Data storage in storage pools
Logical storage pools are the principal components in the IBM Spectrum Protect model of data storage. You can optimize the usage of storage devices by manipulating the properties of storage pools and volumes.
Types of storage pools
The group of storage pools that you set up for the server is called server storage. You can define the following types of storage pools in server storage:
- Primary storage pools
- A named set of volumes that the server uses to store backup versions of files, archive copies of files, and files that are migrated from client nodes.
- Copy storage pools
- A named set of volumes that contain copies of files that reside in primary storage pools. Copy storage pools are used only to back up the data that is stored in primary storage pools. A copy storage pool cannot be a destination for a backup copy group, an archive copy group, or a management class for space-managed files.
- Container-copy storage pools
- A named set of volumes that contain a copy of data extents that reside in directory-container storage pools. Container-copy storage pools are used only to protect the data that is stored in directory-container storage pools.
- Active-data storage pools
- A named set of storage pool volumes that contain only active versions of client backup data.
Primary storage pools
When you restore, retrieve, recall, or export file data, the requested file is obtained from a primary storage pool. Depending on the type of primary storage pool, the storage pools can be onsite or offsite. You can arrange primary storage pools in a storage hierarchy so that data can be transferred from disk storage to lower-cost storage such as tape devices. Figure 1 illustrates the concept of primary storage pools.
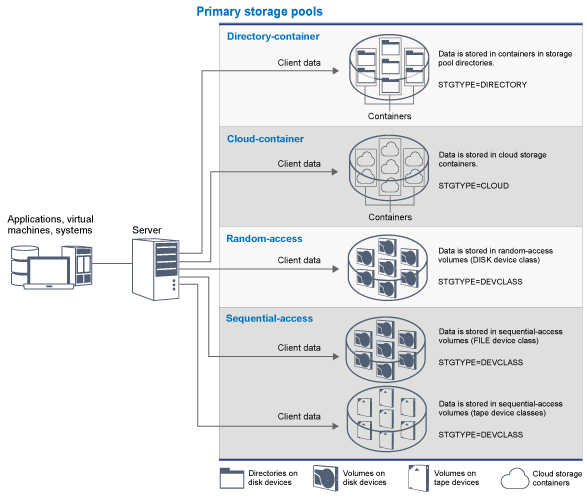
- Directory-container storage pools
-
A storage pool that the server uses to store data in containers in storage pool directories. Data that is stored in a directory-container storage pool can use either inline data deduplication, client-side data deduplication, inline compression, or client-side compression. Inline data deduplication or inline compression reduces data at the time it is stored.Tip: Data that is compressed first cannot be deduplicated, however, deduplicated data can be compressed.
By using directory-container storage pools, you remove the need for volume reclamation, which improves server performance and reduces the cost of storage hardware. You can protect and repair data in directory-container storage pools at the level of the storage pool. You can tier data that is stored in a directory-container storage pool to a cloud-container storage pool.
Restriction: You cannot use any of the following functions with directory-container storage pools:- Migration
- Reclamation
- Aggregation
- Collocation
- Simultaneous-write
- Storage pool backup
- Virtual volumes
- Cloud-container storage pools
-
A storage pool that a server uses to store data in cloud storage. The cloud storage can be on premises or off premises. The cloud-container storage pools that are provided by IBM Spectrum Protect can store data to cloud storage that is object-based. By storing data in cloud-container storage pools, you can exploit the cost per unit advantages that clouds offer along with the scaling capabilities that cloud storage provides. You can use cloud tiering to lower costs by moving data from disk storage to a cloud-container storage pool. IBM Spectrum Protect manages the credentials, security, read and write I/Os, and the lifecycle for data that is stored to the cloud. When cloud-container storage pools are implemented on the server, you can write directly to the cloud by configuring a cloud-container storage pool with the cloud credentials. Data that is stored in a cloud-container storage pool uses both inline data deduplication and inline compression. The server writes deduplicated, compressed, and encrypted data directly to the cloud. You can back up and restore data or archive and retrieve data directly from the cloud-container storage pool.
You can define the following types of cloud-container storage pools:
- On premises
- You can use the on premises type of cloud-container storage pool to store data in a private cloud, for more security and maximum control over your data. The disadvantages of a private cloud are higher costs due to hardware requirements and onsite maintenance.
- Off premises
- You can use the off premises type of cloud-container storage pool to store data in a public cloud. The advantage of using a public cloud is that you can achieve lower costs than for a private cloud, for example by eliminating maintenance. However, you must balance this benefit against possible performance issues due to connection speeds and reduced control over your data.
- Storage pools that are associated with device classes
-
You can define a primary storage pool to use the following types of storage devices:
- DISK device class
- In a DISK device type of storage pool, data is stored in random access disk blocks. You can use caching in DISK storage pools to increase client restore performance with some limitations on server processing. Space allocation and tracking by blocks uses more database storage space and requires more processing power than allocation and tracking by volume.
- FILE device class
- In a FILE device type of storage pool, files are stored in sequential volumes for better sequential performance than for storage in disk blocks. To the server, these files have the characteristics of a tape volume so that this type of storage pool is better suited for migration to tape. FILE volumes are useful for electronic vaulting, where data is transferred electronically to a remote site rather than by physical shipment of tape. In general, this type of storage pool is preferred over DISK storage pools.
- ARCHIVEPOOL
- In the STANDARD policy, this storage pool is the destination for files that are archived from client nodes.
- BACKUPPOOL
- In the STANDARD policy, this storage pool is the destination for files that are backed up from client nodes.
- SPACEMGPOOL
- This storage pool is for space-managed files that are migrated from IBM Spectrum Protect for Space Management client nodes.
Copy storage pools
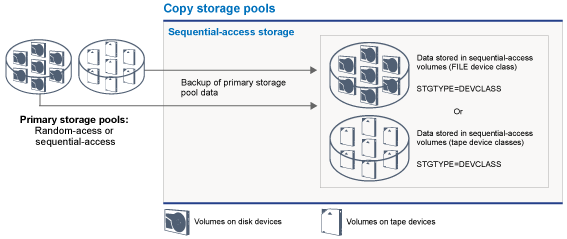
You can move the volumes of copy storage pools offsite and still have the server track the volumes. Moving these volumes offsite provides a means of recovering from an onsite disaster. A copy storage pool can use sequential-access storage only, such as a tape device class or FILE device class.
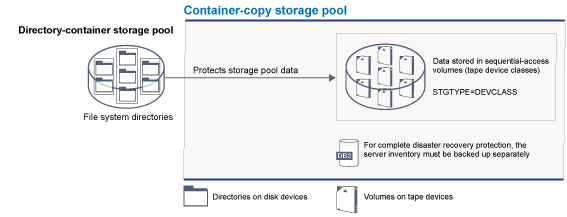
Container-copy storage pools
A server can protect a directory-container storage pool by storing copies of the data in a container-copy storage pool. Data in container-copy storage pools is stored on tape volumes, which can be stored onsite or offsite. Damaged data in directory-container storage pools can be repaired by using deduplicated extents in container-copy storage pools. Container-copy storage pools provide an alternative to using a replication server to protect data in a directory-container storage pool.
Container-copy storage pools can be used to repair minor to moderate directory-container storage pool damage, which includes damaged containers or directories. However, replication is the only way to provide complete disaster recovery protection for directory-container storage pools. With replication, you can directly restore client data from the target server if the source server is unavailable.
- With replication, you can directly restore client data from the target server if the source server is unavailable.
- With container-copy storage pools, you must first restore the server from a database backup and then repair directory-container storage pools from tape volumes.
Figure 3 illustrates the concept of container-copy storage pools.
- If replication is enabled, you can create one offsite container-copy pool. The offsite copy can be used to provide extra protection in a replicated environment.
- If replication is not enabled, you can create one onsite and one offsite container-copy storage pool.
Depending on the resources and requirements of your site, the ability to copy directory-container storage pools to tape has the following benefits:
- You avoid maintaining another server and more disk storage space.
- Data is copied to storage pools that are defined on the server. Performance is not dependent on, or affected by, the network connection between servers.
- You can satisfy regulatory and business requirements for offsite tape copies.
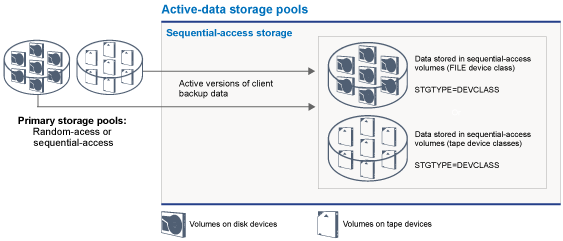
Active-data storage pools
- Increase the speed of client data restore operations
- Reduce the number of onsite or offsite storage volumes
- Reduce the amount of data that is transferred when you copy or restore files that are vaulted electronically in a remote location
- FILE volumes do not have to be physically mounted
- Client sessions that are restoring from FILE volumes in an active-data pool can access the volumes concurrently, which improves restore performance