Upgrading API management
Upgrade the API management component (API Connect) in IBM Cloud Pak® for Integration from version 2020.3 to 2020.4.1, or upgrade to the newest version of API Connect used in 2020.4.
About this task
Table 1 lists the highest (newest) operator version for each version of API Connect (the operand).
| API Connect version | Operator channel version | Highest operator version |
|---|---|---|
| 10.0.1.7-eus | v2.1.7-eus | 2.1.11 |
| 10.0.1.6-ifix1-eus | v2.1.6-eus | 2.1.10 |
| 10.0.1.6-eus | v2.1.6-eus | 2.1.9 |
| 10.0.1.5-ifix4-eus | v2.1.5-eus | 2.1.8 |
| 10.0.1.5-ifix3-eus | v2.1.5-eus | 2.1.7 |
| 10.0.1.5-eus | v2.1.5-eus | 2.1.6 |
| 10.0.1.4-ifix1-eus | v2.1.4-eus | 2.1.5 |
| 10.0.1.2-ifix2-eus | v2.1-eus | 2.1.3 |
| 10.0.1.2-ifix1-eus | v2.1-eus | 2.1.2 |
| 10.0.1.2-eus | v2.1-eus | 2.1.1 |
| 10.0.1.1-eus | v2.1-eus | 2.1.0 |
| 10.0.1.0 | v2.0 | 2.0.0 |
| 10.0.0.0-ifix2 | v1.0 | 1.0.2 |
The upgrade procedure depends on your current version of IBM Cloud Pak for Integration:
- Upgrading the deployed version of API Connect to 10.0.1.7-eus
- Upgrading API management from CP4I 2020.3 to CP4I 2020.4
Upgrading the deployed version of API Connect to 10.0.1.7-eus
Upgrade the API Connect component in CP4I from v10.0.1.1-eus or later to 10.0.1.7-eus.
Before you begin
If you are running API Connect v10.0.1.2-eus, your deployment might be experiencing DNS errors in pgbouncer. Review the known issue to determine whether your deployment is affected and if so, to replace the pgbouncer image before upgrading to API Connect 10.0.1.7-eus.
Complete the following steps to determine whether your deployment is experiencing DNS errors with pgbouncer, and to replace the pgbouncer image if needed. This issue only affects API Connect v10.0.1.2-eus. If you are running a different version of 10.0.1.x-eus, your deployment is not affected and you can proceed directly to the upgrade steps.
- Get the pgbouncer pod
name:
oc get pods -n <APIC_namespace> | grep 'pgbouncer'where
<APIC_namespace>is the namespace where you installed API Connect. - Check the pgbouncer log for the
server DNS lookup failederror message:oc logs <pgbouncer-pod-name> -n <APIC_namespace> | grep 'server DNS lookup failed'
server DNS lookup failed message appears in the log, then your
deployment is impacted and you must replace the pgbouncer image. If other errors appear, this
procedure will not correct them and you should contact IBM Support for assistance. If no errors
appear, you can proceed directly to the upgrade steps.- Get the new pgbouncer image format from the registry where
version 10.0.1.7-eus images were pushed; for example:
<registry-name>/ibm-apiconnect-management-crunchy-pgbouncer@sha256:4a5caaf4e5cd4056ccb3de7d39b8e343b0c4ebce7cae694ccbfbe80924d98752For CP4I, the default
registry-nameis icr. - Get the pgbouncer deployment
name:
oc get deploy -n <APIC_namespace> | grep 'pgbouncer' - Edit the pgbouncer deployment:
oc edit deploy <pgbouncer-deploy-name> -n <APIC_namespace> - In the deployment, replace the container image section with the new image that you downloaded.
- Wait for the pgbouncer pod to restart.
- Exec into the pgbouncer
pod:
oc exec -it <pgbouncer-pod> -n <APIC_namespace> -- bash - Execute
pgbouncer --versionand make sure the response matches the following information:bash-4.4$ pgbouncer --version PgBouncer 1.15.0 libevent 2.1.8-stable adns: evdns2 tls: OpenSSL 1.1.1g FIPS 21 Apr 2020 systemd: yes - Verify that the
server DNS lookup failedno longer appears in the pgbouncer log:oc logs <pgbouncer-pod-name> -n <APIC_namespace> | grep 'server DNS lookup failed' - Delete back-end microservices to force a restart:
- Get the
apimmicroservices pod name:oc get pods -n <APIC_namespace> | grep 'apim' - Delete the
apimpod:oc delete pod <apim-pod> -n <APIC_namespace> - Get the
lurmicroservices pod name:oc get pods -n <APIC_namespace> | grep 'lur' - Delete the
lurpod:oc delete pod <lur-pod> -n <APIC_namespace> - Get the
task managermicroservice pod name:oc get pods -n <APIC_namespace> | grep 'task' - Delete the
task managerpod:oc delete pod <task-manager-pod> -n <APIC_namespace>
- Get the
- Make sure the deployment is up and running before proceeding to upgrade to 10.0.1.7-eus.
About this task
If you already deployed the API Management capability for 2020.4.1 using API Connect 10.0.1.1-eus or later, you can upgrade to 10.0.1.7-eus by completing the following steps.
Procedure
If you are upgrading from an API Connect release prior to 10.0.1.7-eus, complete steps 5, 6, and 7 to resolve certificate issues (certificate manager was upgraded in API Connect 10.0.1.7-eus). Otherwise, skip to step 8.
-
Update the DataPower Gateway and API Connect operands:
-
Click
 at the end of the current row, and then click Change version.
at the end of the current row, and then click Change version.
-
Click
Upgrading API management from CP4I 2020.3 to CP4I 2020.4
About this task
Upgrading to 2020.4 requires you to update the version of OpenShift to 4.6.x, then update IBM Cloud Pak foundational services, Platform Navigator, and API Connect to the eus
subscription channel. When you upgrade the IBM Cloud Pak for Integration API management capability
to release 2020.4, you deploy the newest version of API Connect.
Procedure
Complete the steps in the following sequence:
-
Use the OCP UI to upgrade the API Connect operator by changing the subscription channel to the
eusversion.Notes:- After the operators are upgraded, the following status condition displays for API Connect on the
Platform Navigator UI:
Product version 10.0.1.0-627 is not compatible with your current platform.
This is a temporary condition because you have not completed the upgrade yet. You can ignore this message.
- If you upgrade from API Connect V10.0.1.0 directly to V10.0.1.x on OpenShift,
you will encounter a known problem with the
API Connect operator. During the upgrade, theAPI Connect operatorwill be stuck in the "Upgrade available" state as shown in the following image: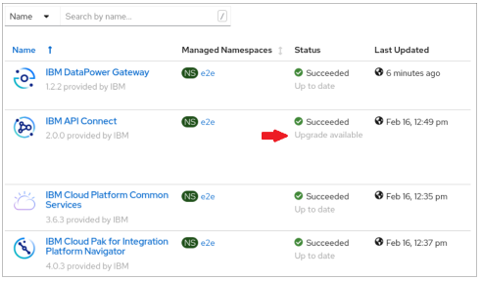
In addition, the
catalog-operatorin theOLMnamespace will throw the following error:sync "<namespace>" failed: found more than one head for channelYou can work around the error by completing the following steps:
This workaround will not have a downtime impact.- Delete the following operators:
DataPower operator,IBM Cloud Platform Common Services, andibm-apiconnect operator. - Re-install the
ibm-apiconnect operator.
- Delete the following operators:
- After the operators are upgraded, the following status condition displays for API Connect on the
Platform Navigator UI:
-
Use Platform Navigator to complete the upgrade for API Connect
and DataPower by changing the subscription channel to the
10.0.1.7-eusversion.DataPower is deployed as a component of API Connect, so when you set the channel for API Connect, DataPower is automatically upgraded as well.
Note: While you navigate in Platform Navigator to complete this step, the following message might display:Minor issue deploying stack-name. Product version 10.0.1.0-627 is not compatible with your current platform.
This is another temporary message indicating that you have not completed the upgrade yet, and you can ignore it. If the message appears again after you dismiss it, continue dismissing it.
-
In the Platform Navigator, click the Runtimes tab.
If an update is available for a runtime, the
 displays next to the runtime's current Version number.Attention: Verify that the Status displays "Ready" before attempting an update.
displays next to the runtime's current Version number.Attention: Verify that the Status displays "Ready" before attempting an update. -
Click at the end of the current row, and then click Change version.
-
In the Platform Navigator, click the Runtimes tab.