 bytes (31 digit limit) |
Unsigned free form numeric |
| SFF |
1 to 44 bytes (31 digit limit) |
Signed free form numeric |
| DT1 |
4 bytes |
SMF date interpreted as Z'yyyymmdd' |
| DT2 |
4 bytes |
SMF date interpreted as Z'yyyymm' |
| DT3 |
4 bytes |
SMF date interpreted as Z'yyyyddd' |
| DC1 |
8 bytes |
TOD date interpreted as Z'yyyymmdd' |
| DC2 |
8 bytes |
TOD date interpreted as Z'yyyymm' |
| DC3 |
8 bytes |
TOD date interpreted as Z'yyyyddd' |
| DE1 |
8 bytes |
ETOD date interpreted as Z'yyyymmdd' |
| DE2 |
8 bytes |
ETOD date interpreted as Z'yyyymm' |
| DE3 |
8 bytes |
ETOD date interpreted as Z'yyyyddd' |
| TM1 |
4 bytes |
SMF time interpreted as Z'hhmmss' |
| TM2 |
4 bytes |
SMF time interpreted as Z'hhmm' |
| TM3 |
4 bytes |
SMF time interpreted as Z'hh' |
| TM4 |
4 bytes |
SMF time interpreted as Z'hhmmssxx' |
| TC1 |
8 bytes |
TOD time interpreted as Z'hhmmss' |
| TC2 |
8 bytes |
TOD time interpreted as Z'hhmm' |
| TC3 |
8 bytes |
TOD time interpreted as Z'hh' |
| TC4 |
8 bytes |
TOD time interpreted as Z'hhmmssxx' |
| TE1 |
8 bytes |
ETOD time interpreted as Z'hhmmss' |
| TE2 |
8 bytes |
ETOD time interpreted as Z'hhmm' |
| TE3 |
8 bytes |
ETOD time interpreted as Z'hh' |
| TE4 |
8 bytes |
ETOD time interpreted as Z'hhmmssxx' |
Note: See Appendix C, "Data Format Descriptions"
for detailed format descriptions.
|
For a CSF or FS format field: - A maximum of 31 digits is allowed. If a CSF or FS value with
32 digits is found, the leftmost digit will be treated as a positive
sign indicator.
For a UFF or SFF format field: - A maximum of 31 digits is allowed. If a UFF or SFF value with
more than 31 digits is found, the leftmost digits will be ignored.
For a ZD or PD format field: - An invalid digit results in a data exception (0C7 ABEND) or incorrect
numeric output; A-F are invalid digits. ICETOOL's VERIFY or DISPLAY
operator can be used to identify decimal values with invalid digits.
- A value is treated as positive if its sign is F, E, C, A, 8, 6,
4, 2, or 0.
- A value is treated as negative if its sign is D, B, 9, 7, 5, 3,
or 1.
For a PD0 format field: - The first digit is ignored.
- An invalid digit other than the first results in a data exception
(0C7 ABEND) or incorrect numeric output; A-F are invalid digits.
- The sign is ignored and the value is treated as positive.
For an FL format field: - The normalized or unnormalized FL (hexadecimal floating-point)
value is converted to a signed integer in the range -9223372036854775808
to 9223372036854775807. The fractional part of the FL value is lost,
and in some cases the signed integer may be one of a number of possible
signed integers for the FL value depending on its precision. Converted
values less than -9223372036854775808 are set to -9223372036854775808.
Converted values greater than 9223372036854775807 are set to 9223372036854775807.
- If you are not running in z/Architecture mode, specifying an FL
format field results in an error message and termination.
For a DT1, DT2, or DT3 format field: - An invalid SMF date can result in a data exception (0C7 ABEND)
or an incorrect ZD date.
- SMF date values are always treated as positive.
For a DC1, DC2, DC3, DE1, DE2, or DE3 format field: - TOD and ETOD date values are always treated as positive.
For a TM1, TM2, TM3, or TM4 format field: - An invalid SMF time can result in an incorrect ZD time.
- SMF time values are always treated as positive.
For a TC1, TC2, TC3, TC4, TE1, TE2, TE3, or TE4 format field: - TOD and ETOD time values are always treated as positive.
- edit
>>-+-Mn------------------------+-------------------------------><
'-+-EDIT=-+-+-(pattern)---+-'
'-EDxy=-' '-('pattern')-'
>>-+----------------------------+--+-----------+---------------><
'-,-+-SIGNS=-+-(lp,ln,tp,tn)-' '-,LENGTH=n-'
'-SIGNz=-'
Specifies how the numeric field is to be edited
for output. If an Mn, EDIT, or EDxy parameter is not specified: - a DC1, DC2, DC3, DE1, DE2, DE3, DT1, DT2, DT3, TC1, TC2, TC3,
TC4, TE1, TE2, TE3, TE4, TM1, TM2, TM3, or TM4 field is edited using
the M11 edit mask.
- a BI, FI, PD, PD0, ZD, FL, CSF, FS, UFF, or SFF field
is edited using the M0 edit mask.
- Mn
- specifies one of twenty-seven pre-defined edit masks (M0-M26)
for presenting numeric data. If these pre-defined edit masks are
not suitable for presenting your numeric data, the EDIT parameter
gives you the flexibility to define your own edit patterns.
The
twenty-seven pre-defined edit masks can be represented as follows:
Table 8. Edit Mask PatternsEdit Mask
PatternsMask
|
Pattern |
Examples |
|---|
| Value |
Result |
|---|
| M0 |
IIIIIIIIIIIIIIIIIIIIIIIIIIIIIITS |
+01234 |
1234 |
| -00001 |
1- |
| M1 |
TTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTS |
-00123 |
00123- |
| +00123 |
00123 |
| M2 |
II,III,III,III,III,III,III,III,III,IIT.TTS |
+123450 |
1,234.50 |
| -000020 |
0.20- |
| M3 |
II,III,III,III,III,III,III,III,III,IIT.TTCR |
-001234 |
12.34CR |
| +123456 |
1,234.56 |
| M4 |
SII,III,III,III,III,III,III,III,III,IIT.TT |
+0123456 |
+1,234.56 |
| -1234567 |
-12,345.67 |
| M5 |
SII,III,III,III,III,III,III,III,III,IIT.TTS |
-001234 |
(12.34) |
| +123450 |
1,234.50 |
| M6 |
III-TTT-TTTT |
00123456 |
012-3456 |
| 12345678 |
1-234-56788 |
| M7 |
TTT-TT-TTTT |
00123456 |
000-12-3456 |
| 12345678 |
012-34-5678 |
| M8 |
IT:TT:TT |
030553 |
3:05:53 |
| 121736 |
12:17:36 |
| M9 |
IT/TT/TT |
123004 |
12/30/04 |
| 083104 |
8/31/04 |
| M10 |
IIIIIIIIIIIIIIIIIIIIIIIIIIIIIIT |
01234 |
1234 |
| 00000 |
0 |
| M11 |
TTTTTTTTTTTTTTTTTTTTTTTTTTTTTTT |
00010 |
00010 |
| 01234 |
01234 |
| M12 |
SI,III,III,III,III,III,III,III,III,III,IIT |
+1234567 |
1,234,567 |
| -0012345 |
-12,345 |
| M13 |
SI.III.III.III.III.III.III.III.III.III.IIT |
+1234567 |
1.234.567 |
| -0012345 |
-12.345 |
| M14 |
SI III III III III III III III III III IITS |
+1234567 |
1 234 567 |
| -0012345 |
(12 345) |
| M15 |
I III III III III III III III III III IITS |
+1234567 |
1 234 567 |
| -0012345 |
12 345- |
| M16 |
SI III III III III III III III III III IIT |
+1234567 |
1 234 567 |
| -0012345 |
-12 345 |
| M17 |
SI'III'III'III'III'III'III'III'III'III'IIT |
+1234567 |
1'234'567 |
| -0012345 |
-12'345 |
| M18 |
SII,III,III,III,III,III,III,III,III,IIT.TT |
+0123456 |
1,234.56 |
| -1234567 |
-12,345.67 |
| M19 |
SII.III.III.III.III.III.III.III.III.IIT,TT |
+0123456 |
1.234,56 |
| -1234567 |
-12.345,67 |
| M20 |
SI III III III III III III III III IIT,TTS |
+0123456 |
1 234,56 |
| -1234567 |
(12 345,67) |
| M21 |
II III III III III III III III III IIT,TTS |
+0123456 |
1 234,567 |
| -1234567 |
12 345,67- |
| M22 |
SI III III III III IIII III III III IIT,TT |
+0123456 |
1 234,56 |
| -1234567 |
-12 345,67 |
| M23 |
SII'III'III'III'III'III'III'III'III'IIT.TT |
+0123456 |
1'234.56 |
| -1234567 |
-12'345.67 |
| M24 |
SII'III'III'III'III'III'III'III'III'IIT,TT |
+0123456 |
1'234,56 |
| -1234567 |
-12'345,67 |
| M25 |
SIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIT |
+01234 |
1234 |
| -00001 |
-1 |
| M26 |
STTTTTTTTTTTTTTTTTTTTTTTTTTTTTTT |
1234 |
+01234 |
| -1 |
-00001 |
The elements used in the representation of the edit masks in Table 8 are as follows: - I indicates a leading insignificant digit. If zero, this
digit will not be shown.
- T indicates a significant digit. If zero, this digit will
be shown.
- CR (in M3) is printed to the right of the digits if the
value is negative; otherwise, two blanks are printed to the right
of the digits.
- S indicates a sign. If it appears as the first character
in the pattern, it is a leading sign. If it appears as the last character
in the pattern, it is a trailing sign. If S appears as both the first
and last characters in a pattern (example: M5), the first character
is a leading sign and the last character is a trailing sign. Four
different sign values are used: leading positive sign (lp), leading
negative sign (ln), trailing positive sign (tp) and trailing negative
sign (tn). Their applicable values for the Mn edit masks are:
Table 9. Edit Mask SignsEdit Mask SignsMask
|
lp |
ln |
tp |
tn |
|---|
| M0 |
none |
none |
blank |
- |
| M1 |
none |
none |
blank |
- |
| M2 |
none |
none |
blank |
- |
| M3 |
none |
none |
none |
none |
| M4 |
+ |
- |
none |
none |
| M5 |
blank |
( |
blank |
) |
| M6 |
none |
none |
none |
none |
| M7 |
none |
none |
none |
none |
| M8 |
none |
none |
none |
none |
| M9 |
none |
none |
none |
none |
| M10 |
none |
none |
none |
none |
| M11 |
none |
none |
none |
none |
| M12 |
blank |
- |
none |
none |
| M13 |
blank |
- |
none |
none |
| M14 |
blank |
( |
blank |
) |
| M15 |
none |
none |
blank |
- |
| M16 |
blank |
- |
none |
none |
| M17 |
blank |
- |
none |
none |
| M18 |
blank |
- |
none |
none |
| M19 |
blank |
- |
none |
none |
| M20 |
blank |
( |
blank |
) |
| M21 |
none |
none |
blank |
- |
| M22 |
blank |
- |
none |
none |
| M23 |
blank |
- |
none |
none |
| M24 |
blank |
- |
none |
none |
| M25 |
blank |
- |
none |
none |
| M26 |
+ |
- |
none |
none |
- any other character (for example, /) will be printed as shown,
subject to certain rules to be subsequently discussed.
The implied length of the edited output field depends on the
number of digits and characters needed for the pattern of the particular
edit mask used. The LENGTH parameter can be used to change the implied
length of the edited output field.
The number of digits needed depends on the format and length of
the numeric field as follows: Table 10. Digits Needed for Numeric FieldsDigits Needed for Numeric
FieldsFormat
|
Input Length |
Digits Needed |
|---|
| ZD |
m |
m |
| PD |
m |
2m-1 |
| PD0 |
m |
2m-2 |
| BI, FI |
1 |
3 |
| BI, FI |
2 |
5 |
| BI, FI |
3 |
8 |
| BI, FI |
4 |
10 |
| BI, FI |
5 |
13 |
| BI, FI |
6 |
15 |
| BI, FI |
7 |
17 |
| BI, FI |
8 |
20 |
| FL |
4 or 8 |
20 |
| CSF or FS |
32 |
31 |
| CSF or FS |
m (less than 32) |
m |
| UFF, SFF |
32 to 44 |
31 |
| UFF, SFF |
m (less than 32) |
m |
The length of the output field can be represented as follows for
each pattern, where d is the number of digits needed, as shown in Table 10, and the result is rounded down to the
nearest integer: Table 11. Edit
Mask Output Field LengthsEdit Mask
Output Field Lengths
Mask |
Output Field Length |
Example |
|---|
| Input (f,m) |
Output Length |
|---|
| M0 |
d + 1 |
ZD,3 |
4 |
| M1 |
d + 1 |
PD,10 |
20 |
| M2 |
d + 1 + d/3 |
BI,4 |
14 |
| M3 |
d + 2 + d/3 |
UFF,20 |
28 |
| M4 |
d + 1 + d/3 |
PD,8 |
21 |
| M5 |
d + 2 + d/3 |
FI,3 |
12 |
| M6 |
12 |
ZD,10 |
12 |
| M7 |
11 |
PD,5 |
11 |
| M8 |
8 |
ZD,6 |
8 |
| M9 |
8 |
PD,4 |
8 |
| M10 |
d |
BI,6 |
15 |
| M11 |
d |
PD,5 |
9 |
| M12 |
d + 1 + (d - 1)/3 |
PD,3 |
7 |
| M13 |
d + 1 + (d - 1)/3 |
FS,5 |
7 |
| M14 |
d + 2 + (d - 1)/3 |
ZD,5 |
8 |
| M15 |
d + 1 + (d - 1)/3 |
FI,3 |
11 |
| M16 |
d + 1 + (d - 1)/3 |
SFF,41 |
42 |
| M17 |
d + 1 + (d - 1)/3 |
FI,4 |
14 |
| M18 |
d + 1 + d/3 |
BI,4 |
14 |
| M19 |
d + 1 + d/3 |
PD,8 |
21 |
| M20 |
d + 2 + d/3 |
FI,3 |
12 |
| M21 |
d + 1 + d/3 |
ZD,3 |
5 |
| M22 |
d + 1 + d/3 |
BI,2 |
7 |
| M23 |
d + 1 + d/3 |
PD,6 |
15 |
| M24 |
d + 1 + d/3 |
ZD,21 |
29 |
| M25 |
d + 1 |
CSF,16 |
17 |
| M26 |
d + 1 |
FL,4 |
21 |
To illustrate conceptually how DFSORT produces the edited output
from the numeric value, consider the following example: OUTFIL OUTREC=(5,7,ZD,M5)
with ZD values of C'0123456'(+0123456)
and C'000302J' (-0003021)
As shown in the preceding tables, it is determined that: - The general pattern for M5 is: SI,III,...,IIT.TTS
- The signs to be used are blank for leading positive sign, C'('
for leading negative sign, blank for trailing positive sign and C')'
for trailing negative sign
- The number of digits needed is 7
- The length of the output field is 11 (7 + 2 + 7/3)
- The specific pattern for the output field is thus: C'SII,IIT.TTS'
The digits of C'0123456' are mapped to the pattern, resulting in
C'S01,234.56S'. Because the value is positive, the leading sign is
replaced with blank and the trailing sign is replaced with blank,
resulting in C' 01,234.56 '. Finally, all digits before the first
non-zero digit (1 in this case), are replaced with blanks, resulting
in the final output of C' 1,234.56 '.
The digits of C'000302J' are mapped to the pattern, resulting in
C'S00,030.21S'. Because the value is negative, the leading sign is
replaced with C'(' and the trailing sign is replaced with C')' resulting
in C'(00,030.21)'. All digits before the first non-zero digit (3 in
this case), are replaced with blanks, resulting in C'( 30.21)'.
Finally, the leading sign is "floated" to the right, next to the first
non-zero digit, resulting in the final output of C' (30.21)'.
To state the rules in more general terms, the steps DFSORT takes
conceptually to produce the edited output from the numeric value are
as follows: - Determine the specific pattern and its length, using the preceding
tables.
- Map the digits of the numeric value to the pattern.
- If the value is positive, replace the leading and trailing signs
(if any) with the characters for positive values shown in Table 9. Otherwise, replace the leading and
trailing signs (if any) with the characters for negative values shown
in that same table.
- Replace all digits before the first non-zero (I) or significant
digit (T) with blanks.
- Float the leading sign (if any) to the right, next to the first
non-zero (I) or significant digit (T).
The following additional rule applies to edit masks: - The specific pattern is determined from the general pattern by
including signs, the rightmost digits needed as determined from the
input format and length, and any characters in between those rightmost
digits. This may unintentionally truncate significant digits (T).
As an example, if you specify 5,1,ZD,M4, the length of the output
field will be 2 (1 + 1 + 1/3). The general pattern for M4 is SI,III,...,IIT.TT,
but the specific pattern will be ST (the leading sign and the rightmost
digit).
- EDIT
- specifies an edit pattern for presenting numeric data. If the
pre-defined edit masks (M0-M26) are not suitable for presenting your
numeric data, EDIT gives you the flexibility to define your own edit
patterns. The elements you use to specify the pattern are the same
as those used for the edit masks: I, T, S, and printable characters.
However, S will not be recognized as a sign indicator unless the
SIGNS parameter is also specified.
- pattern
- specifies the edit pattern to be used. Not enclosing the pattern
in single apostrophes restricts you from specifying the following
characters in the pattern: blank, apostrophe, unbalanced left or
right parentheses, and hexadecimal digits 20, 21, and 22. For example,
EDIT=((IIT.TT)) is valid, whereas EDIT=(C)ITT.TT), EDIT=(I / T) and
EDIT=(S'II.T) are not.
The maximum number of digits (I's and T's)
you specify in the pattern must not exceed 31. The maximum length
of the pattern must not exceed 44 characters.
- 'pattern'
- specifies the edit pattern to be used. Enclosing the pattern
in single apostrophes allows you to specify any character in the pattern
except hexadecimal digits 20, 21, or 22. If you want to include a
single apostrophe in the pattern, you must specify it as two single
apostrophes, which will be counted as a single character in the pattern.
As examples, EDIT=('C)ITT.TT'), EDIT=('I / T'), and EDIT=('S'II.T')
are all valid.
The maximum number of digits (I's and T's) you specify
in the pattern must not exceed 31. The maximum length of the pattern
must not exceed 44 characters.
The implied length of the edited output field
is the same as the length of the pattern. The LENGTH parameter can
be used to change the implied length of the edited output field.
To
illustrate conceptually how DFSORT produces the edited output from
the numeric value, consider the following example: OUTFIL OUTREC=(1,5,ZD,EDIT=(**I/ITTTCR))
with ZD values of C'01230'(+1230)
and C'0004J' (-41)
The digits of C'01230' are
mapped to the pattern, resulting in C'**0/1230CR'. Because the value
is positive, the characters (C'CR') to the right of the last digit
are replaced with blanks, resulting in C'**0/1230 '. All digits before
the first non-zero digit (1 in this case) are replaced with blanks,
resulting in C'** /1230 '. Finally, all characters before the first
digit in the pattern are floated to the right, next to the first non-zero
digit, resulting in C' **1230 '.
The digits of C'0004J' are
mapped to the pattern, resulting in C'**0/0041CR'. Because the value
is negative, the characters (C'CR') to the right of the last digit
are kept. All digits before the first T digit are replaced with blanks,
resulting in C'** / 041CR'. Finally, all characters before the first
digit in the pattern are floated to the right, next to the first non-zero
digit, resulting in C' **041CR'.
In general terms, the steps
DFSORT takes conceptually to produce the edited output from the numeric
value are as follows: - Map the digits of the numeric value to the pattern, padding on
the left with zeros, if necessary.
- If the value is positive, replace the leading and trailing signs
(if any) with the characters for positive values specified by the
SIGNS parameter and replace any characters between the last digit
and the trailing sign (if any) with blanks. Otherwise, replace the
leading and trailing signs (if any) with the characters for negative
values specified by the SIGNS parameter and keep any characters between
the last digit and the trailing sign (if any).
- Replace all digits before the first non-zero (I) or significant
digit (T) with blanks.
- Float all characters (if any) before the first digit in the pattern
to the right, next to the first non-zero (I) or significant digit
(T).
The following additional rules apply to edit patterns: - An insignificant digit (I) after a significant digit (T) is treated
as a significant digit.
- If SIGNS is specified, an S in the first or last character of
the pattern is treated as a sign; an S anywhere else in the pattern
is treated as the letter S. If SIGNS is not specified, an S anywhere
in the pattern is treated as the letter S.
- If the pattern contains fewer digits than the value, the leftmost
digits of the value will be lost, intentionally or unintentionally.
As an example, if you specify 5,5,ZD,EDIT=(IIT) for a value of C'12345',
the result will be C'345'. As another example, if you specify 1,6,ZD,EDIT=($IIT.T)
for a value of C'100345', the result will be C' $34.5'.
- EDxy
- specifies an edit pattern for presenting numeric data. EDxy is
a special variation of EDIT that allows other characters to be substituted
for I and T in the pattern. For example, if you use EDAB instead
of EDIT, you must use A in the pattern instead of I and use B instead
of T to represent digits. x and y must not be the same character.
If SIGNS is specified, x and y must not be S. If SIGNz is specified,
x and y must not be the same character as z. You can select x and
y from: A-Z, #, $, @, and 0-9.
- SIGNS
- specifies the sign values to be used when editing numeric values
according to the edit mask (Mn) or pattern (EDIT or EDxy). You can
specify any or all of the four sign values. Any value not specified
must be represented by a comma. Blank will be used for any sign value
you do not specify. As examples, SIGNS=(+,-) specifies + for lp, -
for ln, blank for tp, and blank for tn; SIGNS=(,,+,-) specifies blank
for lp, blank for ln, + for tp, and - for tn.
- lp
- specifies the value for the leading positive sign. If an S is
specified as the first character of the edit mask or pattern and the
value is positive, the lp value will be used as the leading sign.
- ln
- specifies the value for the leading negative sign. If an S is
specified as the first character of the edit mask or pattern and the
value is negative, the ln value will be used as the leading sign.
- tp
- specifies the value for the trailing positive sign. If an S is
specified as the last character of the edit mask or pattern and the
value is positive, the tp value will be used as the trailing sign.
- tn
- specifies the value for the trailing negative sign. If an S is
specified as the last character of the edit mask or pattern and the
value is negative, the tn value will be used as the trailing sign.
If you want to use any of the following characters
as sign values, you must enclose them in single apostrophes: comma,
blank, or unbalanced left or right parentheses. A single apostrophe
must be specified as four single apostrophes (that is, two single
apostrophes enclosed in single apostrophes).
A semicolon cannot
be substituted for a comma as the delimiter between sign characters.
- SIGNz
- specifies the sign values to be used when editing numeric values
according to the edit pattern (EDIT or EDxy). SIGNz is a special variation
of SIGNS which allows another character to be substituted for S in
the pattern. For example, if you use SIGNX instead of SIGNS, you
must use X in the pattern instead of S to identify a sign. If EDIT
is specified, z must not be I or T. If EDxy is specified, z must not
be the same character as either x or y. You can select z from: A-Z,
#, $, @, and 0-9.
- LENGTH
- specifies the length of the edited output field. If the implied
length of the edited output field produced using an edit mask or edit
pattern is not suitable for presenting your numeric data, LENGTH can
be used to make the edited output field shorter or longer.
- n
- specifies the length of the edited output field. The value for
n must be between 1 and 44.
LENGTH does not change the pattern used,
only the length of the resulting edited output field. For example,
as discussed previously for Mn, if you specify: OUTFIL OUTREC=(5,1,ZD,M4)
the
pattern will be C'ST' rather than C'ST.TT' because the digit length
is 1. Specifying: OUTFIL OUTREC=(5,1,ZD,M4,LENGTH=5)
will
change the pattern to C' ST', not to C'ST.TT'. If you specify
a value for n that is shorter than the implied length, truncation
will occur on the left after editing. For example, if you specify: OUTFIL OUTREC=(1,5,ZD,EDIT=($IIT.TT),LENGTH=5)
with
a value of C'12345', editing according to the specified $IIT.TT pattern
will produce C'$123.45', but the specified length of 5 will truncate
this to C'23.45'.
If you specify a value for n that is longer
than the implied length, padding on the left with blanks will occur
after editing. For example, if you specify: OUTFIL OUTREC=(1,5,ZD,EDIT=($IIT.TT),LENGTH=10)
with
a value of C'12345', editing according to the specified $IIT.TT pattern
will produce C'$123.45', but the specified length of 10 will pad this
to C' $123.45'. Sample Syntax: OUTFIL FNAMES=OUT1,OUTREC=(5:21,19,ZD,M19,35:46,5,ZD,M13)
OUTFIL FILES=1,OUTREC=(4,8,BI,C' * ',13,8,BI,80:X),
ENDREC=10,OMIT=(4,8,BI,EQ,13,8,BI)
OUTFIL FILES=(2,3),
OUTREC=(11:55,6,FS,SIGNS=(,,+,-),LENGTH=10,
31:(41,4,PD),EDIT=(**II,IIT.TTXS),SIGNS=(,,+,-))
- %nn,f,edit or (%nn,f),edit
- specifies that an edited numeric parsed input field is to appear
in the reformatted OUTFIL output record. See PARSE for details of
parsed fields. See p,m,f,edit or (p,m,f),edit for further details.
- p,m,f,to or (p,m,f),to
- specifies that a converted numeric input field is to appear in
the reformatted OUTFIL output record. You can convert BI, FI, PD,
PD0, ZD, FL, CSF, FS, UFF, SFF, DC1, DC2, DC3,
DE1, DE2, DE3, DT1, DT2, DT3, TC1, TC2, TC3, TC4, TE1, TE2, TE3, TE4,
TM1, TM2, TM3, or TM4 fields to BI, FI, PD, PDC, PDF, ZD,
ZDF, ZDC, or CSF/FS fields.
- p
- See p under p,m,f,edit.
- m
- See m under p,m,f,edit.
- f
- See f under p,m,f,edit.
- to
>>-+-fo-----------+-+------------------+-----------------------><
'-TO=-+-fo---+-' '-,LENGTH=-+-n---+-'
'-(fo)-' '-(n)-'
specifies how the numeric field is to be converted
for output.
- fo
- specifies the format for the output field, which can be BI, FI,
PD, PDC, PDF, ZD, ZDF, ZDC, CSF or FS. Any one
of these output field formats (fo) can be used with any one of the
input field formats (f).
If you do not specify the LENGTH parameter,
DFSORT will determine the implied length of the output field from
the length (m) and format (f) of the input field and the format (fo)
of the output field. The implied length of the output field can be
represented as follows for each output format, where d is the number
of digits needed for the input field as shown in Table 10, and the result is rounded down to the
nearest integer:
Table 12. To Output Field LengthsTo Output Field LengthsOutput
Format
|
Output Length |
Example Input (f,m) |
Example Output Length |
|---|
| BI with d <= 9 |
4 |
FS,9 |
4 |
| BI with d > 9 |
8 |
FS,10 |
8 |
| FI with d <= 9 |
4 |
ZD,7 |
4 |
| FI with d > 9 |
8 |
ZD,12 |
8 |
| PD, PDC, or PDF |
d/2 + 1 |
BI,4 |
6 |
| ZD, ZDF, or ZDC |
d |
PD,9 |
17 |
| CSF or FS |
d + 1 |
FI,4 |
21 |
For ZD or ZDF output, F is used as the positive sign and
D is used as the negative sign. For ZDC output, C is used as the
positive sign.
For PD or PDC output, C is used as
the positive sign and D is used as the negative sign. For PDF output,
F is used as the positive sign.
For CSF or FS output, blank
is used as the positive sign, - is used as the negative sign and leading
zeros are suppressed.
For ZD, ZDF, ZDC, PD, PDC,
PDF, CSF, or FS output, the maximum output value is 9999999999999999999999999999999
(31 digits) and the minimum output value is -9999999999999999999999999999999
(31 digits), which correspond to the maximum and minimum input values,
respectively.
For BI output: - An input value greater than 18446744073709551615 (X'FFFFFFFFFFFFFFFF')
produces an output value of 18446744073709551615 (X'FFFFFFFFFFFFFFFF').
- An input value less than zero produces an absolute output value.
For example, an input value of P'-5000' produces a BI output value
of 5000 (X'1388').
For FI output, an input value greater than 9223372036854775807
(X'7FFFFFFFFFFFFFFF') produces an output value of 9223372036854775807
(X'7FFFFFFFFFFFFFFF'), and an input value less than -9223372036854775808
(X'8000000000000000') produces an output value of -9223372036854775808
(X'8000000000000000').
fo, TO=fo and TO=(fo) are interchangeable
except that: - fo must be specified before the LENGTH parameter whereas TO can
be specified before or after the LENGTH parameter.
- TO=fo or TO=(fo) should be used after a symbol rather than fo
to prevent the misinterpretation of fo as f. See the discussion of
OUTFIL OUTREC in Chapter 7 for details.
- LENGTH
- specifies the length of the converted output field. If the implied
length of the output field is not suitable, LENGTH can be used to
make the output field shorter or longer.
- n
- specifies the length of the converted output field. The value
for n must be between 1 and 44.
If you specify a value for n that
is shorter than the implied length, truncation on the left will occur
after conversion. For example, if you specify: OUTFIL OUTREC=(1,8,ZD,TO=PD,LENGTH=3)
with
values of ZL8'-12345678' (X'F1F2F3F4F5F6F7D8') and ZL8'58' (X'F0F0F0F0F0F0F5F8'),
conversion with the implied length (5) will produce PL5'-12345678'
(X'012345678D') and PL5'58' (X'0000000058C'). The specified length
of 3 will then result in truncation to PL3'-45678' (X'45678D') and
PL3'58' (X'00058C'). If you specify a value for n that is longer
than the implied length, padding on the left will occur after conversion
using: - Blanks for CSF and FS output values
- Character zeros for ZD output values
- Binary zeros for PD and BI output values
- Binary zeros for positive FI output values
- Binary ones for negative FI output values
For example, if you specify: OUTFIL OUTREC=(1,4,ZD,TO=FI,LENGTH=6)
with
values of ZL4'-1234' (X'F1F2F3D4') and ZL4'58' (X'F0F0F5F8'), conversion
with the implied length (4) will produce FL4'-1234' (X'FFFFFB2E')
and FL4'58' (X'000004D2'). The specified length of 6 will then result
in padding to FL6'-1234' (X'FFFFFFFFFB2E') and FL6'58' (X'00000000003A'). Sample
Syntax: OUTFIL OUTREC=((21,5,ZD),PD,X,8,4,ZD,TO=FI,LENGTH=2)
- %nn,f,to or (%nn,f),to
- specifies that a converted numeric parsed input field is to appear
in the reformatted OUTFIL output record. See PARSE for details of
parsed fields. See p,m,f,to or (p,m,f),to for further details.
- deccon,edit or (deccon),edit
- specifies that an edited decimal constant is to appear in the
reformatted OUTFIL output record. The decimal constant must be in
the form +n or -n where n is 1 to 31 decimal digits. The sign (+
or -) must be specified. A decimal constant produces a signed, 31-digit
zoned decimal (ZD) result to be edited as specified. If an Mn, EDIT,
or EDxy parameter is not specified, the decimal constant is edited
using the M0 edit mask.
The default number of digits (d) used for
editing is 15 for a decimal constant with 1 to 15 significant digits,
or 31 for a decimal constant with 16 to 31 significant digits. If
EDIT or EDxy is specified, the number of digits in the pattern (I's
and T's) is used.
See edit under p,m,f,edit for further details
on the edit fields you can use.
Sample Syntax: OUTFIL OUTREC=(5,8,+4096,2X,-17,M18,LENGTH=7,2X,
(+2000000),EDIT=(STTTTT.TT),SIGNS=(+))
- deccon,to or (deccon),to
- specifies that a converted decimal constant is to appear in the
reformatted OUTFIL output record. The decimal constant must be in
the form +n or -n where n is 1 to 31 decimal digits. The sign (+ or
-) must be specified. A decimal constant produces a signed, 31-digit
zoned decimal (ZD) result to be converted as specified.
The default
number of digits (d) used for conversion is 15 for a decimal constant
with 1 to 15 significant digits, or 31 for a decimal constant with
16 to 31 significant digits.
See to under p,m,f,to for further
details on the to fields you can use.
Sample Syntax: OUTFIL FNAMES=OUT1,
OUTREC=(6:+0,TO=PD,LENGTH=6,+0,TO=PD,LENGTH=6,/,
6:(-4096),ZD,LENGTH=12)
- arexp,edit or (arexp),edit
- Specifies that the edited result of an arithmetic expression is
to appear in the reformatted OUTFIL output record. An arithmetic
expression takes the form:
term,operator,term<,operator,...>
where: - term is a field (p,m,f), a parsed field (%nn,f),
or a decimal constant (+n or -n). See p,m,f under p,m,f,edit for
details on the fields you can use. See deccon under deccon,edit for
details on the decimal constants you can use.
- operator is MIN (minimum), MAX (maximum), MUL (multiplication),
DIV (division), MOD (modulus), ADD (addition) or SUB (subtraction).
The order of evaluation precedence for the operators is
as follows unless it is changed by parentheses: - MIN and MAX
- MUL, DIV and MOD
- ADD and SUB
The intermediate or final result of a DIV operation is
rounded down to the nearest integer. The intermediate or final result
of a MOD operation is an integer remainder with the same sign as the
dividend. If an intermediate or final result of an arithmetic expression
overflows 31 digits, the overflowing intermediate or final result
will be truncated to 31 digits, intentionally or unintentionally.
If an intermediate or final result of an arithmetic expression requires
division or modulus by 0, the intermediate or final result will be
set to 0, intentionally or unintentionally.
An arithmetic expression
produces a signed, 31-digit zoned decimal (ZD) result to be edited
as specified. If an Mn, EDIT, or EDxy parameter is not specified,
the result is edited using the M0 edit mask.
The default number
of digits (d) used for editing is 15 if every term in the expression
is one of the following: - a 1-4 byte BI or FI field
- a 1-8 byte PD field
- a 1-15 byte ZD, FS, CSF, UFF or SFF field
- a decimal constant with 1-15 significant digits.
The default number of digits (d) used for editing is 31
if any term in the expression is one of the following: - a 5-8 byte BI or FI field
- a 9-16 byte PD field
- a 16-31 byte ZD field
- a 4-byte or 8-byte FL field
- a 16-32 byte FS or CSF field
- a 16-44 byte UFF or SFF field
- a decimal constant with 16-31 significant digits.
If EDIT or EDxy is specified, the number of digits in
the pattern (I's and T's) is used.
See edit under p,m,f,edit
for further details on the edit fields you can use.
Sample
Syntax: OUTFIL OUTREC=(5:C'% REDUCTION FOR ',21,8,C' IS ',
((11,6,ZD,SUB,31,6,ZD),MUL,+1000),DIV,11,6,ZD,
EDIT=(SIIT.T),SIGNS=(+,-))
- arexp,to or (arexp),to
- specifies that the converted result of an arithmetic expression
is to appear in the reformatted OUTFIL output record. See arexp under
arexp,edit for further details on arithmetic expressions.
An
arithmetic expression produces a signed, 31-digit zoned decimal (ZD)
result to be converted as specified.
The default number of digits
(d) used for conversion is 15 if every term in the expression
is one of the following: - a 1-4 byte BI or FI field
- a 1-8 byte PD field
- a 1-15 byte ZD, FS, CSF, UFF or SFF field
- a decimal constant with 1-15 significant digits.
The default number of digits (d) used for conversion is
31 if any term in the expression is one of the following: - a 5-8 byte BI or FI field
- a 9-16 byte PD field
- a 16-31 byte ZD field
- a 4-byte or 8-byte FL field
- a 16-32 byte FS or CSF field
- a 16-44 byte UFF or SFF field
- a decimal constant with 16-31 significant digits.
See to under p,m,f,to for further details on the to fields
you can use.
Sample Syntax: OUTFIL FNAMES=OUT,
OUTREC=(61,3,X,
35,6,FS,ADD,45,6,FS,ADD,55,6,FS,TO=FS,LENGTH=7,X,
(5,11,PD,MIN,112,11,PD),PD,LENGTH=11,X,
64,5,SEQNUM,5,ZD)
- p,m,Y2x or p,m,Y4x
- Specifies that an input date field is to be edited. Real Y2x dates
are edited using the century window established by the Y2PAST option
in effect. Y2x and Y4x dates with special indicators are expanded
appropriately (for example, p,6,Y2T transforms C'000000' to C'00000000').
Editing
involving an input date with an invalid digit (A-F) can result in
a data exception (0C7 ABEND) or an incorrect output value. Editing
involving an invalid input date can result in an invalid output value.
- p
- See p under p,m,a.
- m
- Specifies the length in bytes of the Y2x (two-digit year) or Y4x
(four-digit year) date field.
- Y2x or Y4x
- Specifies the Y2 or Y4 format for the date field. See Data format descriptions for detailed format descriptions.
Sample Syntax: OUTFIL BUILD=(21,3,Y2U,X,3,8,Y4W)
Table 13 shows the output produced for each
type of edited date.
Table 13. Input and result
fields for Yxx date editingInput and result fields for Yxx date
editingm,Yxx
|
Input date |
Output for p,m,Yxx |
|---|
3,Y2T
4,Y2T
5,Y2T
6,Y2T
7,Y4T
8,Y4T
2,Y2U
3,Y2V
3,Y2U
4,Y2V
4,Y4U
5,Y4V
3,Y2W
4,Y2W
5,Y2W
6,Y2W
7,Y4W
8,Y4W
2,Y2X
3,Y2Y
3,Y2X
4,Y2Y
4,Y4X
5,Y4Y
2,Y2C
2,Y2Z
2,Y2S
2,Y2P
1,Y2D
1,Y2B
|
C'yyx' or Z'yyx'
C'yyxx' or Z'yyxx'
C'yyddd' or Z'yyddd'
C'yymmdd' or Z'yymmdd'
C'ccyyddd' or Z'ccyyddd'
C'ccyymmdd' or Z'ccyymmdd'
P'yyx'
P'yyxx'
P'yyddd'
P'yymmdd'
P'ccyyddd'
P'ccyymmdd'
C'xyy' or Z'xyy'
C'xxyy' or Z'xxyy'
C'dddyy' or Z'dddyy'
C'mmddyy' or Z'mmddyy'
C'dddccyy' or Z'dddccyy'
C'mmddccyy' or Z'mmddccyy'
P'xyy'
P'xxyy'
P'dddyy'
P'mmddyy'
P'dddccyy'
P'mmddccyy'
C'yy'
Z'yy'
C'yy'
P'yy'
X'yy'
B'yy'
|
C'ccyyx'
C'ccyyxx'
C'ccyyddd'
C'ccyymmdd'
C'ccyyddd'
C'ccyymmdd'
C'ccyyx'
C'ccyyxx'
C'ccyyddd'
C'ccyymmdd'
C'ccyyddd'
C'ccyymmdd'
C'xccyy'
C'xxccyy'
C'dddccyy'
C'mmddccyy'
C'dddccyy'
C'mmddccyy'
C'xccyy'
C'xxccyy'
C'dddccyy'
C'mmddccyy'
C'dddccyy'
C'mmddccyy'
C'ccyy'
C'ccyy'
C'ccyy'
C'ccyy'
C'ccyy'
C'ccyy'
|
- %nn,Y2x or %nn,Y4x
- Specifies that a parsed input date field is to be edited. See
PARSE for details of parsed fields. See "p,m,Y2x or p,m,Y4x" for
further details.
- p,m,Y2x,edit or p,m,Y4x,edit
- Specifies that the output for a p,m,Yxx input date field as shown
in Table 13 is to be further edited according
to the edit parameters you specify. For example, if you specify:
OUTFIL BUILD=(28,5,Y4V,EDIT=(TTTT-TT-TT)
The
P'ccyymmdd' (X'0ccyymmddC') date value will be transformed to a C'ccyymmdd'
date value and then edited to a C'ccyy-mm-dd' date value.
See
"p,m,Y2x or p,m,Y4x" and "p,m,f,edit" for related details.
- nn,Y2x,edit or %nn,Y4x,edit
- Specifies that the output for a parsed Yxx input date field as
shown in Table 13 is to be further edited
according to the edit parameters you specify. See PARSE for details
of parsed fields. See "p,m,Y2x,edit or p,m,Y4x,edit" for further
details.
- p,m,Y2x,to or p,m,Y4x,to
- Specifies that an input date field as shown in Table 13 is to be converted according to the
to parameters you specify. For example, if you specify:
OUTFIL BUILD=(5,6,Y2W,TO=PD,LENGTH=5)
The
C'mmddyy' date value will be transformed to a Z'mmddccyy' date value
and then converted to a P'mmddccyy' (X'0mmddccyyC') date value.
See
"p,m,Y2x or p,m,Y4x" and "p,m,f,to" for related details.
- %nn,Y2x,to or %nn,Y4x,to
- Specifies that a parsed input date field as shown in Table 13 is to be converted according to the
to parameters you specify. See PARSE for details of parsed fields.
See "p,m,Y2x,to or p,m,Y4x,to" for further details.
- p,m,Y2x,todate or p,m,Y4x,todate
>>-p,m---+-,Y2x,-+-----+-TOJUL=Yaa------+----------------------><
'-,Y4x,-' +-TOJUL=Yaa(s)---+
+-TOGREG=Yaa-----+
+-TOGREG=Yaa(s)--+
+-WEEKDAY=CHAR3--+
+-WEEKDAY=CHAR9--+
+-WEEKDAY=DIGIT1-+
+-DT=(abcd)------+
'-DTNS=(abc)-----'
Specifies that an input date field of one type
is to be converted to a corresponding output date field of another
type. You can convert date fields between combinations of 2-digit
and 4-digit year dates, CH/ZD and PD dates, and Julian and Gregorian
dates. You can also convert a date field to a corresponding day of
the week in several forms.
Each type of date field you can use
as input for date conversions is shown in Table 14.
Table 14. Input fields for p,m,Yxx date conversionInput fields for p,m,Yxx date conversionm,Yxx
|
Input date |
|---|
5,Y2T
6,Y2T
7,Y4T
8,Y4T
3,Y2U
4,Y2V
4,Y4U
5,Y4V
5,Y2W
6,Y2W
7,Y4W
8,Y4W
3,Y2X
4,Y2Y
4,Y4X
5,Y4Y
|
C'yyddd' or Z'yyddd'
C'yymmdd' or Z'yymmdd'
C'ccyyddd' or Z'ccyyddd'
C'ccyymmdd' or Z'ccyymmdd'
P'yyddd'
P'yymmdd'
P'ccyyddd'
P'ccyymmdd'
C'dddyy' or Z'dddyy'
C'mmddyy' or Z'mmddyy'
C'dddccyy' or Z'dddccyy'
C'mmddccyy' or Z'mmddccyy'
P'dddyy'
P'mmddyy'
P'dddccyy'
P'mmddccyy'
|
- p
- See p under p,m,a.
- m
- Specifies the length in bytes of the Y2x (two-digit year) or Y4x
(four-digit year) date field.
- Y2x or Y4x
- Specifies the Y2 or Y4 format for the date field. See Data format descriptions for detailed format descriptions.
- todate
- Specifies the type of date conversion to be performed.
- p,m,Yxx,TOJUL=Yaa
- Converts the input date to a Julian output date.
- p,m,Yxx,TOJUL=Yaa(s)
- Converts the input date to a Julian output date with s separators.
s can be any character except a blank.
- p,m,Yxx,TOGREG=Yaa
- Converts the input date to a Gregorian output date.
- p,m,Yxx,TOGREG=Yaa(s)
- Converts the input date to a Gregorian output date with s separators.
s can be any character except a blank.
The output date field created by each valid TOJUL
and TOGREG combination is shown in Table 15.
Table 15. TOJUL and TOGREG output date fieldsTOJUL and TOGREG output date fieldsYaa
|
TOJUL=Yaa |
TOJUL=Yaa(s) |
TOGREG=Yaa |
TOGREG=Yaa(s) |
|---|
Y2T
Y2W
Y2U
Y2V
Y2X
Y2Y
Y4T
Y4W
Y4U
Y4V
Y4X
Y4Y
|
C'yyddd'
C'dddyy'
P'yyddd'
n/a
P'dddyy'
n/a
C'ccyyddd'
C'dddccyy'
P'ccyyddd'
n/a
P'dddccyy'
n/a
|
C'yysddd'
C'dddsyy'
n/a
n/a
n/a
n/a
C'ccyysddd'
C'dddsccyy'
n/a
n/a
n/a
n/a
|
C'yymmdd'
C'mmddyy'
n/a
P'yymmdd'
n/a
P'mmddyy'
C'ccyymmdd'
C'mmddccyy'
n/a
P'ccyymmdd'
n/a
P'mmddccyy'
|
C'yysmmsdd'
C'mmsddsyy'
n/a
n/a
n/a
n/a
C'ccyysmmsdd'
C'mmsddsccyy'
n/a
n/a
n/a
n/a
|
Sample Syntax:* Convert a P'dddyy' input date to a C'ccyy/mm/dd' output date
OUTFIL BUILD=(21,3,Y2X,TOGREG=Y4T(/),X,
* Convert a C'ccyymmdd' input date to a P'ccyyddd' output date
42,8,Y4T,TOJUL=Y4U,X,
* Convert a C'mmddyy' input date to a C'yymmdd' output date
11,6,Y2W,TOGREG=Y2T)
- p,m,Yxx,WEEKDAY={CHAR3|CHAR9|DIGIT1}
- Converts an input date field to a corresponding output day of
the week in one of several forms.
Each type of input date field
you can use is shown in Table 14. The
different types of output you can display are shown in Table 16.
Table 16. Output
for weekdaysOutput for weekdaysDay
|
CHAR3 |
CHAR9 |
DIGIT1 |
|---|
Sunday
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
|
C'SUN'
C'MON'
C'TUE'
C'WED'
C'THU'
C'FRI'
C'SAT'
|
C'SUNDAY '
C'MONDAY '
C'TUESDAY '
C'WEDNESDAY'
C'THURSDAY '
C'FRIDAY '
C'SATURDAY '
|
C'1'
C'2'
C'3'
C'4'
C'5'
C'6'
C'7'
|
Sample Syntax:* Convert a P'mmddccyy' input date to a 3-character weekday
OUTFIL BUILD=(5:15,5,Y4Y,WEEKDAY=CHAR3,
* Convert a C'yyddd' input date to a 1-digit weekday
18:27,5,Y2T,WEEKDAY=DIGIT1,
* Convert a P'dddccyy' input date to a 9-character weekday
41:121,4,Y4X,WEEKDAY=CHAR9)
- p,m,Yxx,DT=(abcd) or p,m,Yxx,DTNS=(abc)
- Converts an input date field of one type to a corresponding Gregorian
output date field of another type.
Each type of input date field
you can use is shown in Table 14.
DT=(abcd) creates
an output date in the form C'adbdc', where a, b, and c indicate the
order in which the month, day, and year are to appear and whether
the year is to appear as two or four digits, and d is the character
to be used to separate the month, day and year. For a, b, and c,
use M to represent the month (01-12), D to represent the day (01-31),
Y to represent the last two digits of the year (for example, 09),
or 4 to represent the four digits of the year (for example, 2009).
M, D, and Y or 4 can each be specified only once.
DTNS=(abc) creates
an output date in the form C'abc', where a, b and c indicate the order
in which the month, day, and year are to appear and whether the year
is to appear as two or four digits. For a, b and c, use M
to represent the month (01-12), D to represent the day (01-31), Y
to represent the last two digits of the year (for example, 09), or
4 to represent the four digits of the year (for example, 2009). M,
D, and Y or 4 can each be specified only once.
Sample Syntax:* Convert a C'yyddd' input date to a C'dd/mm/ccyy' output date
OUTFIL BUILD=(92,5,Y2T,DT=(DM4/),X,
* Convert a P'ccyyddd' input date to a C'mmddyy' output date
53:32,4,Y4U,DTNS=(MDY))
- Conversion of Real Dates, Special Indicators and Invalid Dates
- For CH/ZD dates (Y2T, Y4T, Y2W, Y4W), the zone and sign are ignored;
only the digits are used. For example, X'F2F0F0F9F1F2F3D0' and X'A2B0C0D9E1F21320'
are treated as 20091230. For PD dates (Y2U, Y4U, Y2V, Y4V, Y2X, Y4X,
Y2Y, Y4Y), the sign is ignored; only the relevant digits are used.
For example, X'120091230D' is treated as 20091230.
For CH/ZD dates
(Y2T, Y4T, Y2W, Y4W), the special indicators are X'00...00' (BI zeros),
X'40...40' (blanks), C'0...0' (CH zeros), Z'0...0' (ZD zeros), C'9...9'
(CH nines), Z'9...9' (ZD nines) and X'FF...FF' (BI ones). For PD
dates (Y2U, Y4U, Y2V, Y4V, Y2X, Y4X, Y2Y, Y4Y), the special indicators
are P'0...0' (PD zeros) and P'9...9' (PD nines).
yy for real
2-digit year dates is transformed to ccyy when appropriate using the
century window established by the Y2PAST option in effect. ccyy for
real 4-digit year dates is transformed to yy when appropriate by removing
cc.
Date conversion is not performed for special indicators;
the special indicator is just used appropriately for the output date
field. For example, if p,5,Y2T,TOGREG=Y4T(/) is used, an input yyddd
special indicator of C'99999' results in an output date field of C'9999/99/99'.
However, CH/ZD special indicators of BI zeros, blanks and BI ones
cannot be converted to PD special indicators.
Conversion involving
an input date with an invalid digit (A-F) will result in a data exception
(0C7 ABEND) or an incorrect output value.
Conversion involving
an invalid input date or invalid output date will result in an output
value of asterisks and an informational message (issued once). A
date is considered invalid if any of the following range conditions
are not met: - yy must be between 00 and 99
- ccyy must be between 0001 and 9999
- mm must be between 01 and 12
- dd must be between 01 and 31, and must be valid for the year and
month
- ddd must be 001 to 366 for a leap year, or between 001 and 365
for a non-leap year
A date is also considered invalid if the input field is
a CH/ZD special indicator of binary zeros, blanks or binary ones,
and the output field is PD.
- %nn,Y2x,todate or %nn,Y4x,todate
- Specifies that an input date field of one type is to be converted
to a corresponding output date field of another type. See PARSE for
details of parsed fields. See "p,m,Y2x,todate or p,m,Y4x,todate"
for further details.
- p,m,Y2x,dateop or p,m,Y4x,dateop
- Specifies an arithmetic operation for an input date field. The
available operations are as follows:
- ADDDAYS, ADDMONS or ADDYEARS can be used
to add days, months or years to a date field. As a simple example,
you could use the following to add 10 days to a C'ccyymmdd' date and
produce the resulting C'ccyy/mm/dd' date:
15,8,Y4T,ADDDAYS,+10,TOGREG=Y4T(/)
- SUBDAYS, SUBMONS or SUBYEARS can be used
to subtract days, months or years from a date field. As a simple
example, you could use the following to subtract 3 months from a P'dddyy'
date and produce the resulting P'ccyyddd' date:
21,3,Y2X,SUBMONS,+3,TOJUL=Y4U
- DATEDIFF can be used to calculate the number of days between
two date fields. As a simple example, you could use the following
to calculate the difference in days between two C'ccyymmdd' dates:
41,8,Y4T,DATEDIFF,31,8,Y4T
- NEXTDday can be used to calculate the next specified day
for a date field. As a simple example, you could use the following
to calculate the next Friday for a C'ccyyddd' date as a C'ccyy.ddd'
date:
3,7,Y4T,NEXTDFRI,TOJUL=Y4T(.)
- PREVDday can be used to calculate the previous specified
day for a date field. As a simple example, you could use the following
to calculate the previous Wednesday for a P'yyddd' date as a C'ccyymmdd'
date:
51,3,Y2U,PREVDWED,TOGREG=Y4T
- LASTDAYW, LASTDAYM, LASTDAYQ or LASTDAYY can
be used to calculate the last day of the week, month, quarter or year
for a date field. As a simple example, you could use the following
to calculate the last day of the month for a C'mmddccyy' date as a
C'mmddccyy' date:
28,8,Y4W,LASTDAYM,TOGREG=Y4W
- %nn,Y2x,dateop or %nn,Y4x,dateop
- Specifies an arithmetic operation for a parsed input date field.
- Adding or Subtracting Days, Months or Years
>>-+-p,m-+-+-,Y2x-+-+-ADDDAYS--+-+-p,m,f--+-+-TOJUL=Yaa-----+--><
'-%nn-' '-,Y4x-' +-ADDMONS--+ '-deccon-' +-TOJUL=Yaa(s)--+
+-ADDYEARS-+ +-TOGREG=Yaa----+
+-SUBDAYS--+ '-TOGREG=Yaa(s)-'
+-SUBMONS--+
'-SUBYEARS-'
- p,m,Yxx,keyword,numeric,todate
- Can be used to add n days, months or years to an input date field,
or subtract n days, months or years from an input date field. The
valid keywords are ADDDAYS, ADDMONS, ADDYEARS, SUBDAYS, SUBMONS and
SUBYEARS.
The numeric value specifies the number of days, months
or years to be added to or subtracted from the input date field.
The resulting output date field is converted to the form indicated
by todate.
p,m,Yxx specifies the starting position
(p), length (m) and format (Yxx) of a 2-digit or 4-digit year input
date field. The valid length and format for each type of date field
you can use is shown in Table 17.
Table 17. p,m,Yxx fields for date arithmeticp,m,Yxx fields for date arithmeticm,Yxx
|
Type of date |
|---|
5,Y2T
6,Y2T
7,Y4T
8,Y4T
5,Y2W
6,Y2W
7,Y4W
8,Y4W
3,Y2U
4,Y2V
4,Y4U
5,Y4V
3,Y2X
4,Y2Y
4,Y4X
5,Y4Y
|
C'yyddd' or Z'yyddd'
C'yymmdd' or Z'yymmdd'
C'ccyyddd' or Z'ccyyddd'
C'ccyymmdd' or Z'ccyymmdd'
C'dddyy' or Z'dddyy'
C'mmddyy' or Z'mmddyy'
C'dddccyy' or Z'dddccyy'
C'mmddccyy' or Z'mmddccyy'
P'yyddd'
P'yymmdd'
P'ccyyddd'
P'ccyymmdd'
P'dddyy'
P'mmddyy'
P'dddccyy'
P'mmddccyy'
|
ADDDAYS adds n days to the p,m,Yxx date field.
ADDMONS adds n months to the p,m,Yxx date field.
If necessary, the resulting date is adjusted backwards to the last
valid day of the month. For example, if 1 month is added to 20101031,
the resulting date will be 20101130 rather than 20101131.
ADDYEARS adds
n years to the p,m,Yxx date field. If the resulting date is February
29 of a non-leap year, it will be adjusted backwards to a valid date
of February 28.
SUBDAYS subtracts n days from the
p,m,Yxx date field.
SUBMONS subtracts n months
from the p,m,Yxx date field. If necessary, the resulting date is
adjusted backwards to the last valid day of the month. For example,
if 1 month is subtracted from 20101031, the resulting date will be
20100930 rather than 20100931.
SUBYEARS subtracts
n years from the p,m,Yxx date field. If the resulting date is February
29 of a non-leap year, it will be adjusted backwards to a valid date
of February 28.
numeric can be a decimal constant
(+n or -n), or a valid numeric field (p,m,f) with BI, FI, ZD, PD,
FS, UFF or SFF format and an appropriately corresponding length.
For
ADDDAYS or SUBDAYS, the numeric constant or field value can be from
-3652058 to +3652058.
For ADDMONS or SUBMONS, the numeric
constant or field value can be from -119987 to +119987.
For
ADDYEARS or SUBYEARS, the numeric constant or field value can be from
-9998 to +9998.
- TOJUL and TOGREG
- See TOJUL and TOGREG under "p,m,Y2x,todate or p,m,Y4x,todate"
for details.
- %nn,Yxx,keyword,numeric,todate
- Can be used to add n days, months or years to a parsed input
date field, or subtract n days, months or years from a parsed input
date field. See PARSE for details of parsed fields. See "p,m,Yxx,keyword,numeric,todate"
for further details.
%nn cannot be used for the numeric
field.
- Calculating Difference in Days
>>-+-p,m-+-+-,Y2x-+-DATEDIFF-p,m-+-,Y2x-+----------------------><
'-%nn-' '-,Y4x-' '-,Y4x-'
- p,m,Yxx,DATEDIFF,p,m,Yxx
- Can be used to calculate the number of days difference between
two input date fields. The result is an 8-byte value consisting
of a sign and 7 digits (sddddddd). If the first date is greater than
or equal to the second date, the sign is + (plus). If the first
date is less than the second date, the sign is - (minus).
p,m,Yxx specifies
the starting position (p), length (m) and format (Yxx) of a 2-digit
or 4-digit year input date field. The valid length and format for
each type of date field you can use is shown in Table 17.
DATEDIFF calculates
the number of days that result when the second date is subtracted
from the first date. The result is in the form sddddddd with + or
- for s as appropriate and leading zeros. The result can be between
-3652058 and +3652058 days.
- %nn,Yxx,DATEDIFF,p,m,Yxx
- Can be used to calculate the number of days difference between
a parsed input date field and another input date field. See PARSE
for details of parsed fields. See
"p,m,Yxx,DATEDIFF,p,m,Yxx" for further details.
%nn
cannot be used for the second date field.
- Next, Previous or Last Day
>>-+-p,m-+-+-,Y2x-+-+-NEXTDday-+-+-TOJUL=Yaa-----+-------------><
'-%nn-' '-,Y4x-' +-PREVDday-+ +-TOJUL=Yaa(s)--+
'-LASTDAYx-' +-TOGREG=Yaa----+
'-TOGREG=Yaa(s)-'
- p,m,Yxx,keyword,todate
- Can be used to specify the next specified day, previous specified
day, or last day of the week, month, quarter or year for an input
date. The valid keywords are NEXTDday, PREVDday or LASTDAYx (where
day can be SUN, MON, TUE, WED, THU, FRI or SAT and x can be W, M,
Q or Y).
The result is an output date field which is converted to
the form indicated by todate.
p,m,Yxx specifies
the starting position (p), length (m) and format (Yxx) of a 2-digit
or 4-digit year input date field. The valid length and format for
each type of date field you can use is shown in Table 17.
NEXTDSUN calculates
the next Sunday for a date field.
NEXTDMON calculates
the next Monday for a date field.
NEXTDTUE calculates
the next Tuesday for a date field.
NEXTDWED calculates
the next Wednesday for a date field.
NEXTDTHU calculates
the next Thursday for a date field.
NEXTDFRI calculates
the next Friday for a date field.
NEXTDSAT calculates
the next Saturday for a date field.
PREVDSUN calculates
the previous Sunday for a date field.
PREVDMON calculates
the previous Monday for a date field.
PREVDTUE calculates
the previous Tuesday for a date field.
PREVDWED calculates
the previous Wednesday for a date field
PREVDTHU calculates
the previous Thursday for a date field.
PREVDFRI calculates
the previous Friday for a date field.
PREVDSAT calculates
the previous Saturday for a date
LASTDAYW calculates
the last day of the week (Friday) for a date field.
LASTDAYM calculates
the last day of the month for a date field.
LASTDAYQ calculates
the last day of the quarter for a date field.
LASTDAYY calculates
the last day of the year for a date field.
- TOJUL and TOGREG
- See TOJUL and TOGREG under "p,m,Y2x,todate or p,m,Y4x,todate"
for details.
- %nn,Yxx,keyword,todate
- Can be used to specify the next specified day, previous specified
day, or last day of the week, month, quarter or year for a parsed
input date. See PARSE for details of parsed fields. See “p,m,Yxx,keyword,todate”
for further details.
- Arithmetic with Real Dates, Special Indicators and Invalid Dates
- For CH/ZD dates (Y2T, Y4T, Y2W, Y4W), the zone and sign are ignored;
only the digits are used. For example, X'F2F0F0F9F1F2F3D0' and X'A2B0C0D9E1F21320'
are treated as 20091230. For PD dates (Y2U, Y4U, Y2V, Y4V, Y2X, Y4X,
Y2Y, Y4Y), the sign is ignored; only the relevant digits are used.
For example, X'120091230D' is treated as 20091230.
For CH/ZD dates
(Y2T, Y4T, Y2W, Y4W), the special indicators are X'00...00' (BI zeros),
X'40...40' (blanks), C'0...0' (CH zeros), Z'0...0' (ZD zeros), C'9...9'
(CH nines), Z'9...9' (ZD nines) and X'FF...FF' (BI ones). For PD
dates (Y2U, Y4U, Y2V, Y4V, Y2X, Y4X, Y2Y, Y4Y), the special indicators
are P'0...0' (PD zeros) and P'9...9' (PD nines).
yy for real
2-digit year dates is transformed to ccyy when appropriate using the
century window established by the Y2PAST option in effect. ccyy for
real 4-digit year dates is transformed to yy when appropriate by removing
cc.
If a special indicator is used for DATEDIFF, the result
will be an output value of asterisks and an informational message
(issued once).
Date arithmetic is not performed for special
indicators; the special indicator is just used appropriately for the
output date field. For example, if p,5,Y2T,ADDDAYS,+10,TOGREG=Y4T(/)
is used, an input yyddd special indicator of C'99999' results in an
output date field of C'9999/99/99'. However, CH/ZD special indicators
of BI zeros, blanks and BI ones cannot be converted to PD special
indicators.
Arithmetic involving an input date with an invalid
digit (A-F) will result in a data exception (0C7 ABEND) or an incorrect
output value.
Arithmetic involving an invalid input date or
invalid output date will result in an output value of asterisks and
an informational message (issued once). A date is considered invalid
if any of the following range conditions are not met: - yy must be between 00 and 99
- ccyy must be between 0001 and 9999
- mm must be between 01 and 12
- dd must be between 01 and 31, and must be valid for the year and
month
- ddd must be between 001 and 366 for a leap year, or between 001
and 365 for a non-leap year.
A date is also considered invalid if the input field is
a CH/ZD special indicator of binary zeros, blanks or binary ones,
and the output field is PD.
- p,m,Y2x(s) or p,m,Y4x(s)
- Specifies that an input date field is to be edited with separators.
s can be any character except a blank. Real Y2x dates are edited
using the century window established by the Y2PAST option in effect.
Y2x and Y4x dates with special indicators are expanded appropriately
(for example, p,8,Y4T(s) transforms C'00000000' to C'0000/00/00').
Editing
involving an input date with an invalid digit (A-F) can result in
a data exception (0C7 ABEND) or an incorrect output value. Editing
involving an invalid input date can result in an invalid output value. - p
- See p under p,m,a.
- m
- Specifies the length in bytes of the Y2x (two-digit year) or Y4x
(four-digit year) date field.
- Y2x(s) or Y4x(s)
- Specifies the Y2 or Y4 format for the date field and the separator
character(s). See Data format descriptions for detailed format
descriptions.
Sample Syntax:* Convert a Z'dddccyy' date to a C'ddd/ccyy' date.
OUTFIL BUILD=(19,7,Y4W(/),X,
* Convert a P'ccyymmdd' date to a C'ccyy-mm-dd' date.
43,5,Y4V(-))
Table 18 shows
the output produced for each type of edited date.
Table 18. Input and result fields for Yxx(s) date editingInput and result fields for Yxx(s)
date editingm,Yxx(s)
|
Input date |
Output for p,m,Yxx(s) |
|---|
3,Y2T(s)
4,Y2T(s)
5,Y2T(s)
6,Y2T(s)
7,Y4T(s)
8,Y4T(s)
2,Y2U(s)
3,Y2V(s)
3,Y2U(s)
4,Y2V(s)
4,Y4U(s)
5,Y4V(s)
3,Y2W(s)
4,Y2W(s)
5,Y2W(s)
6,Y2W(s)
7,Y4W(s)
8,Y4W(s)
2,Y2X(s)
3,Y2Y(s)
3,Y2X(s)
4,Y2Y(s)
4,Y4X(s)
5,Y4Y(s)
|
C'yyx' or Z'yyx'
C'yyxx' or Z'yyxx'
C'yyddd' or Z'yyddd'
C'yymmdd' or Z'yymmdd'
C'ccyyddd' or Z'ccyyddd'
C'ccyymmdd' or Z'ccyymmdd'
P'yyx'
P'yyxx'
P'yyddd'
P'yymmdd'
P'ccyyddd'
P'ccyymmdd'
C'xyy' or Z'xyy'
C'xxyy' or Z'xxyy'
C'dddyy' or Z'dddyy'
C'mmddyy' or Z'mmddyy'
C'dddccyy' or Z'dddccyy'
C'mmddccyy' or Z'mmddccyy'
P'xyy'
P'xxyy'
P'dddyy'
P'mmddyy'
P'dddccyy'
P'mmddccyy'
|
C'ccyysx'
C'ccyysxx'
C'ccyysddd'
C'ccyysmmsdd'
C'ccyysddd'
C'ccyysmmsdd'
C'ccyysx'
C'ccyysxx'
C'ccyysddd'
C'ccyysmmsdd'
C'ccyysddd'
C'ccyysmmsdd'
C'xsccyy'
C'xxsccyy'
C'dddsccyy'
C'mmsddsccyy'
C'dddsccyy'
C'mmsddsccyy'
C'xsccyy'
C'xxsccyy'
C'dddsccyy'
C'mmsddsccyy'
C'dddsccyy'
C'mmsddsccyy'
|
- %nn,Y2x(s) or %nn,Y4x(s)
- Specifies that a parsed input date field is to be edited with
separators. See PARSE for details of parsed fields. See "p,m,Y2x(s)
or p,m,Y4x(s)" for further details.
- p,m,Y2xP
- Specifies that an input date field is to be converted to a packed
decimal output date field. Real Y2x dates are edited using the century
window established by the Y2PAST option in effect. Y2x and Y4x dates
with special indicators are expanded appropriately (for example, p,6,Y2TP
transforms C'000000' to P'00000000').
Editing involving an input
date with an invalid digit (A-F) can result in a data exception (0C7
ABEND) or an incorrect output value. Editing involving an invalid
input date can result in an invalid output value. - p
- See p under p,m,a.
- m
- Specifies the length in bytes of the Y2x (two-digit year) or Y4x
(four-digit year) date field.
- Y2xP
- Specifies the Y2 format for the date field. See Data format descriptions for detailed format descriptions.
Sample Syntax: OUTFIL BUILD=(11,3,Y2XP,X,21,4,Y2WP)
Table 19 shows the output produced for each
type of date.
Table 19. Input and result fields
for Yxx(s) date editingInput and result fields for Yxx(s)
date editingm,Y2xP
|
Input date |
Output for p,m,Y2xP |
|---|
3,Y2TP
4,Y2TP
5,Y2TP
6,Y2TP
2,Y2UP
3,Y2VP
3,Y2UP
4,Y2VP
3,Y2WP
4,Y2WP
5,Y2WP
6,Y2WP
2,Y2XP
3,Y2YP
3,Y2XP
4,Y2YP
2,Y2PP
1,Y2DP
|
C'yyx' or Z'yyx'
C'yyxx' or Z'yyxx'
C'yyddd' or Z'yyddd'
C'yymmdd' or Z'yymmdd'
P'yyx'
P'yyxx'
P'yyddd'
P'yymmdd'
C'xyy' or Z'xyy'
C'xxyy' or Z'xxyy'
C'dddyy' or Z'dddyy'
C'mmddyy' or Z'mmddyy'
P'xyy'
P'xxyy'
P'dddyy'
P'mmddyy'
P'yy'
X'yy'
|
P'ccyyx'
P'ccyyxx'
P'ccyyddd'
P'ccyymmdd'
P'ccyyx'
P'ccyyxx'
C'ccyyddd'
C'ccyymmdd'
C'xccyy'
C'xxccyy'
C'dddccyy'
C'mmddccyy'
C'xccyy'
C'xxccyy'
C'dddccyy'
C'mmddccyy'
C'ccyy'
C'ccyy'
|
- %nn,Y2xP
- Specifies that a parsed input date field is to be converted to
a packed decimal output date field. See PARSE for details of parsed
fields. See "p,m,Y2xP" for further details
- p,m,lookup or %nn,lookup
- specifies that a character constant, hexadecimal constant, input
field (p,m), or parsed input field (%nn) from a lookup table is to
appear in the reformatted OUTFIL output record. You can use p,m,lookup
or %nn,lookup to select a specified set constant (that is, a character
or hexadecimal string) or set field (that is, an input field or parsed
input field) based on matching an input value against find constants
(that is, character, hexadecimal, or bit constants).
- p
- See p under p,m,a.
- m
- specifies the length in bytes of the input field to be compared
to the find constants. The value for m must be 1 to 64 if character
or hexadecimal find constants are used, or 1 if bit find constants
are used.
- %nn
- specifies a parsed input field to be compared to the find constants.
See PARSE for details of parsed fields.
- lookup
- Specifies how the input field or parsed input field is to be changed
to the output field, using a lookup table.
- CHANGE
.-.---------.
V |
>>-CHANGE=(-v---,find,set-+-)-+----------------+---------------><
'-,NOMATCH=(set)-'
specifies a list of change pairs, each
consisting of a find constant to be compared to the input field value
or parsed input field value and a set constant or set field to use
as the output field when a match occurs.
- v
- specifies the length in bytes of the output field to be inserted
in the reformatted OUTFIL output record. The value for v must be
between 1 and 64.
- find
- specifies a find constant to be compared to the input field value or parsed input field value. If the input field value or parsed input field value matches the find constant,
the corresponding set constant or set field is used for the output
field.
The find constants can be either character string constants,
hexadecimal string constants, or bit constants:
- set
- specifies a set constant or set field to be used as the output
field if the corresponding find constant matches the input field value or parsed input field value. Set constants and set
fields can be intermixed.
Set constants can be either character
string constants (C'xx...x') or hexadecimal string constants (X'yy...yy')
of 1 to v bytes. See INCLUDE control statement for details
of coding character and hexadecimal string constants.
If the
string is less than v bytes, it will be padded on the right to a length
of v bytes, using blanks (X'40') for a character string constant
or zeros (X'00') for a hexadecimal string constant.
Set fields are specified as q,n or %nn. q specifies the
input position. See p under p,m,a for details of coding q. n specifies
the input length of 1 to v bytes. %nn specifies a parsed input field.
See PARSE for details of parsed fields. If the set field length is
less than v, the input field or parsed input field will be padded
on the right to a length of v bytes, using blanks (X'40').
- NOMATCH
- specifies the action to be taken if an input field value or parsed input field value does not match any of
the find constants. If you do not specify NOMATCH, and a match is
not found for any input value, DFSORT terminates processing.
If
you specify NOMATCH, it must follow CHANGE. - set
- specifies a set constant or set field to be used as the output
field if a match is not found.
Set constants can be either character
string constants (C'xx...x') or hexadecimal string constants (X'yy...yy')
of 1 to v bytes and can be intermixed. See INCLUDE control statement for
details of coding character and hexadecimal string constants.
If
the string is less than v bytes, it will be padded on the right to
a length of v bytes, using blanks (X'40') for a character string constant
or zeros (X'00') for a hexadecimal string constant.
Set
fields are specified as q,n or %nn. q specifies the input position.
See p under p,m,a for details of coding q. n specifies the input
length of 1 to v bytes. %nn specifies a parsed input field. See
PARSE for details of parsed fields. If the set field length is less
than v, the input field or parsed input field will be padded on the
right to a length of v bytes, using blanks (X'40').
Sample
Syntax: OUTFIL FILES=1,
OUTREC=(11,1,
CHANGE=(6,
C'R',C'READ',
C'U',C'UPDATE',
X'FF',C'EMPTY',
C'X',35,6,
C'A',C'ALTER'),
NOMATCH=(11,6),
4X,
21,1,
CHANGE=(10,
B'.1......',C'VSAM',
B'.0......',C'NON-VSAM'))
- p,m,justify
- specifies that a left-justified or right-justified input field
is to appear in the reformatted OUTFIL output record. For a left-justified
field, leading blanks are removed and the characters from the first
nonblank to the last nonblank are shifted left, with blanks inserted
on the right if needed. For a right-justified field, trailing blanks
are removed and the characters from the last nonblank to the first
nonblank are shifted right, with blanks inserted on the left if needed.
Optionally: - specific leading and trailing characters can be changed to blanks
before justification begins
- a leading string can be inserted
- a trailing string can be inserted
- the output length can be changed (it's equal to the input length
by default)
- p
- See p under p,m,a.
- m
- See m under p,m,a.
- justify
- specifies how the input field is to be justified for output.
- JFY
.-,-------------------.
V |
>>-JFY=--(----+-+-SHIFT=LEFT--+-+-+--)-------------------------><
| '-SHIFT=RIGHT-' |
+-LENGTH=n--------+
+-PREBLANK=list---+
+-LEAD=string-----+
'-TRAIL=string----'
Note: For clarity, in the examples in
this section, b is used to represent a blank in the input fields.
- SHIFT=LEFT
- specifies that a left-justified input field is to appear in the
reformatted OUTFIL output record. Leading blanks are removed and
the characters from the first nonblank to the last nonblank are shifted
left, with blanks inserted on the right if needed. For example, with:
1,15,JFY=(SHIFT=LEFT)
an
input field of: bbbbABbCDbbEFbb
results in
an output field of: ABbCDbbEFbbbbbb
m is
used for the output field length unless LENGTH=n is specified. If
the left-justified input field is shorter than the output field length,
blanks are inserted on the right. If the left-justified input field
is longer than the output field length, characters are truncated on
the right. You can use LENGTH=n to prevent padding or truncation.
- SHIFT=RIGHT
- specifies that a right-justified input field is to appear in the
reformatted OUTFIL output record. Trailing blanks are removed and
the characters from the last nonblank to the first nonblank are shifted
right, with blanks inserted on the left if needed. For example, with:
1,15,JFY=(SHIFT=RIGHT)
an
input field of: bbbbABbCDbbEFbb
results in an
output field of: bbbbbbABbCDbbEF
m is used
for the output field length unless LENGTH=n is specified. If the
right-justified input field is shorter than the output field length,
blanks are inserted on the left. If the right-justified input field
is longer than the output field length, characters are truncated on
the left. You can use LENGTH=n to prevent padding or truncation.
- LENGTH=n
- specifies the length of the justified output field. The value
for n must be between 1 and 32752. If LENGTH=n is not specified,
m (the input field length) is used for the length of the justified
output field. You can use LENGTH=n to prevent padding or truncation.
- PREBLANK=list
- specifies a list of one or more characters to be changed to blanks before justify
processing begins. Only leading and trailing characters are changed
to blanks. Scanning from left to right, each nonblank character at
the start of the input field that matches a character in the list
is replaced by a blank character, until a nonblank character not in
the list is found. Scanning from right to left, each nonblank character
at the end of the input field that matches a character in the list
will be replaced by a blank character, until a nonblank character
not in the list is found.
list can be 1 to 10 characters specified
using a character string constant (C'xx...x') or a hexadecimal string
constant (X'yy...yy'). See INCLUDE control statement for details
of coding character and hexadecimal string constants.
Each character
in the list is treated as one character to be preblanked. Thus PREBLANK=C'*'
specifies an asterisk is to be preblanked, and PREBLANK=C',;$' specifies
a comma, a semicolon and a dollar sign are each to be preblanked.
For
example, let's say we have an input field of: **b<*ABbCD*bEF>*b**
If
we specify: 1,19,JFY=(SHIFT=LEFT,PREBLANK=C'*')
each
leading or trailing asterisk is changed to a blank before left- justify
processing begins. So the output field is: <*ABbCD*bEF>bbbbbbb
If
we specify: 1,19,JFY=(SHIFT=RIGHT,PREBLANK=C'*<>')
each
leading or trailing asterisk, less than sign and greater than sign
is changed to a blank before right-justify processing begins. So
the output field is: bbbbbbbbbbABbCD*bEF
- LEAD=string
- specifies a string to be inserted in the output field before the
first nonblank character in the input field.
string can be 1 to
50 characters specified using a character string constant (C'xx...x')
or a hexadecimal string constant (X'yy...yy'). See INCLUDE control statement for details of coding character and hexadecimal
string constants.
For example, let's say we have an input field
of: bABCbEbbbbb
If we specify: 1,11,JFY=(SHIFT=RIGHT,LEAD=C'XYZ')
the
output field is: bbbXYZABCbE
When we add characters
with LEAD=string, it's often necessary to specify LENGTH=n to avoid
truncation. For example, let's say we have an input field of: AbBbC
If
we specify: 1,5,JFY=(SHIFT=LEFT,LEAD=C'XYZ')
the
output field is: XYZAb
Since the output field
length is defaulted to the input field length of 5, the resulting
8 characters (XYZAbBbC) are truncated on the right to 5 characters
(XYZAb) for output. If we instead specify: 1,5,JFY=(SHIFT=LEFT,LEAD=C'XYZ',LENGTH=8)
the
output field is: XYZAbBbC
LENGTH=8 increases
the output field by the 3 LEAD characters and truncation is prevented.
- TRAIL=string
- specifies a string to be inserted in the output field after the
last nonblank character in the input field.
string can be 1 to
50 characters specified using a character string constant (C'xx...x')
or a hexadecimal string constant (X'yy...yy'). See INCLUDE control statement for details of coding character and hexadecimal
string constants.
For example, let's say we have an input field
of: bABCbEbbbbb
If we specify: 1,11,JFY=(SHIFT=LEFT,TRAIL=C'XYZ')
the
output field is: ABCbEXYZbbb
When we add characters
with TRAIL=string, it's often necessary to specify LENGTH=n to avoid
truncation. For example, let's say we have an input field of: AbBbC
If
we specify: 1,5,JFY=(SHIFT=RIGHT,TRAIL=C'XYZ')
the
output field is: bCXYZ
Since the output field
length is defaulted to the input field length of 5, the resulting
8 characters (AbBbCXYZ) are truncated on the left to 5 characters
(bCXYZ) for output. If we instead specify: 1,5,JFY=(SHIFT=RIGHT,TRAIL=C'XYZ',LENGTH=8)
the
output field is: AbBbCXYZ
LENGTH=8 increases
the output field by the 3 TRAIL characters and truncation is prevented. Sample
Syntax: OUTFIL BUILD=(5:16,20,JFY=(SHIFT=LEFT,PREBLANK=C'*',
LEAD=C'<A>',TRAIL=C'</A>',LENGTH=22))
- %nn,justify
- specifies that a left-justified or right-justified parsed input
field is to appear in the reformatted OUTFIL output record. See PARSE
for details of parsed fields. See p,m,justify for further details.
- p,m,squeeze
- specifies that a left-squeezed or right-squeezed input field is
to appear in the reformatted OUTFIL output record. For a left-squeezed
field, all blanks are removed and the characters from the first nonblank
to the last nonblank are shifted left, with blanks inserted on the
right if needed. For a right-squeezed field, all blanks are removed
and the characters from the last nonblank to the first nonblank are
shifted right, with blanks inserted on the left if needed. Optionally:
- specific characters can be changed to blanks before squeezing
begins
- a leading string can be inserted
- a trailing string can be inserted
- a string (for example, a comma delimiter) can be inserted wherever
a group of blanks is removed between the first nonblank and the last
nonblank
- blanks can be kept as is between paired apostrophes ('AB CD EF')
or paired quotes ("AB CD EF")
- the output length can be changed (it is equal to the input length
by default)
- p
- See p under p,m,a.
- m
- See m under p,m,a.
- squeeze
- Specifies how the input field is to be squeezed for output.
- SQZ
.-,-------------------.
V |
>>-SQZ=--(----+-+-SHIFT=LEFT--+-+-+--)-------------------------><
| '-SHIFT=RIGHT-' |
+-LENGTH=n--------+
+-PREBLANK=list---+
+-LEAD=string-----+
+-MID=string------+
+-TRAIL=string----+
'-+-PAIR=APOST-+--'
'-PAIR=QUOTE-'
Note: For clarity, in the examples in
this section, b is used to represent a blank in the input fields.
- SHIFT=LEFT
- specifies that a left-squeezed input field is to appear in the
reformatted OUTFIL output record. All blanks are removed and the
characters from the first nonblank to the last nonblank are shifted
left, with blanks inserted on the right if needed. For example, with:
1,15,SQZ=(SHIFT=LEFT)
an
input field of: bbbbABbCDbbEFbb
results in an
output field of: ABCDEFbbbbbbbbb
m is used
for the output field length unless LENGTH=n is specified. If the left-squeezed
input field is shorter than the output field length, blanks are inserted
on the right. If the left-squeezed input field is longer than the
output field length, characters are truncated on the right.
- SHIFT=RIGHT
- specifies that a right-squeezed input field is to appear in the
reformatted OUTFIL output record. All blanks are removed and the
characters from the last nonblank to the first nonblank are shifted
right, with blanks inserted on the left if needed. For example, with:
1,15,SQZ=(SHIFT=RIGHT)
an
input field of: bbbbABbCDbbEFbb
results in an
output field of: bbbbbbbbbABCDEF
m is used
for the output field length unless LENGTH=n is specified. If the
right-squeezed input field is shorter than the output field length,
blanks are inserted on the left. If the right-squeezed input field
is longer than the output field length, characters are truncated on
the left.
- LENGTH=n
- specifies the length of the squeezed output field. The value for
n must be between 1 and 32752. If LENGTH=n is not specified, m (the
input field length) is used for the length of the squeezed output
field.
- PREBLANK=list
- specifies a list of one or more characters to be changed to blanks before squeeze
processing begins. Each nonblank character in the input field that
matches a character in the list is replaced by a blank character.
list can be 1 to 10 characters specified using a character string
constant (C'xx...x') or a hexadecimal string constant (X'yy...yy').
See INCLUDE control statement for details of coding character
and hexadecimal string constants.
Each character in the list
is treated as one character to be preblanked. Thus PREBLANK=C'*' specifies
an asterisk is to be preblanked, and PREBLANK=C',;$' specifies a comma,
a semicolon and a dollar sign are each to be preblanked.
For
example, let's say we have an input field of: **b<*ABbC<>D*bEF>*b**
If
we specify: 1,21,SQZ=(SHIFT=LEFT,PREBLANK=C'*',LENGTH=12)
each
asterisk is changed to a blank before left-squeeze processing begins.
The output field is: <ABC<>DEF>bb
If
we specify: 1,21,SQZ=(SHIFT=RIGHT,PREBLANK=C'*<>')
each
asterisk, less than sign and greater than sign is changed to a blank
before right-squeeze processing begins. The output field is: bbbbbbbbbbbbbbbABCDEF
- LEAD=string
- specifies a string to be inserted in the output field before the
first nonblank character in the input field.
string can be 1 to
50 characters specified using a character string constant (C'xx...x')
or a hexadecimal string constant (X'yy...yy'). See INCLUDE control statement for details of coding character and hexadecimal
string constants.
For example, let's say we have an input field
of: bABCbEbbbbb
If we specify: 1,11,SQZ=(SHIFT=RIGHT,LEAD=C'XYZ')
the
output field is: bbbbXYZABCE
When we add characters
with LEAD=string, it's often necessary to specify LENGTH=n to avoid
truncation. For additional information on this, see "LEAD=string"
for JFY shown previously in this section.
- MID=string
- specifies a string to be inserted in the output field wherever
one or more blanks is removed between the first nonblank and the last
nonblank.
string can be 1 to 10 characters specified using a character
string constant (C'xx...x') or a hexadecimal string constant (X'yy...yy').
See INCLUDE control statement for details of coding character
and hexadecimal string constants.
For example, let's say we
have an input field of: bABbbCbbbDbE
If we specify: 1,12,SQZ=(SHIFT=LEFT,MID=C',')
the
output field is: AB,C,D,Ebbbb
When we add characters
with MID=string, it's often necessary to specify LENGTH=n to avoid
truncation. For example, let's say we have an input field of: AbBbC
If
we specify: 1,5,SQZ=(SHIFT=LEFT,MID=C'XY')
the
output field is: AXYBX
Since the output field
length is defaulted to the input field length of 5, the resulting
7 characters (AXYBXYC) are truncated on the right to 5 characters
(AXYBX) for output. If we instead specify: 1,5,SQZ=(SHIFT=LEFT,MID=C'XY',LENGTH=7)
the
output field is: AXYBXYC
LENGTH=7 increases
the output field to accommodate the MID strings and truncation is
prevented.
- TRAIL=string
- specifies a string to be inserted in the output field after the
last nonblank character in the input field.
string can be 1 to
50 characters specified using a character string constant (C'xx...x')
or a hexadecimal string constant (X'yy...yy'). See INCLUDE control statement for details of coding character and hexadecimal
string constants.
For example, let's say we have an input field
of: bABCbEbbbbb
If we specify: 1,11,SQZ=(SHIFT=LEFT,LEAD=X'7D',TRAIL=X'7D')
the
output field is: 'ABCE'bbbbb
When we add characters
with TRAIL=string, it's often necessary to specify LENGTH=n to avoid
truncation. For additional information on this, see "TRAIL=string"
for JFY as shown previously in this section.
- PAIR=APOST
- specifies that blanks and PREBLANK characters between apostrophe
(') pairs are to be kept as is. Use PAIR=APOST when you have literals
that should not be squeezed.
For example, let's say we have an
input field of: b*b'ABbb*''*C'bbb'D*Ebb'*
If
we specify: 1,25,SQZ=(SHIFT=LEFT,PREBLANK=C'*',MID=C',')
all
of the blanks and asterisks, including those inside the apostrophe
pairs, are squeezed out. The output field is: 'AB,'',C','D,E,'bbbbbbbbb
However,
if we specify: 1,25,SQZ=(SHIFT=LEFT,PREBLANK=C'*',MID=C',',
PAIR=APOST)
only the blanks and asterisks outside
of the apostrophe pairs are squeezed out. The output field is: 'ABbb*''*C','D*Ebb'bbbbbb
If
an apostrophe is specified in the PREBLANK list (for example, PREBLANK=C''''
or PREBLANK=X'7D'), it is ignored, that is, an apostrophe in the input
field is not replaced by a blank. So if you want each apostrophe
to be replaced by a blank, do not specify PAIR=APOST. For SHIFT=LEFT,
scanning is left to right. If an apostrophe is found with no subsequent
apostrophe, all of the characters from the apostrophe to the end of
the input field are ignored. For example, let's say we have an input
field of: bbXbY'ABCbbbDbb
If we specify: 1,15,SQZ=(SHIFT=LEFT,PAIR=APOST)
there's
an unpaired apostrophe, so all of the characters from the apostrophe
to the end of the input field are ignored. The output field is: XY'ABCbbbDbbbbb
For
SHIFT=RIGHT, scanning is right to left. If an apostrophe is found
with no previous apostrophe, all of the characters from the apostrophe
to the beginning of the input field are ignored. For example, let's
say we have an input field of: bbXbY'ABCbbbDbb
If
we specify: 1,15,SQZ=(SHIFT=RIGHT,PAIR=APOST)
there's
an unpaired apostrophe, so all of the characters from the apostrophe
to the beginning of the input field are ignored. The output field
is: bbbbbbbXbY'ABCD
- PAIR=QUOTE
- specifies that blanks and PREBLANK characters between quote (")
pairs are to be kept as is. Use PAIR=QUOTE when you have literals
that should not be squeezed.
For example, let's say we have an
input field of: b*b"ABbb*""*C"bbb"D*Ebb"*
If
we specify: 1,25,SQZ=(SHIFT=LEFT,PREBLANK=C'*',MID=C',')
all
of the blanks and asterisks, including those inside the quote pairs,
are squeezed out. The output field is: "AB,"",C","D,E,"bbbbbbbbb
However,
if we specify: 1,25,SQZ=(SHIFT=LEFT,PREBLANK=C'*',MID=C',',
PAIR=QUOTE)
only the blanks and asterisks outside
of the quote pairs are squeezed out. The output field is: "ABbb*""*C","D*Ebb'bbbbbb
If
a quote is specified in the PREBLANK list (for example, PREBLANK=C'"'
or PREBLANK=X'7F'), it is ignored, that is, a quote in the input field
is not replaced by a blank. So if you want each quote to be replaced
by a blank, do not specify PAIR=QUOTE. For SHIFT=LEFT, scanning
is left to right. If a quote is found with no subsequent quote, all
of the characters from the quote to the end of the input field are
ignored. For example, let's say we have an input field of: bbXbY"ABCbbbDbb
If
we specify: 1,15,SQZ=(SHIFT=LEFT,PAIR=QUOTE)
there's
an unpaired quote, so all of the characters from the quote to the
end of the input field are ignored. The output field is: XY"ABCbbbDbbbbb
For
SHIFT=RIGHT, scanning is right to left. If a quote is found with
no previous quote, all of the characters from the quote to the beginning
of the input field are ignored. For example, let's say we have an
input field of: bbXbY"ABCbbbDbb
If we specify: 1,15,SQZ=(SHIFT=RIGHT,PAIR=QUOTE)
there's
an unpaired quote, so all of the characters from the quote to the
beginning of the input field are ignored. The output field is: bbbbbbbXbY"ABCD
Sample
Syntax: OUTFIL BUILD=(5:16,20,SQZ=(SHIFT=LEFT,PAIR=QUOTE,PREBLANK=C'<>'))
- %nn,squeeze
- specifies that a left-squeezed or right-squeezed parsed input
field is to appear in the reformatted OUTFIL output record. See PARSE
for details of parsed fields. See p,m,squeeze for further details.
- seqnum
>>-SEQNUM,n,fs-+----------+-+---------+-+----------------+-----><
'-,START=j-' '-,INCR=i-' +-,RESTART=(p,m)-+
'-,RESTART=(%nn)-'
specifies that a sequence number is to appear in
the reformatted OUTFIL output record. The sequence numbers are assigned
in the order in which the records are received for OUTFIL OUTREC processing.
You can create BI, PD, ZD, CSF, or FS sequence numbers and control
their lengths, starting values and increment values. You can restart
the sequence number at the start value each time a specified OUTFIL
input field (p,m) or parsed input field (%nn) changes.
- n
- specifies the length of the sequence number. The value for n must
be between 1 and 16.
- fs
- specifies the format for the sequence number, which can be BI,
PD, ZD, CSF, or FS.
For a ZD format sequence number, F is used as
the sign.
For a PD format sequence number, C is used as the
sign.
For a CSF or FS format sequence number, blank is used
as the sign and leading zeros are suppressed.
For a PD, ZD,
CSF, or FS format sequence number, the maximum value DFSORT can create
is limited to the lesser of 15 decimal digits or the output field
length (n). If a sequence number overflows this limit, it will be
truncated to the lesser of 15 decimal digits or the output field length,
and then subsequently incremented as usual.
For a BI format
sequence number, the maximum value DFSORT can create is limited to
the lesser of 8 bytes of ones (X'FFFFFFFFFFFFFFFF') or the number
of ones that will fit in the specified output field length (n). If
a sequence number overflows this limit, it will be truncated to the
lesser of 8 bytes or the output field length, and then subsequently
incremented as usual.
- START
- specifies the starting value for the sequence number.
- j
- specifies the starting value. The value for j must be between
0 and 100000000000. The default for j is 1.
- INCR
- specifies the increment value for the sequence number.
- i
- specifies the increment value. The value for i must be between
1 and 10000000. The default for i is 1.
- RESTART
- specifies that DFSORT is to restart the sequence number at the
starting value (START=j) when the binary value for the specified OUTFIL
input field or parsed input field changes. This
allows you to sequence each set of records with the same value (that
is, duplicate records) separately. For example: Without RESTART,
if you had six OUTFIL input records with 'A', 'A', 'A', 'B', 'B' and
'C', respectively, in position 1, the output records would be given
the sequence numbers 1, 2, 3, 4, 5 and 6. But with RESTART=(1,1),
the output records are given the sequence numbers 1, 2, 3, 1, 2 and
1; DFSORT restarts at the starting value (1, by default) when the
input value at position 1 changes from 'A' to 'B' and again when it
changes from 'B' to 'C'.
- p,m or %nn
- specifies the OUTFIL input field or parsed input
field to be used to determine when the sequence number is to
be restarted at the starting value. If a variable-length OUTFIL input
record is too short to contain a specified restart field, binary zeros (or blanks for a parsed field) will be used for the
missing bytes, intentionally or unintentionally.
- p
- See p under p,m,a
- m
- specifies the length in bytes of the input field. The value for
m must be between 1 and 256.
- %nn
- specifies the parsed input field. See PARSE for details of parsed
fields.
Sample Syntax: OUTFIL FNAMES=O1,OUTREC=(SEQNUM,6,ZD,START=1000,INCR=50,
X,22,8,X,13,5)
OUTFIL FNAMES=O2,OUTREC=(1,12,SEQNUM,4,BI)
OUTFIL FNAMES=O3,OUTREC=(1,80,81:SEQNUM,8,ZD,START=21,INCR=20,
RESTART=(35,8))
Default for BUILD
or OUTREC: None; must be specified.
- OVERLAY
>>-OVERLAY=--(-------------------------------------------------->
.-,--------------------------------------------.
V |
>----+----+--+-s--------------------------------+-+--)---------><
'-c:-' +-p,m--+----+----------------------+
| '-,a-' |
+-%nn------------------------------+
+-+-p,m-+-,TRAN-+-LTOU---+---------+
| '-%nn-' +-UTOL---+ |
| +-ALTSEQ-+ |
| +-ATOE---+ |
| +-ETOA---+ |
| +-HEX----+ |
| +-UNHEX--+ |
| +-BIT----+ |
| '-UNBIT--' |
+-+-p,m-+-,HEX---------------------+
| '-%nn-' |
+-+-p,m,f---+-+-,edit-+------------+
| +-%nn,f---+ '-,to---' |
| +-(p,m,f)-+ |
| '-(%nn,f)-' |
+-+-deccon---+--+-,edit-+----------+
| '-(deccon)-' '-,to---' |
+-+-arexp---+--+-,edit-+-----------+
| '-(arexp)-' '-,to---' |
+-+-p,m-+-+-+-,Y2x-+-+---------+-+-+
| '-%nn-' | '-,Y4x-' +-,edit---+ | |
| | +-,to-----+ | |
| | +-,todate-+ | |
| | '-,dateop-' | |
| +-,Y2x(s)--------------+ |
| +-,Y4x(s)--------------+ |
| '-,Y2xP----------------' |
+-+-p,m-+-,lookup------------------+
| '-%nn-' |
+-+-p,m-+-,justify-----------------+
| '-%nn-' |
+-+-p,m-+-,squeeze-----------------+
| '-%nn-' |
'-seqnum---------------------------'
Specifies each item that is to overlay specific
columns in the reformatted record. Columns that are not overlaid
remain unchanged. If you want to insert, rearrange, or delete fields,
use BUILD or OUTREC rather than OVERLAY. Use OVERLAY only to overlay
existing columns or to add fields at the end of every record. OVERLAY
can be easier to use than BUILD or OUTREC when you just want to change
a few fields without rebuilding the entire record.
For fixed-length
records, the first input and output data byte starts at position 1.
For variable-length records, the first input and output data byte
starts at position 5, after the RDW in positions 1-4.
Use c:
(column) to specify the output positions to be overlaid. If you
do not specify c: for the first item, it defaults to 1:. If you
do not specify c: for any other item, it starts after the previous
item. For example, if you specify: OUTFIL OVERLAY=(25,2,11:C'A',15,3,C'**')
Input
positions 25-26 are placed at output positions 1-2; C'A' is placed
at output position 11; input positions 15-17 are placed at output
positions 12-14; and C'**' is placed at output positions 15-16. The
rest of the record remains unchanged.
You can specify items
in any order, you can change the same item multiple times and you
can overlap output columns. Changes to earlier items affect changes
to later items. For example, say you specify: OUTFIL OVERLAY=(21:8,4,ZD,MUL,+10,TO=ZD,LENGTH=6,
5:5,1,TRAN=UTOL,
5:5,1,CHANGE=(1,C'a',C'X',C'b',C'Y'),NOMATCH=(5,1))
and
input position 5 has 'A'. The second item (UTOL) would change 'A'
to 'a' and the third item (CHANGE) would change 'a' again to 'X'.
If
you specify an OVERLAY item that extends the overlay record beyond
the end of the input record, the reformatted record length is automatically
increased to that length, and blanks are filled in on the left as
needed. For variable-length records, the RDW length is increased
to correspond to the larger reformatted record length after all of
the OVERLAY items are processed. For example, if your OUTFIL input
record has a length of 40 and you specify: OUTFIL OVERLAY=(16:C'ABC',51:5C'*',35:15,2)
the
OUTFIL output record is given a length of 55. Blanks are filled in
from columns 41-50. For variable-length records, the length in the
RDW is changed from 40 to 55 after all of the OVERLAY items are processed.
Missing
bytes in specified input fields are replaced with blanks so the padded
fields can be processed.
You can use the OVERLAY parameter with
the FTOV parameter to convert fixed-length record data sets to variable-length
record data sets.
You can use the VLTRIM parameter with the
OVERLAY parameter to remove specified trailing bytes from the end
of variable-length records.
You can use the VLTRAIL
parameter with the OVERLAY parameter to insert a string at the end
of variable-length records.
You can use the OVERLAY parameter
with any or all of the report parameters in the same way as for the
BUILD or OUTREC parameter.
The OVERLAY parameter of the OUTREC
statement applies to all input records whereas the OVERLAY parameter
of the OUTFIL statement only applies to the OUTFIL input records for
its OUTFIL group.
See OUTFIL OUTREC for details of the items
listed in the OVERLAY syntax diagram shown previously
in this section. You can specify all of the items for OVERLAY
in the same way that you can specify them for BUILD or OUTREC with
the following exceptions: - You cannot specify p or p,HEX or p,TRAN=keyword for
OVERLAY.
- You cannot specify / for OVERLAY.
- For p,m,H or p,m,F or or p,m,D fields specified for OVERLAY, fields
are aligned as necessary without changing the preceding bytes.
- For variable-length records, you must not overlay positions 1-4
(the RDW) for OVERLAY, so be sure to specify the first column (c:)
as 5 or greater. Do not specify 1:, 2:, 3: or 4: anywhere in your
OVERLAY parameter. If you do not specify the first column, it will
default to 1: which is invalid for variable-length records with OVERLAY.
Whereas OUTREC=(1,m,...) is required, OVERLAY=(1,m) is not allowed
since it would overlay the RDW.
Sample Syntax:
Fixed input records: OUTFIL FNAMES=FLR,
OVERLAY=(21:21,4,ZD,TO=PD,LENGTH=4,
2:5,8,HEX,45:C'*',32,4,C'*',81:SEQNUM,5,ZD)
Variable
input records: OUTFIL FNAMES=VLR,
OVERLAY=(5:X'0001',28:C'Date is ',YDDDNS=(4D),
17:5C'*')
Default for OVERLAY:
None; must be specified.
- FINDREP
>>-FINDREP--+-IN=incon,OUT=outcon------------+------------------>
| .-,-----. |
| V | |
+-IN=(---incon-+--)--,OUT=outcon-+
| .-,------------. |
| V | |
'-INOUT=(---incon,outcon-+-)-----'
>--+---------------------------+-------------------------------><
| .-,---------------------. |
| V | |
'---+-STARTPOS=p--------+-+-'
+-ENDPOS=q----------+
+-DO=n--------------+
+-MAXLEN=n----------+
+-+-OVERRUN=ERROR-+-+
| '-OVERRUN=TRUNC-' |
'-+-SHIFT=YES-+-----'
'-SHIFT=NO--'
You
can use FINDREP to find constants anywhere in a record and replace
them with other constants of the same or different lengths. You can
find character or hexadecimal input constants anywhere in your records
and replace them with character, hexadecimal or null output constants.
As appropriate, bytes can be shifted left or right, blank padding
can be added for fixed-length records, and the length can be changed
for variable-length records.
Various options of FINDREP allow
you to define one or more input constants and a corresponding output
constant, define one or more pairs of input and output constants,
start and end the find scan at specified positions, stop after a specified
number of constants are replaced, increase or decrease the length
of the output record, define the action to be taken if nonblank characters
overrun the end of the record, and specify whether output constants
are to replace or overlay input constants.
You can use the FINDREP
parameter with the FTOV parameter to convert fixed-length record data
sets to variable-length record data sets.
You can use the VLTRIM
parameter with the FINDREP parameter to remove specified trailing
bytes from the end of variable-length records.
You
can use the VLTRAIL parameter with the FINDREP parameter to insert
a string at the end of variable-length records.
You can use
the FINDREP parameter with any or all of the report parameters in
the same way as for the BUILD or OUTREC parameter.
The FINDREP
parameter of the OUTREC statement applies to all input records whereas
the FINDREP parameter of the OUTFIL statement only applies to the
OUTFIL input records for its OUTFIL group.
Input and output
constants for find and replace processing are defined as follows:
- input constant
- An input constant can be specified as a single character string,
a repeated character string, a single hexadecimal string, or a repeated
hexadecimal string. The syntax is: C'string', nC'string', X'string'
or nX'string'. n can be 1 to 256. The string can be 1 to 256 characters,
or 1 to 256 pairs of hexadecimal digits. The total length of the
constant must not exceed 256 bytes. Use two apostrophes for a single
apostrophe.
- output constant
- An output constant can be specified as a null string, a single
character string, a repeated character string, a single hexadecimal
string, or a repeated hexadecimal string. The syntax is: C'' (null),
C'string', nC'string', X'string' or nX'string'. n can be 1 to 256.
The string can be a null, or 1 to 256 characters, or 1 to 256 pairs
of hexadecimal digits. The total length of the constant must not
exceed 256 bytes. Use two apostrophes for a single apostrophe. A
null string can be used to remove input constants.
You must specify the input and output constants
to be used for find and replace processing in one of the following
ways. The default processing for each method described later
in this section can be changed with various options described
later.
- IN=incon,OUT=outcon
- Specifies one input constant and one output constant. Position
1 (for fixed-length records) or 5 (for variable-length records) will
be set as the current position. The current position of the input
record will be checked for the input constant. If a match is not
found at the current position, the current position will be incremented
by 1, and the process will be repeated. If a match is found at the
current position, the output constant will replace the input constant,
the current position will be incremented past the input constant,
and the process will be repeated. Bytes after the replaced constants
up to the end of the record will be shifted left or right as needed.
Processing will stop when the current position is beyond the end
of the input record.
Example:
OUTFIL IFTHEN=(WHEN=(11,1,CH,EQ,C'3'),
FINDREP=(IN=C'YES',OUT=C'NO'))
Replaces every
C'YES' input constant in records with a C'3' in position 11 with a
C'NO' output constant, and shifts the bytes after each replaced constant
to the left.
- IN=(incon1,incon2,...,inconx),OUT=outcon
- Specifies multiple input constants and one output constant. Position
1 (for fixed-length records) or 5 (for variable-length records) will
be set as the current position. The current position of the input
record will be checked for each input constant in turn until a match
is found or all of the input constants have been checked. If a match
is not found at the current position for any input constant, the current
position will be incremented by 1, and the process will be repeated.
If a match is found at the current position, the output constant
will replace the input constant, the current position will be incremented
past the input constant, and the process will be repeated. Bytes
after the replaced constants up to the end of the record will be shifted
left or right as needed. Processing will stop when the current position
is beyond the end of the input record.
Example:
OUTFIL FINDREP=(IN=(X'FF',3X'00'),OUT=C'')
Removes
every X'FF' and X'000000' input constant, and shifts the bytes after
each removed constant to the left.
- INOUT=(incon1,outcon1,incon2,outcon2,...,inconx,outconx)
- Specifies one or more pairs of input and output constants. Position
1 (for fixed-length records) or 5 (for variable-length records) will
be set as the current position. The current position of the input
record will be checked for each input constant in turn until a match
is found or all of the input constants have been checked. If a match
is not found at the current position for any input constant, the current
position will be incremented by 1, and the process will be repeated.
If a match is found at the current position for an input constant,
the corresponding output constant will replace the input constant,
the current position will be incremented past the input constant,
and the process will be repeated. Bytes after the replaced constants
up to the end of the record will be shifted left or right as needed.
Processing will stop when the current position is beyond the end
of the input record.
Example:
OUTFIL FINDREP=(INOUT=(C'SAT',C'SATURDAY',C'SUN',C'SUNDAY'))
Replaces
every C'SAT' input constant with a C'SATURDAY' output constant, and
every C'SUN' input constant with a C'SUNDAY' output constant, and
shifts the bytes after each replaced constant to the right.
You can specify any or all of the following options
to change the default processing described earlier:
- STARTPOS=p
- Specifies the starting position in the input record for the find
scan, overriding the default of position 1 for a fixed-length record
or position 5 for a variable-length record. Use STARTPOS=p if you
want to start your find scan at a particular position. p can be 1
to 32752. If p is less than 5 for a variable-length record, 5 will
be used for p. If p is beyond the end of the input record, find and
replace processing will not be performed for the record.
Example:
OUTFIL FINDREP=(IN=C'Yes',OUT=C'YES',STARTPOS=11)
Replaces
every C'Yes' input constant found starting at or after position 11
with a C'YES' output constant.
- ENDPOS=q
- Specifies the ending position in the input record for the find
scan, overriding the default of the end of the record. Use ENDPOS=q
if you want to end your find scan at a particular position. ENDPOS=q
only applies to the end of the find scan; bytes will still be shifted
up to the end of the record as needed. q can be 1 to 32752. If q
is less than 5 for a variable-length record, 5 will be used for q.
If q is beyond the end of the input record, the end of the record
will be used for q. If STARTPOS=p and ENDPOS=q are both specified,
and p is greater than q, find and replace processing will not be performed
for the record.
Example:
OUTFIL FINDREP=(IN=(C'D27',C'A52',C'X31'),OUT=C'INVALID',
ENDPOS=2015)
Replaces every C'D27', C'A52' and
C'X31' input constant found before or at position 2015 with a C'INVALID'
output constant, and shifts the bytes after each replaced constant
to the right (past 2015 up to the end of the record).
- DO=n
- Specifies the maximum number of times find and replace is to be
performed for a record, overriding the default of every time. Scanning
for the input constant stops when n input constants have been found
and replaced. Use DO=n if you want to stop after a particular number
of constants have been replaced. n can be 1 to 1000.
Example:
OUTFIL FNAMES=OUT1,FINDREP=(IN=X'015C',OUT=X'015D',DO=3)
Replaces
the first three X'015C' input constants found with X'015D' output
constants.
- MAXLEN=n
- Specifies the maximum length to be used for the output record
created by find and replace processing, overriding the default of
using the maximum length of the input record. Use MAXLEN=n if you
want to increase or decrease the output record length. (For IFTHEN
FINDREP, MAXLEN=n can only be used to increase the output record length,
not decrease it. See "Notes" later in this section for
more information.)
If an output constant is larger than a corresponding
input constant, MAXLEN=n can be used to increase the size of the output
record to allow for shifting characters to the right. n can be 1 to
32752. MAXLEN=n will be used to set the LRECL of the output data
set, when appropriate.
Example:
OUTFIL FINDREP=(INOUT=(C'01',C'January',C'02',C'February',
C'03',C'March'),MAXLEN=150)
Replaces every C'01'
input constant with a C'January' output constant, every C'02' input
constant with a C'February' output constant, and every C'03' input
constant with a C'March' output constant, and shifts the bytes after
each replaced constant to the right, allowing the record to expand
to 150 bytes.
- OVERRUN=ERROR or OVERRUN=TRUNC
- Specifies the action DFSORT is to take if an overrun occurs, that
is:
- if nonblank bytes are shifted to the right past the end of the
output record as specified by MAXLEN=n, or as defaulted to the input
record length, or
- if MAXLEN=n is used to make the output record smaller than the
input record, and nonblank bytes are found in the input record past
the end of the output record.
OVERRUN=ERROR is the default; it tells DFSORT to issue an
error message and terminate if an overrun occurs.
Use OVERRUN=TRUNC
if you want DFSORT to truncate the output record to the MAXLEN=n or
input record length if an overrun occurs, rather than terminating.
Bytes beyond the end of the output record are lost.
Example:
OUTFIL FINDREP=(IN=X'FFFF',OUT=C'INVALID',MAXLEN=50,OVERRUN=TRUNC)
Replaces
every X'FFFF' input constant with a C'INVALID' output constant, and
shifts the bytes after the replaced constants to the right. 50 byte
output records are created. Bytes shifted past position 50 are lost.
Without OVERRUN=TRUNC, if nonblank characters were shifted past position
50, an overrun error message would be issued and the job would terminate.
- SHIFT=YES or SHIFT=NO
- Specifies the action DFSORT is to take if an input constant is
to be replaced by an output constant of a different length.
SHIFT=YES
is the default; it tells DFSORT to shift the bytes after each replaced
input constant to the left or right as needed.
Use SHIFT=NO
if you want DFSORT to overlay the input constant with the output constant
instead of shifting bytes. If a matching input constant is found
and the output constant is smaller than the input constant, the current
position will be incremented past the output constant rather than
past the input constant before processing continues.
Example:
OUTFIL FINDREP=(IN=(C'KW1=YES,',C'KW1=NO,'),OUT=C'KW2',SHIFT=NO)
Replaces
every C'KW1=YES,' input constant with a C'KW2=YES,' output constant.
Replaces every C'KW1=NO,' input constant with a C'KW2=NO,' output
constant. SHIFT=NO ensures that C'KW1' is replaced with C'KW2' and
the '=YES,' and '=NO,' bytes are kept. Without SHIFT=NO, the '=YES,'
and '=NO,' bytes would be removed.
Default for FINDREP: None; must be specified.
FINDREP
notes:
- For a single FINDREP operand, when a constant is replaced at the
current position, no further checks are performed at that position.
So a single FINDREP cannot be used to change a constant and then
change it again. For example, if you had an input record with:
ABC
and
used this OUTFIL statement: OUTFIL FINDREP=(INOUT=(C'AB',C'XY',C'XYC',C'RST'))
the
output record would be: XYC
After C'AB'
is changed to C'XY', the current pointer is advanced to C'C' so C'XYZ'
is not found. However, since each IFTHEN clause starts at the beginning
of the record, multiple IFTHEN clauses with FINDREP can be used to
change a constant and then change it again. If you used: OUTFIL IFTHEN=(WHEN=INIT,FINDREP=(INOUT=(C'AB',C'XY'))),
IFTHEN=(WHEN=INIT,FINDREP=(INOUT=(C'XYC',C'RST')))
for
the ABC record, the output would be: RST
The
first IFTHEN clause would change C'AB' to C'XY'. The second IFTHEN
clause would start over from the first position and change C'XYC'
to C'RST'.
- Duplicates and supersets of the same input constant after the
first are effectively ignored, whereas subsets of the same input constant
after the first are processed. For example, if you had this input
record:
ABCD ABQ
and you used this OUTFIL
statement: OUTFIL FINDREP=(INOUT=(C'AB',C'XY',C'ABCD',C'RSTU'))
the
output record would be: XYCD XYQ
Since
C'AB' is changed to C'XY', C'ABCD' is not found. If you wanted to
change C'ABCD' to C'RSTU' and other instances of C'AB' to C'XY', you
would need to specify C'ABCD' first. If you used this OUTFIL statement: OUTFIL FINDREP=(INOUT=(C'ABCD',C'RSTU',C'AB',C'XY'))
the
output record would be: RSTU XYQ
If C'ABCD'
is found, it is changed to C'RSTU'. Otherwise, if C'AB' is found,
it is changed to C'XY'.
- For fixed-length records, FINDREP in an IFTHEN clause operates
against the maximum record padded with blanks on the right as needed.
If a blank constant is being replaced, the blanks on the right will
be replaced. For example, if we have an 80 byte FB input record and
use:
OUTFIL IFTHEN=(WHEN=INIT,BUILD=(1,20)),
IFTHEN=(WHEN=(2,1,CH,EQ,C'R'),
FINDREP=(IN=C' ',OUT=C'ABC'))
Although in
this case BUILD=(1,20) will result in a 20-byte output record, IFTHEN
FINDREP will operate against the maximum 80-byte record padded with
60 blanks on the right. For a record with 'R' in position 2, each
of those 60 blanks on the right will be replaced with C'ABC'. This
will cause an overrun of the 80 byte record, thus resulting in termination
(OVERRUN=ERROR) or truncation (OVERRUN=TRUNC). ENDPOS=20 could be
used to stop FINDREP from replacing the 60 blanks on the right.
Note
that if we have an 80-byte input record with 'ABC' in positions 1-3
and we use: OUTFIL IFTHEN=(WHEN=INIT,BUILD=(1,3)),
IFTHEN=(WHEN=INIT,FINDREP=(IN=C'ABC',OUT=C'12345'))
an
overrun will not occur because IFTHEN FINDREP will operate against
an 80-byte record padded with 77 blanks on the right, rather than
against a 3-byte record even though the output record will be 3 bytes.
- For FINDREP in an IFTHEN clause, MAXLEN=n can be used to increase
the maximum output length, but cannot be used to decrease the maximum
output length. For example, with:
OUTFIL IFTHEN=(WHEN=INIT,BUILD=(1,100)),
IFTHEN=(WHEN=INIT,
FINDREP=(IN=C'A',OUT=C'B',MAXLEN=150))
the
output length will be set to 150, whereas with: OUTFIL IFTHEN=(WHEN=INIT,BUILD=(1,100)),
IFTHEN=(WHEN=INIT,
FINDREP=(IN=C'A',OUT=C'B',MAXLEN=70))
the
output length will be set to 100.
- IFTHEN
.-,-------------------------------------------------------------------.
V |
>>---IFTHEN=(-+-WHEN=INIT-+-,PARSE=(definitions)-+-------------------+-)-+-><
| '-+-,BUILD=(items)---+-' |
| +-,OVERLAY=(items)-+ |
| '-,FINDREP=(items)-' |
+-WHEN=GROUP-+-,BEGIN=(logexp)-+-,PUSH=(items)---------+
| +-,KEYBEGIN=(p,m)-+ |
| +-,END=(logexp)---+ |
| '-,RECORDS=n------' |
+-WHEN=(logexp)-+-,PARSE=(definitions)-+-+-----------+-+
| '-+-,BUILD=(items)---+-' '-,HIT=NEXT-' |
| +-,OVERLAY=(items)-+ |
| '-,FINDREP=(items)-' |
+-WHEN=ANY-+-,PARSE=(definitions)-+-+-----------+------+
| '-+-,BUILD=(items)---+-' '-,HIT=NEXT-' |
| +-,OVERLAY=(items)-+ |
| '-,FINDREP=(items)-' |
'-WHEN=NONE-+-,PARSE=(definitions)-+-------------------'
'-+-,BUILD=(items)---+-'
+-,OVERLAY=(items)-+
'-,FINDREP=(items)-'
IFTHEN clauses allow you to reformat different
records in different ways by specifying how build, overlay,
find/replace or group operation items are to be applied to records
that meet given criteria. IFTHEN clauses let you use simple or complex
conditional logic to choose how different record types are reformatted.
If
you want to insert, rearrange, or delete fields in the same way for
every record, use BUILD or OUTREC rather than IFTHEN. If
you want to do find and replace operations in the same way for every
record, use FINDREP rather than IFTHEN. Use IFTHEN clauses if you
want to insert, rearrange, delete, or overlay fields, or perform find/replace
operations in different ways for different records, or if you want
to perform operations on groups of records.
You can use five types of IFTHEN clauses as follows: - WHEN=INIT: Use one or more WHEN=INIT clauses to apply
build, overlay, or find/replace items to all of
your input records. WHEN=INIT clauses and WHEN=GROUP clauses are processed
before any of the other IFTHEN clauses.
- WHEN=GROUP: Use one or more WHEN=GROUP clauses
to propagate fields, identifiers and sequence numbers within specified
groups of records. WHEN=INIT clauses and WHEN=GROUP clauses are processed
before any of the other IFTHEN clauses.
- WHEN=(logexp): Use one or more WHEN=(logexp) clauses to
apply build, overlay or find/replace items
to your input records that meet specified criteria. A WHEN=(logexp)
clause is satisfied when the logical expression evaluates as true.
- WHEN=ANY: Use a WHEN=ANY clause after multiple WHEN=(logexp)
clauses to apply additional build, overlay or find/replace items
to your input records if they satisfied the criteria for any of the
preceding WHEN=(logexp) clauses.
- WHEN=NONE: Use one or more WHEN=NONE clauses to apply
build, overlay or find/replace items to your
input records that did not meet the criteria for any of the WHEN=(logexp)
clauses. WHEN=NONE clauses are processed after any of the other IFTHEN
clauses. If you do not specify a WHEN=NONE clause, only the WHEN=INIT and WHEN=GROUP changes (if any) are applied to
input records that do not meet the criteria for any of the WHEN=(logexp)
clauses.
IFTHEN clauses are processed in the following order: - WHEN=INIT clauses and WHEN=GROUP clauses
- WHEN=(logexp) clauses and WHEN=ANY clauses
- WHEN=NONE clauses
Processing of IFTHEN clauses continues unless one of the
following occurs: - A WHEN=(logexp) or WHEN=ANY clause is satisfied, and HIT=NEXT
is not specified.
- A WHEN=(logexp), WHEN=ANY or WHEN=NONE clause is satisfied, and
BUILD with / is specified (multiple output records).
- There are no more IFTHEN clauses to process. When processing
of IFTHEN clauses stops, the IFTHEN record created so far is used
as the output record.
Example: OUTFIL IFTHEN=(WHEN=(12,1,BI,ALL,X'3F'),OVERLAY=(18:C'Yes')),
IFTHEN=(WHEN=(35,2,PD,EQ,+14),BUILD=(1,40,45,3,HEX),HIT=NEXT),
IFTHEN=(WHEN=(35,2,PD,GT,+17),BUILD=(1,40,41,5,HEX),HIT=NEXT),
IFTHEN=(WHEN=ANY,BUILD=(1,55,C'ABC',70:X)),
IFTHEN=(WHEN=(35,2,PD,EQ,+8),BUILD=(1,40,2/,45,10)),
IFTHEN=(WHEN=(63,2,CH,EQ,C'AB'),OVERLAY=(18:C'No')),
IFTHEN=(WHEN=NONE,BUILD=(1,40,51,8,TRAN=LTOU))
For
this example, the IFTHEN clauses are processed as follows: - If IFTHEN clause 1 is satisfied, its overlay item is applied and
IFTHEN processing stops.
- If IFTHEN clause 1 is not satisfied, its overlay item is not applied
and IFTHEN processing continues.
- If IFTHEN clause 2 is satisfied, its build items are applied and
IFTHEN processing continues.
- If IFTHEN clause 2 is not satisfied, its build items are not applied
and IFTHEN processing continues.
- If IFTHEN clause 3 is satisfied, its build items are applied and
IFTHEN processing continues.
- If IFTHEN clause 3 is not satisfied, its build items are not applied
and IFTHEN processing continues.
- If IFTHEN clause 4 is satisfied, its build items are applied and
IFTHEN processing stops.
- If IFTHEN clause 4 is not satisfied, its build items are not applied
and IFTHEN processing continues.
- If IFTHEN clause 5 is satisfied, its build items are applied and
IFTHEN processing stops.
- If IFTHEN clause 5 is not satisfied, its build items are not applied
and IFTHEN processing continues.
- If IFTHEN clause 6 is satisfied, its overlay item is applied and
IFTHEN processing stops.
- If IFTHEN clause 6 is not satisfied, its overlay item is not applied
and IFTHEN processing continues.
- If IFTHEN clause 7 is satisfied, its build items are applied and
IFTHEN processing stops.
- If IFTHEN clause 7 is not satisfied, its build items are not applied
and IFTHEN processing stops.
All of the IFTHEN clauses operate sequentially on an IFTHEN
record. The IFTHEN record is created initially from the input record.
Each IFTHEN clause tests and changes the IFTHEN record, as appropriate.
Thus, changes made by earlier IFTHEN clauses are "seen" by later
IFTHEN clauses. For example, if you have a 40-byte input record
and specify: OUTFIL IFTHEN=(WHEN=INIT,OVERLAY=(8:8,4,ZD,ADD,+1,TO=ZD,LENGTH=4)),
IFTHEN=(WHEN=(8,4,ZD,EQ,+27),OVERLAY=(28:C'Yes')),
IFTHEN=(WHEN=NONE,OVERLAY=(28:C'No'))
The
WHEN=INIT clause adds 1 to the ZD value and stores it in the IFTHEN
record. The WHEN=(8,4,ZD,EQ,+27) clause tests the incremented ZD
value in the IFTHEN record rather than the original ZD value in the
input record.
The IFTHEN record is adjusted as needed for the
records created or changed by the IFTHEN clauses. For fixed-length
records, blanks are filled in on the left as needed. For variable-length
records, the RDW length is adjusted as needed each time the IFTHEN
record is changed.
Missing bytes in specified input fields are
replaced with blanks so the padded fields can be processed.
DFSORT
sets an appropriate LRECL for the OUTFIL output records based on the
build, overlay, find/replace and group operation items
specified by the IFTHEN clauses. However, DFSORT does not analyze
the possible results of WHEN=(logexp) conditions when determining
an appropriate LRECL. When you use OUTFIL IFTHEN clauses, you can
override the OUTFIL LRECL determined by DFSORT with the OUTFIL IFOUTLEN
parameter.
If SEQNUM is used in multiple IFTHEN
clauses, the sequence number will be incremented for each record that
satisfies the IFTHEN clause, that is, a separate SEQNUM counter will
be kept for each IFTHEN clause. For example, if your input is: RECORD A 1
RECORD B 1
RECORD B 2
RECORD C 1
RECORD A 2
RECORD C 2
RECORD B 3
RECORD D 1
and you specify: OUTFIL IFTHEN=(WHEN=(8,1,CH,EQ,C'A'),OVERLAY=(15:SEQNUM,4,ZD)),
IFTHEN=(WHEN=(8,1,CH,EQ,C'B'),OVERLAY=(16:SEQNUM,4,ZD)),
IFTHEN=(WHEN=NONE,OVERLAY=(17:SEQNUM,4,ZD))
your
output will be: RECORD A 1 0001
RECORD B 1 0001
RECORD B 2 0002
RECORD C 1 0001
RECORD A 2 0002
RECORD C 2 0002
RECORD B 3 0003
RECORD D 1 0003
Separate SEQNUM counters are kept
for the 'A' record, for the 'B' record, and for the NONE records. You
can use IFTHEN clauses with the FTOV parameter to convert fixed-length
record data sets to variable-length record data sets.
You can
use the VLTRIM parameter with IFTHEN clauses to remove specified trailing
bytes from the end of variable-length records.
You
can use the VLTRAIL parameter with IFTHEN clauses to insert a string
at the end of variable-length records.
You can use IFTHEN clauses
with any or all of the report parameters (LINES,
HEADER1, TRAILER1, HEADER2, TRAILER2, SECTIONS, BLKCCH1, BLKCCH2,
BLKCCT1, and NODETAIL) in the same way as for the BUILD or OUTREC
parameter.
The IFTHEN clauses of the OUTREC statement apply
to all input records whereas the IFTHEN clauses of the OUTFIL statement
only apply to the OUTFIL input records for its OUTFIL group.
- WHEN=INIT clause
- Specifies build, overlay or find/replace items
to be applied to all records. Multiple WHEN=INIT clauses and WHEN=GROUP
clauses may be intermixed. They are processed before any other type
of IFTHEN clauses and in the order in which they are specified.
- WHEN=INIT
- Identifies a WHEN=INIT clause.
- PARSE=(definitions)
- Defines %nn fixed parsed fields into which variable position/length
fields are extracted for all records. See OUTFIL PARSE for details.
You can use the %nn parsed fields defined in a WHEN=INIT clause
in the BUILD or OVERLAY operand of that clause and all subsequent
IFTHEN clauses.
Sample Syntax: OUTFIL IFOUTLEN=50,
IFTHEN=(WHEN=INIT,
PARSE=(%01=(ABSPOS=11,STARTAT=NONBLANK,
ENDBEFR=C',',FIXLEN=12),
%02=(ENDBEFR=C',',FIXLEN=10),
%03=(FIXLEN=12))),
IFTHEN=(WHEN=(5,2,CH,EQ,C'US'),BUILD=(%02,%03)),
IFTHEN=(WHEN=(5,2,CH,EQ,C'UK'),BUILD=(%01,%02)),
IFTHEN=(WHEN=NONE,BUILD=(%03,%01))
- BUILD=(items)
- Specifies the build items to be applied to each record. See OUTFIL
BUILD for details. You can specify all of the items in the same way
that you can specify them for OUTFIL BUILD, except that you cannot
specify / to create blank records or new records.
- OVERLAY=(items)
- Specifies the overlay items to be applied to each record. See
OUTFIL OVERLAY for details. You can specify all of the items in the
same way that you can specify them for OUTFIL OVERLAY.
Sample
Syntax: OUTFIL FNAMES=OUT1,
IFTHEN=(WHEN=INIT,BUILD=(1,20,21:C'Department',31:3X,21,60)),
IFTHEN=(WHEN=(5,2,CH,EQ,C'D1'),OVERLAY=(31:8,3)),
IFTHEN=(WHEN=(5,2,CH,EQ,C'D2'),OVERLAY=(31:12,3))
- FINDREP=(items)
- Specifies find and replace operations to be applied to each record.
See OUTFIL FINDREP for details. You can specify all of the items
in the same way that you can specify them for OUTFIL FINDREP.
Sample
Syntax
OUTFIL FNAMES=OUT2,
IFTHEN=(WHEN=INIT,FINDREP=(IN=X'00',OUT=X'40')),
IFTHEN=(WHEN=INIT,OVERLAY=(81:SEQNUM,8,ZD))
- WHEN=GROUP clause
- Identifies groups of records in various ways and propagates fields,
identifiers and sequence numbers to the records of each group. Fields,
identifiers and sequence numbers are not propagated to records before,
between or after identified groups. Multiple WHEN=INIT clauses and
WHEN=GROUP clauses may be intermixed. They are processed before any
other type of IFTHEN clauses and in the order in which they are specified.
You
can specify the BEGIN, KEYBEGIN, END and RECORDS
operands in any combination to define the groups, but you must specify
at least one of these operands.
- BEGIN=(logexp)
- Specifies the criteria to be tested to determine if a record starts
a group. See the INCLUDE statement for details of the logical expressions
you can use. You can specify all of the logical expressions in the
same way that you can specify them for the INCLUDE statement except
that:
- You cannot specify FORMAT=f with BEGIN=(logexp).
- You cannot specify D2 format in BEGIN=(logexp).
- Locale processing is not used for BEGIN=(logexp).
- VLSCMP and VLSHRT are not used with BEGIN=(logexp). Instead, missing
bytes in specified input fields are replaced with blanks so the padded
fields can be processed.
A new group starts with a record that satisfies the BEGIN
condition, that is, when the specified logical expression is true
for that record. If BEGIN is specified without END or RECORDS, all
of the records from the begin record up to but not including the next
begin record belong to a group. Here's an example of groups with BEGIN=(1,1,CH,EQ,C'A'):
H
R
A group 1
B group 1
C group 1
A group 2
A group 3
B group 3
Example: OUTFIL IFTHEN=(WHEN=GROUP,
BEGIN=(1,40,SS,EQ,C'J82',OR,1,40,SS,EQ,C'M72'),
PUSH=(41:ID=5))
Starts a new group each time
C'J82' or 'M72' is found anywhere in positions 1-40 of a record.
Overlays positions 41-45 of each record of a group with a 5-byte ZD
identifier. The records before the first group are not changed.
- KEYBEGIN=(p,m)
- Specifies a field to be used to determine if a record starts a
group. A new group starts when the binary value in the specified
key field (p,m) changes. The first input record will start a group.
KEYBEGIN=(p,m) operates in a similar way to BEGIN=(logexp) but uses
a key change as a trigger rather than a condition to be satisfied.
Use KEYBEGIN=(p,m) if you want to start a new group for each consecutive
set of key values in your records.
p is the starting position
of the key and can be from 1 to 32752.
m is
the length of the key and can be from 1 to 256.
If
KEYBEGIN=(p,m) is specified, the first input record will start a group.
Here is an example of groups with KEYBEGIN=(1,1)
A group 1
A group 1
A group 1
B group 2
B group 2
C group 3
Example: OUTFIL IFTHEN=(WHEN=GROUP,
KEYBEGIN=(11,5),PUSH=(81:21,8))
Starts a new
group each time the value in positions 11-15 changes. Overlays positions
81-88 of each record of a group with positions 21-28 from the first
record of that group.
- END=(logexp)
- Specifies the criteria to be tested to determine if a record ends
a group. See the INCLUDE statement for details of the logical expressions
you can use. You can specify all of the logical expressions in the
same way that you can specify them for the INCLUDE statement except
that:
- You cannot specify FORMAT=f with END=(logexp).
- You cannot specify D2 format in END=(logexp).
- Locale processing is not used for END=(logexp).
- VLSCMP and VLSHRT are not used with END=(logexp). Instead, missing
bytes in specified input fields are replaced with blanks so the padded
fields can be processed.
A group ends whenever a record satisfies the END condition,
that is, whenever the specified logical expression is true for that
record. If END is specified without BEGIN or KEYBEGIN,
all of the records up to the end record (or the last record of the
data set) belong to a group. Here's an example of groups with END=(1,1,CH,EQ,C'T')
A group 1
B group 1
T group 1
T group 2
A group 3
T group 3
M group 4
If END is specified with BEGIN or KEYBEGIN, all of the records from the begin
record up to the end record (or the last record of the data set) belong
to a group. Here's an example of groups with BEGIN=(1,1,CH,EQ,C'H'),END=(1,1,CH,EQ,C'T')
H group 1
B group 1
T group 1
T
H group 2
T group 2
M
N
H group 3
A group 3
Example: OUTFIL IFTHEN=(WHEN=GROUP,
BEGIN=(1,2,CH,EQ,C'02',AND,8,3,CH,EQ,C'YES'),
END=(11,5,CH,EQ,C'PAGE:'),PUSH=(61:SEQ=3))
Starts
a new group each time C'02' is found in positions 1-2 and C'YES' is
found in positions 8-10 of a record. Ends the group when C'PAGE:'
is found in positions 11-15 of a record. Overlays positions 61-63
of each record of a group with a 3-byte ZD sequence number. The records
between the groups are not changed.
- RECORDS=n
- Specifies the maximum number of records in a group. n can be 1
to 2000000000. If RECORDS is specified without BEGIN, KEYBEGIN or
END, a new group starts after n records. Here's an example of groups
with
RECORDS=3
H group 1
B group 1
T group 1
H group 2
B group 2
T group 2
M group 3
N group 3
If RECORDS is specified with BEGIN or KEYBEGIN, up to n records starting with the
begin record belong to a group. Here's an example of groups with BEGIN=(1,1,CH,EQ,C'H'),RECORDS=3
H group 1
B group 1
T group 1
A
H group 2
B group 2
H group 3
M group 3
N group 3
P
The records between and after the groups are not
changed.
If RECORDS is specified with END, the group
ends after up to n records or with the end record (or the last record
of the data set), whichever comes first. Here's an example of groups
with BEGIN=(1,1,CH,EQ,C'H'),END=(1,1,CH,EQ,C'T'),RECORDS=4
H group 1
B group 1
T group 1
A
H group 2
B group 2
C group 2
D group 2
E
H group 3
M group 3
The records between the groups are not
changed.
You must specify the PUSH operand to define at
least one field, identifier or sequence number to be added to the
records of each group. You can specify any combination or number
of fields, identifiers and sequence numbers.
- PUSH=(c:item,...)
- Specifies the position where each field, identifier or sequence
number is to be overlaid in the records of each group.
For fixed-length
records, the first input and output data byte starts at position 1.
For variable-length records, the first input and output data byte
starts at position 5, after the RDW in positions 1-4.
You can
use the following in PUSH:
- c:
- Specifies the output position (column) to be overlaid. If you
do not specify c: for the first item, it defaults to 1:. If you
do not specify c: for any other item, it starts after the previous
item. You can specify items in any order and overlap output columns.
c can be 1 to 32752.
If you specify an item that extends the output
record beyond the end of the input record, the record length is automatically
increased to that length, and blanks are filled in on the left as
needed. For variable-length records, the RDW length is increased
to correspond to the larger record length after all of the items are
processed. Missing bytes in specified input fields are replaced with
blanks so the padded fields can be processed.
- p,m
- Specifies a field in the first input record of each group to be
propagated to every record of the group. p specifies the starting
position of the field in the input record and m specifies its length.
A field must not extend beyond position 32752.
- ID=n
- Specifies a ZD identifier of length n is to be added to every
record of each group. The identifier starts at 1 for the first group
and is incremented by 1 for each subsequent group. n can be 1 to 15.
- SEQ=n
- Specifies a ZD sequence number of length n is to be added to every
record of each group. The sequence number starts at 1 for the first
record of each group and is incremented by 1 for each subsequent record
of the group. n can be 1 to 15.
Sample Syntax OUTFIL IFTHEN=(WHEN=GROUP,
BEGIN=(1,5,CH,EQ,C'DATE:'),
RECORDS=3,
PUSH=(15:ID=3,31:21,8))
- WHEN=(logexp) clause
- Specifies build, overlay or find/replace items
to be applied to records for which the specified logical expression
is true. If multiple WHEN=(logexp) clauses are specified, they are
processed in the order in which they are specified.
- WHEN=(logexp)
- Identifies a WHEN=(logexp) clause and specifies the criteria to
be tested to determine if the build, overlay or
find/replace items are to be applied to the record. See the
INCLUDE statement for details of the logical expressions you can use.
You can specify all of the logical expressions in the same way that
you can specify them for the INCLUDE statement except that:
- You cannot specify FORMAT=f with WHEN=(logexp).
- You cannot specify D2 format in WHEN=(logexp).
- Locale processing is not used for WHEN=(logexp).
- VLSCMP and VLSHRT are not used with WHEN=(logexp). Instead, missing
bytes in specified input fields are replaced with blanks so the padded
fields can be processed.
- PARSE=(definitions)
- Defines %nn fixed parsed fields into which variable position/length
fields are extracted for each record for which the logical expression
is true. See OUTFIL PARSE for details. You can only use the %nn
parsed fields defined in a WHEN=(logexp) clause in the BUILD or OVERLAY
operand of that WHEN=(logexp) clause.
Sample Syntax:
OUTFIL IFTHEN=(WHEN=(45,2,CH,EQ,C'AL'),
PARSE=(%01=(ENDBEFR=C',',FIXLEN=12),
%02=(FIXLEN=10)),
OVERLAY=(21:%02,51:%01))
- BUILD=(items)
- Specifies the build items to be applied to each record for which
the logical expression is true. See OUTFIL BUILD for details. You
can specify all of the items in the same way that you can specify
them for OUTFIL BUILD.
- OVERLAY=(items)
- Specifies the overlay items to be applied to each record for which
the logical expression is true. See OUTFIL OVERLAY for details.
You can specify all of the items in the same way that you can specify
them for OUTFIL OVERLAY.
- FINDREP=(items)
- Specifies find and replace operations to be applied to each record
for which the logical expression is true. See OUTFIL FINDREP for details.
You can specify all of the items in the same way that you can specify
them for OUTFIL FINDREP.
Sample Syntax OUTFIL IFTHEN=(WHEN=(11,2,CH,EQ,C'**'),
FINDREP=(IN=C'**',OUT=C''))
- HIT=NEXT
- Specifies that IFTHEN processing should continue even if the logical
expression is true. By default (if HIT=NEXT is not specified), IFTHEN
processing stops if the logical expression is true.
Sample Syntax: OUTFIL FNAMES=OUT2,
IFTHEN=(WHEN=(1,3,CH,EQ,C'T01',AND,
18,4,ZD,LE,+2000),OVERLAY=(42:C'Type1 <= 2000'),HIT=NEXT),
IFTHEN=(WHEN=(1,3,CH,EQ,C'T01',AND,6,1,BI,BO,X'03'),
BUILD=(1,21,42,13)),
IFTHEN=(WHEN=(1,3,CH,EQ,C'T01',AND,
18,4,ZD,GT,+2000),OVERLAY=(42:C'Type1 > 2000 '),HIT=NEXT),
IFTHEN=(WHEN=(1,3,CH,EQ,C'T01',AND,6,1,BI,BO,X'01'),
BUILD=(1,25,42,13))
- WHEN=ANY clause
- Specifies build, overlay or find/replace items
to be applied to records for which the logical expression in any "preceding"
WHEN=(logexp) clause is true. For the first WHEN=ANY clause, the "preceding"
WHEN=(logexp) clauses are those before this WHEN=ANY clause. For
the second or subsequent WHEN=ANY clause, the "preceding" WHEN=(logexp)
clauses are those between the previous WHEN=ANY clause and this WHEN=ANY
clause. At least one WHEN=(logexp) clause must be specified before
a WHEN=ANY clause. A WHEN=ANY clause can be used without any build,
overlay or find/replace items to just stop
IFTHEN processing if any preceding WHEN=(logexp) clause is satisfied.
- PARSE=(definitions)
- Defines %nn fixed parsed fields into which variable position/length
fields are extracted for each record for which the logical expression
in any preceding WHEN=(logexp) clause is true. See OUTFIL PARSE for
details. You can only use the %nn parsed fields defined in a WHEN=ANY
clause in the BUILD or OVERLAY operand of that WHEN=ANY clause.
- BUILD=(items)
- Specifies the build items to be applied to each record for which
the logical expression in any preceding WHEN=(logexp) clause is true.
See OUTFIL BUILD for details. You can specify all of the items in
the same way that you can specify them for OUTFIL BUILD.
- OVERLAY=(items)
- Specifies the overlay items to be applied to each record for which
the logical expression in any preceding WHEN=(logexp) clause is true.
See OUTFIL OVERLAY for details. You can specify all of the items
in the same way that you can specify them for OUTFIL OVERLAY.
- FINDREP=(items)
- Specifies find and replace operations to be applied to each record
for which the logical expression in any preceding WHEN=(logexp) clause
is true. See OUTFIL FINDREP for details. You can specify all of the
items in the same way that you can specify them for OUTFIL FINDREP.
- HIT=NEXT
- Specifies that IFTHEN processing should continue even if the logical
expression in a preceding WHEN=(logexp) clause is true. By default
(if HIT=NEXT is not specified), IFTHEN processing stops if the logical
expression in a preceding WHEN=(logexp) clause is true.
Sample Syntax: OUTFIL FNAMES=OUT3,
IFTHEN=(WHEN=(1,3,SS,EQ,C'T01,T02,T03'),
BUILD=(C'Group A',X,1,80),HIT=NEXT),
IFTHEN=(WHEN=(1,3,SS,EQ,C'T04,T05,T06'),
BUILD=(C'Group B',X,1,80),HIT=NEXT),
IFTHEN=(WHEN=(1,3,SS,EQ,C'T07,T08,T09,T10'),
BUILD=(C'Group C',X,1,80),HIT=NEXT),
IFTHEN=(WHEN=ANY,OVERLAY=(16:C'Group Found'))
- WHEN=NONE clause
- Specifies build, overlay or find/replace items
to be applied to records for which none of the logical expressions
in any WHEN=(logexp) clause is true. If there are no WHEN=(logexp)
clauses, the build, overlay or find/replace items
are applied to all of the records. If multiple WHEN=NONE clauses
are specified, they are processed in the order in which they are specified.
WHEN=NONE clauses are processed after any other type of IFTHEN clauses.
- PARSE=(definitions)
- Defines %nn fixed parsed fields into which variable position/length
fields are extracted for each record for which no logical expression
was true. See OUTFIL PARSE for details. You can only use the %nn
parsed fields defined in a WHEN=NONE clause in the BUILD or OVERLAY
operand of that WHEN=NONE clause.
Sample Syntax:
OUTFIL IFTHEN=(WHEN=(5,2,ZD,GT,+5),
PARSE=(%01=(STARTAT=C'<',ENDAT=C'>',FIXLEN=12),
%02=(STARTAFT=BLANKS,FIXLEN=10)),
BUILD=(5,2,21:%01,X,%02,HEX)),
IFTHEN=(WHEN=NONE,
PARSE=(%03=(STARTAFT=C'(',ENDBEFR=C')',FIXLEN=8)),
BUILD=(5,2,%03,SFF,M12))
- BUILD=(items)
- Specifies the build items to be applied to each record for which
no logical expression was true. See OUTFIL BUILD for details. You
can specify all of the items in the same way that you can specify
them for OUTFIL BUILD.
- OVERLAY=(items)
- Specifies the overlay items to be applied to each record for which
no logical expression was true. See OUTFIL OVERLAY for details.
You can specify all of the items in the same way that you can specify
them for OUTFIL OVERLAY.
Sample Syntax: OUTFIL FNAMES=OUT4,
IFTHEN=(WHEN=INIT,BUILD=(1,20,21:C'Department',31:3X,21,60)),
IFTHEN=(WHEN=(5,2,CH,EQ,C'D1'),OVERLAY=(31:8,3)),
IFTHEN=(WHEN=(5,2,CH,EQ,C'D2'),OVERLAY=(31:12,3)),
IFTHEN=(WHEN=NONE,OVERLAY=(31:C'***'))
- FINDREP=(items)
- Specifies find and replace operations to be applied to each record
for which no logical expression was true. See OUTFIL FINDREP for details.
You can specify all of the items in the same way that you can specify
them for OUTFIL FINDREP.
Default for IFTHEN clauses: None; must
be specified.
- IFOUTLEN
>>-IFOUTLEN=n--------------------------------------------------><
Overrides the OUTFIL LRECL determined by DFSORT
from your OUTFIL IFTHEN clauses. DFSORT sets an appropriate LRECL
for the output records based on the build, overlay, find/replace
and group operation items specified by the IFTHEN clauses. However,
DFSORT does not analyze the possible results of WHEN=(logexp) conditions
when determining an appropriate OUTFIL LRECL. When you use OUTFIL
IFTHEN clauses, you can override the OUTFIL LRECL determined by DFSORT
with the OUTFIL IFOUTLEN parameter.
Fixed-length records longer
than the IFOUTLEN length are truncated to the IFOUTLEN length. Fixed-length
records shorter than the IFOUTLEN are padded with blanks to the IFOUTLEN
length. Variable-length records longer than the IFOUTLEN length are
truncated to the IFOUTLEN length.
- n
- specifies the length to use for the OUTFIL LRECL. The value for
n must be between 1 and 32767, but must not be larger than the maximum
LRECL allowed for the RECFM, and must not conflict with the specified
or retrieved LRECL for the fixed-length OUTFIL data set.
Sample Syntax: OUTFIL FNAMES=OUT5,IFOUTLEN=70,
IFTHEN=(WHEN=(5,1,CH,EQ,C'1',AND,8,3,ZD,EQ,+10),
BUILD=(1,40,C'T01-GROUP-A',65)),
IFTHEN=(WHEN=(5,1,CH,EQ,C'2',AND,8,3,ZD,EQ,+12),
BUILD=(1,40,C'T02-GROUP-B',65))
Default
for IFOUTLEN: The LRECL determined from the IFTHEN clauses.
- VTOF or CONVERT
>>-+-VTOF----+-------------------------------------------------><
'-CONVERT-'
Specifies that variable-length OUTFIL input records
are to be converted to fixed-length OUTFIL output records for this
OUTFIL group.
You must specify a BUILD or OUTREC parameter.
The items you specify produce a reformatted fixed-length OUTFIL output
record without an RDW (the data starts at position 1). Any BUILD or
OUTREC fields you specify apply to the variable-length OUTFIL input
records (the data starts at position 5 after the 4-byte RDW). However,
you cannot specify the variable-part of the OUTFIL input records (for
example, p or p,HEX). Any BUILD or OUTREC columns you specify apply
to the reformatted fixed-length OUTFIL output records.
By default,
VTOF or CONVERT automatically uses VLFILL=X'40' (blank fill byte)
to allow processing of variable-length input records which are too
short to contain all specified BUILD or OUTREC fields. You can specify
VLFILL=byte to change the fill byte.
If you do not specify a
RECFM for the OUTFIL data set, it will be given a record format of
FB.
If you specify a RECFM for the OUTFIL data set, it must
have a fixed-length record format (for example, FB).
If VTOF
or CONVERT is specified for fixed-length input records, it will not
be used.
If VTOF or CONVERT is specified with FTOV, IFTRAIL, IFTHEN, FINDREP or
OVERLAY, DFSORT will terminate.
Sample Syntax: OUTFIL FNAMES=FIXOUT,VTOF,
OUTREC=(1:5,14,35:32,8,50:22,6,7c'*')
Default
for VTOF or CONVERT: None; must be specified.- VLFILL
>>-VLFILL=byte-------------------------------------------------><
Allows DFSORT to continue processing if a variable-length
OUTFIL input record is found to be too short to contain all specified
OUTFIL BUILD or OUTREC fields for this OUTFIL group. Without VLFILL=byte,
a short record causes DFSORT to issue message ICE218A and terminate.
With VLFILL=byte, missing bytes in OUTFIL BUILD or OUTREC fields
are replaced with fill bytes so the filled fields can be processed.
If
VLFILL=byte is specified for fixed-length input records, it will not
be used.
If VLFILL=byte is specified with FTOV, IFTRAIL, IFTHEN, FINDREP or
OVERLAY, DFSORT will terminate.
- byte
- specifies the fill byte. Permissible values are C'x' and X'yy'.
- C'x'
- Character byte: The value x must be one EBCDIC character. If
you want to use an apostrophe as the fill byte, you must specify
it as C''''.
- X'yy'
- Hexadecimal byte: The value yy must be one pair of hexadecimal
digits (00-FF).
Sample Syntax: OUTFIL FNAMES=FIXOUT,VTOF,OUTREC=(5,20,2X,35,10),VLFILL=C'*'
OUTFIL FNAMES=OUT1,VLFILL=X'FF',OUTREC=(1,4,15,5,52)
Default
for VLFILL: VLFILL=X'40' (blank fill byte) if VTOF or CONVERT
is specified. Otherwise, none; must be specified.
- FTOV
>>-FTOV--------------------------------------------------------><
Specifies that fixed-length OUTFIL input records
are to be converted to variable-length OUTFIL output records for this
OUTFIL group.
If you do not specify an OUTREC, BUILD, OVERLAY, FINDREP or IFTHEN parameter, the fixed-length OUTFIL
input record is converted to a variable-length OUTFIL output record.
A 4-byte RDW is prepended to the fixed-length record before it is
written.
If you specify an OUTREC, BUILD, OVERLAY, FINDREP or IFTHEN parameter, the items you specify
produce a reformatted fixed-length record that is converted to a variable-length
OUTFIL output record. Any OUTREC, BUILD, OVERLAY, FINDREP or
IFTHEN fields you specify apply to the fixed-length OUTFIL input records
(the data starts at position 1). A 4-byte RDW is prepended to the
reformatted fixed-length record before it is written.
If you
do not specify a RECFM for the OUTFIL data set, it will be given a
record format of VB.
If you specify a RECFM for the OUTFIL data
set, it must have a variable-length record format (for example, VB
or VBS).
If you do not specify an LRECL for the OUTFIL data
set, it will be given an LRECL that can contain the largest variable-length
output record to be produced, up to a maximum of 32756 for an unspanned
record format (for example, VB) or up to 32767 for a spanned record
format (for example, VBS).
If you specify an LRECL for the OUTFIL
data set, it must be big enough to contain the largest variable-length
output record to be produced.
If your largest variable-length
output record is between 32757 and 32767 bytes, you'll need to specify
a spanned record format (for example, VBS) for the output data set.
If
FTOV is specified for variable-length input records, it will not be
used.
If FTOV is specified with VTOF, IFTRAIL,
CONVERT or VLFILL=byte, DFSORT will terminate.
Sample Syntax: OUTFIL FNAMES=VAROUT,FTOV
OUTFIL FNAMES=V1,FTOV,OUTREC=(1,20,26:21,10,6C'*')
OUTFIL FNAMES=V2,FTOV,
IFTHEN=(WHEN=(12,5,ZD,GT,+20000),OVERLAY=(25:C'Yes')),
IFTHEN=(WHEN=NONE,OVERLAY=(25:C'No'))
Default
for FTOV: None; must be specified.
- VLTRIM
>>-VLTRIM=byte-------------------------------------------------><
VLTRIM=byte specifies that the trailing bytes
are to be removed from the end of variable-length OUTFIL output records
for this OUTFIL group before the records are written.
The trim
byte can be any value, such as blank, binary zero, or asterisk. If
DFSORT finds one or more trim bytes at the end of a variable-length
OUTFIL data record or report record, it will decrease the length of
the record accordingly, effectively removing the trailing trim bytes.
However, VLTRIM=byte will not remove the RDW, the ANSI carriage control
character (if produced), or the first data byte.
For example,
say that you have the following 17-byte fixed-length data records
that you want to convert to variable-length data records: 123456***********
0003*************
ABCDEFGHIJ*****22
*****************
the
following variable-length output records will be written (4-byte RDW
followed by data): Length | Data
21 123456***********
21 0003*************
21 ABCDEFGHIJ*****22
21 *****************
but if you use: OUTFIL FTOV,VLTRIM=C'*'
the
following variable-length output records will be written (4-byte RDW
followed by data): Length | Data
10 123456
8 0003
21 ABCDEFGHIJ*****22
5 *
VLTRIM=C'*' removed the trailing
asterisks from the first and second records. The third record did
not have any trailing asterisks to remove. The fourth record had all
asterisks, so one asterisk was kept.
If VLTRIM=byte is specified
for fixed-length output records, it will not be used.
If VLTRIM is specified with IFTRAIL, DFSORT will terminate.- byte
- specifies the trim byte. Permissible values are C'x' and X'yy'.
- C'x'
- Character byte: The value x must be one EBCDIC character. If you
want to use an apostrophe as the trim byte, you must specify it as
C''''.
- X'yy'
- Hexadecimal byte: The value yy must be one pair of hexadecimal
digits (00-FF)
Sample Syntax: Fixed input:
OUTFIL FNAMES=TRIM1,FTOV,VLTRIM=C' '
Variable input:
OUTFIL FNAMES=TRIM2,VLTRIM=X'00'
OUTFIL FNAMES=TRIM3,VLTRIM=C'*',
OUTREC=(1,15,5X,16,8,5X,28)
Default for
VLTRIM: None; must be specified.
- VLTRAIL
>>-VLTRAIL=string----------------------------------------------><
VLTRAIL=string specifies that the indicated string
is to be inserted at the end of variable-length OUTFIL output records
for this OUTFIL group before the records are written.
string
can be 1 to 50 characters specified using a character string constant
(C'xx...x') or a hexadecimal string constant (X'yy...yy'). See INCLUDE control statement for details of coding character and hexadecimal
string constants.
DFSORT will insert the specified string at
the end of each variable-length OUTFIL data record or report record,
and increase the length of the record accordingly. You must ensure
that the LRECL of the OUTFIL data set is large enough to contain the
added bytes. If the added bytes increase the length of a record beyond
the LRECL for the data set, DFSORT will terminate. To avoid this,
you can specify a larger LRECL on the DD statement, when necessary.
For
example, say that you have the following variable-length input records: Length | Data
28 Professional Development
18 Psychoanalysis
25 Theory of Computation
and you want to add X'0D0A'
(CR,LF) to the end of each record. If you use the following OUTFIL
statement: OUTFIL FNAMES=OUT1,VLTRAIL=X'0D0A'
X'0D0A'
will be inserted at the end of each record and the length of each
record will be increased by 2 bytes. If we represent X'0D0A' by
CL, the OUT1 records will look like this: Length | Data
30 Professional DevelopmentCL
20 PsychoanalysisCL
27 Theory of ComputationCL
Note that if the
LRECL of the output data set is less than the maximum output record
(30 bytes for this example), we must increase it to at least the maximum
(LRECL=30 or greater for this example).
If VLTRIM=byte is used
with VLTRAIL=string, the indicated bytes will be trimmed from the
end of the record before the indicated string is added. For example,
say that you have the following variable-length input records: Length | Data
30 Abby is a sweet rat*******
31 Samantha is a curious rat**
43 Rachel is our oldest rat***************
29 Cathy is a mischief maker
and you want to remove
any trailing asterisks, and add '|March 21|' at the end of each
record. If you use the following OUTFIL statement: OUTFIL FNAMES=OUT2,VLTRIM=C'*',VLTRAIL=C'|March 21|'
The
trailing asterisks will be removed, 'March 21' will be inserted, and
the length of each record will be updated appropriately. The OUT2
records will look like this: Length | Data
33 Abby is a sweet rat|March 21|
39 Samantha is a curious rat|March 21|
38 Rachel is our oldest rat|March 21|
39 Cathy is a mischief maker|March 21|
If
VLTRAIL=string is specified for fixed-length output records, it will
not be used.
If VLTRAIL is specified with IFTRAIL, DFSORT will
terminate.
Sample Syntax: Variable input:
OUTFIL FNAMES=ADD1,VLTRIM=X'00',VLTRAIL=C'$$ADD$$'
OUTFIL FNAMES=(ADD2A,ADD2B),VLTRAIL=X'FFFF',SPLIT
Fixed input:
OUTFIL FNAMES=ADD3,FTOV,VLTRIM=C' ',VLTRAIL=C'end'
Default
for VLTRAIL: None; must be specified.
- REPEAT
>>-REPEAT=n----------------------------------------------------><
Specifies the number of times each OUTFIL output
record is to be repeated for this OUTFIL group. Each OUTFIL output
record is written n times.
If SEQNUM is used in the OUTREC,
BUILD, OVERLAY, or IFTHEN parameter for this OUTFIL group, the sequence
number will be incremented for each repeated record. For example,
if your input is: RECORD A
RECORD B
and you specify: OUTFIL OUTREC=(1,8,X,SEQNUM,5,ZD),REPEAT=2
your
output will be: RECORD A 00001
RECORD A 00002
RECORD B 00003
RECORD B 00004
If SEQNUM is used in multiple IFTHEN
clauses for this OUTFIL group, the sequence number will be incremented
for each repeated record that satisfies the IFTHEN
clause. For example, if your input is: RECORD A 1
RECORD B 1
RECORD C 1
RECORD A 2
RECORD C 2
RECORD B 2
RECORD B 3
and you specify: OUTFIL REPEAT=2,
IFTHEN=(WHEN=(8,1,CH,EQ,C'A'),OVERLAY=(15:SEQNUM,4,ZD)),
IFTHEN=(WHEN=(8,1,CH,EQ,C'B'),OVERLAY=(15:SEQNUM,4,ZD)),
IFTHEN=(WHEN=NONE,OVERLAY=(15:SEQNUM,4,ZD))
your output
will be: RECORD A 1 0001
RECORD A 1 0002
RECORD B 1 0001
RECORD B 1 0002
RECORD C 1 0001
RECORD C 1 0002
RECORD A 2 0003
RECORD A 2 0004
RECORD C 2 0003
RECORD C 2 0004
RECORD B 2 0003
RECORD B 2 0004
RECORD B 3 0005
RECORD B 3 0006
If you specify REPEAT=n with
/ in the OUTREC, BUILD, or IFTHEN BUILD parameter for this OUTFIL
group, the first line is written n times, then the second line is
written n times, and so on. (For IFTHEN, this means each record that
has the SEQNUM item applied to it.) If SEQNUM is used, all lines
for the same record are given the same sequence number. For example,
if your input is: RECORD A
RECORD B
and you specify: OUTFIL OUTREC=(C'P1>',X,1,6,X,SEQNUM,4,ZD,/,
C'P2>',X,8,1,X,SEQNUM,4,ZD),REPEAT=2
your output will
be: P1> RECORD 0001
P1> RECORD 0002
P2> A 0001
P2> A 0002
P1> RECORD 0003
P1> RECORD 0004
P2> B 0003
P2> B 0004
The REPEAT parameter cannot
be used with any of the following parameters: IFTRAIL,
LINES, HEADER1, TRAILER1, HEADER2, TRAILER2, SECTIONS, and NODETAIL.
- n
- specifies the number of times each OUTFIL output record is to
be repeated. The value for n starts at 2 (write record twice) and
is limited to 28 digits (15 significant digits).
Sample Syntax: * WRITE EACH OUTPUT RECORD 12 TIMES.
OUTFIL FNAMES=OUT1,REPEAT=12
* WRITE EACH INCLUDED AND REFORMATTED OUTPUT RECORD 50 TIMES.
* (THE SEQUENCE NUMBER WILL BE INCREMENTED FOR EACH REPETITION.)
OUTFIL FNAMES=OUT2,INCLUDE=(5,2,SS,EQ,C'B2,C5,M3'),
Default
for REPEAT: None; must be specified.
- SPLIT
>>-SPLIT-------------------------------------------------------><
Splits the output records one record at a time
in rotation among the data sets of this OUTFIL group until all of
the output records have been written. As a result, the records will
be split as evenly as possible among all of the data sets in the group.
As
an example, for an OUTFIL group with three data sets: - the first OUTFIL data set in the group will receive records 1,
4, 7, and so on.
- the second OUTFIL data set in the group will receive records 2,
5, 8, and so on.
- the third OUTFIL data set in the group will receive records 3,
6, 9, and so on.
The records are not contiguous in each
OUTFIL data set.SPLIT is equivalent to SPLITBY=1.
The SPLIT parameter cannot be used with any of the following
parameters: IFTRAIL, LINES, HEADER1, TRAILER1,
HEADER2, TRAILER2, SECTIONS, and NODETAIL.
Sample Syntax: * WRITE RECORD 1 TO PIPE1, RECORD 2 TO PIPE2, RECORD 3 TO PIPE3,
* RECORD 4 TO PIPE4, RECORD 5 TO PIPE1, RECORD 6 TO PIPE2, AND SO ON.
OUTFIL FNAMES=(PIPE1,PIPE2,PIPE3,PIPE4),SPLIT
* SPLIT THE INCLUDED AND REFORMATTED OUTPUT RECORDS EVENLY BETWEEN
* TAPE1 AND TAPE2.
OUTFIL FNAMES=(TAPE1,TAPE2),SPLIT,
INCLUDE=(8,2,ZD,EQ,27),OUTREC=(5X,1,75)
Default
for SPLIT: None; must be specified.
- SPLITBY
>>-SPLITBY=n---------------------------------------------------><
Splits the output records n records at a time in
rotation among the data sets of this OUTFIL group until all of the
output records have been written.
As an example, if SPLITBY=10
is specified for an OUTFIL group with three data sets: - the first OUTFIL data set in the group will receive records 1-10,
31-40, and so on.
- the second OUTFIL data set in the group will receive records 11-20,
41-50, and so on.
- the third OUTFIL data set in the group will receive records 21-30,
51-60, and so on.
The records are not contiguous in each
OUTFIL data set. SPLITBY=1 is equivalent to SPLIT.
The SPLITBY parameter cannot be used with any of the following
parameters: IFTRAIL, LINES, HEADER1, TRAILER1,
HEADER2, TRAILER2, SECTIONS, and NODETAIL.
- n
- specifies the number of records to split by. The value for n
starts at 1 and is limited to 28 digits (15 significant digits).
Sample Syntax: * WRITE RECORDS 1-5 TO PIPE1, RECORDS 6-10 TO PIPE2, RECORDS 11-15 TO
* PIPE3, RECORDS 16-20 TO PIPE4, RECORDS 21-25 TO PIPE1, RECORDS 26-30
* TO PIPE2, AND SO ON.
OUTFIL FNAMES=(PIPE1,PIPE2,PIPE3,PIPE4),SPLITBY=5
* SPLIT THE INCLUDED AND REFORMATTED OUTPUT RECORDS 100 AT A TIME
* BETWEEN TAPE1 AND TAPE2.
OUTFIL FNAMES=(TAPE1,TAPE2),SPLITBY=100,
INCLUDE=(8,2,ZD,EQ,27),OUTREC=(5X,1,75)
Default
for SPLITBY: None; must be specified.
- SPLIT1R
-
>>-SPLIT1R=n---------------------------------------------------><
Splits the output records n records at a time for
one rotation among the data sets of this OUTFIL group until all of
the output records have been written.
As an example, if SPLIT1R=10
is specified for an input data set with 35 records and an OUTFIL group
with three data sets: - the first OUTFIL data set in the group will receive records 1-10.
- the second OUTFIL data set in the group will receive records 11-20.
- the third OUTFIL data set in the group will receive records 21-35.
The records are contiguous in each OUTFIL
data set. The SPLIT1R parameter cannot be used with any of the
following parameters: IFTRAIL, LINES, HEADER1,
TRAILER1, HEADER2, TRAILER2, SECTIONS, and NODETAIL. - n
- specifies the number of records to split by. The value for n
starts at 1 and is limited to 28 digits (15 significant digits).
Sample Syntax:
* WRITE RECORDS 1-20 TO PIPE1, RECORDS 21-40 TO PIPE2,
* RECORDS 41-60 TO PIPE3 AND RECORDS 61-85 TO PIPE4.
OUTFIL FNAMES=(PIPE1,PIPE2,PIPE3,PIPE4),SPLIT1R=20
* SPLIT THE INCLUDED AND REFORMATTED OUTPUT RECORDS ONCE
* CONTIGUOUSLY BETWEEN TAPE1 AND TAPE2.
OUTFIL FNAMES=(TAPE1,TAPE2),SPLIT1R=100,
INCLUDE=(8,2,ZD,EQ,27),OUTREC=(5X,1,75)
Default
for SPLIT1R: None; must be specified.
- NULLOFL
>>-NULLOFL=-+-RC0--+-------------------------------------------><
+-RC4--+
'-RC16-'
specifies the action to be taken by DFSORT when
there are no data records for a data set associated with this OUTFIL
statement, as indicated by a DATA count of 0 in message ICE227I.
OUTFIL report records have no affect on the action taken as a result
of this option.
- RC0
- specifies that DFSORT should issue message ICE174I, set a return
code of 0, and continue processing when there are no data
records for a data set associated with this OUTFIL statement.
- RC4
- specifies that DFSORT should issue message ICE174I, set a return
code of 4, and continue processing when there are no data
records for the a data set associated with this OUTFIL statement.
- RC16
- specifies that DFSORT should issue message ICE209A, terminate,
and give a return code of 16 when there are no data records for a
data set associated with this OUTFIL statement.
Default for NULLOFL: The NULLOFL installation
default.
Note: - The NULLOFL value specified for each OUTFIL statement applies
to the data sets associated with that OUTFIL statement. If a NULLOFL
value is not specified for an OUTFIL statement, the NULLOFL installation
default value applies to the data sets associated with that OUTFIL
statement. For example, if the installation default is NULLOFL=RC0
(IBM's shipped default) and the following is specified:
OUTFIL FNAMES=OUT1,NULLOFL=RC16,INCLUDE=(5,3,CH,EQ,C'D01')
OUTFIL FNAMES=(OUT2,OUT3),INCLUDE=(5,3,CH,EQ,C'D02')
OUTFIL FNAMES=OUT4,NULLOFL=RC4,SAVE
then NULLOFL=RC16 applies
to the data set for OUT1, NULLOFL=RC0 (the installation default)
applies to the data sets for OUT2 and OUT3, and NULLOFL=RC4 applies
to the data set for OUT4.
- If you receive message ICE174I or ICE209A, a DATA count of 0 in
message ICE227I identifies an OUTFIL data set for which there are
no data records.
- The return code of 0 or 4 resulting from NULLOFL=RC0 or NULLOFL=RC4,
respectively, can be overridden by a higher return code set for some
other reason, including a return code of 16 resulting from NULLOFL=RC16.
- NULLOUT applies to the SORTOUT data set. NULLOFL applies to OUTFIL
data sets
- LINES
>>-LINES=n-----------------------------------------------------><
Specifies the number of lines per page to be used
for the reports produced for this OUTFIL group. DFSORT uses ANSI carriage
control characters to control page ejects and the placement of the
lines in your report, according to your specifications.
The LINES parameter cannot be used with the IFTRAIL
parameter.
- n
- specifies the number of lines per page. The value for n must
be between 1 and 255. However, n--or the default for n if LINES is
not specified--must be greater than or equal to the number of lines
needed for each of the following:
- The HEADER1 lines
- The TRAILER1 lines
- The sum of all lines for HEADER2, TRAILER2, HEADER3s, TRAILER3s,
and the data lines and blank lines produced from an input record.
Sample Syntax: OUTFIL FNAMES=RPT1,LINES=50
Default
for LINES: None; must be specified, unless HEADER1, TRAILER1,
HEADER2, TRAILER2, SECTIONS, or NODETAIL is specified, in which case
the default for LINES is 60.
- HEADER1
.-,---------------------------------.
V |
>>-HEADER1=(---+----+-+-r----------------------+-+-)-----------><
'-c:-' +-p,m--------------------+
+-+-DATE----------+------+
| +-&DATE---------+ |
| +-DATE=(abcd)---+ |
| +-&DATE=(abcd)--+ |
| +-DATENS=(abc)--+ |
| +-&DATENS=(abc)-+ |
| +-YDDD=(abc)----+ |
| +-&YDDD=(abc)---+ |
| +-YDDDNS=(ab)---+ |
| '-&YDDDNS=(ab)--' |
+-+-TIME---------+-------+
| +-&TIME--------+ |
| +-TIME=(abc)---+ |
| +-&TIME=(abc)--+ |
| +-TIMENS=(ab)--+ |
| '-&TIMENS=(ab)-' |
'-+-PAGE---------------+-'
+-&PAGE--------------+
+-PAGE=(-+-edit-+-)--+
| '-to---' |
'-&PAGE=(-+-edit-+-)-'
'-to---'
Specifies the report header to be used for the reports
produced for this OUTFIL group. The report header appears by itself
as the first page of the report. DFSORT uses ANSI carriage control
characters to control page ejects and the placement of the lines in
your report, according to your specifications. You can use BLKCCH1
to replace the '1' (page eject) for the ANSI carriage control character
in the first line of the report header with a blank, thus avoiding
forcing a page eject. You can use REMOVECC to remove the ANSI carriage
control characters from a report.
You can choose to include
any or all of the following report elements in your report header: - Blanks, character strings, and hexadecimal strings
- Unedited input fields from the first OUTFIL input record
- Current date in a variety of different forms
- Current time in a variety of different forms
- Page number, converted to different numeric formats, or edited
to contain signs, decimal points, leading zeros or no leading zeros,
and so on.
The HEADER1 parameter cannot be used with
the IFTRAIL parameter.
The report header consists of the elements
you select, in the order in which you specify them, and in the columns
or lines you specify. - c:
- specifies the column in which the first position of the associated
report element is to appear, relative to the start of the data in
the report record. Ignore the RDW (variable-length report records
only) and carriage control character when specifying c:. That is,
1: indicates the first byte of the data in the report record for both
fixed-length and variable-length report records.
Unused space preceding
the specified column is padded with EBCDIC blanks. The following rules
apply: - c must be a number between 1 and 32752.
- c: must be followed by a report element, but must not precede
/ or n/.
- c must not overlap the previous report element in the report record.
- The colon (:) is treated like the comma (,) or semicolon (;) for
continuation to another line.
- r
- specifies that blanks, a character string, or a hexadecimal string
are to appear in the report record, or that a new report record is
to be started in the header, with or without intervening blank lines.
These report elements can be specified before or after any other report
elements. Consecutive report elements can be specified. Permissible
values are nX, n'xx...x', nC'xx...x', nX'yy...yy', /.../ and n/.
- nX
- Blanks. n bytes of EBCDIC blanks (X'40') are to appear
in the report record. n can range from 1 to 4095. If n is omitted,
1 is used.
- n'xx...x'
- Character string. n repetitions of the character string constant
('xx...x') are to appear in the report record. n can range from 1
to 4095. If n is omitted, 1 is used. x can be any EBCDIC character.
You can specify 1 to 256 characters.
nC'xx...x' can be used instead
of n'xx...x'.
If you want to include a single apostrophe in
the character string, you must specify it as two single apostrophes: Required: O'NEILL Specify: 'O''NEILL' or C'O''NEILL'
- nX'yy...yy'
- Hexadecimal string. n repetitions of the hexadecimal string constant
(X'yy...yy') are to appear in the report record. n can range from
1 to 4095. If n is omitted, 1 is used.
The value yy represents
any pair of hexadecimal digits. You can specify from 1 to 256 pairs
of hexadecimal digits
- /.../ or n/
- Blank lines or a new line. A new report record is to be started
in the header with or without intervening blank lines. If /.../ or
n/ is specified at the beginning or end of the header, n blank lines
are to appear in the header. If /.../ or n/ is specified in the middle
of the header, n-1 blank lines are to appear in the header (thus,
/ or 1/ indicates a new line with no intervening blank lines).
Either
n/ (for example, 5/) or multiple /'s (for example, /////) can be used.
n can range from 1 to 255. If n is omitted, 1 is used.
As an
example, if you specify: OUTFIL HEADER1=(2/,'First line of text',/,
'Second line of text',2/,
'Third line of text',2/)
the report
header appears as follows when printed: blank line
blank line
First line of text
Second line of text
blank line
Third line of text
blank line
blank line
- p,m
- specifies that an unedited input field, from the first OUTFIL
input record for which a data record appears in the report, is to
appear in the report record.
- p
- specifies the first byte of the input field relative to the beginning
of the OUTFIL input record. The first data byte of a fixed-length
record has relative position 1. The first data byte of a variable-length
record has relative position 5, because the first four bytes are occupied
by the RDW. All fields must start on a byte boundary, and no field
can extend beyond byte 32752. See OUTFIL statements notes for
special rules concerning variable-length records.
- m
- specifies the length in bytes of the input field. The value for
m must be between 1 and 32752.
- DATE
- specifies that the current date is to appear in the report record
in the form 'mm/dd/yy', where mm represents the month (01-12), dd
represents the day (01-31), and yy represents the last two digits
of the year (for example, 95).
- &DATE
- can be used instead of DATE.
- DATE=(abcd)
- specifies that the current date is to appear in the report record
in the form 'adbdc', where a, b, and c indicate the order in which
the month, day, and year are to appear and whether the year is to
appear as two or four digits, and d is the character to be used to
separate the month, day and year.
For a, b, and c, use M to represent
the month (01-12), D to represent the day (01-31), Y to represent
the last two digits of the year (for example, 05), or 4 to represent
the four digits of the year (for example, 2005). M, D, and Y or 4
can each be specified only once. Examples: DATE=(DMY.) would produce
a date of the form 'dd.mm.yy', which on March 29, 2005, would appear
as '29.03.05'. DATE=(4MD-) would produce a date of the form 'yyyy-mm-dd',
which on March 29, 2005, would appear as '2005-03-29'.
a, b,
c, and d must be specified.
- &DATE=(abcd)
- can be used instead of DATE=(abcd).
- DATENS=(abc)
- specifies that the current date is to appear in the report record
in the form 'abc', where a, b and c indicate the order in which the
month, day, and year are to appear and whether the year is to appear
as two or four digits.
For a, b and c, use M to represent the month
(01-12), D to represent the day (01-31), Y to represent the last two
digits of the year (for example, 02), or 4 to represent the four digits
of the year (for example, 2002). M, D, and Y or 4 can each be specified
only once. Examples: DATENS=(DMY) would produce a date of the form
'ddmmyy', which on March 29, 2002, would appear as '290302'. DATENS=(4MD)
would produce a date of the form 'yyyymmdd', which on March 29, 2002,
would appear as '20020329'.
a, b and c must be specified.
- &DATENS=(abc)
- can be used instead of DATENS=(abc).
- YDDD=(abc)
- specifies that the current date is to appear in the report record
in the form 'acb', where a and b indicate the order in which the year
and day of the year are to appear and whether the year is to appear
as two or four digits, and c is the character to be used to separate
the year and day of the year.
For a and b, use D to represent the
day of the year (001-D366), Y to represent the last two digits of
the year (for example, 04), or 4 to represent the four digits of the
year (for example, 2004). D, and Y or 4 can each be specified only
once. Examples: YDDD=(DY-) would produce a date of the form 'ddd-yy'
which on April 7, 2004, would appear as '098-04'. YDDD=(4D/) would
produce a date of the form 'yyyy/ddd' which on April 7, 2004, would
appear as '2004/098'.
a, b and c must be specified.
- &YDDD=(abc)
- can be used instead of YDDD=(abc).
- YDDDNS=(ab)
- specifies that the current date is to appear in the report record
in the form 'ab', where a and b indicate the order in which the year
and day of the year are to appear and whether the year is to appear
as two or four digits.
For a and b, use D to represent the day of
the year (001-366), Y to represent the last two digits of the year
(for example, 04), or 4 to represent the four digits of the year (for
example, 2004). D, and Y or 4 can each be specified only once. Examples:
YDDDNS=(DY) would produce a date of the form 'dddyy' which on April
7, 2004, would appear as '09804'. YDDDNS=(4D) would produce a date
of the form 'yyyyddd' which on April 7, 2004, would appear as '2004098'.
a
and b must be specified.
- &YDDDNS=(ab)
- can be used instead of YDDDNS=(ab).
- TIME
- specifies that the current time is to appear in the report record
in the form 'hh:mm:ss', where hh represents the hour (00-23), mm represents
the minutes (00-59), and ss represents the seconds (00-59).
- &TIME
- can be used instead of TIME.
- TIME=(abc)
- specifies that the current time is to appear in the report record
in the form 'hhcmmcss' (24-hour time) or 'hhcmmcss xx' (12-hour time).
If
ab is 24, the time is to appear in the form 'hhcmmcss' (24-hour time)
where hh represents the hour (00-23), mm represents the minutes (00-59),
ss represents the seconds (00-59), and c is the character used to
separate the hours, minutes, and seconds. Example: TIME=(24.) would
produce a time of the form 'hh.mm.ss' which at 08:25:13 pm would appear
as '20.25.13'.
If ab is 12, the time is to appear in the form
'hhcmmcss xx' (12-hour time) where hh represents the hour (01-12),
mm represents the minutes (00-59), ss represents the seconds (00-59),
xx is am or pm, and c is the character used to separate the hours,
minutes, and seconds. Example: TIME=(12.) would produce a time of
the form 'hh.mm.ss xx' which at 08:25:13 pm would appear as '08.25.13
pm'.
ab and c must be specified.
- &TIME=(abc)
- can be used instead of TIME=(abc).
- TIMENS=(ab)
- specifies that the current time is to appear in the report record
in the form 'hhmmss' (24-hour time) or 'hhmmss xx' (12-hour time).
If
ab is 24, the time is to appear in the form 'hhmmss' (24-hour time)
where hh represents the hour (00-23), mm represents the minutes (00-59),
and ss represents the seconds (00-59). Example: TIMENS=(24) would
produce a time of the form 'hhmmss' which at 08:25:13 pm would appear
as '202513'.
If ab is 12, the time is to appear in the form
'hhmmss xx' (12-hour time) where hh represents the hour (01-12), mm
represents the minutes (00-59), and ss represents the seconds (00-59).
Example: TIMENS=(12) would produce a time of the form 'hhmmss xx'
which at 08:25:13 pm would appear as '082513 pm'.
ab must be
specified.
- &TIMENS=(ab)
- can be used instead of TIMENS=(ab).
- PAGE
- specifies that the page number is to appear in the report record.
The page number for the report header appears as ' 1'.
If
HEADER1 is specified with PAGE, PAGE for the report header (first
page) will be ' 1' and PAGE for the next page (second page) will
be ' 2'. If HEADER1 is specified without PAGE, PAGE for the page
after the report header (second page) will be ' 1' (typical of
a report with a cover sheet).
- &PAGE
- can be used instead of PAGE.
- PAGE=(edit) or PAGE=(to)
- same as PAGE except that the 15-digit page number appears edited
or converted as specified. See p,m,f,edit under OUTREC for further
details on the edit fields you can use. See p,m,f,to under OUTREC
for further details on the to fields you can use.
- &PAGE=(edit) or &PAGE=(to)
- can be used instead of PAGE=(edit) or PAGE=(to).
Sample Syntax: OUTFIL FNAMES=(RPT1,RPT2),
HEADER1=(30:'January Report',4/,
28:'Prepared on ',DATE,//,
32:'at ',TIME,//,
28:'using DFSORT''S OUTFIL',5/,
10:'Department: ',12,8,50:'Page:',PAGE=(EDIT=(TTT)))
Default
for HEADER1: None; must be specified.
- TRAILER1
.-,---------------------------------------------.
V |
>>-TRAILER1=-(---+----+-+-r----------------------------------+-+-)-><
'-c:-' +-p,m--------------------------------+
+-+-DATE----------+------------------+
| +-&DATE---------+ |
| +-DATE=(abcd)---+ |
| +-&DATE=(abcd)--+ |
| +-DATENS=(abc)--+ |
| +-&DATENS=(abc)-+ |
| +-YDDD=(abc)----+ |
| +-&YDDD=(abc)---+ |
| +-YDDDNS=(ab)---+ |
| '-&YDDDNS=(ab)--' |
+-+-TIME---------+-------------------+
| +-&TIME--------+ |
| +-TIME=(abc)---+ |
| +-&TIME=(abc)--+ |
| +-TIMENS=(ab)--+ |
| '-&TIMENS=(ab)-' |
+-+-PAGE---------------+-------------+
| +-&PAGE--------------+ |
| +-PAGE=(-+-edit-+-)--+ |
| | '-to---' | |
| '-&PAGE=(-+-edit-+-)-' |
| '-to---' |
+---+-COUNT----------------+---------+
| +-COUNT15--------------+ |
| +-COUNT=(-+-edit-+-)---+ |
| | '-to---' | |
| +-COUNT+n=(-+-edit-+-)-+ |
| | '-to---' | |
| '-COUNT-n=(-+-edit-+-)-' |
| '-to---' |
+---+-SUBCOUNT--------------+--------+
| +-SUBCOUNT15------------+ |
| '-SUBCOUNT=(-+-edit-+-)-' |
| '-to---' |
+-+-TOTAL=-+--(p,m,f-+-----------+-)-+
| '-TOT=---' '-+-,edit-+-' |
| '-,to---' |
+-MIN=--(p,m,f-+-----------+-)-------+
| '-+-,edit-+-' |
| '-,to---' |
+-MAX=--(p,m,f-+-----------+-)-------+
| '-+-,edit-+-' |
| '-,to---' |
+-AVG=--(p,m,f-+-----------+-)-------+
| '-+-,edit-+-' |
| '-,to---' |
'-| |-------------------------------'
Additional Parameters for TRAILER1
>>-+-+-SUBTOTAL=-+--(p,m,f-+-----------+-)-+-------------------><
| +-SUBTOT=---+ '-+-,edit-+-' |
| '-SUB=------' '-,to---' |
+-SUBMIN=--(p,m,f-+-----------+-)-------+
| '-+-,edit-+-' |
| '-,to---' |
+-SUBMAX=--(p,m,f-+-----------+-)-------+
| '-+-,edit-+-' |
| '-,to---' |
'-SUBAVG=--(p,m,f-+-----------+-)-------'
'-+-,edit-+-'
'-,to---'
Specifies the report trailer to be used
for the reports produced for this OUTFIL group. The report trailer
appears by itself as the last page of the report. DFSORT uses ANSI
carriage control characters to control page ejects and the placement
of the lines in your report, according to your specifications. You
can use BLKCCT1 to replace the '1' (page eject) for the ANSI carriage
control character in the first line of the report trailer with a blank,
thus avoiding forcing a page eject. You can use REMOVECC to remove
the ANSI carriage control characters from a report.
You can choose to include
any or all of the following report elements in your report trailer: - Blanks, character strings, and hexadecimal strings
- Unedited input fields from the last OUTFIL input record
- Current date in a variety of different forms
- Current time in a variety of different forms
- Page number, converted to different numeric formats, or edited
to contain signs, decimal points, leading zeros or no leading zeros,
and so on
- Any or all of the following statistics:
- Count of data records in the report, converted to different numeric
formats, or edited to contain signs, decimal points, leading zeros
or no leading zeros, and so on. You can add a decimal number to the
count before converting or editing it (for example, add 1 to account
for writing a trailer record, or add 2 to account for writing a header
and trailer record).
- Total, minimum, maximum, or average for each specified
ZD, PD, BI, FI, FL, CSF, FS, UFF, or SFF numeric input field in the
data records of the report, converted to different numeric formats,
or edited to contain signs, decimal points, leading zeros or no leading
zeros, and so on.
The TRAILER1 parameter cannot be used with
the IFTRAIL parameter.
The report trailer consists of the elements
you select, in the order in which you specify them, and in the columns
or lines you specify. - c:
- See c: under HEADER1.
- r
- specifies that blanks, a character string, or a hexadecimal string
are to appear in the report record, or that a new report record is
to be started in the trailer, with or without intervening blank lines.
These report elements can be specified before or after any other report
elements. Consecutive report elements can be specified. Permissible
values are nX, n'xx...x', nC'xx...x', nX'yy...yy', /.../, and n/.
- nX
- Blanks. See nX under r for HEADER1.
- n'xx...x'
- Character string. See n'xx...x' under r for HEADER1. nC'xx...x'
can be used instead of n'xx...x'
- nX'xx...x'
- Hexadecimal string. See nX'xx...x' under r for HEADER1.
- /.../ or n/
- Blank lines or a new line. A new report record is to be started
in the trailer, with or without intervening blank lines. If /.../
or n/ is specified at the beginning or end of the trailer, n blank
lines are to appear in the trailer. If /.../ or n/ is specified in
the middle of the trailer, n-1 blank lines are to appear in the trailer
(thus, / or 1/ indicates a new line with no intervening blank lines).
Either
n/ (for example, 5/) or multiple /'s (for example, /////) can be used.
n can range from 1 to 255. If n is omitted, 1 is used.
- p,m
- specifies that an unedited input field, from the last OUTFIL input
record for which a data record appears in the report, is to appear
in the report record.
- p
- See p under HEADER1.
- m
- See m under HEADER1.
- DATE
- See DATE under HEADER1.
- &DATE
- can be used instead of DATE.
- DATE=(abcd)
- See DATE=(abcd) under HEADER1.
- &DATE=(abcd)
- can be used instead of DATE=(abcd).
- DATENS=(abc)
- See DATENS=(abc) under HEADER1.
- &DATENS=(abc)
- can be used instead of DATENS=(abc).
- YDDD=(abc)
- See YDDD=(abc) under HEADER1.
- &YDDD=(abc)
- can be used instead of YDDD=(abc).
- YDDDNS=(ab)
- See YDDDNS=(ab) under HEADER1.
- &YDDDNS=(ab)
- can be used instead of YDDDNS=(ab).
- TIME
- See TIME under HEADER1.
- &TIME
- can be used instead of TIME.
- TIME=(abc)
- See TIME=(abc) under HEADER1.
- &TIME=(abc)
- can be used instead of TIME=(abc).
- TIMENS=(ab)
- See TIMENS=(ab) under HEADER1.
- &TIMENS=(ab)
- can be used instead of TIMENS=(ab).
- PAGE
- specifies that the current page number is to appear in the report
record. The page number for the trailer appears as 6 digits, right-justified,
with leading zeros suppressed. For example, if the page is numbered
12, it appears as ' 12'.
- &PAGE
- can be used instead of PAGE.
- PAGE=(edit) or PAGE=(to)
- same as PAGE except that the 15-digit page number appears edited
or converted as specified. See p,m,f,edit under OUTREC for further
details on the edit fields you can use. See p,m,f,to under OUTREC
for further details on the to fields you can use.
- &PAGE=(edit) or &PAGE=(to)
- can be used instead of PAGE=(edit) or PAGE=(to).
- COUNT
- specifies that the count of data records in the report is to appear
in the report record as 8 digits, right-justified, with leading zeros
suppressed. For example, if there are 6810 input records in the report,
the count appears as ' 6810'.
If slash (/) is used in OUTREC
or BUILD to produce multiple data records, COUNT only counts the number
of data records processed as input to OUTREC or BUILD. For example,
if OUTREC processes 3 input records and creates 2 output records for
each input record, the count is 3, not 6
- COUNT15
- same as COUNT except that the count appears as 15 digits.
- COUNT=(edit) or COUNT=(to)
- same as COUNT except that the 15–digit count appears edited or
converted as specified. See p,m,f,edit under OUTREC for further details
on the edit fields you can use. See p,m,f,to under OUTREC for further
details on the to fields you can use. For example, if there are 6810
input records, COUNT=(M11,LENGTH=6) produces a count of '006810'.
- COUNT+n=(edit) or COUNT+n=(to)
- same as COUNT=(edit) or COUNT=(to) except that n is added to the
15-digit count before it is edited or converted. n can be 1 to 3
decimal digits. For example, if there are 6810 input records, COUNT+2=(M11,LENGTH=6)
produces a count of '006812'. One important use for this parameter
is to add 1 for the TRAILER1 record to the count of data records.
- COUNT-n=(edit) or COUNT-n=(to)
- same as COUNT=(edit) or COUNT=(to) except that n is subtracted
from the 15-digit count before it is edited or converted. n can be
1 to 3 decimal digits. For example, if there are 6810 input records,
COUNT-1=(M11,LENGTH=6) produces a count of '006809'. One important
use for this parameter is to subtract 1 for a header record from the
count of all records.
- SUBCOUNT
- specifies that the running count of input records in the report
is to appear in the report record as 8 digits, right-justified, with
leading zeros suppressed.
For TRAILER1, the running count is the
same as the count, so SUBCOUNT produces the same value as COUNT.
If
slash (/) is used in OUTREC or BUILD to produce multiple data records,
SUBCOUNT counts only the number of data records processed as input
to OUTREC or BUILD. For example, if OUTREC processes 3 input records
and creates 2 output records for each input record, the running count
is 3, not 6.
- SUBCOUNT15
- same as SUBCOUNT except that the running count appears as 15 digits.
- SUBCOUNT=(edit) or SUBCOUNT=(to)
- same as SUBCOUNT except that the 15–digit running count appears
edited or converted as specified. See p,m,f,edit under OUTREC for
further details on the edit fields you can use. See p,m,f,to under
OUTREC for further details on the to fields you can use.
- TOTAL
- specifies that an edited or converted total, for the values of
a numeric input field in all data records of the report, is to appear
in the report record.
TOT can be used instead of TOTAL. - p,m,f,edit or p,m,f,to
- specifies the numeric input field for which the total is to be
produced and how the output field (that is, the total) is to be edited
or converted.
See p,m,f,edit under OUTREC for further details.
However, note that PD0, DC1, DC2, DC3, DE1, DE2, DE3, DT1, DT2, DT3,
TC1, TC2, TC3, TC4, TE1, TE2, TE3, TE4, TM1, TM2, TM3, and TM4 are
not allowed for TOTAL and that for TOTAL, the default number of digits
(d) used for editing or conversion is as follows: Table 20. Digits for TOTAL FieldsDigits for TOTAL FieldsFormat (f)
|
Length (m) |
Digits (d) |
|---|
| ZD |
1-15 |
15 |
| ZD |
16-31 |
31 |
| PD |
1-8 |
15 |
| PD |
9-16 |
31 |
| BI |
1-4 |
10 |
| BI |
5-8 |
20 |
| FI |
1-4 |
10 |
| FI |
5-8 |
20 |
| FL |
4 or 8 |
20 |
| CSF or FS |
1-15 |
15 |
| CSF or FS |
16-32 |
31 |
| UFF |
1-15 |
15 |
| UFF |
16-44 |
31 |
| SFF |
1-15 |
15 |
| SFF |
16-44 |
31 |
If EDIT or EDxy is specified, the number of digits
in the pattern (I's and T's) is used.
- MIN
- specifies that an edited or converted minimum, for the values
of a numeric input field in all data records of the report, is to
appear in the report record.
- p,m,f,edit or p,m,f,to
- specifies the numeric input field for which the minimum is to
be produced and how the output field (that is, the minimum) is to
be edited or converted.
See p,m,f,edit or p,m,f,to under OUTREC
for further details. However, note that PD0, DC1, DC2, DC3, DE1,
DE2, DE3, DT1, DT2, DT3, TC1, TC2, TC3, TC4, TE1, TE2, TE3, TE4, TM1,
TM2, TM3 and TM4 are not allowed for MIN.
- MAX
- specifies that an edited or converted maximum, for the values
of a numeric input field in all data records of the report, is to
appear in the report record.
- p,m,f,edit or p,m,f,to
- specifies the numeric input field for which the maximum is to
be produced and how the output field (that is, the maximum) is to
be edited or converted.
See p,m,f,edit or p,m,f,to under OUTREC
for further details. However, note that PD0, DC1, DC2, DC3, DE1, DE2,
DE3, DT1, DT2, DT3, TC1, TC2, TC3, TC4, TE1, TE2, TE3, TE4, TM1, TM2,
TM3 and TM4 are not allowed for MAX.
- AVG
- specifies that an edited or converted average, for the values
of a numeric input field in all data records of the report, is to
appear in the report record. The average (or mean) is calculated by
dividing the total by the count and rounding down to the nearest integer.
For example:
+2305 / 152 = +15
-2305 / 152 = -15
- p,m,f,edit or p,m,f,to
- specifies the numeric input field for which the average is to
be produced and how the output field (that is, the average) is to
be edited or converted.
See p,m,f,edit or p,m,f,to under OUTREC
for further details. However, note that PD0, DC1, DC2, DC3, DE1,
DE2, DE3, DT1, DT2, DT3, TC1, TC2, TC3, TC4, TE1, TE2, TE3, TE4, TM1,
TM2, TM3 and TM4 are not allowed for AVG.
- SUBTOTAL
- specifies that an edited or converted running total, for the values
of a numeric input field in all data records of the report, is to
appear in the report record.
SUBTOT or SUB can be used instead
of SUBTOTAL.
For TRAILER1, the running total is the same as
the total, so SUBTOTAL produces the same value as TOTAL. - p,m,f,edit or p,m,f,to
- specifies the numeric input field for which the running total
is to be produced and how the output field (that is, the running total)
is to be edited or converted.
See p,m,f,edit or p,m,f,to under
TOTAL for further details.
- SUBMIN
- specifies that an edited or converted running minimum, for the
values of a numeric input field in all data records of the report,
is to appear in the report record.
For TRAILER1, the running minimum
is the same as the minimum, so SUBMIN produces the same value as MIN. - p,m,f,edit or p,m,f,to
- specifies the numeric input field for which the running minimum
is to be produced and how the output field (that is, the running minimum)
is to be edited or converted.
See p,m,f,edit or p,m,f,to under
OUTREC for further details. However, note that PD0, DC1, DC2, DC3,
DE1, DE2, DE3, DT1, DT2, DT3, TC1, TC2, TC3, TC4, TE1, TE2, TE3, TE4,
TM1, TM2, TM3 and TM4 are not allowed for SUBMIN.
- SUBMAX
- specifies that an edited or converted running maximum, for the
values of a numeric input field in all data records of the report,
is to appear in the report record.
For TRAILER1, the running maximum
is the same as the maximum, so SUBMAX produces the same value as MAX. - p,m,f,edit or p,m,f,to
- specifies the numeric input field for which the running maximum
is to be produced and how the output field (that is, the running maximum)
is to be edited or converted.
See p,m,f,edit or p,m,f,to under
OUTREC for further details. However, note that PD0, DC1, DC2, DC3,
DE1, DE2, DE3, DT1, DT2, DT3, TC1, TC2, TC3, TC4, TE1, TE2, TE3, TE4,
TM1, TM2, TM3 and TM4 are not allowed for SUBMAX.
- SUBAVG
- specifies that an edited or converted running average, for the
values of a numeric input field in all data records of the report,
is to appear in the report record.
For TRAILER1, the running average
is the same as the average, so SUBAVG produces the same value as AVG. - p,m,f,edit or p,m,f,to
- specifies the numeric input field for which the running average
is to be produced and how the output field (that is, the running average)
is to be edited or converted.
See p,m,f,edit or p,m,f,to under
OUTREC for further details. However, note that PD0, DC1, DC2, DC3,
DE1, DE2, DE3, DT1, DT2, DT3, TC1, TC2, TC3, TC4, TE1, TE2, TE3, TE4,
TM1, TM2, TM3 and TM4 are not allowed for SUBAVG.
Sample Syntax: OUTFIL FNAMES=RPT1,
TRAILER1=(5/,
10:'Summary of Report for Division Revenues',3/,
10:'Number of divisions reporting: ',COUNT,2/,
10:'Total revenue: ',TOTAL=(25,5,PD,M5),2/,
10:'Lowest revenue: ',MIN=(25,5,PD,M5),2/,
10:'Highest revenue: ',MAX=(25,5,PD,M5),2/,
10:'Average revenue: ',AVG=(25,5,PD,M5))
OUTFIL FNAMES=RPT2,BLKCCT1,
TRAILER1=(/,10:'Grand Total: ',TOTAL=(25,5,PD,M5))
Default
for TRAILER1: None; must be specified.
- HEADER2
.-,---------------------------------.
V |
>>-HEADER2=-(---+----+-+-r----------------------+-+-)----------><
'-c:-' +-p,m--------------------+
+-+-DATE----------+------+
| +-&DATE---------+ |
| +-DATE=(abcd)---+ |
| +-&DATE=(abcd)--+ |
| +-DATENS=(abc)--+ |
| +-&DATENS=(abc)-+ |
| +-YDDD=(abc)----+ |
| +-&YDDD=(abc)---+ |
| +-YDDDNS=(ab)---+ |
| '-&YDDDNS=(ab)--' |
+-+-TIME---------+-------+
| +-&TIME--------+ |
| +-TIME=(abc)---+ |
| +-&TIME=(abc)--+ |
| +-TIMENS=(ab)--+ |
| '-&TIMENS=(ab)-' |
'-+-PAGE---------------+-'
+-&PAGE--------------+
+-PAGE=(-+-edit-+-)--+
| '-to---' |
'-&PAGE=(-+-edit-+-)-'
'-to---'
Specifies the page header to be
used for the reports produced for this OUTFIL group. The page header
appears at the top of each page of the report, except for the report
header page (if any) and report trailer page (if any). DFSORT uses
ANSI carriage control characters to control page ejects and the placement
of the lines in your report, according to your specifications. You can use BLKCCH2 to replace the '1' (page eject) for
the ANSI carriage control character in the first line of the first
page header with a blank, thus avoiding forcing a page eject. You
can use REMOVECC to remove the ANSI carriage control characters from
a report.
You can choose to include any or all of the following
report elements in your page header: - Blanks, character strings, and hexadecimal strings
- Unedited input fields from the first OUTFIL input record for which
a data record appears on the page
- Current date in a variety of different forms
- Current time in a variety of different forms
- Page number, converted to different numeric formats, or edited
to contain signs, decimal points, leading zeros or no leading zeros,
and so on.
The HEADER2 parameter cannot be used with
the IFTRAIL parameter.
The page header consists of the elements
you select, in the order in which you specify them, and in the columns
or lines you specify. - c:
- See c: under HEADER1.
- r
- See r under HEADER1.
- p,m
- specifies that an unedited input field, from the first OUTFIL
input record for which a data record appears on the page, is to appear
in the report record. See p,m under HEADER1 for further details.
- DATE
- See DATE under HEADER1.
- &DATE
- can be used instead of DATE.
- DATE=(abcd)
- See DATE=(abcd) under HEADER1.
- &DATE=(abcd)
- can be used instead of DATE=(abcd).
- DATENS=(abc)
- See DATENS=(abc) under HEADER1.
- &DATENS=(abc)
- can be used instead of DATENS=(abc).
- YDDD=(abc)
- See YDDD=(abc) under HEADER1.
- &YDDD=(abc)
- can be used instead of YDDD=(abc).
- YDDDNS=(ab)
- See YDDDNS=(ab) under HEADER1.
- &YDDDNS=(ab)
- can be used instead of YDDDNS=(ab).
- TIME
- See TIME under HEADER1.
- &TIME
- can be used instead of TIME.
- TIME=(abc)
- See TIME=(abc) under HEADER1.
- &TIME=(abc)
- can be used instead of TIME=(abc).
- TIMENS=(ab)
- See TIMENS=(ab) under HEADER1.
- &TIMENS=(ab)
- can be used instead of TIMENS=(ab).
- PAGE
- specifies that the current page number is to appear in the OUTFIL
report record. The page number for the header appears as 6 digits,
right-justified, with leading zeros suppressed. For example, if the
page is numbered 3, it appears as ' 3'.
If HEADER1 is specified
with PAGE and HEADER2 is specified with PAGE, the page number for
the first page header will be ' 2'. If HEADER1 is not specified
or is specified without PAGE and HEADER2 is specified with PAGE, the
page number for the first page header will be ' 1'.
- &PAGE
- can be used instead of PAGE.
- PAGE=(edit) or PAGE=(to)
- same as PAGE except that the 15-digit page number appears edited
or converted as specified. See p,m,f,edit under OUTREC for further
details on the edit fields you can use. See p,m,f,to under OUTREC
for further details on the to fields you can use.
- &PAGE=(edit) or &PAGE=(to)
- can be used instead of PAGE=(edit) or PAGE=(to).
Sample Syntax: OUTFIL FNAMES=STATUS,
HEADER2=(5:'Page ',PAGE,' of Status Report for ',DATE=(MD4/),
' at ',TIME=(12:),2/,
10:'Item ',20:'Status ',35:'Count',/,
10:'-----',20:'------------',35:'-----'),
OUTREC=(10:6,5,
20:14,1,CHANGE=(12,
C'S',C'Ship',
C'H',C'Hold',
C'T',C'Transfer'),
NOMATCH=(C'*Check Code*'),
36:39,4,ZD,M10,
132:X)
Default for HEADER2: None;
must be specified.
- TRAILER2
.-,------------------------------------------------.
V |
>>-TRAILER2=-(---+----+-+-r-------------------------------------+-+-)-><
'-c:-' +-p,m-----------------------------------+
+-+-DATE----------+---------------------+
| +-&DATE---------+ |
| +-DATE=(abcd)---+ |
| +-&DATE=(abcd)--+ |
| +-DATENS=(abc)--+ |
| +-&DATENS=(abc)-+ |
| +-YDDD=(abc)----+ |
| +-&YDDD=(abc)---+ |
| +-YDDDNS=(ab)---+ |
| '-&YDDDNS=(ab)--' |
+-+-TIME---------+----------------------+
| +-&TIME--------+ |
| +-TIME=(abc)---+ |
| +-&TIME=(abc)--+ |
| +-TIMENS=(ab)--+ |
| '-&TIMENS=(ab)-' |
+-+-PAGE---------------+----------------+
| +-&PAGE--------------+ |
| +-PAGE=(-+-edit-+-)--+ |
| | '-to---' | |
| '-&PAGE=(-+-edit-+-)-' |
| '-to---' |
+---+-COUNT----------------+------------+
| +-COUNT15--------------+ |
| +-COUNT=(-+-edit-+-)---+ |
| | '-to---' | |
| +-COUNT+n=(-+-edit-+-)-+ |
| | '-to---' | |
| '-COUNT-n=(-+-edit-+-)-' |
| '-to---' |
+---+-SUBCOUNT--------------+-----------+
| +-SUBCOUNT15------------+ |
| '-SUBCOUNT=(-+-edit-+-)-' |
| '-to---' |
+-+-TOTAL=-+--(p,m,f-+-----------+-)----+
| '-TOT=---' '-+-,edit-+-' |
| '-,to---' |
+-MIN=--(p,m,f-+-----------+-)----------+
| '-+-,edit-+-' |
| '-,to---' |
+-MAX=--(p,m,f-+-----------+-)----------+
| '-+-,edit-+-' |
| '-,to---' |
+-AVG=--(p,m,f-+-----------+-)----------+
| '-+-,edit-+-' |
| '-,to---' |
+-+-SUBTOTAL=-+--(p,m,f-+-----------+-)-+
| +-SUBTOT=---+ '-+-,edit-+-' |
| '-SUB=------' '-,to---' |
+-SUBMIN=--(p,m,f-+-----------+-)-------+
| '-+-,edit-+-' |
| '-,to---' |
+-SUBMAX=--(p,m,f-+-----------+-)-------+
| '-+-,edit-+-' |
| '-,to---' |
'-SUBAVG=--(p,m,f-+-----------+-)-------'
'-+-,edit-+-'
'-,to---'
Specifies the page trailer to
be used for the reports produced for this OUTFIL group. The page trailer
appears at the very bottom of each page of the report (as specified
or defaulted by the LINES value), except for the report header page
(if any) and report trailer page (if any). DFSORT uses ANSI carriage
control characters to control page ejects and the placement of the
lines in your report, according to your specifications.
You
can choose to include any or all of the following report elements
in your page trailer: - Blanks, character strings, and hexadecimal strings
- Unedited input fields from the last OUTFIL input record for which
a data record appears on the page
- Current date in a variety of different forms
- Current time in a variety of different forms
- Page number, converted to different numeric formats, or edited
to contain signs, decimal points, leading zeros or no leading zeros,
and so on
- Any or all of the following statistics:
- Count of data records on the page, converted to different numeric
formats, or edited to contain signs, decimal points, leading zeros
or no leading zeros, and so on. You can add a decimal number to the
count before converting or editing it (for example, add 1 to account
for writing a trailer record, or add 2 to account for writing a header
and trailer record).
- Total, minimum, maximum, or average for each specified ZD, PD,
BI, FI, FL, CSF, FS, UFF, or SFF numeric input
field in the data records on the page, converted to different numeric
formats, or edited to contain signs, decimal points, leading zeros
or no leading zeros, and so on.
- Running total, minimum, maximum, or average for each specified
ZD, PD, BI, FI, FL, CSF, FS, UFF, or SFF numeric
input field in the data records up to this point, converted to different
numeric formats, or edited to contain signs, decimal points, leading
zeros or no leading zeros, and so on.
The TRAILER2 parameter cannot be used with
the IFTRAIL parameter.
The page trailer consists of the elements
you select, in the order in which you specify them, and in the columns
or lines you specify. - c:
- See c: under HEADER1.
- r
- See r under TRAILER1.
- p,m
- specifies that an unedited input field, from the last OUTFIL input
record for which a data record appears on the page, is to appear in
the report record. See p,m under TRAILER1 for further details.
- DATE
- See DATE under HEADER1.
- &DATE
- can be used instead of DATE.
- DATE=(abcd)
- See DATE=(abcd) under HEADER1.
- &DATE=(abcd)
- can be used instead of DATE=(abcd).
- DATENS=(abc)
- See DATENS=(abc) under HEADER1.
- &DATENS=(abc)
- can be used instead of DATENS=(abc).
- YDDD=(abc)
- See YDDD=(abc) under HEADER1.
- &YDDD=(abc)
- can be used instead of YDDD=(abc).
- YDDDNS=(ab)
- See YDDDNS=(ab) under HEADER1.
- &YDDDNS=(ab)
- can be used instead of YDDDNS=(ab).
- TIME
- See TIME under HEADER1.
- &TIME
- can be used instead of TIME.
- TIME=(abc)
- See TIME=(abc) under HEADER1.
- &TIME=(abc)
- can be used instead of TIME=(abc).
- TIMENS=(ab)
- See TIMENS=(ab) under HEADER1.
- &TIMENS=(ab)
- can be used instead of TIMENS=(ab).
- PAGE
- See PAGE under TRAILER1.
- &PAGE
- can be used instead of PAGE.
- PAGE=(edit) or PAGE=(to)
- See PAGE=(edit) or PAGE=(to) under TRAILER1.
- &PAGE=(edit) or &PAGE=(to)
- can be used instead of PAGE=(edit) or PAGE=(to).
- COUNT
- specifies that the count of data records on the page is to appear
in the report record as 8 digits, right-justified, with leading zeros
suppressed. For example, if page 1 has 40 input records, page 2 has
40 input records, and page 3 has 26 input records, COUNT will show
' 40' for page 1, ' 40' for page 2, and ' 26' for
page 3.
If slash (/) is used in OUTREC or BUILD to produce multiple
data records, COUNT counts only the number of data records processed
as input to OUTREC or BUILD. For example, if OUTREC processes 3 input
records and creates 2 output records for each input record, the count
is 3, not 6.
- COUNT15
- same as COUNT except that the count appears as 15 digits.
- COUNT=(edit) or COUNT=(to)
- same as COUNT except that the 15–digit count appears edited or
converted as specified. See p,m,f,edit under OUTREC for further details
on the edit fields you can use. See p,m,f,to under OUTREC for further
details on the to fields you can use.
- COUNT+n=(edit) or COUNT+n=(to)
- same as COUNT=(edit) or COUNT=(to) except that n is added to the
15-digit count before it is edited or converted. n can be 1 to 3
decimal digits.
- COUNT-n=(edit) or COUNT-n=(to)
- same as COUNT=(edit) or COUNT=(to) except that n is subtracted
from the 15-digit count before it is edited or converted. n can be
1 to 3 decimal digits.
- SUBCOUNT
- specifies that the count of input records up to this point in
the report is to appear in the report record as 8 digits, right-justified,
with leading zeros suppressed. The running count accumulates the count
for all pages up to and including the current page. For example, if
page 1 has 40 input records, page 2 has 40 input records, and page
3 has 26 input records, SUBCOUNT will show ' 40' for page 1,
' 80' for page 2, and ' 106' for page 3.
If slash (/)
is used in OUTREC or BUILD to produce multiple data records, SUBCOUNT
counts only the number of data records processed as input to OUTREC
or BUILD. For example, if OUTREC processes 3 input records and creates
2 output records for each input record, the running count is 3, not
6.
- SUBCOUNT15
- same as SUBCOUNT except that the running count appears as 15 digits.
- SUBCOUNT=(edit) or SUBCOUNT=(to)
- same as SUBCOUNT except that the 15–digit running count appears
edited or converted as specified. See p,m,f,edit under OUTREC for
further details on the edit fields you can use. See p,m,f,to under
OUTREC for further details on the to fields you can use.
- TOTAL
- specifies that an edited or converted total, for the values of
a numeric input field in the data records on the page, is to appear
in the report record.
TOT can be used instead of TOTAL.
- p,m,f,edit or p,m,f,to
- See p,m,f,edit or p,m,f,to under TOTAL for TRAILER1.
- MIN
- specifies that an edited or converted minimum, for the values
of a numeric input field in the data records on the page, is to appear
in the report record.
- p,m,f,edit or p,m,f,to
- See p,m,f,edit or p,m,f,to under MIN for TRAILER1.
- MAX
- specifies that an edited or converted maximum, for the values
of a numeric input field in the data records on the page, is to appear
in the report record.
- p,m,f,edit or p,m,f,to
- See p,m,f,edit or p,m,f,to under MAX for TRAILER1.
- AVG
- specifies that an edited or converted average, for the values
of a numeric input field in the data records on the page, is to appear
in the report record.
- p,m,f,edit or p,m,f,to
- See p,m,f,edit or p,m,f,to under AVG for TRAILER1.
- SUBTOTAL
- specifies that an edited or converted running total, for the values
of a numeric input field in the data records up to this point in the
report, is to appear in the report record. The running total accumulates
the total for all pages up to and including the current page. For
example, if the total for a selected numeric field is +200 for page
1, -250 for page 2, and +90 for page 3, SUBTOTAL will be +200 for
page 1, -50 for page 2, and +40 for page 3.
SUBTOT or SUB can be
used instead of SUBTOTAL. - p,m,f,edit or p,m,f,to
- See p,m,f,edit or p,m,f,to under SUBTOTAL for TRAILER1.
- SUBMIN
- specifies that an edited or converted running minimum, for the
values of a numeric input field in the data records up to this point
in the report, is to appear in the report record. The running minimum
selects the minimum from all pages up to and including the current
page. For example, if the minimum for a selected numeric field is
+200 for page 1, -250 for page 2, and +90 for page 3, SUBMIN will
be +200 for page 1, -250 for page 2, and -250 for page 3.
- p,m,f,edit or p,m,f,to
- See p,m,f,edit or p,m,f,to under SUBMIN for TRAILER1.
- SUBMAX
- specifies that an edited or converted running maximum, for the
values of a numeric input field in the data records up to this point
in the report, is to appear in the report record. The running maximum
selects the maximum from all pages up to and including the current
page. For example, if the maximum for a selected numeric field is
-100 for page 1, +250 for page 2, and +90 for page 3, SUBMAX will
be -100 for page 1, +250 for page 2, and +250 for page 3.
- p,m,f,edit or p,m,f,to
- See p,m,f,edit or p,m,f,to under SUBMAX for TRAILER1.
- SUBAVG
- specifies that an edited or converted running average, for the
values of a numeric input field in the data records up to this point
in the report, is to appear in the report record. The running average
computes the average for all pages up to and including the current
page. For example, if the count of data records and total for a selected
numeric field are 60 and +2205 for page 1, respectively, 60 and -6252
for page 2, respectively, and 23 and -320 for page 3, respectively,
SUBAVG will be +36 for page 1, -33 for page 2, and -30 for page 3.
- p,m,f,edit or p,m,f,to
- See p,m,f,edit or p,m,f,to under SUBAVG for TRAILER1.
Sample Syntax: OUTFIL FNAMES=STATS,
STARTREC=3,
OUTREC=(20:23,3,PD,M16,
30:40,3,PD,M16,
80:X),
TRAILER2=(/,2:'Average on page:',
20:AVG=(23,3,PD,M16),
30:AVG=(40,3,PD,M16),/,
2:'Average so far:',
20:SUBAVG=(23,3,PD,M16),
30:SUBAVG=(40,3,PD,M16))
Default
for TRAILER2: None; must be specified.
- SECTIONS
>>-SECTIONS=---------------------------------------------------->
.-,------------------------------------------------.
| .-,----------------------------------------. |
V V | |
>--(---p,m---+--------------------------------------+-+-+-)----><
+-SKIP=-+-P--+-------------------------+
| +-L--+ |
| '-nL-' |
| .-,-----. |
| V | |
+-HEADER3=-(---field-+-)-+-----------+-+
| '-,PAGEHEAD-' |
| .-,-----. |
| V | |
'-TRAILER3=-(---field-+-)--------------'
Specifies the section break processing to be used
for the reports produced for this OUTFIL group. A section break field
divides the report into sets of sequential OUTFIL input records with
the same binary value for that field, which result in corresponding
sets of data records (that is, sections) in the report. A break is
said to occur when the binary value changes. Of course, because a
break can occur in any record, the data records of a section can be
split across pages in your report.
For each section break field
you specify, you can choose to include any or all of the following: - A page eject between sections.
- Zero, one or more blank lines to appear between sections on the
same page.
- A section header to appear before the first data record of each
section and optionally, at the top of each page. When a page header
and section header are both to appear at the top of a page, the section
header will follow the page header.
- A section trailer to appear after the last data record of each
section. When a page trailer and section trailer are both to appear
at the bottom of a page, the page trailer will follow the section
trailer.
The SECTIONS parameter cannot be used with the IFTRAIL
parameter.
DFSORT uses ANSI carriage control characters to control
page ejects and the placement of the lines in your report, according
to your specifications.
If multiple section break fields are
used, they are processed in first-to-last order, in the same way they
would be sorted by these fields. In fact, the input data set is generally
sorted by the section break fields, to group the records with the
same section break values together for the report. This sorting can
be done by the same application that produces the report or by a previous
application.
A break in section break field 1 results in a break
in section break fields 2 through n. A break in section break 2 results
in a break in section break fields 3 through n, and so on. The section
headers appear before each section in first-to-last order, whereas
the section trailers appear in last-to-first order. For example,
if section break fields represented by B1 with header H3A and trailer
T3A, B2 with header H3B and trailer T3B, and B3 with header H3C and
trailer T3C are specified in order, the following can appear: H3A (header for B1=1 section)
H3B (header for B2=1 section)
H3C (header for B3=1 section)
data records for B1=1, B2=1, B3=1 (new B1, B2, and B3 section)
T3C (trailer for B3=1 section)
H3C (header for B3=2 section)
data records for B1=1, B2=1, B3=2 (new B3 section)
T3C (trailer for B3=2 section)
T3B (trailer for B2=1 section)
H3B (header for B2=2 section)
H3C (header for B3=1 section)
data records for B1=1, B2=2, B3=1 (new B2 and B3 section)
T3C (trailer for B3=1 section)
T3B (trailer for B2=2 section)
T3A (trailer for B1=1 section)
H3A (header for B1=2 section)
H3B (header for B2=2 section)
H3C (header for B3=0 section)
data records for B1=2, B2=2, B3=0 (new B1, B2, and B3 section)
T3C (trailer for B3=0 section)
H3C (header for B3=1 section)
data records for B1=2, B2=2, B3=1 (new B3 section)
T3C (trailer for B3=1 section)
T3B (trailer for B2=2 section)
T3A (trailer for B1=2 section)
- p,m
- specifies a section break field in the OUTFIL input records to
be used to divide the report into sections. Each set of sequential
OUTFIL input records, with the same binary value for the section break
field, results in a corresponding set of data records. Each such
set of data records is treated as a section in the report. A break
is said to occur when the binary value changes.
- p
- specifies the first byte of the input field relative
to the beginning of the OUTFIL input record. The first data byte of
a fixed-length record has relative position 1. The first data byte
of a variable-length record has relative position 5, because the first
four bytes are occupied by the RDW. All fields must start on a byte
boundary, and no field can extend beyond byte 32752. See OUTFIL statements notes for special rules concerning variable-length
records.
- m
- specifies the length in bytes of the input field.
The value for m must be between 1 and 256.
You can specify any, all or none
of SKIP, HEADER3 and TRAILER3 after p,m. If you do not specify SKIP,
HEADER3 or TRAILER3 after p,m, SKIP=0L is used as the default.
- SKIP
>>-SKIP=-+-P--+------------------------------------------------><
+-L--+
'-nL-'
Specifies, for reports produced for this OUTFIL
group, that either:
- Each section for the associated section break field is to appear
on a new page, or
- Zero, one or more blank lines to appear after each section associated
with this section break field, when it is followed by another section
on the same page.
Thus, you can use SKIP to specify how sections will be separated
from each other. - P
- specifies that each section is to appear on a new page.
- L
- specifies that one blank line is to appear between sections on
the same page. L is the same as 1L.
- nL
- specifies that n blank lines are to appear between sections on
the same page. You can specify from 0 to 255 for n.
Sample Syntax: OUTFIL FNAMES=(PRINT,TAPE),
SECTIONS=(10,20,SKIP=P,
42,10,SKIP=3L)
- HEADER3
.-,---------------------------------.
V |
>>-HEADER3=-(---+----+-+-r----------------------+-+-)----------><
'-c:-' +-p,m--------------------+
+-+-DATE----------+------+
| +-&DATE---------+ |
| +-DATE=(abcd)---+ |
| +-&DATE=(abcd)--+ |
| +-DATENS=(abc)--+ |
| +-&DATENS=(abc)-+ |
| +-YDDD=(abc)----+ |
| +-&YDDD=(abc)---+ |
| +-YDDDNS=(ab)---+ |
| '-&YDDDNS=(ab)--' |
+-+-TIME---------+-------+
| +-&TIME--------+ |
| +-TIME=(abc)---+ |
| +-&TIME=(abc)--+ |
| +-TIMENS=(ab)--+ |
| '-&TIMENS=(ab)-' |
'-+-PAGE---------------+-'
+-&PAGE--------------+
+-PAGE=(-+-edit-+-)--+
| '-to---' |
'-&PAGE=(-+-edit-+-)-'
'-to---'
Specifies the section header to be used with the
associated section break field for the reports produced for this OUTFIL
group. The section header appears before the first data record of
each section. DFSORT uses ANSI carriage control characters to control
page ejects and the placement of the lines in your report, according
to your specifications.
You can choose to include
any or all of the following report elements in your section header: - Blanks, character strings, and hexadecimal strings
- Unedited input fields from the first OUTFIL input record for which
a data record appears in the section
- Current date in a variety of different forms
- Current time in a variety of different forms
- Page number, converted to different numeric formats, or edited
to contain signs, decimal points, leading zeros or no leading zeros,
and so on.
The section header consists of the elements you select,
in the order in which you specify them, and in the columns or lines
you specify. - c:
- See c: under HEADER1.
- r
- See r under HEADER1.
- p,m
- specifies that an unedited input field, from the first OUTFIL
input record for which a data record appears in the section, is to
appear in the report record. See p,m under HEADER1 for further details.
- DATE
- See DATE under HEADER1.
- &DATE
- can be used instead of DATE.
- DATE=(abcd)
- See DATE=(abcd) under HEADER1.
- &DATE=(abcd)
- can be used instead of DATE=(abcd).
- DATENS=(abc)
- See DATENS=(abc) under HEADER1.
- &DATENS=(abc)
- can be used instead of DATENS=(abc).
- YDDD=(abc)
- See YDDD=(abc) under HEADER1.
- &YDDD=(abc)
- can be used instead of YDDD=(abc).
- YDDDNS=(ab)
- See YDDDNS=(ab) under HEADER1.
- &YDDDNS=(ab)
- can be used instead of YDDD=(ab).
- TIME
- See TIME under HEADER1.
- &TIME
- can be used instead of TIME.
- TIME=(abc)
- See TIME=(abc) under HEADER1.
- &TIME=(abc)
- can be used instead of TIME=(abc).
- TIMENS=(ab)
- See TIMENS=(ab) under HEADER1.
- &TIMENS=(ab)
- can be used instead of TIMENS=(ab).
- PAGE
- specifies that the current page number is to appear in the OUTFIL
report record. The page number for the header appears as 6 digits,
right-justified, with leading zeros suppressed. For example, if the
page is numbered 3, it appears as ' 3'.
- &PAGE
- can be used instead of PAGE.
- PAGE=(edit) or PAGE=(to)
- same as PAGE except that the 15-digit page number appears edited
or converted as specified. See p,m,f,edit under OUTREC for further
details on the edit fields you can use. See p,m,f,to under OUTREC
for further details on the to fields you can use.
- &PAGE=(edit) or &PAGE=(to)
- can be used instead of PAGE=(edit) or PAGE=(to).
Sample Syntax: OUTFIL FNAMES=STATUS1,
HEADER2=(10:'Status Report for all departments',5X,
'- ',&PAGE,' -'),
SECTIONS=(10,8,
HEADER3=(2/,10:'Report for department ',10,8,' on ',&DATE,2/,
10:' Number',25:'Average Time',/,
10:'Completed',25:' (in days)',/,
10:'---------',25:'------------')),
OUTREC=(10:21,5,ZD,M10,LENGTH=9,
25:38,4,ZD,EDIT=(III.T),LENGTH=12,
132:X)
- PAGEHEAD
>>-PAGEHEAD----------------------------------------------------><
Specifies that the section header to be used with
the associated section break field is to appear at the top of each
page of the report, except for the report header page (if any) and
report trailer page (if any), as well as before each section. If you
do not specify PAGEHEAD, the section header appears only before each
section; so if a section is split between pages, the section header
appears only in the middle of the page. PAGEHEAD can be used when
you want HEADER3 to be used as a page header as well as a section
header.
If PAGEHEAD is specified for a section break field
for which HEADER3 is not also specified, PAGEHEAD will not be used.
Sample
Syntax: OUTFIL FNAMES=STATUS2,
HEADER2=(10:'Status Report for all departments',5X,
'- ',&PAGE,' -'),
SECTIONS=(10,8,
HEADER3=(2/,10:'Report for department ',10,8,' on ',&DATE,2/,
10:' Number',25:'Average Time',/,
10:'Completed',25:' (in days)',/,
10:'---------',25:'------------'),
PAGEHEAD,SKIP=P),
OUTREC=(10:21,5,ZD,M10,LENGTH=9,
25:38,4,ZD,EDIT=(III.T),LENGTH=12,
132:X)
- TRAILER3
.-,------------------------------------------------.
V |
>>-TRAILER3=-(---+----+-+-r-------------------------------------+-+-)-><
'-c:-' +-p,m-----------------------------------+
+-+-DATE----------+---------------------+
| +-&DATE---------+ |
| +-DATE=(abcd)---+ |
| +-&DATE=(abcd)--+ |
| +-DATENS=(abc)--+ |
| +-&DATENS=(abc)-+ |
| +-YDDD=(abc)----+ |
| +-&YDDD=(abc)---+ |
| +-YDDDNS=(ab)---+ |
| '-&YDDDNS=(ab)--' |
+-+-TIME---------+----------------------+
| +-&TIME--------+ |
| +-TIME=(abc)---+ |
| +-&TIME=(abc)--+ |
| +-TIMENS=(ab)--+ |
| '-&TIMENS=(ab)-' |
+-+-PAGE---------------+----------------+
| +-&PAGE--------------+ |
| +-PAGE=(-+-edit-+-)--+ |
| | '-to---' | |
| '-&PAGE=(-+-edit-+-)-' |
| '-to---' |
+---+-COUNT----------------+------------+
| +-COUNT15--------------+ |
| +-COUNT=(-+-edit-+-)---+ |
| | '-to---' | |
| +-COUNT+n=(-+-edit-+-)-+ |
| | '-to---' | |
| '-COUNT-n=(-+-edit-+-)-' |
| '-to---' |
+---+-SUBCOUNT--------------+-----------+
| +-SUBCOUNT15------------+ |
| '-SUBCOUNT=(-+-edit-+-)-' |
| '-to---' |
+-+-TOTAL=-+--(p,m,f-+-----------+-)----+
| '-TOT=---' '-+-,edit-+-' |
| '-,to---' |
+-MIN=--(p,m,f-+-----------+-)----------+
| '-+-,edit-+-' |
| '-,to---' |
+-MAX=--(p,m,f-+-----------+-)----------+
| '-+-,edit-+-' |
| '-,to---' |
+-AVG=--(p,m,f-+-----------+-)----------+
| '-+-,edit-+-' |
| '-,to---' |
+-+-SUBTOTAL=-+--(p,m,f-+-----------+-)-+
| +-SUBTOT=---+ '-+-,edit-+-' |
| '-SUB=------' '-,to---' |
+-SUBMIN=--(p,m,f-+-----------+-)-------+
| '-+-,edit-+-' |
| '-,to---' |
+-SUBMAX=--(p,m,f-+-----------+-)-------+
| '-+-,edit-+-' |
| '-,to---' |
'-SUBAVG=--(p,m,f-+-----------+-)-------'
'-+-,edit-+-'
'-,to---'
Specifies the section trailer to be used with the
associated section break field for the reports produced for this OUTFIL
group. The section trailer appears after the last data record of each
section. DFSORT uses ANSI carriage control characters to control page
ejects and the placement of the lines in your report, according to
your specifications.
You can choose to include
any or all of the following report elements in your section trailer: - Blanks, character strings, and hexadecimal strings
- Unedited input fields from the last OUTFIL input record for which
a data record appears in the section
- Current date in a variety of different forms
- Current time in a variety of different forms
- Page number, converted to different numeric formats, or edited
to contain signs, decimal points, leading zeros or no leading zeros,
and so on
- Any or all of the following statistics:
- Count of data records in the section, converted to different numeric
formats, or edited to contain signs, decimal points, leading zeros
or no leading zeros, and so on. You can add a decimal number to the
count before converting or editing it (for example, add 1 to account
for writing a trailer record, or add 2 to account for writing a header
and trailer record).
- Total, minimum, maximum, or average for each specified ZD, PD,
BI, FI, FL, CSF, FS, UFF, or SFF numeric input
field in the data records in the section, converted to different numeric
formats, or edited to contain signs, decimal points, leading zeros
or no leading zeros, and so on
- Running total, minimum, maximum, or average for each specified
ZD, PD, BI, FI, FL, CSF, FS, UFF, or SFF numeric
input field in the data records up to this point, converted to different
numeric formats, or edited to contain signs, decimal points, leading
zeros or no leading zeros, and so on.
The section trailer consists of the elements you select,
in the order in which you specify them, and in the columns or lines
you specify.
- c:
- See c: under HEADER1.
- r
- See r under TRAILER1.
- p,m
- specifies that an unedited input field, from the last OUTFIL input
record for which a data record appears in the section, is to appear
in the report record. See p,m under TRAILER1 for further details.
- DATE
- See DATE under HEADER1.
- &DATE
- can be used instead of DATE.
- DATE=(abcd)
- See DATE=(abcd) under HEADER1.
- &DATE=(abcd)
- can be used instead of DATE=(abcd).
- DATENS=(abc)
- See DATENS=(abc) under HEADER1.
- &DATENS=(abc)
- can be used instead of DATENS=(abc).
- YDDD=(abc)
- See YDDD=(abc) under HEADER1.
- &YDDD=(abc)
- can be used instead of YDDD=(abc).
- YDDDNS=(ab)
- See YDDDNS=(ab) under HEADER1.
- &YDDDNS=(ab)
- can be used instead of YDDDNS=(ab).
- TIME
- See TIME under HEADER1.
- &TIME
- can be used instead of TIME.
- TIME=(abc)
- See TIME=(abc) under HEADER1.
- &TIME=(abc)
- can be used instead of TIME=(abc).
- TIMENS=(ab)
- See TIMENS=(ab) under HEADER1.
- &TIMENS=(ab)
- can be used instead of TIMENS=(ab).
- PAGE
- See PAGE under TRAILER1.
- &PAGE
- can be used instead of PAGE.
- PAGE=(edit) or PAGE=(to)
- See PAGE=(edit) or PAGE=(to) under TRAILER1.
- &PAGE=(edit) or &PAGE=(to)
- can be used instead of PAGE=(edit) or PAGE=(to).
- COUNT
- specifies that the count of data records in the section is to
appear in the report record as 8 digits, right-justified, with leading
zeros suppressed. For example, if the first section has 40 input records,
the second section has 40 input records, and the third section has
26 input records, COUNT will show ' 40' for the first section,
' 40' for the second section, and ' 26' for the third section.
If
slash (/) is used in OUTREC or BUILD to produce multiple data records,
COUNT counts only the number of data records processed as input to
OUTREC or BUILD. For example, if OUTREC or BUILD processes 3 input
records and creates 2 output records for each input record, the count
is 3, not 6.
- COUNT15
- same as COUNT except that the count appears as 15 digits.
- COUNT=(edit) or COUNT=(to)
- same as COUNT except that the 15–digit count appears edited or
converted as specified. See p,m,f,edit under OUTREC for further details
on the edit fields you can use. See p,m,f,to under OUTREC for further
details on the to fields you can use.
- COUNT+n=(edit) or COUNT+n=(to)
- same as COUNT=(edit) or COUNT=(to) except that n is added to the
15-digit count before it is edited or converted. n can be 1 to 3
decimal digits.
- COUNT-n=(edit) or COUNT-n=(to)
- same as COUNT=(edit) or COUNT=(to) except that n is subtracted
from the 15-digit count before it is edited or converted. n can be
1 to 3 decimal digits.
- SUBCOUNT
- specifies that the running count of input records up to this point
in the report is to appear in the report record 8 digits, right-justified,
with leading zeros suppressed. The running count accumulates the count
for all sections up to and including the current section. For example,
if the first section has 40 input records, the second section has
40 input records, and the third section has 26 input records, SUBCOUNT
will show ' 40' for the first section, ' 80' for the second
section, and ' 106' for the third section.
If slash (/) is
used in OUTREC or BUILD to produce multiple data records, SUBCOUNT
counts only the number of data records processed as input to OUTREC
or BUILD. For example, if OUTREC or BUILD processes 3 input records
and creates 2 output records for each input record, the running count
is 3, not 6
- SUBCOUNT15
- same as SUBCOUNT except that the running count appears as 15 digits.
- SUBCOUNT=(edit) or SUBCOUNT=(to)
- same as SUBCOUNT except that the 15–digit running count appears
edited or converted as specified. See p,m,f,edit under OUTREC for
further details on the edit fields you can use. See p,m,f,to under
OUTREC for further details on the to fields you can use.
- TOTAL
- specifies that an edited or converted total, for the values of
a numeric input field in the data records in the section, is to appear
in the report record.
TOT can be used instead of TOTAL. - p,m,f,edit or p,m,f,to
- See p,m,f,edit or p,m,f,to under TOTAL for TRAILER1.
- MIN
- specifies that an edited or converted minimum, for the values
of a numeric input field in the data records in the section, is to
appear in the report record.
- p,m,f,edit or p,m,f,to
- See p,m,f,edit or p,m,f,tounder MIN for TRAILER1.
- MAX
- specifies that an edited or converted maximum, for the values
of a numeric input field in the data records in the section, is to
appear in the report record.
- p,m,f,edit or p,m,f,to
- See p,m,f,edit or p,m,f,to under MAX for TRAILER1.
- AVG
- specifies that an edited or converted average, for the values
of a numeric input field in the data records in the section, is to
appear in the report record.
- p,m,f,edit or p,m,f,to
- See p,m,f,edit or p,m,f,to under AVG for TRAILER1.
- SUBTOTAL
- specifies that an edited or converted running total, for the values
of a numeric input field in the data records up to this point in the
report, is to appear in the report record. The running total accumulates
the total for all sections up to and including the current section.
For example, if the total for a selected numeric field is +200 for
the first section, -250 for the second section and +90 for the third
section, SUBTOTAL will be +200 for the first section, -50 for the
second section and +40 for the third section.
SUBTOT or SUB can
be used instead of SUBTOTAL. - p,m,f,edit or p,m,f,to
- See p,m,f,edit or p,m,f,to under SUBTOTAL for TRAILER1.
- SUBMIN
- specifies that an edited or converted running minimum, for the
values of a numeric input field in the data records up to this point
in the report, is to appear in the report record. The running minimum
selects the minimum from all sections up to and including the current
section. For example, if the minimum for a selected numeric field
is +200 for the first section, -250 for the second section and +90
for the third section, SUBMIN will be +200 for the first section,
-250 for the second section and -250 for the third section.
- p,m,f,edit or p,m,f,to
- See p,m,f,edit or p,m,f,to under SUBMIN for TRAILER1.
- SUBMAX
- specifies that an edited or converted running maximum, for the
values of a numeric input field in the data records up to this point
in the report, is to appear in the report record. The running maximum
selects the maximum from all sections up to and including the current
section. For example, if the maximum for a selected numeric field
is -100 for the first section, +250 for the second section and +90
for the third section, SUBMAX will be -100 for the first section,
+250 for the second section and +250 for the third section.
- p,m,f,edit or p,m,f,to
- See p,m,f,edit or p,m,f,to under SUBMAX for TRAILER1.
- SUBAVG
- specifies that an edited or converted running average, for the
values of a numeric input field in the data records up to this point
in the report, is to appear in the report record. The running average
computes the average for all sections up to and including the current
section. For example, if the count of data records and total for
a selected numeric field are 60 and +2205 for the first section, respectively,
60 and -6252 for the second section, respectively, and 23 and -320
for the third section, respectively, SUBAVG will be +36 for the first
section, -33 for the second section and -30 for the third section.
- p,m,f,edit or p,m,f,to
- See p,m,f,edit or p,m,f,to under SUBAVG for TRAILER1.
Sample Syntax: OUTFIL FNAMES=SECRPT,
INCLUDE=(11,4,CH,EQ,C'SSD'),
SECTIONS=(3,5,SKIP=P,
HEADER3=(2:'Department: ',3,5,4X,'Date: ',&DATE,2/),
TRAILER3=(2/,2:'The average for ',3,5,' is ',
AVG=(40,3,PD,M12),/,
2:'The overall average so far is ',
SUBAVG=(40,3,PD,M12)),
45,8,SKIP=3L,
HEADER3=(4:'Week Ending ',45,8,2/,
4:'Item Number',20:'Completed',/,
4:'-',20:'-'),
TRAILER3=(4:'The item count for week ending ',45,8,
' is ',COUNT=(EDIT=(II,IIT)))),
OUTREC=(11:16,4,22:40,3,PD,M12,120:X)
Default
for SECTIONS: None; must be specified.
- NODETAIL
>>-NODETAIL----------------------------------------------------><
Specifies that data records are not to be output
for the reports produced for this OUTFIL group. With NODETAIL, the
data records are completely processed with respect to input fields,
statistics, counts, sections breaks, and so on, but are not written
to the OUTFIL data set and are not included in line counts for determining
the end of a page. You can use NODETAIL to summarize the data records
without actually showing them.
The NODETAIL parameter
cannot be used with the IFTRAIL parameter.
Sample Syntax: OUTFIL FNAMES=SUMMARY,NODETAIL,
HEADER2=(' Date: ',DATENS=(DMY.),4X,'Page: ',PAGE,2/,
10:'Division',25:' Total Revenue',/,
10:'--------',25:'-----------------'),
SECTIONS=(3,5,
TRAILER3=(10:3,5,
25:TOTAL=(25,4,FI,M19,
LENGTH=17))),
TRAILER1=(5/,10:'Summary of Revenue ',4/,
12:'Number of divisions reporting is ',
COUNT,/,
12:'Total revenue is ',
TOTAL=(25,4,FI,M19))
Default
for NODETAIL: None; must be specified.
Default for OUTFIL
Statements: None; must be specified. Multiple OUTFIL statements
can be specified in the same and different sources; override is at
the ddname level.
Applicable Functions for OUTFIL Statements:
Sort, merge, and copy.
- BLKCCH1
- specifies that the ANSI carriage control character of '1' (page
eject) in the first line of the report header (HEADER1) is to be
replaced with a blank. You can use BLKCCH1 to avoid forcing a page
eject at the start of the report header. If BLKCCH1 is specified without
HEADER1, it will not be used.
Sample Syntax:
OUTFIL FNAMES=RPT1,BLKCCH1,
HEADER1=(30:'January Report',4/)
Default
for BLKCCH1: None; must be specified.
- BLKCCH2
- specifies that the ANSI carriage control character of '1' (page
eject) in the first line of the first page header (HEADER2) is to
replaced with a blank. You can use BLKCCH2 to avoid forcing a page
eject at the start of the first page header. BLKCHH2 does not prevent
a page eject for the second and subsequent page headers. If BLKCCH2
is specified without HEADER2, it will not be used.
Sample
Syntax:
OUTFIL FNAMES=RPT2,
* Do page eject for HEADER1, but not for first HEADER2.
HEADER1=(30:'January Report',2/),
BLKCCH2,HEADER2=(5:'Account Number',25:'Name')
Default
for BLKCCH2: None; must be specified.
- BLKCCT1
- specifies that the ANSI carriage control character of '1' (page
eject) in the first line of the report trailer (TRAILER1) is to be
replaced with a blank. You can use BLKCCT1 to avoid forcing a page
eject at the start of the report trailer. If BLKCCT1 is specified
without TRAILER1, it will not be used.
Sample Syntax:
OUTFIL FNAMES=RPT3,BLKCCT1
, TRAILER1=(5:'Grand Total is ',TOT=(21,10,ZD,M5))
Default
for BLKCCT1: None; must be specified.
- REMOVECC
>>-REMOVECC----------------------------------------------------><
Specifies that the ANSI carriage control character
is to be removed from OUTFIL output records for this OUTFIL group
before the records are written. In addition, blank lines are not used
to position the page trailer (TRAILER2) at the bottom of the page.
If
REMOVECC is specified without any of the following report parameters,
it will not be used: LINES, HEADER1, TRAILER1, HEADER2, TRAILER2,
SECTIONS, or NODETAIL.
Sample Syntax: OUTFIL FNAMES=RPTWOCC,
TRAILER1=(3/,'Number of records is ',
COUNT=(TO=ZD,LENGTH=6)),
REMOVECC
Default for REMOVECC: None;
must be specified.
- IFTRAIL
>>-IFTRAIL=(TRLID=(logexp),TRLUPD=(c:item,...)-+---------+-----><
'-,HD=YES-'
IFTRAIL allows you to update count and total values
in an existing trailer (last) record to reflect the actual data records
in an OUTFIL data set. Whereas TRAILER1 lets you build a new trailer
record, IFTRAIL lets you update an existing trailer record using the
COUNT and TOTAL features of TRAILER1. When you add, delete or modify
input data records to create an OUTFIL data set, you can use IFTRAIL
to ensure that the trailer record has accurate updated count and total
values.
The count and total values are determined using the
data records processed as input to OUTFIL. If slash (/) is used in
OUTFIL BUILD to produce multiple output data records, the count and
total values are determined using the data records processed as input
to OUTFIL. For example, if you use OUTFIL BUILD=(1,80,/,1,80) to
create 6 OUTFIL output records from 3 OUTFIL input records, the count
is 3, not 6.
You must identify the trailer record using a unique
condition (for example, 'TRL' in positions 1-3). You then specify
how count and total values in the identified trailer record are to
be updated. The trailer record will NOT be treated as a data record,
that is, no other OUTFIL processing will be performed against the
trailer record. You can optionally specify that the header (first)
record will NOT be treated as a data record.
As a simple example,
you could use the following OUTFIL statement to write the header (first)
record, data records with 'D1', and trailer record (identified by
'9' in position 1) in the OUTFIL data set, and set an accurate count
and total in the trailer record for the included input data records. OUTFIL FNAMES=OUT1,INCLUDE=(10,2,CH,EQ,C'D1'),
IFTRAIL=(HD=YES,TRLID=(1,1,CH,EQ,C'9'),
TRLUPD=(11:COUNT=(M11,LENGTH=8),
25:TOTAL=(15,6,ZD,EDIT=(IIIIIT))))
The trailer
record will not be treated as a data record; it will not be
subject to INCLUDE processing, and will not be used for the updated
count or total values.
Since HD=YES is specified, the header
record will not be treated as a data record; it will not be
subject to INCLUDE processing, and will not be used for the updated
count or total values.
- IFTRAIL
- Allows you to update count and total fields in the trailer record
of the data sets for an OUTFIL group. You can use IFTRAIL to identify
a trailer record and indicate count and total fields to be updated
in that record. The identified trailer record will not be used to
determine the count or totals. If you specify HD=YES, the header
(first) record will not be used to determine the count or totals.
You
cannot specify IFTRAIL with any of the following operands in an OUTFIL
statement: HEADER1, TRAILER1, HEADER2, TRAILER2, NODETAIL, SECTIONS,
LINES, SPLIT, SPLITBY, SPLIT1R, REPEAT, FTOV, VTOF, VLTRIM, VLTRAIL or VLFILL.
You must specify the TRLID
and TRLUPD operands. The HD=YES operand is optional.
- TRLID=(logexp)
- Specifies the criteria to be tested to determine if a record is
the trailer record. When a record is found that meets the criteria,
it will be treated as the last record, and subsequent records will
not be processed for the OUTFIL group. Thus if you use TRLID=(1,1,CH,EQ,C'9')
to identify the trailer record and you have three records with '9'
in position 1, the first record with '9' in position 1 will be treated
as the trailer record, and records after that will not appear in the
OUTFIL data sets.
See the discussion of INCLUDE statement in INCLUDE control statement for details of the logical expressions
that you can use. You can specify all of the logical expressions
for TRLID in the same way that you can specify them for the INCLUDE
statement, except that: - You cannot specify FORMAT=f
- You cannot specify D2 format
- Locale processing is not used
- VLSCMP and VLSHRT are not used. The trailer record must be long
enough to contain all fields in the logical expression. Trailer record
checking will be skipped for any variable-length record that is too
short to contain a field in the TRLID logical expression.
The trailer record will not be treated as a data record;
all other OUTFIL processing (for example, INCLUDE, OMIT, BUILD, OVERLAY,
and so on) will be bypassed for the trailer record. The updated
count and total values will not include the trailer record.
- TRLUPD=(c:item,...)
- Specifies the position where each count or total is to be updated
in the trailer record.
For fixed-length records, the first input
and output data byte starts at position 1. The trailer record will
be truncated or padded with blanks to the length of the data records,
if appropriate. You cannot change the length of the trailer record
using TRLUPD.
For variable-length records, the first input and
output data byte starts at position 5, after the RDW in positions
1-4. The original length of the trailer record will not be changed
for output. You cannot change the length of the trailer record using
TRLUPD. If you specify an item beyond the end of the trailer record,
it will not be updated.
- c:
- specifies the output position (column) in the trailer record to
be updated. If you do not specify c: for the first item, it defaults
to 1:. If you do not specify c: for any other item, it starts after
the previous item. You must specify items in ascending output column
order, and an item must not overlap a previous item in the trailer
record. For a variable-length trailer record, you must not specify
columns 1-4.
- item
- specifies the count or total you want to update. Any of the following
count and total items can be used as described for TRAILER1:
- COUNT=(edit)
- COUNT=(to)
- COUNT+n=(edit)
- COUNT+n=(to)
- COUNT-n=(edit)
- COUNT-n=(to)
- TOTAL=(p,m,f,edit)
- TOTAL=(p,m,f,to)
- TOT=(p,m,f,edit)
- TOT=(p,m,f,to)
The count and total values are determined using the data records
processed as input to OUTFIL.
If TOT or TOTAL is used, the
specified p,m,f field from each data record will be totalled, even
if the trailer record is not found. OUTFIL BUILD, OVERLAY or IFTHEN
processing does NOT affect the values that are totalled; the values
in the original OUTFIL input records are used for the totals.
An
invalid field amount can result in a data exception (0C7 ABEND) or
incorrect numeric output. Be careful to use HD=YES if the header
record does not have valid total fields. For example, if the input
file has these records: H***
0001
0002
T***
and this IFTRAIL operand is specified: IFTRAIL=(TRLID=(1,1,CH,EQ,C'T'),
TRLUPD=(5:TOT=(1,4,ZD,TO=ZD,LENGTH=5))
an 0C7
ABEND will result when DFSORT attempts to total the invalid 1,4,ZD
field in the header (H***) record. The use of HD=YES would prevent
this.
An invalid total field can also be encountered if the
trailer record is not found due to erroneous TRLID conditions. For
example, if the input file has these records: H***
0001
0002
T***
and this IFTRAIL operand is specified: IFTRAIL=(TRLID=(1,2,CH,EQ,C'TR'),
TRLUPD=(5:TOT=(1,4,ZD,TO=ZD,LENGTH=5))
the
last (T***) record will not be identified as the trailer record since
it does not have 'TR' in positions 1-2. Thus, an 0C7 ABEND will result
when DFSORT attempts to total the invalid 1,4,ZD field in the last
(T***) record. The use of the correct condition for identifying the
trailer (T***) record would prevent this.
If slash (/) is used
in OUTFIL BUILD to produce multiple output data records, the count
and total values are determined using the data records processed as
input to OUTFIL. For example, if you use OUTFIL BUILD=(1,80,/,1,80)
to create 6 OUTFIL output records from 3 OUTFIL input records, the
count is 3, not 6.
- HD=YES
- Specify HD=YES if you want the first record treated as a header
record rather than as a data record. With HD=YES, OUTFIL processing
(for example, INCLUDE, OMIT, BUILD, OVERLAY, and so on) will be bypassed
for the header record. The updated count and total values will not
include the header record.
If HD=YES is specified, the TRLID test
will not be applied to the first record.
Sample Syntax: OUTFIL IFTRAIL=(HD=YES,
TRLID=(1,3,CH,EQ,C'TRL'),
TRLUPD=(11:COUNT=(M11,LENGTH=4),
21:TOT=(M11,LENGTH=6)))
Default
for IFTRAIL: None; must be specified.


|
 z/OS DFSORT Application Programming Guide
z/OS DFSORT Application Programming Guide
 Copyright IBM Corporation 1990, 2014
Copyright IBM Corporation 1990, 2014